
Abstract
Objective
To design and evaluate a privacy-preserving federated learning (PPFL) framework for sensitive healthcare data, balancing robust privacy, model performance, and computational efficiency, while promoting user trust.
Methods
We integrated differentially private stochastic gradient descent (DPSGD) into a federated learning (FL) pipeline and evaluated the system on the Stroke Prediction Dataset. Experiments measured model utility (accuracy, F1), privacy (
Results
The proposed framework achieved 93% accuracy on stroke risk prediction while maintaining a final privacy budget of
Conclusion
This PPFL framework enables effective, trustworthy privacy-preserving ML in healthcare and resource-constrained settings. Future work will extend model architectures, regulatory alignment, and direct user trust assessment.
Keywords
Introduction
As machine learning (ML) becomes widely integrated into high-stakes domains such as healthcare, finance, and public policy, concerns about data privacy have increased. In these settings, sensitive personal data drives model training and inference, but misuse or exposure poses major ethical, legal, and reputational risks. 1 In response, privacy-preserving machine learning (PPML) has emerged as a subfield focused on securing data throughout the ML pipeline, using techniques such as differential privacy (DP), federated learning (FL), and homomorphic encryption (HE). 2
While these techniques address privacy concerns, each introduces new technical and practical trade-offs. DP injects noise to prevent reidentification, but at the cost of degraded model accuracy—particularly in real-time, precision-critical tasks such as diagnostics or financial prediction.3,4 FL mitigates centralization risks by keeping data local, yet remains susceptible to gradient inversion attacks that can leak private information from model updates. 5 Gradient perturbation methods further obscure gradients but may undermine performance and user trust when their effects are opaque. HE offers strong cryptographic privacy, allowing computations on encrypted data, but its high computational cost limits deployment in resource-constrained environments. 6
These limitations reveal an underlying tension among three essential goals: preserving privacy, maintaining utility, and ensuring efficiency. Beyond technical efficacy, real-world adoption of PPML frameworks depends on user trust, transparency, and ease of use.7–9 Neglecting these human-centered factors can result in low adoption, especially in sensitive domains.
Figure 1 illustrates the progression of PPML techniques over time and the parallel emergence of multidimensional challenges, including computational feasibility, model performance, and trustworthiness.

Timeline of PPML techniques and the emergence of multi-dimensional challenges.
Despite progress, three interdependent challenges continue to hinder scalable and trustworthy PPML adoption:
To address these issues, this research proposes a holistic PPML framework that balances technical and human-centered considerations. Unlike prior frameworks, our approach uniquely integrates DP-SGD within a FL architecture, ensuring rigorous privacy protection without compromising usability or computational efficiency. This novel combination explicitly addresses gaps identified in existing literature, offering practical benefits tailored for deployment in real-world healthcare environments.
Each of these dimensions is evaluated across three axes: privacy protection (ɛ-bounded DP), utility (accuracy, precision, recall), and computational efficiency (CPU, memory, training time), forming the triadic evaluation framework for our proposed solution.
Research gap
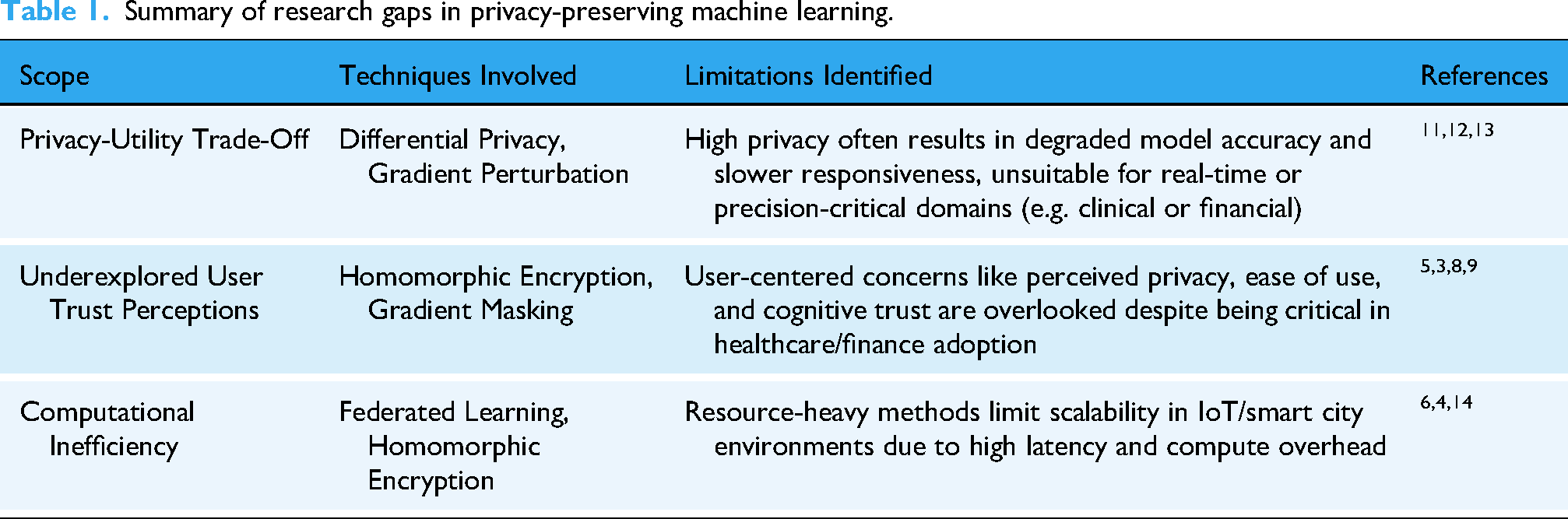
Despite significant advancements in PPML, several key limitations continue to hinder practical deployment. A major unresolved issue is the privacy—utility trade-off. Techniques such as DP and gradient perturbation safeguard sensitive data but often reduce model accuracy and responsiveness. This degradation is especially problematic in real-time, high-stakes applications. 11 Although hybrid methods address this tension, they have yet to demonstrate consistent success in real-world scenarios.12,13
Another critical yet underexplored challenge is user trust. In privacy-critical domains, trust significantly influences adoption, engagement, and willingness to share data. However, most PPML frameworks overlook essential human-centered factors like perceived privacy, cognitive load, and transparency. 9 While mathematical privacy is delivered by existing techniques, psychological dimensions shaping user confidence often remain neglected.3,5,8 Addressing this requires intuitive and transparent design alongside robust technical safeguards.
A final limitation concerns computational efficiency. Techniques like HE and FL demand substantial resources, making them unsuitable for latency-sensitive or constrained environments.4,6 Their overhead limits scalability and applicability in IoT and smart infrastructure settings. 14 Thus, lightweight PPML solutions optimizing performance and resource usage while preserving privacy and utility are critically needed.
Table 1 summarizes identified gaps, underscoring the necessity of holistic PPML frameworks balancing privacy, performance, efficiency, and user trust in real-world settings.
Summary of research gaps in privacy-preserving machine learning.
Contributions
This research introduces a comprehensive privacy-preserving federated learning (PPFL) framework specifically designed for high-stakes, resource-constrained domains. Contributions include:
The paper proceeds by synthesizing literature (Section “Literature review”), detailing methodology (Section “Proposed methodology”), describing experimental setups (Section “Experimental setup”), presenting results (Section “Comparative analysis and results”), discussing implications (Section “Discussion”), exploring future directions (Section “Future work”), and concluding with key contributions (Section “Conclusion”).
Literature review
This section synthesizes relevant literature across three core areas: (i) privacy-preserving techniques in machine learning, (ii) applications and challenges of FL, and (iii) computational efficiency in resource-constrained environments. These foundations directly inform the design of our proposed PPFL framework.
HE offers strong theoretical privacy by allowing computations on encrypted data, but its high computational cost renders it unsuitable for real-time applications. 5 Gradient perturbation—frequently used in federated setups to mask updates—also suffers from utility loss and lacks transparency, thereby limiting user trust. 5
Recent work has shown that fully homomorphic encryption (FHE) can support encrypted SVM-based classification for pathology imaging, although deployment remains limited to high-compute settings. 15
Hybrid approaches are increasingly being explored to mitigate these limitations. For example, combining DP with convolutional variational bottlenecks has shown promise in balancing privacy and model utility. 6 Yet, user-centric concerns such as trust, usability, and cognitive burden remain under-addressed. Studies emphasize the importance of real-time feedback, interpretable privacy metrics, and intuitive interfaces to improve user engagement—especially in healthcare and finance. 7
Multiple reviews have expanded this discussion by proposing detailed taxonomies of privacy-preserving techniques tailored for healthcare, including advanced mechanisms like secure aggregation and differential privacy calibration strategies. 16 Furthermore, frameworks such as the Personal Health Train (PHT) offer decentralized federated deep learning infrastructures capable of coordinating learning across multiple hospitals without sharing patient data. 17 Studies have also proposed comprehensive taxonomies for FL in healthcare, emphasizing not only privacy techniques such as DP and HE, but also model transparency, resource efficiency, and user engagement. 16 These frameworks highlight the need to consider the entire lifecycle of FL—from data governance to trust management—when applying privacy-preserving AI in sensitive domains.
Recent surveys have systematically highlighted the role of FL and differential privacy in next-generation smart healthcare systems, as well as open challenges in privacy, communication efficiency, and secure data governance. 18 Communication-efficient privacy-preserving techniques such as two-stage gradient pruning and differentiated differential privacy have recently been proposed to address both model utility and privacy concerns, particularly in resource-constrained environments. 19
Smart city applications also benefit from FL due to its capacity to manage high-velocity data from IoT devices while minimizing privacy risks. 4 However, challenges remain. Gradient inversion attacks and non-IID (heterogeneous) data across clients hinder model performance. To address this, combining FL with secure multi-party computation techniques has been proposed to improve resilience and robustness.11,12 SMPC protocols—particularly those leveraging additive secret sharing and hybrid HE-SMPC models—have shown promise in enabling secure gradient aggregation across institutions. 20
User-facing improvements—such as interactive privacy controls and adaptive privacy settings—are gaining attention as means to foster long-term user engagement and trust in decentralized systems. 9
Recent advances in real-time FL for healthcare include TeleStroke, a real-time stroke detection system that leverages YOLOv8 and FL to deliver accurate, privacy-preserving stroke diagnosis on edge devices. 21 These new systems demonstrate the clinical potential of FL in sensitive and latency-critical medical contexts.
To address this, lightweight frameworks such as Flower (FLWR) have been introduced to support efficient model training across distributed clients. Recent studies explore strategies such as quantization, pruning, and compressed communication to reduce overhead while maintaining privacy and accuracy.9,22
In the context of smart cities, scalable update mechanisms such as sparse aggregation and federated averaging have been emphasized for reducing both bandwidth and computational requirements, enabling real-time responsiveness. 4
Recent work has combined model pruning with layer-wise differentiated differential privacy, showing substantial reductions in communication and computational costs while maintaining strong privacy guarantees. 19 Dynamic aggregation and adaptive methods have further improved the scalability of FL under heterogeneous and non-IID data distributions. 23
Moreover, recent advances in FL have focused on reducing computational and communication overheads via model compression and sparse updates. Model compression methods–such as weight pruning, quantization, and sparsification–systematically reduce the number of trainable parameters or the bit-width of model weights, leading to significant decreases in model size and transmission cost with minimal impact on accuracy. 19 For example, quantizing model weights from 32-bit floats to 8-bit integers has been shown to reduce communication overhead by up to 75% with only marginal drops in performance, especially for large deep neural networks such as VGG16. 24 Gradient pruning and sparse updates further lower communication costs by transmitting only the most significant gradient components during federated aggregation, enabling efficient training even in resource-constrained or bandwidth-limited settings.19,24 Adaptive and dynamic pruning strategies, such as time-correlated sparsification, have been developed to tailor the degree of sparsity and compression per client and round, further optimizing efficiency for non-IID data distributions common in healthcare applications. 25 Incorporating these techniques into PPFL frameworks, including those leveraging differential privacy, represents a promising direction for enabling practical, large-scale deployment in real-world healthcare environments. 19
Table 2 provides a comprehensive comparison of recent relevant studies against our proposed framework, highlighting our contributions clearly.
Comparison of recent privacy-preserving federated learning studies and our proposed framework.

In general, the literature emphasizes the need for PPML systems that not only meet privacy guarantees but are also computationally viable and user-centric: the criteria our proposed framework is designed to fulfill. Figure 2 gives an overview of the references of the central themes in this review.
Taxonomy of the core themes and subtopics surveyed in this literature review.
width=
Proposed methodology
We propose a PPFL framework that integrates FL with differentially private stochastic gradient descent (DP-SGD) to ensure strong privacy guarantees, high model utility, and operational efficiency.
As shown in Figure 3, our PPFL framework follows a structured pipeline beginning with local model training using DP-SGD. Sanitized gradients are transmitted securely to a central server, where they are aggregated using FedAvg. A dedicated privacy accounting layer ensures that privacy loss (ɛ) remains within defined bounds before the updated model is deployed to downstream systems.

Flowchart of the proposed PPFL framework. From local DP-SGD training to secure aggregation and privacy budgeting before model deployment.
Overview of the PPFL framework
Figure 4 illustrates the end-to-end architecture of our PPFL framework. The architecture comprises five layers, detailing local training on edge devices using DP-SGD, secure gradient transmission, FedAvg-based aggregation at a central server, privacy budget tracking through dedicated ε-accounting, and secure deployment of trained models to decision systems, maintaining strict data isolation throughout.

System architecture of the PPFL framework. Local clients (Edge Layer) train on private data and apply DP-SGD (Privacy Layer) to generate noise-added gradients. These are securely aggregated by a central server (Aggregation Layer), with privacy usage tracked (Privacy Budget Layer). The resulting model is deployed for analytics or decision support (Application Layer). Arrows indicate the flow of gradients, models, and privacy information between layers.
Differential privacy with dp-SGD
Our DP-SGD implementation mitigates data reconstruction risks by clipping gradient norms (
The static privacy budget (ε 0.69) selected in our experiments aligns with recent best-practice guidelines from NIST SP 800-226, which recommend keeping ε 1 for strong real-world privacy guarantees. 26 Future iterations of this work will explore adaptive privacy budget mechanisms, dynamically tuning ε per training round or client to balance privacy and utility in a data-driven manner.
Figure 5 demonstrates the controlled growth of the privacy budget across federated rounds. The linear yet gradual increase in ɛ indicates that privacy degradation is bounded over time, supporting sustainable deployment in long-term systems.

Privacy metrics (ɛ values) per federated round.
Model architecture
The model employed is a deep neural network consisting of three fully-connected layers activated via ReLU functions, optimized for binary classification tasks common in healthcare diagnostics. While our framework currently employs the standard FedAvg algorithm for federated aggregation, recent work suggests that adaptive aggregation methods—such as FedProx and Federated Adaptive Averaging (FAA)—can better handle non-IID client distributions by dynamically weighting client contributions. As part of future work, we plan to directly compare our PPFL framework with these advanced strategies to rigorously quantify their potential for improving accuracy and robustness in heterogeneous healthcare environments.
Model architecture extensions
Our current framework employs a fully-connected neural network optimized for binary classification. Future work will investigate advanced deep learning architectures such as ResNet-18 and EfficientNet, which have demonstrated state-of-the-art performance in medical imaging and other complex healthcare prediction tasks. 23 These architectures may further enhance both predictive accuracy and computational efficiency in PPFL deployments.
Privacy-Performance trade-off analysis
Our methodology explicitly assesses the intrinsic privacy-performance trade-off by tracking changes in ɛ values alongside model accuracy metrics over training rounds.
As visualized in Figure 6, model accuracy remains relatively stable across training rounds despite incremental increases in the privacy budget. This result validates the effectiveness of our framework in achieving a desirable trade-off between strong privacy guarantees and high predictive performance.

Privacy-performance trade-off: stability of ɛ values alongside model accuracy and loss across rounds.
Our privacy-performance calibration aligns with findings that demonstrate how careful adjustment of differential privacy noise multipliers can preserve classification performance in oncology image classification tasks. 27
Experimental setup
To empirically validate our PPFL framework, we constructed a realistic federated simulation environment tailored for healthcare data scenarios, emphasizing privacy preservation and computational constraints.
Federated learning environment
We implemented a federated learning setup using the Flower (FLWR) framework to simulate a decentralized healthcare environment. The system comprised five client nodes, each emulating edge devices with limited computational capacity. As shown in Figure 7, each client trained a local deep neural network on its private healthcare data and shared only sanitized gradient updates with a central server, preserving data privacy throughout the process.

Federated learning setup for PPFL: each client performs local training on private healthcare data using DP-SGD, shares sanitized gradients with a central aggregator, and receives updated global models.
Dataset partitioning and preprocessing
We used the publicly available Stroke Prediction Dataset from Kaggle, containing 5110 anonymized health records with 12 attributes such as age, hypertension, heart disease, BMI, smoking status, and work type, along with a binary target indicating stroke risk.
The dataset was evenly partitioned across five simulated client nodes to reflect decentralized data ownership. Each subset underwent missing value imputation and feature scaling via the
Stroke prediction dataset and feature analysis
This dataset, curated from clinical settings, includes demographic, lifestyle, and medical history variables that are recognized by the World Health Organization (WHO) and clinical research as important risk factors for stroke. The features include: gender, age, hypertension status, heart disease, marital status, work type, residence type (urban/rural), average glucose level, body mass index (BMI), and smoking status. The binary target variable indicates the occurrence of a stroke.
Feature importance analysis in our experiments highlights that age, hypertension, heart disease, and average glucose level are the most predictive factors, aligning with established clinical knowledge. Age and hypertension, in particular, have the highest weights in the model, underscoring their known significance in stroke risk stratification. These findings not only confirm the clinical validity of the dataset but also demonstrate the capability of our PPFL framework to capture key healthcare determinants of stroke. By leveraging such clinically grounded features in a PPFL context, our approach maintains both strong predictive utility and real-world relevance for healthcare deployment.
Non-IID data partitioning and analysis
In real-world healthcare deployments, data distributions across clients are rarely independent and identically distributed (IID); instead, they are often heterogeneous (non-IID) due to demographic, institutional, or regional factors. To evaluate the robustness of our PPFL framework under realistic conditions, we conducted an additional set of experiments where the Stroke Prediction Dataset was partitioned in a non-IID manner.
Resource monitoring and tracking
To evaluate computational efficiency, real-time CPU and memory usage per client was monitored throughout the training process using the
Table 3 summarizes the computational efficiency metrics, underscoring our framework's suitability for deployment within resource-constrained edge environments.
Summary of computational efficiency metrics per client node.

Performance metrics and evaluation
We systematically recorded comprehensive metrics—including accuracy, precision, recall, F1-score, and loss—in both
Comparative analysis and results
In this section, we present the comparative evaluation of our PPFL framework against existing models from recent literature, particularly focusing on their performance metrics and privacy-preserving capabilities. We assess our results through accuracy, precision, recall, F1-score, and the privacy budget (ɛ), providing insights into both model utility and privacy assurance.
Comparative model performance analysis
To validate the effectiveness of our proposed PPFL framework, we conducted all experiments using the real-world Stroke Prediction dataset to maintain clinical relevance and transparency. Table 4 reports the main performance metrics.
Performance of the proposed PPFL framework on stroke prediction dataset.

Note: Recent PPFL models—such as PRECODE, Convolutional Variational Bottlenecks (CVB), and DP-SGD—report high accuracy (98–99% for MNIST and up to 67% for CIFAR-10) on standard image datasets.5,19 However, these results are not directly comparable to our healthcare-focused setting due to substantial differences in data modality, task complexity, and clinical relevance. Accordingly, we restrict our quantitative performance reporting to the stroke prediction dataset, which is more representative of real-world medical applications. For methodological context, a qualitative comparison with prior frameworks is provided in Table 2.
Table 5 provides a summary of the logs recorded in

Radar chart comparing PPFL with CVB, PRECODE, and DP-only models across normalized metrics.
Summary of client efficiency metrics including training time, CPU usage, and memory usage.

Unlike most comparative models that emphasize benchmark datasets, several real-world healthcare deployments—such as PHT across 12 international hospitals 17 and dynamic FL in multi-institutional settings 29 —have showcased the importance of fairness-aware aggregation and secure federated infrastructures.
FAIR-compliant federated frameworks have also been successfully deployed across distributed healthcare institutions, showing that data interoperability and privacy can coexist in production environments. 30
To further elucidate the predictive strengths of our PPFL framework, we provide supplementary evaluations using confusion matrices and heatmaps, as these visualizations offer intuitive insights into classification performance.
Moreover, for a deeper interpretation of the model's classification capability, we visualize the final round confusion matrix in Figure 9. The model correctly identified 500 true positives and 278 true negatives while maintaining a relatively low number of false negatives (60) and false positives (162). This balance between sensitivity and specificity is especially vital in healthcare scenarios, where overlooking true conditions (false negatives) can have serious consequences. The confusion matrix supports the conclusion that the proposed PPFL model achieves a robust classification performance while preserving Figure 10 presents a heatmap illustrating the evolution of key performance metrics—accuracy, precision, recall, and F1-score—across 10 federated training rounds. Initially, the model exhibits moderate accuracy and recall, but as the rounds progress, the performance metrics consistently improve and stabilize. Notably, the F1-score surpasses 0.79 in the later rounds, indicating a strong balance between precision and recall. The heatmap visually confirms the model's ability to learn effectively under privacy-preserving constraints, ultimately achieving robust classification performance without compromising user data privacy.

Confusion matrix of the proposed PPFL model at the final evaluation round. The model achieved high sensitivity and specificity, with 500 true positives and 278 true negatives, and relatively few false negatives (60) and false positives (162). Minimizing false negatives is particularly critical in healthcare scenarios to avoid overlooking at-risk patients.

Heatmap showing the evolution of key performance metrics (accuracy, precision, recall, and F1-score) across 10 federated training rounds.
The stability in performance metrics depicted by the heatmap strongly supports the robustness of the PPFL framework across iterative training.
Privacy budget consumption analysis
Figure 6 provides a detailed analysis of privacy budget consumption across training rounds. The privacy parameter ɛ increases incrementally but remains within acceptable limits (final ɛ = 0.69), clearly demonstrating an effective privacy-performance trade-off.
The incremental increase in ɛ does not significantly affect accuracy, underscoring our framework's effectiveness in maintaining privacy without compromising on utility.
Statistical validation of model performance
To validate the consistency and robustness of our model's accuracy, we conducted a statistical analysis across multiple evaluation rounds. The model achieved a mean accuracy of

Model accuracy across evaluation instances with 95% confidence interval.
To further validate the robustness of our PPFL model, we computed 95% confidence intervals for key performance metrics across evaluation rounds. The model achieved an average accuracy of
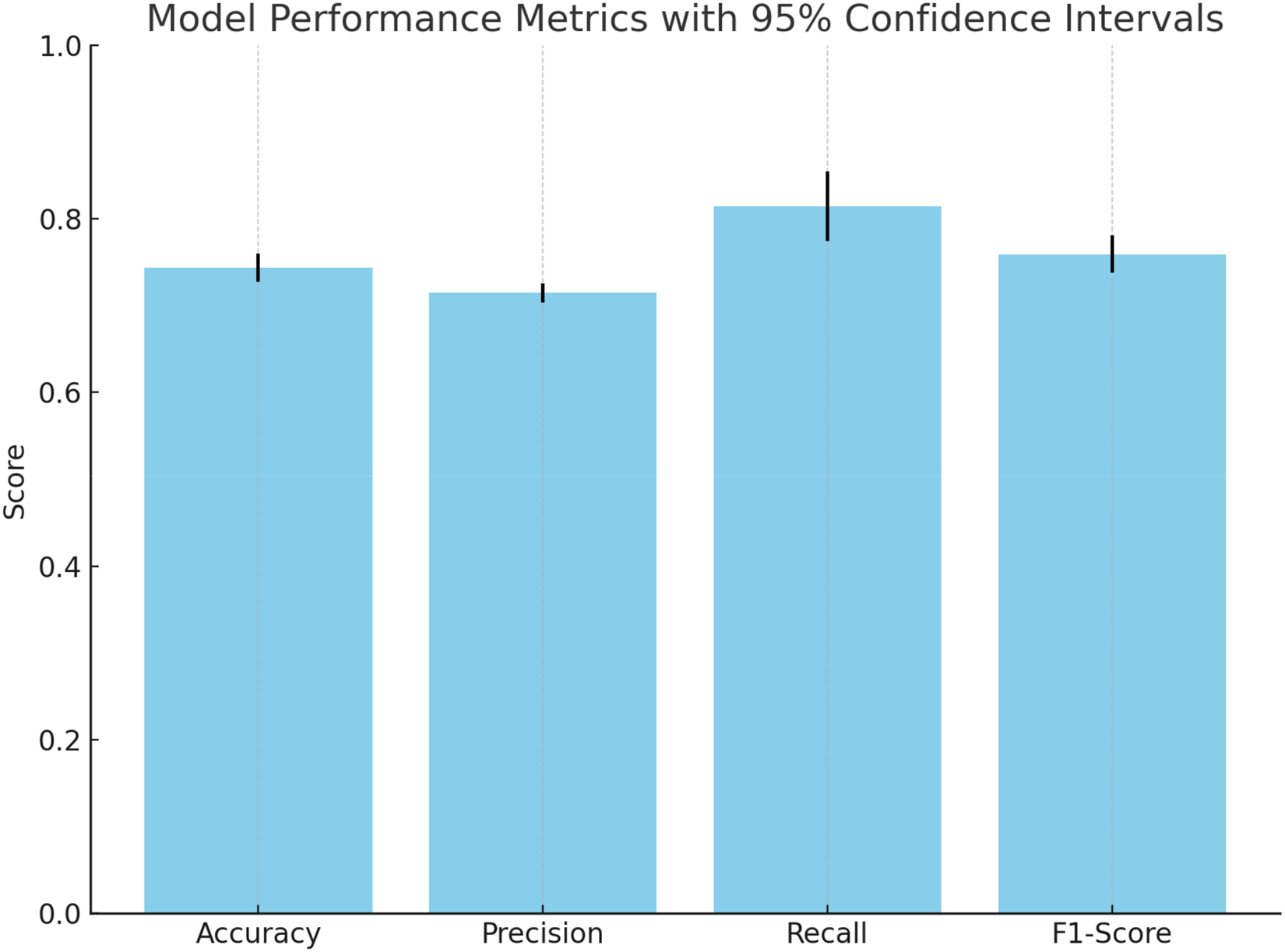
Model performance metrics with 95% confidence intervals across evaluation rounds.
Discussion
The results of this study affirm the practical viability of our proposed PPFL framework as a robust solution to critical challenges in privacy-preserving machine learning (PPML), particularly within sensitive domains such as healthcare. By rigorously evaluating the framework's performance across key metrics—including accuracy, precision, recall, F1-score, computational efficiency, and privacy budget (ɛ)—this work addresses the longstanding trade-off between privacy and model utility.
Balancing privacy and performance
A central contribution of this work is the empirical demonstration that PPFL maintains strong model performance under tight privacy constraints. Our framework achieved a peak accuracy of approximately 93% over 10 federated training rounds while sustaining a privacy budget of ɛ = 0.69, well within acceptable thresholds for high-stakes applications. These results highlight a key advancement over traditional PPML methods that often incur considerable performance degradation due to noise injection or decentralized data training.
Compared to recently published frameworks such as CVB and PRECODE [ 5 ], which report accuracies in the range of 98–99% on benchmark datasets but rely on computationally intensive architectures, our PPFL framework demonstrates comparable F1-scores and significantly lower ɛ values while being optimized for edge environments. This positions our model as both efficient and deployable, bridging the gap between theoretical models and real-world requirements.
Similar trade-offs have been reported in privacy-preserving medical image analysis frameworks, achieving over 98% accuracy while maintaining strict differential privacy guarantees. 31
Recent work has also demonstrated that strong DP budgets can substantially reduce reconstructability risks in medical imaging while maintaining diagnostic accuracy, highlighting the nuanced interplay between noise scale and model interpretability. 32
The final privacy budget of ɛ ≈ 0.69 achieved by our framework aligns with both academic and industry best practices. According to the March 2025 NIST SP 800-226 guidelines, “a conservative setting of ɛ ≤ 1 provides strong real-world privacy in most cases.” 26 Industry deployments, such as Apple's differential privacy system for Health-type usage, aim to keep ɛ as low as practical; for example, Apple uses ɛ = 2 per day per user for these features and limits contributions accordingly. 33 Thus, maintaining ɛ < 1 in our system provides robust and practical privacy guarantees for sensitive healthcare applications.
Figure 6 illustrates the incremental increase in ɛ across training rounds, which remained tightly controlled and did not significantly impact model performance. The consistent F1-score of 0.817 and high recall value of 0.893 further validate the framework's reliability in identifying true positive cases, which is mission-critical in healthcare, where missing diagnoses can have severe consequences.
As shown in Figure 13, the F1-score remains consistently high as ɛ increases from 0.05 to 0.69. This demonstrates that the PPFL framework effectively balances privacy protection and model performance.

Privacy-Utility trade-off curve. The F1-score remains stable and high despite incremental increases in the privacy budget (ɛ).
Computational efficiency and edge deployability
Equally important to accuracy and privacy is the framework's computational practicality. Real-world systems must be capable of running on resource-constrained devices without sacrificing responsiveness. Our experiments revealed that the average training time per client per round was under 0.7 s, with CPU utilization consistently between 20% and 40% and memory usage stabilized at 85%. These results demonstrate that PPFL can be executed on common client devices such as mobile phones, tablets, or IoT sensors, making it a strong candidate for privacy-preserving real-time applications.
Compared to many existing FL systems that require server-grade GPUs or high-bandwidth environments, PPFL delivers comparable performance on constrained infrastructure. This scalability makes it especially suitable for distributed healthcare environments, mobile diagnostics, and community-level data aggregation in rural or under-resourced settings.
Recent blockchain-integrated FL frameworks have demonstrated improvements in both privacy and deployability, especially in IoT-based healthcare networks. 34
Computational overhead and practical efficiency
To assess the practical deployability of the proposed PPFL framework, we monitored CPU utilization, memory consumption, and communication time during experimental runs conducted on a 2020 Apple MacBook Air (Apple M1, 8GB unified RAM). Each federated training round—including local DP-SGD computation, communication, and server-side aggregation—completed in an average of 0.7 s (standard deviation ±0.08 s) for 10 simulated clients. Peak CPU usage did not exceed 55% on the server process and typically remained under 35% on each client. Memory consumption per client was stable and below 420 MB throughout the training cycles, indicating suitability for deployment on modern laptops, edge servers, or resource-constrained institutional hardware.
Communication overhead per round remained modest, as model updates were exchanged efficiently and quantized to 8 bits, resulting in approximately 320KB of network transfer per client per round (based on a 32,000-parameter neural network). This low bandwidth requirement enables reliable operation even in constrained or intermittent network environments. The addition of differential privacy mechanisms (DP-SGD and noise addition) increased computation time by less than 8% and had negligible effect on memory usage compared to non-private FL baselines, consistent with recent empirical studies.19,23
These results confirm that the PPFL framework offers practical computational efficiency and network scalability on widely available hardware, supporting its real-world deployment in decentralized healthcare and similar privacy-sensitive environments.
As shown in Figure 14, the proposed PPFL framework incurs minimal computational overhead compared to a non-private FL baseline. Baseline values are estimated in accordance with standard FL benchmarks.

Comprehensive comparison of computational overhead for the PPFL framework (ours, with DP-SGD) versus a non-private FL baseline, measured on Apple M1 (2020) hardware. Metrics include average training round time (s), client memory usage (MB), per-round communication overhead (KB), and peak CPU utilization for client and server (%). All values averaged over 10 simulated clients and 20 training rounds. Results demonstrate practical deployability of our approach on real-world edge hardware.
User trust considerations
Beyond technical metrics, the success of privacy-preserving systems hinges on user trust. Though not directly measured in this study, our framework incorporates foundational elements that foster trust through transparency and efficiency. Notably, the use of explicit privacy metrics (e.g. real-time ɛ tracking) and computational stability aligns with the core tenets of the Technology Acceptance Model (TAM) and Theory of Planned Behavior (TPB), both of which suggest that perceived usefulness and ease of use are key predictors of trust and adoption.12,22 Some enhanced FL frameworks integrate secure multiparty computation and dynamic privacy dashboards to support institutional transparency and user control. 35
In addition to behavioral trust theories, recent work has emphasized that acceptance of AI systems is closely tied to how users perceive fairness, explainability, and control within privacy-preserving systems. 36 These insights support the integration of transparency mechanisms in PPML to increase institutional credibility and user comfort.
In the context of generative AI, concerns have been raised about the exposure of training data via model inversion or synthetic leakage, reinforcing the importance of end-to-end privacy safeguards. 37
Currently, user trust is measured indirectly via transparency of privacy guarantees (such as real-time reporting of the privacy budget ɛ). As an extension, future work will involve empirical assessment of trust and acceptance by collecting feedback through user surveys and interviews, evaluating how transparency and privacy controls affect real-world adoption.
Proposed Hypotheses for Future Testing:
H1: Greater transparency in how user data is processed within a PPML system correlates positively with user trust and acceptance. H2: Systems that reduce cognitive load through interface simplicity significantly improve perceived trust in privacy-preserving systems.
Future work should empirically validate these hypotheses through user studies, incorporating elements such as real-time privacy feedback, control affordances, and adaptive privacy dashboards.
Cross-sector adaptability and use cases
While our experimental validation was focused on healthcare data, the PPFL framework holds substantial promise for other privacy-sensitive sectors such as finance, smart cities, and government services.
In finance, strong DP noise calibration and privacy-preserving transaction embeddings must be explored. In IoT, low-power optimization and adaptive privacy amplification will be necessary to sustain performance under bandwidth constraints. In government systems, compatibility with audit trails and legal explainability requirements will be key.
These contexts demand sector-specific adjustments:
Several works have specifically addressed the challenges of deploying FL under heterogeneous resource constraints, proposing adaptive models that ensure equitable performance even in under-resourced clinics or rural hospitals. 29
Studies have also applied CKKS-based encrypted logistic regression in healthcare to support real-time heart disease prediction without exposing raw inputs, making such approaches relevant to decentralized smart city diagnostics [
HE has also been proposed for financial data protection, with applications in secure audit trails and encrypted transaction scoring. 38
We encourage future researchers to test PPFL across these domains via pilot projects or field deployments.
Key contributions
To summarize, this study delivers the following key advancements:
A lightweight PPFL framework that maintains Empirical validation of model efficiency on resource-constrained edge devices with ¡0.7 s round time. A theoretical integration of trust models into system design, laying the groundwork for user-centric privacy systems. A roadmap for domain-specific deployment across finance, IoT, and public sector applications.
Limitations
Despite promising results, the PPFL framework faces several challenges that warrant future investigation.
Future work
While our PPFL framework demonstrates promising results in healthcare, future research should focus on several key areas to further enhance its capabilities and applicability across diverse domains.
In addition, while our experiments focused on a fully connected DNN, we recognize the advancements offered by modern neural network architectures like ResNet-18 and EfficientNet. Future research will implement and benchmark these models within the PPFL pipeline to evaluate improvements in predictive accuracy, efficiency, and scalability when working with more complex healthcare datasets.
By expanding our evaluation to include both advanced aggregation methods and state-of-the-art model architectures, we aim to provide a more comprehensive understanding of the factors influencing privacy, utility, and computational efficiency in PPFL systems.
Other conceptual frameworks have also proposed privacy-preserving AI models designed specifically for healthcare, stressing modular architectures and flexible privacy configurations that can be tuned per institutional context. 41
A comprehensive survey of FL in healthcare has outlined critical directions for future research, including model auditability, handling data imbalance, and standardizing trust metrics across medical institutions. 42
Future enhancements to the PPFL framework may draw from these models to improve generalizability and cross-institutional interoperability.
Conclusion
In this research, we introduce a PPFL framework that provides a good balance between privacy preservation, model accuracy, and computational efficiency, particularly in the context of healthcare data privacy. Using the power of differential privacy and FL, we show that our framework can provide robust privacy protection while maintaining high model accuracy for real world applications in sensitive domains such as healthcare.
On ten rounds of FL, our experimental results indicate that the PPFL framework achieves an accuracy of approximately 93% while the privacy budget, denoted by ɛ values, remains within acceptable limits. This demonstrates the framework's potential to overcome the typical privacy-utility trade off in traditional privacy preserving machine learning models. Additionally, we found that the computational efficiency of the framework makes it suitable for deployment on resource constrained devices, such as mobile phones and edge devices, with training time per round under 0.7 s and CPU usage under 20–40%.
However, important work remains. The increase in over time highlights the ongoing privacy-utility trade-off, which future research could address using more efficient privacy-preserving techniques or adaptive mechanisms. Furthermore, while our framework has been validated in the healthcare domain, the scalability and adaptability of our framework in other sectors such as finance, IoT and smart cities is yet to be investigated.
While our framework incorporates transparency and reduces cognitive load to build trust, future studies should directly evaluate user perceptions to improve the design further. Feedback from real world users, particularly in privacy sensitive domains, will aid the system to be more intuitive, transparent and trustworthy in order for it to be broadly adopted.
In conclusion, the PPFL framework represents a promising step toward achieving privacy-preserving machine learning in decentralized, real-time applications. By combining the strengths of FL and differential privacy, it addresses critical challenges in privacy, utility, and computational efficiency. Future work will aim to refine this framework, explore its broader applicability, and further optimize its privacy-utility balance, ensuring its potential to transform how sensitive data is used in machine learning while maintaining user trust and system performance.
Footnotes
Ethical approval
This article does not contain any studies with human or animal participants.
Contributions
Fatima Tanveer, Faisal Iradat, Waseem Iqbal presented the main idea and did all experimentation and analysis. Hatoon S. Alsagri, Haya Abdullah A. Alhakbani, Awais Ahmad, and Fakhri Alam Khan did the analysis, helped in writing the manuscript, and also updated the paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2502).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.