
Abstract
Suicide takes the lives of nearly a million people each year and it is a tremendous economic burden globally. One important type of suicide risk factor is psychiatric stress. Prior studies mainly use survey data to investigate the association between suicide and stressors. Very few studies have investigated stressor data in electronic health records, mostly due to the data being recorded in narrative text. This study takes the initiative to automatically extract and classify psychiatric stressors from clinical text using natural language processing–based methods. Suicidal behaviors were also identified by keywords. Then, a statistical association analysis between suicide ideations/attempts and stressors extracted from a clinical corpus is conducted. Experimental results show that our natural language processing method could recognize stressor entities with an F-measure of 89.01 percent. Mentions of suicidal behaviors were identified with an F-measure of 97.3 percent. The top three significant stressors associated with suicide are health, pressure, and death, which are similar to previous studies. This study demonstrates the feasibility of using natural language processing approaches to unlock information from psychiatric notes in electronic health record, to facilitate large-scale studies about associations between suicide and psychiatric stressors.
Keywords
Introduction
As the worst acute outcome in psychiatry, suicide takes the lives of nearly a million people globally each year. 1 In addition to death by suicide, the rate of suicide attempts is also very high. Suicidal behaviors have an estimated economic impact of over US$40 billion in the United States. However, due to the low occurrence of, and heterogeneous risk factors for suicidal behaviors, clinicians and researchers face great challenges to detect and address such behaviors. Until now, it has been well established that suicidal ideation, non-fatal and fatal attempts often occur in the context of underlying mental health and substance use disorders. 2 Despite the tremendous efforts spent on prevention and intervention, the suicide rate in the United States has increased from 10 deaths per 100,000 persons in 1955 to 13 per 100,000 in 2014 in the United States, indicating the need for more effective approaches to understand suicide. 3
Current approaches in suicide prevention are often based on suicide risk assessment tables or interviews. However, many patients who had suicide death denied suicidal ideation when assessed, even just 0–7 days prior to their death. 4 Dredze et al. 5 found that participants (or patients) tend to respond to surveys and interviews in ways that they believe are expected (“social desirability bias”) of them, especially for sensitive topics and topics that require patient cooperation. Therefore, asking people directly about suicide ideation or plan may yield less accurate results than observing their behavior. 5
Previous studies have proposed various signs of suicidal behaviors from multiple perspectives. Based on transcripts of cognitive therapy sessions from 35 patients, Adler et al. 6 proposed a set of cognitive warning signs for suicide attempts such as state hopelessness and focus on escape, and so on. World Health Organization 7 proposed that the use of mixed methods was needed for suicide research, in which three key topics were highlighted: risk factors, efficacy of suicide prevention, and cultural factors. Recently, efforts were also made for suicidal behavior analysis and detection from social media data. Wongkoblap et al. 8 conducted a systematic review of mental health research via social media and found that about 17 percent of the research was focused on using text analysis methods for suicidal behaviors. Cohan et al. 9 used a supervised classifier with lexical, psycholinguistic, and topic modeling features to detect posts of self-harm from mental health forum. Similarly, Burnap et al. 10 also used machine learning–based approaches to identify suicide ideation from tweets.
Recently, the implementation of electronic health records (EHR) systems has made large amounts of clinical data available digitally, which has facilitated applications of computational or statistical methods to detect risk factors for suicide ideation/attempts from observational data. 11 Researchers are investigating potential risk factors from various dimensions, including both structured, coded EHR data (e.g. demographic information, mental disorders, and physical disorders) and information (e.g. frequent words, sentiment polarity) extracted from clinical narrative using natural language processing (NLP)–based methods. By analyzing the full spectrum of data in EHR, computerized risk screening approaches may enhance prediction beyond individual analysis by clinicians. 1
One type of essential risk factor of suicide consists of psychiatric stressors,12–14 which are defined as psychosocial or environmental factors (e.g. loss of a loved one, job issues) that can profoundly impact cognition, emotion, and behavior of patients.15,16 Moreover, there is a major category of trauma and stressor-related mental disorders, including adjustment disorders, acute stress disorder, posttraumatic stress disorder, dissociative disorders, and so on. 15 Current association analysis between stressors and suicidal behaviors is mainly dependent on surveys and interviews. Although suicide ideations/attempts and stressors are often recorded in psychiatric notes (see examples in Figure 1), few studies have utilized this type of data, probably due to that psychiatric stressors are often recorded in narrative text in EHR systems and are not directly available for analysis.

Examples of sentences with stressors in psychiatric notes. The mentions of stressors are blue colored; and the mentions of suicide behaviors are red colored.
Therefore, to enable large-scale quantitative analysis of psychiatric stressors and suicidal behavior using EHR data, it is critical to develop automated approaches to extract and structure stressor information from clinical text. However, as illustrated by the examples in Figure 1, psychiatric stressors have several distinctive attributes, making automatic extraction of the information from text extremely challenging. First, stressors are highly unique to the individuals and come from a broad range of psychosocial environments, leading to very sparse distribution of stressors across different patients and clinical notes. In addition, the identification of stressors is greatly dependent on and constrained by contextual information.
This study takes the initiative to automatically extract both mentions of suicidal behaviors and psychiatric stressors from clinical notes using NLP-based methods. Mentions of stressors are further grouped into 15 types and modifiers (such as negation and subject) of each mention are recognized. Subsequently, a statistical association analysis between positive suicide ideations/attempts and stressors of the patients is carried out using the chi-square test. 17 Our evaluation using a clinical corpus shows that the NLP-based methods are capable of extracting both mentions of suicidal behaviors and psychiatric stressors with practical performance. Furthermore, association signals between suicide and psychiatric stressors are similar to previous findings.18–21 To the best of our knowledge, this is one of the first studies for association analysis between stressors and suicides based on automatically extracted information from clinical text using novel NLP approaches.
Materials and methods
System overview
Figure 2 shows an overview of the workflow for detecting stressor signals of suicide. First, the mentions of suicide ideation/attempt and stressors are annotated automatically in psychiatric notes using NLP-based methods. Mentions of stressors are further classified into 15 types to reduce the data sparseness. Then, the modifiers, such as negation, and subject of each mention are recognized. Only positive suicide ideation/attempt and stressor mentions of the patients are kept for further processing. A statistical association analysis between suicide ideations/attempts and stressors is then carried out using the chi-square test. 17 The key components of the systems are presented in the following sections with details.
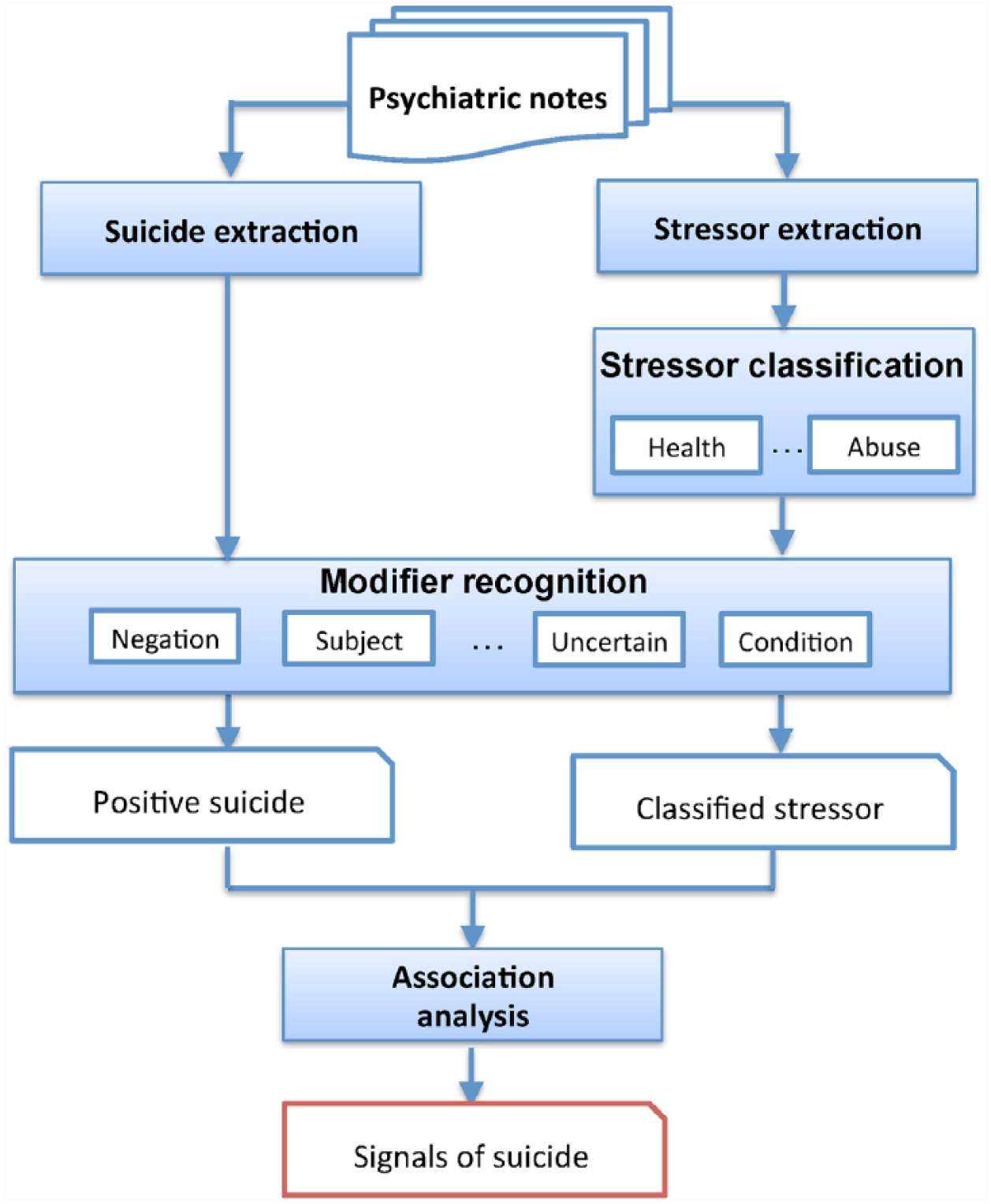
Study design for detecting stressor signals of suicide.
Dataset and annotation
The psychiatric notes from the CEGS N-GRID (Centers of Excellence in Genomic Science Neuropsychiatric Genome-Scale and RDOC Individualized Domains) 2016 challenge organizers are used in this study. 22 The 2016 CEGS N-GRID challenge aims to extract the symptom severity of patients from neuropsychiatric clinical records, which consists of three NLP tracks: Track 1 was de-identification of psychiatric text, Track 2 was the RDOC classification, which is to determine the symptom severity for patients, based on information included in their initial psychiatric evaluation. Finally, Track 3 was for novel use of the dataset: The data released for this 2016 challenge are the first set of mental health records released to the research community. These data can be used for mental health-related research questions that go beyond what is posed by the challenge organizers. The access of the dataset needs to be applied from the i2b2 data portal (https://www.i2b2.org/NLP/DataSets/). As the first corpus of mental health records released to the NLP research community, it contains 909 initial psychiatric evaluation records. Initial psychiatric evaluation records are produced by psychiatrists to document psychiatric signs and symptoms, disorders, and other medical conditions in order to decide the course of treatment. 23 All of the records are de-identified.
The original training set of the CEGS N-GRID 2016 challenge contains two subsets, one with gold-standard annotations of the severity of mental disorders and another is unlabeled. For the convenience of later applications, 409 psychiatric notes were selected from the labeled subset to build the gold-standard corpus of stressors, which was used to generate the automatic tools for suicide recognition, stressor recognition, and classification. An annotation guideline was developed and two annotators were recruited who manually annotated all the psychiatric suicide and stressor mentions in each note by following the guideline. In total, 327 psychiatric notes contained at least one stressor annotation. A total of 151 suicide behaviors were annotated, with a kappa value of 0.90 between the two annotators; 2194 stressors were annotated, with a kappa value of 0.68 between the two annotators.
Suicide behavior recognition
First, clinical records with mentions of suicide ideations/attempts need to be identified. According to the previous study of Anderson et al., 24 suicidal ideation expressions extracted using keywords and patterns from clinical text only have an overlap of 3 percent with International Classification of Diseases—ninth revision (ICD-9) codes, and suicide attempt expressions only have an overlap of 19 percent with ICD-9 codes. 25 Therefore, it is necessary to extract such expressions from clinical text using NLP-based methods; a list of keywords such as “suicidal,” “suicide attempts,” “suicidal ideation/thoughts,” and “suicidality” are used to match mentions of suicide ideation/attempt from psychiatric notes.
Another challenge of collecting positive suicide ideation/attempt expressions of patients is the modifiers of such expressions. As illustrated in Table 1, the modifier could be negation, conditional, and uncertain, and the subject of the suicide mention could be another person instead of the patient. We use the machine learning–based modifier recognition module in the Clinical Language Annotation, Modeling, and Processing Toolkit (CLAMP) 26 to label the modifiers of suicide-related expressions automatically. In addition to suicide mentions in the clinical narrative, whether the patient has a personal history or family history of suicide behavior is also recorded in two structured fields (“Hx of Suicidal Behavior” and “Family History of Suicidal Behavior”) of the psychiatric notes. The values of these two fields (yes/no) are used to verify and adjust the modifiers identified by CLAMP. Finally, the positive suicide ideation/attempt mentions of patients (including both current and patient history) are kept for later association analysis with stressors.
Different types of modifiers for suicide mentions in the context.

Stressor recognition and classification
A hybrid approach for stressor recognition
The identification of stressor mentions can be addressed as a typical named entity recognition (NER) task. In a machine learning–based NER task, the problem is converted into a sequence labeling task by representing each word using specific labels. 27 The BIO labels are commonly used to represent named entities, where “B,” “I,” and “O” denote the beginning, inside, and outside of an entity, respectively. Therefore, the stressor recognition problem was converted into a sequence labeling task, assigning one of the three labels to each word. Figure 3 shows an example of the BIO representation, where the stressor entity “father’s death” is represented as “father/B ’/I s/I death/I” after tokenization.

An example of BIO annotation for psychiatric stressors.
In our previous work on stressor recognition, 28 we mainly used Conditional Random Fields (CRF)-based machine learning methods and a set of features combining basic NLP features, domain knowledge features, and word representation features:
Basic NLP features. The most common NER features including bag-of-words, orthographic information (word patterns, prefixes, and suffixes), syntactic information (POS (part of speech) tags), as well as n-grams of words, POS tags, and their combinations (unigrams, bigrams, and trigrams). 29
Domain knowledge features. Features collected from domain knowledge bases related to various aspects of stressors, including lexicons of stressors, mental disorders, common disorders (i.e. non-mental disorders), negative words (e.g. “sad,” “against”), psychosocial environments (e.g. family members, social relations), and cues of discourse relations (e.g. “in setting of,” “in the context of”). Please find a complete list of terms used in this study in Appendix 1.
Unsupervised word representation features. Word representation features were generated from a corpus of unlabeled clinical documents. Specifically, we used word embeddings that produce a distributional word representation for each word in an unlabeled corpus as a real-valued vector using neural networks.30–32 We used the binarized word embedding feature proposed in 2014 by Guo et al. 33 The intuition of the binarized embedding feature is to discretize the original real-valued matrix of Word embeddings and omit the insignificant dimensions. Specifically, to convert the real values in the original Word embedding matrix MV×D to discrete symbolic values in [+,−, 0], the positive mean MEAN(j)+ and negative mean MEAN(j)− for the jth dimension (column) of MV×D are first calculated as follows
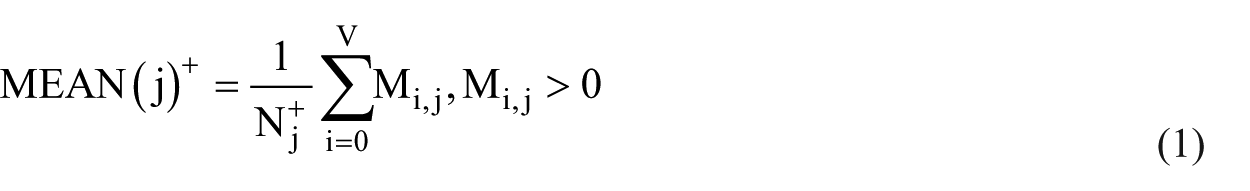
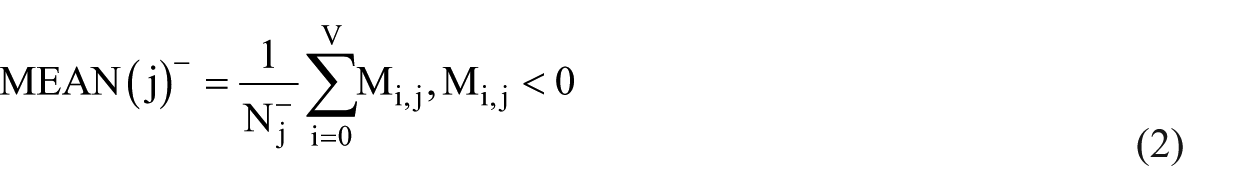
where Nj+ is the total number of rows with jth column M.j > 0, and Nj− is the total number of rows with jth column M.j < 0. Then the discrete-valued matrix M*V×D can be derived by the following projection
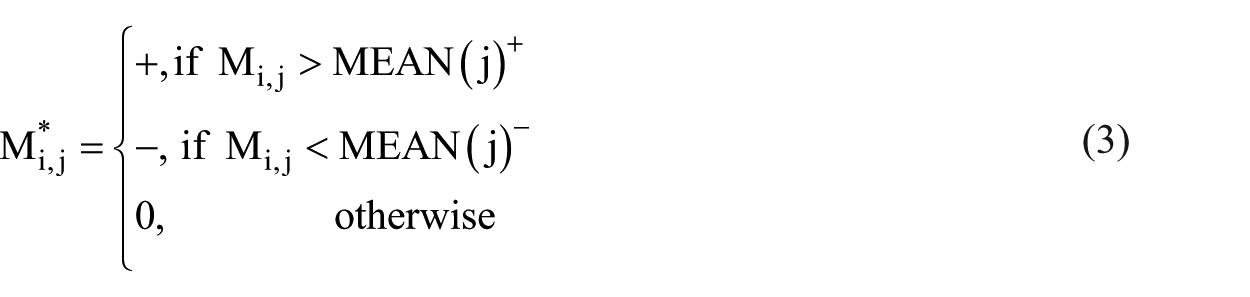
Values in the
The optimal configuration in Guo et al. 33 was used in our study. Specifically, the Skip-gram model is adopted for the original word embedding generation. The negative sampling method is used for optimization, and the asynchronous stochastic gradient descent algorithm (Asynchronous SGD) is applied for parallel weight updating. Since the real values of word embeddings are binarized, only three labels remained for the word embeddings, where “POS” stands for positive, “NEU” stands for zero, and “NEG” stands for negative.
However, the previous stressor recognition systems suffered from a very low recall of 34.7 percent for exact match and 65.5 percent for inexact match, mainly due to the sparseness, long boundaries and complex structures of stressor expressions, conjunctive structures formed by multiple stressor expressions, and the highly unbalanced corpus with a 1:12 ratio between sentences with stressors and the whole set of sentences. In addition to expanding the annotation corpus from 246 psychiatric notes to 327, this study uses the following strategies to address the low recall problem:
Minimal boundary of stressor annotation. To alleviate the sparseness and boundary ambiguity problems of stressors, the most informative text with minimal span was annotated as stressors. For example, in the sentence “Loss of father to cardiac event in December 2083,” “Loss of father” was annotated as the stressor without any further detailed description.
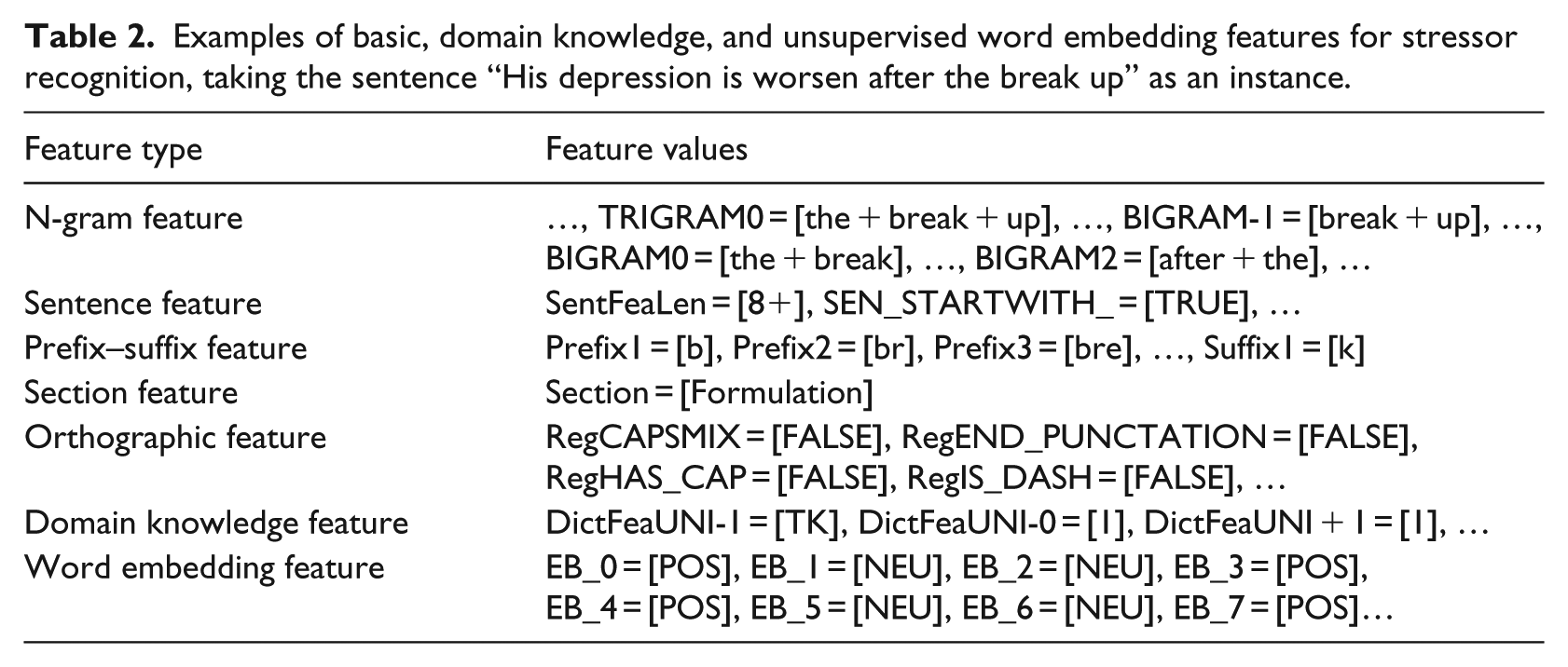
Examples of basic NLP features, domain knowledge features, and unsupervised word embedding features are listed in Table 2. In total, 36 basic NLP features are used for each token, including n-gram features, orthographic features, and so on. The dictionary of domain knowledge–based terms contains 4310 entries in total, including keywords of context, psychiatric symptoms, stressors, other common disorders, and positive and negative words. In addition, the word embedding feature is a binary feature with a value of “POS” or “NEU” for each token.
Examples of basic, domain knowledge, and unsupervised word embedding features for stressor recognition, taking the sentence “His depression is worsen after the break up” as an instance.
Re-weighting features of stressor sentences. The weights of features for each token inside the sentences with stressors are enhanced to 12 based on the proportion between sentences with stressors and the whole set of sentences.
Pattern-based stressor recognition. Considering that multiple stressors are frequently present in conjunctive structures, rules consisting of context patterns and conjunctive structure patterns are employed to label stressors. The output stressors are used as one additional type of feature for the machine learning–based method, to reduce the false positive errors produced by the pure pattern-based method. Some examples of patterns for stressor recognition are listed in Table 3.
Rule-based post-processing. We also used some simple post-processing rules to fix a number of obvious errors by the machine learning–based classifier: (1) conduct a dictionary lookup by exact match in the abstract, using the recognized entities and keywords of stressors as a lexicon. If there is a string that matches the recognized entity or a stressor keyword, then label the string as a new entity. (2) If there is any recognized named entity in a conjunctive structure, the other strings in parallel with the recognized entity will be labeled as new entities.
Examples of patterns for stressor recognition.

The position of candidate stressors is shown in bold.
Stressor classification
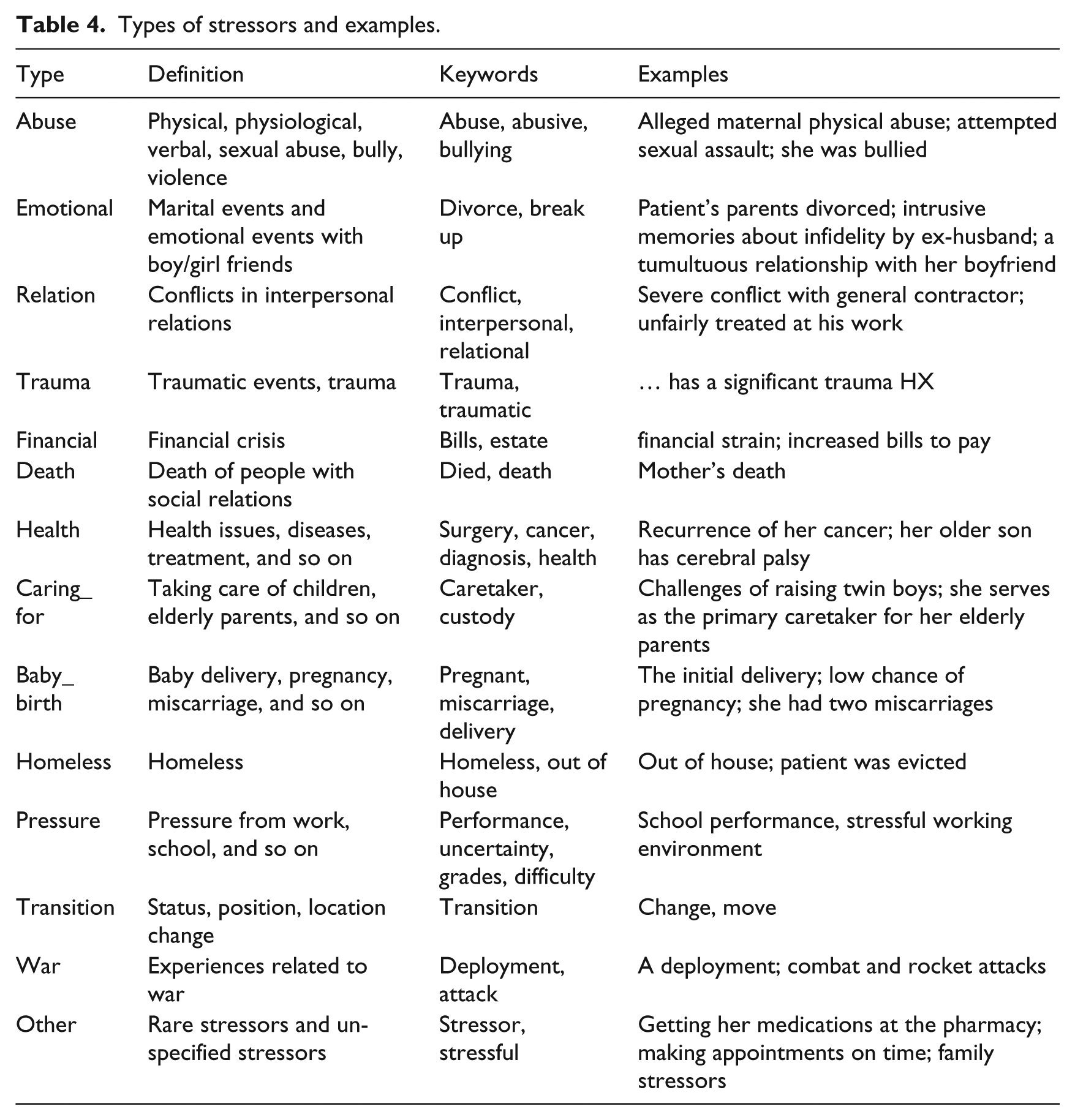
The extracted stressor mentions need to be normalized to different categories, before analyzing their association with suicide ideations/attempts. Based on manual analysis of stressors in the corpus of psychiatric notes used in this study, we summarized 14 different types of stressors, as listed in Table 4. Frequent keywords and patterns of each type of stressors are collected, based on which the stressors are categorized (Table 4).
Types of stressors and examples.
Association signal detection for suicide
To identify the salient signals between stressors and suicide ideations/attempts, contingency tables based on the co-occurrence between suicide mentions and stressors within the same psychiatric notes are generated, and the statistical association between suicide ideations/attempts and stressors is calculated using the chi-square test. Multiple mentions of suicide and stressors in different sections of one psychiatric note are only counted as one time. Furthermore, contingency tables are dropped without association calculation if the value of any entry in this table is lower than 8.
Experiments and evaluation
For experimental evaluation, the 327 clinical notes were separated into a training set of 215 clinical notes and a test set of 112 clinical notes. The optimal configuration of CRF was obtained using 10-fold cross validation on the training set, which were “-a lbfgs –p c2 = 0.9.” Word embedding features were derived from the set of unstructured notes in the Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC II) 34 corpus. To generate word embedding features, we implemented the ranking-based deep neural network algorithm according to the paper from Collobert and Weston 30 using Java.
For stressor recognition, we started with a baseline system that implemented common NLP features. Then, we evaluated the effects of domain knowledge features, unsupervised word representation features, feature re-weighting, pattern-based features, and post-processing by adding each of them incrementally to the baseline system. The systems for automated suicide extraction, stressor recognition, and classification were trained from the training set and the performance of each system on the test set was evaluated using precision, recall, and F-measure, which is the harmonic mean of precision and recall as
Results
Performance of suicide recognition
The suicide expressions are relatively straightforward to recognize in psychiatric notes. Only two phrases of “suicidal tendencies” and “suicidal gestures” in the test corpus were not exactly covered by the list of suicide behavior expressions collected from the training set (Table 5).
Performance of suicide recognition. Both the performance of exact matching and inexact matching are reported (%).

Performance of stressor recognition
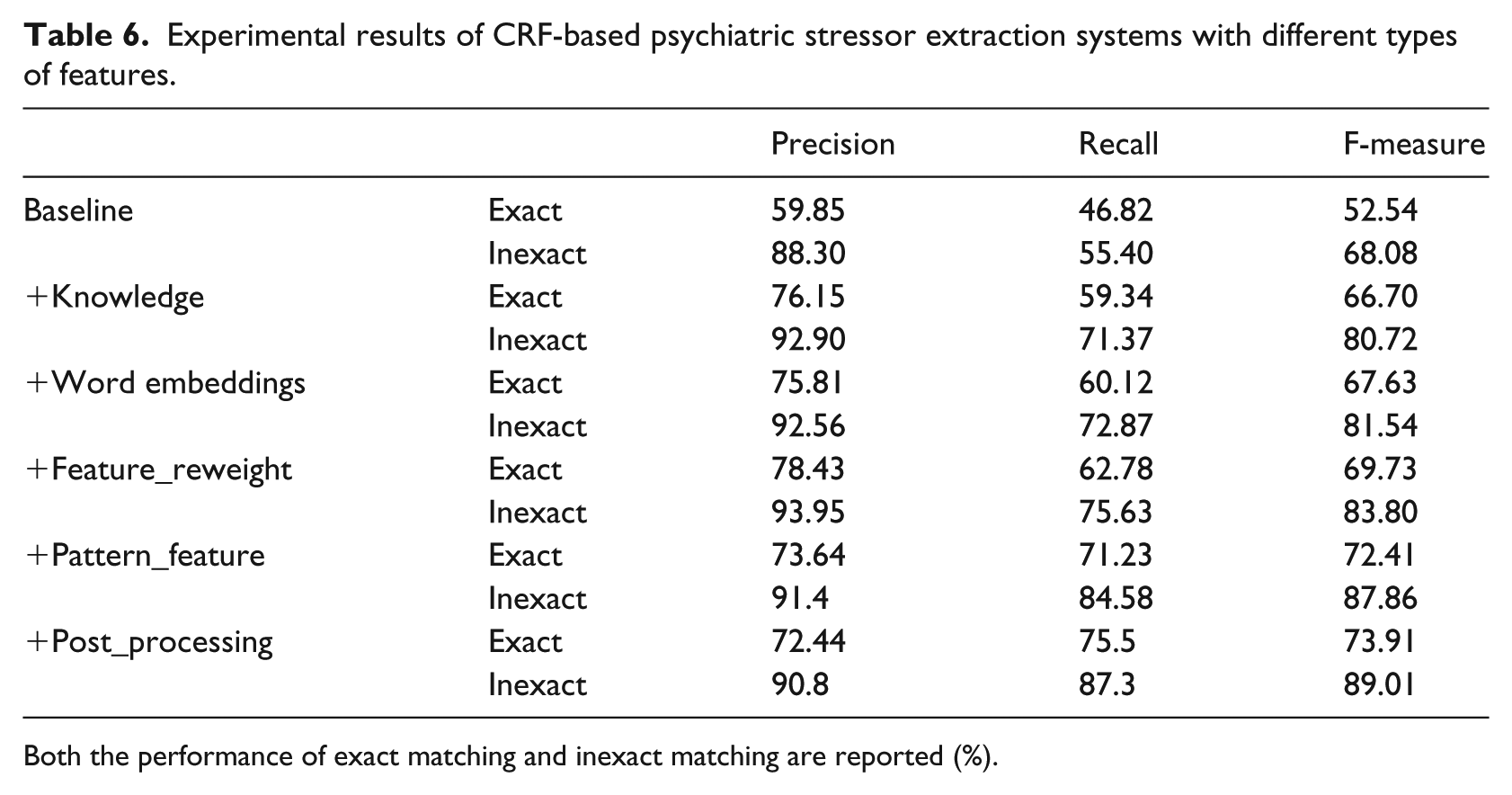
As shown in Table 6, the overall performance of exact matching is relatively poor. Adding domain knowledge features enhanced both the precision and recall and also yielded an F-measure of 66.70 percent. The word embedding features further enhanced the recall (60.12% vs 59.34%) and increased the F-measure to 67.63 percent. The performance increased consistently due to the addition of the feature re-weight strategy, pattern-based features, and post-processing, yielding the optimal F-measure of 73.91 percent.
Experimental results of CRF-based psychiatric stressor extraction systems with different types of features.
Both the performance of exact matching and inexact matching are reported (%).
As for the results of inexact matching, the baseline CRF model yielded high precision, while the recall was still very low (precision: 88.30%, recall: 55.40%). Integrating domain knowledge into CRF significantly enhanced the recall (55.40% vs 71.37%). The word embedding features further improved the recall (71.37% vs 72.87%), with a slight drop in the precision (92.90% vs 92.56%). Both precision and recall were increased by re-weighting the features (93.95% vs 92.56%, 75.63% vs 72.87%). Notably, the pattern-based features and post-processing enhanced the recall most significantly (84.58% vs 75.63%; 87.30% vs 84.58%), with a sacrifice of precision. Overall, the system incorporating all features achieved the optimal F-measure of 89.01 percent.
Performance of stressor classification and distribution of stressors
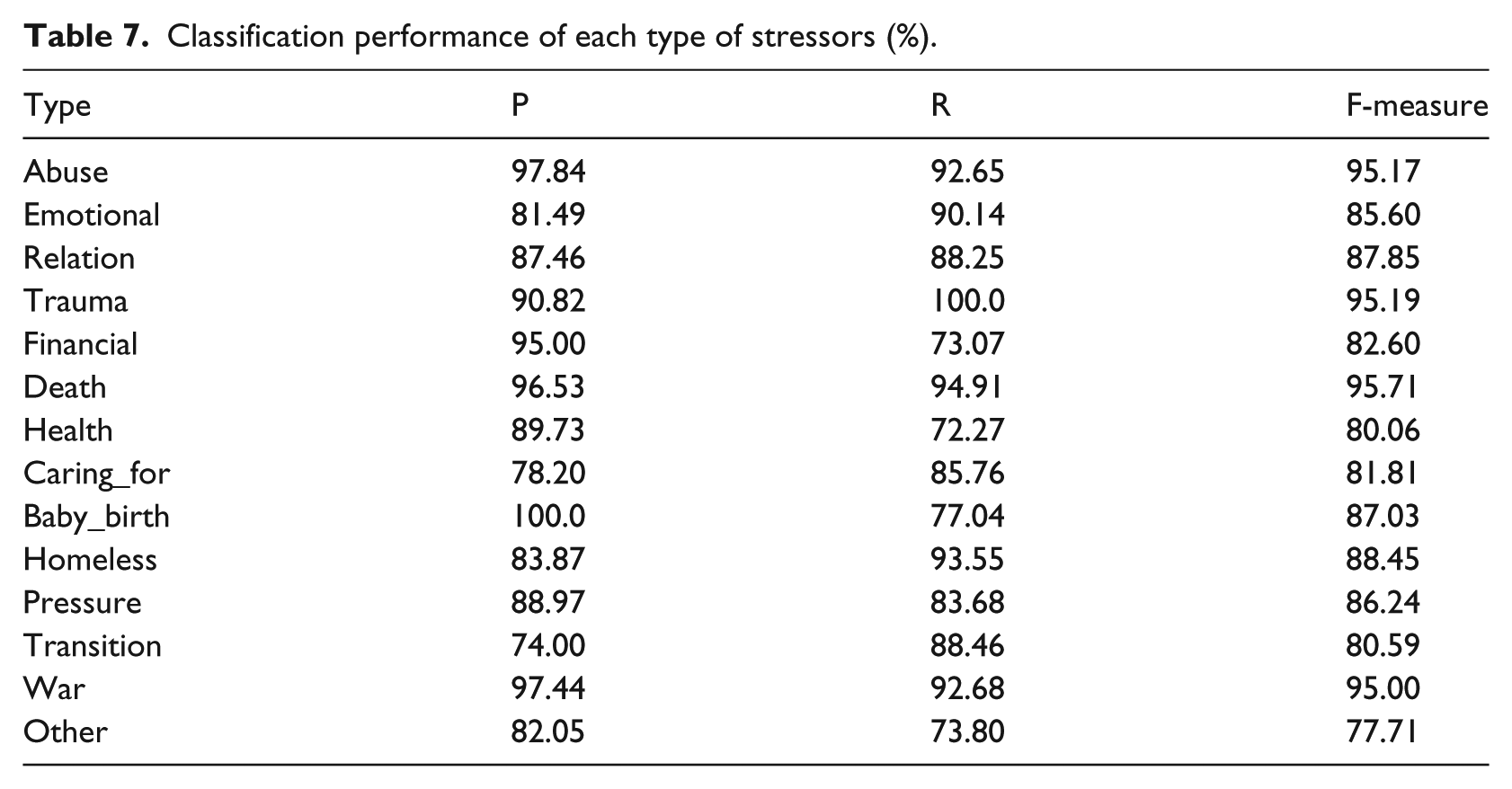
As illustrated in Table 7, the F-measures for classifying Abuse, Trauma, Death, Career, and War are above 90 percent because the keywords of these types are relatively limited and straightforward. The types of Health and Other yielded the lowest F-measure of 80.06 percent and 77.71 percent, respectively. The potential reason for this is that stressors of these two types are more diverse and sparse, and they are not covered comprehensively by the current lexicons and patterns.
Classification performance of each type of stressors (%).
In total, we collected 4794 stressors from 669 psychiatric notes among the whole corpus of 909 notes (327 notes with manual annotation, 342 notes with automatic annotation). Figure 4 illustrates the distribution of each type of stressors. The most frequent stressors are related to issues of emotions, abuse, health, family, and death.
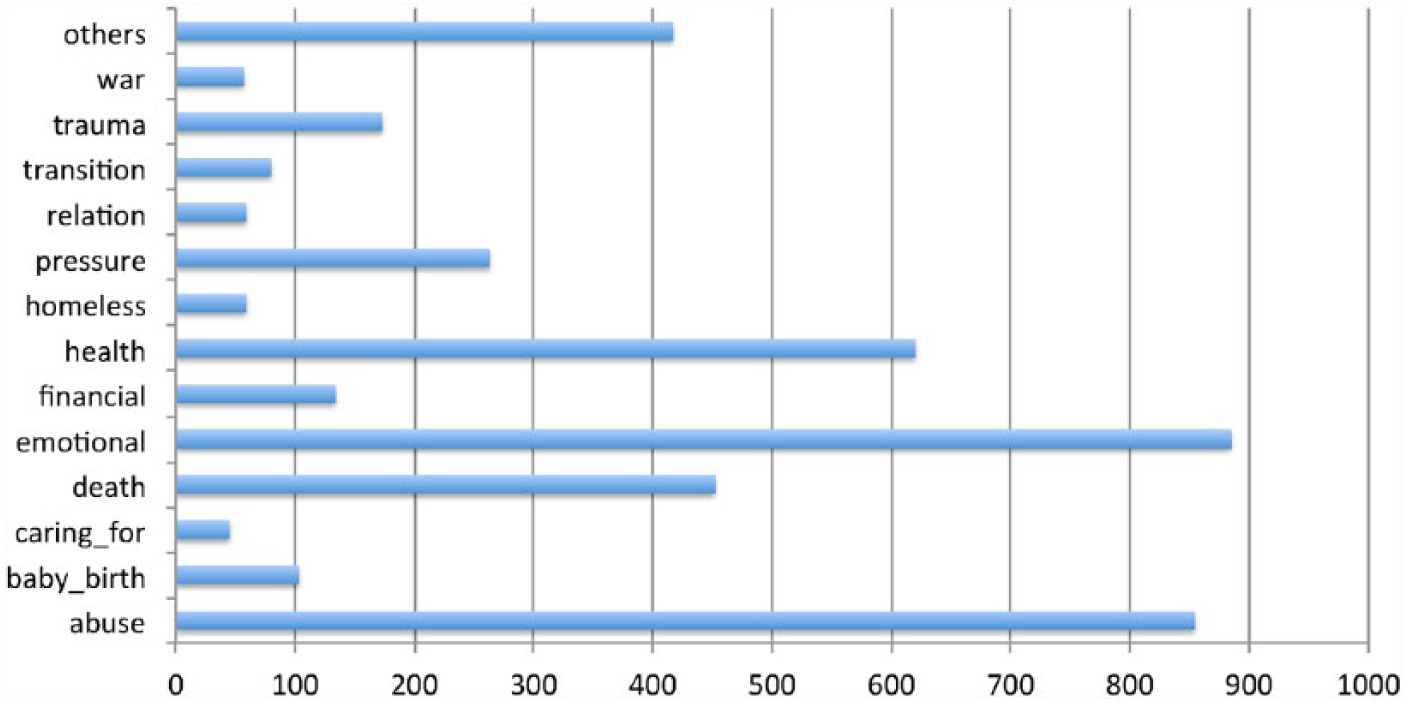
Distribution of different stressor types.
Association between stressors with suicide
Table 8 listed the stressor types of significant associations with suicide behaviors (p < 0.05). Among them, health issues are the most significant signal for suicide behaviors, following by pressure from job or schools, death of family members or people with other social relations, taking care of children or elderly people, and abusive behavior.
Statistically significant association between suicide ideations/attempts and stressors (p < 0.05).

Discussion
The wide implementation of EHR systems provides a novel opportunity to psychiatric research and practice to embrace the “big data” era with rapidly accumulating psychiatric notes available digitally. 22 By analyzing the full spectrum of observational and phenotypic data in EHR, computational and statistical approaches may yield findings beyond individual research. 11 Particularly, as an emerging novel technique to unlock information in psychiatric text in EHRs, NLP-based methods have been adopted for various applications recently, such as negative symptom recognition of schizophrenia, 35 cannabis use identification, 36 and predicting early psychiatric readmission. 37 Researchers are also attempting to differentiate suicidal patients with the others using information extracted automatically by NLP-based methods, including frequent words, 38 sentiment polarity, 39 and expressions in conversations. 40 However, few studies have been carried out on associations between suicide and stressors by leveraging information in psychiatric text. To the best of our knowledge, this is the first study to automatically extract and classify psychiatric stressors using NLP-based methods and conduct statistical association analysis between suicide ideations/attempts and stressors based on clinical narrative. Experimental results show that the employed NLP-based methods can yield promising performance for automatic suicide behavior and stressor extraction.
Existing studies of associations between stressors and suicide behavior mainly rely on survey data collected from patients and people in the same social community where patients at present. Different sets of stressors and related questions are designed for the survey, dependent on the specific cohorts (e.g. youth, 18 adolescents, 13 soldiers 19 ) investigated in the studies. Common significant suicide signals found from previous works include health problems,20,21 abusive experience of patients (particularly from their childhood), 19 and pressure from the social environment. 18 Similar findings are obtained from this study, demonstrating the feasibility of conducting statistical association analysis between suicide and psychiatric stressors using narrative text in EHR.
Although our system showed reasonable performance using inexact matching, challenges remain for stressor information extraction, mainly due to complex syntactic structures and poor formatting in clinical notes. For example, some stressors have multiple modifiers in conjunctive structures (e.g. school and job stressors), with each modifier indicating a different stressor. Special pattern-based rules need to be designed for the identification and classification of such stressors. Indeed, clinical text may be ill-formed due to dependence on the writing habit of physicians. For example, some sentences consist of multiple clauses without any punctuations to connect them syntactically, such as in “Since he and his most recent girlfriend ended their relationship he has been homeless but recently he began receiving housing resources and is in the process of trying to find more permanent housing.” Such ill-formed text may cause boundary errors and false negative errors for stressors. Furthermore, a majority of false negative errors are caused by stressors of rare and complex patterns, which cannot be covered either by machine learning–based methods or by rules. Examples of rare patterns are sentences such as “Recently, there were questions whether the medications would be covered.” and “She and her husband are currently planning to sue husband’ s family over parents’ estate.” Another type of false negative errors is caused by co-reference, as in the sentences of “Her colleague was forced out and there was concern that she might be in a similar situation.” and “I’m a Manager in Public Administration and it’s been stressful.” To resolve such errors, co-reference resolution should be conducted first.
The performance of suicidal behavior recognition reported in our study is much higher than the performance reported in Hammond and Laundry 19 (F-measure: 97.3% vs 83.1%). There are two possible reasons for this comparison: (1) different datasets were used in these two studies. Initial psychiatry evaluation records were used in our study, with relatively straightforward mentions of suicidal behaviors. In contrast, a wide range of clinical documents were used in the study of Hammond and Laundry. 19 Their candidate documents were retrieved using a keyword-based search engine, and the relevance of the documents with suicidal behaviors was not guaranteed. (2) Since a modest dataset of 327 notes was used in this study, the performance may suffer from an overfitting problem. We tried to alleviate this problem using 10-fold cross validation for feature and parameter tuning on the training set and reported the final performance on the test set. More thorough evaluation will be conducted in the future on large-scale datasets with different types of clinical documents like in Hammond and Laundry 19 to examine our method of suicidal behavior identification. Further work should also be conducted in the future to validate the method on multiple datasets such as MIMIC II. Moreover, the domain expert could manually review the stressor extraction and classification results in a random sample of notes to check the feasibility of the method for practical applications.
One limitation of this study is the small sized data of 909 psychiatric notes used for statistical association analysis between suicide and stressors. Despite that similar findings were obtained from this study with previous works using survey data, the limited data size hinders the definition of stressor types with finer granularity and in-depth association analysis focusing on specific cohorts with different demographic information. Another limitation of this work is that we mainly used the CRF algorithm for psychiatric stressor recognition. The algorithm was chosen because it was widely applied with a strong performance of NER. We will compare the CRF algorithm and other machine learning–based methods including the deep learning–based methods for stressor recognition in the next step. Besides, the longitudinal development paths of stressors are not considered in our current analysis. Acute and chronic stressors may have different roles in the formation of suicide ideations/attempts. 41 Temporal modifiers of suicide behaviors and stressors will also be recognized using NLP-based methods in the near future to stratify stressors of different association with suicide behaviors. In addition, except for statistical associations, NLP-based systems could also be developed to extract the direct cause–effect relation between suicide behaviors and stressors from clinical narrative, so that more precise stressor signals of suicide behaviors can be obtained.
Conclusion
This study takes the initiative to automatically extract and classify psychiatric stressors from clinical text using NLP-based methods and conduct a statistical association analysis with suicide behaviors. Experimental results demonstrate the feasibility of using NLP approaches to unlock information from psychiatric notes in EHR, in order to facilitate large-scale studies about associations between suicide and psychiatric stressors.
Footnotes
Appendix 1
Acknowledgements
We thank the organizers of the CEGS N-GRID 2016 challenge for providing the corpus.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: H.X. is a founder of Melax Technologies, Inc., which licenses the CLAMP software.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Library of Medicine (grant number 2R01LM010681-05).