
Abstract
Prenatal clinical notes in electronic medical records contain a wealth of information on pregnancy complications and outcomes. Extracting this critical information provides a unique opportunity for risk assessment to identify at-risk patients who may benefit from early monitoring and intervention. We developed and validated a rule-based computerized algorithm called PregHisEx to characterize past obstetrical history (preeclampsia/eclampsia) by mining prenatal clinical notes for women delivered in 2012 within a large healthcare maintenance organization. The algorithm successfully identified cases with past history of preeclampsia/eclampsia: 2984 definite and 479 probable cases at sentence level; 2419 definite and 348 probable cases at note level; and 762 definite and 82 probable cases at pregnancy episode level. Validation conducted on a random sample of 200 notes using PregHisEx yielded 88.0 percent sensitivity, 98.9 percent specificity, 91.7 percent positive predictive value, 98.3 percent negative predictive value, and F-score of 0.90. The high-performing PregHisEx can be applied for other prenatal conditions.
Keywords
Introduction
Preeclampsia/eclampsia (PE/E), a disorder characterized by hypertension and proteinuria, affects approximately 3 percent to 8 percent of all pregnancies and is the most feared pregnancy-related complication, carrying an increased risk of maternal and infant morbidity and mortality. 1 The etiology of PE/E is presently unknown, although several potential risk factors have been suggested including nulliparity, advanced maternal age, nonwhite race/ethnicity, multifetal gestation, being overweight or obese, excessive pregnancy weight gain, chronic hypertension, and renal disease.1–5 Women with a previous history of PE/E are at increased risk of recurrence in subsequent pregnancies. 4 Therefore, great emphasis must be given toward reviewing a detailed obstetric history in order to identify women that are at-risk of adverse prenatal outcomes and may benefit from close monitoring and early intervention. Obstetricians traditionally rely on administrative structured data to identify these at-risk pregnant women. However, findings from recent studies showed that the validity of extracting accurate maternal medical history from administrative structured data varied from 37 percent to 93 percent. 6 The status of pregnancy-related complications such as preeclampsia occurring in current and previous pregnancies (i.e. history of preeclampsia) is usually documented in the clinical notes by healthcare providers during routine prenatal care visits formatted in the form of unstructured free-text. Due to the complexity and variability of clinical information formatted in free-text, the ability to efficiently and accurately extract meaningful information from these unstructured texts is challenging. A lengthy and costly manual review of these data is often engaged. Therefore, developing a systematic and reliable method of extracting information on current or past history of medical and obstetrical complications from the clinical notes has major beneficial implications in the advancement of preventive strategies and management of patient care for high-risk pregnancies.
It is well known that the clinical notes in electronic medical records (EMRs) are somewhat disorganized due to the free style format. Embedded special characters, mistyped or misspelled words, and multiple concatenated words without separate tokens are commonly seen in clinical notes. Furthermore, various specific abbreviations are also frequently used in clinical notes. For example, “history” is abbreviated as “HX” and “chronic hypertension” as “CHTN.” The use of abbreviations can be varied by healthcare organizations as well as healthcare providers. There are numerous abbreviations for prenatal conditions, especially for those related to adverse outcomes and procedures. For example, “CSD” is an abbreviation for “cesarean section delivery” and “NSVD” for “normal spontaneous vaginal delivery.”
Natural language processing (NLP) is a field of computer-based methods aimed at standardizing and analyzing various natural (human) languages including unstructured clinical notes. It is an invaluable tool used to convert information residing in the natural language into a more structured format for research purposes. A number of NLP systems have been successfully developed and implemented in various clinical domains with varying focuses. To name a few, the Clinical Text Analysis and Knowledge Extraction System (cTAKES) was used to process clinical documents on smoking status. 7 The Cancer Text Information Extraction System (caTIES) was used to identify potential cancer cases from pathology reports. 8 Other examples include the application for retrieving disease information from radiology reports, 9 the NegEx for identifying negated findings, 10 and the application for extracting family history from textual clinical reports.11–13 A typical NLP application usually includes a free-text preprocessing pipeline consisting of text cleaning and standardization, word tokenization, section detection, sentence splitting, and so on. 14 When a NLP system is used to identify diseases or specific events, it usually requires the implementation of a NegEx pipeline to negate and rule out diseases or specific events. 10 Furthermore, the NLP system needs to determine whether the corresponding condition is a current or past history of the medical condition. Although each NLP application applies some specific processes to determine the disease history status and generate meaningful information for patient care and decision-making, classifying disease history is still very challenging, especially historical medical conditions described during prenatal care visits. For example, when collecting data on obstetric and medical conditions from medical records, the term “history” may indicate a condition that occurred in previous pregnancies or in the early stages of the index pregnancy. Therefore, accurately ascertaining the status of a pregnancy-related condition or complication is critical and important in supporting prenatal research and clinical care. There is no general algorithm that has been developed to systematically process disease history to fit all patient conditions and circumstances accurately.
Pregnancy-related complications and their statuses (current or past history) are routinely noted in prenatal clinical notes. Extracting these from unstructured prenatal clinical notes and converting them into a structured format can help clinicians deliver and manage care in a more timely and efficient manner, minimizing adverse maternal and fetal outcomes. Recently, Knowles et al. 15 leveraged the machine learning and NLP techniques to detect at-risk pregnancies. Their focus was on flagging high-risk cases for further review by clinicians rather than identifying pregnancy-related complications and their statuses. PE/E, a transient but potentially dangerous complication,1,2,5 is associated with an array of adverse maternal and fetal outcomes 16 with an increasing secular trend over time in the overall affected percentage or incidence rate. 17 Therefore, the objective of this study is to develop a systematic and rule-based computerized algorithm to accurately identify past history of PE/E from prenatal clinical notes and then automate the extraction process to better support prenatal research and translate the findings into patient care.
Methods
Our organization is an integrated healthcare delivery system composed of 14 hospitals and more than 220 satellite medical offices throughout southern California with a comprehensive EMR system, providing services to over 4.5 million active members. 18 The average annual pregnancies delivered in our system is approximately 36,000 in recent years. Patient medical records which included various free-text clinical notes on past and current obstetrical services were maintained and archived in the EMR system. Obstetric records were retrospectively extracted from a Perinatal Service System for all women who delivered in our hospital setting during 2012. For each individual, corresponding clinical notes from prenatal service visits starting from the last menstrual period date (or 280 days prior to the delivery date if missing) to 30 days after delivery were extracted. Patient instructional notes were excluded from the process as these notes usually contained generic descriptions and explanations on medical and obstetrical complications rather than on the diagnosis of interest. The study was approved by our Institutional Review Board, with waiver of informed consent.
Clinical notes for computerized algorithm development, validation, and implementation
A total of 2,776,199 prenatal clinical notes were extracted from the EMR system. Of these notes, 20 percent (n = 555,240) were randomly selected and used as training notes for the computerized algorithm development. The remaining notes were used for algorithm validation and implementation.
Clinical notes cleaning, standardization, and segmentation
Due to the complicated and unstructured free-text format of clinical notes in the EMR, to improve the algorithm accuracy, preprocessing steps were implemented to clean and standardize the clinical notes. First, non-meaningful or invisible special characters were removed from the clinical notes, such as “return carriage” and special symbols. Second, a set of 96 mistyped, misspelled, or concatenated words detected from our development training notes were corrected and automatically applied to the clinical notes used for validation. For example, “likely” was mistyped as “likley,” “previous” as “previosu,” “eclampsia” as “ec+lampsia,” and the two words “1 pregnancy” was concatenated as “1pregnancy.” Third, a set of phrases related to the patient’s history, pregnancy delivery, pregnancy-related procedures, and abbreviations (see Appendix 1 for the complete list) were expanded for regular expression matching if they appeared in the clinical notes. Because both uppercase and lowercase characters were frequently used in the free-text note, all letter characters in a clinical note were converted to uppercase for easy program processing and for enhancing the performance of the computerized algorithm. Finally, the clean and standardized notes were split into sections, paragraphs, and sentences using the Natural Language Toolkit (NLTK) to split paragraphs and sentences, 19 ConTextNLP to split sentences and detect sections, 20 and some specific characters in our EMR system to indicate the end of sections and sentences.
Algorithm development and processing at sentence level
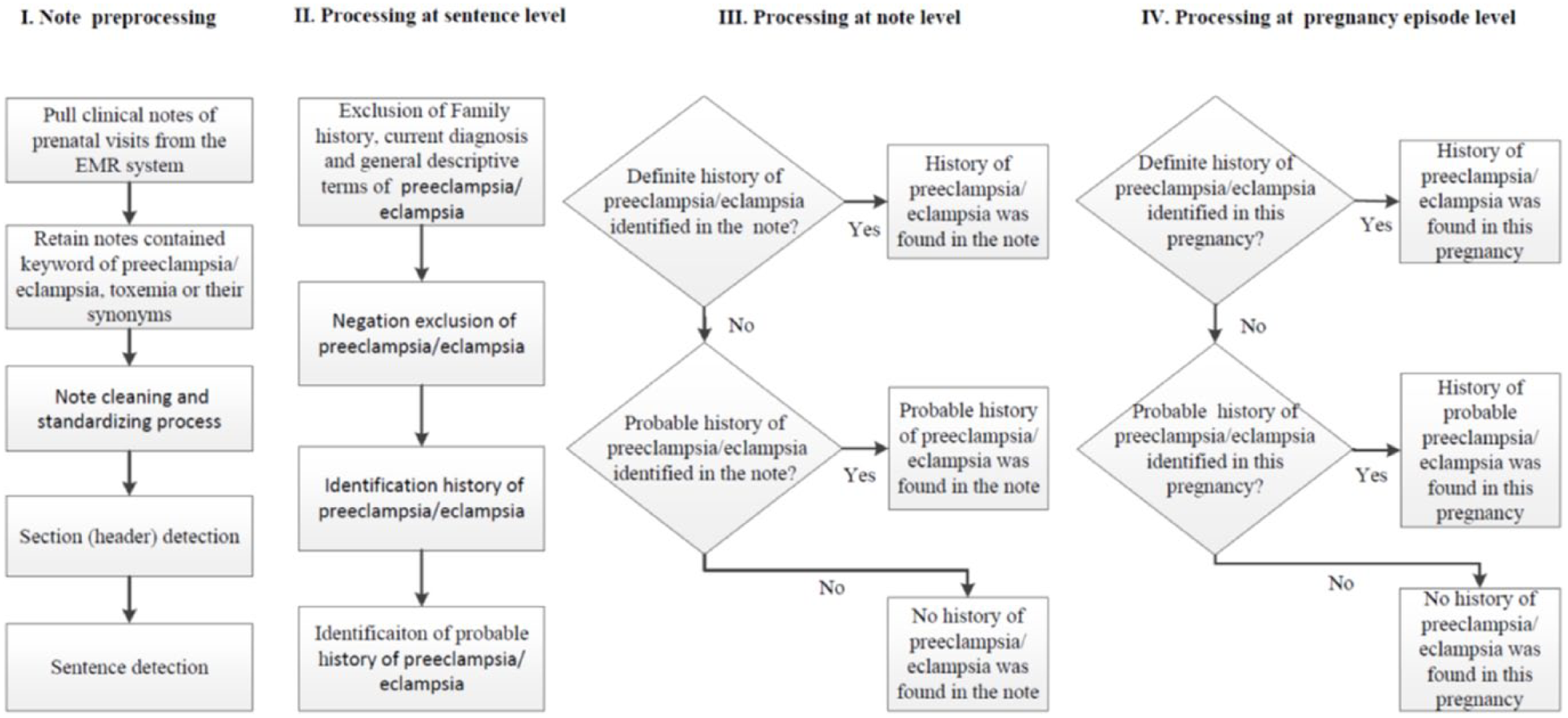
For each sentence, a rule-based computerized algorithm called PregHisEx was devised to ascertain if a pregnancy-related complication described in the prenatal clinical notes was an event that occurred in a previous pregnancy. The algorithm of PregHisEx was based on the training notes. We first chose to identify PE/E as it is one of the most serious pregnancy-related complication. A set of PE/E terms (referred as <PE/E> within this entire article) including preeclampsia, eclampsia, toxemia, and their synonyms or abbreviations was first identified using the Unified Medical Language System (UMLS) application 21 and confirmed by an experienced and professional prenatal expert. Pregnancy-induced hypertension (PIH), a separate disorder characterized by a rise in blood pressure without proteinuria, was not included in the search list. A set of iteratively refined sequencing rules were derived and summarized from sentences containing the <PE/E> term in the training notes to determine whether it was truly a past pregnancy diagnosis. The processing flow of identifying any history of PE/E condition is shown in Figure 1 and summarized in the following steps:
Search the sentences to determine whether they contained any term in <PE/E>. If no term was found, the processing stopped and no history of PE/E was identified. If multiple terms were found within a sentence, subsequent steps were independently applied to each term with the sub-sentence starting from the first word token followed by the previous term. If there was no identifiable previous term, the beginning of the sentence to the word token just before the next term was used. If there was no additional identifiable next term, the end of the sentence was used. For example, there were two preeclampsia terms in the sentence “subjective: patient feels better, she has no preeclampsia symptoms but patient had preeclampsia with her last pregnancy.” The first term was negated while the second term was a history of preeclampsia that occurred in a previous pregnancy.
Exclude family history, current diagnosis, and non-historically related general descriptions or explanations preceded or followed by the <PE/E> term. If any of the following conditions were satisfied, the history of PE/E was classified as “no” and the identifying process stopped. Any of the phrases “family history problem relation,” “supervision of normal first pregnancy,” or “advanced maternal ages first pregnancy” appeared in the sentence. These phrases described either family-related problems or the current pregnancy episode. A female family member or immediate relative description (see Appendix 2 for details) was preceded by the <PE/E> term:
<Female family member or immediate relative> word tokens (0,2) <PE/E>
The flow diagram of the process to identify history of PE/E from prenatal clinical notes.
where word tokens (0,2) represents zero to two word tokens allowed between the two sets of terms.
(c) A corresponding current diagnosis code was preceded by or followed by the <PE/E> term: <Diagnosis codes> word tokens (0,2) <PE/E> or
<PE/E> word tokens (0,2) <Diagnosis code>
For example, 642.xx was the corresponding diagnosis code of preeclampsia that occurred in the current pregnancy.
(d) Any phrase in the set of non-historically related or generally described phrases (summarized from the training notes) appeared either in the front of or after the PE/E term: <Non-history or general related phrase> <PE/E> or
<PE/E> <Non-history or general related phrase>
This pattern expression required no word token between <non-history related phrase> and <PE/E>. For example, “preeclampsia consultations,” “preeclampsia discussions.” See Appendix 2 for the full list of excluded phrases.
3. Apply a set of pre-term and post-term negation phrases described in the NegEx pipeline
20
to determine whether the <PE/E> term was explicitly negated in the sentence: <Pre-term negation phrase> word tokens (0,6) <PE/E> or
<PE/E> word tokens (0,6) <Post-term negation phrase>
The word tokens between the bracket terms should not have contained any of the stop words described in the NegEx pipeline. 20 If any of the above negated expressions (either pre-term negation or post-term negation) appeared in the sentence except for the pseudo negation or double negated phrases, the <PE/E> term was negated and the identifying process was stopped.
4. Apply a set of historically related pregnancy phrases (a total of 16) that preceded or followed the <PE/E> term to ascertain the history status. If any of the following pattern expressions were true, the history status was assigned as “Yes” temporarily. The word tokens between the bracket terms should not have contained any of the stop words described in step 3 or words/phrases related to the current pregnancy episode as listed in Appendix 2. <Described previous phrase> word token (0,1) <PE/E>. The list of <Described previous phrase> included “last,” “previous,” “past,” “prior,” and their abbreviations. However, the pattern “prior to preeclampsia” was excluded because it did not describe the condition as related to a previous pregnancy. <Described previous phrase> word token (0,1) <Pregnancy, birth and delivery related event> word tokens (0,6) <Preposition phrase> word token (0,1) <PE/E>. The phrases of <pregnancy, birth and delivery related events> included “pregnancy,” “delivery,” “demises,” “cesarean section,” and so on, where the preposition phrase contained words such as “with,” “for,” “due to,” “because of.” See Appendix 2 for the complete list of these two phrases. For example, “patient had a previous delivery with preeclampsia.” <Described history phrase> word token (0,1) <Pregnancy, birth and delivery related event> word tokens (0,6) <Preposition phrase> word token (0,1) <PE/E>. The history phrases included “history,” “history of,” their abbreviations and plural forms. For example, “history of cesarean section at 33 6/7 weeks due to severe preeclampsia and remote from delivery.” See Appendix 2 for the complete list of history phrases. The <Number phrase> word tokens (0,6) <Preposition phrase> word token (0,1) <PE/E>. See Appendix 2 for a complete list of <number phrase> described pregnancy-, birth-, and delivery-related events. For example, “the first one due to eclampsia.” <Pregnancy, birth and delivery related event> <x|times?> <Number description> word tokens (0,6) <Preposition phrase> word token (0,1) <PE/E>. The <Number description> can be a numerical value or a word, such as “1”, “2”, “one”, “two”. The symbol “?” meant that the preceding letter “s” could be missing or appear once. For example, “cesarean section x 1 for preeclampsia and preterm delivery at 33 weeks.” <Described previous phrase> word token (0,1) <Described history phrase> word tokens (0,6) <Preposition phrase> word tokens (0,1) <PE/E>. For example, “prior history of cesarean section at 28 weeks for preeclampsia.” <Described previous phrase> word token (0,1) <pregnancy and delivery related event>: word tokens (*) <PE/E>. The symbol “*” indicated zero or any number of word tokens. For example, “previous pregnancy: preeclampsia, pregnancy-induced hypertension, preterm labor.” <Described previous phrase> word token (0,1) <Described history phrase>: word tokens (*) <PE/E>. For example, “past ob history: preeclampsia at term.” <PE/E> word tokens (0,6) <Preposition phrase> word tokens (0,6) <Described previous phrase or number description> word tokens (0,2) <Pregnancy and delivery related event>. For example, “she had a preeclampsia in last pregnancy.” <PE/E> word tokens (0,6) <years?|\d\d months?> <ago|before>. The “|” represents “or” and “\d” indicates any numerical value. For example, “she had preeclampsia 1 year ago.” <PE/E> <at|during|in|within> that <time|year>. For example, “she had severe preeclampsia at that year.” <PE/E> word tokens (0,6) <Number description> out of <Number description> <Pregnancy and delivery related event>. For example, “the patient has preeclampsia two out of four her pregnancies.” <PE/E> word tokens (0,6) <x|times?> <number description>. For example, “preeclampsia x 2 pregnancy but deliveries at term.” <Described history phrase> word token (0,1) <PE/E> word tokens (0,6) <patient of answer|poa> Yes. This was in regards to questions and answers on the history of pregnancy-related complications that were embedded in the clinical notes. For example, “history of preeclampsia? poa: yes.” <Described history phrase> word token (0,1) <PE/E> word tokens (0,6) <Gestational age>. The <Gestational age> was required to be greater than the gestational age for the current pregnancy episode in the clinical notes on the associated visit date. This indicated that the description of PE/E and gestational age was related to a previous pregnancy rather than current pregnancy. Search the date associated with <PE/E>. The closest associated dates preceding or following the <PE/E> had to be prior to the pregnancy last menstrual date or the closest associated year had to be one or more years prior to the current pregnancy year. For example, “induction of labor in 2008 for severe preeclampsia at 30w.”
5. Apply probable terms to determine whether the history flag assigned in the above step 4 was a “definite” or “probable” case. If any of the following patterns: <Pre-term probable phrase> word tokens (0,6) <PE/E> or
<PE/E> word tokens (0,6) <Post-term probable phrase>
was true, then the case identified in step 4 was classified as a “probable” history; otherwise, it was classified as a “definite” history case. The probable phrases included “possible,” “presumptive,” and so on. The complete list is shown in Appendix 2. An example of a “definite” or “probable” history of preeclampsia case was “past ob gyn history: possible preeclampsia with first pregnancy.”
Algorithm to determine the history of PE/E at the clinical note and pregnancy episode level
After the above steps were processed, the history of PE/E diagnosis was classified as “definite,” “probable,” or “no” for each sentence. However, a clinical note may have had one or multiple sentences describing a PE/E condition. Thus, a logic process was developed to determine the history of PE/E at the note level using the following prioritization:
If the history of PE/E was classified as “definite” for at least one sentence within the clinical note, then “definite” history indicator was assigned at the note level regardless of the status of other sentences. If this was not true, the next step was applied.
If any sentence within the clinical note was classified as a “probable” history condition, then a “probable” history indicator was assigned at the note level. Otherwise, the history indicator was assigned as “no.”
Finally, the above priority was also applied to determine the history of PE/E (“definite,” “probable,” or “no”) within each pregnancy episode. Specifically
If any clinical note was associated with a pregnancy episode, it was classified as a “definite” history condition. A “definite” history indicator was assigned at the pregnancy episode level regardless of the level status of other notes. If this was not true, the next step was applied.
If any clinical note within the pregnancy episode was classified as a “probable” history condition, then a “probable” history indicator was assigned at the pregnancy episode level. Otherwise, the history indicator was assigned as “no.”
Computerized algorithm evaluations
A sample of 200 clinical notes containing at least one <PE/E> term was randomly selected from the non-training prenatal clinical notes. A perinatal research expert (D.G.) reviewed each note and classified the history of PE/E for each note as “definite,” “probable,” or “no.” The results served as the “gold standard” to be compared with the results from the computerized algorithm. The measure of accuracy, including sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and the overall accurate measure F-score, was calculated. Sensitivity (recall) was defined as the number of clinical notes in which history of PE/E was correctly identified by the computerized algorithm (same as the manual results and either classified as “definite” or “probable”) divided by the total number of clinical notes where PE/E was classified as “definite” or “probable” by the prenatal expert. Specificity was defined as the number of clinical notes without history of PE/E that were correctly identified by the computerized algorithm divided by the total number of clinical notes without history of PE/E classified by the prenatal expert. PPV (precision) was defined as the number of clinical notes in which history of PE/E was correctly classified as being the same as the manual results (“definite” or “probable”) divided by the total number of clinical notes in which the history of PE/E was classified as “definite” or “probable” by the computerized algorithm. NPV was defined as the number of clinical notes without history of PE/E that was correctly classified as being the same as the manual results divided by the total number of clinical notes without history of PE/E classified by the computerized algorithm. The F-score was calculated as
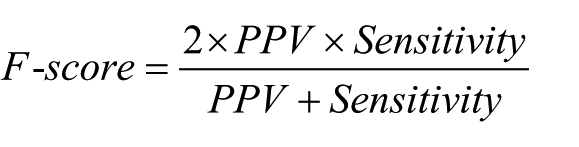
Implementation to identify the history of PE/E
The developed computerized algorithm PregHisEx was implemented through Python programming 22 on a high-performance Linux server to identify the history of PE/E from associated clinical notes from all prenatal visits for pregnancies delivered between 1 January 2012 and 31 December 2012. The computerized results were summarized and analyzed at the sentence, note, and pregnancy episode levels.
Results
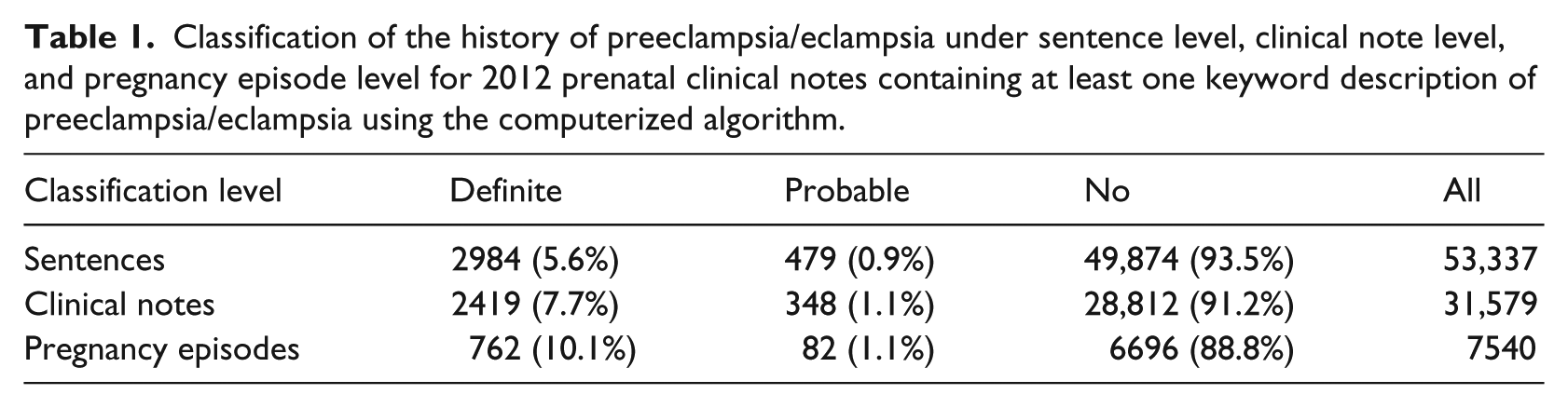
A total of 34,969 women delivered in 2012 at our hospital settings, for whom 2,776,199 clinical notes were generated during their prenatal care visits. Of these notes, there were 31,579 (~1.1%) clinical notes and 53,337 sentences containing at least one PE/E term. In the sentences that included the PE/E term, a total of 2984 (5.6%), 479 (0.9%), and 49,874 (93.5%) sentences were identified as “definite,” “probable,” and “no” history of PE/E in a prior pregnancy, respectively (Table 1). At the note level, a total of 2419 (7.7%) and 348 (1.1%) clinical notes were classified with “definite” and “probable” history of PE/E in a prior pregnancy, respectively. Finally, a total of 762 (10.1%) pregnant women were identified as “definite” and 82 (1.1%) pregnant women were identified as “probable” history of PE/E in a prior pregnancy.
Classification of the history of preeclampsia/eclampsia under sentence level, clinical note level, and pregnancy episode level for 2012 prenatal clinical notes containing at least one keyword description of preeclampsia/eclampsia using the computerized algorithm.
Data on the comparison of computerized results versus the prenatal expert manual results for 200 randomly selected clinical notes from the non-training clinical notes are shown in Table 2. The NLP computerized algorithm achieved a high accuracy performance in capturing prior history data (sensitivity (88.0%), specificity (98.9%), PPV (91.7%), NPV (98.3%), and F-score (0.90)).
Comparison of the performance of the natural language processing algorithm for the history of preeclampsia/eclampsia against prenatal expert manual reviews for 200 randomly selected prenatal clinical notes containing at least one keyword of preeclampsia/eclampsia.
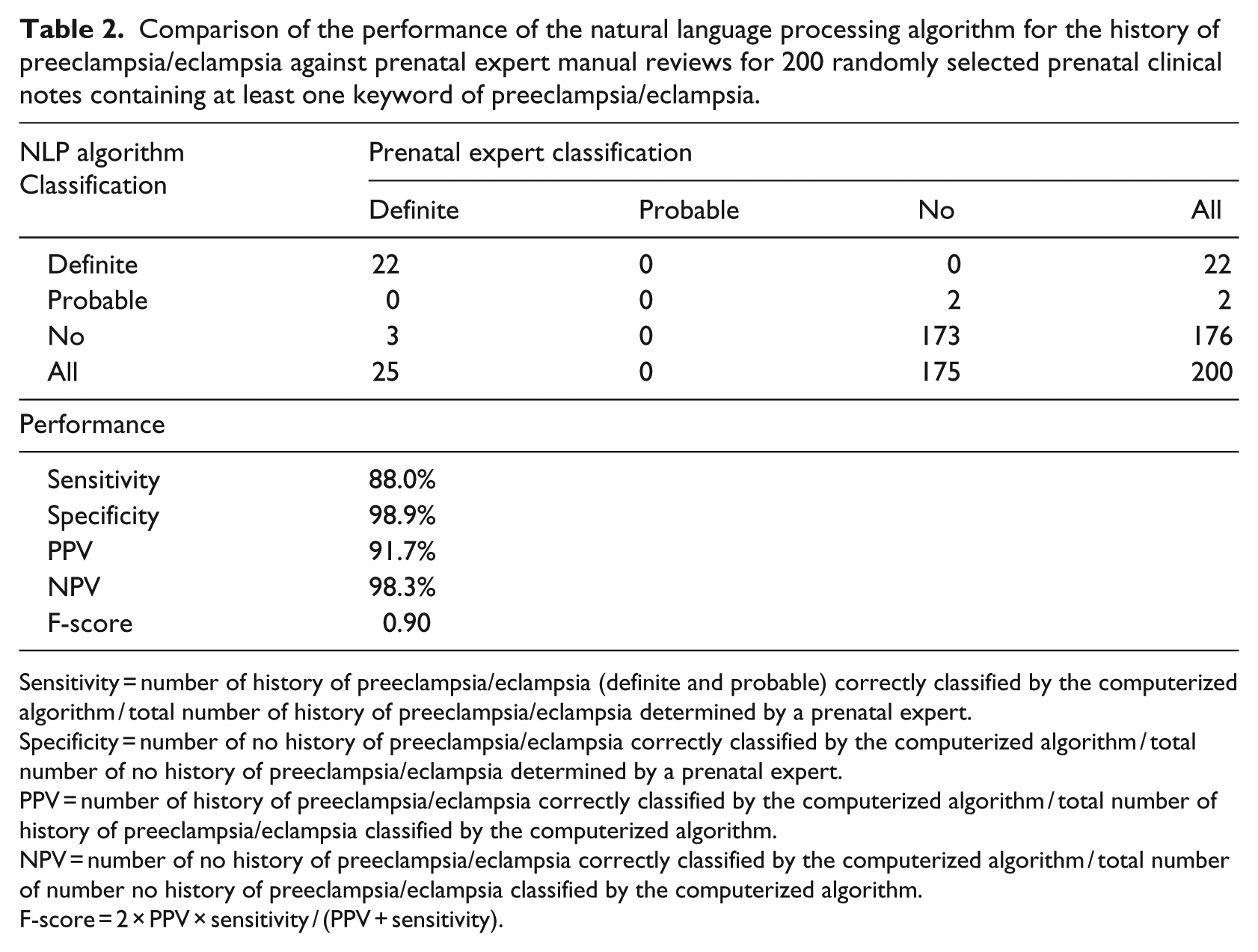
Sensitivity = number of history of preeclampsia/eclampsia (definite and probable) correctly classified by the computerized algorithm / total number of history of preeclampsia/eclampsia determined by a prenatal expert.
Specificity = number of no history of preeclampsia/eclampsia correctly classified by the computerized algorithm / total number of no history of preeclampsia/eclampsia determined by a prenatal expert.
PPV = number of history of preeclampsia/eclampsia correctly classified by the computerized algorithm / total number of history of preeclampsia/eclampsia classified by the computerized algorithm.
NPV = number of no history of preeclampsia/eclampsia correctly classified by the computerized algorithm / total number of number no history of preeclampsia/eclampsia classified by the computerized algorithm.
F-score = 2 × PPV × sensitivity / (PPV + sensitivity).
Discussions
The timely and accurate identification of medical and obstetrical complications occurring in a previous pregnancy is critical for prenatal research studies1–7and quality improvement of high-risk pregnancies. 23 In this study, we developed a rule-based computerized algorithm named “PregHisEx” that successfully extracted PE/E diagnosis made in a previous pregnancy from clinical notes documented during prenatal service visits. Compared with expert manual review as a gold standard, PregHisEx produced a high level of performance (sensitivity of 88.0%, PPV of 91.7%, and F-score of 0.90). The discrepancy between PregHisEx-based NLP and expert manual review results was largely driven by the term “history of preeclampsia.” Since a pregnancy episode may last several months (~280 days), the term “history of” was frequently and commonly used by healthcare providers to describe complications occurring in the early stages of the current pregnancy or previous pregnancy. Therefore, in the absence of other referential context (word descriptions) of previous pregnancies, or descriptions that were located in different sentences or out of the required searching word token window, our PregHisEx algorithm treated it as an event occurring in the current pregnancy rather than in a previous pregnancy. For example, a false negative case stated “Assessment: supervision of high-risk pregnancy, history of cesarean section, history of preeclampsia, first trimester pregnancy evaluation.” The algorithm PregHisEx classified “history of preeclampsia” as a preeclampsia condition occurring in the current pregnancy while the prenatal expert classified it as occurring in a previous pregnancy.
Our study acknowledges potential limitations. First, the set of rules in our algorithm was based on a subset of randomly sampled training notes. Therefore, it may not have been representative of a complete obstetric history as documented in the entire clinical notes. Second, integration of our study computerized algorithm into the other applications and in other healthcare settings may have yielded some varying results due to the variation in format and presentation of clinical notes. The accuracy though should have essentially remained consistent since the rule-based algorithm was robust and not specified or limited to any fixed/strict formatted notes. Third, the term “history of” was constantly used to describe past adverse events in the clinical notes of the EMR. It was one of the terms used in several previous studies to ascertain history-related outcomes.11–13,20 However, because the PregHisEx algorithm was set to identify complications occurring in a previous pregnancy rather than the current pregnancy, the term “history of” could only be classified as a history case if it was accompanied by additional direct or indirect word descriptions. A reason for adopting this restricted approach was to distinguish past pregnancy history from the one that was frequently used by obstetricians to describe events occurring during the early stages of the index pregnancy. However, the application of such restriction could have led to a misclassification of PE/E cases as described above. Fourth, our computerized algorithm also searched the closest date associated with the term “preeclampsia/eclampsia” in the same sentence. If a date was found within the string that was prior to the last menstrual period of the index pregnancy, the PregHisEx algorithm classified the condition as an event occurring in a prior pregnancy. If the stated date was unrelated to PE/E, potential misclassification may be introduced. Finally, our current computerized algorithm parsed each sentence within the clinical note for text strings independently and may have missed some potential true cases if the information was separately presented in different sentences. A recent study 24 constructed a coreference resolution system to identify a set of entities referring to the same concept in the entire clinical note. Future work can leverage a similar approach to enhance the classification within multiple sentences and paragraphs of each clinical note to potentially improve the algorithm performance. Finally, our current study built a process to correct 96 algorithm-related mistyped, misspelled, or concatenated words identified through the training notes. Although the number of clinical notes with incorrect words was relatively small in comparison to the entire volume of notes, a spelling-correction tool, such as GSpell 25 or ASpell, 26 can be used to resolve incorrect words systematically for future work.
Despite these limitations, our study developed a high-performing computerized algorithm “PregHisEx” to help researchers correctly identify women with a prior history of PE/E from prenatal clinical notes. The PregHisEx algorithm can be applied to prenatal clinical notes in a general healthcare setting. Implementation of these rules in other settings may yield some varying results due to the differences in format and presentation of clinical notes, but the accuracy of the results should not be affected. Although the algorithm PregHisEx was developed and illustrated using PE/E, it can increase the certainty of distinguishing between past and present medical or obstetrical conditions of a pregnancy. Our algorithm can serve as a foundation for future research to be conducted. One of the great advantage of PregHisEx is that it can be easily adapted by other text processing programming languages such as Python and can integrate into other existing note processing applications and tools. Implementation of PregHisEx to examine the clinical notes in a systematic and automated manner can help clinicians and researchers in correctly identifying at-risk pregnancies, thus helping to manage patient care efficiently and accurately to reduce the risk of adverse pregnancy outcomes.
Conclusion
We successfully developed a high-performing computerized algorithm called PregHisEx to better support numerous pregnancy-related research studies and activities. The algorithm PregHisEx proved to be applicable and efficient for identifying medical and obstetrical conditions of a previous pregnancy with accuracy similar to an expert manual review of medical records, but with the added benefit of reducing time and cost associated with manually reviewing large prenatal clinical notes.
Footnotes
Appendix
Summary of words and phrases and the categories used to determine the history of pregnancy-related complications by the computerized algorithm PregHisEx (corresponding plural and tense words are not listed here).

| Category | List of word or phrase |
|---|---|
| Female family member or immediate relative | Mother, daughter, sister, grandmother, granddaughter, ant, niece |
| Non-history-related general description | Anxious, anxiety, assess, assessment, check, recheck, concern, consult, consultation, discuss, discussion, educate, education, evaluate, evaluation, reevaluate, exam, examine, examination, explain, explanation, factor, follow up, followup, instruct, instruction, investigate, investigation, learn, labs, manage, management, monitor, nature, observe, observation, panel, pend, precaution, prevent, prevention, regard, relate, relation, risk, screen, sign, symptom, surveil, surveillance, warning, watch, work up, workup, worry, worrisome |
| Preposition associated with pregnancy-related complications of interest | About, after, at, before, by, due to, during, for, from, in, on, within, with, secondary to, secondary for, because of |
| Word or phrase used to describe pregnancy-, birth-, and delivery-related events | Abortion, born, birth, baby, child, demise, fetal death, firstborn, loss, delivery, deliver, pregnancy, induction, stillbirth, stillborn, induction of labor, cesarean section, cesarean section delivery, low transverse cesarean section, repeat low transverse cesarean section, past low transverse cesarean section, spontaneous vaginal delivery, normal spontaneous vaginal delivery, fetal spontaneous vaginal delivery, vacuum-assisted vaginal delivery, preterm delivery |
| Words and the variants used to describe the number of pregnancy-, birth-, and delivery-related events | One, first, two, second, three, third, four, fourth, five, fifth, six, sixth, seven, seventh, eight, eighth, nine, ninth, ten, tenth, eleven, eleventh, twelve, twelfth, thirteen, thirteenth, fourteen, fourteenth, fifteen, fifteenth, sixteen, sixteenth, seventeen, seventeenth, eighteen, eighteenth, nineteen, nineteenth, twenty, twentieth, each, both, all, other, most recent, twin, triplets, quadruplets, quint, octuplets |
| Words or phrases related to current pregnancy episode | Current, currently, recurrent, recurrently, new, newly, present, presently, now, today, tonight, tomorrow, yesterday, this time, prior to admission, this admission, this week, last week, prior week, past week, previous week, this month, last month, prior month, past month, previous month, this quarter, last quarter, prior quarter, past quarter, previous quarter, this trimester, last trimester, prior trimester, past trimester, previous trimester |
| Word or phrases used to describe the possibility of a condition | Assume, doubt, presume, suspect, likely, possible, possibly, probable, probably, potential, potentially, presumptive, presumably, questionable, suspicious for, suspicion of, suspicion for |
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.