
Abstract
Keywords
Introduction
Opioid use disorders (OUD) and opioid-related overdose deaths are a public health crisis in the United States. The prevalence of OUD and mortality from opioid overdose have increased rapidly since the early 1990s, partly because physicians were encouraged to aggressively treat pain, treating it as the “fifth vital sign.” 1 Prescription opioids are one of the most effective treatments for acute pain, though the most commonly cited reason for initial opioid use in patients who develop OUDs is chronic pain.2,3 In 2014, approximately 12.5 million Americans had OUD, and prescription opioid overdoses caused approximately 52 Americans to die each day, accounting for 18,893 deaths annually. 4 Since 2015, Healthcare organizations have introduced initiatives to control opioid prescribing. 5 However, prescription opioid-related overdose fatalities have remained significantly high, with 17,029 deaths in 2017. 6 In addition, patients with OUD are more likely to become polysubstance abusers and to experience psychiatric disorders, disability, and various infectious diseases, including hepatitis C and human immunodeficiency virus disease.7–9 OUD is also associated with a high cost for the health care system. 2 Effectively identifying individuals with, or at risk for, OUD may help to reduce opioid-related morbidity, mortality, and economic burden the USA healthcare system.
Healthcare providers have been strongly encouraged to perform risk evaluation for OUD universally when prescribing opioids for pain management. 10 Screening and diagnostic tools have been developed to help clinicians identify patients who are currently misusing or dependent on opioids.11,12 However, screening may not identify all at-risk patients, as some may be reluctant to admit a history of misuse or addiction. In addition, the implementation of routine screening in practice has proven a challenge due to time constraints, competing demands, and other clinical priorities.13–15 Typically, diagnoses recorded in the electronic health record (EHR) utilize the International Classification of Diseases (ICD) codes; ICD codes for OUD submitted by either a coder or a clinician, unless the primary diagnosis for a visit, are unlikely to impact reimbursement levels in most settings; it is not surprising that the OUD diagnosis is sometimes not recorded as ICD even when presents. In addition, using ICD codes may misclassify OUD and may not distinguish OUD for prescription opioids and illicit drugs. 16 Instead, patient’s problems, conditions, diagnoses, and treatment plans are often more completely recorded in clinical notes. That information can be effectively extracted using natural language processing (NLP). NLP is a computerized technique that automatically extracts information of interest from unstructured clinical notes and converts that information to a structured format for further analysis. 17
Recent studies showed that NLP could identify 30–50% more patients with clinical evidence of prescription OUD than ICD coded data.18,19 Even when a clinician detects some behaviors indicative of OUD, they may not add the diagnosis codes to the patient’s record, thereby not passing on important information to other care providers. As such, NLP-based OUD identification may be an effective supplementing patient screening, patient medical record manual review, or ICD-coded data and can certainly add value by identifying patients that these other methods do not pick up. In this study, we developed NLP algorithms that identify OUD from clinical notes in patients prescribed prescription opioids. Then we formally evaluated NLP algorithm performance against the gold standard (manual review). The concordance between ICD-coded OUD and NLP-identified OUD was also explored.
Methods
Study setting
The study was conducted at the Medical University of South Carolina (MUSC), an academic medical science center with inpatient, outpatient, and emergency facilities serving Charleston, South Carolina, and surrounding areas. MUSC initiated the EpicCare EHR system (Epic Systems Corp., Verona, WI) for outpatient care in 2012 and for inpatient care in 2014. A Research Data Warehouse (RDW) copies the Epic data and serves as the data repository for clinical research. For this study, we used patient medical records from the RDW. A multidisciplinary team with expertise in addiction, pain management, statistics, and medical informatics conducted this study.
Data source
To develop an NLP pipeline to identify OUD from clinical narratives, we used clinical notes from adult non-cancer patients who received chronic opioid therapy (COT) from 2013 to 2018. COT was operationally defined as having received at least a 70-day supply of prescription opioid medication within any 3 months.
20
Opioid medications include prescription analgesics administered transdermally or orally. Once COT patients were identified, all of their medical records were used for analyses, including data recorded outside of the COT period. Source data included various clinical narratives, such as progress notes, consultant notes, outpatient visit notes, orders, and discharge summaries. Patient demographic and ICD-coded diagnosis data were also extracted. The study subject ID linked patient source documents and structured demographic and clinical data across each individual’s records for analysis. Of 13,654 eligible patients, 10,218 (75%) patients were randomly selected as a training set to develop an NLP lexicon and NLP algorithms. The remaining 3436 patients (25%) were used as a test dataset to evaluate NLP algorithm performance (Figure 1). Patient selection.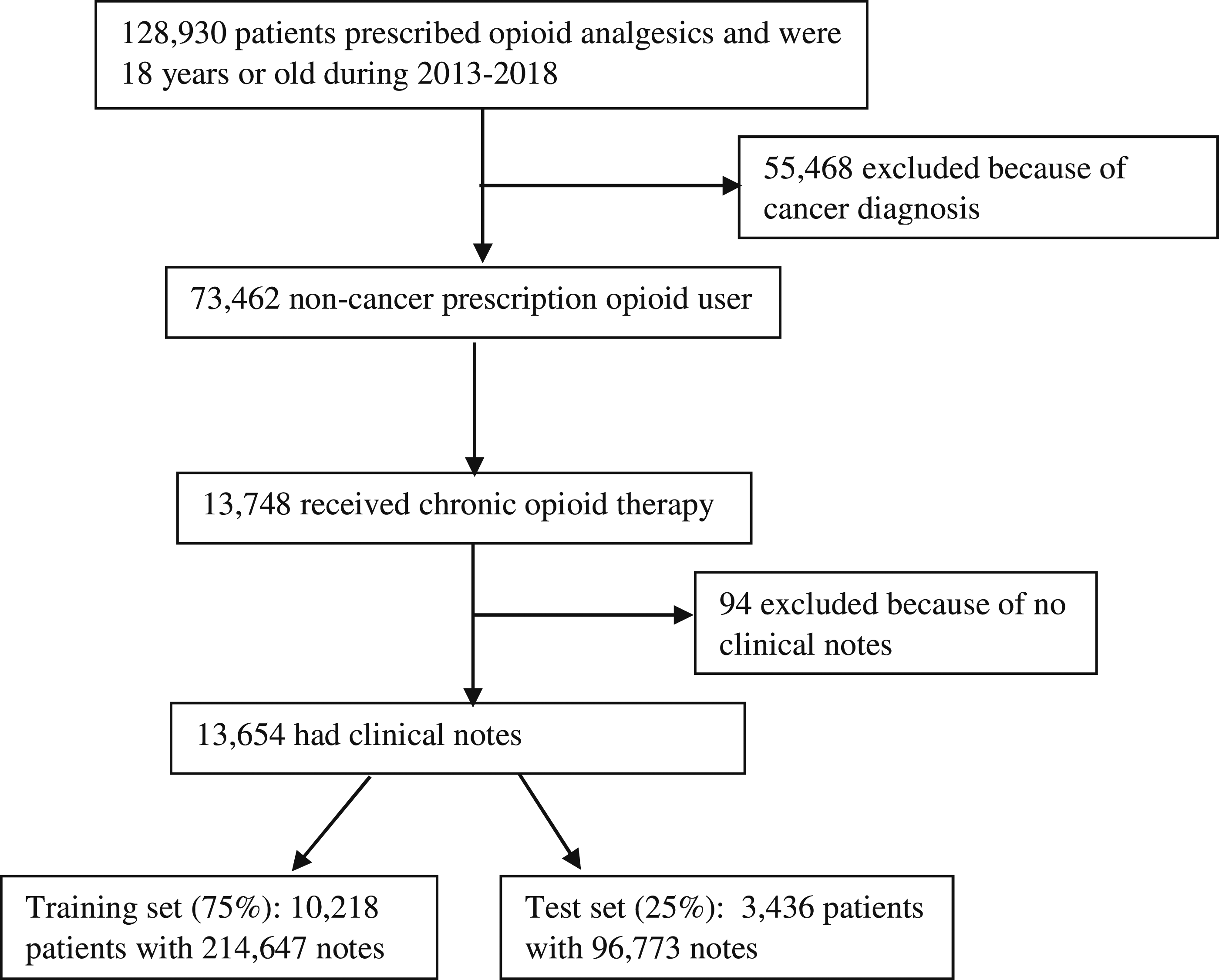
NLP software
We used NLP software (Linguamatics I2E version 5.4, Cambridge, United Kingdom) to index, parse, and query each clinical note. The I2E NLP software applies standard medical terminology concept-based indexing techniques and performs named entity recognition from text documents. Then queries retrieve information for reports, meeting a user-defined set of criteria through a user-friendly interface to define syntactic and semantic representations. 21 Our previous work using this NLP software demonstrated high accuracy approaches identifying under-coded healthcare issues from clinical notes. In previous work using the same NLP software, we abstracted numerator data for the Group Physician Reporting Option (GPRO) quality measure for fall risk assessment. The NLP algorithm identified 62 (of 144) patients for whom a fall risk screen was documented only in clinical notes and, thus, was not ICD coded. A manual review confirmed 59 patients as true positives and 77 patients as true negatives. That NLP approach scored 0.92 for precision, 0.95 for recall, and 0.93 for F-measure. 22 Another recent study using I2E identified 1.6% of prostate cancer patients suffering from social isolation, which was documented only in clinical notes. 23 The NLP pipeline demonstrated 90% precision, 97% recall, and 93% F-measure. Our experience ensures the development of accurate NLP algorithms identifying OUD from clinical notes in this study.
Development of the lexicon for opioid use disorder
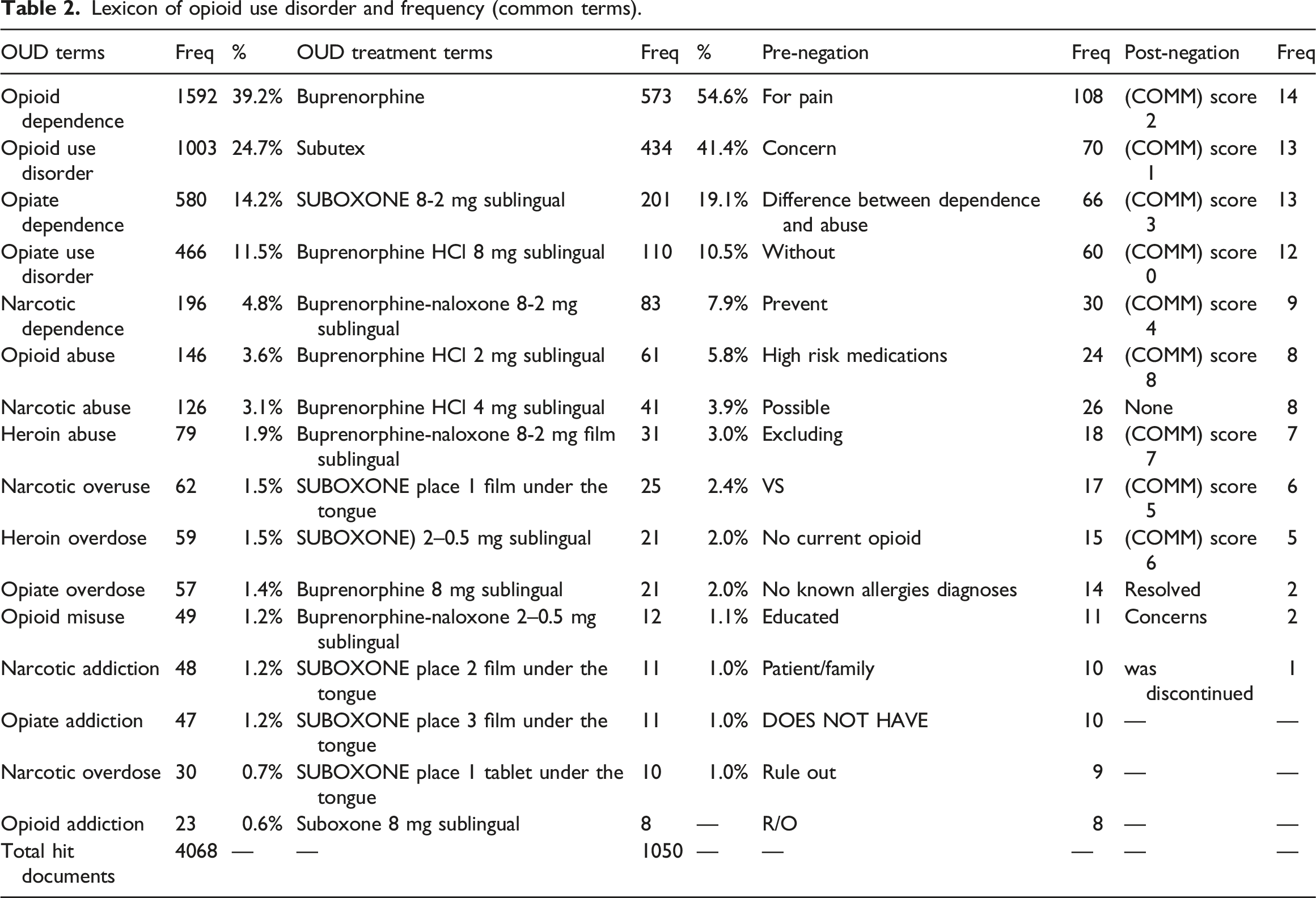
To develop an accurate and complete lexicon for OUD identification, we utilized multiple resources, including domain experts’ knowledge, ICD9/10 coding systems, the NLP software I2E built-in standard terminology SNOMED CT (Systematized Nomenclature of Medicine Clinical Terms) for clinical findings and RxNorm for medications.24,25 Two psychiatrists (Brady and Barth), who have extensive clinical experience in addiction science and pain management, generated an initial list of commonly used terms. These terms represented: (1) opioid medications (e.g., opioid, opiate, narcotic, fentanyl, duragesic, analgesic, heroin, Oxycontin, etc.); (2) use disorder (e.g., abuse, addiction, misuse, dependency, poison, overdose, overuse, sedation, etc.); the combination of “opioid medication” and “use disorder” represents OUD; (3) FDA-approved medications for OUD in all formulations (e.g., buprenorphine sublingual tablet, Suboxone sublingual film/tablet, methadone, Zubsolv, Subutex, Vivitrol, etc.); (4) Current Opioid Misuse Measure (COMM) score greater than 8; and (5) mention(s) of regional addiction treatment facilities (e.g., Barrier Island, MUSC, Center for Drug and Alcohol Programs [CDAP]). We also included descriptive tokens of ICD relevant to OUD (e.g., Opioid dependence, Poisoning by other opioids, opioid abuse). 26 For each term, informaticians (Zhu and Lenert) utilized the NLP software to generate an enhanced term list with spelling variants, acronyms, and abbreviations. Also, the built-in ontologies for opioid medications (RxNorm) and OUD (SNOMED CT clinical finding) were included in the initial lexicon. Domain experts (Brady and Barth) who were blinded to this process evaluated the list by manually reviewing 1000 randomly sampled candidate phrases with OUD mentions identified by the NLP software. When disagreement occurred, the reviewers discussed the terms and came to a mutual agreement in order to form an enhanced and refined lexicon for OUD clinic evidence. We then iteratively refined the NLP queries and lexicon according to their feedback.
Develop and evaluate NLP algorithms for OUD
We developed a set of NLP queries to identify OUD mentions from clinical notes based on domain knowledge. A positive OUD case was identified by the following criteria: a) discovered named entity of OUD defined by the OUD lexicon; and b) excluding OUD mentions with negations. These NLP queries were designed to capture semantic information, syntactic patterns, and clinical negations in order to translate a documented OUD case to the following structured data elements: (1) patient medical record number (MRN), (2) OUD mentions, (3) author type, (4) note ID, (5) date of the document, and (6) type of clinical note. The query development is an iterative process based on two research assistants’ manual review of NLP identified OUD cases in the training dataset. The final NLP queries were established when sensitivity and specificity for NLP algorithms could not be improved.
Performance measure
We used the gold standard, a manual chart review (in this instance, by one post-doctoral researcher on addiction science and one research assistance with extensive experience on chart review) to evaluate NLP performance using the test dataset. Because the patients in the test dataset usually had multiple clinical notes in the training dataset, domain expert reviewed their latest progress notes. The inter-rater agreement rate was calculated. We calculated three standard performance measures for the NLP algorithm: precision, recall, and F-measure. Precision (exactness) is the proportion of true positives to the total number of algorithm-identified cases; in contrast, recall (completeness) is the proportion of true positives that are retrieved by algorithms. F-measure is a harmonic mean of precision and recall (F-measure = 2* precision * recall/(precision + recall)); an F-measure reaches its best value at one and worst at zero. 26 Finally, for all false positives and false negatives generated by the NLP algorithms, the reasons for incorrect classification were manually determined and summarized.
We also conducted a secondary analysis between NLP-identified OUD and ICD-coded data.
Results
Opioid use disorder lexicon
Number and prevalence of different note type in training data set.
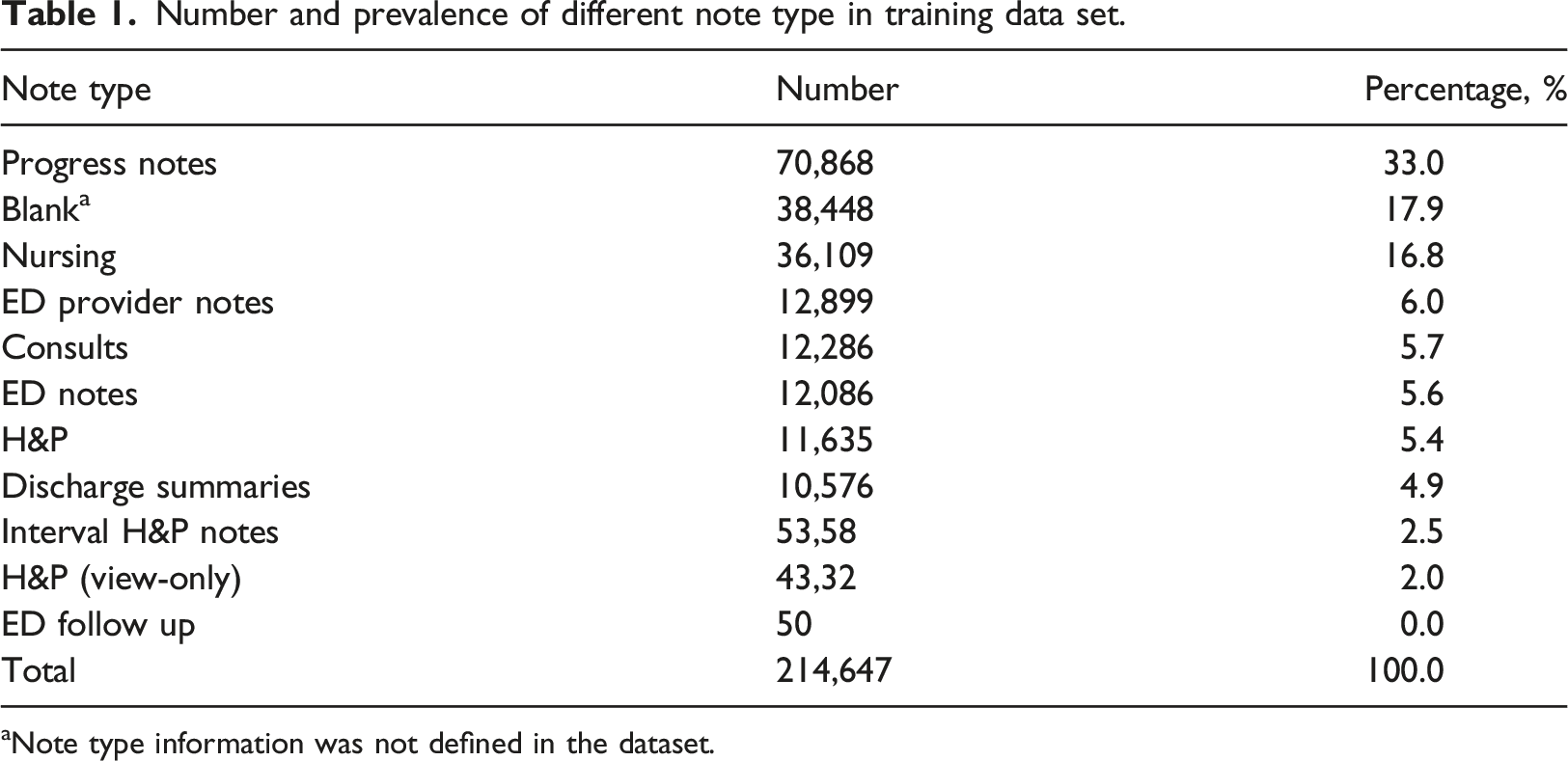
aNote type information was not defined in the dataset.
Lexicon of opioid use disorder and frequency (common terms).
NLP algorithm performance
The multiple NLP queries combining seven modules produced a structured output table for further analyses. The output table also provided a link to the original document, which the NLP developer and reviewers could validate during the development and evaluation phases (Figure 2). Among 96,773 notes from 3436 patients in the test dataset, the NLP query identified 2088 notes with OUD mentions(s) from 158 patients (4.6%). The percentage of OUD patients in the test dataset was consistent with the training dataset (4.7%), which indicated that both the training dataset and test dataset were representative. Based on the prevalence of NLP-identified OUD patients in the sample and the assumption of classification accuracy of the NLP algorithm (area under the ROC curve) as 0.9 (Type I error = 0.05 and Power = 80%), two reviewers first manually evaluated 4 randomly selected clinical notes that NLP-identified as positive for OUD, and 74 notes that NLP-identified as negative for OUD. Both reviewers found no false positives or false negatives in those notes. Then, 1000 randomly selected clinical notes that NLP-identified as positive for OUD were evaluated. Among these 1000 notes, one reviewer identified 14 false positives, and another reviewer identified 13 false positives. Their inter-rate agreement was 98.6%. Counting at the document level, our NLP algorithm for OUD identification had a precision of 98.5%, recall of 100%, and an F-measure of 99.2% (Figure 3). Examples of false positives are listed in Table 3. The following major reasons accounted for false positives: (1) the NLP approach did not completely exclude false OUD mentions in the instruction of opioid side effects in the discharge summary; (2) the screening workup had no score immediately appearing after COMM; (3) sublingual buprenorphine was used off-label for pain management; or (4) a physician documented concern about the diversion of a patient’s opioid pain medications to a person with OUD. NLP output example. (Note: Patient_ID and Note_ID were masked) NLP algorithm performance evaluated by the gold standard. Examples of false positives.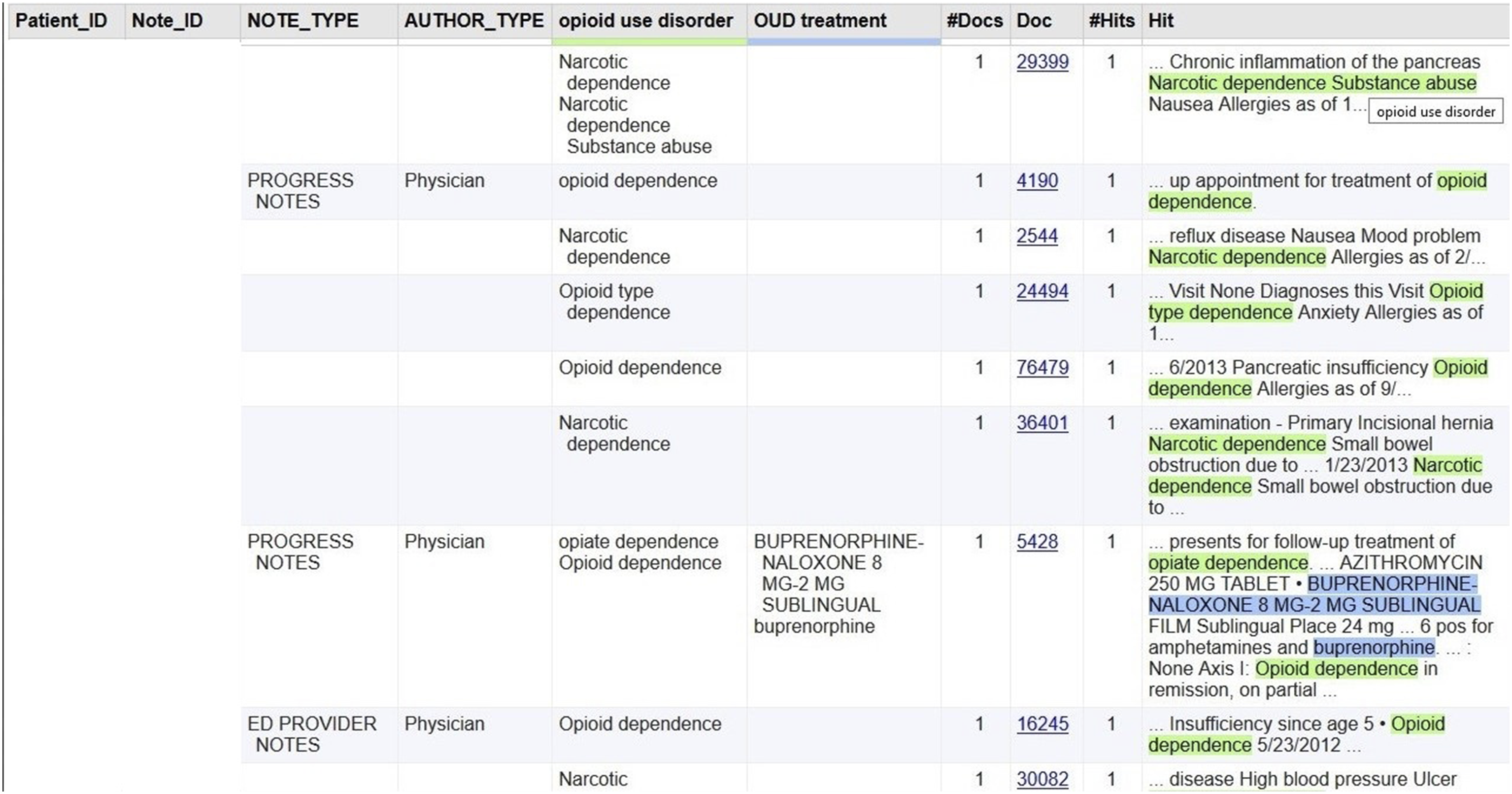


Comparison between NLP-identified OUD and ICD-coded OUD
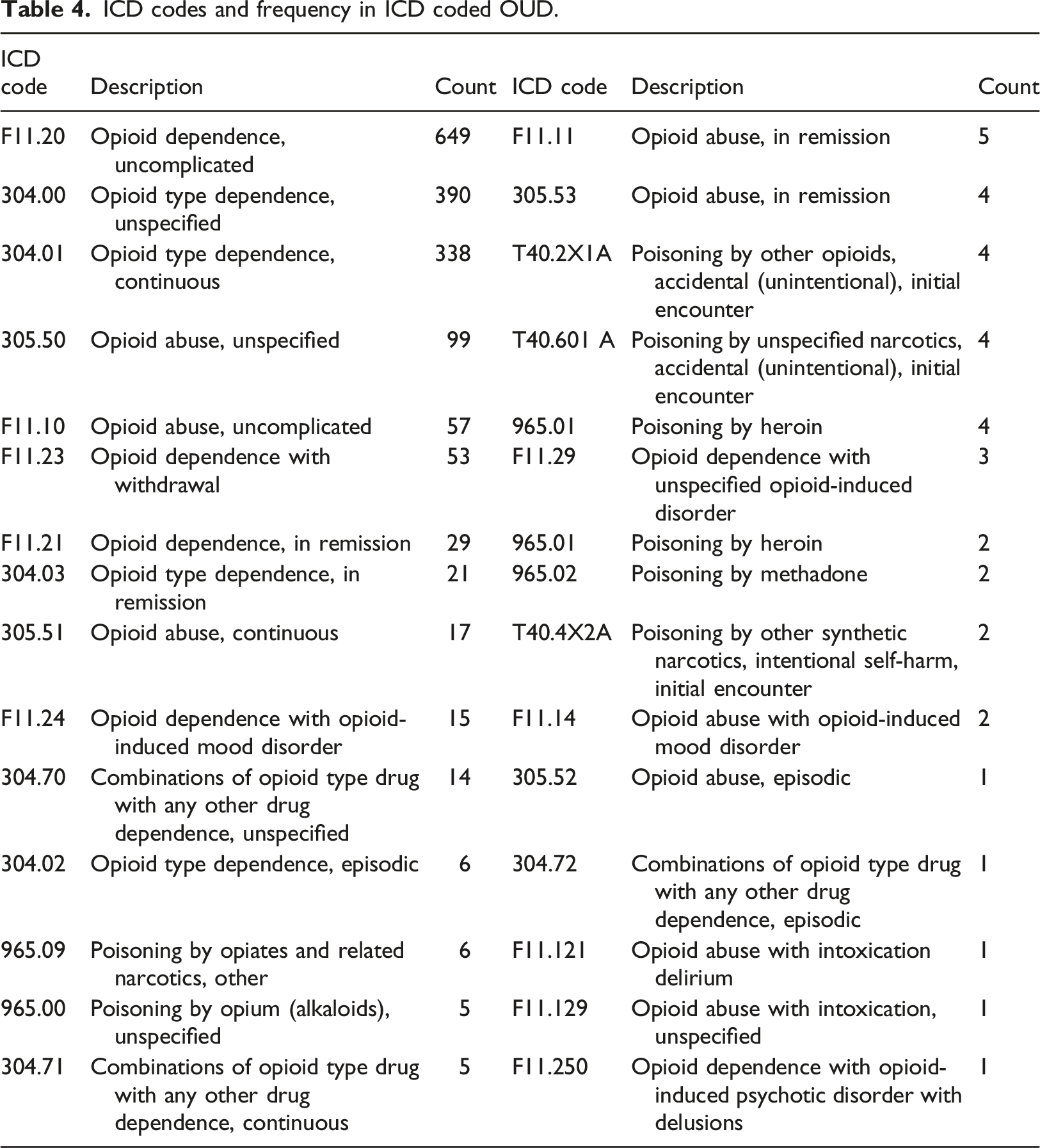
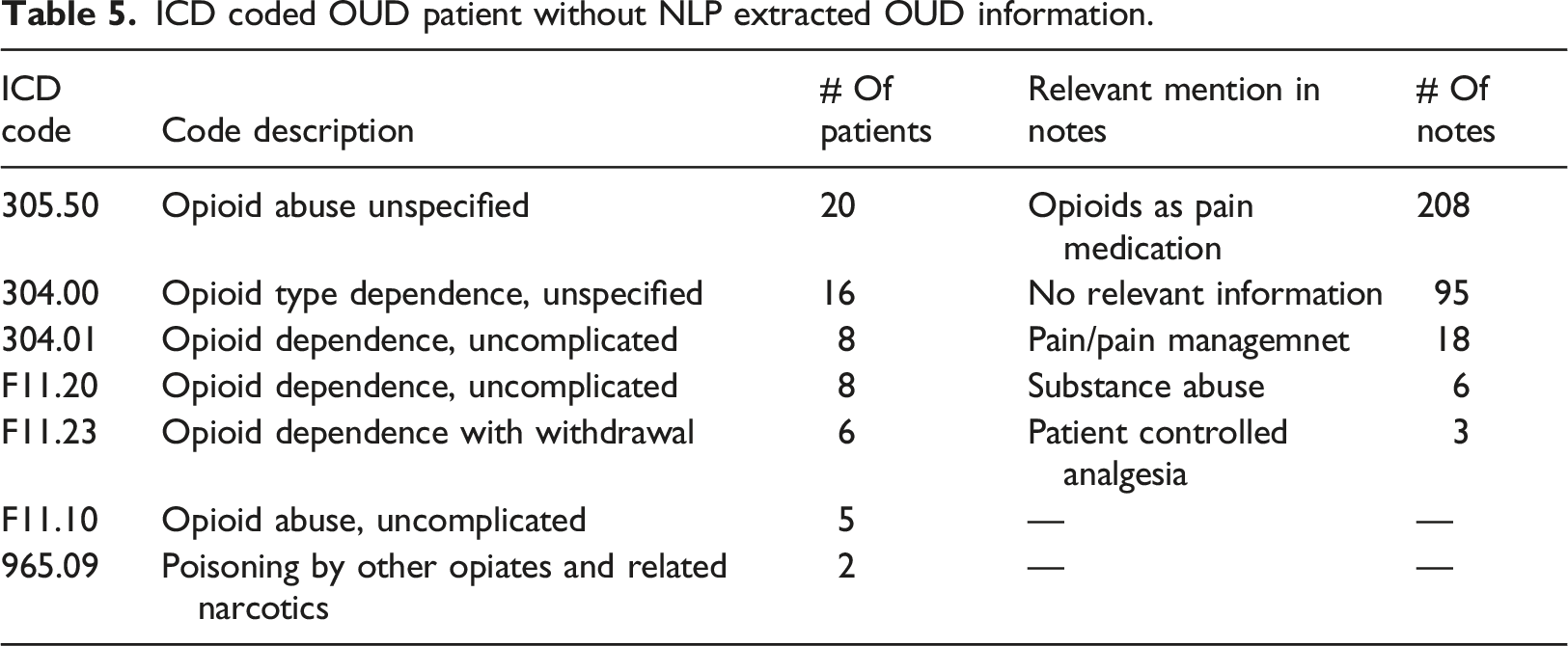
We further explored the concordance between NLP-identified OUD and ICD codes representing OUD. The NLP pipeline included OUD treatments as an indication of OUD. To compare with ICD-identified OUD, we excluded NLP-identified cases by OUD treatment for this comparison because ICD codes represent diagnosis context. Using a lexicon of OUD diagnosis alone, the NLP approach identified 462 patients with positive OUD mention(s) from their clinical notes in the training dataset. In the coded data (ICD9: 305.5, 304.0, 304.2, 304.7, 965.0; ICD10: F11.1, F11.2, T40 (0-5)X (1-3), T40.60 (1-4),etc.), 368 patients (3.6%) had an OUD diagnosis. The overlap between ICD coded and NLP-identified OUD included 308 patients. Moreover, among patients with NLP-identified OUD, 154 (33.3%) had no ICD-coded OUD. Of patients with ICD coded OUD, 60 (16.3%) had no NLP-identified OUD evidence from clinical notes (Figure 4). Cohen Kappa, for these two approaches, was 0.63. The concordance between the NLP approach and ICD coding is also modest in the subgroup of OUD. For example, In the training set, NLP identified about 40% of patients had “opioid dependence” mention(s) in their clinic notes. However, only 95 patients had recorded ICD code(s) for “opioid dependence.” The distribution of OUD diagnostic codes for opioid dependence and opioid abuse is most prevalent, which is similar to the NLP OUD lexicon distributions (Table 4). For these 60 patients who had ICD code(s) for OUD but no corresponded information in their clinical notes a well-trained medical research team member (Kopscik) reviewed 330 (average five notes per patient) prominent clinical notes (progress note, H&P, ED provider notes, or discharge summary). These notes were dated 8 days before and after an ICD coded OUD event. This extended 16 days interval ensures that an ICD coded OUD event has at least one major clinical note to be examined. The investigation results suggested that most of these patients were on opioid medication for pain management; for example, “dilaudid 2 mg IV prn - opioid dependence,” “Opioid dependence/Chronic pain.” These patients might physically dependent on opioids for pain control; however, they were coded as opioid dependence or opioid abuse (Table 5). The study cohort was patients who have been on COT. We intended to develop NLP negations to exclude opioid usage as pain treatment from OUD. Therefore, our NLP algorithm did not identify these 60 patients as OUD. ICD code or NLP identified OUD patients in the training dataset. ICD codes and frequency in ICD coded OUD. ICD coded OUD patient without NLP extracted OUD information.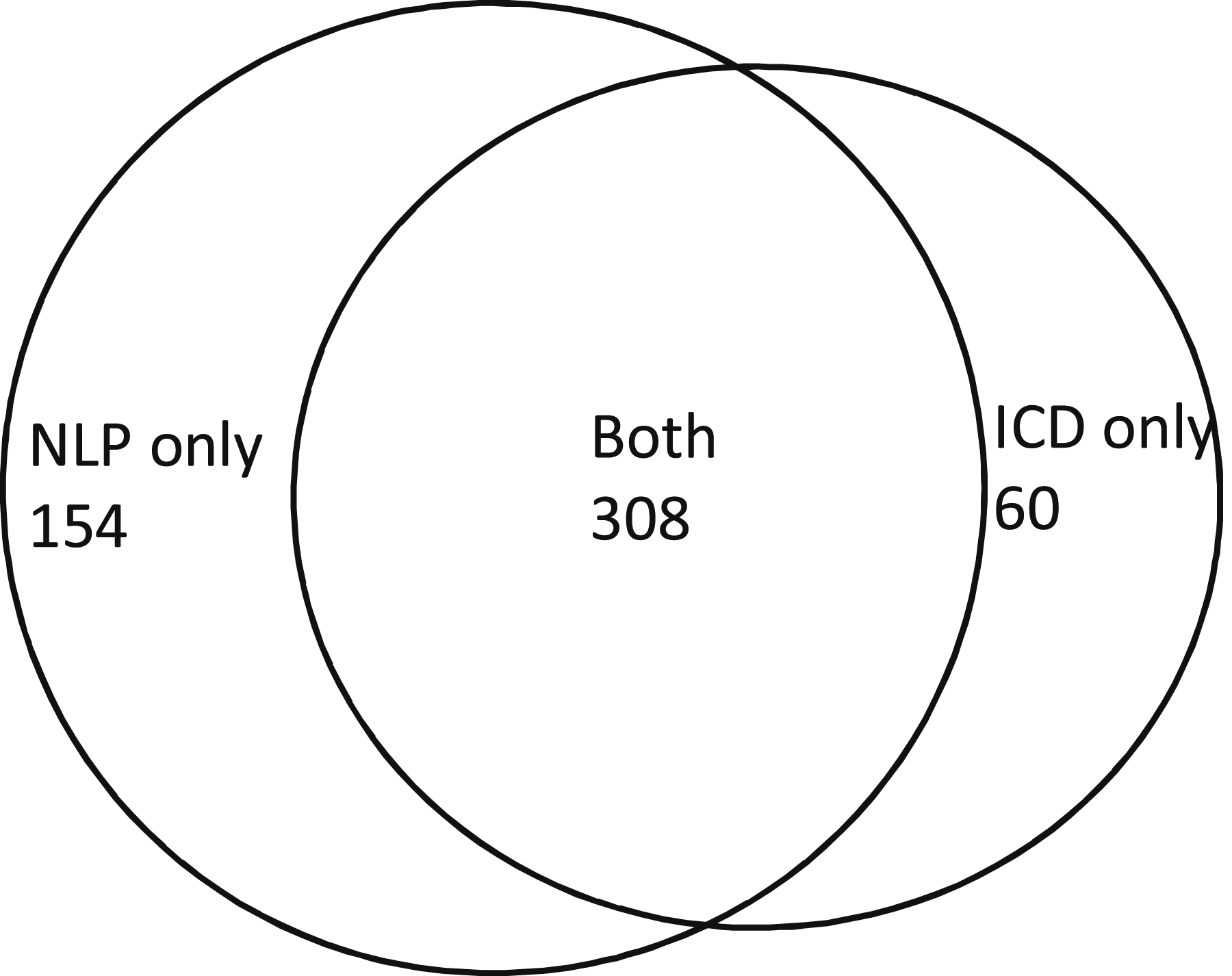
Discussion
This study demonstrates that NLP can identify OUD from clinical notes with high precision and recall when evaluated by manual chart review (considered the gold standard). Developing accurate NLP approaches by incorporating clinical knowledge into computerized algorithms can be a daunting task. Developing a lexicon that completely and accurately reflects information about OUD in clinical notes is an essential step. There is no consensus on OUD terminology, and considerable heterogeneity of terminology use (both accurate and inaccurate) can be seen in clinical documentation. 28 We maximally utilized available resources, including descriptive terms from ICD codes, standard terminologies (SNOMED CT for diagnoses and RxNORM for medications) as the build-in feature in the NLP software, and terms from the scant, yet informative, literature on this topic. Most importantly, we heavily relied on domain experts’ clinical knowledge about how providers document OUD-relevant information in their practice. Both ICD 9/ICD 10 codes and SNOMED CT provided a broad array of terms with the full coverage of medical specialty; however, providers may not use only these standard terms to document clinical findings. Therefore, using these terms alone for case identification may miss important clinical information about OUD. For example, “opioid use disorder” is not a term in either the ICD codes or SNOMED CT; that term was suggested by our domain experts because it is the official term used in the Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition (DSM-V). 29 In our dataset, “opioid use disorder” was not uncommon; notably, it represented 28% of the clinical notes with NLP-identified OUD mentions. Other terms, also suggested by our domain experts, significantly improved OUD identification in our study, including “opiate use disorder,” ”narcotic dependence,” “narcotic abuse,” and “opiate addiction.” In contrast, diagnostic coding systems (ICD and SNOMED CT) suggest using “opioid abuse,” “opioid dependence,” or “poisoning by opioid” to document OUD incidents; however, “poisoning by opioid” or “opioid poisoning” were not found in any clinical notes; similarly, “opioid abuse” had a very modest frequency. We observed that “opioid dependence” was the most dominant (40%) term of OUD in clinical notes; moreover, the frequency of ICD codes demonstrated the same finding. However, those mentioned above three standard terms altogether identified less than half of the OUD cases in our analysis. Besides terms of diagnosed OUD, the domain experts also suggested using FDA-approved treatments for OUD as an indication of OUD, which identified an additional 4% of OUD cases and further reduced false negatives for our NLP algorithm. To minimize false positives, we utilized the NLP built-in clinical negations. In addition, our domain experts manually examined sentences identified by OUD terms in order to develop customized negations, which more specifically excluded false mentions of OUD, such as “for pain,” “education,” “prevent,” “concern,” and terms for “COMM sore <9.” These negations excluded 25% of candidate OUD cases (from 6.3% to 4.7%) and thus reduced false positives. Consequently, our NLP algorithm achieved high performance (with 98.5% precision and 100% recall), which primarily resulted from our domain experts’ knowledge and their careful evaluation of NLP-generated results during the development process. The lexicon generated from the current study combines standard concepts and domain expert knowledge, thus offering a more complete and accurate data extraction method.
A critical secondary finding was that the agreement between NLP identification from clinical notes and diagnosis codes was slightly above moderate (Kappa = 0.63) and bi-directional in the EHR. NLP identified nearly 40% more OUD cases than ICD diagnoses codes alone; we also observed that about 25% of ICD-coded OUD had no NLP-identified evidence from clinical notes, suggesting that these two methods of identification are complementary. To the best of our knowledge, this is one of only a few studies that have compared NLP-based identification versus ICD-coded data for OUD. Carrell et al. (2015) recently developed and studied an NLP system that performed a dictionary look-up task from clinical notes using a customized dictionary of prescription opioid problem usage (addiction, abuse, misuse, or overuse) for patients receiving COT within Group Health system. The researchers found that traditional diagnostics codes identified 10.1% of patients who experienced at least one form of opioid problem uses in their COT cohort. Their NLP system identified an additional 3.1% of patients from clinical notes. Carrell et al. also reported that the Cohen Kappa agreement between ICD-9 codes and NLP identification was moderate (Kappa = 0.51). 18 In another study, Palmer et al. (2015) also studied the prevalence of problem opioid use identified by NLP versus ICD9 diagnosis codes for the same Group Health COT cohort. Those researchers found that over 33% of NLP-identified cases for problem opioid use did not have an ICD-9 diagnosis of opioid abuse or dependence; moreover, about 40% of patients with ICD-9 codes of OUD did not have NLP-identified evidence of OUD. The two methods of NLP identification and ICD code identification also demonstrated slightly above moderate agreement (Kappa = 0.61). 20 Our study confirmed findings from those previous studies that neither ICD diagnosis codes nor the NLP approach alone could ultimately reflect the true prevalence of OUD extracted from EHR data.
ICD codes have been predominantly used to record diagnoses in EHR; However, using ICD codes alone is incomplete and inaccurate for case identification for primary diseases (accuracy: 0.06-0.71).30,31 Notably, ICD codes for OUD lack both sensitivity and specificity from both previous studies and the current investigation. A recent study reported that more than 40% of patients with assigned ICD codes of OUD did not meet the DSM-5 OUD diagnosis criteria evaluated by the domain experts’ chart review. 32 The DSM criteria were usually referred by providers as the gold standard for diagnosing OUD at clinical practices. 33 While the DSM-5 uses the terminology “Opioid use disorder” replacing the terms “opioid abuse” and “opioid dependence” in older versions, ICD coding still uses these outdated terms to record OUD diagnosis and lump all opioid uses, including pain treatment, under this large umbrella. 34 Notably, a study reported that “Opioid dependence,” the primary ICD code for OUD, could not distinguish psychological dependence on opioids (OUD) and physiological dependence on opioid therapy for pain management. 35 Our study results demonstrated a similar finding: most of the 60 patients, who were ICD coded as OUD but not classified as OUD by NLP, were on opioid treatment for pain. The potential solution is to update the ICD coding system of OUD to reflect the definition of OUD in DSM-5 more closely and provide cleaner guidelines to providers around coding practice for OUD. For example, using the new ICD code Z79.891 (long-term [current] use of opiate analgesic) rather than F11.20 (opioid dependence, uncomplicated) to document the opioids treatment for pain. 35 Besides ICD codes, we also can utilize other clinical data to identify OUD patients, such as clinical notes, to supplement the ICD coding system. ICD codes are commonly used for acute diagnoses; chronic diseases, such as OUD, may commonly be documented in problem lists that are usually codified with SNOMED-CT. Information about OUD may also be documented in clinical notes as chief complaint, problem list, history of present illness, clinical findings, or treatment plan. As clinical notes are readily available in the electronic format for clinical practices and research, NLP can automatically unlock such information and add value by identifying OUD patients that ICD codes do not pick up. NLP methods have significantly advanced in the past 5 years with the development of many software packages to support analytics in clinical domains. Extraction of explicitly stated concepts can reach very high accuracy (greater than 90% in many settings, including prior work on opioid abuse).36,37 Our methods are reusable with other NLP software as a reference dictionary and clinical logic for both rule-based and data-driven approaches, which reflect its potential for broader dissemination with necessary customizations. Importantly, some studies have utilized either coded data or an NLP strategy alone to identify OUD patients from the EHR.38,39 However, our findings demonstrated that combining NLP-extracted OUD evidence from clinical notes with evidence from ICD diagnostic codes is necessary to provide a comprehensive picture of OUD for clinical practice, research, and surveillance systems.
Limitations
There are several limitations associated with this study. First, our study only focused on patients who had received COT; we did not study illicit opioid users, patients with a history of short-term opioid use (e.g., surgical or dental patients), or patients with cancer. Providers may have documented clinical information differently for these opioid users. The purpose of this study was to develop a fundamental lexicon and NLP algorithm to identify OUD from clinical notes. Studying data from patients on COT may help us to understand OUD information in a longitudinal and focused way in order to develop NLP approaches more efficiently. Future investigators of opioid user subpopulations may customize and utilize our approach and thus add additional necessary components for rapid algorithm development. For example, other street drug names of opioids could be added for illicit opioid users. Secondly, this study was designed for MUSC patient care. NLP tasks are usually institutionally specific, and generalizability is a common concern. During the development process, we intended to maximize the generalizability of the OUD lexicon and algorithms by using the DSM-V classification system, ICD9/10 coding systems, and the I2E built-in standard terminologies SNOMED CT and RxNorm to extract OUD indicators from clinical notes. Our dataset consisted of patients’ longitudinal clinical notes with diverse note types (Table 1); thus, our lexicon and algorithms maximally reflected the patterns of OUD documentation in different note types at MUSC. The OUD lexicon and NLP pipelines generated from this study are reusable with customization: other institutions may engage providers to review the OUD lexicon to confirm, add, or delete terms based on their local practice. In addition, performance evaluation (e.g., Figure 3) and error analyses for false positives and false negatives (e.g., Table 3) using their local dataset are needed before implementation. 40 Finally, this current study utilized a rule-based approach. In future work, we will leverage our gained knowledge of identified OUD from clinical notes to develop machine learning and deep learning approaches and compare the performance of different NLP strategies.
Conclusions
NLP can accurately identify patients with OUD from clinical note data. Using both the ICD diagnostic code and NLP-extracted OUD evidence from clinical notes can improve our ability to identify OUD patients from the EHR and positively inform treatment interventions.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by U.S. National Institute of Drug Abuse (K12DA031794-06A1; K23DA039328-01A1; UG1DA013727), U.S. National Library of Medicine (R21LM012945), and U.S. National Center for Advancing Translational Sciences (5UL1TR000062–05).
Ethical approval
This study performed the secondary analysis using data from EHR and was approved by the MUSC Institutional Review Board.