
Abstract
Background
Over the last 50 years, there has been an abundance of literature from social science disciplines on the existence of racial disparities across all social domains. Significant investment to eliminate racial health disparities has been made with the convergence of racial injustice protests and national solidarity; empirical evidence related to social determinants of health and health disparities; and the financial burden of disparities, which is expected to exceed $363 billion by 2050. 1 Conventionally, racial health disparities have been attributed to genetic variation among races, lifestyle, and behavioral choices. However, findings from the Human Genome Project2,3 have shown that race is a social construct rather than a biological function, with slight genetic variation between races. Lifestyle and behavioral choices are estimated to account for only 30% of an individual’s health outcomes. 4 Thus, genetic variation among races, lifestyle, and behavioral choices fail to sufficiently explain racial health disparities.
Researchers have begun to explore racial health disparities as a mechanism of structural racism. Structural racism occurs when multiple interconnected institutions operate with embedded laws, policies, and rules that result in detrimental treatment for members of a particular racial group. This is in contrast to institutional racism, which focuses on the actions of a single entity. 5 There are two critical elements of structural racism related to processes or policies: it generates disparities with or without explicit bias or intention 4 and it reinforces and perpetuates racial group inequities. 5 A growing body of evidence related to structural racism has galvanized leading health and research organizations and governing entities to address health disparities. The National Institutes of Health (2021) established the UNITE collaborative initiative intending to address structural racism within clinical research by promoting diversity (https://www.nih.gov/ending-structural-racism/unite). The National Academy of Medicine (2021) published the Future of Nursing 2020-2030, Charting A Path to Achieve Health Equity, which includes a detailed plan for nurse leaders to address structural racism. 6
An emerging field of research has discovered racial bias in artificial intelligence (AI) across multiple fields. This bias has impacted interest rates, housing and employment opportunities, criminal justice, and the social determinants of health of racial minorities. 7 The exploration of existing algorithms, AI, and machine learning (ML) models in all social institutions, including healthcare, has intensified due to the dissemination of racially biased findings. Regulatory interventions have been suggested in many fields including facial recognition. 8
While algorithms may be accurate in a population overall, they may differentially recognize and have worse performance for certain populations. This may occur as a result of a biased population in training data, outcomes, variables in survey data, or laboratory values. 9 An example of dataset bias in AI is the issue of facial recognition systems struggling to accurately identify individuals with darker skin tones. Early training datasets for these systems often lacked diversity, leading to biased models that performed poorly on people of color; they performed even more poorly when detecting women of color. Despite significant publicity and ongoing efforts to ensure fairness and equity in facial recognition technology, bias remains an enduring problem. 10
While statistical correction,11–13 pre-processing of data and fairness constraints (i.e., transforming data to remove sensitive information), 11 and post-processing (i.e., trying to correct bias when the ML data or algorithms are unavailable) 7 have been discussed, none represent a comprehensive solution to algorithmic inaccuracies and poor performance.9,14
AI holds great promise for healthcare, but proper bias detection and correction are essential in ensuring good healthcare outcomes. 15 There is a growing need for discussion on the topic of bias correction in ML and AI. 15 The purpose of this white paper is to describe the findings of a recently held workshop in which experts described potential solutions for detecting and correcting bias within healthcare AI, and is further illuminated by a subsequent literature review. We anticipated that this approach would facilitate the emergence of both innovative and established ideas on the topic. By engaging with renowned experts in dynamic discussions, we aimed to provoke new insights and refine existing concepts; generating insight from the workshop attendees allows us to determine strategies that are currently being thought of and/or utilized by people in the industry. This method not only leverages expert feedback to enhance and validate current evidence but also identifies critical gaps that merit further investigation through subsequent literature review.
Methods
To discuss potential solutions to reducing healthcare bias in ML/AI, we created a workshop that was held during the 2022 Healthcare Information and Management Systems Society (HIMSS) Global Health Conference and Exhibition in Orlando, Florida. Nearly 29,000 professionals across disciplines in healthcare and data science attended the conference and approximately 50 of those professionals in medicine, nursing, engineering, data science, and healthcare education participated in the workshop; specific demographics of the attendees were not collected as this was not a research study. The workshop began with a presentation that defined bias in healthcare and discussed the effect of biased data on AI in healthcare. After the presentation, workshop participants were requested to provide feedback aimed at achieving the following objectives. • Contrast various proposed solutions to reduce and eliminate bias in healthcare AI • Hypothesize best solutions for addressing concerns about bias in healthcare, whether by mixing existing solutions or determining if a new solution is needed • Appraise the solutions presented during the discussion session for reducing/eliminating bias in healthcare AI
The workshop was recorded and posted on the conference platform for view by those attendees unable to attend, and viewers were invited to submit additional feedback. That additional feedback was incorporated with the feedback from the workshop.
Participants were encouraged to provide feedback on the content and the ideas presented by others. Notes were taken by the session moderator and subsequently analyzed for thematic content by the authors of this paper within the framework of current evidence, using the methods suggested by Kiger and Varpio. 16 First, the workshop moderators familiarized ourselves with the data through attending the workshop, discussing the results, and reviewing the notes and transcripts from the workshop. We then generated initial codes which were reviewed by the manuscript authors and searched for themes. Together, through iterative rounds we defined and named the themes, and worked together to produce the report. Supported by a subsequent literature review, the results of the thematic analysis are presented and further explored below. As this workshop did not fit the criteria of human subjects’ research, Institutional Review Board approval was not required.
Results
For the purposes of the workshop, AI was defined as mathematical algorithms used to simulate intelligence built on datasets input by healthcare systems. Because of the cyclic nature of feedback meant to improve algorithms over time, biases in the dataset or the algorithms can have a positive feedback loop, increasing the biases over time.
Approaches to reduce bias in healthcare and potential strengths and weaknesses based upon workshop participant feedback.

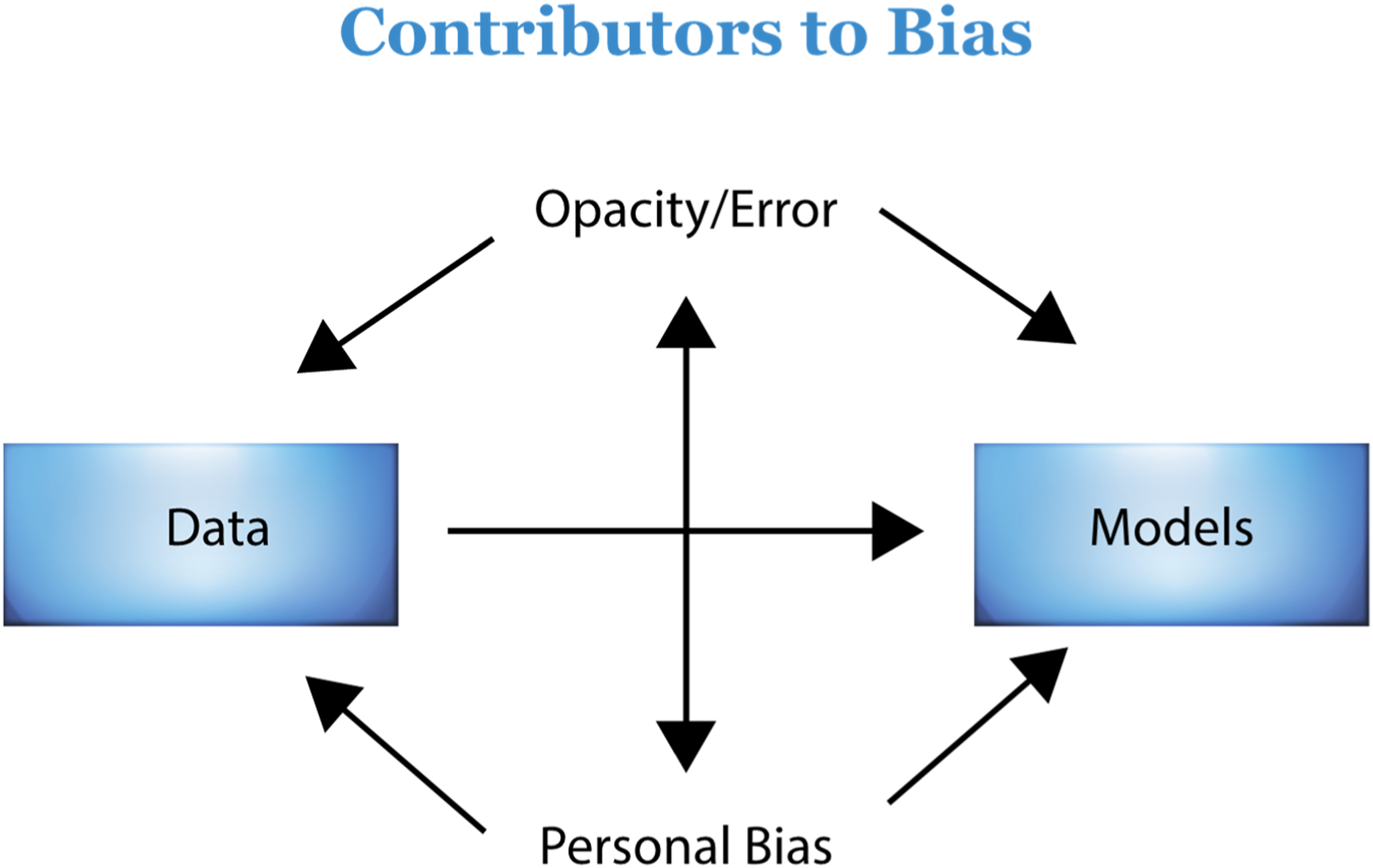
The relationship of factors that contribute to bias. A model showing how various factors introduce bias into AI overlap; these need to be regulated. Opacity and error, as well as personal bias, cause bias in both data and models and reinforce bias in each other. Bias in data sets contributes to bias in models. Regulation should be governed by diverse stakeholders and regulation should also include regulation of stakeholders. 36
Discussion
Reducing dataset bias
The discussion from workshop participants revealed that the use of existing data may have inherent biases. While some datasets are created for the express purpose of developing AI on a particular topic, existing datasets must often be used; a key example is the Electronic Health Record (EHR). An EHR is a digital database of patient information, medical results, provider notes, images, and much more. 18 While it serves as the repository of rich information that can be used to better understand medical procedures and practices, it stems from what was formerly a physical document, which through many iterations was developed into an electronic format over the past 40 years. Because of this, EHRs and related data warehouses combining these records are exceedingly complex with many redundancies. Often, finding information can be difficult, even with the development of natural language processing to assist in this capacity.
Participants suggested that one of the most important ways to reduce bias in AI is to ensure that the data used to train the model are accurate and suitable for use in an AI model. 37 For example, during a patient encounter, a provider has the opportunity to do a review of systems (ROS) and to account for the review in the EHR. 17 The data input into the EHR during the patient appointment provide valuable information that can be used to understand how to treat the patient in the future. If the data that are input into the EHR based upon the encounter are inaccurate, then the future decisions made based upon these data will be biased. Studies have shown that there are inconsistencies between audio-visual data of what occurred in the appointment and the information input into the EHR. 17 Thus, while ensuring that data input into an EHR will generate rich data with which to model, accuracy of the data must also be considered.
Workshop participants also suggested the use of synthetic data may to build a model if the data in an EHR are not reliable or do not include sufficient observations from a given race, ethnic, or minority group. The use of synthetic data has many strengths. Synthetic data is artificially generated or simulated information, modeled to reflect the statistical properties of real data derived from actual events. 19 There is little cost associated with generating synthetic data, there are no privacy concerns, it enables increased exploration, and potentially avoids the need for a lengthy review process. 19 While these strengths are many, synthetic data, based upon how it is simulated, may not be accepted by a stakeholder viewing the results. This is especially the case if the synthetic data are created in such a way that they do not reflect what would occur in a real-world scenario. For example, if there is insufficient underlying evidence about certain populations, synthetic data will not reflect the statistical properties of those populations and, thus, create unintended bias. If the use of synthetic data is discouraged and a dataset is known to be biased, then an alternative could be to experiment with how the dataset is sampled and modeled. For example, an ensemble of models (where a group of models is combined and used to build a better predictive model than any of the individual models) could be built using the current data, 20 thus reducing the bias of using a single methodology to model the data.
An additional intervention suggested by workshop participants to reduce dataset bias was the use of crowdsourcing of data. If a dataset omits certain minority groups and is thus known to be biased, the public could be requested to reply to a survey or there could be a call for data to supplement the dataset (i.e., “crowdsourcing”). Studies have shown that crowdsourced data can increase the quality of data, reduce the cost of acquiring data, and increase the volume of data. 24 In a recent study, Yank et al. 38 compared crowdsourced data to comparable data from the Behavioral Risk Factor Surveillance System (BRFS). While individuals in the crowdsourced data had slightly different characteristics from the BRFS data (e.g., younger and with higher levels of education), the additional data were valuable in making decisions, and the differences were controlled for in the analysis. Historically, this method has been limited because it tends to recruit mainly younger, more highly-educated, non-Hispanic whites, or has not collected robust datasets.24,38 However, recent efforts have demonstrated the ability to intentionally target more diverse, representative, and robust samples, such as the All of Us Research Program conducted by the National Institutes of Health. 23
All of Us came out of the National Institute of Health’s (NIH) “Precision Medicine Initiative Working Group of the Advisory Committee to the Director.” To achieve precision medicine (i.e., individualized healthcare plans based on the individual and incorporating the environment), there must be a representative database. Therefore, the All of Us project aims to build a diverse and comprehensive database through online recruitment ad campaigns that can provide data for thousands of research studies on a variety of topics and conditions. Within this program, there is a targeted effort to include a representative sample of all types of people and groups. 23 This is one of the largest examples of crowdsourcing and demonstrates the power of this mechanism to develop a large, diverse database using crowdsourcing. The dataset has recently been used to study health equity in the fields of hypertension 39 and pneumonia 40 and to illuminate biases in access to care. 41 While there is no perfect way to address lack of or inaccurate data, the actions discussed in this section such as crowd-sourcing and the use of synthetic data may help reduce bias.
Accurate modeling of existing data
Because the EHR contains a huge amount of rich information, it is a valuable resource when trying to model and understand disparity in care; workshop participants emphasized that accurate modeling of these kinds of data is needed to reduce bias. AI built to handle the vastness and complexity of the data has the potential of enabling researchers to improve on shortcomings within datasets. While an EHR contains providers’ notes, descriptions, and diagnoses, providers may also make decisions based upon their intangible assessments of a patient. This data has been described as unobservable data. 19 Notably, if a provider has an explicit or implicit bias against patients because of their race, ethnicity, or other factors, the information and the conclusions they formulate will be biased. Although the medical information is recorded in the EHR, the bias/prejudice is not; it is unobservable. Thus, any AI built from the data will be biased, and unable to recognize a fairer decision. The decisions from the AI will perpetuate the bias further, and increase the negative feedback loop that keeps patients from receiving the care they deserve or need. 42
It can be especially difficult to build AI that can account for unobservable data. Lakkaraju, Kleinberg 25 propose a model that compares the performance of a predictive model and human decision-makers with the results of a single model decision-maker (e.g. provider) with that of a group and, specifically, the “most lenient” of the group. For example, in a medical setting, the decision of a provider to recommend a patient for a specific medication would be compared to a group of providers who have made a similar decision, and the provider who has recommended the medication the most frequently (i.e., the most lenient). If it is found that a model or decision-maker is abnormal compared to the group, then action can be taken. An evaluation of providers’ actions with this type of model could improve the data that are input into the EHR, and thus, improve an AI model built from the data.
Another way suggested to potentially account for currently unobservable data is to try to increase the amount of observable data. This would entail increasing the amount of data that are recorded in the EHR or another mechanism that could recognize and record unobservable physician action. This solution could also be problematic for a few reasons. First, the EHR is already complex. Adding more data and trying to fit a model to a specific dataset from each EHR may result in overfitting of a model. Too many specialized fields in an EHR for a specific hospital would make any model built from that data less robust and applicable across fields and medical centers. Secondly, health care providers already report fatigue with current entry requirements for EHRs. 25 User fatigue when entering data leads to mistakes; errors in the EHR introduce bias in AI. Lakkaraju, Kleinberg 25 state “If the health-care provider is not overwhelmed by the data input process, the probability of errors will be much smaller.”
Increasing the amount of data collected in the EHR may be necessary in an attempt to collect unobservables, but should only be done if there is confidence that the additional data will help to capture a datapoint that was previously considered unobservable. It is important to develop mechanisms that can account for this bias; in the case of the most “lenient provider,” this could be the amount of funding spent in advertising by pharmaceutical companies (that could unnecessarily influence providers), or whether scientific literature based on the efficacy of certain drugs reaches prescribers.
Finally, the last recommended strategy for accurate modeling of existing data was that researchers should be aware of bias during the ideation phase of clinical trials. Planning for ways to reduce bias in clinical trials could potentially reduce the bias in the end result, and should be considered at each stage, starting with the development of the clinical protocol. 43
Transparency of AI
Workshop participants emphasized that transparency of AI is important, as it allows for more oversight and accountability. In the process of developing AI, black box models have become prevalent, where the logic behind a model and the link between the inputs and outputs cannot be understood by a human. Some feel that not understanding the mechanisms of the AI can be dangerous because it does not allow for or makes it very difficult for the user to detect mistakes. 28 Others have argued that AI models do not need to be black box, and interpretable models, models where the inputs and outputs can be linked and understood, do not reduce the accuracy or ability of the model to make predictions.29,30 Even if a black box model can be explained after it is built, explanations can be unreliable or misleading. This could mean that while explainable models are helpful, it would be better to build an interpretable model, where users can understand how input variables are used to determine the output. 30 Some decisions that are high risk may require human oversight to avoid costly or harmful mistakes. 29 On the other hand, some argue that explainability is not necessary, as humans often do not fully understand the mechanisms of the tools they use (e.g., most people do not understand how a computer works, but still rely on the output it generates as being valid). 26
The idea of transparency relates back to the concept of bias in the dataset. For instance, one may allow for less transparency if the dataset is known to be unbiased, whereas one may be less comfortable with a lack of transparency when dealing with unfamiliar or unexplored concepts. 26 Bias can also be introduced during the modeling process, so it is important to use appropriate evaluation metrics and testing procedures to ensure that the model is not biased. For example, training data with labels applied by humans has been shown to be flawed by magnifying the bias introduced during the labeling process. 28 AI developers should document the data used to train the model, the features selected, and the algorithms used.
Transparency can also be used as a method to engage stakeholders, by allowing them to manipulate inputs and have confidence that implementation of the model will work properly, and has been suggested as a way to assist in the regulation of AI.27,44 Stakeholders refer to those that have an interest in or are impacted by a model. Compromise between transparency and a willingness to use AI with a black box that has demonstrated value, and accuracy may be an important way to ensure the advancement of technology without introducing additional bias.
Regulation of AI
The participants noted that regulation of AI would be an important step to reduce bias in healthcare AI. Currently, regulation of data scientists and developers in healthcare is lacking; there are minimal requirements for who is qualified to produce, distribute, or vend healthcare AI, and skillsets or credentials are not currently defined. Those opposing such regulation fear the possible unintended consequences of regulation, such as stymied growth. 36
Government regulation of AI has not matched the rate of its adoption AI across industries. While the United States government has issued a “Blueprint for an AI Bill of Rights,” the document lacks concrete steps for monitoring and regulating both AI and producers of AI. 45 Moreover, existing laws lack the ability to catch and regulate subtleties that could exacerbate racism in healthcare. 45 The United Kingdom (UK) has progressed further with the first proposed rules on AI, but these are also lacking in concrete steps to monitor or regulate AI. 46 The U.S. Food and Drug Administration (FDA) attempted to issue guidance in 2019 47 on the regulation of AI, but the guidance was issued for discussion purposes only, and therefore had little impact. In 2021, it issued an action plan in response to the proposed guidance, but as of the time of this writing, the plan has not been implemented. Whereas the focus of this paper is to strategize ways to reduce bias in AI models, the workflow proposed by the FDA gives an overview of the lifecycle and process of AI development, denoting points where interventions could be made to ensure the safety and quality of a machine learning product (the full model can be viewed in the report at: https://www.fda.gov/media/122535/download/). 37 This workflow may clarify the lifecycle of ML/AI development, but the lack of a concrete implementation plan limits the utility of these suggestions.
Importantly, regulation should include stakeholders, a strategy that overlaps with many of the other aspects already presented here for reducing bias in healthcare AI. Among the ways to include stakeholders are: active involvement of healthcare workers, multidisciplinary sharing of information, training of diverse and underserved groups to become professionals in the field, the ability to ask a human for a second opinion, and having people from outside the industry involved in regulation. 48
The National Academy of Medicine issued a report that suggests that existing laws may provide regulation over some aspects of AI, but these are not specifically geared toward AI and may miss subtleties that are introduced through the use of AI. 49 Importantly, while stakeholders are frequently mentioned, the need for regulation and diversity of these stakeholders is not.
External validation of a model could help with regulation by allowing outsiders to confirm the utility of certain AI models. However, external validation is limited by the fact that it requires sharing of information that could be private, and limits the external validator’s ability to properly assess a model. 49 Some authors suggest that full transparency is not feasible for a number of reasons, including disclosure of private data, the loss of a competitive edge for the developers, the ability for users to “game” the system, and a possibility that due to the complex nature of ML, algorithms would be difficult to understand. 50 To overcome this, oversight boards may allow for regulation of ML and such bodies could be granted full transparency, even if it is not feasible for the public. 50
Methods such as bias-correction algorithms have been recommended,11,12 but have inherent problems that cannot be addressed by programming alone. The algorithms require regulation over their production and the training of the producers of the algorithms. As we have discussed, using AI to regulate AI bias exacerbates the issues of bias in AI.
Recent advances in AI have resulted in large language models (LLMs), such as those used by CHATGPT4, that are being quickly adopted to advance healthcare. LLMs are deep-learning neural networks that use language to predict and generate text in a human-like fashion. While LLMs may be used as a starting point to answer a question, they may provide incomplete or inaccurate responses. Because LLMs are being built on widely available data, they have the propensity to exacerbate biases imbedded in data. For example, in the spring of 2023, we asked CHATGPT3.5 to write this paper. The results were limited in depth and included inaccurate and fabricated references. For example, one article reference had the correct authors and publisher, but an incorrect title (correct title: Fairness and machine learning: Limitations and opportunities; inaccurate title: Fairness and machine learning. In Big Data: A Survey). 51 Another provided reference had the correct title and publisher, but included an additional author and incorrect year (correct authors: Raji & Buolamwini; inaccurate authors: Raji, Hardt, & Buolamwini). 52 As LLMs rapidly develop, special attention needs to focus on the potential integration of biases, as recent literature shows biases by race, ethnicity and politics persist. 53 Furthermore, companies that develop these models are mainly controlled by the US and so results tend to favor western English speakers, US culture and economic status. 53
This is partly due to the limited access of other countries to the resources that US holds both in terms of physical equipment and technology needed to develop LLMs, access to large data sets needed to develop LLMs (some countries, such as China, restrict both the use of LLMs and access to the data needed to develop such models), and the companies developing LLMs. Additionally, without freedom of speech, government censorship may also hinder development of AI and intentionally introduce biases in AI. 54
The true power of LLMs is the continuous data input that improves results; however, because of the privacy of health data, this ability is limited. Some have argued that regulation of LLMs should be focused on outcomes rather than the technology itself, while the UK has proposed that regulation should be focused on use-case (e.g., more stringent regulation of high risk scenarios than low risk scenarios).46,55 Rapid development of LLMs has already revealed that existing laws may not be enough to deter companies from unethical practices; certainly clearer laws with penalties sufficient to deter this behavior must be developed. 56
Guidelines for testing ML models have been proposed and could be adapted for use in regulation, in addition to requiring researchers and developers to test models as they are built. 57 Toolkits have been developed that are freely available for integrating bias detection within algorithms and commercial companies are developing detection software programs, but neither have been integrated into governmental oversight.58,59 Additionally, toolkits may introduce additional bias by putting the ultimate authority of one group as the decision makers of detecting bias over all others. While there has been academic discussion about the need for testing for bias, more needs to be implemented in terms of clinical research and regulation. 58
Bringing stakeholders to the table
Workshop attendees suggested an overlapping strategy recommended to reduce bias was to ensure that underrepresented groups are included in the development of healthcare AI.59,60 Underrepresented groups should be included in all aspects of bias detection and correction. 59 This should include pipeline development, where strategies are put in place to ensure that underserved or underrepresented people have the opportunity to obtain the education and training necessary to become data scientists, software developers, and others. 61 Programs such as the United States’ Affirmative Action help to ensure a diverse body of students in the technology field. Historically, bans on programs such as these have resulted in fewer people of color across fields of studies, with some of the more notable effects in engineering fields. 62 Thus, recent bans of Affirmative Action programs are likely to increase bias in AI in the long run. Because of the overlap with many other methods to reduce bias as described above, it is evident that bringing representative stakeholders into the process of creating, using, and regulating AI is critical in reducing bias in healthcare.
To diversify the technology workforce and develop a robust pipeline of AI talent from both within and outside the industry, a multifaceted approach is essential. One key strategy is expanding access to education and training through scholarships, grants, and affordable or free AI courses, particularly targeting underrepresented communities. Early STEM education is also crucial in fostering interest in tech careers. Inclusive hiring practices, such as bias-free recruitment, diverse interview panels, and targeted outreach to institutions like historically Black colleges and universities (HBCUs), can help in attracting diverse talent. Additionally, partnerships between industry and academia, along with mentorship programs, can provide real-world experience and guidance for individuals from underrepresented groups.
Retention and career advancement of diverse employees can be supported through transparency in pay and hiring processes and ensuring diversity at all levels, as well as supporting worker-driven diversity movements. 63 Reskilling programs and career transition partnerships can also open doors for professionals from non-tech industries to enter the AI field.
Supporting entrepreneurship among underrepresented groups through funding, innovation hubs, and incubators can further diversify the AI landscape. Finally, advocating for policy changes, such as government incentives for companies that hire and train diverse talent, and fostering public-private partnerships can ensure a comprehensive approach to developing a diverse AI workforce. These strategies are aligned with the growing recognition of the importance of diversity in AI, as a diverse workforce brings varied perspectives that can lead to more innovative and equitable AI solutions. 63
Limitations
This paper presents the results of a single workshop. While the HIMSS Global Health Conference is one of the largest health informatics conferences in the world, with many professionals across industries, diverse backgrounds, and a broad geographical representation, it is likely there were some views or ideas that were not represented. To counter this, we invited feedback from those unable to attend via the video posted through the conference proceedings. We also conducted a literature review to augment the feedback and uncover whether there was additional information or ideas missing from the commentary. However, future studies could include other methods to ensure more ideas are included, such as a Delphi survey.
The purpose of this paper was to understand the potential mechanisms that could be used to overcome bias in healthcare AI rather than to define the specific processes to surmount the current issues with bias in healthcare. Specific, concrete steps should be developed and could include developing action committees, both within institutions as well as within governments to develop specific policies and procedures to implement the strategies suggested here. Progress measures should include outcome measures (such as more equitable healthcare outcomes) rather than only process measures (e.g. number of policies or committees developed, etc.). Future studies may also compare the relative ability of each strategy to create change.
Conclusion
Our workshop and subsequent literature review of the suggestions resulted in five main domains to be addressed to reduce bias in AI; reducing dataset bias, transparency in AI, accurate modeling of existing data, regulation of AI and the people who develop it, and bringing stakeholders to the table. Current literature illuminates a deficit of research or discussion about the need for representative stakeholders, and the need for diversity in both the development of oversight and the pipeline of future scientists who will create AI.
Evaluating the long-term impact of strategies such as reducing dataset bias, improving AI transparency, and regulating AI systems and their developers is crucial. These strategies will require sustained effort to achieve meaningful short-term results and are likely to produce more significant long-term effects. Similarly, efforts to include diverse stakeholders and create a robust pipeline for increasing diversity among AI developers may not yield immediate results but are expected to have a profound and lasting impact on reducing bias in healthcare AI over time.
The passage of the Health Information Technology for Economic and Clinical Health Act (HITECH Act) in 2009 and subsequent legislation mandating that all private and public providers maintain EHRs has spurred the rapid development of AI to improve health outcomes. The saying, “garbage in, garbage out,” related to programming input illuminates the risks of health-oriented learning models and algorithms trained on inaccurate data. It also highlights the associated detrimental consequences related to health outcomes (including misdiagnosis and undertreatment), and the increase in health disparities for underrepresented or misrepresented groups within the dataset. Safeguarding the accuracy of new and existing datasets, such as EHRs, is crucial for health equity. New software and recruitment interventions have attempted to mitigate AI bias, but the need to bring diverse stakeholders to the table to reduce flawed input leading to biased Al models is crucial for long term success.
The workshop presented a breadth of experts interested in reducing bias in AI. While most of the ideas presented were not novel, they did provide a comprehensive overview of the many aspects that need to be addressed to ensure that bias is reduced or eliminated from AI. Many of these will require long term, strategic planning to be successful. This paper presents an in-depth overview with clear descriptions of promising methods to reduce bias in healthcare AI.
The workshop offers a significant advantage over traditional literature reviews by harnessing the power of collective idea generation in a much shorter time frame. Unlike literature reviews, which can be lengthy and sometimes stagnant processes, a conference workshop fosters real-time collaboration and rapidly synthesizes diverse perspectives, yielding insights that might otherwise take much longer to uncover.
Our experience underscores this advantage. The workshop application was submitted in 2021, the event took place in 2022, and we have been working to publish our findings since late 2022. This timeline illustrates the efficiency of the workshop model in generating actionable ideas and solutions. By contrast, the process of reviewing and analyzing the data, and conducting a comprehensive literature review took nearly a year, highlighting the extended duration typically required for conventional methods.
Moreover, the workshop surfaced critical and novel insights not previously highlighted in existing literature. For example, it emphasized the urgent need to build a diverse workforce pipeline and address broader societal structural issues that perpetuate racism—topics that have not been sufficiently addressed in prior literature reviews. This demonstrates the workshop’s unique ability to advance the discourse by identifying and prioritizing emerging issues that may be overlooked in more static review processes. Thus, the workshop not only accelerates the generation of innovative ideas but also contributes valuable, previously unexplored perspectives to the field.
We believe focus should be put on developing a pipeline of diverse healthcare technology engineers and healthcare stakeholders. We found nothing in the literature to suggest whether or not having a diverse group of stakeholders improves healthcare outcomes. This is an area ripe for research. Our literature review suggests that while many of these topics have been acknowledged, there are more proposed suggestions for improvement rather than concrete action plans. Governments and institutions should recognize these stakes and create structures and plans that support the development of a healthcare AI workforce. Strategies and progress measures should be actionable and transparent to ensure change.
Footnotes
Acknowledgements
The authors would like to acknowledge with gratitude those who attended the workshop at the HIMSS 2022 conference and participated in the generation and discussion of these ideas, as well as Dr. Lisa Persad for input into early drafts of the manuscript and Dr. Shiela Strauss for assistance with copyediting earier drafts of the manuscript.
Author contributions
CS developed the concept for the workshop and paper. Both authors contributed to analysis of finidngs, literature review, writing, editing, and review of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.