
Abstract
The core part of the popular tracking-by-detection trackers is the discriminative classifier, which distinguishes the tracked target from the surrounding environment. Correlation filter-based visual tracking methods have the advantage of computing efficiency over the traditional methods by exploiting the properties of circulant matrix in learning process, and the significant progress in efficiency has been achieved by making use of the fast Fourier transform at detection and learning stages. But most existing correlation filter-based approaches are mainly restricted to translation estimation, which are susceptible to drifting in long-term tracking. In this article, a compressed multiple feature and adaptive scale estimation method is presented, which uses multiple features, including histogram of orientation gradients, color-naming, and raw pixel value to further improve the stability and accuracy of translation estimation. And for the scale estimation, another correlation filter is trained, which uses the compressed histogram of orientation gradients and raw pixel value to construct a multiscale pyramid of the target, and the optimal scale is obtained by exhaustively searching. The translation and scale estimation are unified with an iterative searching strategy. Extensively experimental results on the benchmark data set of scale variation show that the performance of the proposed compressed multiple feature and adaptive scale estimation algorithm is competitive against state-of-the-art methods with scale estimation capabilities in terms of robustness and accuracy.
Keywords
Introduction
Visual object tracking is one of the fundamental problems of computer vision and widely used in many applications, such as driverless vehicle, intelligent human–computer interaction, security, video surveillance and analysis, video encoding, augmented reality, traffic control in intelligent transportation system, video editing, 1 and so on. It also forms a basic part of higher level vision tasks such as scene analysis and behavior recognition. Although visual tracking problem has been studied for several decades and considerable progress has been made in recent years, 2 –4 robust visual tracking is still an open research problem. There are some challenging factors for visual tracking, such as appearance changing, scale variations, occlusions, motion blur, and fast motion, some of these factors come from the motion between the object and camera, some come from the target itself, such as geometric deformations, and some others come from the environment, such as illumination changes; all these factors make the visual tracking a very challenging task.
Generally, the existing tracking approaches can be classified into two groups according to the appearance model, discriminative model-based or generative model-based. Generative model-based trackers 5 –14 try to build a metric model using, for example, templates or statistical models to search the best match in the candidate patches for the tracked object. And discriminative model-based methods usually use the binary classifier or learning-based techniques to recognize the tracked object from the background. For example, Struck 15 is a representative discriminative tracker, where the target’s location is directly connected with the training samples by the structured support vector machine (SVM) and gets the impressive result in the visual tracking benchmark data set. 16 tracking-learning-detection (TLD) 17 divides the tracking task into three submodules, Lucas-Kanade algorithm-based tracking module, a boosting classifier-based detecting module, and P-N learning-based learning module. As the redetection function is included, it may work robustly even in the some challenging videos. Multiple instance learning (MIL) 18 tries to construct the tracker by using a set of positive samples with a boosting variant approach. The classifier with online multi-instance boosting 19 or semiboosting 20 strategies have been adapted for object tracking. Zhang et al. 21 propose a real-time compressive tracking method, which uses a sparse measurement matrix to extract the features while the tracking problem is modeled as a binary classification. The discriminative learning methods made a big progress in visual tracking research recently.
The tracking task of discriminative learning method can be formulated as an online learning process. When an initial image patch which contains the object to be tracked is provided, the key problem is to train a classifier to discriminate between the target and its surrounding environment. The classifier will exhaustively evaluate at as much locations as possible in order to find the most likely location, which will be taken as the positive sample and be used to update the model. The image patches from other locations and scales in the image are taken as negative samples to train the classifier. Theoretically, the more samples used for the training process, more accurate and stable results we can get. Due to the time-critical nature of visual tracking, a challenging issue is that how to use as many samples as possible for the training, at the meantime, keep the computational demand low. Traditional approaches always randomly select a few samples each time. 15,17,18,21 However, some works show that under-sampling negatives may inhibit the performance in discriminative learning-based tracking. 22
Recently, discriminative correlation filter (DCF) has successfully been applied to visual tracking. 23 –25 Correlation filter (CF) has been usually used as a fundamental tool in signal processing field since the last 1980s. It can be used as a similarity measurement between two signals and provides a reliable distance metric. Moreover, the correlation operation in time domain can be implemented with an element-wise multiplication operation in Fourier domain, which avoids the time-consuming convolution operation. For visual object tracking task, the CF-based tracker usually locate the target in each frame by learning a DCF. Generally, if more negative samples, which are always relevant to the environment, are used for learning in discriminative methods, the better results can be obtained. By making use of the circulant matrix, we can theoretically take thousands of samples at different relatively translated position into learning. The learning algorithm is implemented in Fourier domain which greatly decreases the computing load, and it also becomes easier when we add more samples. These characteristics of DCF make it a potential application in visual tracking. CF-based methods are the mainstream for visual tracking presently, but most of these methods only take the translation estimation into consideration; this limits the performance in long-term tracking application.
In this article, we address the problems that the target undergoes large appearance changing mainly caused by the relative motion between the camera and target, or the deformation of target and heavy occlusion, and so on, in long-term visual tracking with CF. For the long-term visual tracking of discriminative model-based method, a big well-known issue is the stability–plasticity dilemma. 26,27 That is, if we use some stable samples, such as the target assigned in the first frame, to train the classifier, then the tracker is unlikely to drifting and more robust to occlusions. However, if the target appearance variation is not taken into account in this case, the tracker is doomed to work not well in long-term visual tracking process. On the contrary, if a highly adaptive online classifier is employed, it may results in drifting because of noisy updates. To balance this dilemma, benefitting from the CF-based visual tracking framework, we propose a multiple property-based visual tracking method in this article. The proposed method encodes the target appearance and its surrounding context with multiple properties, which include histogram of orientation gradients (HOG), color-naming, and raw intensity value. Because more properties are integrated in the CF, this makes the proposed method resistant to heavy occlusion and large deformation. Compared with existing methods, most of them only use the HOG properties and prone to drifting in long-term tracking, the proposed algorithm improves the accuracy and reliability considerably. Figure 1 presents some examples where the proposed algorithm outperforms against the other CF-based method, and the tracking results of the proposed method is drawn in red rectangle.

The improvement in terms of accuracy. (Rectangle drawn in blue line is the results of Scale Adaptive with Multiple Features tracker (SAMF), green one is for fDSST, red one is for the proposed method, magenta color one is for Long-term Correlation Tracking (LCT), black one is for Collaborative Correlation Tracking (CCT), and white one is for the ground truth.)
We further address the adaptive scale estimation issue in the long-term tracking, and a compressed multifeature scale space search strategy is proposed. Generally, by exploiting the fast Fourier transform (FFT) at both detection and learning stages, CF-based tracking methods can achieve a significant gain in speed. But currently, most DCF-based tracking methods only focus on the translation estimation. For a long-term tracking task in mobile robot application, the DCF-based tracker may imply poor performance if there are significant scale variations of the target. A few literatures work show that scale estimation plays a very important role in visual tracking task. It can improve the accuracy and stability of the tracking results. 28,29 To estimate the scale change in long-term CF-based tracking, the tracking problem can be decomposed into subtasks, translation, and scale estimation. For the adaptive scale estimation, although there are several strategies can be adopted, some of them are computing expensive. In this article, by making use of the multifeature-based target model for the translation estimation and compressed scale space search strategy, the computing demand of the proposed algorithm is well balanced. Additionally, we evaluate the performance of the proposed approach on a large-scale benchmark with more than 50 challenging video sequences. 16 Extensive experimental results show that the proposed approach outperforms against the state-of-the-art CF-based methods in terms of robustness and accuracy.
Related works
The existing methods which are closely related to our works include (i) CF-based tracking and its extension in multiresolution and (ii) adaptive scale estimation in CF.
CF-based tracking
This kind of visual tracking method has been proved to be very competitive with the traditional approaches. It is very computing efficient and can be run at a very high frames per second. Because of its computing efficiency and high performance, CF-based tracking methods have drawn considerable attention recently. Early works of applying CF to visual tracking include the minimum output sum of squared error (MOSSE) filter proposed by Bolme et al. 23 The proposed method is based on raw intensity value; the appearance change of target is encoded by the learned filter and updated on every frame. Henriques et al. 24 extend CFs to kernel space in the Circulant Structure with Kernel Tracker (CSK) tracker which builds on raw intensity value and achieves the highest speed up-to-now. Furthermore, they demonstrate that the DCF formulation can be equivalently modeled as learning a ridge regression on the involved training sample patches, besides the set of all cyclic shifted samples. After that, kernel method is introduced to CFs and some literatures have investigated the generalization of DCF-based tracker recently. For example, Galoogahi et al. 25 extend the DCF with multichannel filter. From a signal processing perspective, they formulate the descriptors popularly used in pattern detection, such as HOG or SIFT, as a correlation between a multichannel detector/filter and a multichannel image, and a single-channel response map is obtained which indicates where the pattern (e.g., object) exists. However, this kind of filter cannot directly apply to the online tracking problem. Based on their works, Henriques et al. 22 further apply HOG feature with CSK method and propose the kernelized version of CF-based tracking algorithm.
Multichannel features application
HOG 30 is one of the most popularly used visual features, where a histogram of the discrete gradient orientation is counted. Usually, 31 gradient orientation bins were used in the literatures. Additionally, color-naming feature is another powerful feature, 31 –33 it is linguistic label and displays a certain amount of photometric invariance and widely applied in many visual applications, such as image description, object detection, and recognition, and the results are promising. In this article, we transform from the original red-green-blue (RGB) space to the color name space as described in Weijer et al. 34 and the result is an 11-dimensional color vectors. The HOG and color-naming feature are complementary with each other. Generally, HOG addresses the gradient information while color-naming lays stress on the color property. A novel framework of multichannel filter has been proposed in reference, 25 which can be used to integrate multichannel features/properties efficiently in the frequency domain. Based on the CSK tracker, Danelljan et al. 35 exploit the color-naming feature of target and learning an adaptive CF by mapping multichannel features into a kernel space. By integrating the HOG and color-naming features under the CF framework, Li and Zhu. 28 get promising results. On one hand, the accuracy and robustness of the tracker are improved by multifeature integration, even with the more challenging scenarios. Our analysis shows that, by fusing multifeature in the framework of CF, the stability–plasticity dilemma in discriminative model-based method is improved. But on the other hand, as aforementioned, both the HOG and color-naming feature use a high-dimensional feature descriptor, which increase the computing power greatly. For the time-critical nature of real-timing tracking, we need to find a balance between the tracking performance and computing efficiency.
Scale space estimation
The DCF-based approach can accurately locate target in many different challenging scenarios. But most of DCF-based trackers are restricted to translation estimation of the target. This will greatly limit the performance when there exist significant scale variations of the target. Furthermore, in many tracking applications, 36 the target scale can provide important information and plays very important rule in the tasks. Recently, Li and Zu 28 proposed a kernelized correlation translation filter with multiresolution extension. To solve the scale estimation problem, the target in different scales is sampled first, then these samples are resized into a prefixed size, and the scale with the highest correlation score is taken as the final result. However, to get sufficient scale accuracy, the translation filter needs to be run at several resolution layers; this brings a higher computational cost. By incorporating context information into filter learning, Zhang et al. 37 estimate the scale variation based on consecutive correlation results. In Discriminative Scale Space Tracking (DSST) tracker, 38 a HOG feature-based adaptive multiscale CF is learned to cope with the scale change problem. By learning the appearance changes caused by scale variations directly and using fused features like raw intensity value and HOG feature, DSST tracker can estimate the target scale adaptively and track at a higher frame rate. However, this method does not address the online model updating issue. And these CF-based trackers are susceptible to drifting. Danelljan et al. 29 employed an adaptive feature dimensionality reduction method as in Felzenszwalb et al. 30 to lower down the computational cost while tracking performance is preserved. A collaborative correlation tracker is proposed in Zhu and Wang, 39 which estimate the scale factor by a kernelized matrix. By using a tracking-by-detection framework, Ma et al. 40 also proposed to decompose the tracking task into two subtasks, such as translation and scale estimation, and a redetection scheme is employed. For the scale estimation, a multiscale pyramid of the target is constructed; by using a target regression method, the scale variation is estimated, which is as same as in DSST method.
Currently, based on CF, three main strategies for scale estimation are proposed—multiresolution-based approach, joint scale space filter, and iterative joint scale space estimation. The multiresolution-based scale estimation method applies a sample searching strategy in the scale space; as in Scale Adaptive with Multiple Features tracker (SAMF) method, 28 the fused feature-based translation estimation and the scale estimation are separated and processed. Instead of estimating the translation and scale separately, joint scale space-based method tries to jointly estimate the scale and translation of the target. In a multiscale pyramid space, the correlation scores of a rectangle region are computed. The translation and scale estimation are then obtained by searching the maximum correlation score. Obviously, joint scale space-based method suffers from the computational cost and is not suitable for real-time application. To reduce the effects of the shearing distortion in scale space, the iterative scale space filter strategy can be employed, just like in DSST. 38,29 In order to reduce the computing cost as possible, an iterative joint scale space estimation is employed in this article.
Multiple feature integration in CFs
The proposed tracking approach in this article is based on the learning DCF. 23 After extracted a set of samples which are actually the image patches of the target, the location of the target in the coming frame is determined by learning an optimal CF in a DCF-based tracking method. This process can be equivalently defined as learning a classifier with all cyclic shifted sample patches as described in MOSSE tracker. 24 DCF approach is recently extended to multidimensional feature expressions. In this work, to enhance the robustness and accuracy for long-term tracking task, where the target may suffer from significant appearance variation, we resolve the tracking problem to two subtasks—translation estimation and scale estimation, and both the translation and scale estimation are using multichannel and multiproperty-based CFs. To compensate for the efficiency caused by the fused features, an iterative joint scale space search strategy and a dimensionality reduction scheme are adopted.
In this section, we start from the linear regression, the basic of circulant matrix, CF, and single-channel CF—MOSSE filter are introduced; then, the single-channel CF is extended to multichannel CF. The basic principle of multichannel-based CF visual tracking is illustrated in Figure 2. Based on multichannel CF, the translation and scale estimation method are derived in detail.

Multichannel-based correlation filter. Each layer of X in the left indicates a feature channel, which is correspondent to its filter h, and the correlation results of every channel are summed up to get the final response map y.
Ridge regression
As illustrated in formula (1), the first part to be minimized in the formula is a standard least square estimator, by putting further constraints on the parameters w which correspondent to the second part, and ridge regression penalizes the size of the regression coefficients. The solution of formula (1) is simple and closed-form; however, it can get high performance which is comparable with the complicated methods, like Support Vector Machines. For the tracking tasks in DCF, a function
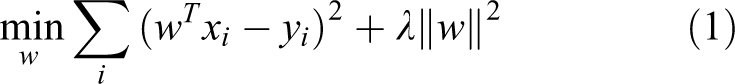
where λ is a regularization or penalty coefficient that controls overfitting, as in the SVM. The solution of the cost function in (1) is closed-form and is solved by Rifkin et al.
41

where the matrix

where XH is defined as the Hermitian transpose, that is,
Generally, if we have large number of samples, then we will have a large system composed of linear equations to get the solution. For visual tracking tasks, if more samples can be used for training, the performance of the classifier can be improved. But due to the time-critical requirement of visual tracking application, it is conflict between incorporating as many samples as possible and keeping the computational demand low. Fortunately, this confliction can be solved by using the properties of circulant matrix that is a special case of xi, which will be discussed in the following section.
Circulant matrix
For simplicity but without losing generality, we first address on single-channel, one-dimensional signal. Then with a straightforward way, the results will be easily generalized to multichannel, 2-D images.
A circulant matrix is a typical matrix which every row vector is rotated one element to the right related to the previous row vector. Let a n × 1 vector x represents a patch, which is correspondent to the interested object; here, it is called as the base sample, let

The matrix
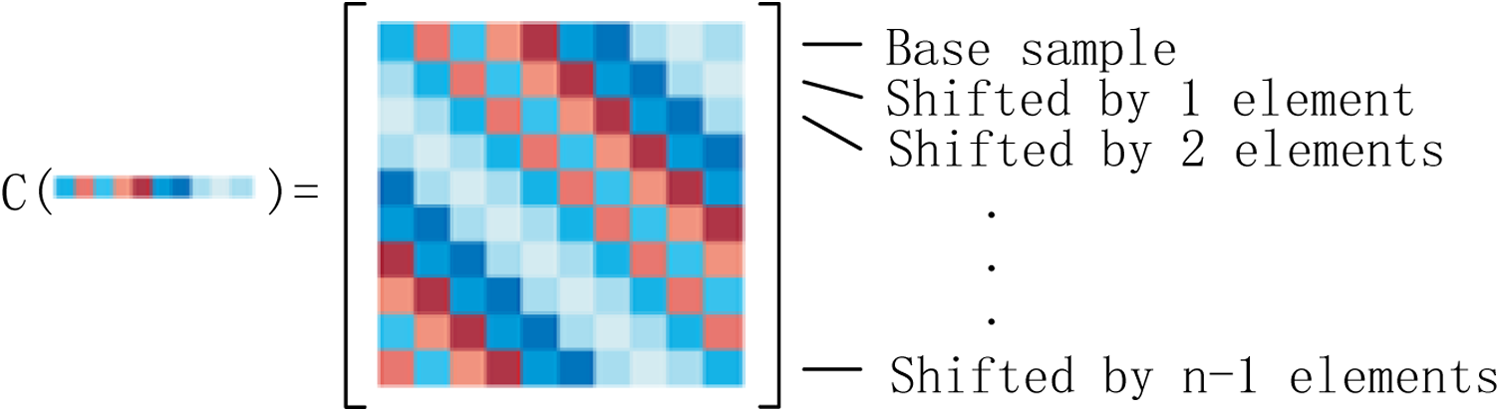
The construction of a circulant matrix. The rows are cyclic shifts of a base sample or its translations in 1-D.

The cyclic shifts of a base sample both in vertical and horizontal direction. The base sample is the middle one, and the number under image is the translated offset in pixels.
According to the property of cyclic shift, for the n × 1 vector x, we will obtain the same signal x for every n shifts. Then, all the shifted signals can be expressed as
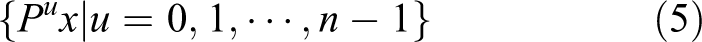
For the full set of the shifted signals, because of the cyclic property, if we put the base sample in the middle position of this set, then the previous half of this set can be regarded as the shifted samples in the negative direction, and the left half are the shifted samples in the positive direction. The larger distance from the base sample, the more shift related to it. When we use the base sample and the shifted samples as the rows of a matrix X as follows

then we get a circulant matrix C(x). The resulting pattern is illustrated as in Figure 3. There are several intriguing properties for circulant matrix.
42
The most useful and amazing property is that, disregarding of the base sample vector

where F does not depend on the sample
The CF
Circulant matrix is powerfully tool and provides a bridge between the popular learning methods and traditional signal processing. It can be diagonalization by a DFT as in equation (7), and the linear equations that contain them can be solved quickly with FFT. In our case, we can use circulant matrix to facilitate the linear regression in equation (3) as the training samples are formed by the cyclic shifted samples. And with DFT, the cyclic convolution can be converted into component-wise multiplication.
According to equation (7), we can have

Here,

By defining the element-wise product as ⊗, the product of two diagonal matrices in equation (9) is rewritten as follows

Here, the item within brackets is intrinsically the autocorrelation of the signal x, and it is also known as the power spectrum in the Fourier domain.
43
By replacing equations (10) in (3), we have

By using the unitarity property of F, we can have
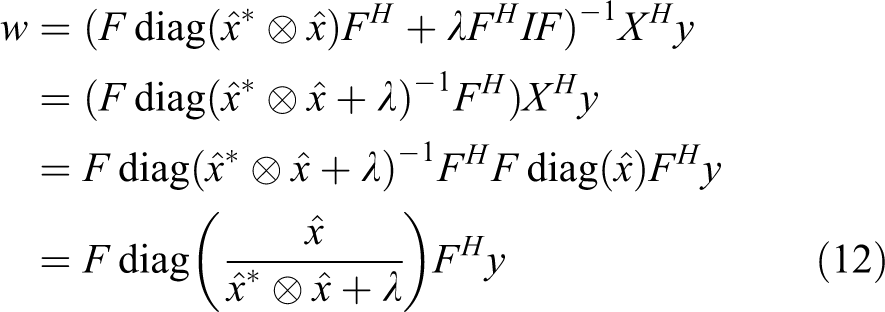
It is then equivalent to
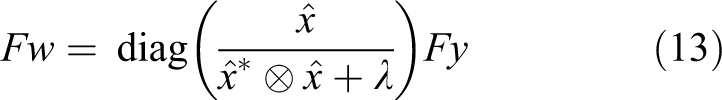
As aforementioned, for any vector z, we have

Because the first item in the right-hand side of equation (14) is a diagonal matrix, the product can be briefly expressed as follows

It is element-wise division in equation (15). The results are expressed in frequent domain, we can estimate w in spatial domain by the inverse DFT.
MOSSE filter
The MOSSE filter
23
is one of the earliest works which introduces the CF into visual tracking. It trains the filter by minimizing the total squared error over multiple base samples

with the products rule for block matrices, and by factoring the bracketed expression, it is rewritten as follows

It looks like equation (3) exactly, except for the sums. We can follow the same steps as aforementioned to diagonalize it; then, the result filter is obtained by

Comparing it with equation (12), the only difference here is that MOSSE filter try to minimize the error over multiple base samples, but equation (12) is only for a single base sample. Moreover, the MOSSE filter does not support multiple channels.
Multichannel CF
Now we extend the single-channel, one-dimensional signal to multichannel CF.
Provided that the target sample x at each location n is expressed as a d-dimensional feature vector
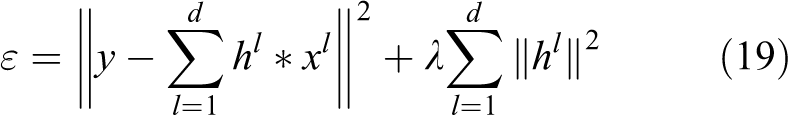
where the symbol* represents the correlation operation. The second term in right-hand side of equation (19) defines a regularization term on filter h with a weight value λ.
Equation (19) defines a linear least squares (LS) problem, and the solution can be obtained efficiently when it is converted to Fourier domain. To be simple but without loss of generality, the desired correlation output y is chosen as a preset standard deviation Gaussian function. The solution for equation (19) is achieved by

where Hl is the learnt filter for feature channel l and is expressed in Fourier domain,
Update rules
According to equation (20), the optimal filter h can be estimated if a single sample x is provided. In practice, to get a robust CF h, more samples

When a new frame is captured, a new sample zt will be extracted from the interested region of transformations. It is correspondent to the image patch which is centered on the predicted target location in standard translation filter case. The test sample zt is extracted as the training samples xt, with the same representation. The correlation score yt by using the DFT is computed in the Fourier domain as
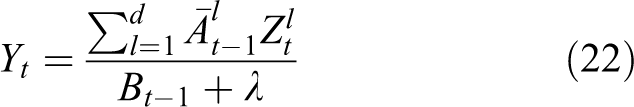
Where
Translation filter and adaptive scale filter
Multichannel-based translation filter
The translation filter in this article is built as in KCF tracker. 22 By making use of the circulant matrix structure, KCF tracker can employs much negative samples to enhance the discriminative performance with the tracking-by-detection scheme. It can get very promising results while the computing power is lower than other kind of discriminative model-based method.
For the linear ridge regression problem, as described in equation (1), the regression function f(.) is expressed as the linear combination of basic samples:
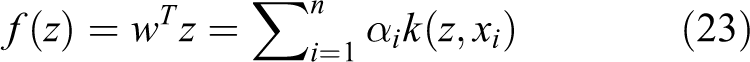
to solve the problem, which allows more powerful classifier. The possible kernel functions we can use including Gaussian kernel, polynomial function, and so on. For the kernelized version of ridge regression, the solution of the dual space coefficients α is learnt by

where kxx refers to the kernel correlation. Same as the linear case, α is learnt in Fourier domain. We adopt the most commonly used Gaussian kernel, and the circulant trick is applied as

where x, x′ are two arbitrary vectors,
The labeled output y for training is usually a Gaussian function, where at the center of target, it is one and decays smoothly to zero for other shift. In the next frame, the image patch z at the same location is regarded as the base sample to get the correlation response map in Fourier domain

where
Multiple channels extension
The advantages of the kernel correlation function are obvious, for example, we only need to compute the vector norm and dot product, which allow us to extend it to multiple channels. Let x is a vector with C individual channels,
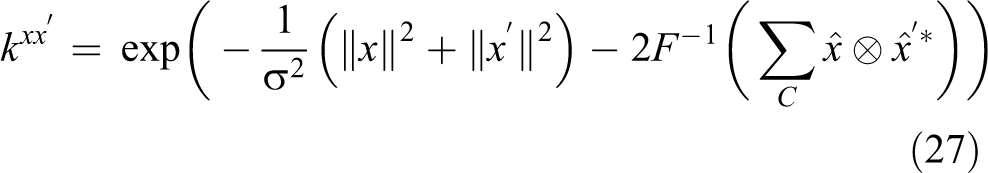
For the visual tracking application, if we can use more strong features besides the raw gray scale pixels, the accuracy and stability can be improved. Furthermore, we can use different features to explore the advantages of feature fusion.
In this article, we use three kinds of features in the proposed method. Besides the raw intensity value, two other features, HOG 30 and color-naming, are also employed for translation and scale filter. HOG is a popular used visual features and can be implemented efficiently. Color-naming is the linguistic color label, and the distance expressed in color label space is more like human perception and better than the other color space expression, such as RGB space. We adopt the method like in Weijer et al. 34 to map RGB space to the color names space; the result is an 11-D vector. These two types of feature provide much complementary information about the target. The idea is quite simple and straight forward, but the performance gain is promising. For the multiple-channel application, it should be noted that different features may have different sizes, so an alignment operation may be applied first before the correlation process.
In our experiments, we found that by using the feature fusion of HOG, color-naming, and raw pixel intensity, the accuracy and stability of tracking results are improved greatly, but the computing load is not suitable for real-time application. To reducing the computing power without loss of the performance, a dimension compressing strategy is used.
Dimensionality reduction
Generally, in a single-channel CF, the computational cost is mainly spent on FFT. For the multichannel filter, the amount of FFT computation scale linearly with the dimension d of the feature. To cut down the FFT computations, we adopt a standard Principle component analysis (PCA)-based strategy to decrease the dimensionality of the CF as similar to the study of Danelljan et al. 29,35 Here, we briefly summarize this dimensionality reduction approach.
A target template
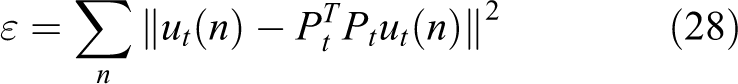
where n is the range in the template ut, and
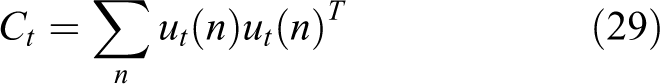
The solution of equation (28) can be obtained by the eigenvalue decomposition of equation (29). The rows of the obtained matrix Pt are equal to the
After we get the projection matrix Pt, then the filter can be updated using the projected training sample and target template as
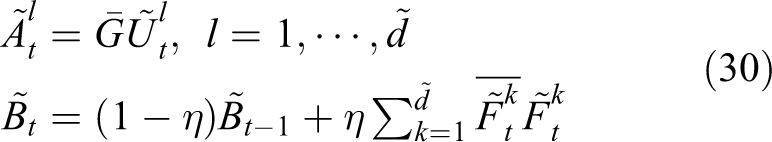
where

The scores for the test sample zt are computed similarly as to equation (22), with the projected sample
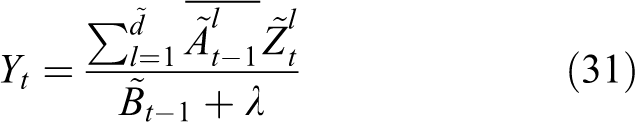
To compensate for the efficiency of multichannel features, we use PCA–HOG
30
for feature expression, which is implemented as in reference.
44
To save the computing load, a coarser feature grid is used. To get pixel-level correlation scores, an interpolation technique is applied. The correlation feature vector is first established using HOG with 4×4 cells; then, the vector is augmented by color-naming and the average gray scale value in the correspondent cell. The gray scale values are normalized to the range
Adaptive scale estimation
Among the three main scale estimation strategies, both the multiresolution-based 28 and joint scale space filter methods are suffered from the computational cost and are not suitable for real-time application. Another issue is that, at the detection step, because the feature pyramid in joint scale space filter method is always constructed around the predicted target location. The difference between the predicted location and actual target center may result in a shearing effect. It is mainly caused by the errors in the predicted target location. Because the shearing part introduces a bias in the translation estimate, it will greatly affect the performance of the filter. In this article, we adopt the iterative joint scale space estimation strategy as in DSST tracker, which can cope with this issue.
Typically, based on the observation that scale variation of the target between two consecutive frames is small compared with the change in translation, the translation filter
As shown in Figure 5, we use a 2-D multichannel feature, which includes PCA–HOG, color-naming, and raw intensity value for translation filter and a separate 1-D scale filter for scale estimation as in DSST tracker. To set up the training sample ft, scale, the features are extracted using different window sizes around the target. Assuming P × R is the window size in present frame and S is the scale filter size. For each

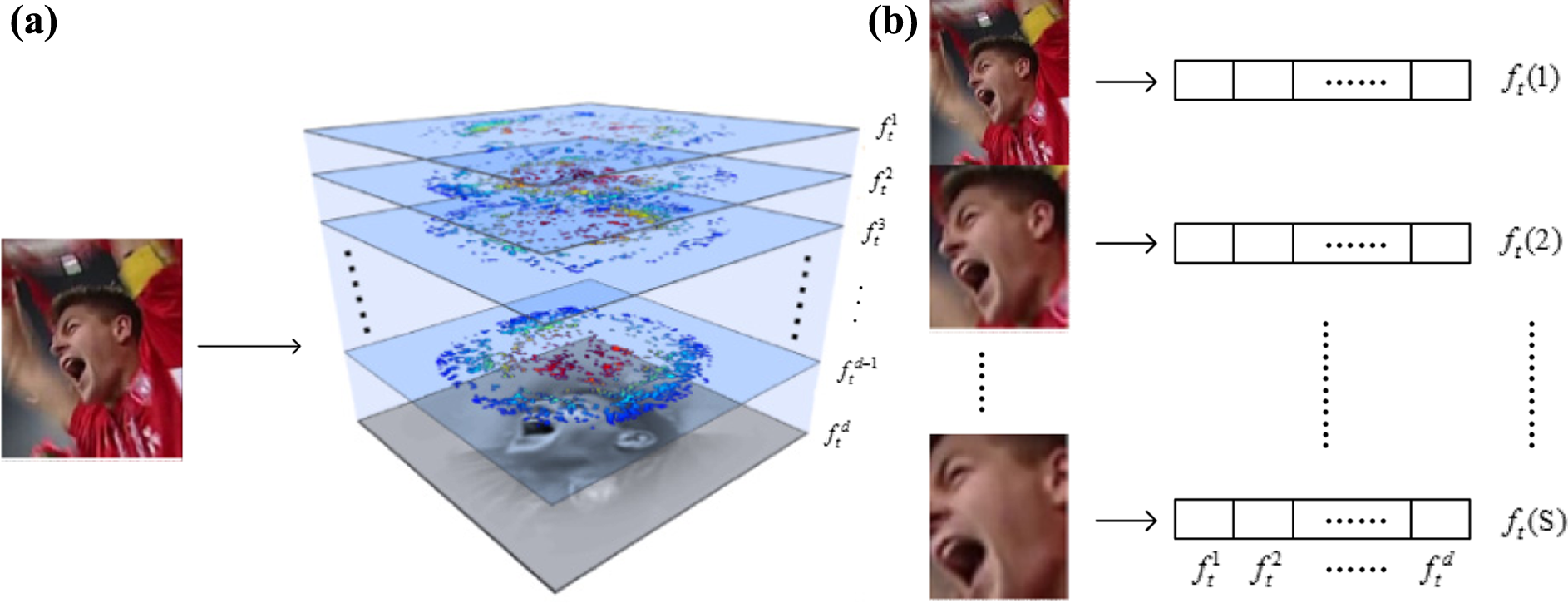
Training samples used in the proposed method. (a) The left of above figure shows the HOG, color-naming, and raw intensity feature layers (translation filter sample). All three types of features are combined for the translation estimation. (b) The 1-D features from different scale spaces are combined for scale estimation (scale filter sample). HOG: histogram of orientation gradients.
an image patch In of size
For the computational purpose, the same dimensionality reduction technique used in translation filter can be adopted to the scale filter as aforementioned. That is, based on the input of ut, scale and ft, scale, two projection matrices
Experiments
Because we address the scale estimation issue for correlation-based long-term visual tracking, we run five variants of trackers, including SAMF, DSST, Long-term Correlation Tracking (LCT), Collaborative Correlation Tracking (CCT), and the proposed compressed multiple feature and adaptive scale estimation (CMFASE) method. All these trackers take the advantages of circulant matrix tool or kernel-based CF. Table 1 shows the feature and scale estimation method used in these trackers. Table 2 shows the process of the proposed algorithm.
The differences among the trackers.
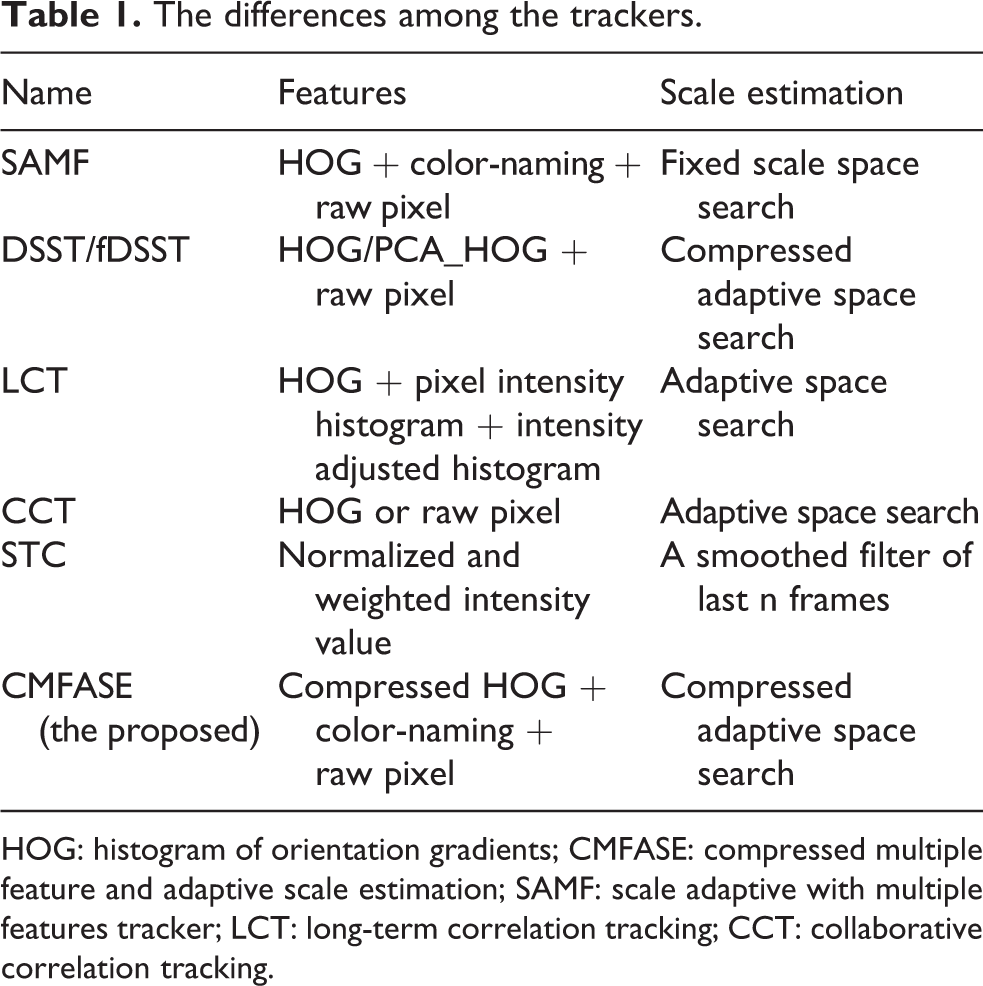
HOG: histogram of orientation gradients; CMFASE: compressed multiple feature and adaptive scale estimation; SAMF: scale adaptive with multiple features tracker; LCT: long-term correlation tracking; CCT: collaborative correlation tracking.
The proposed algorithm.

Data set
To evaluate the performance of the proposed method, extensive qualitative and quantitative experiments are conducted on the scale variation sequence of OTB benchmark data set, 45 which include Biker, BlurBody, BlurCar2, BlurOwl, Board, Box, Boy, Car1, Car24, Car4, CarScale, ClifBar, Couple, Crossing, Dancer, David, Diving, Dog, Dog1, Doll, DragonBaby, Dudek, FleetFace, Freeman1, Freeman3, Freeman4, Girl, Girl2, Gym, Human2, Human3, Human4.2, Human5, Human6, Human7, Human8, Human9, Ironman, Jump, Lemming, Liquor, Matrix, MotorRolling, Panda, RedTeam, Rubik, Shaking, Singer1, Skater, Skater2, Skating1, Skating2.1, Skating2.2, Skiing, Soccer, Surfer, Toy, Trans, Trellis, Twinnings, Vase, Walking, Walking2, Woman, and so on; there are totally 57 video sequences. And more results on other data set will be presented in the near future.
Experiment setup
All the trackers are run with Matlab R2016b, which is installed on an Intel Core(TM)2 Duo CPU P8600 @ 2.4 GHz with 8 GB memory, though parallel tool is provided in Matlab R2016b, but we turn it off. The parameter values of the trackers are set as provided. For example, the parameter values of SAMF for all videos are set to the same, a Gaussian kernel type and HOG–color feature type are used, the cell size is 4, nine orientations are used for HOG. The padding size is set to 1.5, the regularization value is λ = 0.01, and the learning rate is set to η = 0.025. The desired CF output g is set to 2-D Gaussian shape with standard deviation of 1/16 of the target size. The scaling pool for scale estimation of SAMF is set as
Evaluation criteria
Two evaluation criteria are used in this article, such as mean center location error (CLE) and the Pascal VOC overlap ratio (VOR). The CLE is defined as the distance difference between the center of the ground truth and tracked results. The Pascal VOR
46
is defines as
where S(⋅) refers to the area function, BT is the bounding box of tracked results, and BG is the bounding box from ground truth. It is obvious that the larger value of VOR is, the more accurate results are obtained.
The scale estimation experiments
Because all the compared trackers include the scale estimation, we make a qualitative comparison among these trackers. The referent scale value is defined as
Here, the initial scale value is S0 = 1 in first frame,

Scale estimation results of the five trackers for (a) BlurCar2, (b) Car4, (c) Doll, and (d) Soccer. (Blue line is the results of SAMF, green one is for fDSST, red one is for the proposed method, magenta color one is for LCT, dotted black line is for CCT, and solid black line is for the ground truth.)
In Figure 7, rectangle draw in blue is the tracking output of SAMF, green one is for fDSST, red one is for our proposed method, magenta color one is for LCT, black one is for CCT, and white one is for the ground truth. For the following experiments, we follow the same color labeling rules. As shown in Figure 2, here only two video tracking results are presented, which confirm that though both SAMF and the proposed use the same multiple features, that is HOG, color-naming, and raw intensity value, the proposed method shows some advantages over the SAMF tracker even with a compressed HOG feature. This performance gain exists in many video sequences.

The tracking results for (a) BlurBody and (b) Soccer. (Rectangle draw in blue line is the results of SAMF, green one is for fDSST, red one is for the proposed method, magenta color one is for LCT, black one is for CCT, and white one is for the ground truth.)
Furthermore, as shown in Figure 8, we pick out some frames with results from BlurCar2. We can see that the ground truth may be not accurate, as indicated in frame no. 5. On the other hand, because of the motion blur, it is hard to say which one is more accurate as indicated in frame no. 369/465/531.

The tracking results of BlurCar2 with SAMF (indicated with red color)/fDSST (indicated with green color)/the reference (indicated with blue color).
The robustness and accuracy comparison
Figure 9 shows the CLE and VOR results for the BlurBody, the proposed method shows good performance, but the gap with other trackers is not large, and same results are obtained for BlurCar2, boy, Car4, ClifBar, Crossing, Dog, Human5, Liquor, Walking, Woman, and so on. But for the other videos, such as Soccer, David, FreeMan1, and so on, the proposed method shows a large performance gain over other trackers, as shown in Figure 10.

CLE and VOR results for BlurBody. Blue line is the results of SAMF, green one is for fDSST, red one is for the proposed method, magenta color one is for LCT, and black one is for CCT. CLE: center location error; VOR: VOC overlap ratio.
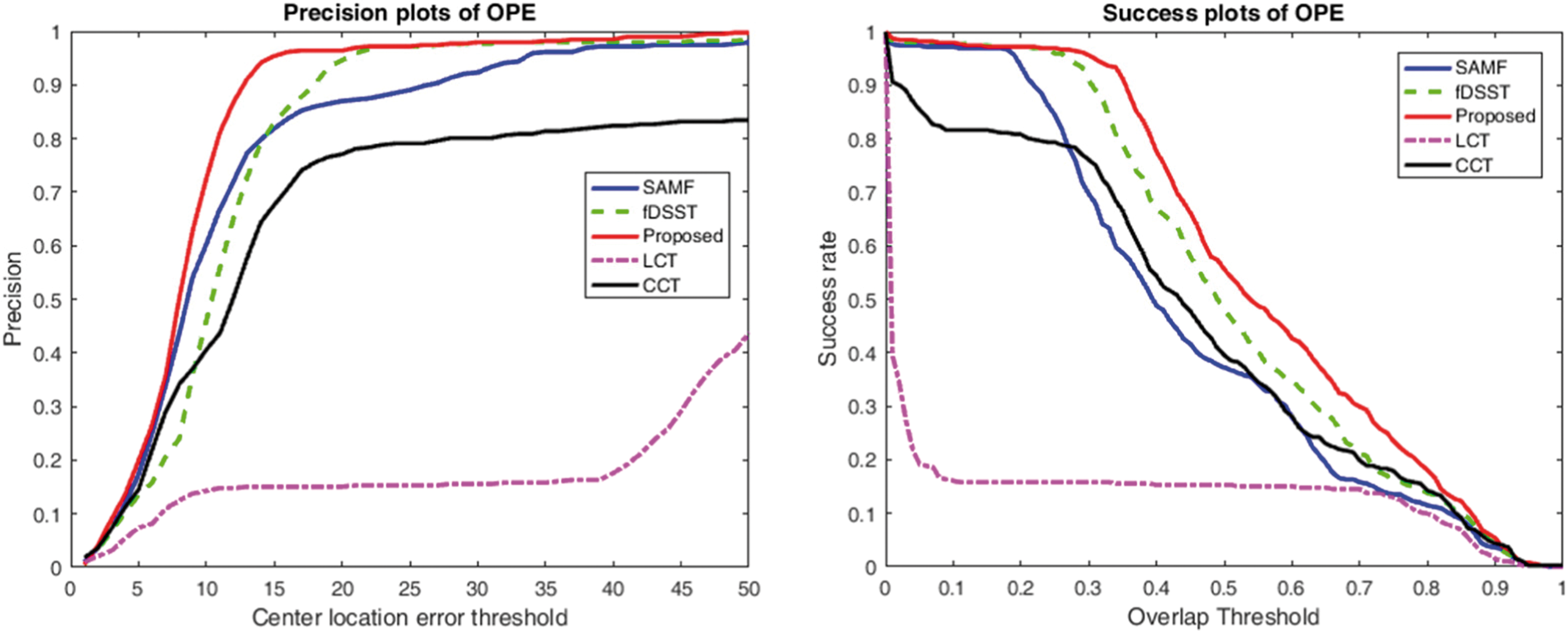
The comparison of CLE and VOR results for Soccer. (Blue line is the results of SAMF, green one is for fDSST, red one is for the proposed method, magenta color one is for LCT, and black one is for CCT.) CLE: center location error; VOR: VOC overlap ratio.
We can see that though the framework is similar, the obtained performances in terms of accuracy and robustness are quite different. The experiments show that the search strategy and visual features used by the tracker are very important in visual tracking tasks. By making use of the fusion of the compressed features and the adaptive scale estimation scheme, the proposed tracker has better performance both in terms of VOR and CLE. The overall performance on all scale variation video sequence is shown in Figures 11 and 12.
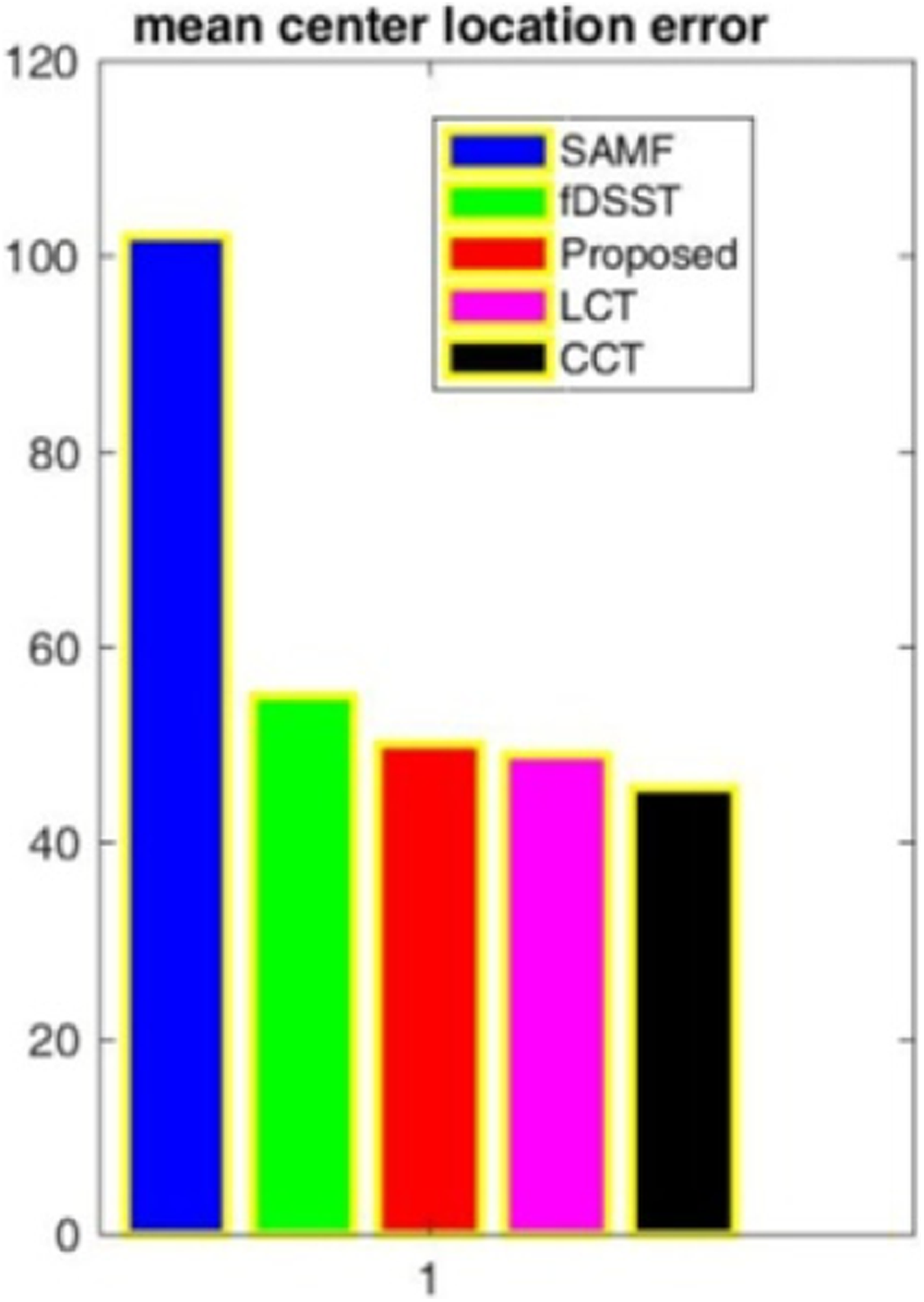
Mean center location error over all scale variation (SV) sequences. (The bar indicated with blue color is the results of SAMF, green bar is for fDSST, red bar is for the proposed method, magenta color bar is for LCT, and black bar is for CCT.)
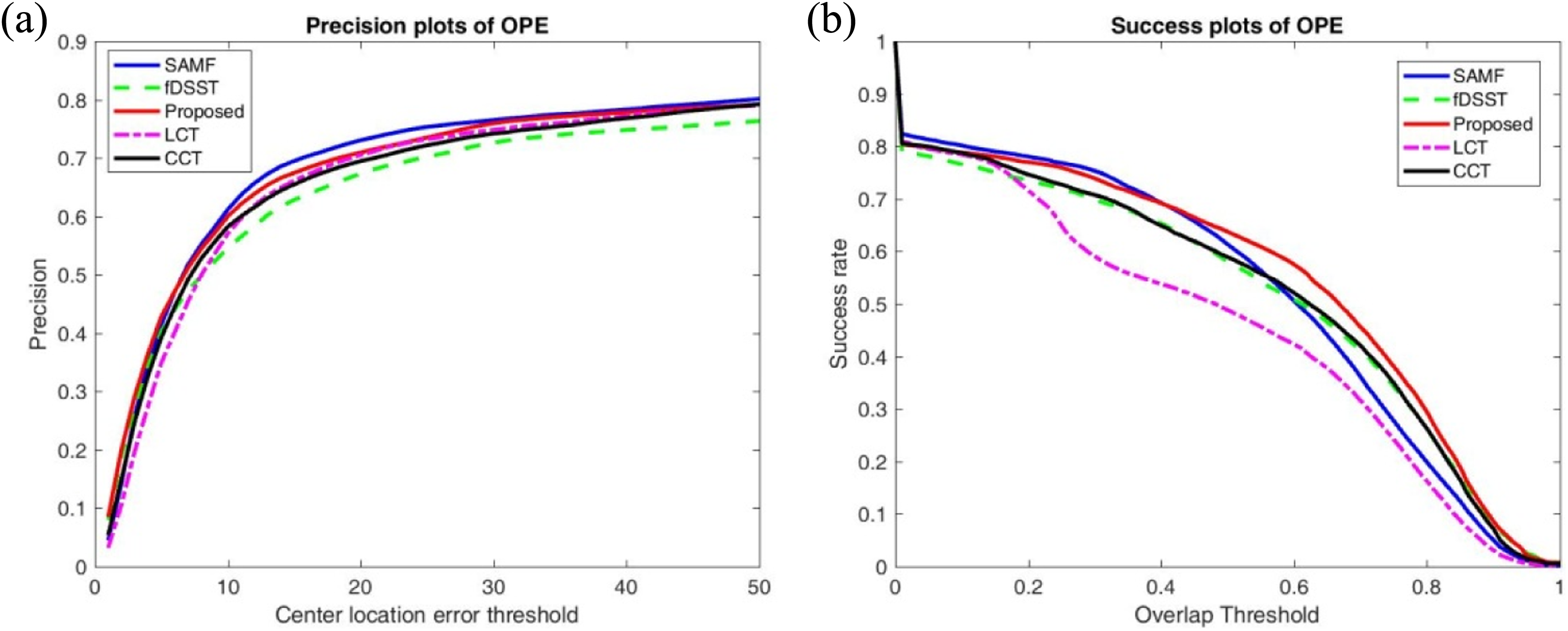
The benchmark overall plot. (a) CLE plot and (b) VOR plot. The blue line is the results of SAMF, dotted green line is for fDSST, red line is for the proposed method, dotted magenta color line is for LCT, and black line is for CCT. CLE: center location error; VOR: VOC overlap ratio.
As shown in Figure 12(a), for the precision plot of OPE, SAMF tracker seems better than the proposed method, but we found that generally a more accurate scale estimation result is obtained for the proposed method. As shown in Figure 13, the results of SAMF are indicated with blue rectangle, the proposed method is drawn with red color. This means SAMF always get a bigger box than the proposed. Furthermore, as shown in Figure 8, we found that the ground truths were not accurately provided, especially for the blurred image sequences. Maybe this can explain the reason what has happened.

The tracking results for BlurCar2. Rectangle draw in blue line is the results of SAMF, green one is for fDSST, the red is for the proposed method, the magenta color one is for LCT, the black is for CCT, and the white one is for the ground truth.
Conclusion
In this article, a CMFASE method is proposed, which makes use of multiple features under the framework of CF-based visual tracking, both for translation and scale estimation filter. The translation and scale estimation are unified with an iterative searching strategy. The qualitative and quantitative experiments have been conducted on the OTB benchmark data set, particularly with the scale variation sequences; the results show that the proposed approach performs favorably against other methods with scale estimation capabilities in terms of robustness and accuracy.
Currently, the performance is demonstrated on the scale variation videos, we will conduct more experiments on other data set, or even more challenging scenarios. We also want to add the redetection process for long-term tracking tasks.
Footnotes
Acknowledgment
The authors would like to thank the anonymous reviewers for all the suggestions and questions and Dr Taru Narula for preparing this manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflict of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of China under grant no.61573057, partly by the national science and technology support program (2015BAF08B01), and partly by the Fundamental Research Funds of BJTU(2017JBZ002).