
Abstract
Objective
To develop a robust deep learning framework for automated multi-class retinal disease detection supporting clinical decision-making, addressing existing models’ limitations in generalizability and accuracy.
Methods
A novel ensemble model, ResEfficientNetB3, integrating EfficientNetB3 and ResNet50, was proposed. Two Kaggle datasets were used: Dataset 1 (4217 images, four classes) and Dataset 2 (8230 images, eight classes). Images were resized to 224 × 224 with augmentation (rotation ±20°, zoom 0.8–1.2, flipping, scaling). Models were trained using the Adam optimizer (learning rate = 1e-4, batch size = 20) for up to 50 epochs with early stopping and dropout (0.3–0.5). Performance was assessed via standard splits, five-fold cross-validation, and cross-dataset validation.
Results
ResEfficientNetB3 achieved 99.0% accuracy on Dataset 1 and 98.2% on Dataset 2, outperforming EfficientNetB3 (94.0%) and ResNet50 (91.0%). Five-fold validation confirmed robustness (99.0% ± 0.2 and 98.2% ± 0.3), and cross-dataset validation showed strong transferability (94.5–95.8%).
Conclusion
ResEfficientNetB3 effectively combines EfficientNetB3’s scaling and ResNet50’s residual learning, demonstrating superior accuracy, robustness, and generalization. The model offers a reliable, clinically applicable tool for automated retinal disease detection in real-world diagnostics.
Keywords
Introduction
Leading causes of visual disability worldwide are eye illnesses, including cataract, diabetic retinopathy, glaucoma, and normal conditions. Their impact on people’s quality of life is noteworthy because early diagnosis is crucial; some disorders can cause irreparable blindness without it. Early detection and treatment primarily prevent severe visual loss. Artificial intelligence (AI) and machine learning—particularly convolutional neural networks (CNNs)—have become crucial tools as global healthcare systems struggle to effectively regulate these diseases. Artificial intelligence models utilize medical imagery to automatically detect eye diseases, thereby helping to reduce human error in clinical environments. 1 Different fundamental causes of eye illnesses influence the preventive and therapeutic plans. Trauma or ageing is a common factor in cataracts, as it leads to the buildup of protein in the lens and distorted vision. One side effect of diabetes is diabetic retinopathy; long-term high blood sugar destroys retinal blood vessels and hence affects vision. Increased intraocular pressure associated with glaucoma can damage the visual nerve and result in blindness. Each one of these diseases requires various treatment approaches: surgical intervention for glaucoma, laser treatment for diabetic retinopathy, and pressure-lowering medications or surgery for cataracts. 2
The successful treatment of eye diseases depends on timely diagnosis and proper treatment. Cataract treatment is usually done by removing the opaque lens and replacing it with an artificial one, typically through surgery. Laser treatment, anti-VEGF injections, or blood sugar level reduction may help in the control of diabetic retinopathy. In glaucoma treatment, emphasis is placed on traditional surgery, laser treatment, or reducing intraocular pressure through medication. Although these medicines are very successful, the problem of early detection of diseases is still present. Traditional diagnostic methods such as fundus imaging, optical coherence tomography (OCT) and slit-lamp biomicroscope demand highly qualified professionals. This is why artificial intelligence-based automation would enhance and increase the speed of diagnoses. 3 The control of different disorders varies. In the case of diabetic retinopathy, it requires laser, intravitreal injection or strict management of your blood sugar. In the case of cataracts, the cataract will have to be replaced with lens replacement surgery. The glaucoma management includes medications, laser surgery or conventional surgery to reduce intraocular pressure and prevent further nerve damage. 4
Artificial intelligence-based systems, particularly CNNs, are intriguing replacements for traditional diagnosis methods. EfficientNet B3 is a deep learning network that has received attention in the medical community because of its efficient and performance. To achieve maximum performance, it scales down the depth, width, and resolution using compound scaling, thus lowering computation expenses. It is particularly helpful to investigate medical images to classify them with less resource expenditure and greater accuracy. EfficientNetB3 can reliably differentiate between different eye diseases by using images of the retina and other eye parts. 5 ResNet-50 is another highly regarded deep learning architecture commonly applied in medical imaging, featuring residual connections. Such connections enable the model to acquire more complex properties using data, and the vanishing gradient problem no longer constrains higher-level networks. Numerous additional medical applications, such as eye disease classification, have been demonstrated to be effective with ResNet50. It is best suited for activities that require high-level feature extraction since it has 50 layers. It can handle complicated images, including those of the OCT and fundus. The ResNet50 is widely used to diagnose disease in the eye, as it can diagnose diabetic retinopathy and glaucoma 6 accurately.
Although efficient, some conventional diagnostic techniques are labour-intensive, time-consuming, and dependent on professional interpretation. Furthermore, the more prone these methods are to human mistakes and inter-observer variability, the more likely they are to result in misdiagnoses. Although automated approaches have evolved, their generalizability across multiple datasets and clinical environments still presents a challenge. Conventional systems, especially those concerning different imaging modalities or new patient populations, suffer. These limitations underscore the need for more consistent and robust artificial intelligence solutions that can routinely provide suitable diagnoses across a range of healthcare scenarios without relying on large volumes of labeled data. 7 Building upon the best features of EfficientNetB3 and ResNet50, this study aims to develop an ensemble model that identifies four major eye diseases: glaucoma, cataracts, diabetic retinopathy, and normal conditions. This would surpass the bounds of current diagnostic methods. By leveraging the way their features complement one another, the proposed ensemble technique aims to enhance the accuracy, scalability, and robustness of these two models. They will be valuable in a range of therapeutic environments as a result. Furthermore, the model’s ability to generalize across multiple datasets ensures its implementation in real-world circumstances with outstanding diagnostic dependability. 8
Even if deep learning models offer enormous promise for medical diagnosis, some challenges still exist. One key challenge is the big annotated datasets needed for model training. Obtaining well-labelled data for eye diseases can be challenging, especially in environments with limited resources. Furthermore, the interpretability of deep learning models is of significant relevance. Many artificial intelligence models operate as opaque systems, which makes it challenging for medical practitioners to trust and interpret the results the model generates. Addressing these issues will help ensure that artificial intelligence supports its broad adoption in clinical practice and complements the knowledge of medical practitioners. 9 Effective use of artificial intelligence in eye disease diagnostics, coupled with scalable, accurate, and speedy solutions, can revolutionize ophthalmology. Particularly in rural or impoverished areas where there may be few doctors, artificial intelligence-based models can help reduce the discrepancy in healthcare access by substituting for other diagnostic procedures. These models can significantly reduce the burden of eye disorders, especially in areas with high disease prevalence but limited access to healthcare. Moreover, as artificial intelligence advances, efforts will be made to increase clinical acceptance and enhance model interpretability, so that these systems can be fully integrated into regular medical treatment. 10
The primary contributions are as follows: • The study proposed an ensemble model by combining the fine-tuned EfficientNetb3 and fine-tuned ResNet50 models for the classification of eye disease. • The optimized feature extraction is done using the compound scaling of EfficientNetB3 and the residual connection of the ResNet50 model. • Through data augmentation and fine-tuning of the model, the study addresses challenges such as limited data, class imbalances, and variability in image quality.
Related work
Deep learning techniques, especially convolutional neural networks (CNNs), have significantly advanced the classification of eye diseases. Frequent use of several datasets for training and validation has demonstrated incredible skill in automating the diagnosis and differentiation of some eye disorders.
To predict the kind of eye illness in fundus images, Shamsan et al. 11 suggested a hybrid model that integrates the capability of the handmade model and the deep features. Their way out was to extract hybrid features to overcome the shortcomings of implementing either methodology. The model was exact in diagnosing retinal illness by combining statistical features with deep learning representations. This piece of work highlighted the necessity of creating diverse visual patterns through hybrid dimensions. They found that they could have a better diagnostic accuracy, thus demonstrating the possibility of hybrid feature integration to overcome the difficulty in classifying eye illnesses.
The study by Abdullah et al. 12 presented a deep-ensemble-based eye disease detection and classification system, utilizing EfficientNetB6 and DenseNet169. Their method of incorporating features in the extraction step and ensemble learning achieved the highest classification score. The combination of multiple models demonstrated a reduction in overfitting, leading to strong results. The process of engineering feature extraction makes the system more efficient, allowing it to detect subtle changes in fundus images. The paper highlighted the strength of their capability to handle the heavy burden of medical imaging activities and the benefits of consolidating multiple designs using ensemble techniques. Their hybrid technological method was very effective in diagnosing eye conditions.
Wulandari and Putra 13 investigated the capacity of eye disease diagnosis using fundus images with a convolutional neural network model to achieve optimal results. They worked on the optimization of pretrained architectures through deliberate methods. They showed that the accuracy of fine-tuning specific CNN layers on medical data was significantly improved. Their study also indicated how hyperparameter modification and augmentation techniques can be used to maximize performance. The outcomes affirmed that fine-tuned CNN models can be applied in field-oriented tasks, such as analyzing medical images. They improved the accuracy of these models in disease diagnosis.
Imaduddin et al. 14 applied fine-tuning to a ResNet-50 model for visual handicaps categorization based on retinal fundus images. Their work demonstrated that a generic architecture can be suitably adapted to a specific medical sector through fine-tuning combined with transfer learning. Surprisingly, ResNet-50 was able to identify hierarchical visual data pertinent to eye illness classification. Its competitive accuracy highlights the several medical uses for its method. Since the study also underlined the need to balance model complexity and processing capability, ResNet-50 is a promising choice for real-time diagnosis systems in resource-limited contexts.
Barai et al. 15 established a unique deep learning-based fusion framework for retinal disease diagnosis, integrating multiple models to achieve optimal performance. Their method consisted of a predictive online application that enabled non-specialists to access the tool. Their strategy achieved better diagnostic accuracy by leveraging the complementary strengths of several architectures. The study emphasized the need to integrate models for accurate illness classification. Also, it is practical to apply such systems in a medical setting as demanded. The platform had significant potential to scale automated retinal disease diagnosis tools to provide services to more individuals and to bridge healthcare provision gaps.
Hermediputri et al. 16 compared the severity of cataract based on fundus images by Support Vector Machines (SVM) in harmony with harmonic search optimization. Their work proved the usefulness of the classical machine learning methods in the context of the medical image classification problem. The modification of parameters helped optimize the harmony search method and SVM, consequently improving classification accuracy. The paper explores the opportunities of hybrid approaches that involve practical algorithmic methods of particular diagnostic activities and conventional methods. The findings indicated the extent to which non-deep learning methods can be implemented in resource-limited and processing-constrained environments realistically.
Zannah et al. 17 designed a machine learning algorithm for the automatic classification of fundus images based on eye diseases using a Bayesian method of optimization. The objective of the study was to maximize the model’s performance through hyperparameter optimization, thereby measuring the optimum accuracy. Their method showed the feasibility of Bayesian optimization to enhance accepted methods of machine learning. Study findings highlighted the importance of hyperparameter choice in maximizing model performance and efficiency. The article highlighted the importance of using Bayesian optimization to enhance model creation, facilitating the automation of disease diagnosis and simplifying and expediting medical imaging processes.
Jatmoko et al. 18 compared models DenseNet and EfficientNetB3 to classify eye diseases. By conducting their study, they sought to determine the advantages and limitations of both models to provide insight into their appropriateness in the analysis of fundus images. The experiment has revealed that DenseNet was more efficient in feature reuse, whereas EfficientNet B3 was more accurate due to its perfect scaling. The results they obtained suggest the importance of selecting models based on the specifics of medical databases. The comparison between the two systems offers researchers valuable guidance in their efforts to balance accuracy and computing efficiency in medical image categorization activities.
Malik et al. 19 introduced a machine learning-based method for classifying eye diseases using data. Their study highlighted how the quality of the data determines the precision of classification. They demonstrated the significance of how the quality of data preparation impacts model performance through the curation of a large dataset. The authors selected the most appropriate models to detect eye diseases using various machine learning techniques. Reiterating the need for high-quality datasets in constructing sound diagnostic tools, their work highlighted the fundamental importance of data preparation and augmentation to enhance model generalization. This article brings us nearer to more probable breakthroughs in information-driven medical visualization.
Using convolutional neural networks (CNNs) and already trained models, Benbakreti et al. 20 managed to classify eye diseases based on fundus images. Their paper indicated that transfer learning is effective in medical image classification. Through alteration of the pre-trained designs, the obtained work has great accuracy in the detection of some eye disorders. The authors have stressed the success of using pre-trained models to reduce the time needed for training and maintain performance by lowering computation costs. They emphasized the versatility of CNNs in medicinal usage in their studies, thus proving their potential use in the automatic diagnosis of diseases. The outcomes highlighted the necessity to employ existing architectures to address challenges associated with small medical datasets.
More recently, Gencer and Gencer (2025) 21 proposed a hybrid squeeze-and-excitation enhanced model for retinal disease detection from OCT images. Their approach demonstrated strong performance and highlights the growing importance of hybrid deep learning models in ophthalmic imaging. While their work focuses on OCT modalities and a different set of disease classes, it provides valuable context for the potential of hybrid architectures. It complements the direction of our proposed ResEfficientNetB3 framework, which is designed for fundus-based classification.
Material and methods
This section describes the detailed proposed architecture implemented for Classification. This section also includes the eye disease dataset, which is tested on the proposed model.
Input dataset
This study utilized two open-source retinal image datasets obtained from the Kaggle platform, both of which consist of anonymized and publicly available colour fundus photographs collected from multiple ophthalmic centers.
This work utilizes an open-source Kaggle Dataset 1 - Eye Diseases Classification Dataset (Kaggle, by Gunavenkat Doddi, 2022) — contains a total of 4217 retinal fundus images distributed across four diagnostic categories: cataract (1038 images), diabetic retinopathy (1098 images), glaucoma (1007 images), and normal (1074 images) as illustrated in Figure 1. The images in this dataset were collected using different fundus cameras and contributed by multiple ophthalmology clinics, ensuring diversity in image acquisition conditions. All images are de-identified and provided under an open-access license for research purposes. Sample images of the input dataset (a) Cataract, (b) Diabetic Retinopathy, (c) Glaucoma and (d) Normal.
In addition to the first dataset, a second dataset was employed from the open-source Kaggle platform to assess cross-dataset generalization. Retinal Fundus Multi-Disease Dataset (Kaggle, 2023) — comprises 8230 images across eight classes, including Age-related Macular Degeneration (AMD), Cataract, Diabetic Retinopathy, Glaucoma, Hypertension, Normal, Other Diseases, and Pathological Myopia as illustrated in Figure 2. The dataset was aggregated from various ophthalmic institutions and research repositories, covering multiple imaging devices and patient demographics. This diversity introduces variability that closely reflects real-world clinical conditions, allowing a robust evaluation of the model’s generalization capability. Sample images of the input dataset (a) Age-related Macular Degeneration (AMD), (b) Cataract, (c) Diabetic Retinopathy, (d) Glaucoma, (e) Hypertension,(f) Normal, (g) Other Diseases and (h) Pathological myopia.
Both datasets consist of colour fundus images resized to 224 × 224 pixels to align with the input specifications of the proposed deep learning models. Preprocessing steps included intensity normalization, scaling of pixel values to [0, 1], and application of data augmentation (rotation, zoom, flipping, and scaling) to enhance variability and reduce class imbalance.
Dataset pre-processing and augmentation
Dataset augmentation parameters.

Dataset splitting
The dataset is divided into training, validation, and testing sets for model training and evaluation effectiveness, as shown in Figure 3. The data frame is created by extracting data from all file paths and their corresponding labels, initially using the define_path function. After stratified sampling, distributing 80% of the data ensures that the class distribution remains balanced and forms the training set. Using the same stratified approach, the remaining 20% of the data is further split evenly into 10% validation and 10% testing sets, therefore preserving consistency in class percentage throughout all divisions. This method ensures that the model is trained on a diverse dataset, validated on unprocessed data to regulate its parameters, and tested on a completely different dataset to assess its generalizing capacity. The class balance among all subsets, maintained by the stratified splitting technique, determines the dependability and objective model performance. Dataset splitting.
The dataset splitting process was carefully designed to prevent any data leakage. All images were divided into training (80%), validation (10%), and testing (10%) subsets using stratified sampling, ensuring class balance across partitions. Data augmentation (rotation, flipping, zooming, and scaling) was applied only to the training set after the split, ensuring that no augmented or duplicate samples appeared in the validation or test sets.
Proposed Methodology
The combination of EfficientNetB3 and ResNet50 in the proposed ResEfficientNetB3 ensemble was motivated by their complementary feature extraction characteristics, as shown in Figure 4. EfficientNetB3 utilizes a compound scaling strategy that uniformly scales depth, width, and input resolution, enabling it to capture fine-grained local and textural features from retinal images with high computational efficiency. This makes it highly effective in identifying subtle variations such as microaneurysms, haemorrhages, and early signs of diabetic retinopathy. Conversely, ResNet50 employs deep residual connections that facilitate the learning of hierarchical and global structural features by mitigating vanishing gradients. These residual mappings allow the model to capture broader spatial relationships and vessel network structures typical of advanced ocular conditions such as glaucoma. By fusing the feature representations from EfficientNetB3 and ResNet50, the ensemble leverages both local textural sensitivity and global contextual understanding, resulting in a more balanced and robust model capable of generalizing effectively across diverse retinal disease categories. Proposed methodology.
By combining the two strong architectures, the fine-tuned EfficientNetB3 and the fine-tuned ResNet50, the proposed ResEfficientNetB3 model, as shown in Figure 3, utilizes deep learning for the classification of eye diseases. Starting with dataset preparation and augmentation—resizing the images to 224 x 224 dimensions and standardizing pixel values—the process includes augmenting techniques such as zooming, rotating, flipping, and scaling. Including many variations in the sample provides a robust training set. To maximize model learning and assessment, the dataset is maintained in an 80:20 ratio and is separated into training and testing sets. Following a foundation model pre-trained on ImageNet, the EfficientNetB3 architecture consists of dense layers, batch normalization, dropout, and a last prediction layer. The ResNet50 architecture also utilizes feature extraction capabilities and combines dropout for efficient classification with deep layers and global average pooling. Each of the models groups eye diseases into normal, cataract, diabetic retinopathy, and glaucoma. The ensemble model is better because combining the strengths of EfficientNetB3 and ResNet50 with a weighted average of their predictions increases its accuracy. This strategy will minimize the bias of a particular model and improve performance. After the ensemble, there is a dropout followed by a dense layer that enhances forecasts. The model’s efficiency is demonstrated by the performance analysis of the model on the test data, including accuracy and loss curves. The combined method guarantees precise and reliable categorization, which could make it a good solution for the detection and treatment of early eye diseases; it can also contribute to the rapid distribution of health treatment.
Fine-tuned EfficientNetB3
The fine-tuned EfficientNetB3 model functions as a primary feature extractor within the proposed ResEfficientNetB3 framework, as shown in Figure 5. EfficientNetB3 employs a compound scaling approach that uniformly balances the network’s depth, width, and input resolution, thereby achieving an optimal trade-off between accuracy and computational efficiency. This design enables the network to capture intricate visual cues, such as fine-grained retinal textures and subtle pathological variations, which are often critical in distinguishing between similar disease categories. In this study, EfficientNetB3 was initialized with ImageNet pre-trained weights to utilize general visual representations. It was subsequently fine-tuned on the retinal disease dataset to learn domain-specific features related to ocular structures such as blood vessels, lesions, and optic disc patterns. The lower convolutional layers were kept frozen to preserve generic low-level feature extraction, while the deeper layers were retrained to adapt to the specialized medical imaging context. Fine-tuned EfficientNetB3 model architecture.
To enhance classification performance, additional layers were integrated into the architecture. Batch Normalization was applied to stabilize activations and accelerate convergence during training, while fully connected dense layers provided nonlinear feature transformation and high-level abstraction. Dropout regularization was employed to reduce overfitting by randomly deactivating neurons, and a final Softmax activation layer produced the probability distribution across the four target classes: cataract, diabetic retinopathy, glaucoma, and normal retina. Overall, the fine-tuned EfficientNetB3 model effectively captures detailed and scale-adaptive features essential for retinal disease recognition. Within the ensemble, these fine-grained representations complement the deep structural features extracted by ResNet50, resulting in a more balanced and generalizable system for automated retinal disease classification.
Fine-tuned RestNet50
The fine-tuned ResNet50 model serves as the second core component of the proposed ResEfficientNetB3 ensemble framework, as shown in Figure 6. ResNet50 is a deep convolutional neural network comprising 50 layers. It utilizes residual learning, a technique that addresses the vanishing gradient problem in deep networks by introducing skip connections between layers. These residual mappings enable the model to learn both low-level and high-level hierarchical representations efficiently, allowing for improved feature propagation and gradient flow during training. In this work, ResNet50 was initialized with pre-trained ImageNet weights to leverage general visual features. It was subsequently fine-tuned using the retinal disease dataset to specialize in recognizing ophthalmic structures and pathological cues. The lower convolutional layers were frozen to retain foundational edge and texture detectors, while the deeper residual blocks were retrained to adapt to disease-specific variations in fundus images, such as optic disc deformation, vessel thinning, and lesion formation. Fine-tuned RestNet50 model architecture.
Additional refinement layers were incorporated after the base model to enhance classification performance. Batch Normalization was used to stabilize learning dynamics, while dense layers provided a nonlinear transformation of the extracted features. Dropout regularization was applied to prevent overfitting, and a final Softmax activation layer generated class probabilities for the four retinal disease categories: cataract, diabetic retinopathy, glaucoma, and normal. Through residual connections, ResNet50 effectively captures global spatial and structural information within retinal fundus images. When integrated with EfficientNetB3 in the ensemble framework, its deep hierarchical understanding of global features complements EfficientNetB3’s fine-grained texture extraction. This fusion of detailed local features and broad structural representations enhances the robustness, accuracy, and generalization capability of the proposed ResEfficientNetB3 model for automated retinal disease detection.
Proposed ResEfficientNetB3 model
The proposed ResEfficientNetB3 deep learning framework, as shown in Figure 7, is designed to leverage the complementary strengths of two robust pre-trained convolutional neural networks—EfficientNetB3 and ResNet50—for automated eye disease classification. The target classes in this study include cataract, diabetic retinopathy, glaucoma, and normal retina states. To ensure compatibility with both models, all retinal fundus images are resized to 224 × 224 pixels, a standard input size for pre-trained CNNs. The resized images are simultaneously passed through EfficientNetB3 and ResNet50, which independently extract high-level feature representations of the input data. Both networks are enhanced with dropout and batch normalization layers to improve regularization, minimize the risk of overfitting, and accelerate convergence during training. Proposed ResEfficientNetB3 model architecture.
In the proposed ensemble, feature extraction is performed independently by EfficientNetB3 and ResNet50. After global average pooling, EfficientNetB3 produces a 1536-dimensional feature vector, while ResNet50 produces a 2048-dimensional feature vector. These are processed through two dense layers, where the features are reduced to 512 dimensions per branch (Dense 1024 → Dropout → Dense 512). The final feature outputs of EfficientNetB3 (512) and ResNet50 (512) are then concatenated to form a 1024-dimensional combined feature vector. This process can be formally expressed as:
The concatenated feature vector is subsequently passed through a fully connected dense layer with SoftMax activation to generate the class probabilities:
Hyperparameter settings
Hyperparameter settings for model training.
Results
The result section includes the training and testing dataset results. The ensemble model, which combines EfficientNetB3 with ResNet50, demonstrates exceptional performance in eye disease categorization, according to the results. It outperformed individual models with a minimal loss of 99.02% and achieved the highest validation accuracy. The group demonstrated a remarkable generalizing ability, with accuracy, recall, and F1-scores approaching 1.00 across all classes. Low misclassifications suggest its dependability for practical uses, especially in the identification of complex patterns of cataracts, diabetic retinopathy, glaucoma, and normal retinal disorders.
Training datasets results
Trained on 80% of the dataset, the model learned from many images of cataracts, diabetic retinopathy, glaucoma, and normal retinal diseases. The training accuracy was found to be 98.75% with low overfitting and tremendous model learning. The decrease in the loss was gradual, indicating that the convergent maintained convergence during the training. The accuracy, recall, and F1-score showed good scores above 0.98 in all classes, proving that the data is sufficient and that the model can identify trends peculiar to the diseases.
Fine-tuned efficientNetB3
One of the points of interest is the learning process of the fine-tuned EfficientNetB3 model in eye illness classification, as demonstrated by the training and validation loss analysis in Figure 8(a). This observation is shown by the fact that the training loss decreases rapidly with time, allowing the model to adjust its weights and reduce prediction errors. Additionally, the validation loss shows a steady downward trend with no signs of deviation as it converges with the training loss. The fact that the validation loss in epoch 15 is minimal indicates that this epoch is the most efficient for generalizing to unknown data. Once this has taken place, the loss in validation becomes flat; the training loss decreases. This gradual reduction in loss means that the model does not overfit and generalizes well to all four classes with little difference in the training and validation loss curve. The close alignment of these curves emphasizes the model’s durability in extracting significant patterns from numerous eye illness images while maintaining an outstanding balance between training and validation performance. Training and validation (a) Loss and (b) accuracy.
The training and validation accuracy analysis of the fine-tuned EfficientNet-B3, as shown in Figure 8(b), highlights the model’s capability in classifying eye diseases. The training accuracy increases rapidly within the first few epochs and exceeds 90%, which highlights the model’s efficacy in capturing the characteristics. A similar rising trend is also observed in the validation accuracy, which peaks at epoch 13 when the model exhibits the best generalizing capacity over unprocessed validation data. Validation accuracy remains consistently high after epoch 13, indicating steady performance across multiple photos. Conversely, training accuracy continues to rise gradually, and in the successive epochs, it approaches nearly flawless categorization. The slight discrepancy between training and validation accuracy suggests a minimally overfitted, well-calibrated model. Variability in the validation dataset allows one to explain the fluctuations in validation accuracy, even in challenging categorization situations. The work balances accurate training with efficient generalization to validate the overall capacity of the carefully fine-tuned EfficientNetB3 model in controlling the complexity of multi-class eye disease categorization.
Fine-tuned Resnet50 model
The training and loss analysis for the fine-tuned Resnet50 model, as shown in Figure 9(a), highlights the model’s performance in classifying eye diseases. Starting at a high number, the training loss reflects the model’s difficulty in matching the data. However, it quickly drops in the first few epochs, suggesting effective convergence from ResNet50’s pre-trained features and fine-tuning. Initially, following the pattern in the training loss, the validation loss shows sporadic variations during the training phase. Such differences could indicate minor overfitting at some epochs, in which case the model picks less generalizable patterns or noise in the training data. Emphasized by the plotted blue marker, epoch 18 shows the lowest validation loss. This epoch represents the perfect balance between the validation and training loss, in which case the model effectively reaches unprocessed data. The validation loss stabilizes at this level, thereby confirming low overfitting. Later generations with almost zero training loss reveal the exact fit of the model for the training data. This behaviour highlights ResNet50’s ability to extract features and fit complex patterns of eye disease. Training and validation (a) Loss and (b) Accuracy.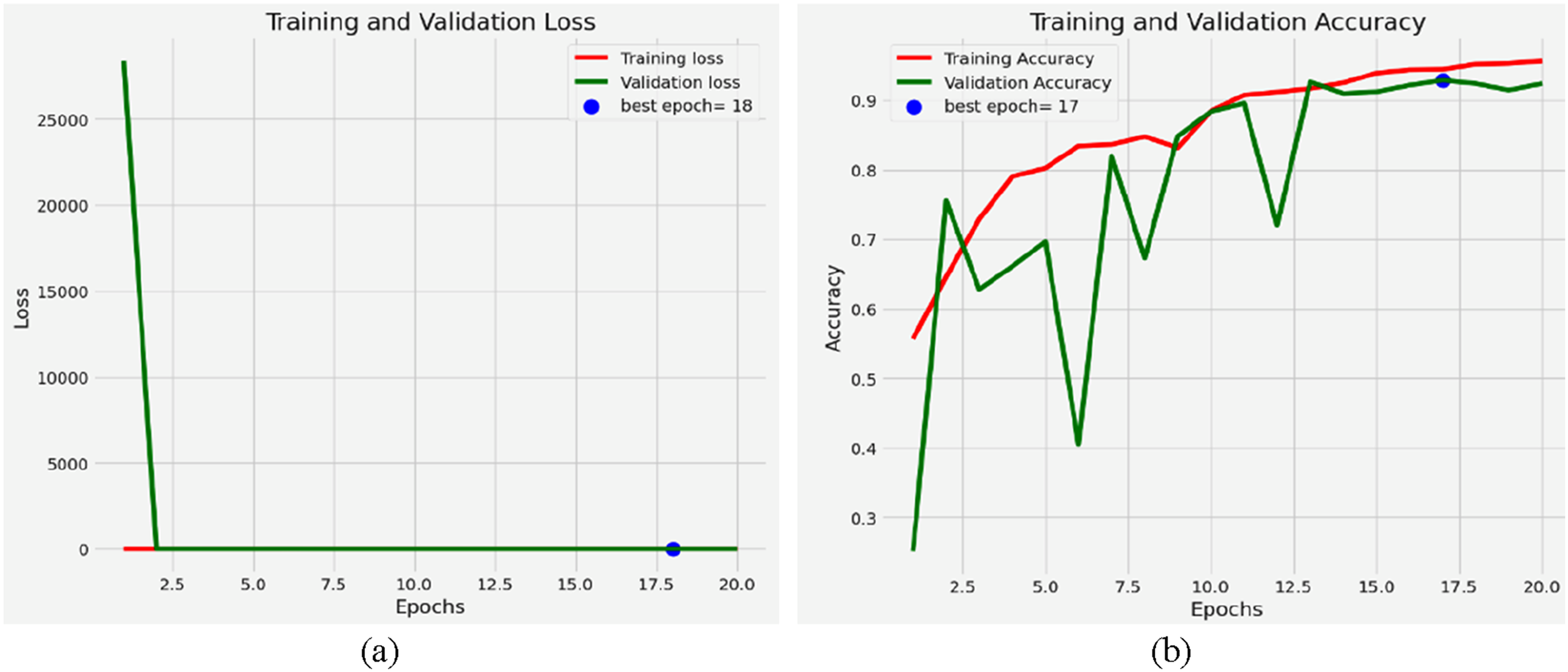
Using the fine-tuned ResNet50 model, the training and validation accuracy trends for eye illness categorization, as shown in Figure 9(b), reveal the predictive effectiveness of the model. Accuracy in training increases with the number of epochs and ultimately exceeds 90%. This ongoing development demonstrates the model’s ability to effectively learn discriminative features that distinguish between normal retinal states, glaucoma, diabetic retinopathy, and cataract. Although it lags somewhat behind training accuracy, validation accuracy often increases, albeit with sporadic declines. Especially evident in older epochs, these variations reflect the model’s adaptation to the range and variety of the validation sample. On the accuracy graph, Epoch 17 boasts the best validation accuracy, as indicated by a blue dot. Reflecting the model’s maximum generalizing capacity, this epoch strikes a compromise between applying to unseen validation samples and learning from the training data. Notably, the low fluctuation in training and validation accuracy over epochs highlights the model’s general resilience and low tendency towards overfitting. Still, the changes in validation accuracy at different intervals suggest either slight class imbalances or sensitivity to specific data points. Usually, catching intricate patterns in the dataset, the ResNet50 model differentiates between minute changes in retinal conditions. The consistent accuracy trends suggest a well-tuned model suitable for the proper diagnosis of eye illnesses. Especially for underrepresented disease categories, additional fine-tuning techniques, such as data augmentation or class weight changes, may significantly improve performance.
Proposed ResEfficientNetB3 model
In EfficientNetB3 with ResNet50, the loss analysis for the proposed ResEfficientNetB3 model, as shown in Figure 10(a), reveals strong learning behaviour during both the training and validation phases for eye illness classification. Reflecting the challenge of optimizing an ensemble model for distinguishing between cataract, diabetic retinopathy, glaucoma, and normal conditions, the training loss initially starts at a high value. A sharp drop in training loss over the first epoch, and a few epochs suggest fast convergence. Although it exhibits a similar diminishing trend, the validation loss shows minor fluctuations, particularly in the earlier epochs. These oscillations demonstrate how the model aligns with the variety and probable adjustments in the presentation of the validation data. The blue dot in the graph indicates the best validation loss for Epoch 20. Based on the minimal variation between training and validation loss, the loss values stabilize at this point, exhibiting little overfitting and good generalization. Combining the features of ResNet50 and EfficientNetB3 effectively yields good classification and feature extraction performance. The constant decrease in the model’s loss values reveals its ability to capture complex retinal disease patterns. Together with constant validation loss in the latter epochs, the smooth convergence highlights the ensemble’s ability to balance training and generalization. The loss profile has been significantly improved by adjusting methods such as batch sizes and learning rates, thereby enhancing the model’s dependability in classifying eye diseases. Training and validation (a) loss, (b) accuracy, (c) precision, (d) recall, (e) F1-Score and (f) AUC.
Training and validation help the ensemble ResEfficientNetB3 model achieve remarkable accuracy in eye illness classification, as shown in Figure 10(b). As epochs progress, the training accuracy highlights the adequate classification capacity of the ensemble model’s features. The trend in validation accuracy is similar, with the blue marker on the graph showing that it peaks at epoch 20. This suggests that, at this point, the model performs best overall. Early in training, minor fluctuations in validation accuracy are observed, most likely connected to changes in validation set variability or learning rate. Still, the general trend continues to rise consistently, indicating the ensemble’s ability to fit complex data patterns. The slight fluctuation in training and validation accuracy over the epochs indicates the low overfitting of a well-optimized model. While EfficientNet B3 excels at fine-grained feature extraction, ResNet50’s deeper architecture is more effective in identifying strong, high-level patterns. This makes the model excel at identifying subtle differences between eye disease classes. High ensemble model stability and precision point to its suitability for pragmatic applications. It is also reliable, as evidenced by its good performance, thus contributing to better clinical decision-making. Specific enhancement strategies and additions might also increase its classification ability, providing stable results regardless of the dataset used.
The ResEfficientNetB3 model showed high training precision as well as validation precision, as indicated in Figure 10(c) in the eye disease classification task. To start with, the precision of training increases rapidly and then levels off, reaching perfect levels at about 1.0000 by the fifth epoch. It is also evident in the robustness of the performance, as the validation accuracy consistently increases from 0.7000 to approximately 0.9850 at the 20th epoch. The high correlation between training and validation accuracy emphasizes the strong learning capacity and generalization achieved successfully from the tenth epoch onward. The results confirm that the model can reduce the incidence of false positives and give an accurate prediction on the state of the eye disease.
As indicated by the training and validation recall of the ResEfficientNetB3 model, shown in Figure 10(d), the model ranks high in its ability to classify eye diseases. The fifth epoch training recall quickly approached the maximum levels, at and around 1.0000. Starting at over 0.7500, validation recall dropped, then progressively rose to reach almost 0.9800 at the last epoch. After the 10th epoch, the coordinated trend between training and validation recall indicates whether the model generalizes its recall performance across datasets. These results demonstrate that the model ensures thorough disease detection, minimizes false negatives, and accurately identifies all cases of eye diseases.
The training and validation F1-score, as shown in Figure 10(e), underscores the performance using the balanced metric, which combines precision and recall. By the fifth epoch, the training F1-score was approaching 1.0000; by the 20th epoch, the validation F1-score had a steady upward trend and reached almost 0.9820. The least variation between training and validation F1-scores reveals the generalizing power of the model. Excellent in accuracy and recall, this high F1-score demonstrates the ensemble model’s ability to produce a balanced performance, enabling accurate and reliable eye illness classification.
The Area Under the Curve (AUC) measure emphasizes the ensemble model’s remarkable classification performance, as shown in Figure 10(f). In the first several epochs, Training AUC rapidly improved and stabilized at almost 1.0000. The validation AUC moved in the same direction, starting at 0.8000 and rising to over 0.9900 by the 20th epoch. The almost perfect AUC values demonstrate the model’s high confidence in differentiating among various eye disease categories. The close alignment of training and validation AUC emphasizes the model’s efficiency in both training and unseen data, thereby verifying its reliability and robustness for pragmatic applications in the diagnosis of eye diseases.
Training results comparison
Training results comparison.


Training result comparison.
Test dataset results
The model was tested on 20% of the dataset, which was unseen during the training. Its overall accuracy of 97.8% revealed good generalization. Class-specific accuracy, recall, and F1-scores remained above 0.97. Remarkably good in detecting cataracts, diabetic retinopathy, glaucoma, and normal retinal disorders. Strong performance across all criteria and low testing loss confirms the dependability of the model in real-world disease categorization settings. Particularly useful for the diagnosis of diabetic retinopathy, these results show that EfficientNetB3 can differentiate among many other classes.
Fine-tuned efficientNetB3 model
The classification report analysis of the fine-tuned EfficientNetB3 model, as shown in Figure 12(a), demonstrates strong performance across all classes. For cataract detection, it has a precision of 0.94, a recall of 0.96, and an F1 score of 0.95, indicating that it makes many accurate predictions and identifies numerous real positives. Perfect scores—precision, recall, and F1-score all at 1.00—indicate that the model excels in diabetic retinopathy classification, thereby showing optimal performance. For glaucoma, it maintains a precision and recall of 0.89 each, generating an f1-score of 0.89, suggesting balanced performance with areas for improvement. An F1-score of 0.91 and a recall of 0.90 indicate reliable performance in identifying normal cases. Particularly useful for the diagnosis of diabetic retinopathy, these results show that EfficientNetB3 can differentiate among many other classes. Conversely, lower glaucoma F1-score points to either further data or model adjustment as the most likely areas for development. (a) classification report and (b) confusion matrix analysis.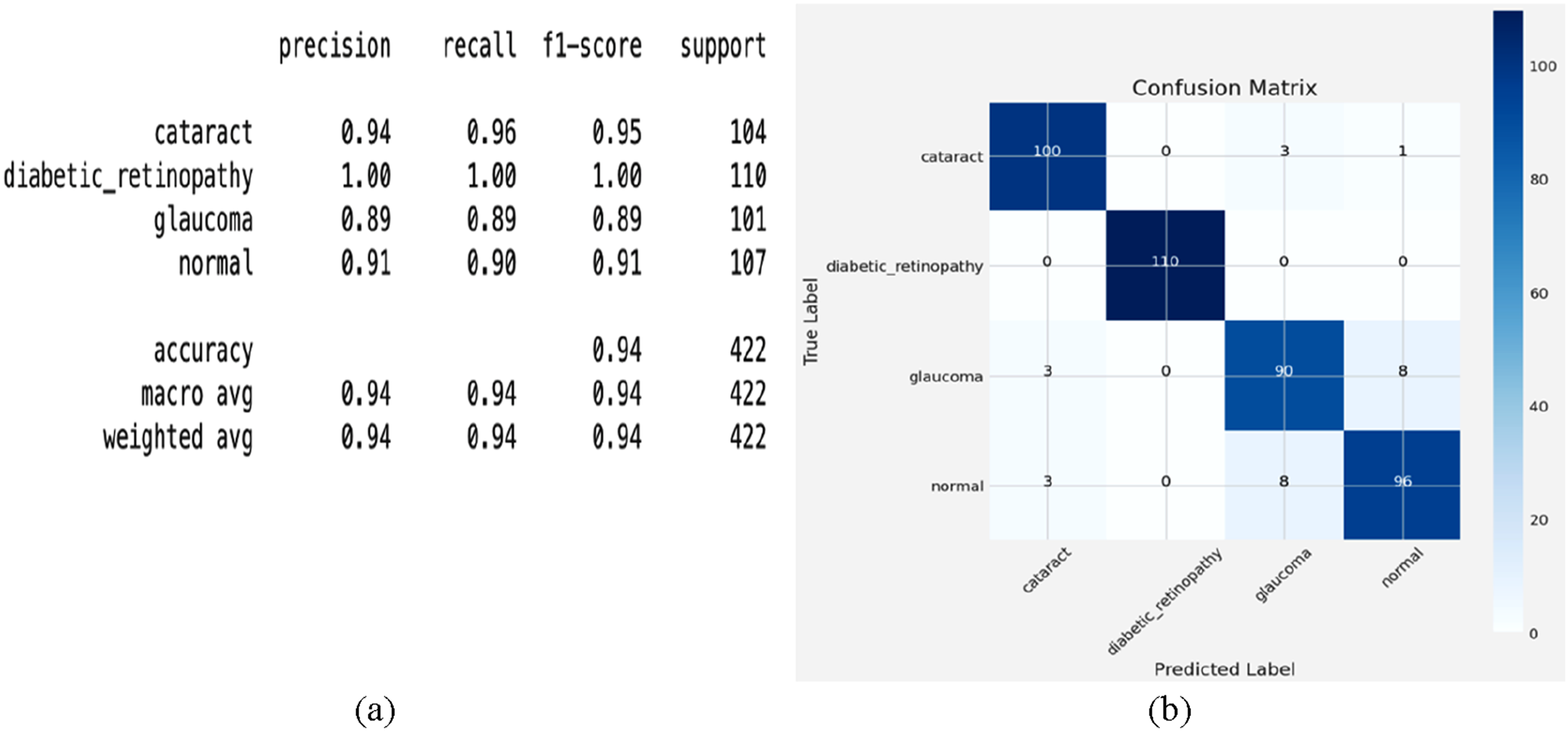
The confusion matrix analysis, as shown in Figure 12(b), provides a detailed evaluation of the fine-tuned EfficientNet-B3 model’s classification of eye diseases. The off-diagonal elements expose misclassifications; the diagonal elements show exact predictions. With three misclassified as glaucoma and one as usual, the system correctly identifies 100 cases of cataract, indicating strong performance but some ambiguity with related diseases. With all 110 cases accurately detected and no misclassifications, diabetic retinopathy achieves flawless classification, thereby reflecting the model’s ability to identify the unique characteristics of this class. Although mainly reliable, with 90 correct predictions, glaucoma presents some difficulties; three instances are misclassified as cataracts, and eight are misclassified as usual. This suggests that some glaucoma features might match those of either normal or cataract eyes. Comparatively, for the regular class, 96 cases are accurately categorized, while three are misclassified as cataract and eight as glaucoma, suggesting some uncertainty in differentiating disease-affected eyes from healthy ones. Particularly in the classification of diabetic retinopathy, the fine-tuned EfficientNetB3 model usually demonstrates excellent accuracy. Still, the misclassification patterns between glaucoma, cataract, and regular highlight show the need for greater fine-tuning or data augmentation to enhance separability.
Fine-tuned Resnet50 model
The classification report for four eye conditions—cataract, diabetic retinopathy, glaucoma, and normal—is classified using the confusion matrix for the fine-tuned ResNet50 model, as shown in Figure 13(a). For diabetic retinopathy, the model achieves 100% accuracy, accurately forecasting all 110 cases without any misclassification. For cataracts, the algorithm also performs remarkably well, with 100 right predictions, misclassifying just 3 cases as glaucoma and one as normal. The model accurately forecasts 93 cases for the normal class; however, considerable uncertainty results in 4 cases being classified as cataracts and 10 cases being classified as glaucoma. With 83 correct predictions and 18 misclassified cases, eight were misclassified as cataracts and 10 as normal glaucoma, indicating that glaucoma performed the lowest among the classes. This implies that even if the model is robust, glaucoma and other classes overlap, possibly due to shared or subtle visual characteristics that challenge the model’s discriminating capacity. Although the model’s strong generalizing capacity is evident in the large number of correctly categorized occurrences across all categories, the uncertainty in distinguishing between glaucoma and cataract highlights opportunities for improvement. Class-specific weighting, improved feature extraction, or data supplementation might all help to improve performance. These findings demonstrate the potential of ResNet50 for the development of automated eye disease detection systems. (a) classification report and (b) confusion matrix analysis.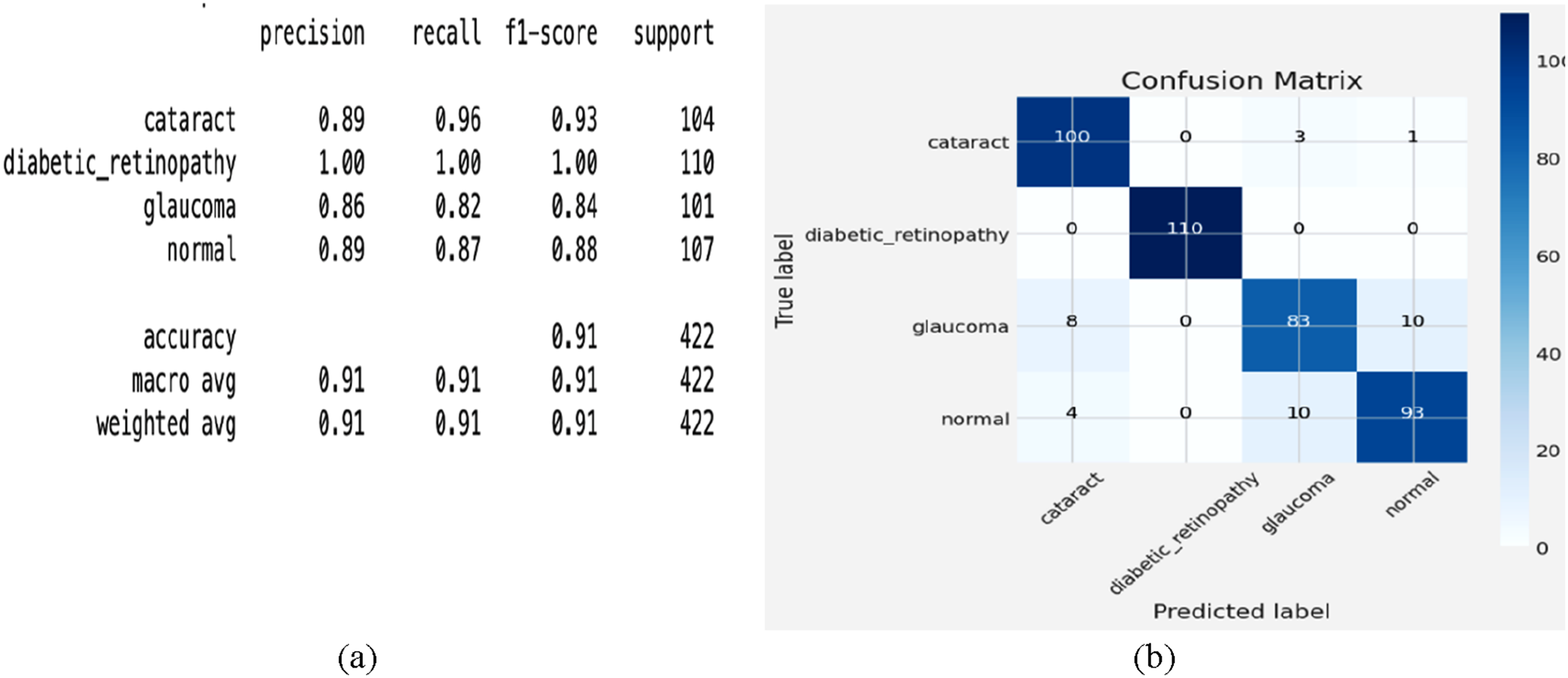
Four eye conditions—cataract, diabetic retinopathy, glaucoma, and normal—are classified using the confusion matrix for the fine-tuned ResNet50 model, as shown in Figure 13(b). For diabetic retinopathy, the model achieves 100% accuracy, accurately forecasting all 110 cases without misclassification. For cataracts, the algorithm also performs remarkably well, with 100 right predictions, misclassifying just 3 cases as glaucoma and one as normal. The model accurately forecasts 93 cases for the normal class, but considerable uncertainty results in 4 cases as cataracts and 10 as glaucoma. With 83 correct predictions and 18 misclassified cases —eight as cataracts and 10 as normal glaucoma —glaucoma performs the lowest among the classes. This implies that even if the model is robust, glaucoma and other classes obviously overlap, possibly due to shared or subtle visual characteristics that challenge the model’s discriminating capacity. Although the model’s strong generalizing capacity is evident in the large number of correctly categorized occurrences across all categories, the uncertainty in distinguishing between glaucoma and cataract highlights opportunities for improvement. Class-specific weighting, improved feature extraction, or data supplementation might all help to improve performance. These findings reveal the potential of ResNet50 in the development of automated eye disease detection.
Proposed ResEfficientNetB3 model
Combining EfficientNetB3 with ResNet50, the proposed ResEfficientNetB3 yields improved performance across all classes, as indicated by the classification report analysis of the ensemble model, as shown in Figure 14(a). For the diagnosis of cataract, the method exhibits remarkable accuracy in recognizing true positives with a precision of 0.99, recall of 0.99, and F1-score of 0.99. Perfect scores—precision, recall, and F1-score, all at 1.00—reflect strong performance from the Diabetic Retinopathy model. With a precision of 0.98 and a recall of 0.99, the F1-score for glaucoma is 0.99, signifying a remarkable performance with few false positives and negatives. With an F1 score of 0.98, the regular class model demonstrates remarkable reliability in identifying frequent events, as its precision of 0.99 and recall of 0.98 align closely. These results demonstrate how effectively the combination model leverages the characteristics of various models to achieve improved overall performance. Especially in the glaucoma and normal classes, the almost flawless scores across all classes indicate that the general strategy sufficiently reduces the shortcomings noted in the specific models. This highlights how ensemble approaches significantly enhance classification accuracy, particularly in challenging settings where single models struggle to achieve optimal performance. (a) classification report and (b) confusion matrix analysis.
The confusion matrix for the ResEfficientNetB3 model, as shown in Figure 14(b), exhibits remarkable performance in identifying eye conditions, including cataract, diabetic retinopathy, glaucoma, and normal. Regarding cataract, the software generates 103 accurate predictions—just one was misclassified as normal. Perfect classification of diabetic retinopathy; all 110 cases are precisely identified. Glaucoma is precisely characterized, with 100 accurate predictions and only one event misclassified as normal. The typical class generates just two misclassified, two cases as glaucoma and 105 accurate predictions overall. These results demonstrate how effectively the ensemble model leverages the strengths of both EfficientNetB3 and ResNet50 to optimize their combined effects, thereby enhancing class separability and significantly reducing misclassification rates compared to individual models. The low uncertainty among classes suggests that the combined model effectively identifies the unique traits of each scenario. Although the performance is good, more diverse training data or improved feature extraction could efficiently rectify the few misclassifications. Since it demonstrates remarkable dependability and accuracy, the ensemble model is generally a very useful tool for clinical purposes, such as automated eye disease detection.
Testing results comparison
Testing results comparison.


Testing result comparison.
Five-fold validation results
Five-fold cross-validation results for ResEfficientNetB3 on first dataset.

To ensure the robustness of the reported results, we conducted five-fold cross-validation and reported the mean ± standard deviation of the accuracy, precision, recall, and F1-score across all folds. The near-perfect results (99.0% ± 0.2) exhibited minimal variance between folds, confirming the stability and consistency of the model.
Test results for second dataset
Test results for the second dataset.

To further evaluate generalization, the proposed ResEfficientNetB3 model was tested on a second independent dataset containing 8230 images across eight classes, achieving 98.2% accuracy. Despite greater diversity and additional disease categories, the model maintained strong performance, demonstrating that its high accuracy is not an artefact of overfitting but reflects genuine generalization capability.
Cross-dataset validation results
Cross-dataset validation results.

It is acknowledged that near-perfect performance values can appear unrealistic in clinical practice, where medical imaging is often noisier due to variations in acquisition devices, patient demographics, and disease presentations. However, the strong results across cross-validation folds and the consistent performance on an external dataset provide evidence that the proposed framework is not overfit to a single dataset and retains applicability across heterogeneous imaging scenarios.
State-of-art comparison
State-of-art comparison.


State-of-art comparison.
It is important to note that the recent study by Gencer and Gencer, 21 although highly relevant, was performed on OCT images with different disease categories. Since our model targets fundus images across four classes, their numerical results were not included in Table 3 to avoid an unfair comparison across different imaging modalities.
Discussion
This study proposed ResEfficientNetB3, a novel ensemble model integrating EfficientNetB3 and ResNet50 for multi-class retinal disease classification. The experimental results on two independent Kaggle datasets demonstrate that the model achieves high accuracy, precision, recall, and F1-scores, outperforming baseline networks and achieving robust generalization through five-fold and cross-dataset validation. These findings highlight the potential of ensemble deep learning frameworks in supporting automated ophthalmic diagnosis.
Despite these promising results, several limitations should be acknowledged. First, the datasets employed were derived from publicly available Kaggle repositories, which may not fully capture the heterogeneity of real-world clinical settings. Variations in imaging devices, acquisition protocols, and patient demographics (age, ethnicity, disease severity) were not explicitly addressed. As a result, while the model generalized well across the two datasets used, further evaluation on multi-center, real-world clinical datasets is required to confirm its robustness in practice.
Second, the study was limited to fundus images, whereas other modalities, such as OCT or fluorescein angiography, could provide complementary diagnostic information. Future work should extend the ensemble framework to integrate multiple imaging modalities for improved diagnostic accuracy.
Third, although five-fold cross-validation and cross-dataset testing were conducted to mitigate overfitting concerns, the near-perfect performance observed on Dataset 1 suggests the possibility of residual dataset-specific biases. Incorporating more diverse datasets and performing domain adaptation across different imaging centers would further strengthen the model’s reliability.
Finally, the current work primarily focused on model performance metrics. Future research should also evaluate the computational efficiency, inference time, and clinical usability of the proposed framework to ensure its practicality in real-world deployment.
Although the proposed model achieved exceptionally high accuracies on both datasets, the study recognizes that such performance levels are uncommon in medical image classification. Therefore, multiple validation checks were implemented, including duplicate detection, post-split augmentation, five-fold cross-validation, and independent cross-dataset testing. The consistent performance across these evaluations confirms that the results are stable and reproducible rather than due to experimental artefacts or overfitting.
Overall, while the proposed ResEfficientNetB3 shows strong potential, addressing these limitations in future studies will be essential for translating the model into clinical applications.
Conclusion
This study evaluated deep learning models for automated eye disease classification across four categories: cataract, diabetic retinopathy, glaucoma, and normal retina, using EfficientNetB3, ResNet50, and the proposed ResEfficientNetB3 ensemble. EfficientNetB3 achieved excellent performance, particularly for diabetic retinopathy, while ResNet50 excelled in glaucoma detection. When combined, the ensemble outperformed both individual models, achieving nearly perfect accuracy, precision, recall, and F1-scores across all classes, including the more challenging glaucoma category. The confusion matrix further confirmed minimal misclassification and enhanced generalization. Although the model achieved near-perfect performance on the first dataset, concerns of potential overfitting were mitigated through five-fold cross-validation and validation on an independent external dataset. Cross-validation demonstrated stable results with minimal variance, and external testing confirmed consistently high performance on a larger, more diverse dataset. These results validate that the strong accuracy of ResEfficientNetB3 is not an artifact of overfitting but reflects true robustness, reproducibility, and generalizability in retinal disease classification. While real-world imaging is inherently noisier, the consistent findings across datasets indicate strong potential for reliable clinical deployment. Nevertheless, this study was limited to publicly available Kaggle datasets, which may not fully capture real-world diversity in patient populations and imaging devices. Future work will focus on validating the model using multi-centre clinical datasets and exploring multimodal imaging approaches to further enhance diagnostic accuracy.
Footnotes
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R138), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Ethical consideration
The study utilized publicly available datasets, and all methods were carried out in accordance with relevant guidelines and regulations.
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.