
Abstract
Background
Decisions about new health technologies are increasingly being made while trials are still in an early stage, which may result in substantial uncertainty around key decision drivers such as estimates of life expectancy and time to disease progression. Additional data collection can reduce uncertainty, and its value can be quantified by computing the expected value of sample information (EVSI), which has typically been described in the context of designing a future trial. In this article, we develop new methods for computing the EVSI of extending an existing trial’s follow-up, first for an assumed survival model and then extending to capture uncertainty about the true survival model.
Methods
We developed a nested Markov Chain Monte Carlo procedure and a nonparametric regression-based method. We compared the methods by computing single-model and model-averaged EVSI for collecting additional follow-up data in 2 synthetic case studies.
Results
There was good agreement between the 2 methods. The regression-based method was fast and straightforward to implement, and scales easily to include any number of candidate survival models in the model uncertainty case. The nested Monte Carlo procedure, on the other hand, was extremely computationally demanding when we included model uncertainty.
Conclusions
We present a straightforward regression-based method for computing the EVSI of extending an existing trial’s follow-up, both where a single known survival model is assumed and where we are uncertain about the true survival model. EVSI for ongoing trials can help decision makers determine whether early patient access to a new technology can be justified on the basis of the current evidence or whether more mature evidence is needed.
Highlights
Decisions about new health technologies are increasingly being made while trials are still in an early stage, which may result in substantial uncertainty around key decision drivers such as estimates of life-expectancy and time to disease progression. Additional data collection can reduce uncertainty, and its value can be quantified by computing the expected value of sample information (EVSI), which has typically been described in the context of designing a future trial.
In this article, we have developed new methods for computing the EVSI of extending a trial’s follow-up, both where a single known survival model is assumed and where we are uncertain about the true survival model. We extend a previously described nonparametric regression-based method for computing EVSI, which we demonstrate in synthetic case studies is fast, straightforward to implement, and scales easily to include any number of candidate survival models in the EVSI calculations.
The EVSI methods that we present in this article can quantify the need for collecting additional follow-up data before making an adoption decision given any decision-making context.
Keywords
Introduction
The expected value of sample information (EVSI) quantifies the expected value to the decision maker of reducing uncertainty through the collection of additional data,1,2 for example, a future randomized controlled trial. Although a few studies have considered the use of EVSI methods at interim analyses of adaptive trials, 3 overall little research has been done on EVSI for trials that are ongoing at the point of decision making.
In the past decade, the European Medicines Agency has introduced regulatory mechanisms that are aimed at accelerating the licensing of new pharmaceuticals, such as adaptive pathways 4 and conditional marketing authorizations. 5 When evidence is obtained from a trial at an early stage, the events of interest, such as disease progression or death, may have only been observed in a small proportion of patients. Health care authorities therefore have to issue guidance on new pharmaceuticals based on less mature evidence than previously, resulting in greater uncertainty about clinical and cost-effectiveness. With this comes an increased risk of recommending a technology that reduces net health benefit. 6
Additional evidence can be valuable as it can lead to better decisions that improve health and/or reduce resource use. 6 Positive adoption decisions can be costly or difficult to reverse and may remove the incentives for manufacturers to provide additional data. When a trial is ongoing at the point of decision making, for example, when follow-up is continued for regulatory purposes, there may therefore be value in delaying the adoption decision until additional data have been collected in the ongoing trial and uncertainty has reduced. 7 In this context, there will be a tradeoff between granting early access to a new technology that may turn out to reduce health benefits and waiting for uncertainty to be reduced through ongoing data collection with a potential loss of health benefits while waiting. When the manufacturer is already committed to continuing the ongoing trial, the option to delay a decision is relevant even in a policy context in which the decision maker does not have the formal authority to commission research. The value of delaying the decision could be quantified, at least in theory, by computing the EVSI for the additional follow-up data.
Estimates of life expectancy and time to disease progression are often key drivers of cost-effectiveness, particularly in oncology. However, immature data means that there may be substantial uncertainty around these estimates, and they rely on extrapolation beyond the trial follow-up period. 8 The choice of the survival distribution for extrapolation can have major implications for cost-effectiveness, and uncertainty surrounding this choice can be accounted for by model averaging, which may improve the quality of the extrapolations compared with selecting a single model. 9 A potential benefit of continuing an ongoing trial is to reduce the structural uncertainty as to the most appropriate survival distribution. However, to the best of the authors’ knowledge, there is no guidance on how to compute EVSI for survival data from a trial that is ongoing at the point of decision making nor on how to account for structural uncertainty about the choice of survival model in the EVSI calculations.
In this article, we present algorithms for computing the EVSI of extending a trial’s follow-up with and without accounting for structural uncertainty. The algorithms are based on nested Markov Chain Monte Carlo (MCMC) methods and a fast nonparametric regression-based method. 10 The nonparametric regression-based method 10 is generally more practical than other EVSI approximation methods, as it neither requires nested Monte Carlo computations nor importance sampling. 11 The article is structured as follows. In the second section, we describe single-model and model-averaged EVSI algorithms for survival data from an ongoing trial. In the third section, we compare the EVSI algorithms in 2 illustrative case studies, and in a final section, we conclude with a brief discussion.
Method
EVSI for an Ongoing Study Collecting Time-to-Event Data
Decision problem and model definition
We assume a decision problem with
EVSI for further follow-up in an ongoing study
The EVSI for a new study that will provide (as yet uncollected) data,
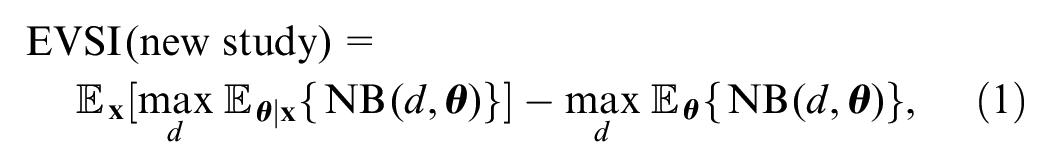
where the first term is the expected value of a decision based on our beliefs about
The value of extending the follow-up from current time
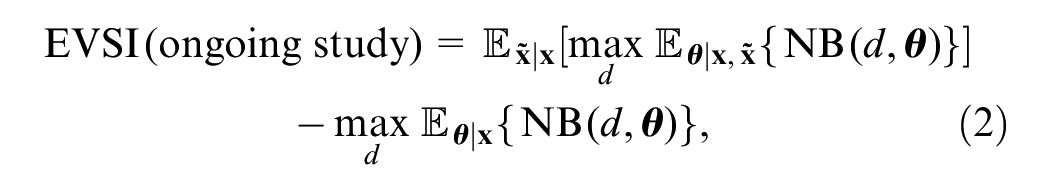
where the first term is the expected value of a decision based on our beliefs about
Specifying current beliefs about model parameters for an ongoing study
The distribution for the cost-effectiveness model parameters given knowledge at
Specifying the likelihood for ongoing time-to-event data and left truncation
To compute EVSI, we must define the data-generating distribution for the follow-up data between
Structure of Data for 1 Arm of a Study with Follow-up at 12 and 24 mo a
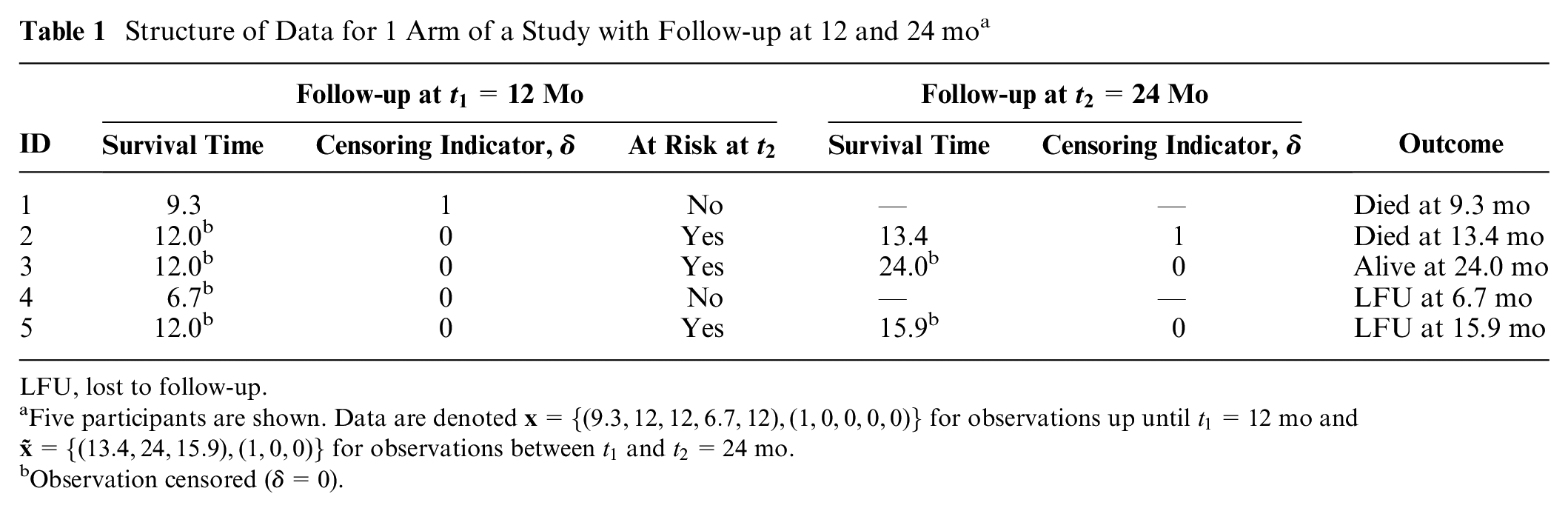
LFU, lost to follow-up.
Five participants are shown. Data are denoted
Observation censored
Survival times are usually assumed to arise from a data-generating process that can be described using a parametric model, the form of which must be chosen by the analyst.
14
Censoring is common when collecting time-to-event data, as the follow-up time may not be long enough to observe the endpoint of interest for all individuals in the trial, and some individuals may be lost to follow-up.
15
The likelihood function for survival data,
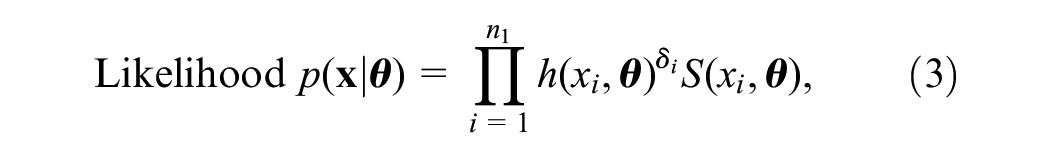
where
The data collected between time points
Once we have derived the posterior distribution for the model parameters given data at
We are now in a position to describe methods for computing EVSI that account for uncertainty about the choice of survival model.
Model-Averaged EVSI for an Ongoing Study Accounting for Survival Model Uncertainty
Survival model uncertainty and model averaging
In this section, “model” refers to the survival model for the time-to-event data
The net benefit function for decision option
and the optimal choice at time point
EVSI for an ongoing study accounting for model uncertainty
Additional follow-up data
The EVSI for an ongoing study, where we average over models, is given by
which is identical to equation (2), except that expectations are now taken over models as well as parameters (see Appendix C for a derivation).
To compute equation (6) we will need a method for generating plausible data sets
Deriving model probabilities given observed data up until
We assume that before we see the observed data
where
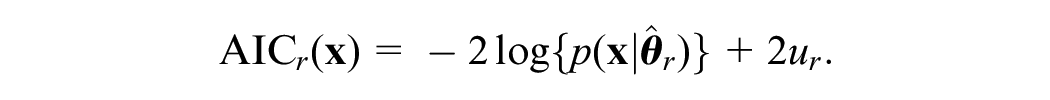
The term
Generating plausible ongoing follow-up data sets,
, that we may observe between
and
Plausible data sets from the distribution
Updating model probabilities given ongoing follow-up data from
to
We can derive our posterior model probabilities at time point
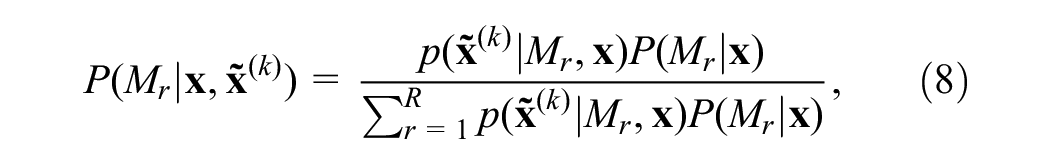
where
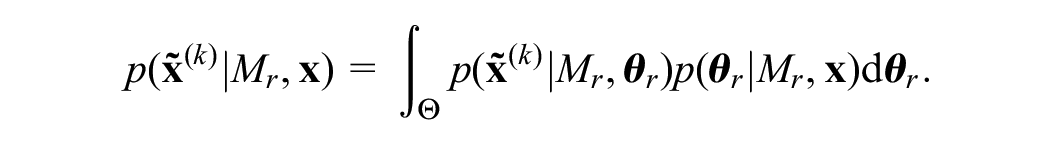
We use bridge sampling to approximate the marginal likelihood, which is a form of importance sampling that has been shown to give good approximations in a wide range of settings.21–24 The key notion behind bridge sampling is that the marginal likelihood can be written as the ratio of 2 expectations, each of which can be estimated via importance sampling. The name “bridge” reflects the incorporation in the estimator of a density function that “bridges” (i.e., has good overlap with) the 2 densities from which samples are drawn. A detailed tutorial on the bridge sampling method is given in the article by Gronau et al.,
23
and the method is straightforward to implement in the R package bridgesampling.
25
Given the bridge sampling estimates of
As with single-model EVSI, computing model-averaged EVSI (expression [6]) will require numerical methods. Nested Monte Carlo and a regression-based approach are described in Appendix D. In the next section, we will apply these methods in a synthetic case study.
Synthetic case study
We will model survival with and without accounting for survival model uncertainty.
Decision problem and model definition
Our decision problem is to determine which of 2 treatment options has the longest mean survival: a new treatment
In the single-model case, survival is assumed to follow a Weibull distribution, and the net benefit of each treatment option is assumed to equal the restricted mean survival time, given an overall time horizon of
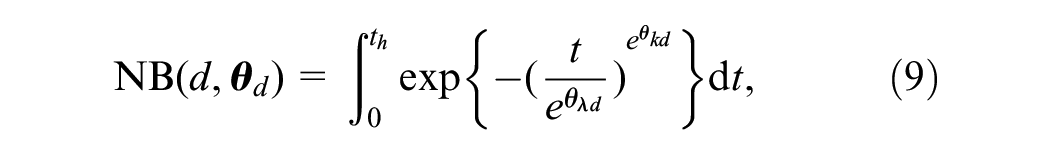
where the model parameters are the log-transformed Weibull shape and scale parameters,
In the model-averaged case, the decision problem is as above, but we assume we are uncertain about the choice of survival model,
Generating synthetic case study data sets,
, collected up to
months
We generated 2 synthetic case study data sets: one in which the hazard of death is monotonically increasing and the other in which it is monotonically decreasing. For each case study, we generated a data set with 200 participants per trial arm with a maximum follow-up of
To explore the performance of the method when the survival model was misspecified, we generated survival times evenly spaced from either a Weibull or a Gamma distribution, using the
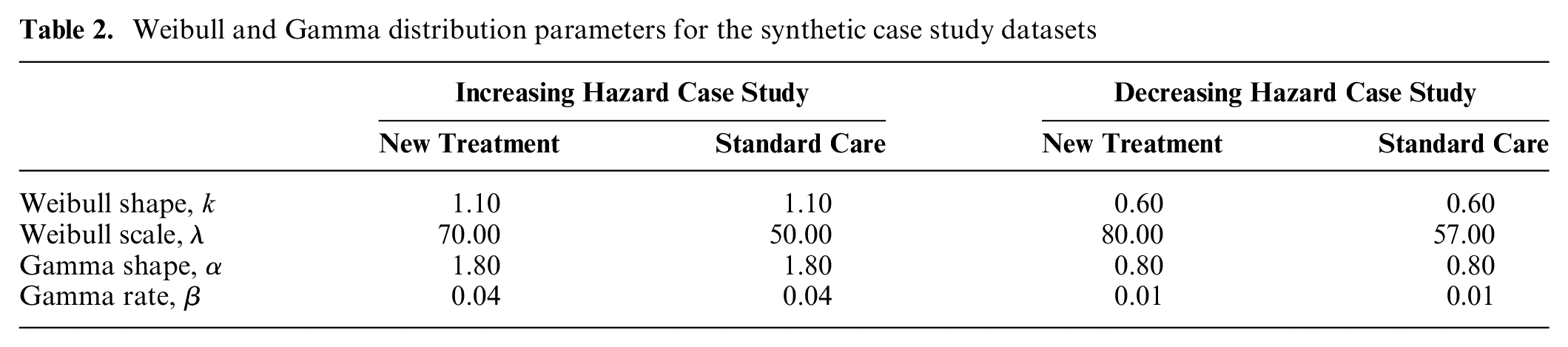
Weibull and Gamma distribution parameters for the synthetic case study datasets
We enrolled all patients in the trial at
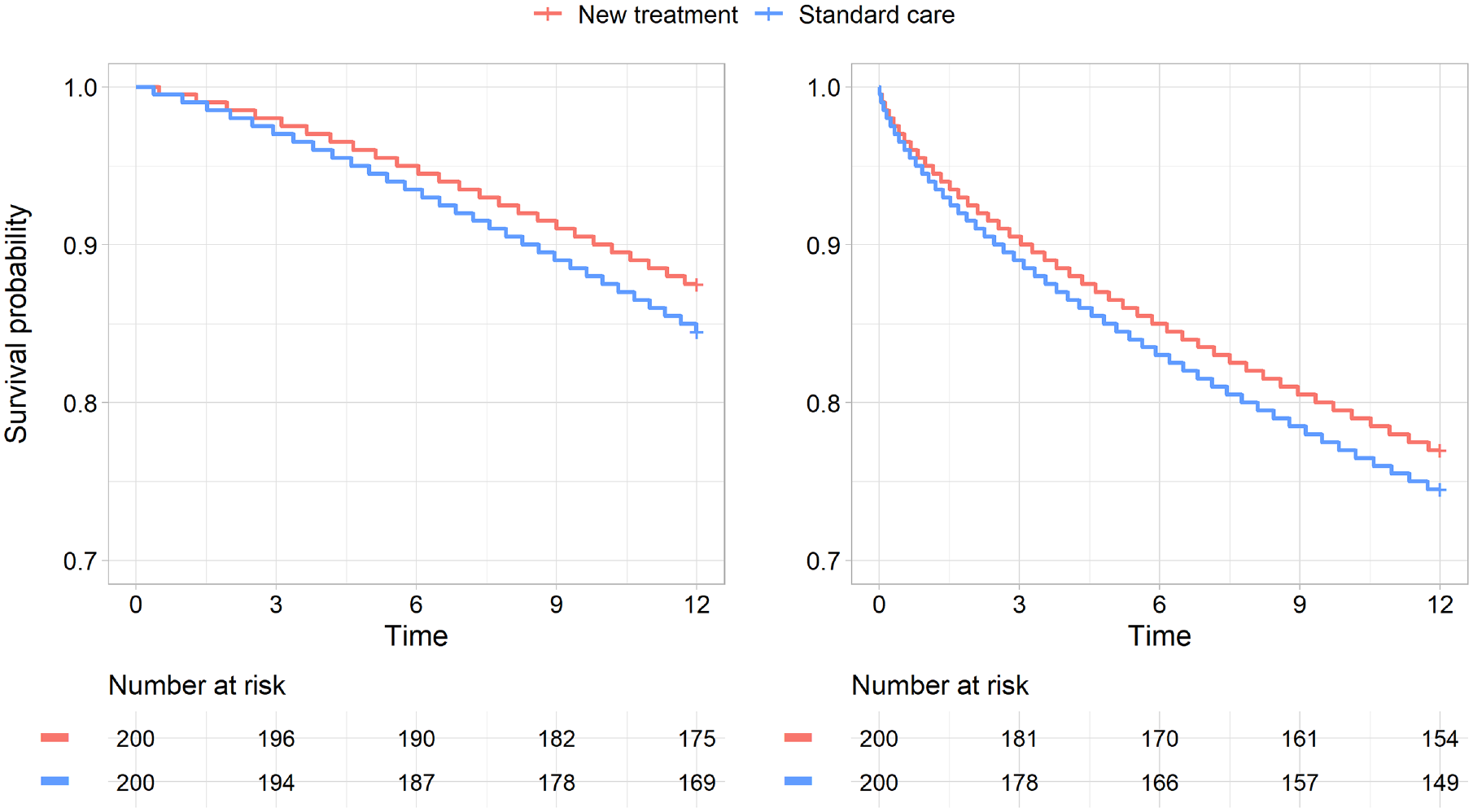
Kaplan-Meier plots for the increasing hazard data set (left) and decreasing hazard data set (right).
Initial Trial Analysis at
Months
For each synthetic case study, we analyzed the 2 trial arms separately. We fitted all 4 models to the data from each arm and estimated the model parameters using maximum likelihood (as implemented in the flexsurvreg function).
26
We assumed that our judgments about the log-transformed parameters for each survival model conditional on the observed data up to
Net benefits, AICs, and model probabilities are shown in Table 3, and means and covariances for each model are reported in Appendix G.
Mean Survival, Akaike’s Information Criterion (AIC), and Prior Model Probabilities
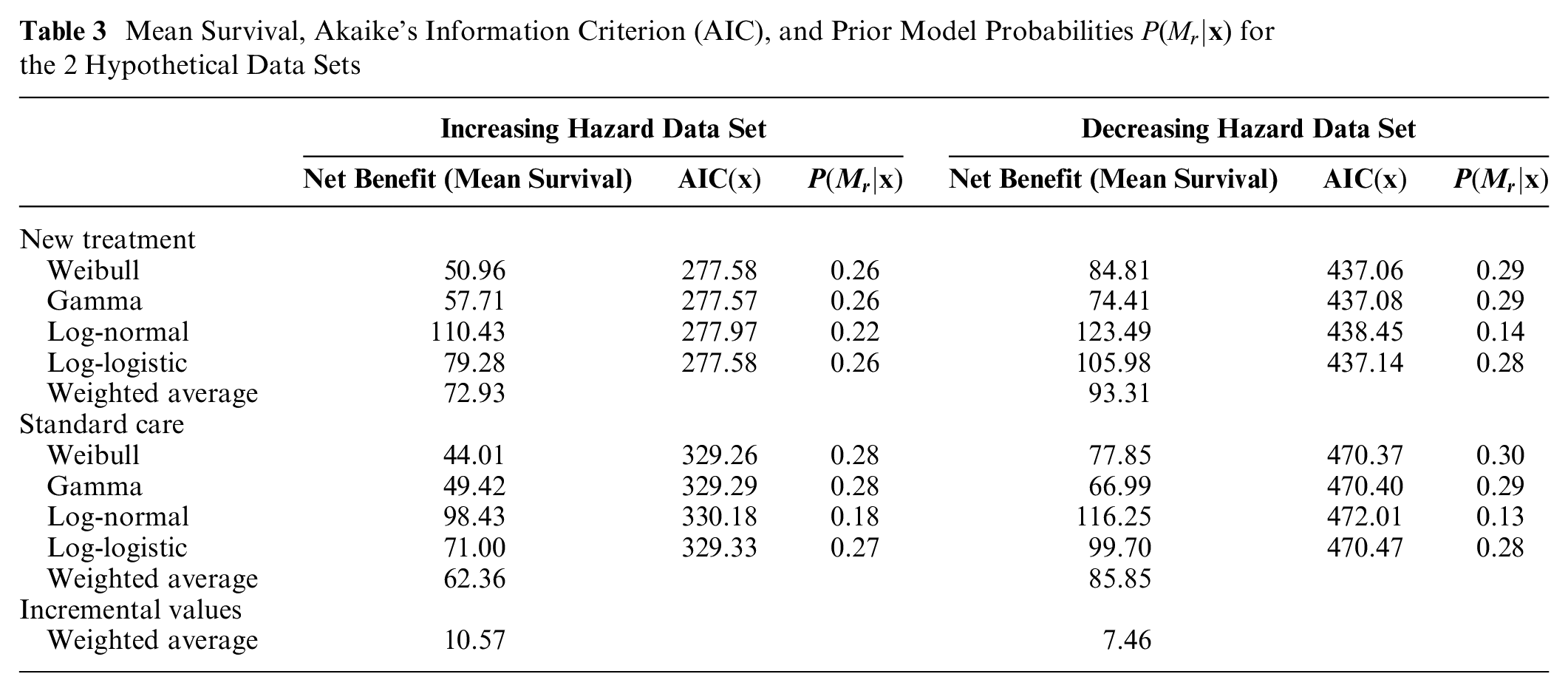
The expected net benefits (mean survival times) assuming a single Weibull model computed via Equation (9) are 50.96 versus 44.01 mo (incremental = 6.95 mo) for the increasing hazard data set and 84.81 versus 77.85 mo (incremental = 6.97 mo) for the decreasing hazard data set. The expected value of perfect information (EVPI) values, computed via Monte Carlo simulation with a sample size of
The model-averaged net benefits, weighted by model probabilities, were 72.93 versus 62.36 mo (incremental = 10.57 mo) for the increasing hazard data set and 93.31 versus 85.85 mo (incremental = 7.46 mo) for the decreasing hazard dat set. The model-averaged EVPI values are 10.32 and 9.97 mo for the respective data sets.
Generating plausible ongoing follow-up data sets,
, for the EVSI computation
Both the nested Monte Carlo and regression-based EVSI methods require a set of sampled ongoing follow-up data sets for each trial arm, denoted
In the single-model case, we first sampled log-shape and log-scale values (
In the model-averaged case, we first chose a model
Computing EVSI for ongoing follow-up via nested Monte Carlo
To sample from the posterior distributions,
In the single-model case, for each outer loop sampled data set,
In the model-averaged case, for each outer loop data set, we generated the
Computing EVSI for ongoing follow-up via regression
The generalized additive model (GAM) approach to computing EVSI for extending the follow-up until time
For each trial arm, we computed a low-dimensional summary statistic for each data set. A convenient choice here is the number of observed events
Then, for each of the 2 decision options, we fitted a GAM regression model with the stored net benefits
The GAM-based approximation method for model-averaged EVSI is identical to that used in the single-model case.
Results
EVSI Values for the Weibull Ongoing Data
The nested Monte Carlo– and GAM-based EVSI estimates for additional follow-up times of 12, 24, 36, and 48 mo (i.e.,
EVSI (SE) Values for Additional Follow-up Time for the 2 Hypothetical Data Sets Given a Weibull Distribution for the Survival Times
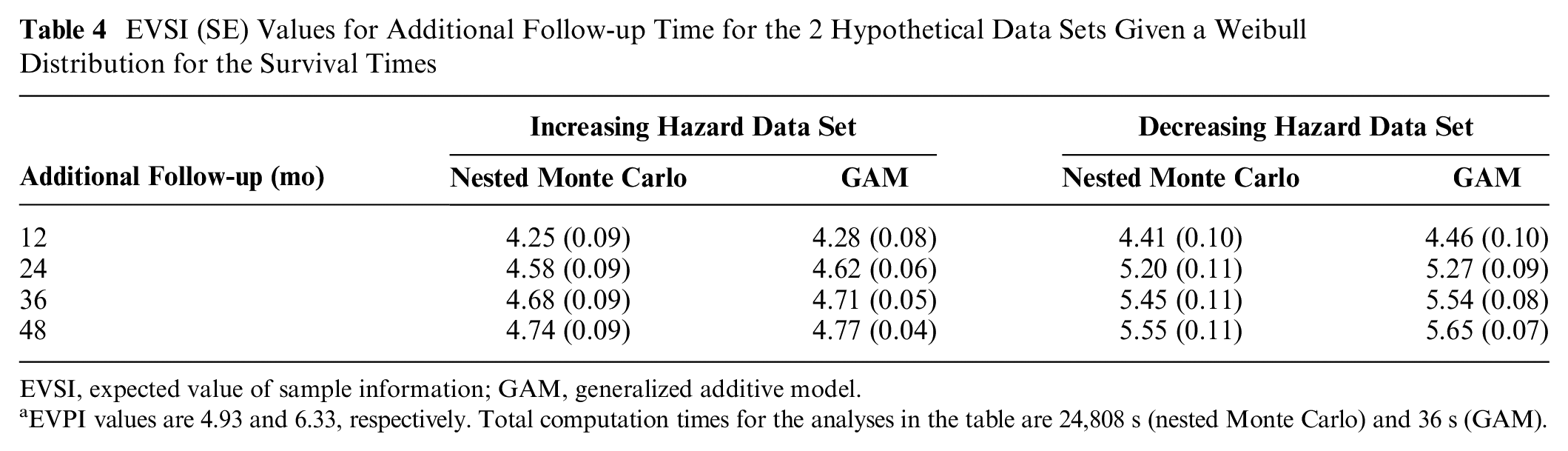
EVSI, expected value of sample information; GAM, generalized additive model.
EVPI values are 4.93 and 6.33, respectively. Total computation times for the analyses in the table are 24,808 s (nested Monte Carlo) and 36 s (GAM).
As expected, the EVSI reflects the diminishing marginal returns for increasing the follow-up duration and converges toward the EVPI. The EVSI varies depending on the underlying hazard pattern, even when point estimates of mean incremental survival benefit are similar (6.95 mo for the increasing hazard data set and 6.97 mo for the decreasing hazard data set). The increasing hazard data set has lower numbers of prior observed events and higher expected numbers of future events for the additional follow-up time than the decreasing hazard data set does, which—all else equal—is expected to result in greater EVSI values. This upward effect on EVSI is, however, canceled out by the downward effect of lower estimates of mean survival, resulting in greater EVSI values for the decreasing hazard data set than for the increasing hazard data set.
The GAM method agrees well with the MCMC method, with the benefit of a greatly reduced computational cost. The MCMC inner loop for the Monte Carlo method used parallel processing, but even with this additional efficiency, the regression method was approximately 700 times faster than the nested Monte Carlo method was. We used a machine running Windows 10 with an Intel Core i9 CPU with 15 threads running on 8 cores at 2.40 GHz and with 32 GB RAM.
Of note is that the standard errors for the nested Monte Carlo estimator slightly increase with increasing follow-up duration, while the opposite is true for the GAM estimator. This is due to different mechanisms through which the effective sample size of the generated data
Model-Averaged EVSI Values
The nested Monte Carlo– and GAM-based model-averaged EVSI estimates for additional follow-up times of 12, 24, 36, and 48 mo (i.e.,
Model-averaged EVSI (SE) Values for Additional Follow-up Time for the 2 Hypothetical Data Sets Given a Mixture of Weibull, Gamma, Lognormal and Log-logistic Distributions for the Survival Times
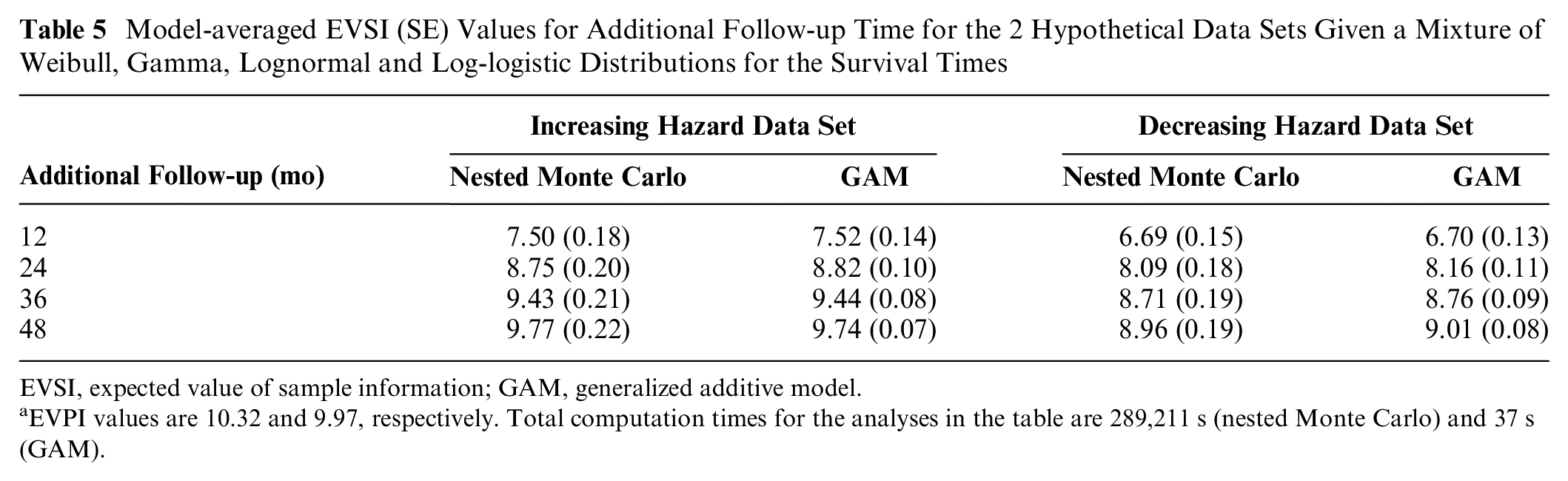
EVSI, expected value of sample information; GAM, generalized additive model.
EVPI values are 10.32 and 9.97, respectively. Total computation times for the analyses in the table are 289,211 s (nested Monte Carlo) and 37 s (GAM).
As expected, the EVSI converges toward the EVPI as follow-up time increases, and there is good agreement between the 2 methods. The model-averaged EVSI values for additional follow-up are greater than the Weibull model EVSI (Table 4), which reflects the additional value in reducing model as well as parameter uncertainty. The GAM method is approximately 8000 times faster than the nested Monte Carlo method.
Expected net benefit of sampling
The net value of additional data collection can be quantified by computing the expected net benefit of sampling (ENBS).
32
In the context of an ongoing study, the ENBS is the difference between the EVSI for collecting additional data between
If the adoption decision is reversible, then there are 2 decision options given that the new technology is expected to improve net health benefits: “approval with research” (AWR), which refers to approval while additional data are being collected, or “only in research” (OIR), which means a decision to approve or reject is withheld until additional data have been collected. 6 An adoption decision may also be reversible with a cost, in which case the EVSI for AWR will be lower than for OIR. 7 For example, some irrecoverable costs, such as high initial treatment costs that are offset only by later health benefits, may be avoided if treatment initiation could be delayed until additional data have been collected. 33 If these avoidable costs are large, OIR may potentially be more appropriate than AWR, even if the decision is reversible. OIR may also be recommended if the new technology is not expected to improve net health benefits, but there is value in collecting additional data. If the adoption decision is irreversible, or approval would mean that further research could not be conducted, then AWR is not available and OIR may be the only option. In these circumstances, opportunity costs, in terms of potential net health benefits foregone, will be incurred while the research is being conducted if the new technology is expected to improve net health benefits.
Establishing population ENBS requires an assessment of the number of current and future patients who may benefit from additional data collection over the decision relevance time horizon. 34 The cost of continuing an ongoing study will primarily consist of variable (per patient) costs, including marginal incremental treatment costs and marginal reporting costs. Fixed study costs that have already been incurred will not affect the decision to continue the ongoing study or not.
Figure 2 illustrates that if AWR is recommended, the marginal benefit in terms of population model-averaged EVSI equals the marginal cost of continuing the trial at 22 and 23 mo of additional follow-up for the increasing and decreasing hazard data sets, respectively. These are the time points at which the ENBS is at a maximum. If OIR is recommended, the ENBS is at a maximum when the marginal benefit of delaying the decision until more data have been collected equals the marginal cost of continuing the trial and withholding approval, which is at 14 and 17 mo of additional follow-up for the increasing and decreasing hazard data sets, respectively.
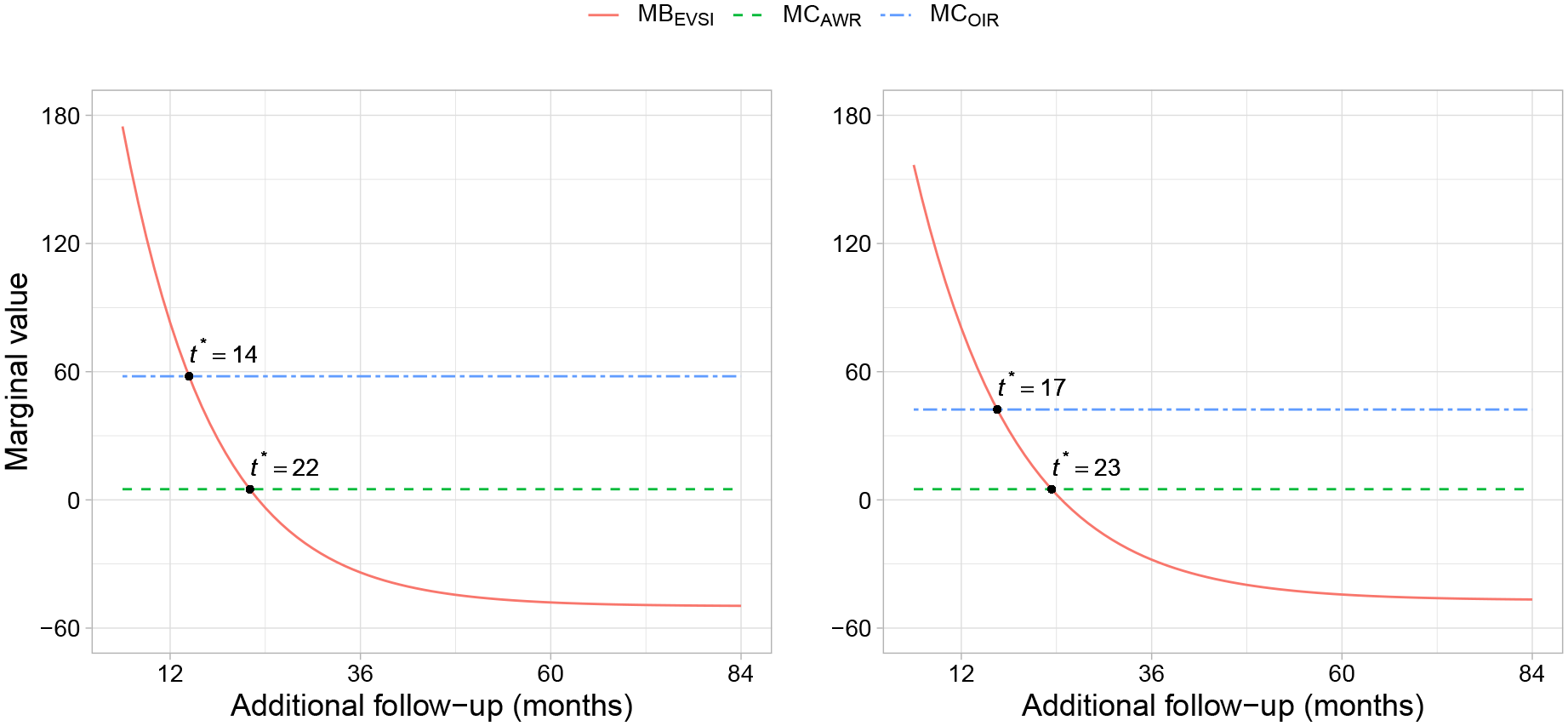
Marginal benefit (
Discussion
EVSI is useful not only for informing the design of a future trial but also for deciding whether an ongoing study should continue in order to collect additional data before making an adoption decision. This article is the first to set out generic EVSI algorithms for survival data from an ongoing trial with or without accounting for survival model uncertainty. The EVSI algorithms generalize to any decision context in which structural uncertainty is present, provided that the analyst is able to derive probability weights for the competing scenarios.
Strengths and Limitations
The nonparametric regression-based method is fast and straightforward to implement, even when we include consideration of model uncertainty. In fact, extending the method to include model uncertainty does not increase the complexity or computation time. The nested Monte Carlo procedure, on the other hand, is extremely computationally demanding when we include model uncertainty.
Although we considered only 2 treatment options in the synthetic case study, the EVSI methods described in this article extend to any number of treatment options that are being compared. This requires the generation of data for each treatment arm for which additional data will be collected conditional on samples from the distribution of the model parameters, which could be drawn from independently fitted survival models or from a joint model based on proportional hazards or an accelerated failure time assumption. The net benefit for each treatment arm can then be regressed on the treatment arm–specific summary statistics of the generated data, and EVSI can be computed the usual way following the algorithms in this article.
When a large part of the relevant time horizon is unobserved, the clinical plausibility of the survival extrapolations is often of greater importance than the mathematical fit to the observed data. 14 Deriving prior model probabilities from purely statistical measures such as AIC may therefore not always be appropriate when data are immature, since these measures do not reflect the plausibility of the extrapolations. 8 This became evident in the synthetic case studies, as the AIC-based prior model probabilities of the log-normal and log-logistic models were similar to those of the Weibull and Gamma models for the increasing hazard data set, despite the fact that the former 2 models do not allow for monotonically increasing hazards and therefore cannot capture the true underlying hazard pattern.
Similar to previous work,9,35 we have viewed model uncertainty in terms of a discrete model space, which can be addressed by model averaging. An alternative view on model uncertainty could involve indexing candidate models within a continuous model space, using a single very flexible model that includes all the models the analyst believes plausible. For example, the generalized F distribution includes most commonly used parametric survival distributions as special cases. 36 In this case, the EVSI algorithms in this article would reduce to the single-model case. This approach, however, requires the specification of a prior that appropriately reflects uncertainty in choosing between alternative functional forms within the flexible model, which may be not be straightforward. Flexible models such as the generalized F distribution, Royston-Parmar spline models, or fractional polynomials are also prone to overfitting and may not always provide reliable predictions of mean survival, particularly when data are immature. 9
For the purposes of describing the new method, we assumed that the survival distribution in the future unobserved time period is the same as in the observed period. This is a simplifying assumption that may not hold in real-life settings. Most importantly, we may have additional uncertainty about the postobservation period that is not captured by the uncertainty encoded in the survival model probability distribution. For example, the duration of the treatment effect is conditional on multiple factors such as the biological effect mechanism, treatment-stopping rules, compliance, and side effects. 37 The extrapolation of trial data may therefore have to be supplemented with external evidence 38 and assumptions about disease progression and mechanisms of action of the treatments that reflects additional knowledge and uncertainty. This typically involves eliciting expert opinion. 39 We also did not consider flexible parametric models such as Royston-Parmar spline-based models 40 or mixture cure models 41 in the synthetic case studies. Although the EVSI methods described in this article apply equally to any survival distribution and underlying assumptions (including those regarding the duration of the treatment effect), they require the generation of plausible data sets that obey all the model rules, which may not be straightforward for complex study designs. This is a common limitation of existing EVSI methods, and more research in this area may be needed.
In the synthetic case studies, we assumed all patients had the same follow-up at
We did not consider sequential trial designs, 42 which require EVSI to be recalculated after each observation and to account for all the possible ways in which future patients may be allocated to the trial arms or when to stop the trial. 34 This can give rise to a large number of subproblems that may have to be solved using dynamic programming methods, which can be computationally very demanding.
Policy Implications
Immature evidence leads to a high level of decision uncertainty, which may result in the uptake of technologies that reduce net health benefit. The decision-making context in which trials are ongoing and evidence is immature is particularly pronounced for new oncology drugs. The purpose of the Cancer Drug Fund (CDF) in the United Kingdom, for example, is to enable early patient access to promising new cancer drugs while allowing evidential uncertainty to be reduced through ongoing data collection. In the period between 2017 and July 2018, the National Institute for Health and Care Excellence (NICE) recommended more than half of the appraised cancer drugs through the CDF, typically because of concerns about immature survival data. 43
EVSI will depend on both the study design and the decision context44,45 but also on whether the trial results generalize to multiple jurisdictions46,47 and whether the adoption decision can be fully implemented.48,49 The benefit of additional data collection can be realized only when trial results are reported. 50 An assessment is therefore required of when the ongoing trial might report and at which point the adoption decision can be revisited. 51 Risk-sharing agreements between a manufacturer and payer may potentially modify the value of collecting additional data as well as the expected net benefit of access to a new technology.6,47,52 The option to enroll more patients into an ongoing trial should also be considered if it has a positive net value.
The EVSI algorithms in this article can help decision makers determine whether early patient access to a new technology can be justified on the basis of the current evidence or whether more mature evidence is needed. Unlike most of the existing work on EVSI that primarily targets commissioners and funders of research, EVSI for ongoing trials also addresses the policy context of decision makers who do not have the remit to commission additional research.
Supplemental Material
sj-pdf-1-mdm-10.1177_0272989X211068019 – Supplemental material for An Efficient Method for Computing Expected Value of Sample Information for Survival Data from an Ongoing Trial
Supplemental material, sj-pdf-1-mdm-10.1177_0272989X211068019 for An Efficient Method for Computing Expected Value of Sample Information for Survival Data from an Ongoing Trial by Mathyn Vervaart, Mark Strong, Karl P. Claxton, Nicky J. Welton, Torbjørn Wisløff and Eline Aas in Medical Decision Making
Footnotes
Acknowledgements
We thank researchers at the Centre for Health Economics in York for their comments on this work during a seminar in April 2020. We also thank the editor and 3 anonymous reviewers for their comments.
Correction (May 2023):
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article. The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided entirely by a grant from the Norwegian Research Council through NordForsk (298854). The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.