
Abstract
Machine learning (ML)-based content moderation tools are essential to keep online spaces free from hateful communication. Yet ML tools can only be as capable as the quality of the data they are trained on allows them. While there is increasing evidence that they underperform in detecting hateful communications directed towards specific identities and may discriminate against them, we know surprisingly little about the provenance of such bias. To fill this gap, we present a systematic review of the datasets for the automated detection of hateful communication introduced over the past decade, and unpack the quality of the datasets in terms of the identities that they embody: those of the targets of hateful communication that the data curators focused on, as well as those unintentionally included in the datasets. We find, overall, a skewed representation of selected target identities and mismatches between the targets that research conceptualizes and ultimately includes in datasets. Yet, by contextualizing these findings in the language and location of origin of the datasets, we highlight a positive trend towards the broadening and diversification of this research space.
Introduction
Hateful communication is a vehicle of conflict between individuals and groups and exposure to hateful communication online is not a rare phenomenon. In a cross-national survey of internet users, 53% of American respondents report being exposed to hate material online, while 48% of Finns, 39% of Brits, and 31% of Germans report exposure (James Hawdon and Räsänen, 2017). In a more recent study in Germany, about 76% of respondents said they had been confronted with hateful communication online and 39% had to deal with online hate very often (Landesanstalt für Medien NRW, 2023). Online platforms increasingly appear to be media of de-civilization since even a low prevalence of hateful content can lead to high exposure rates if uncivil content becomes popular.
Researchers, legal scholars, and practitioners have not agreed upon a single definition of hateful online communication and definitions range from very specific to extremely broad (Siegel, 2020). Our definition of hateful online communication builds upon the definitions of hate speech by the Encyclopedia of the American Constitution (Nockleby, 2000) and Britannica (Curtis, 2023). Consequently, we define hateful communication as “any form of communication or expression (e.g., speech, images, text) that denigrates a person or persons on the basis of (alleged) membership in a social group identified by attributes such as race, ethnicity, gender, sexual orientation, religion, age, physical or mental disability, and others.”
To tackle the problem of hateful online communication, we need to detect and address it. To this end, practitioners and researchers devoted significant effort to developing automated methods to detect hateful online communication based on Machine Learning (ML). Since it is well known in Computer Science that the performance of an ML model is upper-bound by the quality of the training data, the topic of data quality gained more attention recently (Geiger et al., 2021; Jain et al., 2020; Liang et al., 2022). The famous “garbage in, garbage out” principle does not only apply to supervised ML approaches (where the data quality depends on the quality of data annotations that guide the ML model, among other factors) but also to semi-supervised and fully unsupervised ML methods (where the quality of data depends amongst others on the data selection and preprocessing decisions). Dimensions of data quality that are typically discussed by ML scholars include noisy labels/annotations, class imbalance, data coverage, data homogeneity, and data valuation (Jain et al., 2020; Liang et al., 2022). In the social sciences scholars differentiate between intrinsic and extrinsic data quality dimensions (Daikeler et al., 2024). In the context of hateful communication datasets, intrinsic quality dimensions refer to the extent the dataset covers the phenomenon of interest in its full diversity; extrinsic quality dimensions relate to the accessibility and reusability of datasets. How those identities that shape and are covered by the datasets impact the intrinsic and extrinsic quality of datasets has received little attention so far.
While it is well known that curating datasets requires crucial design decisions that impact their quality, little attention has been paid to the identities of those who curate the datasets. The identity of an individual refers to its community, socio-demographics, position, or self-representation, including but not limited to political affiliation, age, body image, and institutional or organizational membership. Especially when curating data for hateful online communication we expect that the identities of data curators may impact the data quality of the final data in at least two ways: on the one hand, the scientific environment and background of the researchers may affect their definitions of the construct and their practices as data curators; on the other hand, their awareness, interests, and sensibilities towards different targets of hateful communication intersect with their own beliefs, attitudes, and experiences, which in turn may affect their choices on which targets and phenomena to include in the datasets.
Furthermore, issues of data quality related to the identities of researchers compound with those related to annotators. Previous research suggests that identities and beliefs of data annotators impact their perceptions and consequently their annotation of hateful online communication (Pei & Jurgens, 2023; Sap et al., 2022). Sap et al. (2022) find that more conservative annotators and those who scored highly on their scale for racist beliefs were less likely to rate anti-Black language as toxic, but more likely to rate African American English dialect as toxic. More recently Pei and Jurgens (2023) re-annotated 1500 comments sampled from a dataset consisting of Reddit comments (Hada et al., 2021) using 262 annotators from a representative sample from prolific. Their results show that people from other cultures may perceive the same comment with a lower or higher degree of offensiveness.
For ML models to have a real-world, positive impact on the targets of hateful communication, it is necessary to unpack the relationships between the identities included in the datasets and identities involved in the curation of datasets.
Recent systematic reviews summarized how the literature in hateful communication advanced methodologically and theoretically (Pamungkas et al., 2023; Paz et al., 2020; Vidgen & Derczynski, 2020). Our research adds to this body of literature by addressing the practices around curating hateful communication datasets, with a focus on how they represent the targets of hateful communication. In particular, we offer a positionality outlook on hateful communication research. We perform a systematic review of the past decade of datasets meant for training ML models for detecting hateful language, focusing on the identities that are included and that shape the production of hateful communication datasets.
First, we focus on the producers of hateful communication datasets and their practices. We find that in the past five years, the field of hateful communication research broadened its geographic borders, became shaped by international collaboration, and increased its coverage of different languages and platforms in the datasets. Yet the production is still dominated by researchers with U.S.-based affiliations and the majority of datasets are in English.
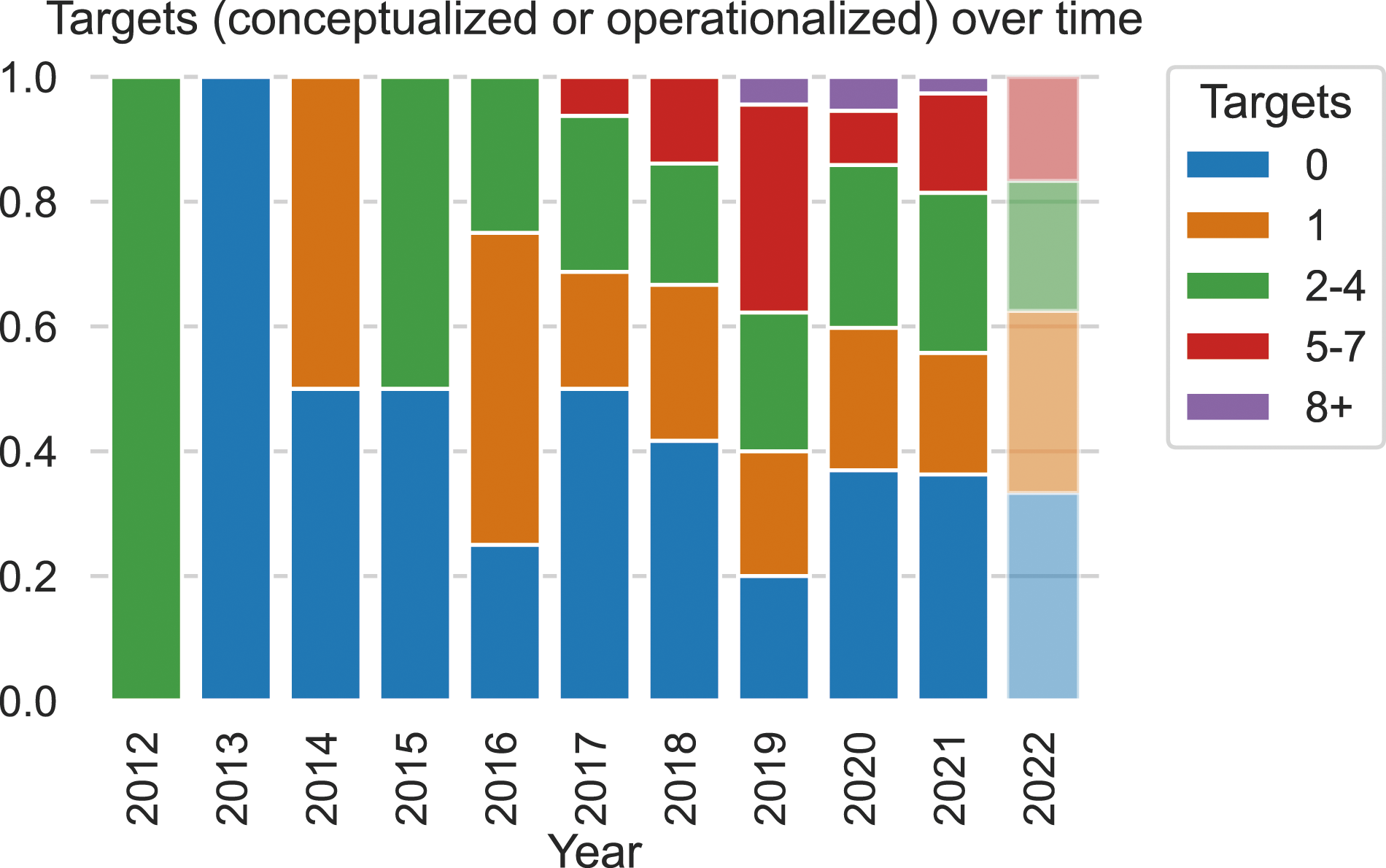
Next, we focus on the targets of hateful communication that are explicitly included in their design. Leveraging frameworks for assessing the quality of datasets (Sen et al., 2021), we distinguish between explicitly conceptualized targets—those who are included in the explicit definition for hateful communication as a construct—and operationalized targets—those who are operationalized in the sampling, annotation and/or analysis of the dataset. We find that hand-in-hand with the broadening of the production of hateful communication research, conceptualized and operationalized targets came to include more identities in recent years. However, some target identities, such as age and body image are rarely covered in any of the datasets, which raises concerns about the ability of ML systems to detect hate towards those target identities.
Focusing on a sample of 15 highly used datasets, we analyze the discrepancy between the targets included in writing—conceptualized and operationalized targets—and the detected targets, actually present in the datasets, independently of whether they were included in writing. We find that among the instances for which we detect targets, up to 16% fall in single target categories that were not conceptualized and/or operationalized first. This may make the hate classifier perform unpredictably on such targets.
In summary, the paper addresses the following questions:
Overall, this work highlights a diversification and broadening of the research space around the curation of hateful communication datasets, in terms of both the participants in the scientific field and their attention toward the targets of hateful communication. Within this overall positive trend, the review identifies shortcomings in how research reflects local contexts and identities. Addressing this gap may help the next decade of research in addressing the needs of the targets of hateful communication more accurately and equitably. Thus, this work suggests practical steps for developing standards and practices that ensure the quality of hateful communication datasets.
Related Work
Creating an ideal dataset for training and evaluating hate speech detection systems is challenging (Sodhi et al., 2021). Frequently observed limitations include datasets that are too narrow in their linguistic diversity, with standard English vernaculars being the most studied (Ghosh et al., 2022); datasets that are limited to ad-hoc definitions of hateful content, restricting the validity of the resulting machine learning models (Albadi et al., 2018; Hardaker & McGlashan, 2016); and datasets that skew towards frequently studied targets, disregarding less-frequent but equally consequential ones (Gao & Huang, 2017; Vigna et al., 2017).
For example, Moy et al. (2021) analyzed the language discrepancy between English and non-English hate speech datasets and highlighted the importance of non-English datasets for hate speech detection, especially in multilingual countries. The study of Swamy et al. (2019) highlights the redundancy and non-generalizability between datasets for abusive language detection through experiments on cross-dataset training and testing.
Despite the numerosity of datasets that cover instances of hateful content, only a few studies have focused on their quality. Waqas et al. (2019) released a literature review on hate speech research, focusing on research papers from the Web of Science core database published through March 2019. Specifically, they concentrated on mapping broad research indices, prevalent research topics, research hotspots, and significant stakeholders such as organizations and contributing areas. Fortuna and Nunes (2018) provided an analysis of the status of hate speech by presenting a summary of approaches, covering algorithms, methodologies, and main features. They also focus on categorizing the different works that aim to detect hate speech for different targets (i.e., Racism, Sexism, Prejudice toward refugees, Homophobia, and General hate speech). Vidgen and Derczynski (2020) reviewed 63 publicly available abusive language datasets also using the PRISMA review methodology. They described the information that the datasets contain (and exclude), how they have been annotated, and how tasks have been constructed. Lastly, they gave a comprehensive examination of methods for making training datasets more accessible and helpful. Poletto et al. (2021) systematically assessed the hate speech datasets’ characteristics, including their creation methods, thematic focus, and language coverage. While they do not cover targets specifically, they analyzed topical focus, that is, the specific topics and abusive phenomena addressed. For example, topical focuses can be aggressiveness, homophobia, toxicity, or misogyny. While topical focus can also consider targets, this is more related to the task addressed.
Some reviews on hateful communication paid particular attention to Natural Language Processing (NLP) methods rather than datasets. Schmidt and Wiegand (2017) presented a survey on the automatic detection of hate speech, mainly focusing on the NLP approaches. A survey review conducted by Torregrosa et al. (2021) focused on the existing NLP techniques on extremism detection and their application and mentioned datasets about their availability. Similarly, Jahan and Oussalah (2021) systematically reviewed literature of the last 10 years from a technological perspective, with a special focus on NLP and deep learning technologies applied for automatic hate speech detection. Ayo et al. (2020) focused on the Machine Learning techniques for hate speech classification of Twitter data and provided their current status and future directions.
Unlike previous work, our study focuses on the identities included in the datasets and identities involved in the curation of datasets and how they impact the quality of hateful communication datasets. Target identities play a main role in the dataset from its production to the analysis, which varies a lot across contexts and languages. It could influence the type of content being included and the results of analysis, depending on the research topic of the original study. Prior studies have focused more on explicit characteristics of the dataset being analyzed like language and the approaches used for analysis, while less attention has been paid to the mediator that distinguishes the dataset, namely, the target identities of hateful communication. Unlike previous work, our study focuses on the identities included in the datasets and identities involved in the curation of datasets and how they impact the quality of hateful communication datasets.
Methods and Data
In this section, we outline how we survey the literature and analyze papers that introduce novel datasets of hateful communication. Then, we clarify the methodology used to assess the identities that are included and that shape the hateful communication datasets and their quality.
Paper Analysis: Systematic Literature Review
We follow the PRISMA guidelines for surveying the literature systematically (Page et al., 2021). Here, we clarify how we search, select, and annotate papers. In particular, to gain an encompassing view of the quality of the datasets introduced by this body of work, we annotate the papers introducing the datasets, the datasets themselves, and the targets of hateful communication explicitly mentioned in the papers. We conducted this literature review in early 2022; therefore our sample is restricted to papers published till March 2022. To prevent misunderstandings related to the partial availability of data for the year 2022, we de-emphasize the corresponding results by reducing their opacity in plots.
Search and Selection Procedures
We based our literature search on the following academic databases and search engines: Scopus, ACM Digital Library, and ACL Anthology because of their topical relevance and interdisciplinary nature.
To achieve a broad inclusion of datasets concerned with different dimensions of hateful content, we first constructed a set of queries, composed of four parts. These queries systematically combine four different dimensions: topic, content, dataset, and data source. Our broad understanding of hateful content is reflected particularly in the wide range of keywords in the topic dimension. For each dimension, we defined a set of relevant keywords: topics (e.g., “hate,” “troll,” “dehumanize”), content (e.g., “message,” “speech,” “language”), datasets (e.g., “corpora,” “dataset,” “corpus”) and data source (e.g., “web,” “internet,” “online”). While these queries help to include a large number of datasets on hateful content, they also lead to the inclusion of related, but not relevant constructs and datasets. These publications are screened out in the second stage of our extensive manual paper selection procedure. An overview of the literature screening process is given in Figure 1. Further details on the search and selection procedures can be found in the appendix. Details of literature search and screening process using the PRISMA flow diagram. Notes: DL stands for Digital Library; I&E stands for Inclusion and Exclusion.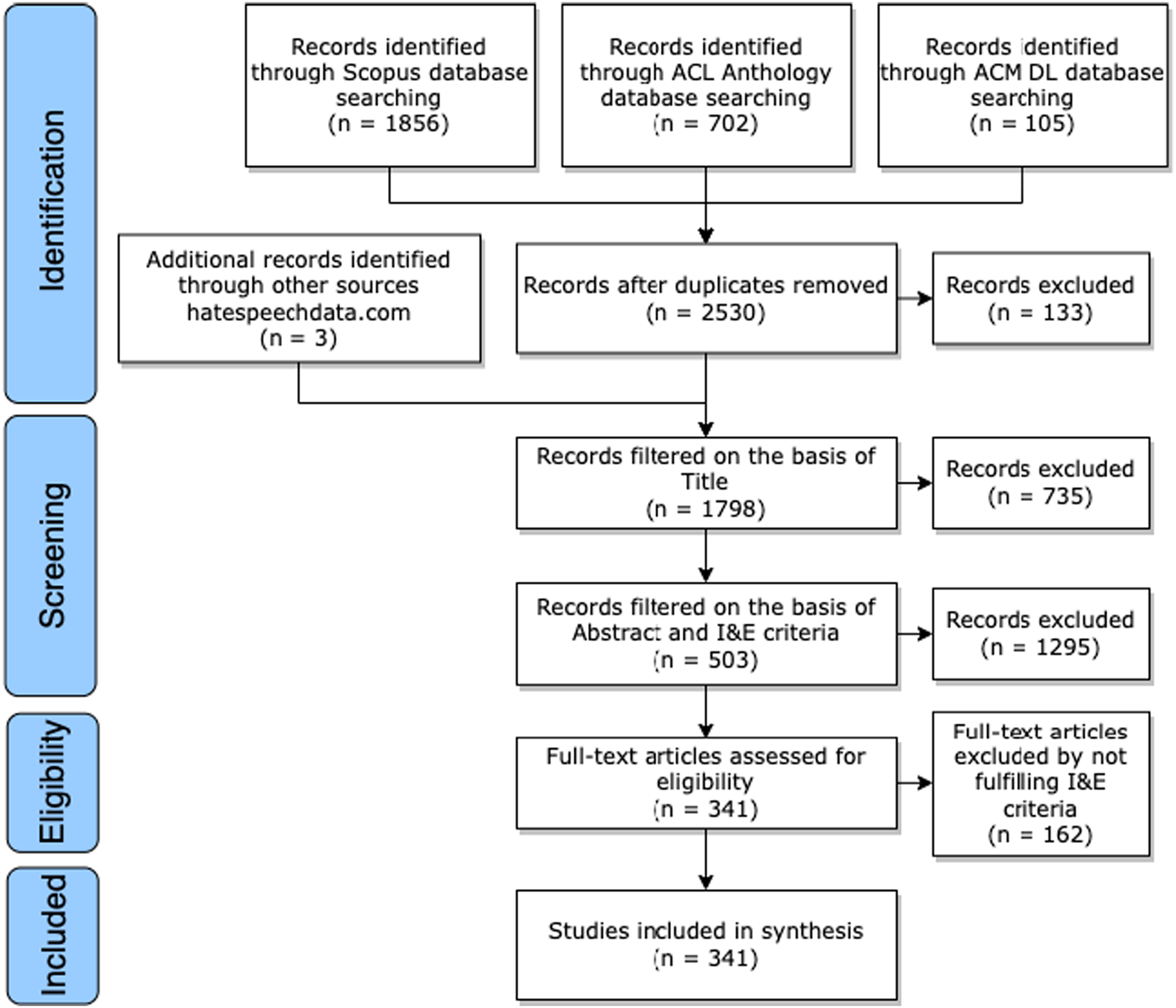
Annotation Procedure
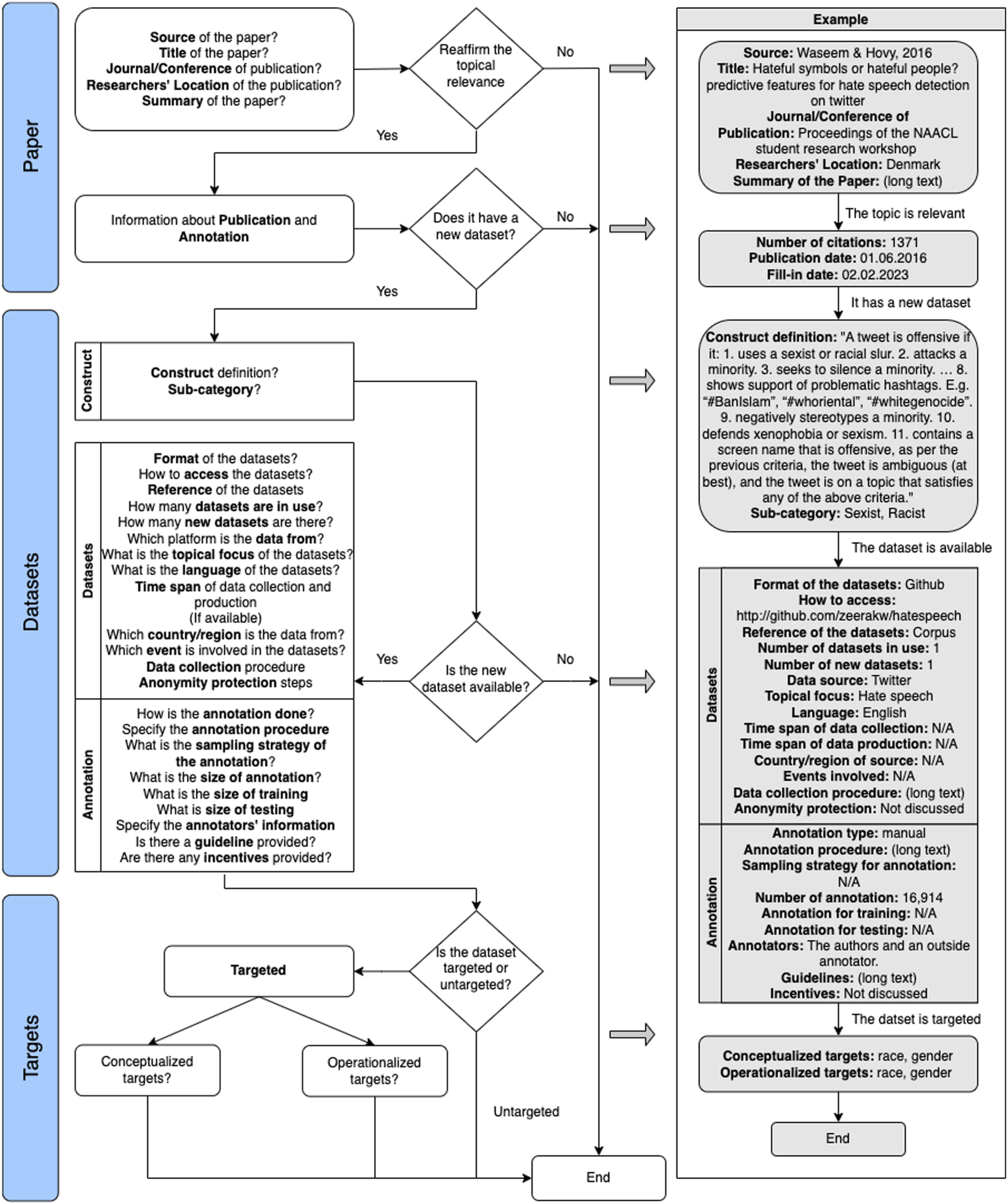
We constructed a concept matrix (Appendix Figure 14) that included details about the publications, corresponding datasets, and targets to assist in guiding our data annotation process. For the final round of reviews, three annotators evaluated the full text of each paper and completed the annotation matrix for all papers included in our sample.
Annotation: Paper Metadata
The paper section provides the publication’s general metadata, including its title, journal, country of author affiliation, summary, citation number, publication date, and accessibility. Within the dataset section, we differentiate between construct definition, metadata about the dataset (e.g., its collection procedure, time span, and topical focus) and its annotation (e.g., number of annotators, guidelines, and incentives).
Annotation: Dataset Metadata
The dataset metadata block contains detailed information about the dataset, including its availability, way to access, format, reference name, number of newly created or adapted datasets, language, data source, topical focus, relevance to social events, data production and collection time, country of origin, and any measures taken for anonymity protection of the data source. We explored the annotation process that was used during the dataset creation by identifying information about the annotation type, procedure, selection strategy, overall data size and the size used for training and testing, information about annotators, guidelines, and incentives provided.
Annotation: Conceptualized Targets
The target section provides information about the authors’ definitions of targets of hateful communication that are explicitly addressed by the authors of the datasets. We differentiate between papers that aim to measure hate towards selected targets and papers that do not discuss specific targets. We further differentiate between individual targets (e.g., a specific politician), and targets corresponding to collective identities (e.g., one’s political affiliation). We categorize collective identity targets according to the taxonomy introduced in ElSherief, Kulkarni, et al. (2018) and iteratively added four other major collective identities we found in the publications in our literature review, namely, political affiliation, age, body image, and institutional or organizational membership. 1
For the construct, we collected its definitions in the text of the papers, including all potential sub-categories of the main construct. From the definitions, we extract both the topical focus—the communicative phenomenon under study, such as male chauvinism—and the targets of the hateful communication—such as women. In this paper, we call conceptualized targets those that are explicitly mentioned in the construct definition.
As an example, Taradhita and Darma Putra (2021) define the hate speech construct as “an act of communication by a particular person or group that aims to insult a person or a group based on their ethnicity, race, religion, gender, sexual orientation, or class,” the latter being the targets of the particular kind of hateful communication. On the contrary, some definitions in the literature do not explicitly identify specific groups of targets as part of the construct definition. For example, according to Zhang et al. (2018) “we identify that hate speech 1) targets individual or groups on the basis of their characteristics (targeting characteristics); 2) demonstrates a clear intention to incite harm, or to promote hatred; 3) may or may not use offensive or profane words.”
Following frameworks for data quality (Sen et al., 2021), we aim to assess the inclusion of targets in all phases of dataset creation. To this end, we annotate targets beyond those mentioned in the construct definition at two crucial steps: those included intentionally and explicitly in the operationalization (i.e., data creation process), and those included in the final dataset itself even if unintentionally. We clarify the former, before discussing the latter in the next section.
Annotation: Operationalized Targets
We annotate as operationalized targets those targets for which the authors define concrete measures to ensure that their presence in the data is visible. For example, authors may mention targets in the annotation codebook and/or use them as labels or may use certain methods that are specifically designed to detect certain targets (e.g., a dictionary to detect gender words or an antisemitism classifier). Additionally, some authors also define measures that increase the presence of certain targets in the data (i.e., define data collection strategies that potentially boost the presence of certain targets).
Dataset Analysis: Detected Targets
We next turn to the targets that are included in the datasets themselves, irrespective of whether the authors of the datasets mentioned them in the conceptualization or operationalization of the construct under study. We call these detected targets.
Therefore, we complement our literature review with an in-depth analysis of a convenience sub-sample of targeted datasets—a combination of datasets already included in our systematic review and datasets added and annotated exclusively for this analysis—which was made available by Risch et al. (2021). For this sub-sample, we analyze the prevalence of different targets. This analysis allows quantifying the potential mismatch between conceptualized, operationalized and included targets in datasets that are or can be used to train hate speech detection systems. A potential mismatch on these different levels that are depicted in Figure 2 may lead to surprising failures of hate speech detection systems. The three types of targets studied in this work and the potential mismatches between them. We introduce a two-tier categorization of targets. First, we distinguish between conceptualized targets (i.e., those who are included in the explicit definition of hateful communication as a construct chosen by the researcher) and operationalized targets (i.e., those who are operationalized in the sampling, annotation and/or analysis of the dataset). Moreover, while conceptualized and operationalized targets are explicitly accounted for and typically described in the paper, the corresponding dataset may include other targets that are not: we call the latter detected targets. The figure depicts a mismatch between these three types of targets: the researcher has chosen a very broad conceptualization of hateful online communication encompassing rage, gender, and religion, but a narrow operationalization, which only aims to capture hate towards gender identities in the dataset; yet, ultimately, the final dataset may include also targets that were part neither of the conceptualization nor the operationalization, such as identities based on political ideology.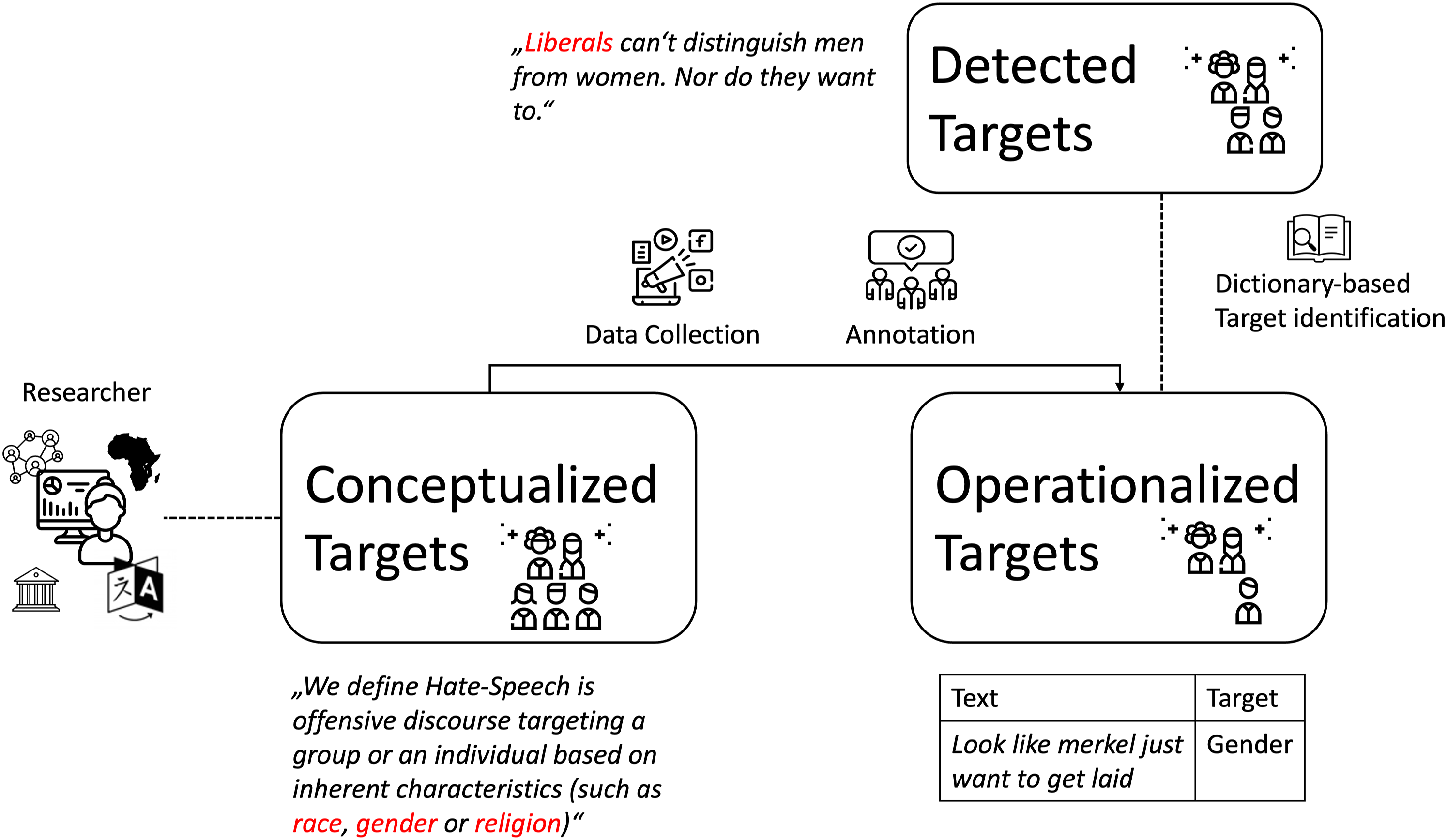
For target detection, we use a dictionary-based approach, which aims to detect different identity terms that are mentioned in a hateful or non-hateful context.
Dictionary Creation
Our methodology for the dictionary-based target detection builds on related work with a strong focus on target identities (ElSherief, Nilizadeh, et al., 2018; Silva et al., 2016; Vidgen & Derczynski, 2020). Starting with a list of more than 750 keywords from the website hatebase.org, ElSherief, Nilizadeh, et al. (2018) identify the 51 terms most indicative of hate speech, removing phrases that were deemed context-sensitive or that would frequently be used in contexts other than hate speech, for example, the term “pancake”. hatebase.org, one of the biggest repositories of multilingual hate speech, compiled this list by asking users to contribute through the addition of new hate speech terminology and classifying it into different categories. Both the compressed list of keywords and the categorization scheme were subsequently adopted as a basis for the analysis by ElSherief, Nilizadeh, et al. (2018).
After reviewing several works focusing on hate speech targets (Davidson et al., 2017; de Gibert et al., 2018; Kennedy et al., 2020, 2022; Pamungkas et al., 2020; Qian et al., 2019; Vidgen et al., 2021), we decided to further extend the target dictionary proposed by ElSherief, Nilizadeh, et al. (2018) to improve the coverage of target categories discussed in existing literature. Specifically, we incorporated the categories Age and Body, along with corresponding keywords found in Vishwamitra et al. (2020) and Baheti et al. (2021). Additionally, we included the category Political, as well as the category Organizations/Institutions and corresponding keywords from Zampieri et al. (2019). We excluded the category Archaic as it did not represent a single, homogeneous target group. The final set of target categories is Age, Body, Class, Disability, Gender, Nationality, Organisations/Institutions (Org./Inst.), Political, Race, Religion, and Sexuality. We report in Table 3 of the appendix the full list of keywords associated with each category.
Dictionary Application
For each instance of a dataset, we check whether one or multiple keywords defined in the dictionary occur in the instance’s text. To improve the accuracy of these matches and increase the efficiency of the matching process, minor preprocessing steps such as the deletion of stopwords, digits, and punctuation and a transformation into lowercase text were implemented. As the keywords in our dictionary included bigrams, we tokenized the instances’ texts into both uni- and bigrams, before applying the dictionaries to them. The results were aggregated on the dataset level, resulting in a distribution of the instances over the available target categories for each dataset. To identify the hateful instances in the datasets, we rely on the annotations provided by the dataset creators.
Dictionary Validation
While we cannot assess the recall of our dictionary approach for detecting targets, we find that it does afford precision: estimating on a stratified random sample of 33 instances where at least one target was detected (3 instances for each of the 11 target categories), the correct target is present in 21 instances, corresponding to a macro-average precision of 68%. While the agreement between our annotations and the dictionary results is high for the frequently operationalized target categories, it seems to be inherently difficult to operationalize the categories Age and Body using a theory-based lexicon. Even though we observe low agreement for these categories, we decided to retain them to surface this difficulty and highlight the lack of datasets covering them. For the categories Organisations/Institutions and Nationality, the round of manual annotations showed their proximity to the categories Political and Race, respectively. This observation is in line with the difficulties that Bretschneider and Peters (2017) and Ousidhoum et al. (2019) report in distinguishing those category pairs during their annotations.
Results
We provide an overview of the state-of-the-art in hateful communication datasets, before presenting our findings on the identities that shape them. First, we analyze the location of the authors’ institutional affiliations, the languages of the datasets they contribute, and the topics they focus on. Next, we study which targets of hateful communication are explicitly mentioned in the papers that introduce new hateful communication datasets, to map out how research has distributed its efforts across different target groups. Finally, we analyze the targets that are empirically included in the datasets to assess the possible mismatches between the conceptualization of hateful communication and the resources intended to address it.
Summary of Collected Papers and Datasets
Out of 2533 papers initially matching our search queries, we identified 341 papers introducing novel datasets about hateful online communication suitable for training machine learning models. Figure 3 shows the increase in the number of datasets shared over time, spanning publication years 2012–2022. Conceptualized and operationalized targets by year along with the distribution of datasets. Targeted refers to datasets that have explicitly mentioned at least one target in their construct definition (i.e., in the conceptualization phase) and/or publications in which the authors define concrete measures to ensure and validate the presence of at least one target group in the data (i.e., in the operationalization phase). Untargeted refers to all other datasets that do not meet these two criteria. Note that the data for 2022 is only partially available (as described in our Methods and Data Section).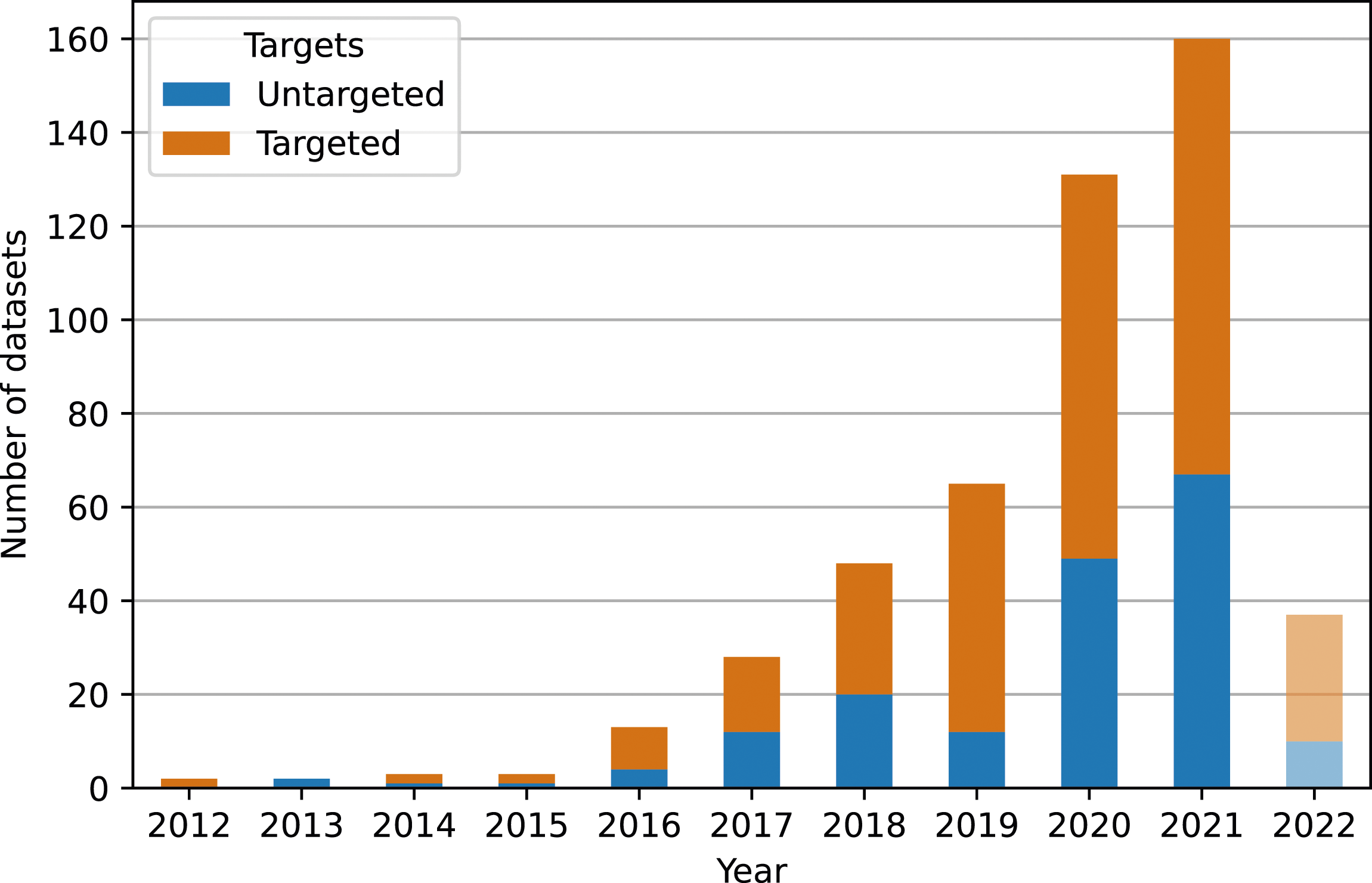
Dataset Multiplicity
While most papers (261 out of 341) introduced one hateful communication dataset, 80 papers introduced two or more datasets. Overall, the research introduced 492 datasets on hateful communication.
Q1: In What Countries are Producers of Hateful Communication Datasets Located, What Languages are They Studying and How are the Datasets’ Qualities Evolving?
We now turn to the stakeholders of the hateful communication datasets. We start by unpacking the context of the production of the datasets. We investigate the diversity of researchers contributing to this body of work, using the location of their institutional affiliations to situate the researchers. We show how researchers’ locations are correlated with differences in the choice of languages and topics covered by the datasets they produce. We analyze the quality of hateful communication datasets with respect to both intrinsic data quality indicators—such as the diversity and coverage of languages, platforms, and targets—as well as extrinsic factors—that include the accessibility and interoperability of datasets.
Dataset Availability
51% (251) of all datasets in our sample are publicly available (i.e., authors provide links to the dataset or specify that the data is available upon request; we also included those papers that are only available upon request since terms of use of social media platforms often hold authors back from sharing their data in public data repositories). Among those that are available, the most common way to distribute datasets is GitHub, with 62% of datasets shared via Github, followed by some open repositories such as Zenodo (5%) and Google Drive (2%), and the rest are available through a provided link to websites. Only 7% of datasets are specifically available upon request via email or any given contact.
Although all 180 publications corresponding to the 251 publicly available datasets mention ways to access the data, we found that it was not possible to access 21 datasets of 17 papers due to wrong or expired links. The remaining 163 out of 180 studies provided valid access to 230 novel datasets.
Diversity of Data Sources
Next, we turn to the platforms that researchers used as sources for data collection. Most of the publications collected the datasets on a single platform (252), while the remaining were from two (45) or more platforms (44) (Figure 4). Twitter is the most popular data source, featured in 55% (272) of all datasets, followed by YouTube (11% (54) datasets), Facebook (10% (50) datasets), Reddit (8% (40) datasets), Wikipedia (7% (33) datasets), and Instagram (3% (16) datasets). Single vs. multiple platforms as data sources over time. While most of the datasets are collected from a single source, around 2018 researchers are increasingly collecting data from multiple sources (i.e., two or more).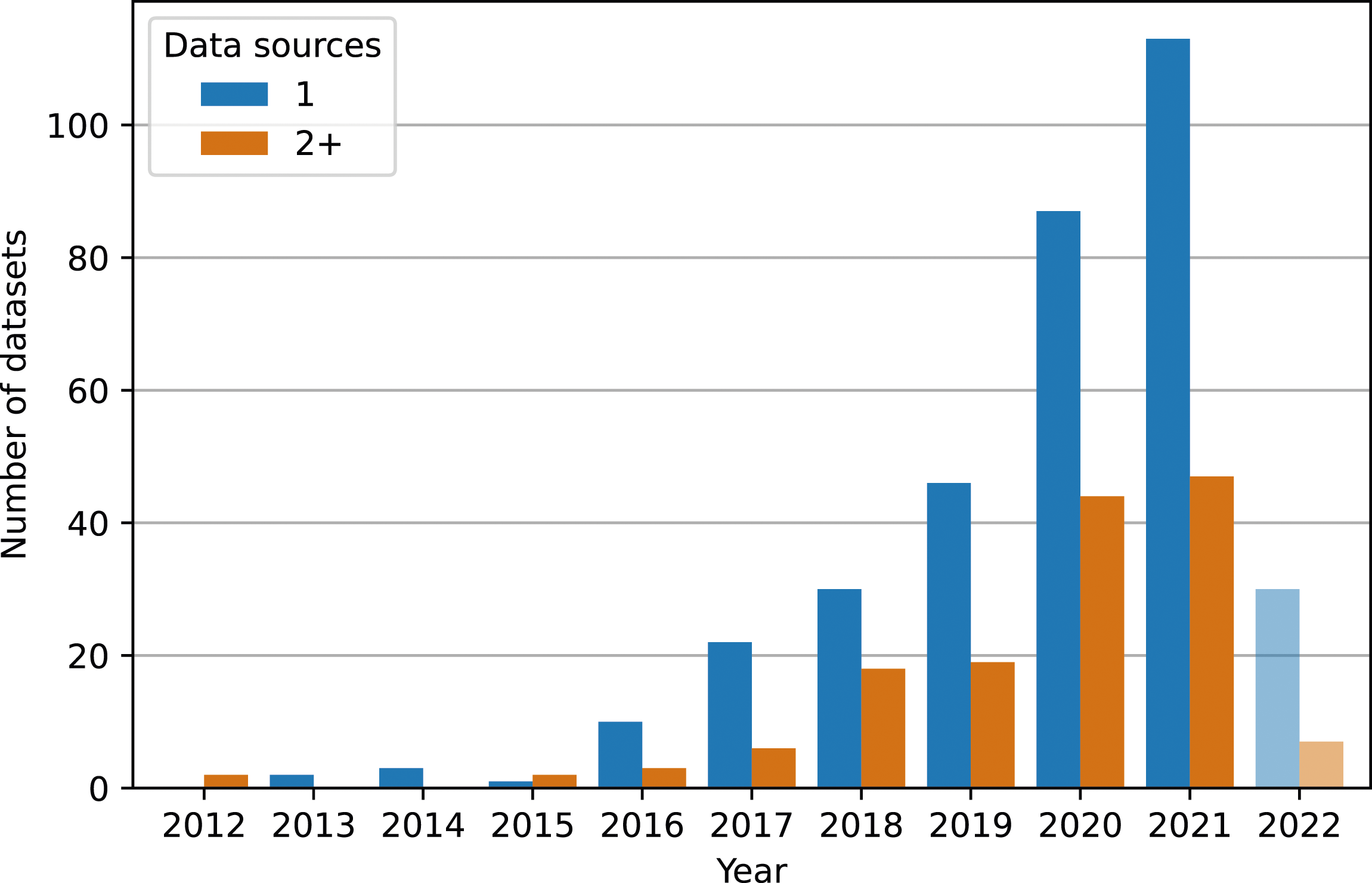
Diversity of Researchers’ Locations
The United States is the country leading the production of hateful communication datasets. Overall, U.S.-based researchers were involved in the creation of 135 new datasets—27% of the total number of datasets (492). In decreasing order, the remaining locations with the most contributed datasets are India (12% (57) datasets), the United Kingdom (12% (57) datasets), Germany (7% (32) datasets), and Italy (7% (32) datasets) (Figure 5). Geographic distribution of researchers’ affiliation that contributed datasets. Researchers affiliated with institutions located in the U.S. published the most datasets, followed by researchers from India and the United Kingdom institutions.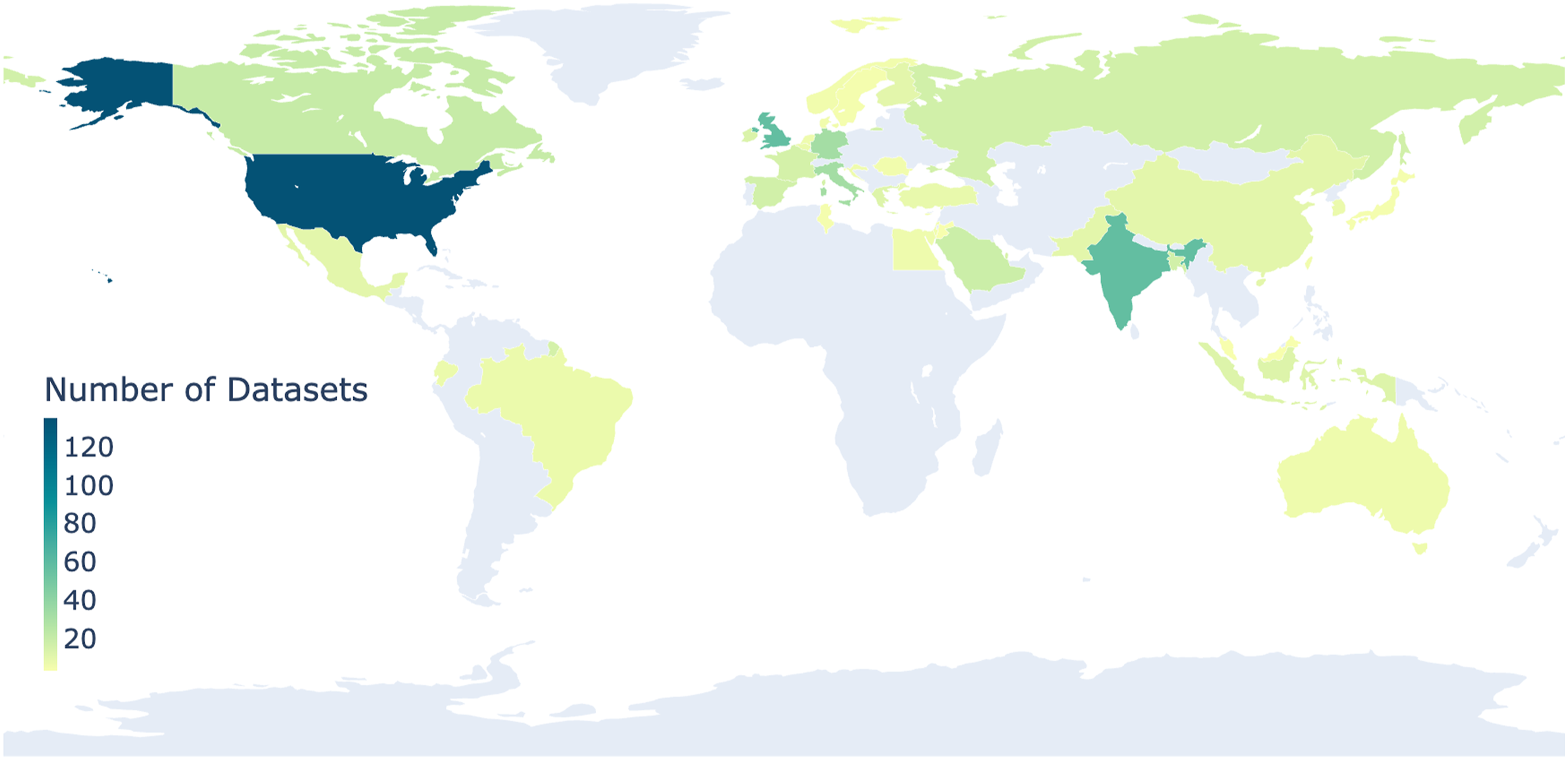
Yet the field appears changing over time. Not only is the field growing in size (as noted in the previous section and depicted in Figure 3), but it is concurrently expanding its geographic borders. As of 2022, researchers with affiliations in 59 countries contributed new datasets, compared to 9 countries before 2017. Especially, since 2017, each of the top-5-dataset-producing countries contributed fewer datasets than the non-top-5 countries taken together (see Figure 6a). Moreover, since 2017, transnational collaborations increased: 23% of all datasets in our sample were published by transnational teams since 2017, while only 1% of datasets were published by transnational teams before 2017. Linguistic and geographic trends over time in harmful language research. Notably, the number of datasets for the non-top five languages continues to be lower than all English ones, while since 2017 we see more and more datasets in languages other than English. (a) The distribution of datasets over time for the five most frequent researcher locations and all other locations combined. Researchers from the US publish the most consistently, while other countries began producing more datasets since 2016. (b) The distribution of datasets over time for the five most studied and all other languages combined. English has received most of the attention which has risen over time, while research on other languages became prominent after 2017.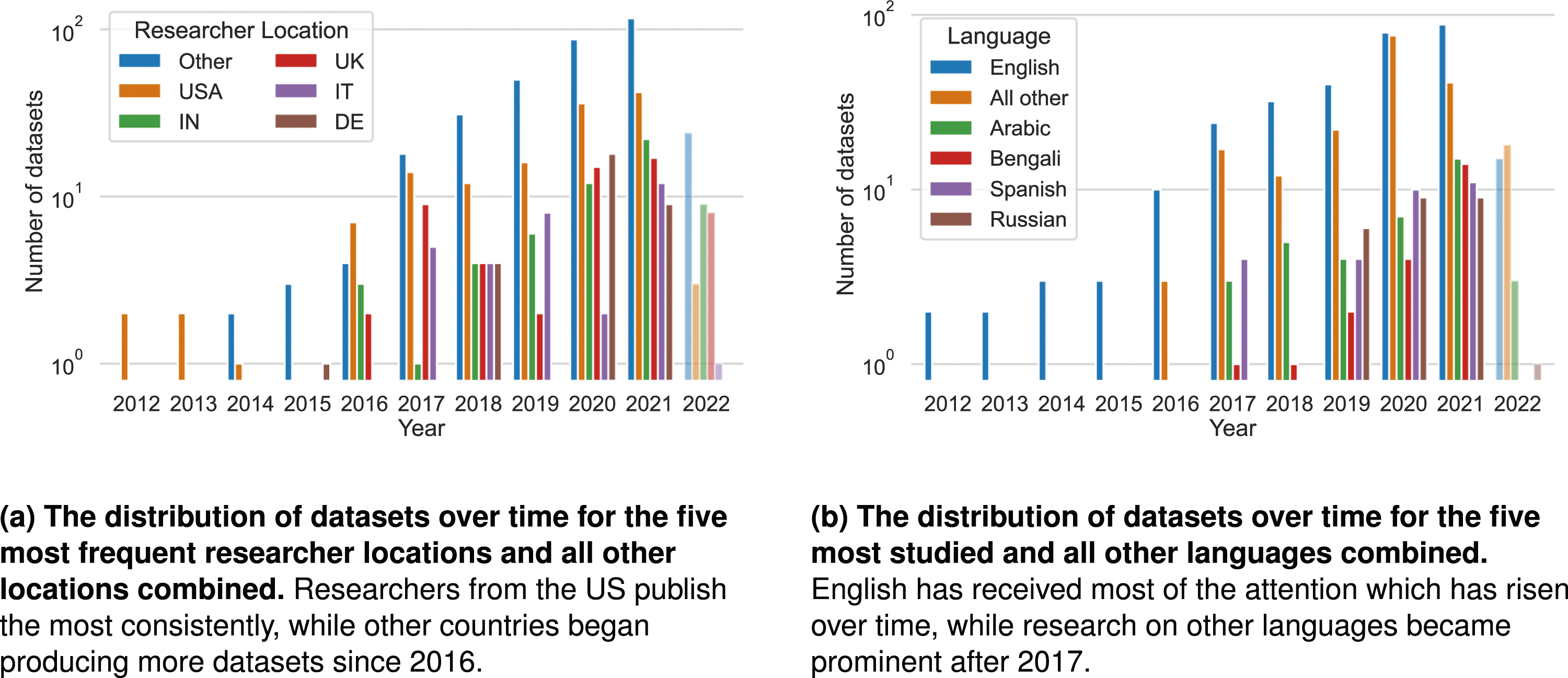
Also when accounting for the low number of datasets before 2017, we see a difference in the frequency of transnational collaborations: before 2017, only 4 out of 23 datasets (17%) were created by transnational teams, while since 2017, 25% of datasets fall into that category.
This highlights the increasing diversity of teams that contribute hateful datasets but also shows that large parts of the world are not involved despite experiencing hate online.
Diversity of Dataset Languages
The hateful communication datasets in our sample span over 49 languages, with English being the most common language (61% (298) datasets), followed by Arabic (8% (37) datasets), Spanish (6% (29) datasets), Russian (5% (25) datasets), Bengali (4% (22) datasets),
2
French (4% (22) datasets), German (4% (20) datasets), and Hindi-English (3% (17) datasets).
3
Some datasets also focus on low-resource languages such as Urdu (2% (11) datasets), Kazakh (0.4% (2) datasets), and Malay (0.2% (1) dataset). 90% of all datasets are monolingual (Figure 7), 5% contain text in two languages, and 5% include more than two languages. Monolingual vs. multilingual datasets over time. While monolingual datasets are more frequent, around 2017 researchers began producing multilingual datasets.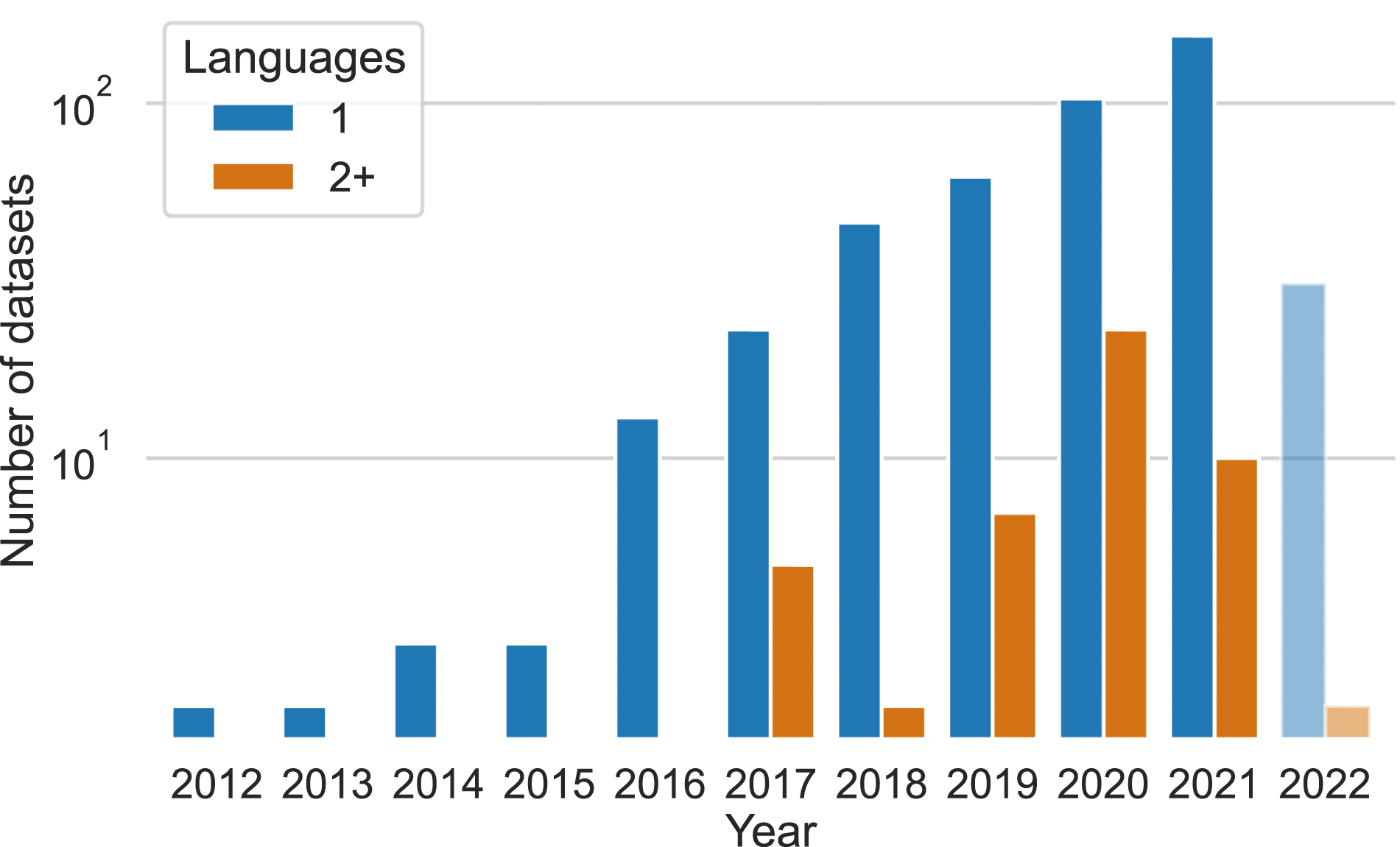
Figure 6(b) shows that the number of datasets in English has steadily risen since 2012. However, similarly, as for the locations of the researchers, we have witnessed a diversification of the languages since 2017/2018. Before 2017, almost all datasets were in English. After 2018, there are almost as many datasets in non-top-5-most-common languages as there are in English each year.
Next, we unpack how the language of the datasets relates to the location of the researchers authoring them. Figure 8 shows the distribution of datasets by their language and the location of their authors. Researchers in selected locations, such as the U.S. and U.K., contribute to datasets in a range of languages. The converse appears also true: English is the most common dataset language even for researchers in countries that do not speak English as an official language. For all other languages, the majority of datasets are contributed by countries that speak the language itself officially, for example, Bengali datasets mainly originate from Bangladesh and Russian datasets from Russia. Arguably, this may reflect the contextual nature of hateful communication, which requires not only linguistic proficiency, but also deep cultural situatedness—researchers’ own experiences (historical, cultural, familial, and personal) shape the way they act in the world around them, in this case through their focus on different languages, and possibly different phenomena: for example, what hateful communication looks like in Germany may be shaped by its current sociopolitical condition as well as its history, and therefore may significantly differ from hateful communication in neighboring countries such as France. This opens questions on the ability of hateful communication research to be effective in social contexts that are currently not represented in datasets. Hateful datasets by language and the researchers’ location. We show the distribution of the top 16 language datasets and the 40 most common locations of the researchers who created these datasets. The frequency of datasets is log-scaled to reduce the dominant effect of English language datasets. We see that research in English is widespread across many geographic regions, while researchers from the US and UK contribute to research in a variety of languages. Spanish and Arabic are also researched in multiple countries, reflecting the spread of their worldwide speakers. On the other hand, research in other languages is concentrated in countries or locations where they are most widely spoken, for example, publications with Indonesian and Russian datasets originate from Indonesia and Russia, respectively.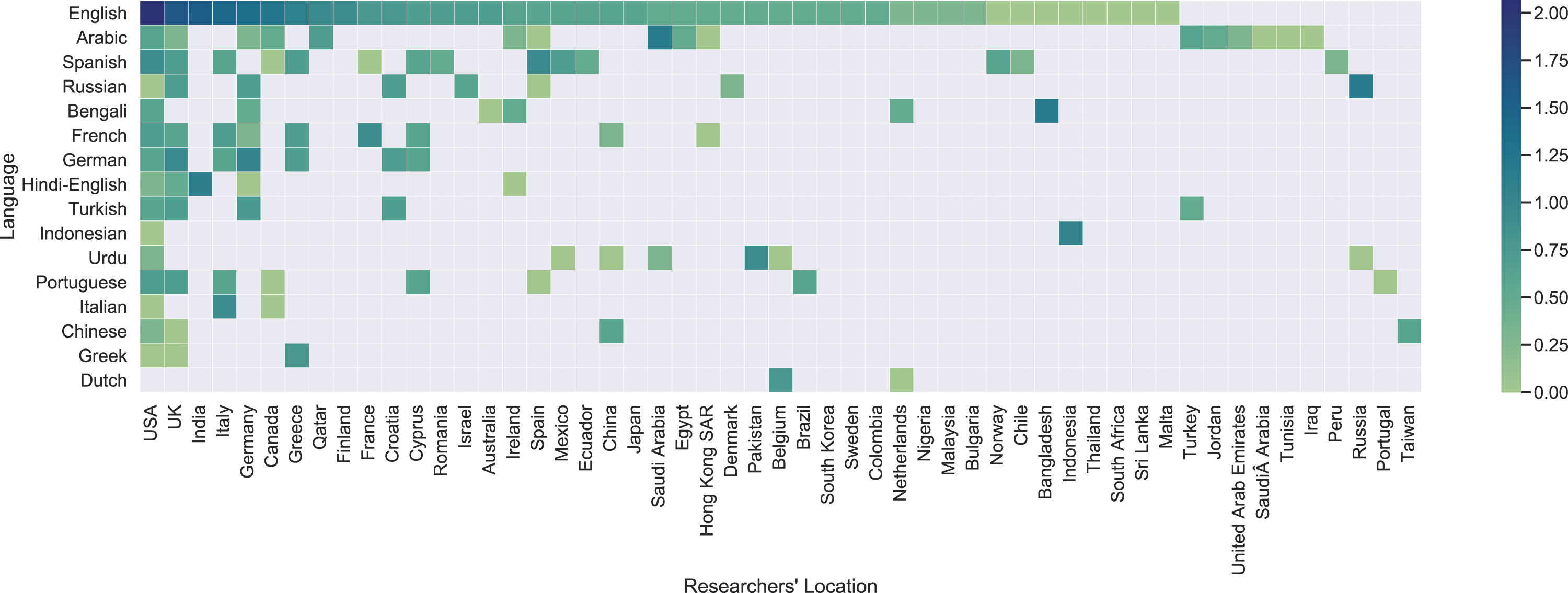
Diversity of Topical Focus
Hate speech is the most popular construct covered by research in hateful communication with 28% (138 datasets from 97 publications), followed by cyberbullying with 13% (62 datasets from 40 publications), offensiveness with 13% (62 datasets from 39 publications), abusiveness with 12% (59 datasets from 40 publications), toxicity with 8% (38 datasets from 27 publications), and sexism with 3% (13 datasets from 10 publications).
Given the relevance of situatedness for hateful communication research, we further unpack the relationship between how researchers define the construct under study and the language of the datasets. We find that how researchers define a construct varies significantly depending on the language of the dataset. To gain qualitative insights into those differences we use word clouds that surface the most discriminative terms used in construct definitions across various languages. Figure 9 shows the differences between the top 6 languages in our sample. To surface the most discriminative terms used in construct definitions across various languages, we use an approach based on Term Frequency Inverse Document Frequency (TF-IDF). Specifically, we combine the construct definitions of all datasets in a language into a single document, compute the TF-IDF scores of each keyword in all documents, and then highlight keywords with a TF-IDF above the threshold of 0.01. This approach highlights the words that are especially salient for certain languages, instead of words that are common across all languages. Our results show that gender is emphasized in French and Spanish datasets, while race and religion are more pertinent in Arabic datasets. This highlights the diversity of conceptualizations of hate across different languages. Considering those differences is especially important when researchers merge and translate datasets to train hateful content detection systems which is a promising approach, especially for under-resourced languages (Röttger et al., 2022). Wordclouds summarizing the construct definitions across different languages, with the color highlighted by TF-IDF scores of the keywords. While English and Bengali datasets’ constructs are defined to include many different targets, we can see gender is emphasized in French and Spanish datasets, while race and religion are more pertinent in Arabic datasets.
Summary
Our results highlight that the quality of datasets according to extrinsic factors is relatively low. Only half of the datasets are directly accessible, and data interoperability may be hindered by discrepancies in how researchers conceptualize the construct. However, we see an increase in multilingual datasets over time, which is a positive indicator for the dataset quality, since it signals increases in the diversity and coverage of the dataset. Before 2018, U.S.-based researchers led the production of hateful communication datasets, which are predominantly in English. Since, with a growing number of researchers from various backgrounds involved, the overall volume and the diversity in languages and targets of hateful communication have increased, which also contributes to an improved representation of hateful communication in the collection of datasets in the field as a whole.
Q2: Which Identities are Discussed as Targets of Hateful Communication in the Scientific Literature?
The previous section analyzed the temporal evolution of the production of hateful communication datasets and unpacked how those identities relate to different practices that affect the qualities of the datasets. Next, we analyze the identities that this body of research focuses on—in particular, the identities of the targets of hateful communication. Following frameworks for assessing the quality of datasets (Sen et al., 2021), we track how targets are included in the conceptualization phase of the work—that is, in the definitions of the constructs under study—in the operationalization phase—that is, in the choice and design of automated or manual labeling procedures, as well as sampling and data collection procedures.
Diversity of Targets in the Literature
Here we show how the literature divides its effort among targets that are mentioned in the construct definition and/or are considered in the data creation process. In this analysis, we combine conceptualized and operationalized targets for the large sample of 341 papers.
Figure 11 shows the distribution of papers that describe targets explicitly over time. Overall, 64% (314) of all datasets mention at least one specific target group, contrasted to the other 36% (178) of datasets that explore hateful content as a general phenomenon without covering any identifiable target groups. Distribution of conceptual or operationalized targets across languages. The most popular target categories are race, gender, and religion. Race is the most frequent target studied in English, German, Portuguese, and Italian datasets. In contrast, gender-based abuse is widely studied in Spanish, French, and Hindi-English code-mixed datasets, and religion is the most frequent target for Arabic, Turkish, and Indonesian, and one of the main targets in Bengali and Urdu. Other target attributes like class, disability, and age are rare. Temporal variability of targets included in the literature. We see that there has been a gradual rise towards multi-target datasets.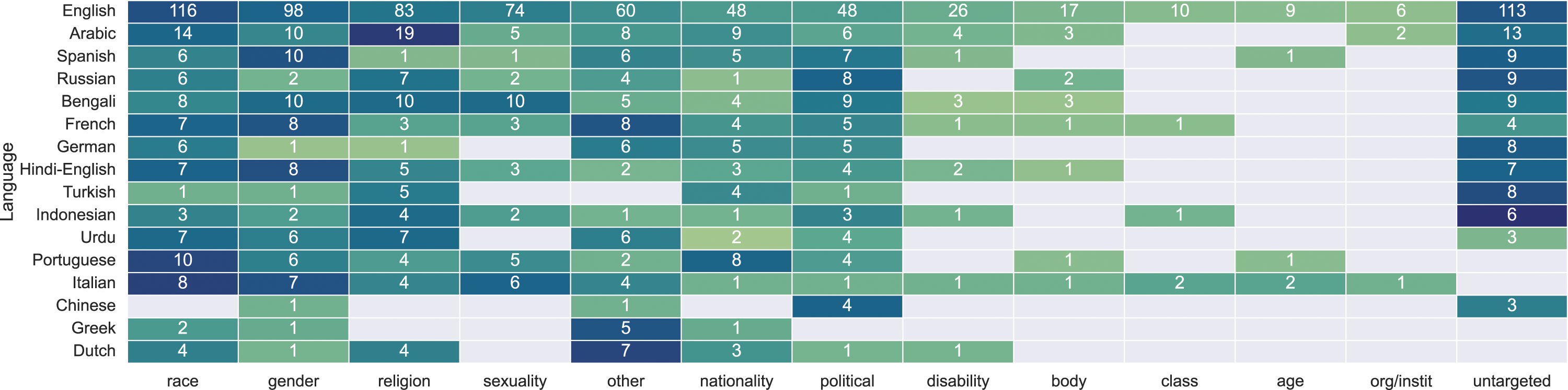
The most common target identities are race (38% (188) datasets), gender (35% (172) datasets), religion (32% (158) datasets), sexuality (22% (110) datasets), and political affiliation (19% (92) datasets). There are also 21% (103) of all datasets containing targets outside our predefined categories which we label “other”; examples of other targets include celebrities (Lu et al., 2020) and students (Del Bosque & Garza, 2014). Although certain targets are underrepresented in hateful communication datasets (e.g., groups discriminated against for their age, body image, social class, and organizational/institutional affiliation), overall, this research space appears in the process of becoming more inclusive: since 2017, the number and diversity of targets increased compared to the preceding five years. Figure 11 summarizes how the normalized distribution of targets shifted over time, whereas Figure 12 shows the multiplicity of targets per dataset and year. Yearly proportion of targets in datasets over time based on our literature review. There has been an increase in attention towards targets beyond race, gender, and religion, especially after 2017.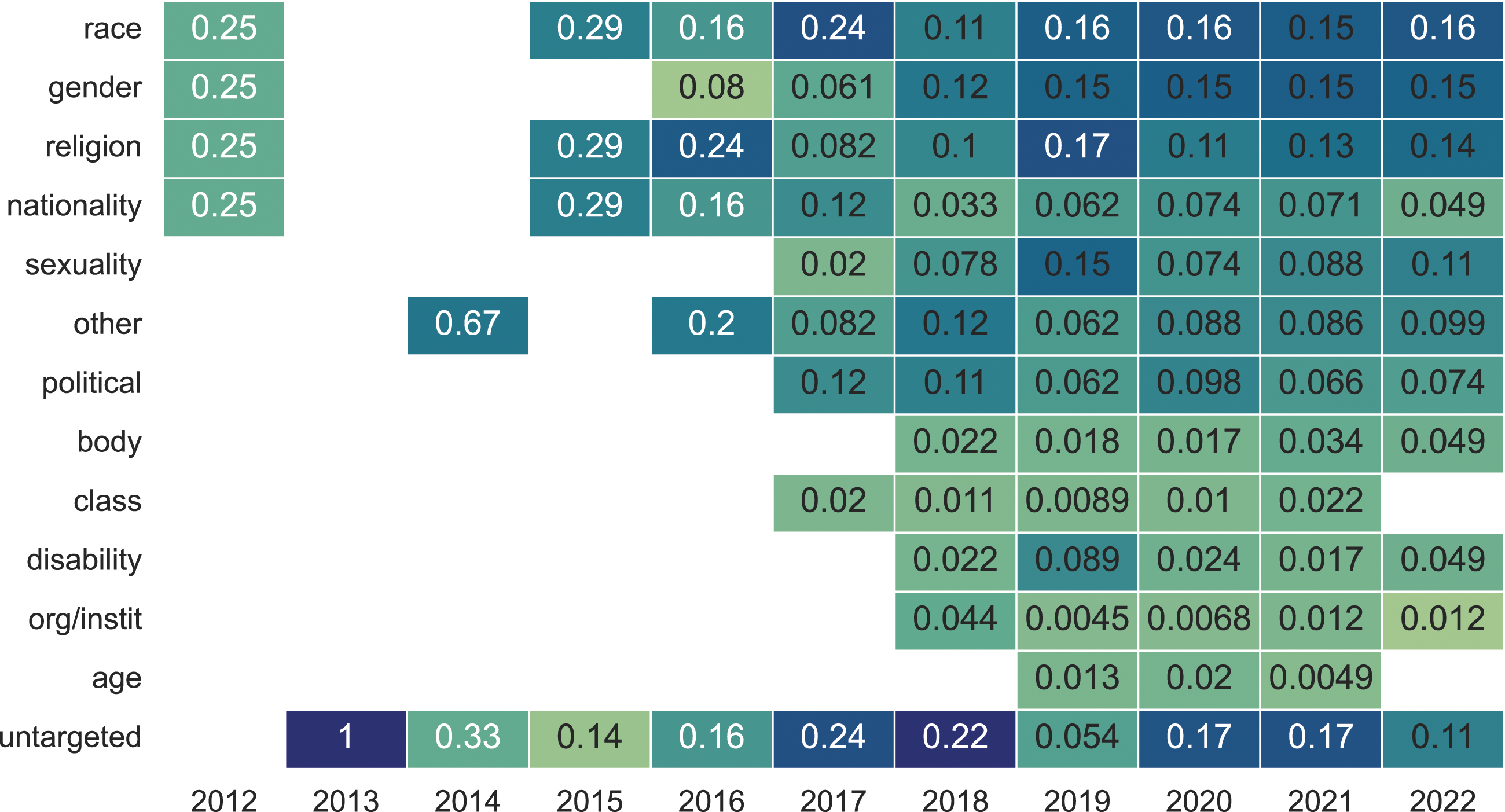
When looking at the diversity of targets that are represented in different languages (see Figure 10), we see differences between languages that are also in line with the differences in the conceptualizations that we discussed before (see Figure 9). For example, religious hatred, particularly Islamophobia is a major focus in Muslim-majority countries where Arabic, Turkish, Bengali, and Urdu are spoken (Turkey, Bangladesh, Pakistan, etc.), while gender is the most frequent target in Spanish, French, and Hindi-English datasets. While those variations in the prominence of targets may be a reflection of specific cultural and political factors in countries where these languages are spoken, it is important to consider those differences when datasets are used for training multilingual hate detection systems.
Summary
Datasets are increasingly specific about which targets they aim to include by applying more refined and targeted sampling strategies, and diverse in the range of targets they cover. However, datasets rarely cover certain target identities such as age, body image, and organizational/institutional affiliation. Differences in which targets are represented in different languages are very pronounced and can hinder the interoperability of datasets.
Q3: Which Identities are Included as Targets in Hateful Communication Datasets, Even if not Explicitly Mentioned in the Literature?
Next, we assess how the targets that are described in the literature are empirically included in the datasets themselves. First, we report on the diversity of dataset creation strategies observed in the literature, briefly discussing their potential impact on the composition of resulting datasets. Second, we aim to identify, if any, the discrepancy between conceptualized, operationalized, and detected targets. For this in-depth analysis, we focus on a convenience sample of 15 widely cited and easily accessible English language datasets. Three computational social science (CSS) researchers independently annotated conceptualized and operationalized targets in the 15 publications, discussing differences until consensus. Then, we computationally analyze the datasets to find detected targets, which may be present regardless of whether they were conceptualized or operationalized in the accompanying publications.
We first give an overview of the different dataset creation strategies found in the literature, then compare conceptualized and operationalized targets, and finally compare them in aggregate against detected targets.
Diversity and Impact of Dataset Creation Strategies
For 34.6% of datasets (170 datasets from 131 publications), the procedure to collect the dataset is explicitly mentioned. The most common strategy is full or partial random sampling (34% (57) datasets), followed by the use of a specifically developed lexicon, corpus, dictionary, or otherwise assembled list of topically relevant terms and keywords (31% (52) datasets). Other than that, the focus on specific languages (8% (14) datasets) and the use of classifiers (5% (9) datasets) are additional dataset creation strategies in active use.
There is a direct link between the dataset creation strategy used and the composition of the resulting dataset. Datasets created using fully or partially random sampling are expected to cover a broad range of targets (e.g., the dataset by Wulczyn et al., 2017), while datasets that result from term- and keyword-based lists naturally tend to more precisely capture the specific group of targets operationalized via the underlying list (e.g., the dataset by Waseem & Hovy, 2016).
Conceptualized versus Operationalized Targets
Confusion Matrix, Showing the (Mis-)match Between Conceptualizations and Operationalizations of Targets. The (Mis-)matches are Analyzed on a Dataset Level Based on our Convenience Sample.
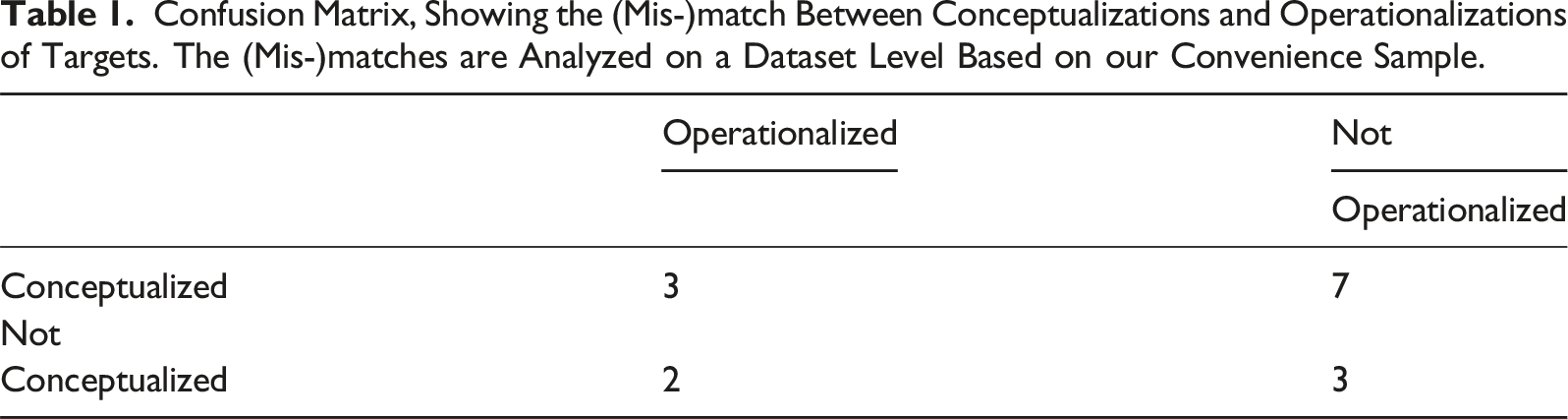
The majority of datasets (7 out of 15) conceptualize targets without explicitly labeling which targets are present in their datasets. Upon close inspection, we find that targets are often included in the annotation instructions, but the annotators’ task is ultimately to label whether a message contains hateful communication or not in an untargeted, binary way. We speculate that this is for a cost/benefit trade-off. Firstly, annotating targets can be expensive since it requires additional time and effort. Secondly, the downstream applications are often formulated as binary problems—for many benchmarks and shared tasks, models are expected to identify hateful communication and not necessarily its targets.
2 out of 15 datasets operationalize more targets than they conceptualize. We find this is due to post hoc analyses where the authors of the datasets decided to label data characteristics they found interesting. As an example, Bretschneider and Peters (2017) set out to study anti-immigrant hate, but after finding several discussions about politicians in the data, they included “politicians” as one of their operationalized targets. Three datasets neither conceptualize nor operationalize targets because they study phenomena like general abuse or toxicity. Only three datasets operationalize the exact targets they conceptualize. This finding is surprising and stresses the need for standardized reporting practices in the field.
Conceptualized/Operationalized versus Detected Targets
Considering the inconsistencies around conceptualized and operationalized targets observed in our convenience sample, we combine them before comparing them against detected targets. In the following analyses, we focus on the proportion of the datasets that are labeled as containing hateful communication because those instances supposedly include conceptualized and operationalized targets.
Figure 13 shows the distribution of detected targets. Black frames denote conceptualized/operationalized targets. Each cell displays the proportion of instances containing each detected target category. Instances for which we could not detect any target are reported in the “untargeted” column. Distribution of instances labeled as “hate” over the target categories per dataset. To the right of the heatmap, the share of instances labeled as “hate” is indicated for each dataset. The last row shows the distribution over the target categories for all datasets aggregated. Darker shades of green correspond to a higher share of targets in the respective target category. A red frame around a cell indicates that the target category has been either explicitly conceptualized or operationalized by the dataset creators in the corresponding publication. If the publication does not explicitly conceptualize or operationalize any targets, “untargeted” is highlighted. The activity diagram of literature survey and annotation with an example.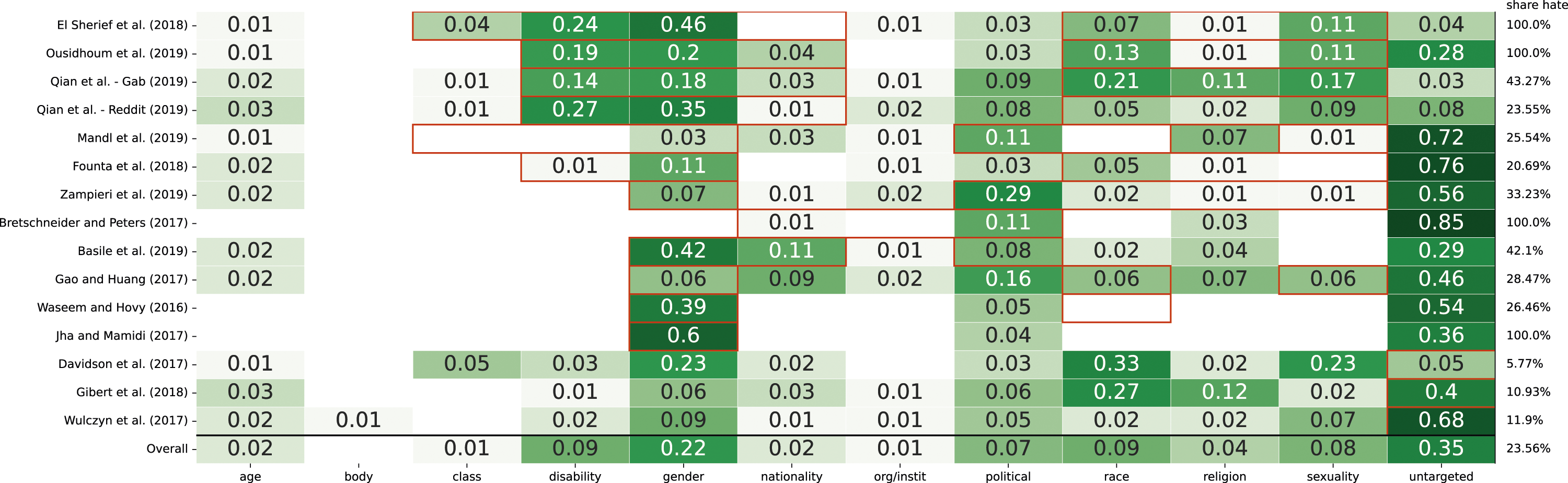
Among those publications that explicitly conceptualize or operationalize specific targets, we find that the fraction for single categories of detected targets that were not part of these definitions ranges between 1% and 16%. Although relatively small, the presence of non-conceptualized targets is consequential, as it may impact the performance of classifiers trained on the data in terms of divergent validity—for example, a classifier claiming to detect hate toward women (conceptualized target: gender) may in practice detect opposition to left-wing ideology (detected target: political affiliation), which may be empirically correlated in the dataset; the application of such classifier would have unintended consequences, such as censoring political views rather than preventing harm.
While three papers in our sample did not declare targets in their conceptualization or operationalization we find that empirically, the corresponding datasets cover a wide range of detected targets in varying proportions (1%–33% of the instances). This unequal distribution may negatively impact reliability in detecting hateful communication toward underrepresented targets. Note that the issue of distribution among different targets is also present in papers that conceptualize and operationalize targets. We provide suggestions for researchers on how to critically address this issue in the discussion section.
Finally, we identify an overarching pattern. Works that explicitly operationalize the targets they conceptualized (Jha & Mamidi, 2017; Ousidhoum et al., 2019; Waseem et al., 2017), also include a higher fraction of matching detected targets—in other words, the datasets are empirically good fits with what was documented in the paper and annotated by labelers. In contrast, targets that are conceptualized but not operationalized are also frequently underrepresented as targets in the datasets, or missing altogether (Basile et al., 2019; Founta et al., 2018; Gao & Huang, 2017; Mandl et al., 2019; Qian et al., 2019; Zampieri et al., 2019). We speculate that including targets in the operationalization phase prompts authors and labelers to be aware of them throughout the whole dataset creation process. Hence, what benefits from such a practice is not just the quality of documentation, but also the quality of the dataset itself.
Summary
Conceptualized and operationalized targets match in only 20% of datasets in our sample. For datasets that conceptualize or operationalize targets, up to 16% of their instances contain targets that were never conceptualized nor operationalized, which may make classifiers perform unpredictably on such targets. Datasets that do not declare targets at all cover targets unequally, which may impact the accuracy of classifiers on underrepresented targets. It is crucial to underscore that our findings are derived from a convenience subset of 15 datasets. While these datasets hold significant prominence within the domain of hateful communication, being frequently referenced sources, future research is needed to assess if the observed patterns persist in larger samples.
Discussion and Conclusions
The State of Hateful Communication Datasets
This review proposed a broader outlook on the quality of hateful communication datasets, the identities of the targets of hate, as well as the linguistic diversity and backgrounds of the researchers involved in the processes of data collection, annotation, and curation. In the context of the computational study of hateful communication, we unpacked how the identity and diversity of the targets included in the research not only depend on the identities of the data annotators but also on the wider research context in which datasets are created. We found that the production of hateful communication datasets is concentrated in selected locations: researchers with affiliations in the U.S. contribute over one-fourth of the datasets. Similarly, almost two-thirds of the datasets are in English. This is in contrast with the situatedness of hateful communication research: languages other than English are mainly covered by researchers located in native-speaking countries, and the constructs that they study differ depending on such languages. This arguably reflects the need for deep knowledge about the context where hateful communication takes place.
Furthermore, it is important to discuss the potential causes and effects of this apparent conflict between an established U.S.- and English-centric mainstream, and the need for contextualization in the specific domain of study. On the one hand, the relative homogeneity of datasets cast doubt on their suitability to train machine learning models that capture context-specific aspects of hateful communication. We find that promisingly, the production of hateful communication datasets is not only growing in output but also diversifying in who is represented in it—in terms of both the researchers that produce it and the identities that are included in the data.
On the other hand, multiple factors may slow down the diversification of this field. We argue that researchers may be incentivized to produce datasets in English both explicitly and implicitly. Producing datasets is costly: obtaining reliable annotations for a wide range of targets and at a scale requires substantial investment. Moreover, curating datasets in new languages may require developing specialized resources, contrasted with highly available tools and techniques to sample and process data in English. Therefore, it is unsurprising that new datasets rarely introduce new languages, and that the Global North is among the largest producers of datasets, which raises concerns about the ability of this field to avoid reproducing inequality. Furthermore, curating datasets in English may widen the user base for the datasets and consequently, increase the visibility of the research.
In this light, institutionalized incentives for promoting local impact are essential to sustain the diversification of the field, especially through the inclusion of a broader range of researchers.
Implications for the Users of Hateful Communication Datasets
Although research is broadening its attention towards a diverse range of targets of hateful communication, we found that some identities (such as class, disability, and age) receive less attention. Moreover, a sizable fraction of the publications to date do not specify which targets are included in their datasets, and for the publications that do, there is a discrepancy between the targets documented in the publications and those effectively present in the datasets. These findings can be problematic for the users of hateful communication datasets—especially those who train machine learning models on such datasets to detect hateful communication in different application domains.
Lack of representation, under-representation, and undocumented representation of targets all make machine learning models unable to perform accurately and predictably. Determining an ideal ratio of targets in a dataset may not be practical or possible. However, for research to have a positive real-world impact, the dataset should precisely represent the targets it aims to capture. Future research could explore participatory approaches (Maronikolakis et al., 2022), data documentation (Miceli et al., 2021), and theory-informed and target-aware data collection procedures (Li & Caragea, 2021; Samory et al., 2021; Uyheng et al., 2022) as promising avenues to overcome and document the mismatch between the conceptualized, operationalized, and detected targets.
Implications for the Creators of Future Hateful Communication Datasets
We highlighted a gap in how present-day datasets cover the variety of hateful communication targets. Especially, the field is moving towards including multiple targets in each dataset, which enables sophisticated computational modeling and robust evaluation. Thus, there are ample opportunities for the creation of novel datasets that better serve minority identities. Furthermore, we find a shortage in studies focusing on intersectionality—while some papers do explicitly operationalize intersectional targets (Vidgen & Derczynski, 2020; Waseem et al., 2017), they are a small portion of datasets studied in this work.
Yet we also identified avenues for improving data practices, to sustain high-quality standards in this socially relevant field. We stress the importance of clearly including targets in all phases of the dataset creation process, starting with the conceptualization of the construct that the dataset aims to capture (whereas, several papers to date omit this crucial information). Targets should also be included in the operationalization phase of the data curation process, for example, in sampling strategies, annotation instructions, and annotation labels if possible (whereas, almost half of the conceptualized targets were not operationalized in the literature). Finally, authors should take steps to identify targets in their collected dataset that they did not explicitly intend to include, and be upfront about their treatment of such cases (whereas, we found that almost all papers in our sample had targets included in their dataset that were not described in the paper). Overall, we surfaced the need for better conceptualization, operationalization, and documentation practices around targets. To this end, we believe it a fruitful avenue of research to develop tools and standard procedures to aid the fine-grained documentation of targets.
Future Work and Limitations
This review proposes ways forward to improve the quality of datasets in future studies. First, instituting benchmarks, measures and shared tasks to empirically evaluate the dataset generalizability across contexts and targets may promote critical approaches to data quality; Second, research on the science of computational social science should arguably aim for improved measures of data quality, to establish causal links between the quality of datasets and the practices, views and characteristics of those involved in the creation. Finally, we argue that higher reflexivity in this research field may be beneficial, such as via positionality statements in papers and datasets.
The study presented has some limitations that must be considered when interpreting its results. Although we attempted to cover most of the existing literature and datasets on hateful content, we made some restrictive assumptions that may have resulted in missing works. Firstly, we only examined three academic databases, which may not have included all relevant publications. Secondly, we only included English publications, meaning that language-specific conferences were excluded, potentially leading to the exclusion of relevant research. Lastly, we excluded all papers that did not mention whether a newly created dataset was introduced based only on the information provided in the abstract. This may have led to an increased number of false-negative decisions.
Furthermore, we discovered during the annotation process that while it is relatively easy to decide if a paper talks about targets or not, it is often non-trivial to identify the conceptualization of targets and differentiate it from the operationalization. For example, in Warner and Hirschberg (2012), hate speech and potential targets are mentioned in several sections of the paper, such as the introduction and related work. Therefore it is not easy for annotators of the literature review to determine the target conceptualization employed in the context of the respective work. On the other hand, based on the annotator instructions, it is clear that targets are explicitly annotated as anti-semitic, anti-black, anti-Asian, anti-woman, anti-muslim, anti-immigrant, or other-hate (Warner & Hirschberg, 2012). To avoid building our analysis on annotations where we know that annotators had a hard time and also in part disagreed, we decided to merge the conceptualized and operationalized target annotations for the large sample. For the small sample, we provide an in-depth discussion of the differences together with more detailed and time-consuming annotations.
Also, our dictionary-based approach to identifying targets is limited and prior work suggests that the Hatebase lexicon includes terms that are generally not used in a hateful context (Davidson et al., 2017). Our small validation study does not assess the recall of the dictionary but shows that the precision is acceptable (0.68). We apply our dictionary only to the small sample and acknowledge that it would have been ideal to conduct this analysis on the complete body of datasets. However, we are confident that the subset provided by Risch et al. (2021) is an adequate representation.
Finally, our study of targets is abstracted at a demographic identity level, focusing on broad categories of race, gender, religion, etc. We do not distinguish between finer-grained identities within these, for example, we do not differentiate Islamophobia from anti-Christian rhetoric. Future research can build on our work to specifically measure the representation of persecuted minority groups within these categories.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was created in the context of the project: Digital Dehumanization: Measurements, Exposure and Prevalence (DeHum), funded by the Leibniz Association Competition (P101/2020).
Data Availability Statement
We acknowledge the importance of open and transparent data sharing and adhere to the FAIR (Findable, Accessible, Interoperable, and Reusable) principles. The data used in this study are available via a data archive for non-commercial purposes, subject to any necessary ethical and legal considerations. 4