
Abstract
Introduction
Language change and the euphemistic treadmill
Many of the changes in popular language reflect changes in society, such as the invention of new terms for new technologies or new slang for new generations. However, some changes come from the ‘euphemistic treadmill’ 1 which describes how persistently uncomfortable topics (e.g. bodily fluids, marginalised groups, illnesses, conditions or differences among many others) are continually referred to in new ‘polite’ or ‘correct’ terms when the previously used term acquires a negative connotation by association with the uncomfortable topic. Sometimes the changes seem to be for the benefit of those most directly affected by the topic, as can be seen in the shift from ‘feminine hygeine’ to ‘period products’ or ‘menstrual products’ which increase accuracy, reduce stigma and include masculine or non-binary people who menstruate.2,3 In contrast, some of the changes seem to be for the benefit of those who are speaking about the topic more so than those affected, as can be seen by the negative reaction to terms like ‘handi-capable’ or ‘differently-abled’.4–6
Who benefits from the most commonly used language and terminology matters, especially when the language and terminology is being used by public bodies and authority figures as these can influence social perceptions, public policy, clinical practice and future research. 7 Consequently, the language and terminology used to talk to and about people with a diagnosis or condition is receiving attention with increasing frequency. 8 Already, this attention has lead to several language guidelines proposed by professional societies and scientific publications9–13 to help when writing those diagnoses and conditions although the decisions made when producing the guidelines are not always clearly motivated by observations of actual language use. Language guidance helps when talking about disability14,15 and race, ethnicity, and ancestry in genetics research 16 , but so far the language guidance does not cover everything that may be helpful.
PFL and IFL
A recent and ongoing shift in language surrounds ‘person-first language’ (PFL) and ‘identity-first language’ (IFL). PFL was proposed in the 1970’s and puts the person before the identifier (e.g. ‘person with autism’) based on the logic that the person would be less marginalised or stigmatised by highlighting person-hood rather than the condition. 17 PFL literally ‘puts the person first’ and describes a condition or diagnosis as something they have rather than something they are to emphasise that their disability is only one part of their identity rather than a defining part. 18 In contrast, IFL puts the identifier before the person (e.g. ‘autistic person’) based on the logic that diagnoses, conditions or differences should not be singled out with special language structures and instead should be seen as any other adjective (e.g. ‘young person’ or ‘cheerful person’). IFL seeks to equalise language so that people can claim their identity by declaring how they want themselves to be described rather than letting others choose potentially negative terms or descriptions.11,12,17,19 IFL also matches well with the social model of disability 20 which posits that disabilities should not be hidden or downplayed because they are not shameful features of individuals but are instead signs of a mismatch between society and its members. 6
Discussion around PFL and IFL first began in the context of disability, especially in relation to autism 21 but reviews are starting to emerge on the use of similar language in scientific literature on alcohol use, 22 amputation, 23 diabetes and obesity, 24 hearing loss 25 and Down Syndrome. 26 While PFL was proposed as a positive way to avoid stigmatising language, there are arguments that it can be ableist 27 because it contributes to the idea that the identifier (e.g. autism or Downs syndrome) is primarily or only seen negatively, a view not shared and often strongly opposed by the community.17,28,29 A large proportion of the literature provides commentary on the use of PFL/IFL,7,30 discussing the impact of language 31 and calls to action for changing the language 32 or on following the guidelines already in place. 33 There is no consensus on the best language to use; the numerous arguments for and against PFL and IFL have led to one being preferred over the other by some people, in some places or for some conditions. 6 Reflecting this, some style guides suggest that using either or both is fine unless a clear preference is known as the result of contacting (self-) advocacy groups, relevant stakeholders or the people directly involved.10–12 Some style guides advocate that IFL is less ableist,27,34 while others suggest that PFL is the better option when the preference is unknown (e.g. when addressing children) because IFL is often seen as an active choice that a person makes about their own identity.35,36
To date there are no reviews looking at the use of PFL/IFL in genetics and there are no clear recommendations or style guides for this area of research. An important first step towards making the decisions that underpin the development of a guide on language choices is to quantitatively analyse how PFL and IFL are currently used. To this end, the research presented here uses natural language processing (NLP) methods to describe the frequency, timing, and contextual factors associated with PFL and IFL in published genetics research abstracts. NLP methods have been used for many diverse tasks within health informatics research as ways to make efficient use of the large and rapidly growing volumes of text data. 37 One particularly relevant application of NLP methods is to provide quantitative support for decision-making. For example, NLP methods applied to psychiatric outpatient responses to the question “How are you feeling today?” have been analysed to create a suicide risk assessment tool, 38 have been used to identify potential problems in patient safety and care providers by analysing patient complaints 39 and have been used to accelerate clinical research and improve decision-making by revealing age and sex-related clusters in neurological patient files. 40 This article focusses on the methodology of how NLP can be used rather than on the outcomes and how they relate to style guideline development, which is being written up separately in another article by the same authors.
Methods
This study applies two basic NLP methods to 20 years of conference abstracts. The first method is commonly known as the ‘bag of words’ method was applied to the entire set of abstracts as well as to a subset of abstracts that contained keywords of interest. This method puts all of the words together, then removes unhelpful differences (such as case, pluralisations, verb endings, etc.) and unhelpful words (like articles, prepositions, etc.). This method ends by counting the frequencies of each unique word. The ‘bag of words’ method provides a quantitative understanding of what the input documents “are about” and is thus a useful sense check as well as allowing us to compare and contrast the entire set of abstracts and the subset of contains-keyword abstracts.
The second method, known as pattern matching, was applied only to the subset of contains-keyword abstracts. This method retains the order, structure and unique features of the original text so that it can be examined for sequential patterns that align with either PFL or IFL. Each matching pattern is then manually reviewed to ensure that it is a genuine example of either PFL or IFL. Once identified, the matches are further processed and examined to understand their frequency, context and co-occurrence within the original texts. The pattern matching is the most important for the research objectives as it zeroes in on the exact parts of the text that match either PFL or IFL, allowing us to quantify the use of each relative to each other and over time. Further, by isolating the PFL and IFL examples in this way, we can examine their contexts and co-occurrence within a single abstract to better understand whether authors are likely to be following strict style guidelines.
All of the work described in the methods section was completed in jupyter notebooks and can be found in a GitHub repository. 41 This repository includes all of the code and data from the point that the texts were converted to .csv, allowing readers to run each step of the analysis and inspect the inputs and outputs of that steps. Specifically, this includes the inputs and outputs to the manual review so that, for example, readers can compare exactly what choices we made when checking that the pattern matches were genuine examples of PFL or IFL and how these choices changed the results. The repository also contains edited versions of the.PDF files originally used, but does not contain all of the .PDF to .csv conversion code. The edited .PDF files are not exactly like the downloadable originals as this exceeded the limits of GitHub, and instead have irrelevant pages (e.g. cover pages, advertisements, indices, etc.) removed. Further, readers are welcome to download the repository if they wish to run the analysis themselves, adapt the code for other analysis, make different choices in the manual review phase, or otherwise use the code and data for their own purposes. The authors believe that science works better with full transparency and that reproducibility is essential for trust in science and research findings.
Data preparation
Data sources
The European Society of Human Genetics (ESHG) holds annual conferences for which all of the accepted abstracts are collected and published by the European Journal of Human Genetics in .pdf format. These abstracts include poster presentations, oral presentations, keynotes, and other sessions that take place at the conference. This research uses the .pdf files for all conference abstracts available between 2001 and 2021 inclusive, totalling 26 files as some years produced separated .pdf files for different categories of abstracts.
Data cleaning
The text from the .pdf files was scraped and processed by first importing everything into one long line of text, after which the text was broken into lines containing a single abstract by using regular expressions to detect the clearly structured session code preceding each individual abstract. If possible, the resultant abstract was then processed for further structured text elements such as the title, author names, institutional affiliations and more. After detection, each abstract was stored in a row of a .csv files divided among appropriate columns when possible (e.g. title in the title column, abstract text in the text column, corresponding author’s email in the email address column, etc.). Unfortunately, the structure of the session codes was not consistent from year to year, nor was there a consistent format for the other structured information (e.g. authors’ names, institutional affiliations, contact details, etc.). At the same time, special characters (which appear frequently in author and institution names) require encoding in .pdf creation but this was another way that .pdfs were not consistent from one year to the next. Consequently, the regular expressions used in the .pdf to .csv conversion process had to be checked and potentially modified for each .pdf individually. Further complicating the matter, converting text from .pdf is inherently difficult as structured text that does not belong to any abstract (e.g. page numbers, headers, footers, etc.) can be forced into the text for nearby abstracts. As a result, abstracts and especially their texts are not always detected accurately. Some simply had extra text (e.g. page numbers) interrupting the abstract text but it is possible that others might be forced together into a single .csv row or split across multiple .csv rows if the interrupting text fell inside the session code or if some other text accidentally matched the session code pattern.
Abstract and keyword detection
Table with the number of abstracts reported by ESHG for a given year, as well as how many abstracts were detected by the .pdf to text conversion process and how many of the detected abstracts contain one or more of the keywords of interest.


Graphical representation of how many abstracts are reported in a given year alongside how many abstract texts were detected by the .pdf to .csv conversion process and how many of those contained one or more of the keywords.
Sense check
The detected and contains-keyword abstract counts show that, with the exception of 2004, the data are coherent or as might be expected. First, the ratio of reported to detected abstracts is very close for most years. Second, the proportion of detected to contains-keyword keyword abstracts is reasonable for a conference that includes but is not centred on the topics captured by the keywords of interest. Third, the detected and contains-keyword values show peaks and troughs that roughly correlate but do not precisely track each other. Thus, although .pdf to .csv conversion process is clearly not perfect, the errors do not appear to be an impediment to further analysis.
Text-mining methods
Text-mining is an iterative process; each pass through the data with one or more text-mining methods may motivate a rethink that requires starting over from the beginning. For example, this exploration began with several ways to quantify the texts through relatively simple counting before moving on to more in-depth explorations of the structure and context for language. Those in-depth explorations revealed some unexpected uses of language that required a restart so that the unexpected language count be counted alongside the more expected versions. For example, we expected to find the term ‘Asperger Syndrome’ and to use it as a keyword but relatively far into the analysis we found that some abstracts also use the abbreviation ‘AS’. Thus, we restarted the analysis with the inclusion of an additional keyword. The methods described here are the last of multiple iterations through the process which, despite its seeming linearity, should be understood as a dynamic and iterative approach to understanding the texts as well as answering the research questions.
Preliminary word frequency
Texts are often quantified through the ‘bag of words’ method, 42 a popular and relatively simple way to understand or classify a document or set of documents by counting the most frequent tokens (often but not always words) within the input document(s). We began our ‘bag of words’ approach by tokenising the abstracts, which turns each word or word-like segment from all of the original texts into a list of unique word-token items for further processing. These tokens are then processed to turn all uppercase letters into lowercase letters and to remove all punctuation, numerical digits, stop words (e.g. ‘the’, ‘to’, ‘and’, etc.). Any null tokens created by these processes were then deleted and the remaining non-null tokens are stemmed, which removes plurals, verb endings and other transformations of a word to return it to is ‘stem’ form. All of this ensures that, for example, ‘child’ and ‘children’ both become ‘child’ while ‘association’ and ‘associated’ are both transformed into ‘associ’. The non-null, non-stop word, stemmed tokens are then counted which is a simple way to capture what the input document(s) “are about”, with stemmed tokens returning more meaningful counts than their unstemmed syntactical forms. 43
Most popular tokens found from through the ’bag-of-words’ method, alongside the counts of each token within the set of detected and contains-keyword abstracts, and the ratio of how the counts relate to each other.
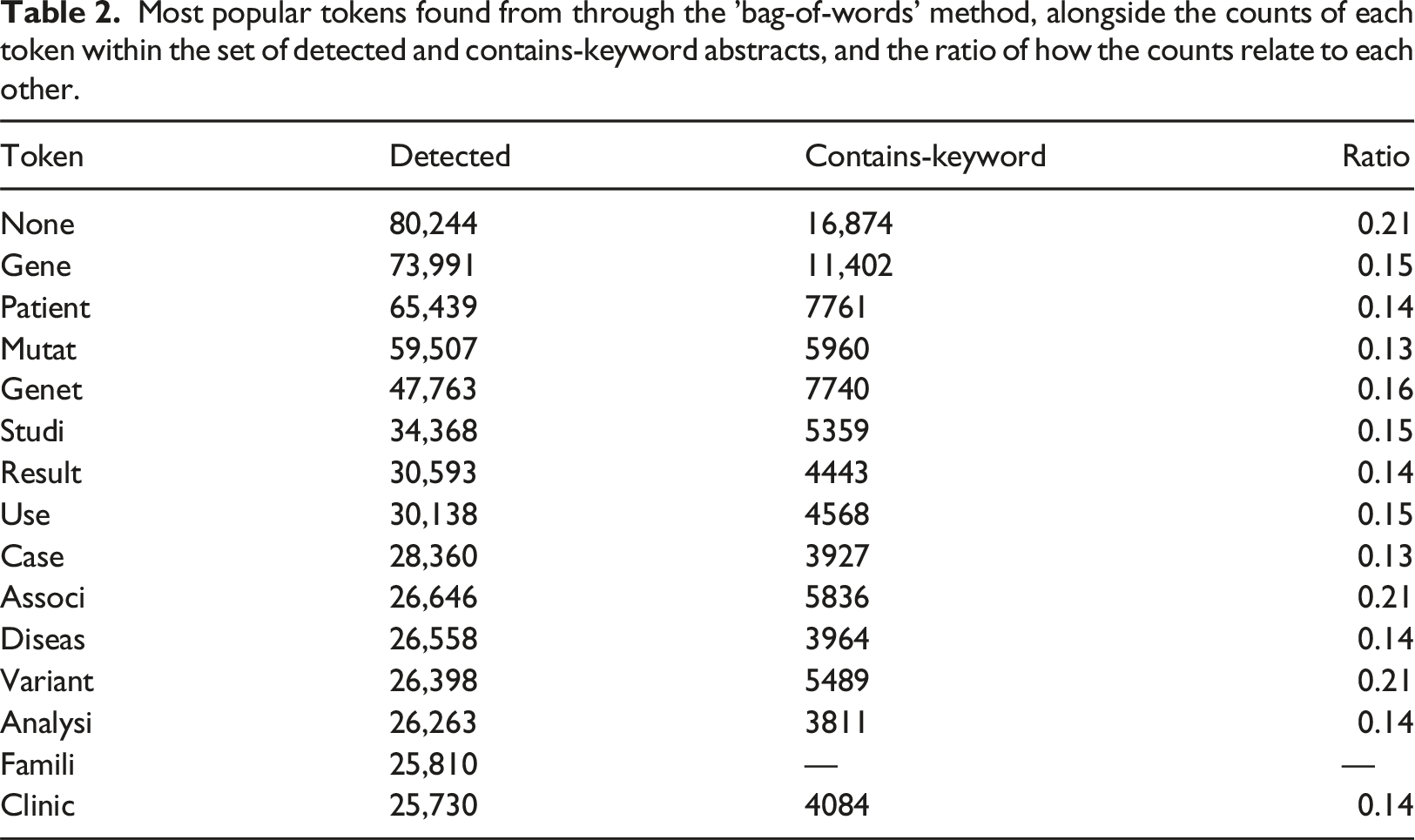
In our study, the first analysis consisted of looking at word frequencies which allowed us to ensure that the abstracts address what we expect them to. For example, that: • the most common tokens make sense in the context of genetic research conference abstracts; • the most common tokens for the two sets of abstracts have tokens in common; and • the relative frequency of the most common tokens for the two sets of abstracts are not identical.
As the results of the word frequency sense-check matched our expectations, we proceeded to the next step of text-mining methods. Importantly, the remaining steps discard the changes made during the ‘bag of words’ steps. Thus, the subsequent analysis begin afresh from the abstracts as they appeared after importing to .csv, with all of the varied case, punctuation, verb endings, pluralisation and more.
Pattern match detection
Our main objective was to understand the frequency and context of both PFL and IFL within the abstracts. Natural language is semi-structured; it follows rules (e.g. grammar, spelling, capitalisation, etc.) that give it some shape and predictability but it is not rigidly pre-defined in form or length. The language of interest to this research is particularly clear in structure because there are rules about the nature and order of the words that feature in each. PFL always starts with a noun or noun phrase that relates to a person followed by words like ‘with’ or phrases such as ‘affected by’ or ‘suffering from’ and then a word relating to a diagnosis or condition while IFL always starts with an adjective relating to a diagnosis or condition followed by a noun or noun-phrase about a person. A complicating factor is that both patterns allow for variations in the person-nouns (e.g. ‘child’, ‘children’, ‘proband’ and ‘patient’ are all valid). Another complication is that both also allow for noun phrases with descriptive words that modify the person-noun or the diagnosis-word (e.g. ‘child with severe autism’ or ‘boy diagnosed with high-functioning Aspergers syndrome’).
Despite the complications, the underlying structure of natural language can be captured and amplified in order to match many if not almost all of the patterns of interest. Pattern matching is another popular NLP analysis method that typically involves phases of cleaning, extraction and consolidation. 44 Focusing only on the contains-keyword abstracts as they appeared before the ‘bag of words’ steps were applied, the cleaning phase begins by correcting some white space errors from the .pdf to .csv conversion process, followed by sentence-tokenisation and re-organisation so that each sentence-token appears on its own row. The sentence-tokens are then filtered to remove any sentences that do not contain at least one of the keywords, along with any duplicate or null entries. At this point, there were 9775 sentence-tokens that contained at least one instance of a keyword. Then, various versions of the keywords are rewritten to amplify the pattern-matching in the extraction and consolidation phases. For example, ‘Autism Spectrum Disorder’, ‘autism syndrome’, and ‘autistic spectrum’ were all changed to ‘autism’.
‘Person-first’ pattern with 3 of the 45 unique matches.

‘Identity-first’ pattern with 3 of the 71 unique matches.

The consolidation phase begins by removing any rows for sentence-tokens that did not match at least one of the patterns. For example, ‘they were referred for further testing after a diagnosis of autism’ contains a keyword, and so appears in the sentence-tokens, but does not match either of the patterns of interest. Then, some sentence-tokens will contain more than one match to either of the PFL or IFL patterns so matches are split out so that each match appears on its own row. An extra check is run to remove empty or duplicate rows. At this point, there were 1088 matches for either PFL or IFL. The pattern matches are then processed to remove plurals for easier analysis.
At this point, the consolidation phase switches over to a semi-manual process; the results are written out to a file that is manually checked to remove any instances that match either the PFL or IFL pattern but that do not refer to people. For example, ‘autistic testing’ matches the IFL pattern but is not an instance of IFL. Many pattern matches were either clearly about or not about people, but there were some ambiguous matches. For example, ‘autistic dataset’ could refer to a dataset of test results or samples with multiple entries from the same individual. In this case, the pattern match would not be about people. On the other hand, it could refer to a dataset of individuals, comparable to ‘autistic group’ or ‘autistic population’, in which case it would be about people. Reading the entire sentence or abstract from which the ambiguous matches were drawn would sometimes, but not always, remove the ambiguity. As there were relatively few genuinely ambiguous matches (mostly for the words ‘dataset’ and ‘case’), we chose to leave them in. At this point, there were 522 matches that had manually been checked to be genuine examples of PFL or IFL.
Iterative process
This manual review stage was the most difficult, although not because the reviewing itself was very difficult. Instead, it was the first opportunity to closely examine how diversely PFL and IFL was used. For example, we had not originally included ‘AS’ as a keyword but the manual review stage showed that ‘Asperger’s syndrome’ and ‘Asperger spectrum’ (each appearing spelled in multiple ways) were reasonably common in the texts and that these terms were sometimes abbreviated to ‘AS’. Thus, we modified the set of keywords in the code and re-ran the entire process from the beginning each time a new keyword was identified to ensure that no relevant abstracts or sentences were excluded from further review. Further, our original concept of PFL focused on a person-nouns followed by the word ‘with’, which did not capture person-first language such as ‘a child affected by autism’ or ‘patient suffering from ASD’. As with the additional keywords, when we identified potential examples of PFL or IFL that were not captured by our existing patterns, we modified the code to expand the patterns matched and completely re-ran the entire process to ensure that no relevant patterns were missed. Although we did see some of this language during the review stage, it was ultimately not found to have been used in relation to autism. Thus, there were no actual examples of PFL that did not simply use ‘with’. The manual review stage was thus difficult because it was the step which motivated many changes to and passes through the previous steps. At the end of this manual review stage, we also double checked to ensure all rows had a title in the title column; a few were found to be missing but these were easily corrected by reading the abstract and manually selecting what seemed to be the title from the text.
Sense check
After manual checking, there were 522 genuine instances of either PFL or IFL coming from 254 unique abstracts. These were saved to a file before further processing to extract the noun used in each matching pattern into its own column according to the pattern from which it originally came. For example, ‘patient with ASD’ and ‘patient with autism’ would both have ‘patient’ written in a column for “PF nouns” while ‘ASD patient’ and ‘autistic patient’ would both have ‘patient’ written in a column for “IF nouns”. This step was also saved to a file and manually checked before before proceeding to the statistical analyses to understand how each pattern was used over time and how many abstracts used each type of pattern.
Results
Total frequency of PFL and IFL
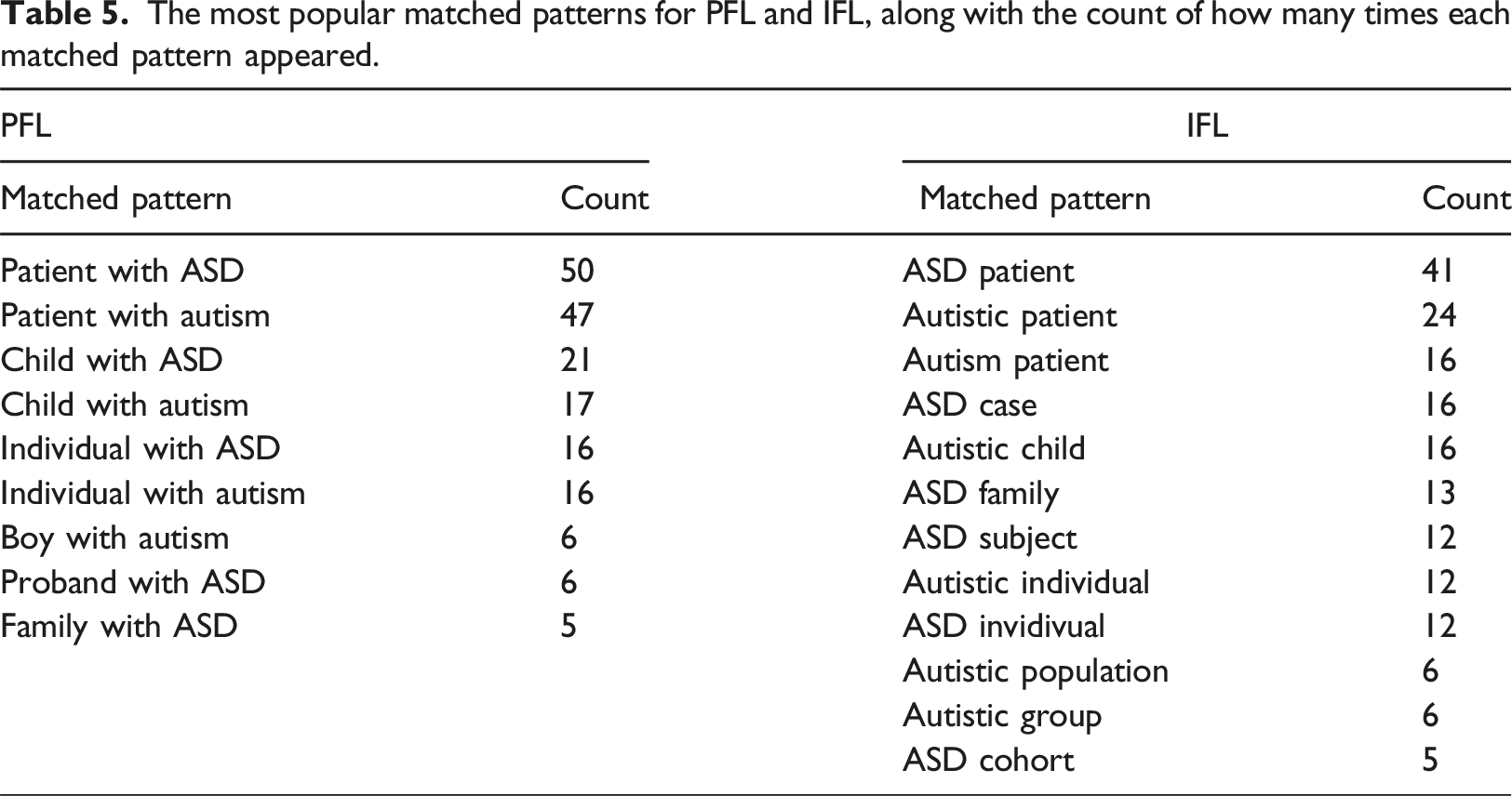
The most popular matched patterns for PFL and IFL, along with the count of how many times each matched pattern appeared.
Frequency of nouns used in PFL and IFL
The most popular nouns used within the matched patterns for PFL and IFL, along with the count of how many times each noun was used in either the PFL or IFL context.

Frequency of PFL and IFL over time
The number of PFL and IFL pattern matches was also plotted by year in Figure 2. This shows how each pattern fluctuates in popularity over time. Interestingly, the patterns of use over time are often similar, with comparable rises and falls from 1 year to the next, for most of the time period studied. This probably reveals more about popularity shifts in research on autism than popularity shifts in use of PFL or IFL. Nevertheless, the patterns begin to diverge in more recent years, starting in 2018. At this point, the popularity of both PFL and IFL diverge drastically, seeming to alternate which is more popular each year. This sudden divergence may indicate that debates around PFL and IFL or style guidelines in related fields are beginning to have an effect on the use of PFL and IFL in human genetics research publications. Graphical representation of how many instances of PFL and IFL were found per year.
Use of both PFL and IFL within the same abstracts
Finally, there were 254 abstracts with at least once instance of either PFL or IFL or both. Most of these had only a single instance of PFL or IFL, with PFL being slightly more popular. A few abstracts used multiple instances of one or the other pattern. The abstract with the most instances of PFL was titled “Prevalence of PTEN mutations in Turkish children with autism spectrum disorders and macrocephaly” and it had 7 occurrences of PFL but none of IFL. The abstract with the most instances of IFL was titled “Role of serotonin transporter promoter length polymorphism in autism: A south African population based study” and it had 9 instances of IFL but none of PFL. There were also 50 abstracts found to contain at least one instance of both PFL and IFL. The abstracts are plotted in Figure 3 according to how many instances of PFL and IFL were found within a single abstract, showing how most abstracts contain a single instance of either PFL or IFL, a few contain multiple instances of either PFL or IFL and a very few contain instances of both PFL and IFL. Clearly, some authors show a strong tendency toward either PFL or IFL, but there are also authors who use both within a single abstract. A scatterplot showing how many abstracts contain at least one instance of PFL, IFL or both according to how many of each the abstract contains.
Discussion
Style guidelines are intended to standardise language use in such a way that everyone is using the most appropriate, sensitive or accurate language but both PFL and IFL are argued by proponents to be the better choice. There are no such style guidelines for human genetics, and guidelines from other health research fields are not especially helpful as they do not consistently advocate for one or the other. Many of these style guidelines suggest that it is best to use the language preferred by those on whom a study or publication is based. When asked for themselves, most English speaking autistic adults prefer IFL, 17 with large majorities of adults in the USA 45 and the UK 46 preferring IFL. Recent research is emerging to show that self-identification with autism community and later age at diagnosis are predicting a stronger preference for IFL. 47 Another aspect influencing the PFL/IFL language preferences might be related to the native language. Another study on Dutch speaking countries highlighted a more nuanced discussion regarding PFL/IFL language choice, showing that over a half of participants had preference for PFL (54%), while no preference was indicated by 27% of participants, and IFL was preferred by 14% of participants. 48 In contrast, a similar survey with French-speaking participants highlighted preference towards IFL language. 49 More personally, one of this study’s authors prefers IFL for their own autism and disability self-identification because it better captures the idea that differences between people are not bad or shameful and that any negativity surrounding some differences is a consequence of society failing to be welcome, accepting or accommodating. In light of this, it seems that IFL is the better option for English-speaking autistic adults.
However, the consensus in other areas is not so clear. One study covering 23 countries found that 49% of disabled people preferred IFL while 33% preferred PFL and a further 18% had no preference between the two 50 and another study finding that 68% of adults prefer PFL for themselves. Even the studies showing preferences for IFL in autistic adults show that PFL is preferred by autism stakeholders who are not themselves autistic (such as researchers, parents, educators and more). This may be a result of how using IFL for oneself is often seen to be a choice, or even a political act, because it reclaims disability or difference as an integral part of the person and their life rather than something that they incidentally have but which is not a part of their identity. Children are not usually seen as able to make such a choice for themselves. Consequently, style guidelines suggest using PFL for children or those who have not expressed a preference, presumably because as it may be understood to be ‘less political’ or ‘more neutral’.
Development of a style guideline for human genetics should begin by understanding how language is currently used before introducing any changes. While this research does not definitely provide answers toward the development of such a style guideline, it does begin by quantifying how PFL and IFL are actually used over 20 years in a large corpus of natural language texts.
To that end, this research applies text-mining and natural language processing to the use of PFL and IFL in the context of autism. Looking at the abstracts accepted by the European Conference on Human Genetics from 2001 to 2021, the study reveals that in the context of autism, PFL was used 262 times and IFL was used 264. Not only are these total numbers very close, but the number of times each was used in a given year was also very close over most of the studied time frame. This suggests that authors used both interchangeably or that the authors using each were roughly equal in numbers.
The idea that they are used interchangeably or at least evenly across authors and over time is further supported by instances of both patterns being used within a single abstract. Many abstracts used only PFL or only IFL but a minority used both PFL and IFL. If both PFL and IFL appeared together within an abstract, there would typically be one of each. Very rarely, there were multiple instances of either PFL or IFL but only one or a few of the other. Thus, authors seem to have a preference for one or the other that evened out to negligible difference in total use. Of course, word limits may also come into play, with authors wanting to use PFL but finding themselves switching to IFL (which is typically at least one word fewer) if word counts bite hard enough.
However, the apparent interchangeability of PFL and IFL is not the same across time. After 2018, the use of PFL and IFL diverges with their popularity alternating each year. This may suggest that researchers have become aware of the debate surrounding PFL and IFL or that style guidelines published for related fields have begun to influence publications in genetics conferences.
Another interesting aspect can be seen in how PFL and IFL are used can be seen by looking at the nouns most commonly used with each construction. ‘Patient’ is the most popular noun for both, but beyond that PFL seems to use sigificantly more nouns that are obviously about people, with ‘child’ being the next most common noun in PFL constructions and with many other nouns that are rarely or never used in IFL such as ‘boy’, ‘girl’, ‘people’, ‘brother’ and ‘adolescent’. In contrast, IFL appears to be used in abstract contexts with the second most common noun being ‘case’ and with many other nouns that are rarely or never used in PFL such as ‘population’, ‘group’, ‘dataset’, ‘proband’, ‘subject’ and ‘cohort’. Altogether, this suggests that authors may be more likely to use IFL when talking about people in abstract situations. In contrast, authors may be more likely to use PFL to talk about people as individuals, as when they discuss ‘boys’ or ‘girls’ or when talking about conditions that do not have an obvious adjectival form.
A final interesting aspect is that most abstracts used only PFL or IFL but a few used both. It is not entirely clear if this is related to the focus of the abstract being more “about people” or “about research”, the native language of the author, the particular stylistic or grammatical choices surrounding each pattern, the word count restrictions on the abstract, some other factor, or a combination of these factors.
While the results of this study are interesting, there were limitations to the study. Most importantly, the source of the text data was compromised by being converted from .PDF rather than being imported directly from a digital source. This means that the various structured details of each abstract (e.g. authors’ names, affiliations, contact details, etc.) were not always adequately extracted. This prevented us from doing comprehensive statistics on how PFL and IFL were used in relation to potentially interesting contexts. For example, if we had been able to consistently extract the conference session codes, we might have found, for example, that abstracts in streams about genetic counseling used very different language than abstracts in streams about bench research. Likewise, we were not consistently able to relate each abstract to a location which may have shown that patterns of PFL and IFL use linked to dominant language in non-English speaking countries. However, the most compromising feature of the .PDF to .csv conversion process is the assumption that some of the text was interrupted in ways that meant abstracts, PFL or IFL patterns or individual words were split or otherwise corrupted. While we can assume that it affected the initial counts of detected abstracts, we cannot be certain that it did not have some influence on the more detailed results.
All the interesting patterns and quantification of language use identified in this study required the use of text-mining and natural language processing methods. This required access to digitised text in large volumes. Unfortunately, the source texts were in .pdf format instead of a more directly accessible digital text format so there was some loss and corruption of texts during the conversion process. The authors would thus like to advocate that any holders of text data who may be interested in that data being used for such text-mining and NLP research would be well advised to convert that data into more appropriate formats for analysis such as simple .csv files accompanied by metadata to clarify any encoding used for special characters.
Conclusions
To sum up, PFL and IFL are used almost equally over most of the time span studied, until something happened around 2018 that send their uses on divergent paths. Both patterns are used most often in the context of the word ‘patient’ but beyond this, PFL is used more often in “about people” contexts while IFL is used more often in “about research” contexts. Most authors use only one pattern within a single abstract but there are authors who used both.
There are several ways that these conclusions could be taken forward the same basic methods and keywords used here could be applied to new sources of text data, such as additional years of the ESHG conference, other conferences or peer-reviewed journal articles, either from the same or different disciplines. Expanding the sources of texts analysed in this way could reveal these results to be artefacts arising from the particular audience or conference guidelines of the ECHG. Equally, wider text sources could reveal the results to be more generally applicable in human genetics research or beyond. Finally, it would be interesting to re-apply these methods to the same abstracts were they obtained directly from the digital sources rather than scraped from .PDF to see if there are any substantive changes in results attributable to the conversion process.
Further, the same basic methods could be applied to the same or different text data, but with different keywords to see whether or not PFL and IFL hold the same basic patterns of usage when referring to other conditions. The discussion around PFL and IFL exists beyond autism and so using keywords related to obesity, diabetes, deafness or hearing loss, dementia or any other condition could show how the structures are used in other contexts. If similar results arise in other contexts, that would hint about that the structures are being interpreted or used irrespective of the content within the structures while if different results arise in other contexts then it would be clear that each discussion is progressing independently.
Another way the conclusions could be taken forward would be to narrow the scope down to manually review some or all of the abstracts that contained any PFL or IFL examples. A detailed analysis of the language used in relation to the conference session codes, the affiliated institutions, the authors’ professional background, the length of the abstract or other conceivable factors may help disentangle whether the patterns are used in the same contexts or why both patterns are sometimes used in a single abstract.
In conclusion, the methods demonstrated in this study show how NLP methods can quantitatively support the decisions behind style guideline development as well as subsequently monitor the effectiveness of such style guidelines. Showing how to quantify actual language use is a first step in the development of style guidelines that seek to influence how language is used, and thus an important factor in shaping effective and respectful communication within an important area of health research and care.
Footnotes
Acknowledgements
We would like to thank The European Society for Human Genetics for their support in carrying out this research.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Universitatea Babes-Bolyai; 32968/23.06.2023, Economic and Social Research Council; ES/P008437/1, LifeArc; PATHFINDER004, Horizon 2020 Framework Programme; 945151, Medical Research Centre; MR/Y008383/1 and Manchester Biomedical Research Centre; NIHR203308.