
Abstract
Background
Expected value of sample information (EVSI) quantifies the expected value to a decision maker of reducing uncertainty by collecting additional data. EVSI calculations require simulating plausible data sets, typically achieved by evaluating quantile functions at random uniform numbers using standard inverse transform sampling (ITS). This is straightforward when closed-form expressions for the quantile function are available, such as for standard parametric survival models, but these are often unavailable when assuming treatment effect waning and for flexible survival models. In these circumstances, the standard ITS method could be implemented by numerically evaluating the quantile functions at each iteration in a probabilistic analysis, but this greatly increases the computational burden. Thus, our study aims to develop general-purpose methods that standardize and reduce the computational burden of the EVSI data-simulation step for survival data.
Methods
We developed a discrete sampling method and an interpolated ITS method for simulating survival data from a probabilistic sample of survival probabilities over discrete time units. We compared the general-purpose and standard ITS methods using an illustrative partitioned survival model with and without adjustment for treatment effect waning.
Results
The discrete sampling and interpolated ITS methods agree closely with the standard ITS method, with the added benefit of a greatly reduced computational cost in the scenario with adjustment for treatment effect waning.
Conclusions
We present general-purpose methods for simulating survival data from a probabilistic sample of survival probabilities that greatly reduce the computational burden of the EVSI data-simulation step when we assume treatment effect waning or use flexible survival models. The implementation of our data-simulation methods is identical across all possible survival models and can easily be automated from standard probabilistic decision analyses.
Highlights
Expected value of sample information (EVSI) quantifies the expected value to a decision maker of reducing uncertainty through a given data collection exercise, such as a randomized clinical trial. In this article, we address the problem of computing EVSI when we assume treatment effect waning or use flexible survival models, by developing general-purpose methods that standardize and reduce the computational burden of the EVSI data-generation step for survival data.
We developed 2 methods for simulating survival data from a probabilistic sample of survival probabilities over discrete time units, a discrete sampling method and an interpolated inverse transform sampling method, which can be combined with a recently proposed nonparametric EVSI method to accurately estimate EVSI for collecting survival data.
Our general-purpose data-simulation methods greatly reduce the computational burden of the EVSI data-simulation step when we assume treatment effect waning or use flexible survival models. The implementation of our data-simulation methods is identical across all possible survival models and can therefore easily be automated from standard probabilistic decision analyses.
Keywords
Expected value of sample information (EVSI) quantifies the expected value to a decision maker of reducing uncertainty through a given data collection exercise, such as a randomized clinical trial. 1 Methods for computing the EVSI for collecting survival data (i.e., time-to-event data) when there is uncertainty about the choice of survival model have recently been developed by Vervaart et al. 2 These methods require, in common with other EVSI methods, the simulation of plausible study data sets that reflect the study design proposed for collecting future data and the time-to-event distribution of individuals included in such a study. 3 This is typically achieved by evaluating quantile functions at random uniform numbers using standard inverse transform sampling (ITS). The standard ITS method is straightforward to implement when closed-form expressions for the quantile function are available, such as for standard parametric survival models, but these are often not available when assuming treatment effect waning and for flexible survival models.
Sufficient evidence on time-to-event outcomes, such as overall survival (OS) and time to progression, is crucial for accurately determining the long-term effects of new treatments. 4 Yet, health technology assessments often have to rely on immature survival data obtained from trials at an early stage, especially for new cancer treatments. 5 This can partly be explained by the introduction of accelerated licensing schemes for new pharmaceuticals by regulatory bodies such as the European Medicines Agency6,7 and the US Food and Drug Administration. 8 Immature survival data require a high degree of extrapolation, which led to the introduction of flexible survival models such as response-based landmark models, mixture cure models, relative survival models, and model-averaging approaches.9,10 Nevertheless, more complex models do not necessarily result in plausible extrapolations, and therefore, extrapolations are often supplemented with assumptions about disease progression and treatment mechanisms. For example, the National Institute for Health and Care Excellence recommends that waning of treatment effects is considered in technology appraisals, 11 for instance, by assuming no more treatment benefit beyond a chosen time point 12 or by assuming that the treatment effect diminishes over the long term. 13 This is typically implemented in cost-effectiveness models by adjusting the predicted hazards, thereby altering the survival probabilities generated by parametric survival models. This poses a challenge for the EVSI data-simulation step for survival data, as closed-form expressions for the quantile function are often unavailable for custom distributions that incorporate assumptions about treatment effect waning and for flexible survival models. In these circumstances, the standard ITS method for simulating survival data could be implemented by numerically evaluating the quantile distributions at each iteration in a probabilistic analysis, but this can greatly increase the computational burden.
In this article, we address the problem of computing EVSI when we assume treatment effect waning or use flexible survival models, by developing general-purpose methods that standardize and reduce the computational burden of the EVSI data-generation step for survival data. We develop a discrete sampling method and an interpolated ITS method for simulating survival data from a probabilistic sample of survival probabilities over discrete time units. The discrete sampling method samples time cycles using the survival probabilities and sets the event times to the half-cycle times. The interpolated ITS method extends this to continuous time by initially sampling random uniform numbers between 0 and 1 and then interpolating the survival probabilities using cubic splines at the sampled numbers and recording the interpolated cycle times. We demonstrate in an illustrative case study that, when the general-purpose data-simulation methods are combined with a recently proposed nonparametric EVSI method,2,14 EVSI computations for survival data can be automated from standard probabilistic decision analyses, irrespective of the assumed data-generating process.
The article is structured as follows. In the second section, we first describe the standard ITS method and then introduce the general-purpose methods for simulating survival data. In the third section, we compare the standard ITS method and the general-purpose data-simulation methods based on an illustrative partitioned survival model for scenarios with and without adjustment for treatment effect waning. In the final section, we conclude with a short discussion.
Method
Decision Problem
In health technology assessment, cost-effectiveness models are widely used to compare alternative health technologies in terms of expected costs
EVSI for a New Study
The expected value of the optimal decision given current information is the value of the decision option that maximizes expected net benefit and can therefore be considered cost-effective,
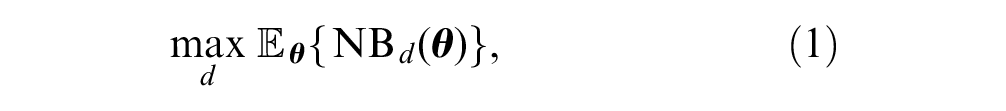
A new study would provide data
The expected value of the optimal decision made after collecting
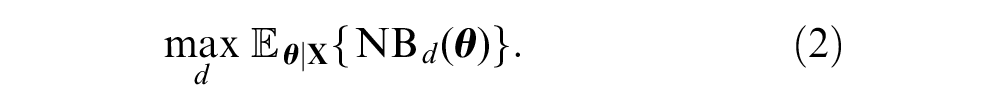
The value of collecting
The expected value of the decision made with additional sample information is given by
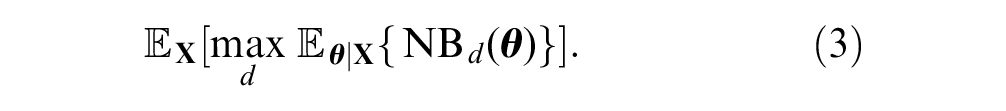
The EVSI
16
measures the expected value of reducing uncertainty about the optimal decision by collecting
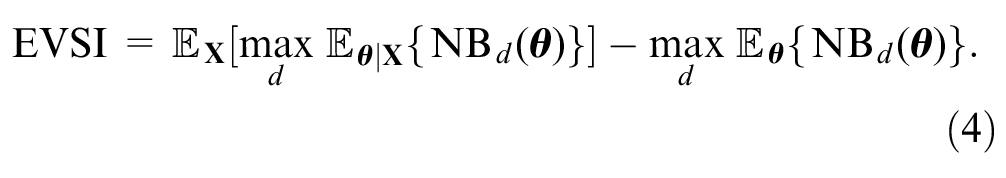
In the next section, we describe the EVSI estimation procedure for collecting time-to-event data.
Computing EVSI for Time-to-Event Data
Time-to-Event Data
Time-to-event data, such as time to disease progression and time to death, are frequently collected in the context of clinical trials. A special feature of time-to-event data is censoring, which occurs when the follow-up time is not long enough to observe the event of interest for all individuals or when individuals are lost to follow-up.
17
A single time-to-event data set
To predict outcomes over the long term, censored time-to-event data usually need to be extrapolated beyond the observed follow-up period using a parametric survival model.
4
Parametric models are commonly specified using either the survivor function,
The survivor function
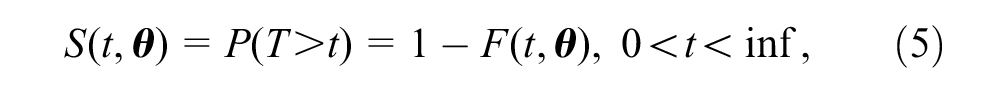
where
The hazard function
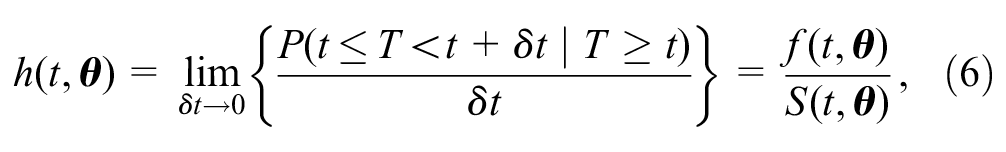
where
Most cost-effectiveness models are in discrete time and therefore evaluate
Computing the Expected Net Benefits Given Current Information
We can compute the expected net benefits given current information in a probabilistic analysis (PA) using Monte Carlo simulation. This involves sampling
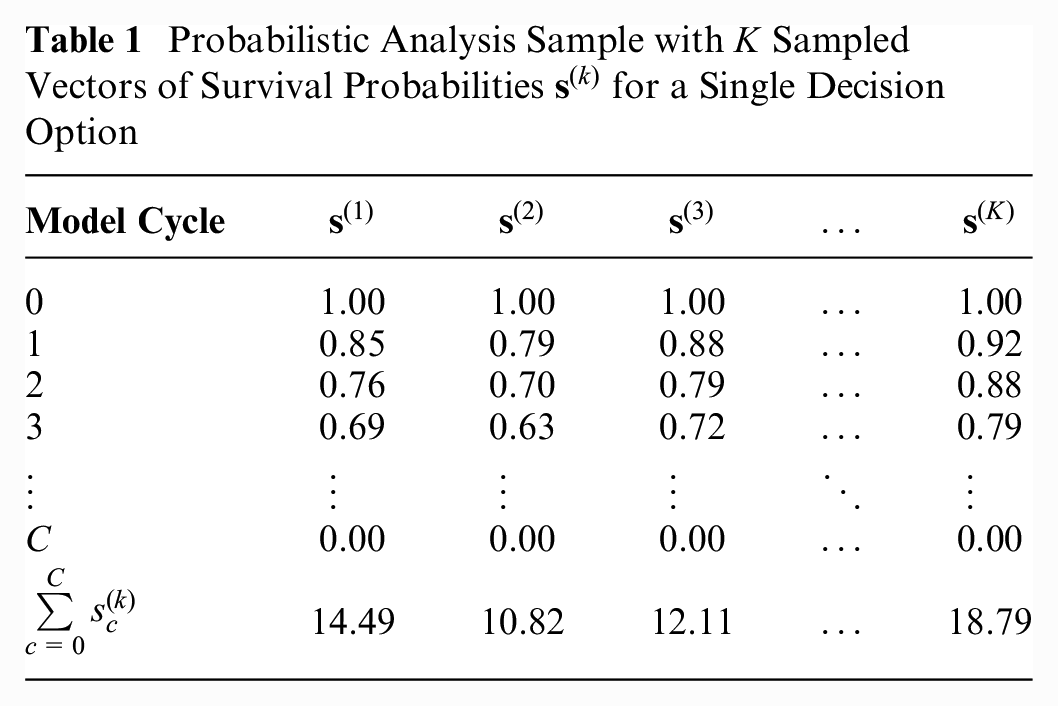
Table 1 illustrates a PA sample in which
Probabilistic Analysis Sample with
Simulating Time-to-Event Data
Standard ITS Method
To compute the expected net benefits given new time-to-event data
The standard ITS scheme for simulating time-to-event data is given in Box 1.
Standard Inverse Transform Sampling Scheme for Simulating Time-to-Event Data

Sampling from a Weibull distribution, such as by using the rweibull function in R, can result in any value between 0 and infinity. If we want to ensure that the sampled survival times do not exceed a biologically plausible time horizon
The algorithm in Box 1 could, in theory, be used for any survival model for which we can define a hazard function,
Analytic solutions to the integrals and function inverses, such as implemented in the
In the next section, we will introduce general-purpose methods for simulating survival data that can be standardized from standard probabilistic decision analyses and greatly reduce the computational burden of the standard ITS method when closed-form expressions for the quantile function are unavailable.
Simulating Time-to-Event Data from a Vector of Survival Probabilities over Discrete Time Units
Interpolated ITS method
We can also use the ITS method to generate
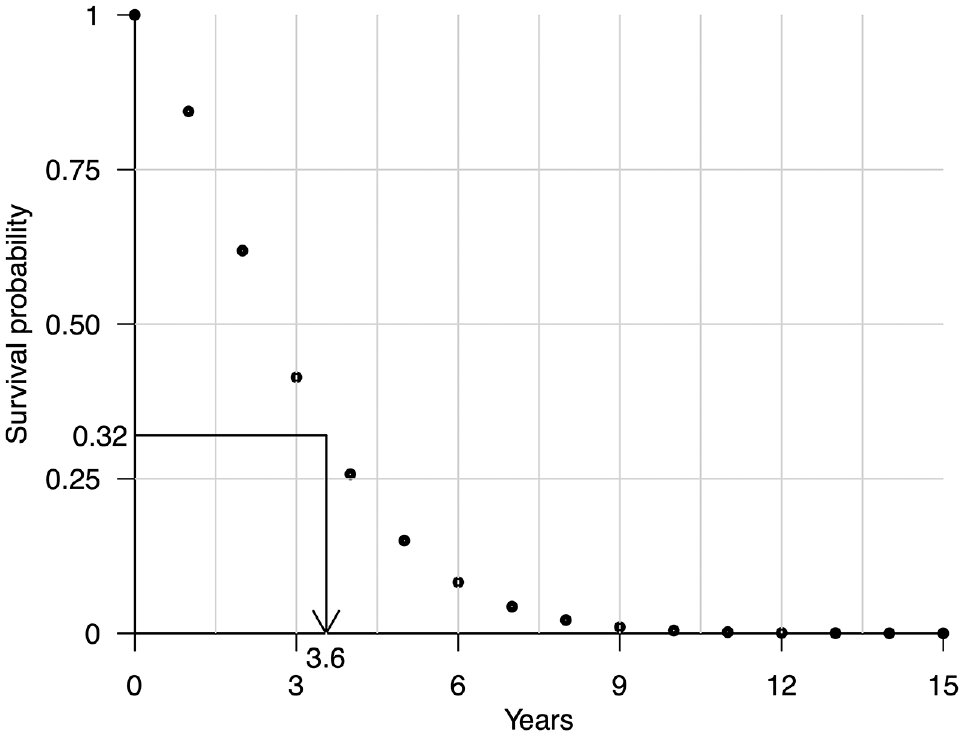
Illustration of the interpolated inverse transform sampling method for simulating time-to-event data. A survival time of 3.6 y has been simulated by first sampling a value of 0.32 from a uniform distribution between 0 and 1 and then interpolating the survival probabilities over discrete time units using monotone cubic splines at 0.32 and recording the interpolated cycle time of 3.6 y.
The interpolated ITS sampling scheme for simulating time-to-event data from a vector of survival probabilities over discrete time units is given in Box 2.
Interpolated Inverse Transform Sampling Scheme for Simulating Time-to-Event Data from a Vector of Survival Probabilities over Discrete Time Units

Discrete sampling method
An alternative approach for simulating
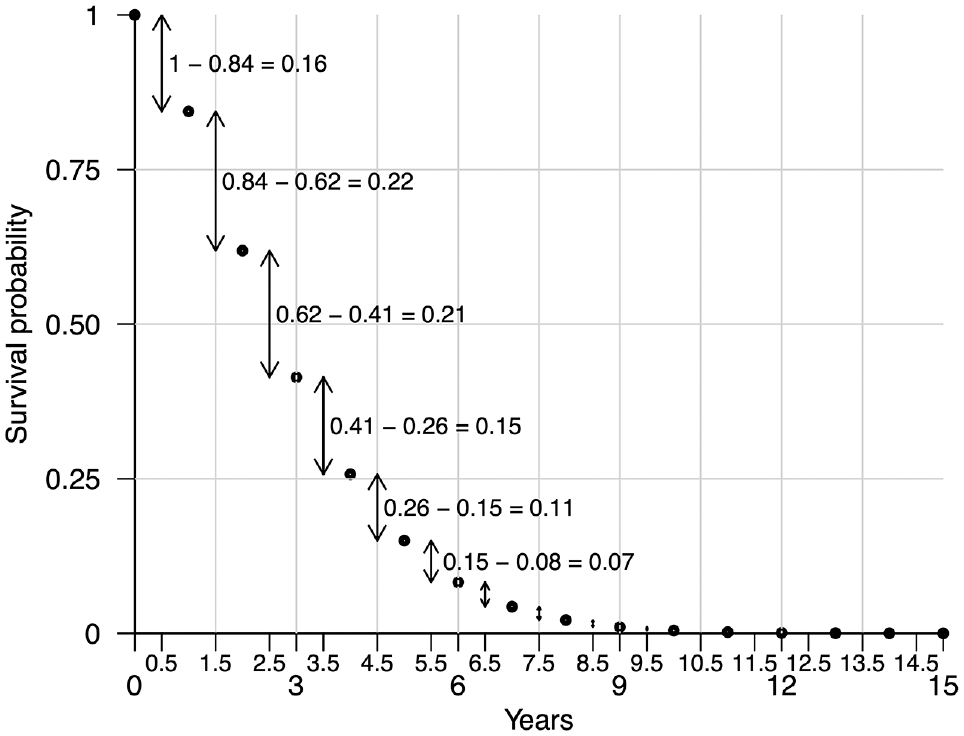
Illustration of the discrete sampling method for simulating time-to-event data. Survival times can be simulated by sampling from the half-cycle times on the x-axis with probability derived from the survival probabilities over discrete time units, as indicated by the arrows.
The discrete sampling scheme for simulating time-to-event data from a vector of survival probabilities over discrete time units is given in Box 3.
Discrete sampling scheme for simulating time-to-event data from a vector of survival probabilities over discrete time units.

Appendix A describes a step-by-step implementation in R of the interpolated ITS and discrete sampling methods, and a comparison of their computational efficiency with the standard ITS method based on analytic and numerical solutions.
Computing the expected net benefits given new data
We could compute the expected net benefits given the
In the regression-based approach, we require only the vectors of
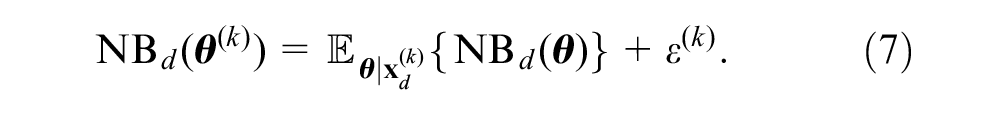
Strong et al.
14
explain that the conditional expectation
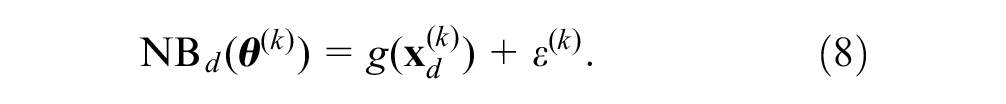
We then summarize
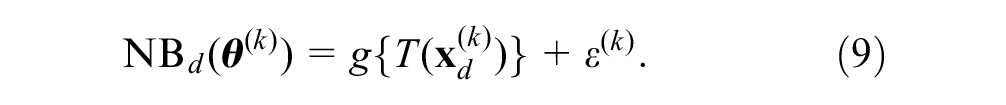
A convenient choice for
We can estimate the posterior net benefits by regressing the prior net benefits,
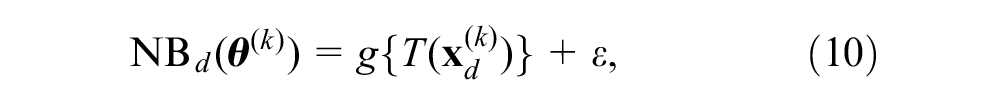
where
The GAM-based EVSI estimate is given by
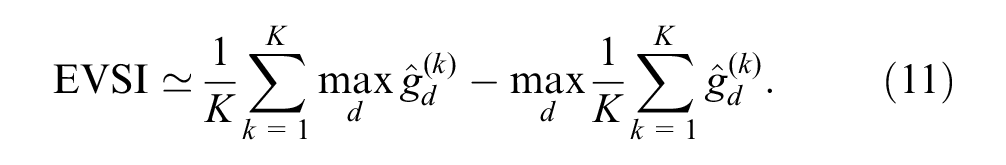
EVSI for an ongoing study
When a trial is ongoing at the point of decision making, there could be value in reducing uncertainty by collecting additional data from the ongoing trial before making an adoption decision. This is especially common for cost-effectiveness analyses of new cancer drugs, which increasingly rely on immature data obtained from trials in an early stage. 5
We denote the new data collected between the observed follow-up time
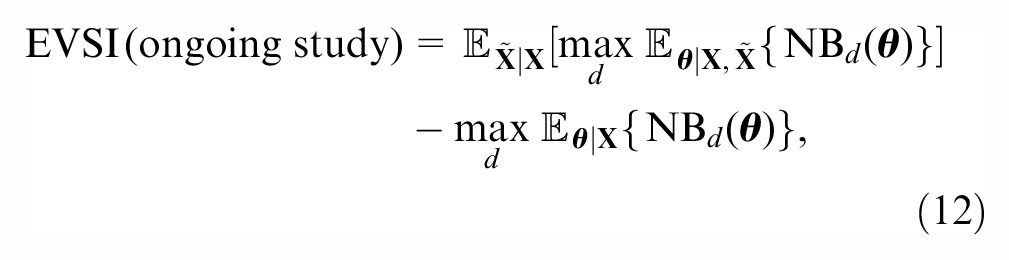
where the first term is the expected value of a decision based on the joint posterior distribution of
Events beyond
Model-averaged EVSI
Uncertainty about the choice of survival model is often a key driver of decision uncertainty, particularly when data are immature.
21
If we are uncertain about choosing from a set of competing survival models for extrapolating study data over the long term,
Synthetic Case Study
Decision Problem and Model Definition
To demonstrate the application of our methods, we developed a simple yet realistic synthetic case study based on a partitioned survival model (PSM)
26
comparing a new treatment (d = 1) with standard care (d = 2). The PSM uses OS and progression-free survival (PFS) curves to estimate the proportion of patients in 3 health states: PFS, postprogression survival (PPS), and death, given
Prior Parameter Distributions for the Partitioned Survival Model Parameters
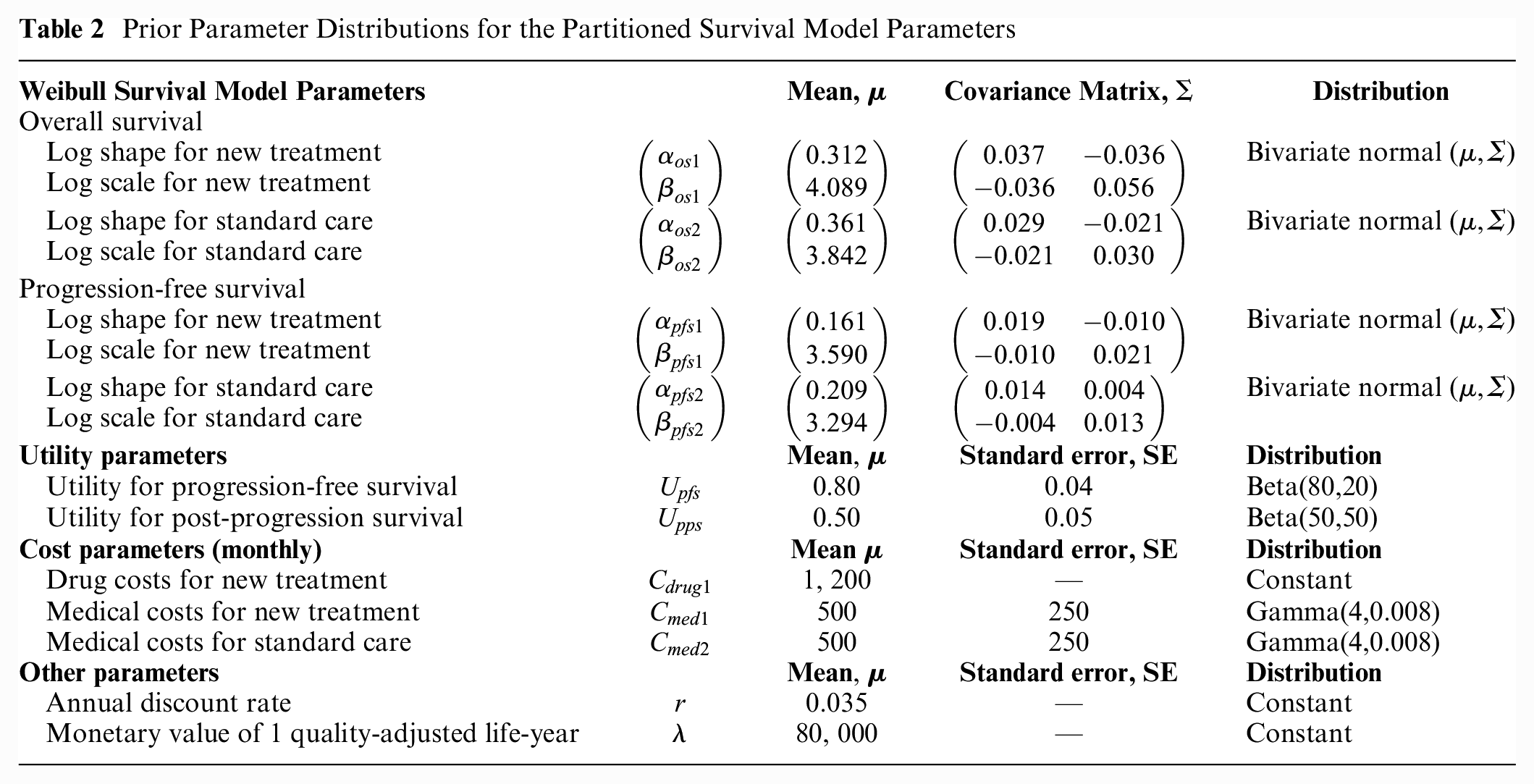
Treatment-stopping rule and treatment effect waning
We also considered a scenario with a 2-y treatment-stopping rule, after which the drug costs for the new treatment
To avoid these limitations, we used an alternative approach to implement treatment effect waning. For
The waning-adjusted hazard function for OS and PFS for the new treatment is given by
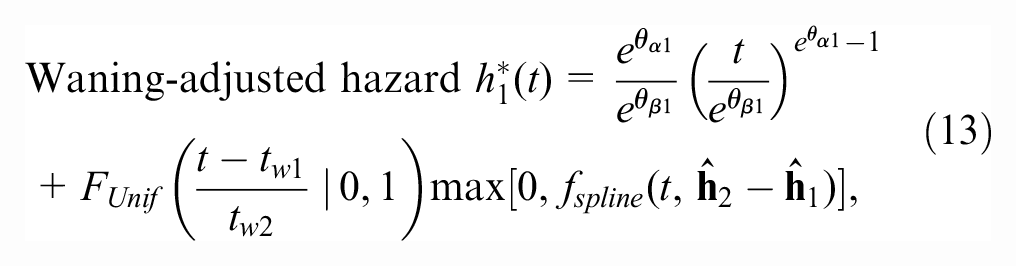
where the first term is the Weibull hazard function,
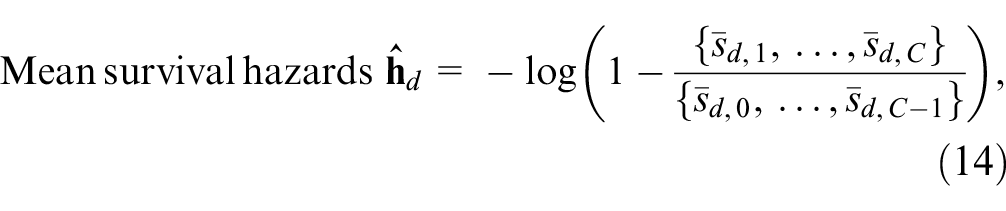
where
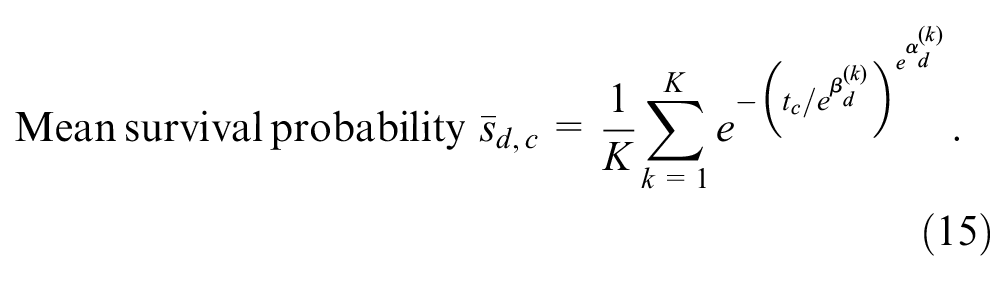
All other model assumptions and net benefit functions are as above.
The expected Weibull survival curves for the scenarios with and without adjustment for treatment effect waning are given in Figure 3.
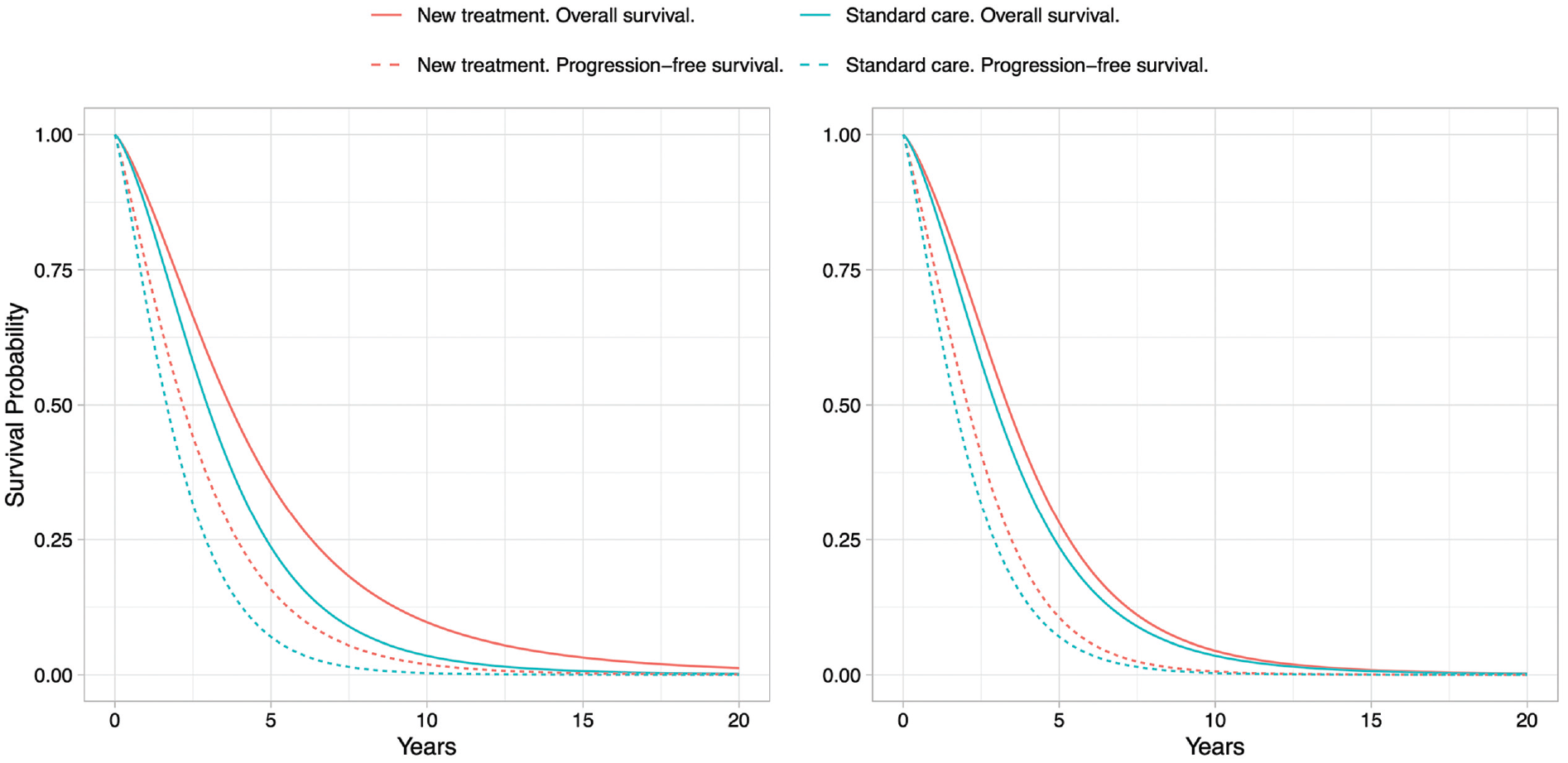
Expected Weibull survival curves for overall survival and progression-free survival for the new treatment and for standard care without adjustment (left) and with adjustment for treatment effect waning (right).
Computations
We assume we want to compute the EVSI for a new study that will collect OS and PFS data for the new treatment and for standard care. We considered a sample size of
Simulating OS and PFS data
In the scenario without adjustment for treatment effect waning, we simulated OS data sets,
We simulated PFS data sets for the new treatment and standard care (
Computing EVSI via GAM regression
To reduce the number of regression equations
14
and improve the stability of the EVSI computations,
28
we used the incremental net benefit (INB), defined as
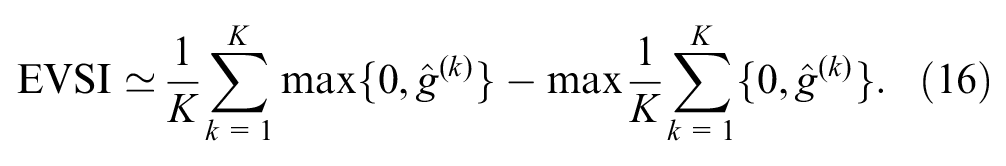
We computed 95% intervals for the GAM estimator by sampling 2,000 values from a multivariate normal distribution of the GAM coefficients, as described in an appendix of the article by Strong et al. 30
Results
Figure 4 shows the EVSI values and 95% intervals without adjustment for treatment effect waning for follow-up times of 1, 2, 3, 4, 5, and 10 y. There is excellent agreement between the standard ITS method, interpolated ITS method, and discrete sampling method both for OS only and OS and PFS. The EVSI reflects diminishing marginal returns for increasing follow-up durations, ranging from 2,711 to 11,311 for OS only and from 3,387 to 11,547 for OS and PFS, and converges toward the partial EVPI for the respective sets of model parameters. This indicates that the value of reducing uncertainty about PFS in addition to OS is relatively small. We did not compute the EVSI for PFS only, since PFS is a composite endpoint that is defined as time to progression or time to death, whichever is soonest, and therefore also requires the collection of OS data. The total computation times for the data-simulation procedures in the scenario without adjustment for treatment effect waning are 12 s, 32 s, and 12 s for the standard ITS method, interpolated ITS method, and discrete sampling method, respectively.
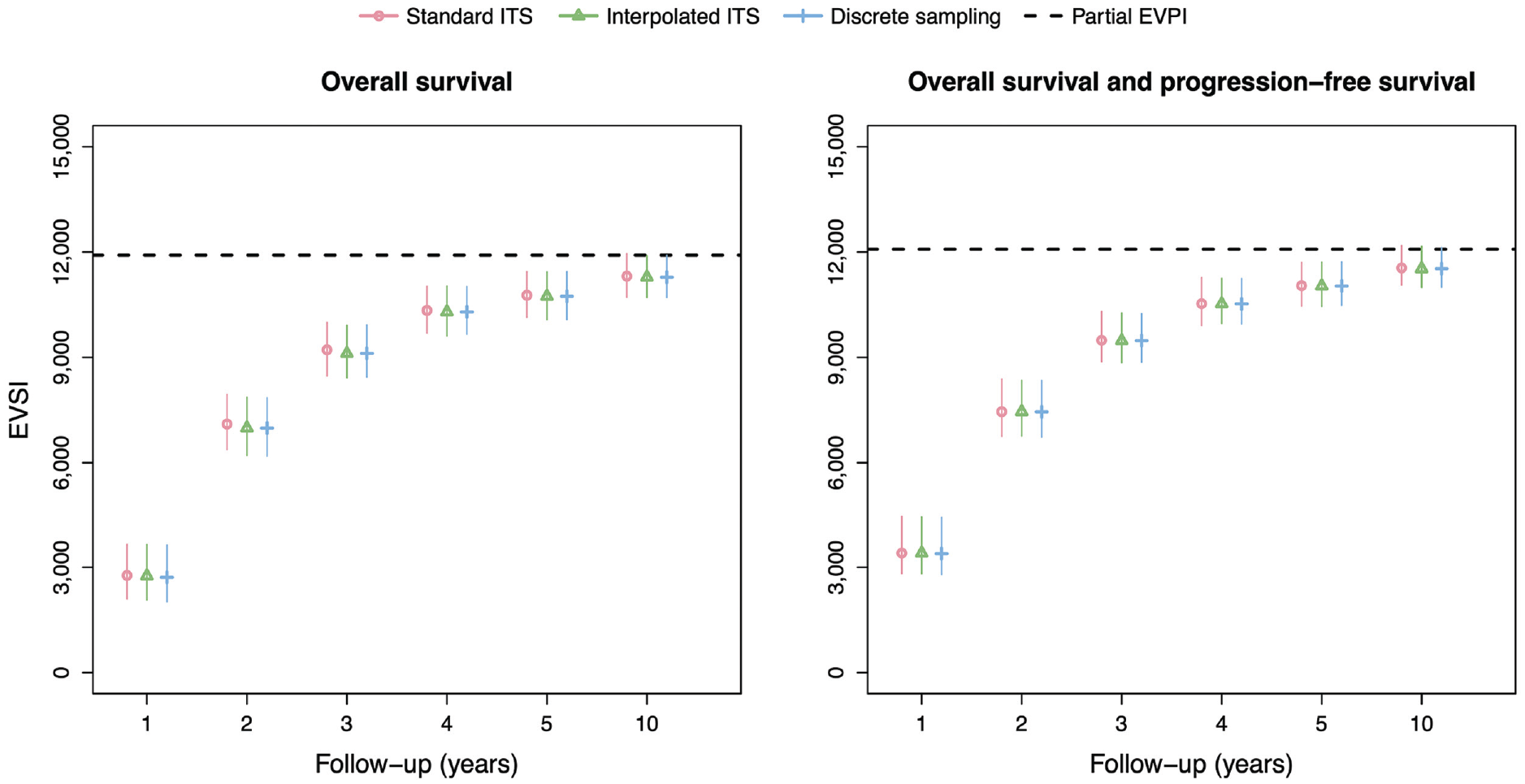
EVSI values for the synthetic case study without adjustment for treatment effect waning. Total computation times for the data-simulation procedures are 12 s (standard ITS), 32 s (interpolated ITS) and 12 s (discrete sampling). EVSI, expected value of sample information; ITS, inverse transform sampling.
The EVSI estimates in the scenario with adjustment for treatment effect waning (Figure 5) are greater than in the scenario without adjustment for treatment effect waning, reflecting the added value of learning about treatment effect waning. The EVSI estimates range from 5,433 to 11,961 for OS only and from 6,064 to 12,384 for OS and PFS, almost twice as high for the 1-y follow-up period compared with the scenario without adjustment for treatment effect waning. The interpolated ITS method and discrete sampling method again agree closely with the standard ITS method but at a greatly reduce computational cost. The computation times for the interpolated ITS and discrete sampling methods are, in fact, the same as in the scenario without adjustment for treatment effect waning, and approximately 3,600 and 10,000 times faster, respectively, than the standard ITS scheme that used numerical solutions for the integrals and function inverses.
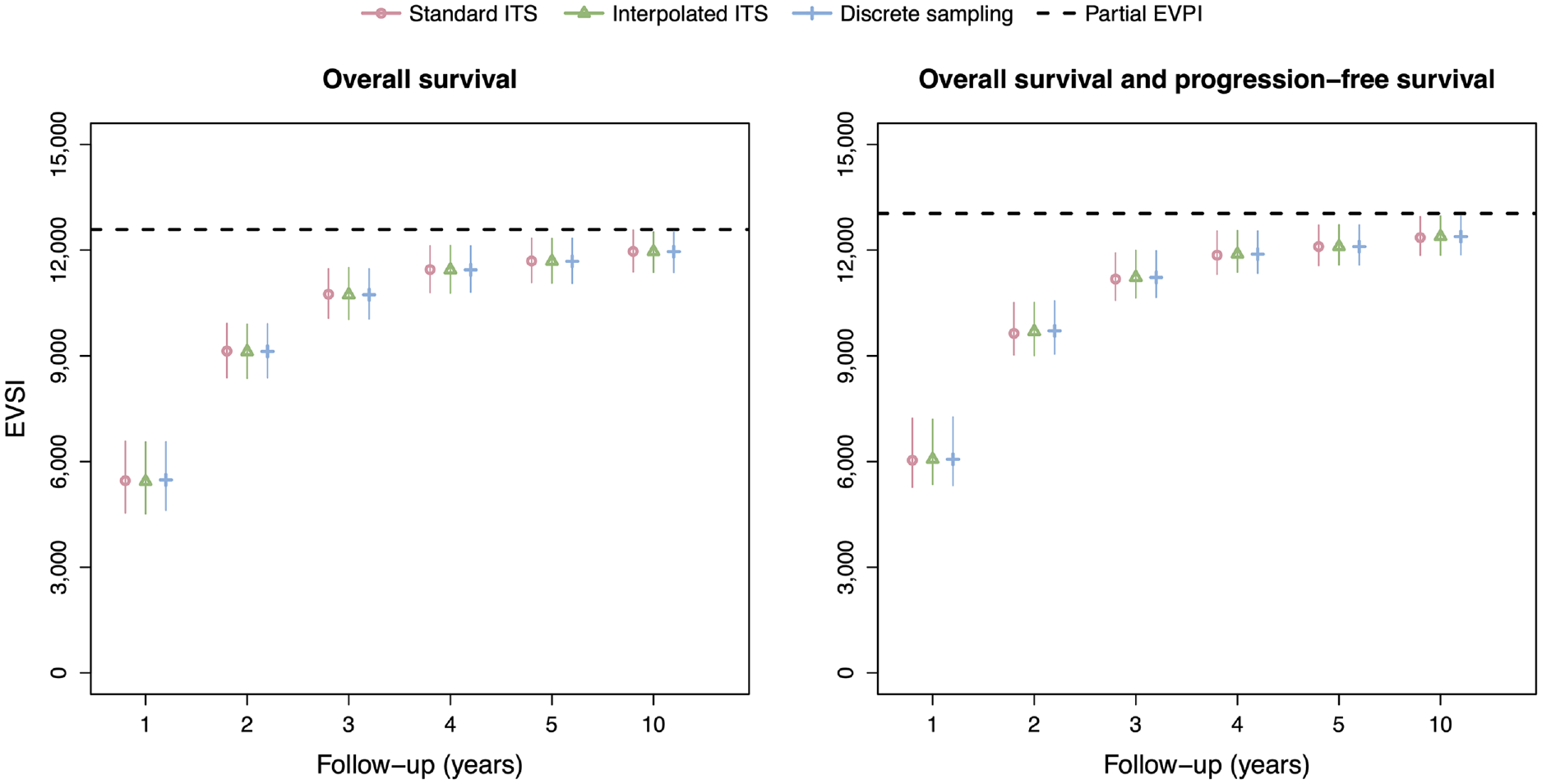
EVSI values for the synthetic case study with adjustment for treatment effect waning. Total computation times for the data-simulation procedures are 120,180 s (standard ITS), 33 s (interpolated ITS), and 12 s (discrete sampling). EVSI, expected value of sample information; ITS, inverse transform sampling.
Discussion
Strengths and Limitations
We developed an interpolated ITS method and a discrete sampling method for simulating survival data from a probabilistic sample of survival probabilities over discrete time units. Our general-purpose methods greatly reduce the computational burden of the standard ITS method when closed-form expressions for the quantile function are unavailable, such as for custom distributions that incorporate assumptions about treatment effect waning as commonly encountered in practice, 11 and for flexible survival models, including relative survival models, spline models, mixture cure models, and response-based landmark models.9,10 The implementation of our methods is identical across all possible survival models and can therefore be easily standardized from standard probabilistic decision analyses.
Generally, the precision of the EVSI estimator is influenced by the number of simulated data sets and the effective sample size of the simulated data. The discrete sampling method and, to a lesser degree, the interpolated ITS method, additionally introduce an approximation error that depends on the cycle length. It is generally recommended that discrete-time health economic models use a short cycle length to reduce the discrete-time approximation error, which could be as short as 1 week for slowly progressing chronic diseases. 31 Our synthetic case study suggests that the approximation error introduced by our general-purpose methods is very small even when using a longer cycle length of 1 mo in combination with short follow-up times and a low effective sample size of the simulated data given a rapidly progressing disease.
We structured the synthetic case study around a PSM, a type of model that is frequently used to inform reimbursement decisions for new oncology drugs. 27 The key assumption behind a PSM is that survival endpoints, such as OS and PFS, are independent. This also implies that dependency between OS and PFS is not reflected in the EVSI data-simulation procedure when using a PSM. Joint modeling of OS and PFS could be implemented in a state transition model (STM), which uses transition probabilities to describe movements between health states over time. STMs require individual patient data to estimate all relevant transition probabilities, unlike PSMs, which can use digitized Kaplan–Meier data from published trials. OS and PFS data can be simulated jointly from a STM by first sampling a PFS time and then deciding whether the sampled PFS time is a progression or death event using a binomial experiment with probability derived from the hazards of transitioning from PFS to PPS and OS. 32 If the sampled PFS time is a progression event, residual time until death can be simulated using the survival distribution for PPS to OS. Since transition probabilities are typically derived from survival curves fitted to time-to-event data, our data-simulation methods could also be useful in a STM framework.
If individual patient data are available with a similar study design and at least the same length of follow-up as the proposed study, study data sets could alternatively be simulated using a 2-level resampling method based on bootstrapping.
33
In this approach, the observed data set is first resampled
The key notion behind EVSI is that the prior distribution of the model parameters is updated with simulated study data to estimate the joint posterior distribution given both prior information and the simulated study data. In EVSI analyses, the prior distribution is often informed by external evidence, such as digitized Kaplan–Meier data. This may, however, not match the way in which real-world analyses of study data are conducted, since these may not synthesize the collected study data and the external evidence. Analysts should therefore ensure that the way in which the study data is analyzed once it has been collected is aligned with the assumptions underpinning the EVSI analysis.
Despite its routine application in cost-effectiveness analyses, there is currently a lack of guidance on how to model treatment effect waning. 12 In the synthetic case study, we modeled treatment effect waning by specifying probability distributions for the start and duration of the waning period, while preserving uncertainty about independent survival endpoints using a novel additive hazard approach. This had a large impact on the EVSI estimates, which highlights the importance of appropriately incorporating uncertainty about treatment effect waning in the EVSI calculations. There may be other possible approaches to model treatment effect waning, and these can easily be captured by our data-simulation methods as well.
Conclusion
The increasing prevalence of immature survival data in decision making, particularly for new cancer treatments, 5 has been accompanied by the introduction of increasingly complex approaches for extrapolation,9,10 which complicates the EVSI data-simulation step. Our general-purpose data-simulation methods greatly reduce the computational burden of the EVSI data-simulation step when custom distributions that incorporate treatment effect waning or flexible survival models are used for which closed-form expressions for the quantile function are unavailable. Our methods are straightforward to implement and can easily be automated from standard probabilistic decision analyses, such as those used in technology assessments of new pharmaceuticals.11,34–36 This means that our general-purpose methods can be used to simulate survival data—with a similar accuracy and computational cost—as using the correct closed-form quantile function for any survival model. Efficient EVSI calculations for survival data can help decision makers determine whether current evidence is sufficient or whether there is a need for collecting additional survival data before making an adoption decision.
Supplemental Material
sj-docx-1-mdm-10.1177_0272989X231162069 – Supplemental material for General-Purpose Methods for Simulating Survival Data for Expected Value of Sample Information Calculations
Supplemental material, sj-docx-1-mdm-10.1177_0272989X231162069 for General-Purpose Methods for Simulating Survival Data for Expected Value of Sample Information Calculations by Mathyn Vervaart, Eline Aas, Karl P. Claxton, Mark Strong, Nicky J. Welton, Torbjørn Wisløff and Anna Heath in Medical Decision Making
Footnotes
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article. The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MV, EA, KC, MS, NJW, and TW were funded by a grant from the Norwegian Research Council through NordForsk (grant 298854). AH was supported by a Canada Research Chair in Statistical Trial Design and the Natural Sciences and Engineering Research Council of Canada (grant RGPIN-2021-03366) The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.