
Abstract
Introduction
Periodontal disease (PD), also known as gum disease, 1 is a widespread chronic inflammatory condition that affects the supporting structures of the teeth, including the gums, periodontal ligament, and alveolar bone. It is considered one of the most important and preventable oral health concerns globally. 2 The disease is characterized by the accumulation of bacterial plaque on the surfaces of the teeth, leading to localized inflammation and damage to the surrounding tissues. 3 Approximately 42% of adults in the United States (US) aged 30 and older with natural teeth experienced periodontitis, with 7.8% suffering from severe periodontitis.4,5 A total of 3. 3% of the probed sites (equivalent to 9. 1% of the teeth) had a probe depth of 4 mm or more and 19. 0% of the sites (equal to 37. 1% of the teeth) showed a clinical attachment loss of 3 mm or more.4,5 Severe periodontitis was most common among individuals aged 65 and older, Mexican Americans, non-Hispanic blacks, and smokers. 6 If left untreated, PD can cause tooth loss 7 and have a significant impact on the general health of an individual8,9 and quality of life. 10
Investigations of the frequency and effects of PD revealed that several individual factors are associated with compromised oral health. Men are more susceptible to severe PD compared to women. 11 Racial and ethnic minority populations, including Native Americans, Blacks, and Hispanics, exhibit higher rates of PD, untreated root caries, and tooth loss. Minority populations are more susceptible to an increased frequency of oral cancer compared to non-Hispanic whites. 12 Dental disparities in periodontitis are influenced by various aspects of socioeconomic status, such as income, living conditions, education, and access to dental care. 13 Periodontitis is influenced by lifestyle factors, including a poor diet, nutritional deficiencies, and inadequate dental hygiene practices. 14 Elderly individuals are more likely to have periodontitis, 15 as a result of reduced adherence to dental hygiene practices and limited access to adequate dental care. When examining periodontitis-related dental factors 16 including host characteristics (age, gender), social and behavioral factors, including socioeconomic status, smoking, 17 and alcohol 18 can increase the likelihood and severity of PD.
PD can be prevented if its risk factors are identified early and mitigated. 19 Therefore, early identification of these risk factors is crucial for managing and preventing their onset. Farhadian et al. 20 used support vector machines (SVM) to develop decision support systems to improve the diagnosis of periodontitis. The development of decision support systems to identify risk factors associated with periodontitis is critical to its prevention and treatment, and to improve dental health outcomes. A recent review by Kierce et al. 21 discussed the use of artificial intelligence (AI) to improve the management of PD. In this current study, the application of AI is directed towards improving patient health knowledge about PD. Through the use of extensive data sets and advanced algorithms, machine learning (ML) techniques improve the early diagnostic phase. The primary goal of this study is to enhance the performance of predicting PD diagnosis, thus facilitating the development of personalized treatment strategies.
This study used data from the National Health and Nutrition Examination Survey (NHANES), which provides extensive information on the health and nutritional status of the US population through data collected from interviews, physical examinations, and laboratory tests. NNHANES incorporates direct clinical assessments collected by trained examiners following standardized protocols. Several of these assessments are not typically available in routine clinical practice, as they require specialized procedures and examiner calibration. NHANES has been widely used to predict various health conditions and their associated risk factors, including cardivascular diseases,22,23 cancer,24,25 insomnia, 26 diabetes,27,28 kidney-related diseases,29,30 liver diseases,31,32 osteoarthritis,33,34 and dental related diseases.35–38 While numerous existing studies have conducted statistical analyses to understand the risks and contributing factors associated with PD,38–42 there remains a significant gap in leveraging ML techniques to comprehensively predict PD and analyze its associated factors. To the best of our knowledge, no prior work has systematically investigated the potential of ML classifiers in this domain. Despite progress in preventive dental care, access remains uneven, 43 especially for low-income, minority, and rural populations due to poor insurance coverage, limited awareness, and geographic barriers such as dental deserts. 44 Periodontal disease remains a significant public health burden in the US, affecting over 42% of adults aged 30 and above. 45 Leveraging automated analytical approaches can facilitate the identification of key contributing factors, enabling early intervention and targeted public health strategies. In this study, our objective is to address this gap by evaluating the effectiveness of various ML classifiers in accurately identifying PD. Through this approach, we seek to provide deeper insight into the predictive capabilities of these models, while also exploring the importance of features that contribute to the prediction of PD. Although earlier studies have mainly focused on examining individual variables in isolation, this study adopts a more integrated analytical approach. In addition, most of the variables used in this study are readily available from routine clinical records and do not require specialized clinical measures.
Materials and methods
Data source
This study used the publicly available version of the 2009-2014 National Health and Nutrition Examination Survey (NHANES). Our study was exempt from Institutional Review Board (IRB) review under 45 CFR 46.101(b) since it involved the analysis of deidentified secondary data. The NHANES annual assessment involves in-depth interviews and clinical examinations to evaluate oral health. In addition, the dataset includes questionnaires that cover demographic information, socioeconomic status, diet habits, various physical and mental health conditions, laboratory components, and other pertinent factors.
Study population
The data cohort analyzed in this study comprised of 10,714 adults aged 30 years or older who underwent a full-mouth periodontal examination. 15 Participants were selected using a random probability sampling method designed to be representative of 143.8 million US adults. The regression analysis utilized the probability weight for each individual in the sample. 8 Dental exams were performed by trained and calibrated dentists in mobile examination centers (MEC). 8
Methodology
The proposed ML pipeline to predict PD using NHANES data to develop accurate predictions is shown in Figure 1. Data preprocessing steps involved handling missing values, eliminating irrelevant or redundant features, and recoding essential features. This research focused on a subset of nineteen informative features. Feature engineering involves handling missing values through imputation techniques and creating enhanced derived features. The preprocessed data are split into training (80%) and testing (20%) sets. Eleven ML classifiers, including logistic regression (LR), decision trees (DT), SVM, Random Forest (RF), Naïve Bayes (NB), k-nearest neighbors (KNN), neural networks (NN), and ensemble classifiers such as GradientBoost classifier, AdaBoost classifier, XGBoost classifier, and CatBoost classifier, are employed. The training set is employed for model development, while the test set is utilized to assess performance using metrics such as accuracy, precision, sensitivity, and specificity. ML pipeline for periodontal prediction.
Outcome definition
In this study, periodontitis was the primary oral health outcome variable. The outcome was represented as a binary variable, with responses coded as ’yes’ (1) or ’no’ (0) to indicate the presence or absence of periodontitis among participants during clinical examination. The CDC/AAP standard for population-based periodontitis surveillance, including clinical attachment loss (CAL) and periodontal pocket depth (PPD), was used for this classification. 6 Periodontitis was classified as having two or more interproximal sites with PPD of 4 mm (not on the same tooth) or at least one interproximal site with PPD of 5 mm in addition to two or more interproximal sites with CAL of 3 mm (on different teeth). 46
Independent variables
Summary of confounding variables and their value ranges.
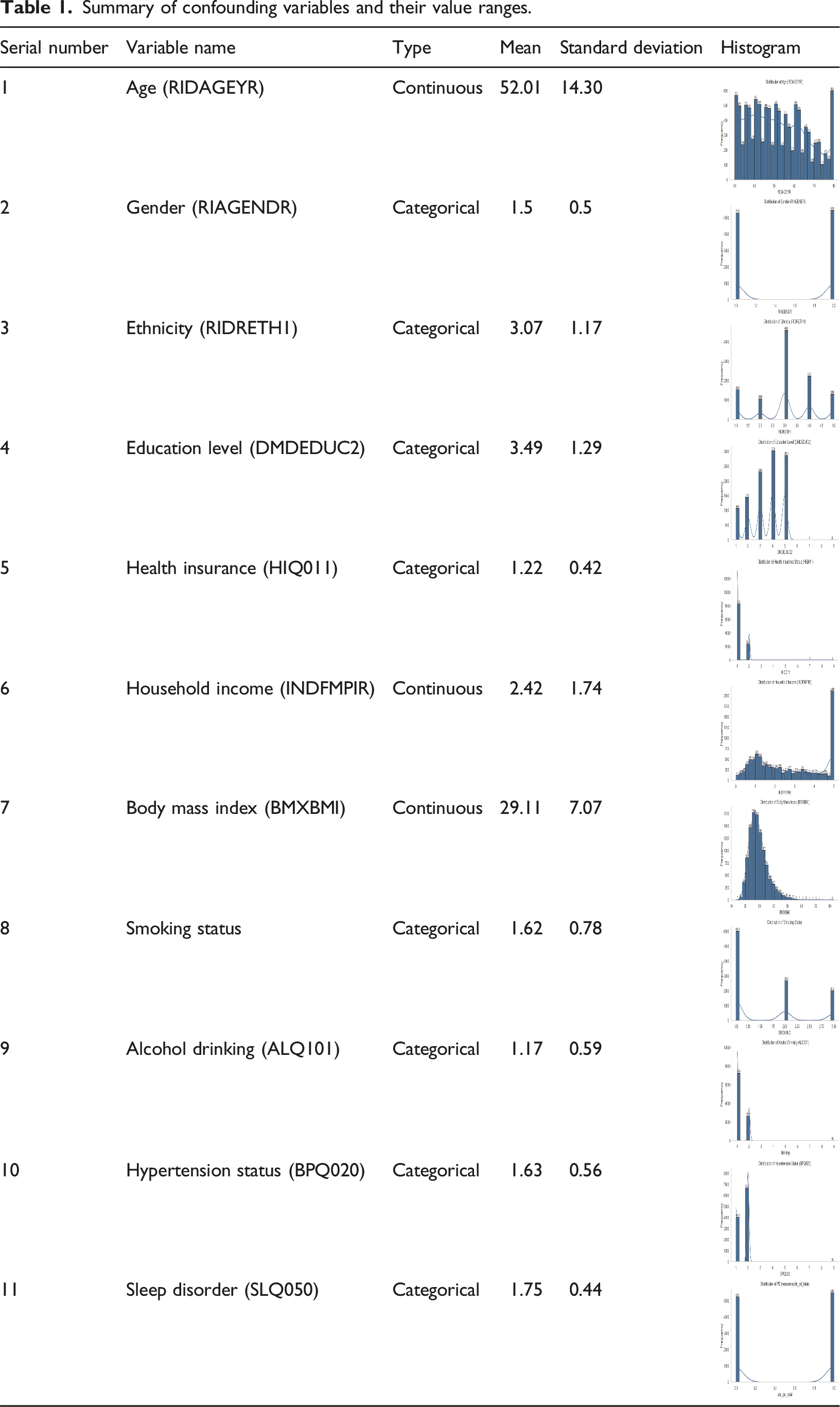
Summary of expert-driven variables and their value ranges.
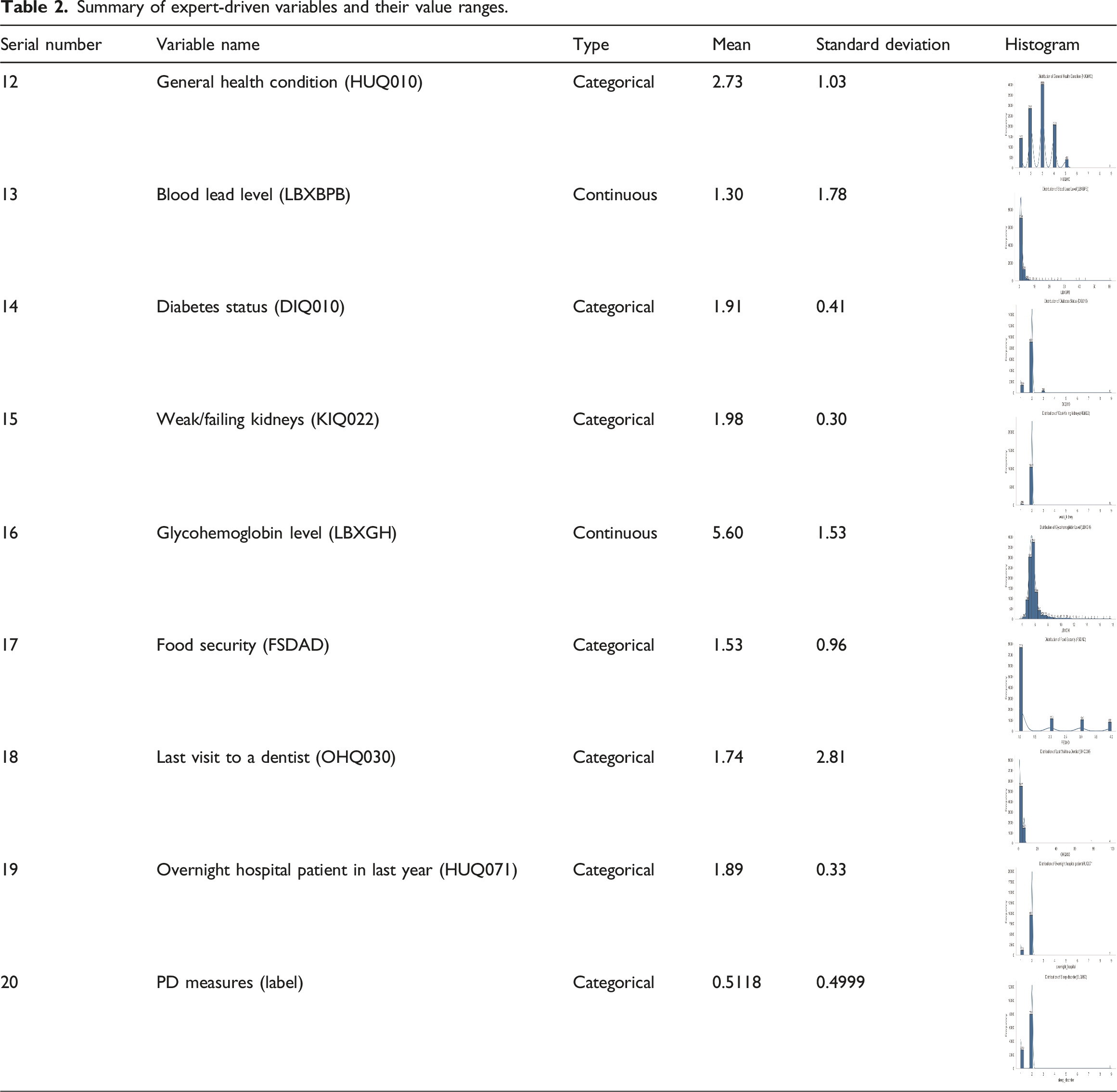
As people get older, their likelihood of having PD increases. This correlation is visually illustrated in Figure 2, indicating a distinct association between age and the risk of PD. Dental visits were classified as follows: less than 6 months (coded as 1), less than a year (coded as 2), less than 2 years (coded as 3), less than 3 years (coded as 4), less than 5 years (coded as 5), more than 5 years (coded as 6), and never visited a dentist (coded as 7). Gender was represented as male (coded as 0) or female (coded as 1). Race and ethnicity were grouped as follows: Mexican American (coded as 1), Other Hispanic (coded as 2), non-Hispanic White (coded as 3), non-Hispanic Black (coded as 4), and other races (coded as 5). Education level was divided into five categories
1
: less than 9th grade,
2
9-12th grade,
3
high school graduate,
4
some college degree, and
5
college graduate. Family income was a continuous variable with values ranging from 0 to 5.00. Due to missing values in smoking status (SMQ020, SMQ040), it was consolidated into single feature as follows: participants who smoked fewer than 100 cigarettes in the past were classified as never smokers (coded as 1). Those who currently do not smoke but have smoked at least 100 cigarettes were classified as former smokers (coded as 2). Participants who currently smoke every day or some days with at least 100 cigarettes in the past were categorized as current smokers (coded as 3).
6
Obesity, calculated based on BMI, was a continuous variable with BMI values between 13.18 and 82.9. Food security was divided into four categories: full (coded as 1), marginal (coded as 2), low (coded as 3), and very low (coded as 4). The blood lead level (ug/dL) included a range of values between 0.18 and 43.52. Tables 1 and 2 presents the variables used in this study along with their respective value ranges. Age versus periodontal.
Data preprocessing
The original NHANES dataset comprised of 101,316 cases and 10,896 features. Cases with missing periodontal data were excluded to prepare the data for ML analysis, resulting in a reduced sample size of 10,714. Following a comprehensive and systematic review of the existing literature38–42 on statistical analyses of risk factors for PD, supplemented by clinical expertise specific to this study, nineteen features were identified for the initial investigation. These features were selected based on their documented importance in previous research and their potential relevance in capturing patterns associated with PD.54–56 By combining evidence-based insights from the literature with clinical expertise, we ensured that the selected features not only align with established knowledge but also hold practical significance for predictive modeling and analytical purposes. Redundant features providing similar information and variables that were likely outcomes of periodontitis were excluded from the NHANES dataset for three cycles (2009–2014). Rows containing values marked as ”refused” and ”don’t know” were removed from the dataset.
The preprocessed dataset had missing values, presenting a substantial challenge for ML classifiers. The adept management of missing data is crucial to obtaining reliable results. Imputation is a widely adopted technique for addressing missing values, entailing the substitution of missing data with estimated or calculated values. 57 In this study, the iterative imputer was employed. This method leverages the internal structure and relationships within the dataset to estimate and fill in missing values. It follows an iterative modeling approach by initializing missing values with preliminary estimates. The imputation process iteratively refines values by fitting a model that predicts missing values based on relationships among observed features in a multiple linear regression equation. This iterative process continues until convergence, refining prior imputations in each iteration. The final imputed values are determined by averaging imputations across multiple iterations, effectively optimizing missing value estimates using the best available information. Iterative imputation was chosen for its ability to capture multivariate relationships with greater accuracy than simple methods, while offering a balance of interpretability and efficiency compared to complex DL-based techniques—making it well-suited for structured tabular healthcare data.
Identifying the most relevant features can enhance the performance of the ML classifiers. The feature selection process not only focuses on pertinent features, reducing overfitting and improving interpretability, but also accelerates training and inference, leading to the development of more efficient and robust models capable of effectively generalizing new data. Initially, all the columns with more than 50% NaN were removed, leading to 408 features. The study considered the top 50 features with the most significant F-scores. Redundant variables conveying similar information, as well as those highly influential in PD prediction, such as the count of teeth loss (OHX*), dental visit reason, etc., were excluded. Confounding variables identified in prior literature, along with insights from expert dentists, were integrated with the resulting selected features. This led to the inclusion of nineteen distinct features for analysis. To mitigate any significant association between periodontitis (coded as 1) and non-periodontitis (coded as 0) groups, Chi-square tests were conducted. It was observed that four variables (weak kidney, drinking, overnight hospitalization, and sleep disorder) had higher p-values, indicating their independence from the response variable and rendering them unsuitable for model training. Consequently, these variables were removed from the dataset. This exclusion helps improve the model’s performance by eliminating irrelevant variables that do not contribute meaningfully to predictive accuracy. It also prevents overfitting and enhances model interpretability. Domain expertise further confirmed their minimal clinical relevance in the context of this study. A total of thirteen variables exhibited statistically significant relationships with the outcome variable, PD (p < 0.05). Additionally, the pairwise correlation matrix of the features revealed a strong correlation
Statistical analysis
ML techniques were used to classify PD presence (coded as 1) or absence (coded as 0). 58 ML classifiers analyze the training data, recognize patterns and relationships between input features and desired outcomes. Throughout the training phase, the algorithm fine-tunes its parameters to minimize the disparity between its predicted periodontal outcomes and the actual target periodontal outcomes. Subsequently, these learned parameters are applied to predict future outcomes for the test dataset. The performance of the ML classifiers is assessed through diverse metrics, which entail comparing predicted and actual periodontal outcomes derived from the test dataset, distinct from the training phase. ML has a distinct advantage in processing large and complex datasets, especially with complex correlations between features. ML can enhance clinical decision support by providing potential benefits for the precise diagnosis and prognosis of oral health conditions. An important implication of these findings is the formulation of personalized dental treatment plans.
A total of 10,714 cases were used to train and test the ML classifiers. Among them, 8571 cases (80% of 10,714) were randomly selected for training, while 2143 cases (20% of 10,714) were reserved for testing purposes. In order to ensure fair results, identical splits (using a unique random seed) were utilized for all ML classifiers. The ML classifiers in this study were developed using Python 3.7.0 (Python Software Foundation). Evaluation metrics such as accuracy, precision (macro), recall (macro), f1-score (macro), sensitivity, specificity, and AUC were calculated using the test dataset.
Results
The study included 10,714 participants, with 48.67% males and 51.6% females. The racial/ethnic distribution was 40.83% White, 21.3% 22.02% African American, 21.50% Hispanic or Mexican American, and 15.65% others. Among the participants, 79.24% were below 65 years, while 20.76% were 65 years or older.
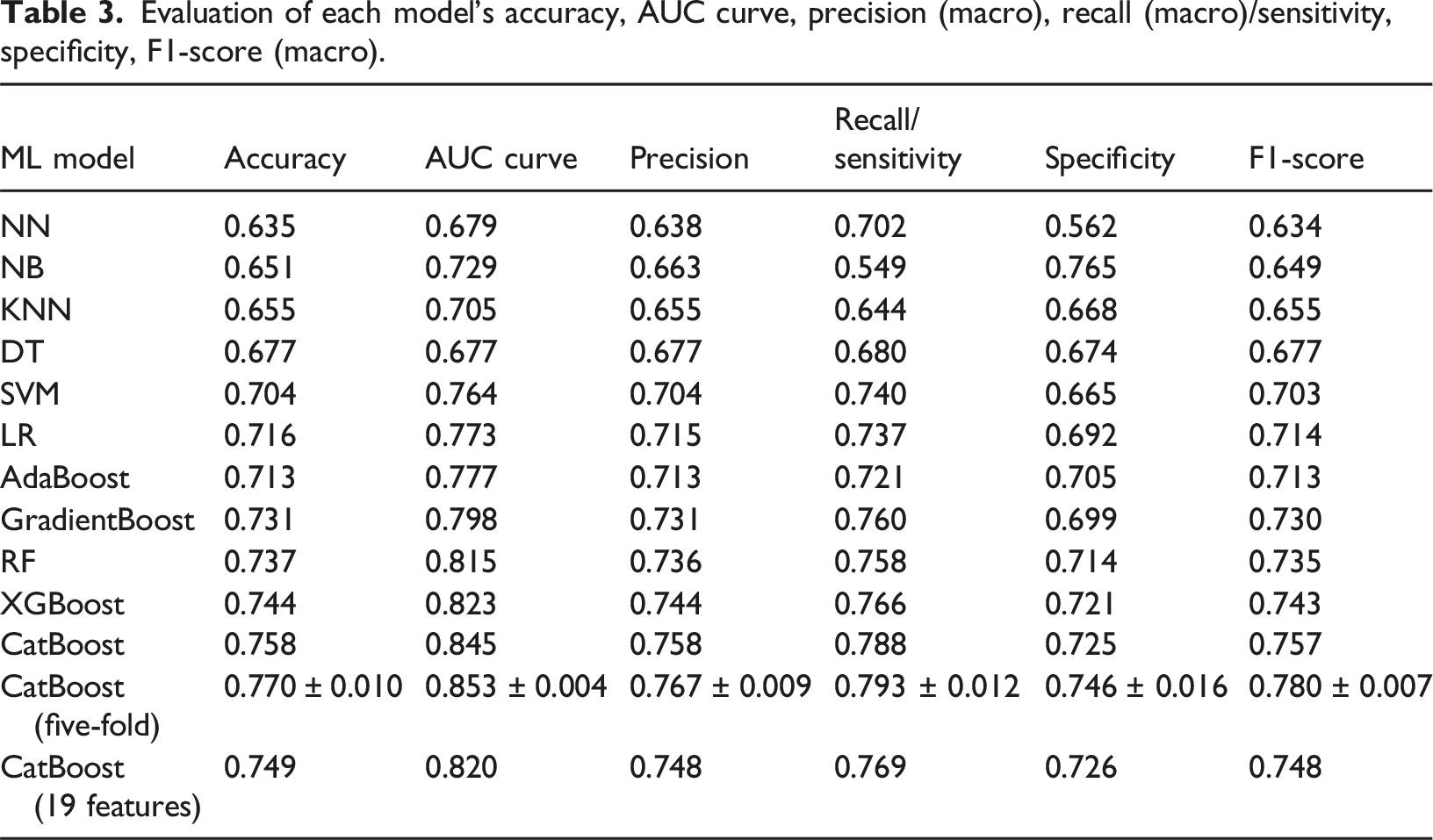
Evaluation of each model’s accuracy, AUC curve, precision (macro), recall (macro)/sensitivity, specificity, F1-score (macro).
A confusion matrix (refer to Figure 3) from the CatBoost classifier was the optimal model. The model has made 2143 predictions. Of these, 739 instances were correctly classified as negative (true negatives), indicating that the model accurately identified negative cases. However, there were 281 false positive cases where the model incorrectly predicted instances as positive when they were actually negative. On the other hand, there were 238 false negative cases where the model incorrectly classified instances as negative when they were actually positive. The model performed well in terms of true positive cases, correctly identifying 885 instances as positive. Confusion matrix with evaluated statistics.
The Figure 4 depicts the precision-recall curve, demonstrating the trade-off between precision and recall in a binary classification model. The primary objective of the model is to minimize false negatives when identifying potential dental patients. It is essential to minimize false negatives to ensure that no potential patients are overlooked. Therefore, the emphasis is on maximizing the recall metric, which signifies the model’s capability to accurately identify all positive cases. Precision-recall curve.
By prioritizing recall, the model seeks to identify the maximum number of PD patients, reducing the chances of overlooking individuals requiring dental attention. Maintaining a balance between false positives and false negatives is crucial to upholding the model’s overall performance. Although false positives might occur, the significance of preventing false negatives—which could lead to the neglect of patients in need of dental care—overshadows their impact. Overall, the research model emphasizes maximizing recall to reduce false negatives and ensure that potential dental patients are not overlooked while maintaining a balance with false positives for an effective and practical screening approach.
The Receiver Operating Characteristic (ROC) curves shown in Figure 5 demonstrate the performance of different ML classifiers. CatBoost exhibited outstanding ROC, with an AUC of 0.84. This can be attributed to its ability to efficiently handle multivariate, structured datasets like NHANES, which include both continuous and categorical variables. Its native support for categorical data reduces the need for extensive preprocessing while preserving feature relationships. Additionally, CatBoost’s ordered boosting technique mitigates overfitting by preventing target leakage—particularly valuable when dealing with correlated clinical variables. In contrast, the Decision Tree classifier demonstrated the lowest performance, with an AUC of 0.68, likely due to its tendency to overfit and its limited capacity to capture complex feature interactions. Receiver operating characteristics AUC score for each model.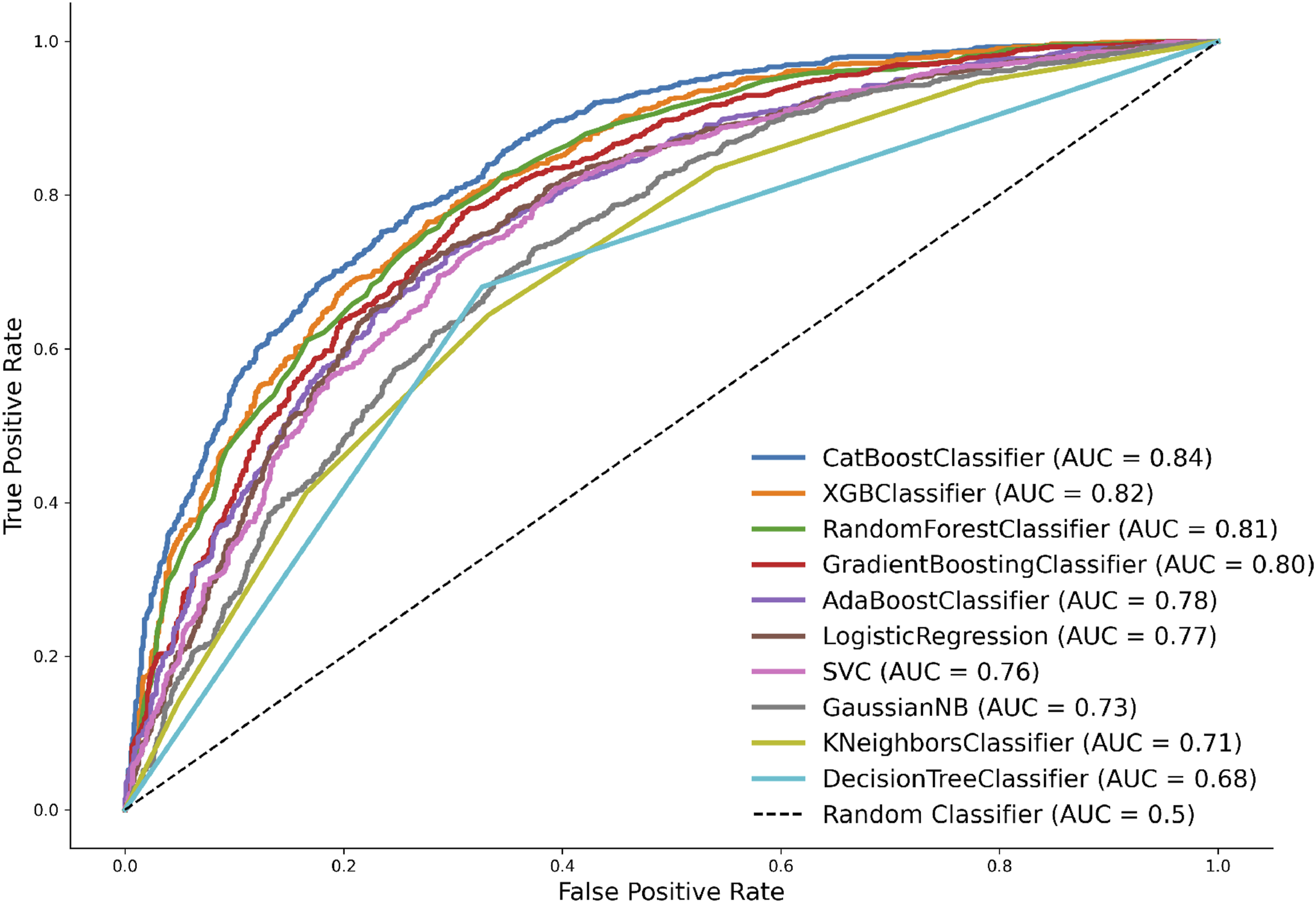
Discussion
Periodontitis is a chronic inflammatory condition affecting the supportive structures of the teeth, including the gums, periodontal ligament, and alveolar bone. This condition leads to a progressive deterioration of the supportive tissues, primarily caused by gum disease (gingivitis). The study centered on periodontitis due to its significant impact on oral health. However, periodontitis is preventable and treatable, with early intervention playing a crucial role in minimizing its consequences. Identification of periodontitis was carried out through oral examinations conducted by licensed and trained dental professionals as part of the NHANES study. Assessment of periodontitis involved evaluating the health of the gums, periodontal ligament, and alveolar bone. Various clinical parameters, such as probing depth, attachment loss, and bleeding on probing, were measured to diagnose the condition and assess its severity.
The increasing prevalence of PD presents a significant public health challenge. Leveraging ML techniques offers the opportunity to uncover factors associated with periodontitis, thereby facilitating improvements in oral health and subsequent enhancements in overall well-being. In this study, we utilized ML approaches on a comprehensive dataset to detect periodontitis. Through the analysis of NHANES data, we applied various ML methods to identify the optimal model and factors correlated with PD. Our results indicated that the CatBoost classifier demonstrated the highest accuracy in distinguishing between the presence and absence of PD. The CatBoost classifier also demonstrated the highest accuracy when utilizing the nineteen initial features (refer Table 3). However, the performance was observed to decline due to the inclusion of irrelevant features. This underscores the importance of an effective preprocessing method, which successfully identified features for exclusion from the initial cohort. The selected subset of thirteen features provided the superior performance, highlighting the significance of the proposed preprocessing approach. Moreover, this feature reduction minimizes the number of parameters that need to be documented, facilitating the real-time development of applications with fewer features while preserving the model’s performance.
To assess the significance of features in identifying PD, feature importance scores (F-Scores) were derived from the CatBoost Classifier and depicted in Figure 6. Higher scores indicate a greater contribution to the accurate identification of PD. Interestingly, dental visit status, household income, and age have emerged as the three most influential variables. Following these, the ten top ranking characteristics include blood lead level, glycohemoglobin, obesity (BMI), demographic factors (sex, race/ethnicity), and smoking status. In addition, it could be observed that most of the filtered features had a minimal impact on the performance of the model. Variable importance measurement score based on F-Score for: (a) all nineteen features and (b) the selected thirteen features.
Several features consistently emerged as critical indicators of PD across different ML methods. These variables included dental visit status, age, household income, blood lead level, obesity, demographic factors, and smoking status. Age was identified as the most relevant predictive variable, aligning with existing evidence 15 that highlights the increased risk of PD with advancing age. As individuals grow older, they are more prone to gum tissue inflammation and bone loss, contributing to the development of PD. Low income, a marker of socioeconomic status and potential financial barriers to dental care access, was also found to be associated with PD. 59 Lack of regular dental care can impede early diagnosis, prevention, and treatment of PD, leading to poorer oral health outcomes.
During our ML feature analysis, we noted a notable correlation between daily smoking and an elevated probability of developing PD. Individuals who smoke daily are at increased risk of developing PD compared to non-smokers, corroborating findings from recent studies.17,60 Furthermore, an interesting correlation observed in our analysis is the association between blood lead levels. Several recent statistical studies61–63 have highlighted the link between blood lead levels and the risk of periodontitis. To further enhance the interpretability of the model, the model, Shapley Additive Explanations (SHAP)
64
and Individual Conditional Expectation (ICE)
65
used to provide insight into the into the predictive logic of the CatBoost model. Figure 7(a) and (b) represent the ICE feature expectation plots. Figure 8(a) and (b) represent the SHAP feature importance scores. As observed in both graphs, the elimination of six features had minimal impact on model performance, highlighting the effectiveness of the preprocessing techniques in identifying redundant features. ICE feature expectation plots for: (a) the selected features and (b) the remaining six features. SHAP feature importance score for: (a) all nineteen features and (b) the selected thirteen features.

Evaluation of each model’s accuracy, AUC curve, precision, sensitivity, specificity.
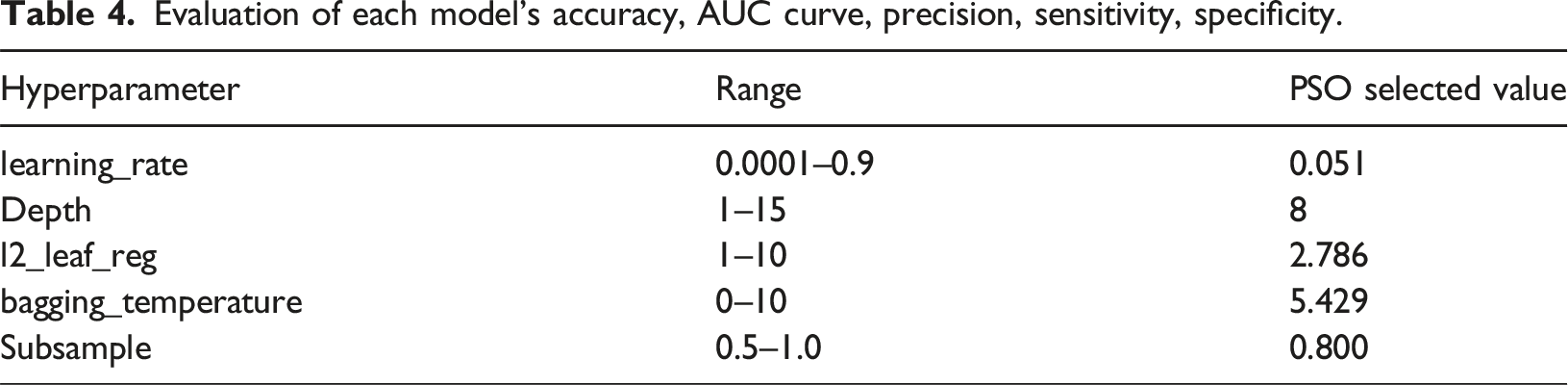
Evaluation of each model’s accuracy, AUC curve, precision (macro), recall (macro/sensitivity), specificity, f1-score (macro).

The potential for AI to revolutionize oral health diagnosis and prognosis is immense. By seamlessly integrating ML algorithms into future applications, such as real-time clinical decision support tools, precision medicine in dental care can become a reality. These screening tools can be utilized in various settings, including general medical practices, clinics, social service centers, and online platforms. They can provide oral examination recommendations for those at high risk. Additionally, ML can provide valuable insights into identifying underlying medical conditions or lifestyle factors linked to PD. This information can be particularly beneficial for non-dental professionals who recognize at-risk patients and refer them to oral health experts for prompt intervention, evaluation, and prevention.
By 2034, it is anticipated that the older population will substantially increase, with approximately one in five individuals aged 65 years or older, as projected by the US Census Bureau’s 2017 National Population Projections. 67 With the aging demographic, the prevalence of PD and other oral health issues among older individuals is expected to rise. Leveraging ML techniques presents an opportunity to gain deeper insights into and address PD in elderly populations, offering a promising avenue for early intervention and enhancing oral health outcomes. Through this study, robust and accurate algorithms have been developed to classify periodontitis using ML. These algorithms have the potential to catalyze the development of automated, cost-effective tools for dental care and precision medicine, with far-reaching implications for the prevention and management of PD and other oral health conditions.
Limitations
Several limitations were encountered in this study. First, the prediction model was developed exclusively using data from NHANES, potentially restricting the generalizability of our results. Moreover, reliance on self-reported data for behavioral factors such as smoking and alcohol consumption may introduce reliability issues and could influence the accuracy of our prediction model. Additionally, the utilization of imputation methods to address missing data could impact the performance of the model.
Future studies
In future research endeavors, the proposed model will undergo application and potential retraining with an expanded dataset. Furthermore, investigation into various other NN architectures will be conducted to bolster the model’s performance. Additionally, the exploration of incorporating new risk factors will be pursued to better encapsulate the distribution and behavior of input features within the model. We plan to explore additional imputation methods68,69 and conduct further sensitivity analyses to ensure the robustness of our findings. Although this study used features selected from the prior literature and expert dental insights, further refined through feature engineering, future research could extend this work through comprehensive data-driven research of feature selection. 70 Such studies may utilize all available features to identify optimal combinations and apply advanced methods to validate the robustness of the selection process. This study lays the groundwork for the development of a decision support tool aimed at assisting healthcare practitioners in making well-informed decisions regarding the risk of PD development across various patient screening scenarios.
Conclusions
Periodontal disease represents a widespread oral health concern, and the development of ML techniques to assist in diagnostic decision-making and preventive interventions for this condition can yield substantial health advantages. Our initial investigation yielded promising results by leveraging NHANES data and ML techniques to predict the likelihood of PD. The implementation of such a model holds the potential to provide healthcare providers with fresh insights into the risks associated with PD and the key factors contributing to its progression. Consequently, clinicians can adopt proactive measures informed by this knowledge. The models developed in this study demonstrated commendable performance in accurately categorizing the presence or absence of PD, as evidenced by strong accuracy, sensitivity, specificity, precision, and AUC scores. The visualization of features facilitated the interpretability of the predicted outcomes. Notably, many identified features aligned with findings from recent studies, underscoring the clinical relevance of our approach. This knowledge can empower clinicians to adopt proactive, informed interventions for PD management.
Footnotes
Author contributions
Giang T. Vu: Contributed to conception, design, data acquisition and interpretation, drafted and critically revised the manuscript. Veena Mayya: Contributed to design, data acquisition and interpretation, drafted and critically revised the manuscript. Babu Mandhidi: Contributed to data acquisition and interpretation, drafted and critically revised the manuscript. Christian King: Contributed to draft and critically revised the manuscript. Bert B. Little: Contributed to draft and critically revised the manuscript. Varadraj Gurupur: Contributed to draft and critically revised the manuscript. Astha Singhal: Contributed to draft and critically revised the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.