
Abstract
Research on interoperability and information exchange between information technology systems touts the use of secondary data for a variety of purposes, including research, management, quality improvement, and accountability. However, many studies have pointed out that this is difficult to achieve in practice. Hence, this article aims to examine the causes for this by reporting an ethnographic study of the data work performed by medical records coders and birth certificate clerks working in a hospital system to uncover the practices of creating administrative data (e.g. secondary data). The article illustrates that clerks and coders use situated qualitative judgments of the accuracy and authority of different primary medical accounts. Coders and clerks also employ their understandings of the importance of different future uses of data as they make crucial decisions about how much discretion to exercise in producing accurate data and how much effort to put toward clarifying problematic medical data. These findings suggest that information technology systems designed for interoperability and secondary data also need to be designed in ways that support the qualculative practices of data workers in order to succeed, including making future uses of data clear to data workers and finding ways to minimize conflicting data before data workers encounter it.
Keywords
Introduction
Easy exchange of healthcare data between dispersed people and organizations has been outlined as a crucial facilitator of good patient care, quality improvement, clinical research, and novel research using big data analytics.1–3 It has been estimated that creation of healthcare information exchange and interoperability—the establishment of a standardized system of information exchange between healthcare entities including providers, laboratories, radiology centers, payers, pharmacies, public health services, and so on—would provide a net value of 77.8 billion per year. 3 Research, design, and practice innovations related to interoperability have arisen to facilitate data and information exchange between data originating from different people and different healthcare settings, such as electronic health record (EHR) systems, standardized terminologies, architectures, and overall frameworks.4,5 Unfortunately, actually creating integrated, interoperable health data has proven to be incredibly challenging.6,7
A number of barriers to interoperability and health information exchange have been noted in the literature, including social and legal barriers to data sharing (e.g. privacy concerns and information blocking), 1 the inherent complexity of healthcare work and the organizational and institutional arrangements in which it takes place, 6 heterogeneity of digital systems and system selection being driven by factors other than interoperability, 8 and inconsistent and incompatible interoperability standards for healthcare information systems maintained by world-leading standards bodies (e.g. International Organization for Standardization (ISO) and Health Level-7 (HL7)). 2 However, this prior literature on the difficulty of achieving interoperability lacks sufficient study of a major issue preventing interoperability of systems and exchange of healthcare data, namely the challenges to interoperability posed by contingencies of data work.
To fill this gap, this research answers the following research questions: How do healthcare data workers create administrative data from clinical records to be used for secondary purposes? Further, what are the implications for interoperable IT systems of these administrative data work practices?
This work demonstrates that designing systems to support interoperability of healthcare data solely from a technical angle is insufficient. Without attending deeply to the practices through which people transform clinical records into structured data forms and standardized terminologies, new information technology (IT) systems (and healthcare stakeholders for that matter) will not be able to support these practices.
Conceptually, I draw on the computer-supported cooperative work (CSCW) field, which has a long tradition of exploring how work is actually conducted at micro level9,10 (for recent empirical examples, refer previous studies11,12). I supplement this with the notion of qualculation from the science and technology studies (STS) field13,14 in order to highlight how the situated work of calculation and judgment is required to interpret and use information from one context to the next.
This study is based on ethnographic data collection (observations and interviews) conducted with coders, clerks, and supervisors between 2014 and 2016 in a hospital system in the Western United States.
I have examined the qualculative practices used by medical records coders (“coders”) and birth certificate clerks (“clerks”), two occupations responsible for creating administrative datasets that are integrally important for secondary uses (coders produce billing and discharge data used for research, quality measurement, and a variety of other purposes; clerks produce birth certificate data used for research and quality measurement).
Related work
A multitude of healthcare stakeholders have touted the benefits of widespread implementation of EHR systems related to interoperability, data sharing, and data reuse. The Healthcare Information and Management Systems Society (HIMSS) defines interoperability as “… the extent to which systems and devices can exchange data and interpret that shared data” (from HIMSS website, http://www.himss.org/library/interoperability-standards/what-is). According to the medical informatics literature, there are three “levels” of interoperability: foundational, structural, and semantic.15,16 Semantic interoperability, the highest level, exists when systems or elements are able to exchange and use information because both entities are taking advantage of structures promoting data exchange and codified data (e.g. data rendered into standardized terminologies). 17 One large benefit of interoperability is the promotion of secondary usages of data rendered into standardized formats, which can be aggregated, shared, and reused by different entities for research, management, and accountability.18 –20 Two overarching kinds of data are available for such secondary usages—clinical data and administrative data.21,22 Clinical data are data drawn directly from the medical record. Administrative data are data that originated from the medical record/patient data but has been transformed through various coding processes to be used for administrative purposes, such as billing, clinician credentialing, and so forth.
While commentaries in medical journals, trade magazines, and popular press periodicals tout the promise of available clinical data that can be easily aggregated and analyzed, in practice, the stores of clinical data in EHRs are still largely unavailable for management and research. 23 Research shows that despite the wide implementation of EHR systems, there is a gap between the information found in the EHR and the quality and requirements of information required for clinical research such as clinical trials, and this gap is bridged in practice by effortful data recording practices. 24 Due to such difficulties with data extraction and ensuring data quality 25 and the effort it takes to overcome them, clinical data from EHRs are not yet widely used for second-order research purposes.23,26,27 Administrative data, however, are widely used in clinical research, public health research, health services research, and healthcare management and regulation. 28 Still, it is not clear how apparently robust administrative data are created and prepared for reuse purposes.
A wealth of research examining the social and the sociotechnical practices of data production, data management, data sharing, and so forth has shown that data are not “natural” objects that can circulate and aggregate regardless of their origins. 29 Data are produced through localized work within social, cultural, and political contexts that in turn shape the production and interpretation of data. 5 Studies of data sharing and reuse show that these activities involve intensive and collaborative labor that must be carried out on an ongoing basis; the origins of data must be understood and data sets must be recontextualized within their new settings for data sharing and reuse to be successful.6,7,30
Along these lines, in the healthcare domain, research has examined the historical background, construction, and consequences of classification systems integral to data work, such as the International Classification of Diseases (ICD) and the Nursing Interventions Classification (NIC). 29 Researchers have also provided rich accounts of the effortful practices of reading and writing involved in documenting patient information in the medical record 31 and the work practices of sorting patients according to diagnostic categories. 32 Dixon-Woods et al. 33 describe in ethnographic detail the variations in collecting and calculating data about central venous catheter bloodstream infections. However, the research conducted to date on data practices in healthcare has focused on “first order” data practices (e.g. direct recordings of clinical information); there is a marked lack of research focused on the practices of workers who transform primary data, typically clinical charts, into the stores of administrative data that are so important for a multitude of purposes, including influential research and governance systems based on performance measurement. This research takes a different tack by examining in detail the practices of medical record coders and birth certificate clerks who transform clinical charts to systematically understand the skilled judgments and logics of work that underlie administrative data work in healthcare.
The notion of qualculation (Law and Callon, 2005)14,34 is promising in this regard as it provides a lens to study the practices involved in calculation and situated judgment that people employ in transforming clinical charts into administrative data. Calculation is often assumed to be a mechanical algorithmic act that is deployed upon “clear and codified” information that “holds its shape” despite moving around, meaning it stays the same and engenders the same interpretation from one context to another (in the STS literature, such objects have been referred to as “immutable mobiles”). 14 Judgment, however, is seen as situated, potentially somewhat tacit, and artful. The concept of qualculation sees judgment and calculation as inherently related—calculation is not straightforward and mechanical, it involves situated qualitative judgments that are inherently quite effortful.13,14 Taking this view, information is better seen as a mutable mobile, because even the most seemingly immutable objects adapt to local contexts and circumstances. Thus, information not only “flows,” in that it moves around through networks, but it is also “fluid,” meaning that it is always incomplete, emergent through practice, and situated in local contexts. 14 Thus, calculations are always qualculative because they are inherently bound up with situated judgments employed by specific people, in specific organizational and institutional environments, working in specific situations. 14
Scholars have examined the qualculative practices involved in a variety of tasks, from clinical decision making 14 to evaluating the electricity market, 35 but thus far scholars have not examined the qualculative practices of applying standardized schemes and vocabularies to data to create standardized data elements. In healthcare, achieving semantic interoperability requires that all entities involved be able to exchange standardized coded data. This study examines the microwork of creating standardized data elements—transposing unstructured clinical data into structured data fields and applying controlled coding to medical charts—to shed light on the qualculative dimension of interoperability of healthcare data.
Methods
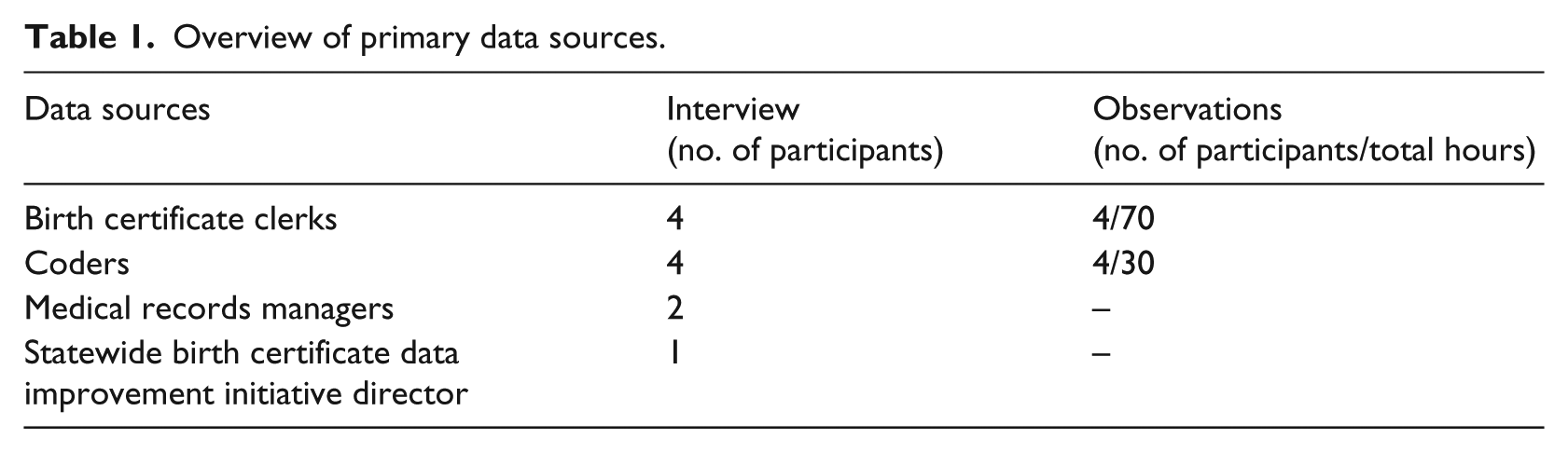
Coders and clerks are occupational groups who translate clinical records into structured administrative data—discharge data and birth certificate data. I utilized qualitative methods (ethnographic observations and interviews) to study the data work of coders and clerks in three hospitals in a not-for-profit hospital system in the Western United States between 2014 and 2016 as well as interviews with the managers of the medical records departments. See Table 1 for an overview of data sources.
Overview of primary data sources.
The four birth certificate clerks represent all clerks who work in the three different hospitals. All clerks observed were quite experienced, although they varied from about 2 years to over 10 years of experience. Coders were more difficult to recruit because coders in my fieldsites often work remotely from home, and I was limited to data collection with coders who come in to work in the medical records offices and who volunteered to participate in the study. All coder participants were similarly experienced, with the most inexperienced having about 3 years of experience as a coder. Interview questions focused on the basic structure of coding/clerk work, frequent problems that arise while carrying out data work and how they are dealt with, how participants’ perceptions about how different secondary usages of data (e.g. billing, research, and accountability) shape their work, and how they interact with other personnel in the hospital involved with data work. Interviews lasted 60 min, while observations lasted from 4 to 8 h. Clerks and coders were instructed to narrate their activities out loud as they did their work. Coders were asked to code obstetrical charts during observations. Both interviews and observations were transcribed for data analysis. In addition, a statewide initiative to improve birth certificate data was taking place during the fieldwork, so the director of this initiative was interviewed, and a 2-h webinar and 1-day workshop which focused on improving birth certificate data quality were observed. These events provided in-depth examples that helped me to understand complexities of the data work performed by the clerks.
An interpretive approach to qualitative data analysis was used, in which I identified emerging themes during and after data collection using a combination of open coding and composing memos. 36 Memos were written to expand on emergent themes related to contingencies of data work (e.g. “judging accuracy of diagnosis”). As coding and memoing proceeded, I compared different instances of categories to one another, reworking my understanding of a theme in light of new data on an ongoing basis. I continued coding until I reached both theoretical saturation and inductive thematic saturation. 37 Memos then formed the basis of the findings, presented next.
Findings
Overview of the data work of coders and clerks
Coders, who typically complete a 1- to 2-year certificate program in medical coding before beginning work, apply standardized numeric classification systems to patient records to produce administrative data used for medical billing and other purposes. The general process of coding a chart involves identifying a primary diagnosis and secondary diagnoses, identifying numeric diagnosis and procedure codes from the ICD-10 and supplementary code sets, and entering a finished code set into an “encoder” program accessed through the EHR system, Epic (Epic is an integrated suite of healthcare software that together comprises an omnibus EHR system that supports clinical, administrative, and other functions. The Epic EHR system is developed by Epic Systems Corporation and has a huge market share in the US healthcare market; see Figure 1). Government health insurance (Medicare/Medicaid) and certain private insurance companies use diagnosis-related groups (DRGs) for reimbursement, and coders are responsible for assigning the correct DRGs to charts when necessary. The hospital system uses a Computer Assisted Coding (“CAC”) program that uses text recognition to automatically “code” patient charts for both ICD-10 and DRG groups. Coders are responsible for manually coding the chart and correcting the CAC program, gradually improving the CAC program over time.

Coder at work, with patient chart on the left hand screen, code entry EHR module on the right hand screen, and personal coding notebook on the desk in foreground.
Birth certificate clerks are housed in the labor and delivery (L&D) unit although their work is overseen by the medical records departments in the hospitals. Clerks have no formal training or certification programs associated with their work and are trained to be birth certificate clerks by the individual hospitals where they work. Clerks are responsible for completing birth certificate paperwork including the “long form” which records an extensive amount of patient data, filed with the state’s vital records office. Nurses initially fill out birth certificate worksheets, which clerks review and correct by accessing the patient chart in Epic. They then complete an extensive structured computer-based form in a software system (“AVSS”) used by the state to manage vital records data (Figure 2). Once entered, the clerk creates a printout for the patient to review and sign, makes additional corrections based on the patient’s review of the data, and files paperwork with the state. AVSS is an old system initially developed in 1987 and little about the system has been updated since. Clerks are translating between two separate systems, and many of the structured questions in Epic (e.g. on the patient summary sheet) are different than in AVSS, where each structured data field has a set of predefined answer codes that differ from the answer codes in Epic. Birth certificate data, kept on record by the state in perpetuity, are important for public health research and have recently become immensely important for quality measurement of healthcare because they are the only standardized, widely available source of certain key data elements for hospital quality measures (see Pine et al. 38 for an in-depth description of clerk work practices).
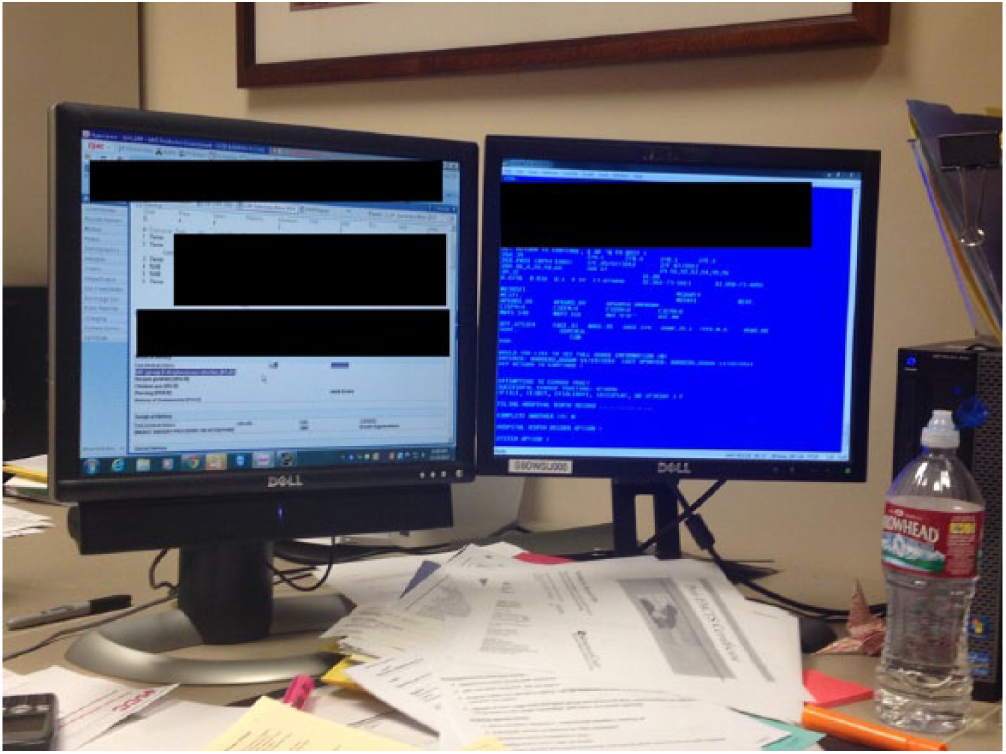
A clerk’s workstation. The clerk is entering birth certificate data into AVSS (right screen) using a birth certificate worksheet (not pictured) and the patient chart in Epic.
Interpreting medical reports: judgments of accuracy and authority
The data work of coders and clerks rests on interpreting textual and numerical data reported by clinicians and patients (in the case of clerks) and applying classification systems and structured data fields to this messy heterogeneous data. Coders and clerks have the difficult task of judging the accuracy of data and identifying instances where data are incomplete, conflicting, or inaccurate, and making determinations about which data are correct. At the same time, coders and clerks make judgments about the relative authority of different data sources. Coders and clerks have protocols related to which data sources they should prioritize and which they should exclude, but these protocols are selectively applied depending on circumstances.
For example, the coder “DI” coded a chart for a patient who was induced (labor was started artificially) because her pregnancy had gone on too long. The patient eventually had a cesarean section (surgical birth). When she reached the end of the chart, one of the final documents DI reviewed was the discharge summary, which had been written by a different doctor than the primary doctor who oversaw the birth. For coders, the discharge summary written by a physician is considered the “final diagnosis” and is the most authoritative account. The discharging clinician is supposed to review all of the patient’s charting before writing the discharge summary. In this discharge summary, the discharge doctor wrote that the patient came into the hospital in active labor (not for an induction). The discharge summary did not document a drug to stimulate labor that the patient received during labor or the cesarean section even though previous documentation from the primary doctor recorded giving the drug and doing the surgery. DI had been reviewing the charting piece by piece in Epic and building a preliminary code set in a personal notebook. When DI read the discharge summary, (s)he crossed out induction of labor in the coding notebook (meaning (s)he would not enter a code for this procedure), explaining that the discharge summary is the most authoritative source of data for the coder: “… we go with the final diagnosis, because it was established after study.” DI explained that (s)he was certain an induction of labor had occurred, but felt (s)he could not code for it because the discharging doctor did not include a diagnosis that would lead to induction of labor nor note the procedure in the discharge summary. However, DI did enter diagnosis and procedure codes for the cesarean section because there was an operative report for the surgery.
In a different observation, another coder (“WA”) described why (s)he entered a code for a patient that was post-term (past her expected date for delivering her baby) despite there being no physician documentation about the patient being post-term on the discharge summary: “Technically we have to go by the ultimate, last, final, diagnosis. But because we know this is a template, and it’s just a documentation error, and I have enough to support it, and the fact that she was induced, I will code it.” WA describes a number of situated judgments about data accuracy—the discharge summary does not include a note that the pregnancy was post-date but based on the fact that a procedure (induction) was documented and the fact that (s)he has “enough to support it” in other sections of the chart, (s)he has decided the discharge summary is inaccurate and has interpreted other sources as more authoritative in building a code set. In another instance, a coder decided not to enter a code for advanced maternal age (a mother who is 35 years or older), a diagnosis that had been recorded by a physician on the discharge summary, because on the same discharge summary and elsewhere in the chart the patient age was recorded as 34. In this case, the coder selected the data that (s)he judged as more accurate given conflicting information recorded by the same source.
Coders also interact with information presented in the CAC program. The CAC highlights sections of the medical record and suggests associated codes. When coders hover the cursor over highlighted text, the CAC offers prompts and links to a digital copy of the coding guidelines. For example, here DI narrates an interaction with the CAC: … if I’m not sure which one to take, I can hover and it will tell me what the next option is going to be … So I’m gonna go newborn conditions, other. Specified condition originating in the perinatal period. So it’s 7989. And if I look in my codebook: “Use additional code to specify the condition.” So now I would code the reflux.
However, the CAC, guidelines, and other computer-assisted tools are a resource to action, not a strict contract. Coders often ignore CAC codes and change the order of codes that are automatically ordered by the encoder program when entering the final code set.
Like coders, clerks use a patient’s clinical chart in Epic to fill out the long-form birth certificate. Clerks draw on some additional data sources that coders do not have access to, including the summary worksheet filled out by an obstetrical nurse and the patient themselves, since clerks interact directly with patients when they visit new mothers to have them review birth certificate data. In fact, clerks often deem the mother to be the ultimate authoritative source of data. For example, a common source of difficulty is the data field for “last menstrual period (LMP).” AVSS uses the LMP data field to automatically calculate another data field, “weeks gestation” or how far along in pregnancy a baby was when it was born, but since women often have irregular periods, LMP is not always an accurate way to gauge the start of a pregnancy. Clerks check to see if different sources (nurse worksheet and patient chart in Epic) of LMP data match up, and they check to see if entering LMP results in a reasonable “weeks gestation” output. Often, LMP is missing or recorded differently in different places, and clerks need to select the LMP that they believe is most accurate; in such cases, clerks often ask the woman directly what her LMP was, sometimes trying to help a woman figure it out if she cannot remember (e.g. asking the woman what her due date was) and using a tool called a “pregnancy wheel” based on the woman’s information to see if due date and LMP align. Clerks report valuing the information given by patients over other accounts at times. For example, one clerk said, If they give me a date that is screwy and the ultrasound date matches the birth date, I go with the ultrasound date. Sometimes the ultrasound date is totally off, because they maybe didn’t have it until, I don’t know, 12 weeks or something, and the [due date] is what they have told me, and somebody has just input the information wrong. So they are already telling me that this is their due date … They are right there, you know? So I totally go with what the mom says at that point …
Perceived future uses of data
Coders and clerks used their understanding of how the data they were producing were going to be used to guide the qualitative aspects of their data work. In interviews, it was clear that coders saw their data work as being primarily driven by certain data end uses. When asked about why (s)he coded for the cesarean section even though it wasn’t on the discharge summary, DI said, … we’re gonna get paid on this. But for physician credentialing, activity reports. Anytime they want to know, “Oh, we are considering adding a surgeon. Can you guys tell me how many procedures we had that offered this type of anesthesia?” All these data elements can be put together and queried, and reports run. So decision support. Stuff like that. Credentialing. And so this is where it all comes from.
Another example of how perceived importance of future uses shapes data work comes from how coders exercise their ability to query clinicians of record. Interviews revealed that querying is quite rare and exercised with caution: “… we have the ability to query the doctor if … if need be. Yes. But … it has to be a pretty serious thing or affect, you know, or affect reimbursement. If it’s gonna affect reimbursement we would consider.” It is clear that reimbursement was seen as the dominant priority of coders’ data work.
Interestingly, clerks that we interviewed had little understanding of the potential future uses of birth certificate data. When asked in interviews “what will these data be used for in the future?” clerks gave vague answers, such as, “Not census, but statistical, you know? If they didn’t go in until 25 weeks and the baby has some malformation, maybe they could have caught that early, you know?” Medical records managers had more understanding of the importance of birth certificate data for quality measurement, but this data use was not reported by any of the clerk participants, and use of birth certificate data for research was only vaguely alluded to by clerks. It is clear that coders engage in qualculations that maximize the use of the data they produce for billing, with clinician credentialing taking secondary status. For the coders, research and quality measurement were absent from their accounting of the potential future uses of data and thus did not figure into qualculations (for example, coders rarely prioritized accuracy over incorrect authoritative accounts in cases where billing was not going to be effected). Clerks had little understanding of the future uses of the birth certificate data they entered beyond “statistics” maintained by the state. It is hard to know if clerks would have worked to promote data accuracy in alignment with future uses had these future uses been known to the clerks, but it is possible that such an understanding would have influenced how clerks carried out their data work.
Discussion
Interoperability has been highlighted as a major goal of healthcare IT and policy. 1 Interoperability at the highest level requires standardized coded datasets that can be easily exchanged and interpreted by all parties. Administrative data, produced using controlled vocabularies and coded structured fields, have frequently been used for secondary purposes under the assumption that it is high quality and more easily exchangeable than clinical data drawn directly from EHRs, 28 which is difficult to standardize at sufficient quality for secondary usages such as research (Botsis et al., 2010).23,24 However, this study illuminates the multiple and often competing logics that data workers apply in creating stores of administrative data. Examining the micropractices of data entry and coding engaged by clerks and coders makes clear that although they are touted as readily available and standardized datasets, administrative data are produced through deeply qualitative data work that result in large-scale datasets that do not prioritize data accuracy. Just as with other kinds of calculations, affixing numeric codes to specific diagnoses and procedures and arraying data within structured fields involves far more than rote, rational calculations—it involves deeply influential judgments of the data sources that shape the creation of data elements at the most basic level. While the vast majority of the literature on interoperability in healthcare focus on developing technical solutions (e.g. platforms for data sharing between systems or creation of standardized nomenclatures that facilitate data aggregation), such approaches to interoperability are wholly insufficient because they do not take into account the qualculative practices which inherently combine both calculation and situated judgment 14 that data workers apply in practice. The findings of this study demonstrate that qualculative aspects of healthcare data production must be understood to appreciate the advantages and limitations of administrative data for secondary uses as a whole.
In transforming clinician- and patient-reported data into administrative data, I found that coders and clerks engaged in qualculations related to two qualitative aspects of data work in particular: judgments related to the accuracy of data sources (employed to determine which data was accurate in the face of ambiguous, conflicting, or missing data) and judgments related to the authority of data sources. For example, when DI decided to code that a cesarean section was performed despite the fact that the discharging physician did not record the surgery, DI should have coded based on the discharge summary, but felt the operative report was an authoritative account that effectively disputed the faulty “final diagnosis” recorded in the discharge summary. Thus, the final code set reflected a carefully maintained balance between accuracy and institutionally apportioned authority attached to different sources of medical data. Clerks engage in similar judgments of accuracy and authority as they interpret charts and enter data into the structured birth certificate form.
Coders and clerks often prioritized judgments of authority over judgments of accuracy, entering data that they believed were inaccurate if it came from an authoritative source. I found that coders, in particular, were willing to push back against formal understandings of authoritative source in order to protect the accuracy of data, but typically, coders prioritized judgments of accuracy over judgments of authority only when not doing so would threaten the data in terms of its perceived dominant purpose (billing). Clerks did the same if data were going to be wildly inaccurate because this would threaten the potential use of birth certificate data for health statistics, although future uses of data were less of a concern for clerks than for coders overall.
Scholars have called for a sociotechnical approach to interoperability in science more broadly 39 and in healthcare specifically. 40 This research demonstrates that supporting qualculative practices should be a key concern for researchers and other stakeholders focused on developing interoperability of healthcare data from a sociotechnical perspective. To support the qualculative work of producing standardized coded data, stakeholders should make clear the future uses of data and the relative importance of these future uses to data workers and their managers, so data workers can take these uses into account when making qualculations related to the importance of accurate data under different conditions. This information could be incorporated into the design of IT systems or work processes for data entry and coding work, which would help data workers modulate their judgments according to the multitude of actual future uses of data. Many coders, for example, are unaware of the importance of codes for research and quality measurement and are solely focused on the importance of codes for billing. These findings suggest coders, in particular, may benefit from increased latitude to accept a variety of data sources as authoritative, since coders often knowingly enter inaccurate data because they prioritize authority of data sources over accuracy except when billing is at stake.
Ambiguity in clinical data entered by clinicians complicates the ongoing judgments of accuracy that coders and clerks must make. Sociotechnical system-oriented design solutions should be sought to address the prevalence of ambiguous data in the clinical chart by minimizing entry of conflicting data by clinicians in EHRs in the first place and to create minimally burdensome procedures for coders and clerks to query clinicians to clarify ambiguous and discrepant clinical data. Finally, as in other domains, 41 managing the qualculative dimension of healthcare interoperability will require managers to develop new skill sets such as coming to identify and understand situated judgments of data workers and achieving a systems view of the potential future uses of administrative data as they become increasingly important for healthcare research, management, and governance.
The findings of this study resonate with prior work on qualculation that shows that practices such as calculating, classifying, labeling, and framing inherently involve qualitative judgments14,42 and that qualculation involves multiple entities and relations between those entities. 13 The apparatus of qualculation employed by coders and clerks to create administrative healthcare data reflects a push–pull relationship between judgments of accuracy and judgments of authority, conditioned by data workers’ understanding of future uses of administrative data and the relative importance of these different future uses. This research on the microwork of data entry and coding demonstrates that qualculation is fundamental to the creation of standardized coded healthcare datasets—the type of data required for interoperability of healthcare information systems. Furthermore, examining the qualculative dimension of creating standardized coded healthcare data elements also sheds new light on the study of qualculative practices. Prior research on qualculation has not applied a qualculative lens to the ground-level work of producing data elements. These findings demonstrate that qualculation is present in seemingly simple actions such as applying highly controlled coding schemes to less-structured data to create data elements that are then used to perform higher-order calculations (and qualculations) on things like clinical outcomes and quality assessment. In addition, existing studies of qualculation examine how qualculation involves what will count as information and what will not, such as in the seemingly simple four lines of text used to match heart transplant donors with recipients. 14 However, previous studies of qualculation do not examine cases where people knowingly record incorrect data because they are compelled by logics that make recording incorrect data seem the best option under certain circumstances. This study, however, clearly shows that people render data that are incorrect into codes and data fields. More work is needed to unpack the complex logics that underlie qualculation beyond interpretation of information.
Conclusion
Interoperability has been advanced as a key goal of digital health IT. Achieving interoperability requires standardized structured datasets that can be exchanged and interpreted between settings. Using ethnographic methods, this study revealed the effortful qualculations that coders and clerks engage in as they go about producing the codified datasets that are so essential to interoperability. Data entry and coding involve both calculations and complex qualitative judgments about the accuracy and authority of different data sources, judgments that must be balanced against each other. Coders and clerks have limited leeway to query clinicians about discrepancies in clinical charting, which are rampant, and data workers’ perceptions about the importance of different end uses of the data condition the relative weight they accord to judgments of accuracy and authority. This work shows that qualculation is inherent even in seemingly low-level data work and suggests that managers and other stakeholders should seek to manage the qualculative practices of data workers as part of developing capabilities for healthcare data interoperability.
Footnotes
Acknowledgements
The author thanks Christine Wolf, Melissa Mazmanian, Yunan Chen, and Gunnar Ellingsen, who helped shape the conceptual thinking for this paper, and Mary Pauline Lowry, who contributed to data collection and data management. She also thanks all the participants and key informants.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was supported by the National Science Foundation (grant no. 1319897) and the Intel Science and Technology Center for Social Computing.