
Abstract
The value of learning an uncertain input in a decision model can be quantified by its partial expected value of perfect information (EVPI). This is commonly estimated via a 2-level nested Monte Carlo procedure in which the parameter of interest is sampled in an outer loop, and then conditional on this sampled value, the remaining parameters are sampled in an inner loop. This 2-level method can be difficult to implement if the joint distribution of the inner-loop parameters conditional on the parameter of interest is not easy to sample from. We present a simple alternative 1-level method for calculating partial EVPI for a single parameter that avoids the need to sample directly from the potentially problematic conditional distributions. We derive the sampling distribution of our estimator and show in a case study that it is both statistically and computationally more efficient than the 2-level method.
Keywords
The value of learning an input to a decision-analytic model can be quantified by its partial expected value of perfect information (partial EVPI). 1 –4 The partial expected value of information for some model input, Xi , is the expected difference between the value of the optimal decision based on perfect information about Xi and the value of the decision made only with prior information. To express this formally, we first introduce some notation.
We assume that we are faced with D decision options, indexed d
= 1, . . ., D, and have built a model yd
=
f (d, x) that aims to predict the net benefit of
decision option d given a vector of input parameter values x. We
denote the true unknown values of the inputs
The expected value of our optimal decision, made only with current information, is
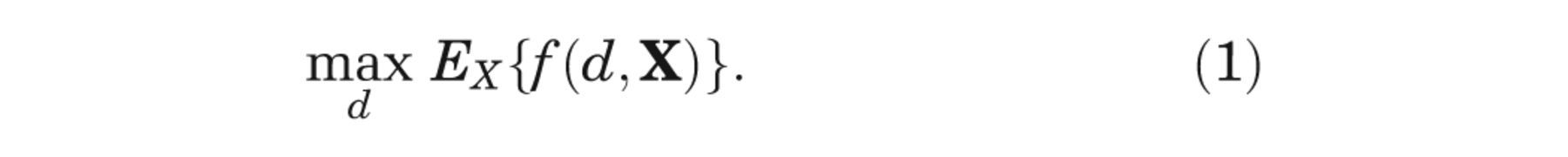
If we knew the value of some input of interest, Xi
, then the optimal
decision would be that with the greatest net benefit, after averaging over the conditional
distribution of the remaining unknown inputs,
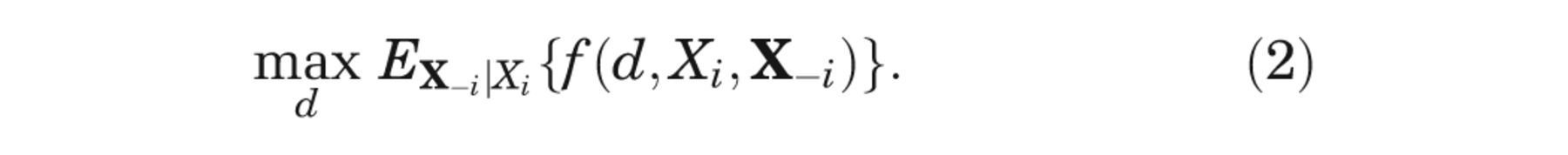
But, since Xi is unknown, we must average over our current information about Xi , giving
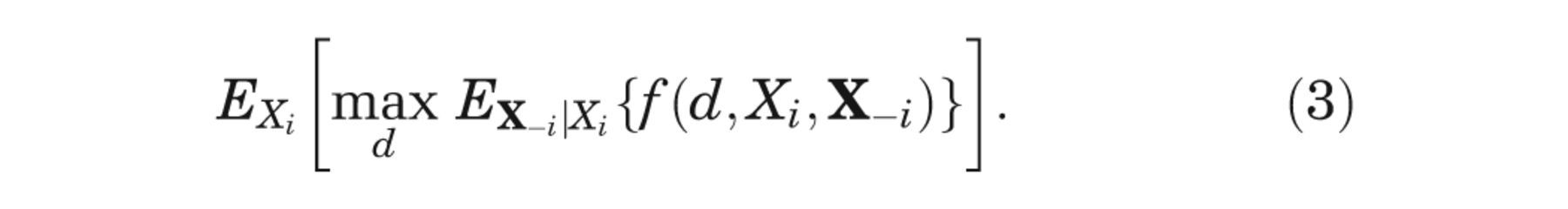
The partial EVPI for input Xi is the difference between equation (3), the expected value of the decision made with perfect information about Xi , and equation (1), the expected value of the current optimal decision option, 3,4
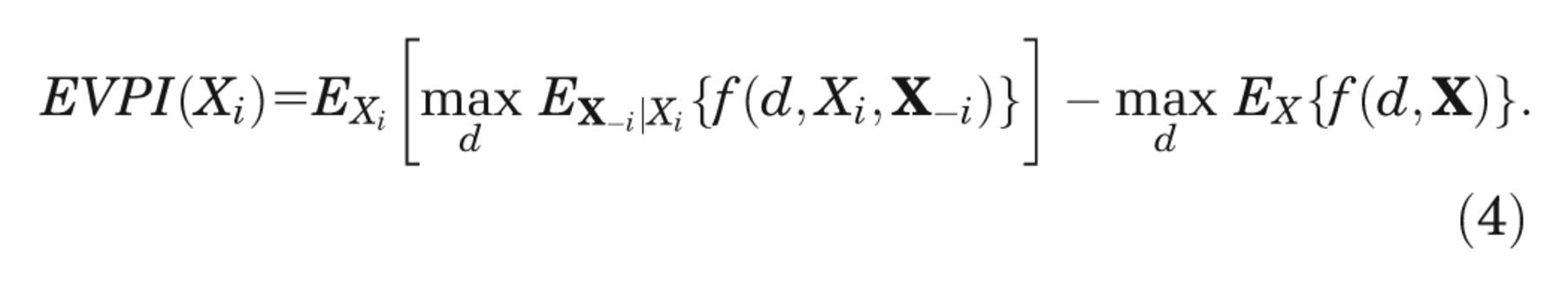
We are commonly in a situation in which we cannot evaluate any of the 3 expectations in equation (4) analytically.
Important exceptions are cases in which models are either of linear form (e.g.,
In the absence of analytic solutions to the expectations in equation (3), the usual approach is to use a nested 2-level Monte Carlo method. This requires us to sample a value of the input parameter of interest in an outer loop and then to sample values from the joint conditional distribution of the remaining parameters and run the model in an inner loop. 5,6 Sufficient numbers of runs of both the outer and inner loops are required to ensure that the partial EVPI is estimated with sufficient precision and with an acceptable level of bias. 7
We recognize 2 important practical limitations to the standard 2-level Monte Carlo approach to calculating partial EVPI. First, the nested 2-level nature of the algorithm with a model run at each inner-loop step can be highly computationally demanding for all but very small loop sizes if the model is expensive to run. Second, we require a method of sampling from the joint distribution of the inputs (excluding the parameter of interest) conditional on the input parameter of interest. If the input parameter of interest is independent of the remaining parameters, then we can simply sample from the unconditional joint distribution of the remaining parameters. However, if inputs are not independent, we may need to resort to Markov chain Monte Carlo (MCMC) methods if there is no analytic solution to the joint conditional distribution. Including an additional MCMC step in the algorithm is likely to increase the computational burden considerably, as well as requiring additional programming.
In this article, we present a simple 1-level “ordered input” algorithm for calculating single-parameter partial EVPI, which requires only a single set of the sampled inputs and corresponding outputs to calculate partial EVPI values for all input parameters. The method is applicable in any modeling scenario in which there is no analytic solution to the expectations in equation (4). The method avoids the nested double loop and is therefore computationally less demanding than the standard 2-level method, and it also avoids the need to sample directly from the conditional distributions of the inputs when inputs are correlated. We describe methods for quantifying the upward bias and precision of the estimator. We illustrate the method in a case study with 2 scenarios: a multilinear model in which inputs are correlated, but with known analytic solutions for all conditional distributions, and the same model in which inputs are correlated but where sampling from the conditional distributions requires MCMC.
Methods
In this section, we describe an algorithm for computing the partial EVPI for a single input parameter of interest, Xi . Code for implementing the algorithm in R 8 is shown in Appendix A and is available for download at http://www.shef.ac.uk/scharr/sections/ph/staff/profiles/mark.
Briefly, the idea is as follows. We assume we have a set of samples from the joint distribution of the model input parameters and a corresponding set of model outputs (i.e., net benefits). The net benefits (for each decision option) are ordered with respect to the input of interest and then partitioned into subsets of equal size. Within each subset, we calculate the mean of the net benefits for each decision option and take the maximum across the decision options. The average of these maxima is taken as an approximation to the first term in equation (4). The second term in equation (4) is computed using standard Monte Carlo sampling—that is, for each decision option, we calculate the mean of the net benefits corresponding to the whole set of input samples and then take the maximum of these means.
In the following subsections, we introduce notation and describe the algorithm in detail in a series of stages.
Stage 1
We define the Monte Carlo sample of model inputs and corresponding model outputs as
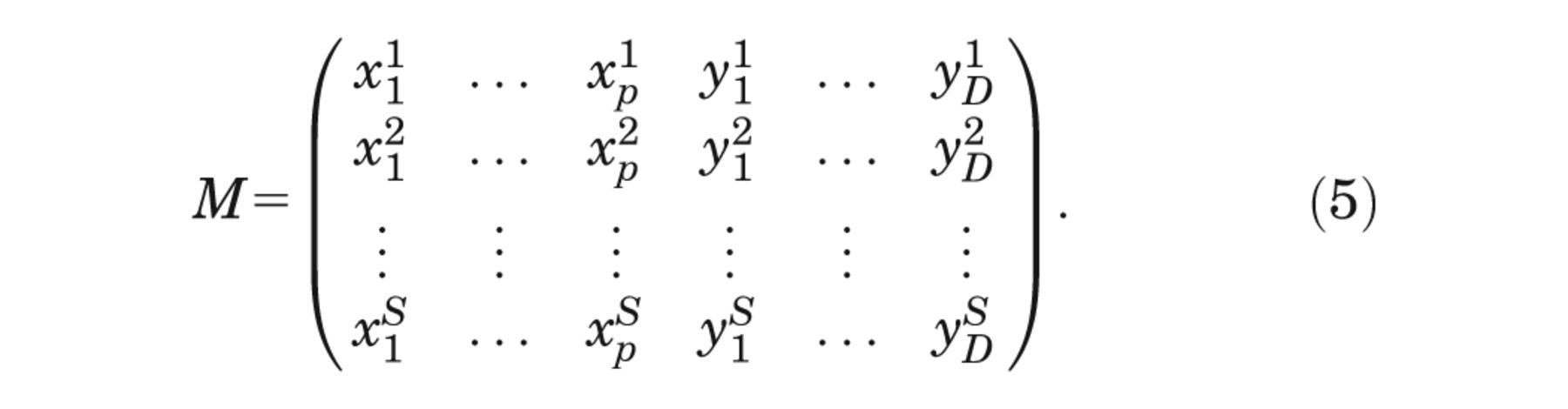
Stage 2
For parameter of interest i, we extract the xi and y 1,. . . ,yD columns and reorder with respect to xi , giving

where
Stage 3
We partition the resulting matrix into k = 1,. . .,K
submatrices
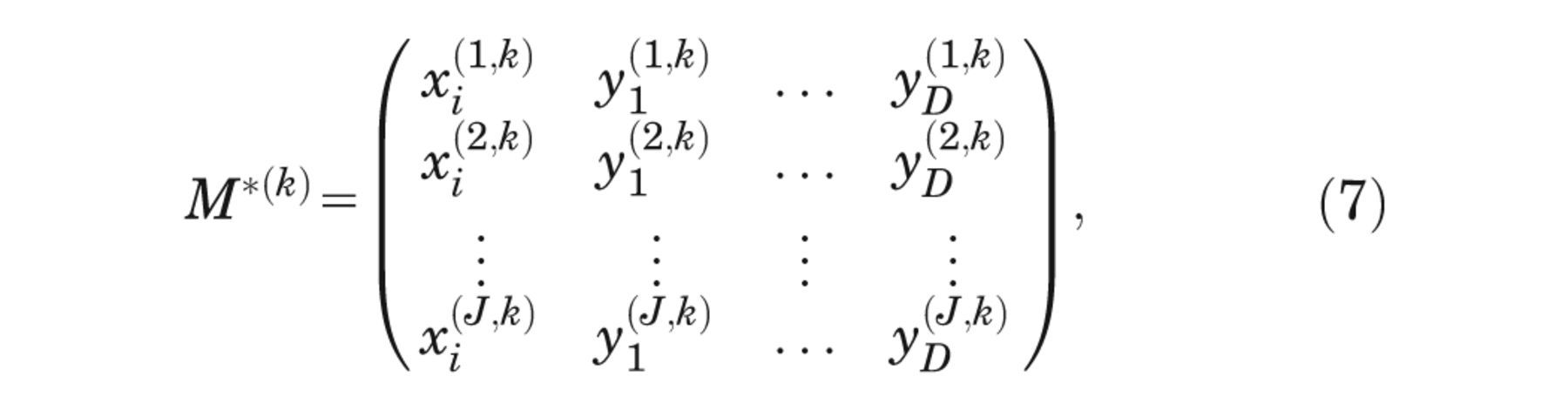
retaining the ordering with respect to xi , and where the row indexed (j, k) in equation (7) is the row indexed (j + (k − 1)J) in equation (6). Note that J × K must equal the total sample size S.
Stage 4
For each
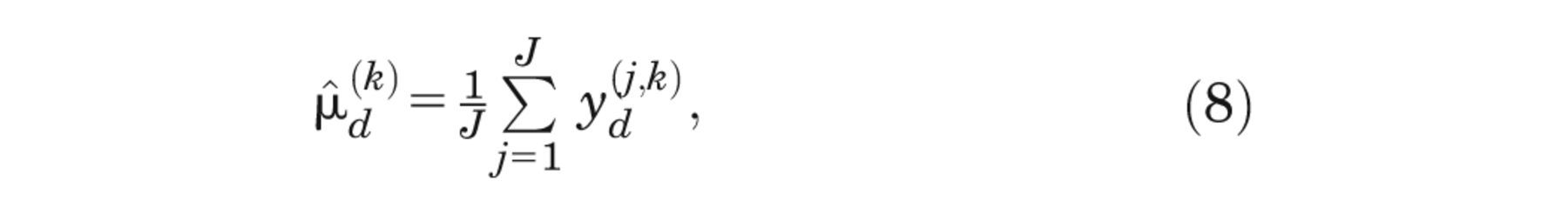
where
The justification for this rests on recognizing that if J is small compared with
S, then the ordered values of the input of interest
The maximum
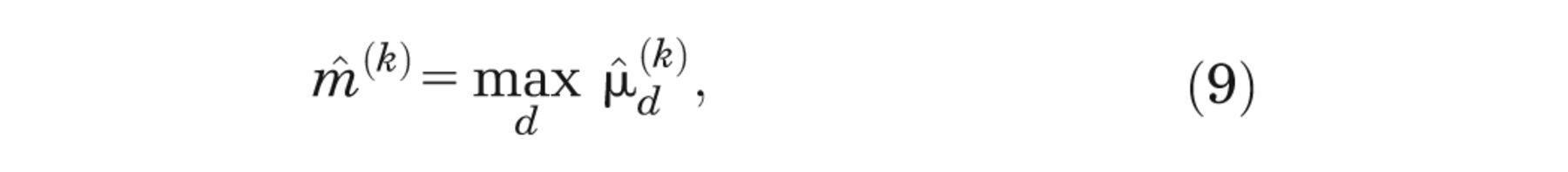
and finally we estimate the first term on the right-hand side of equation (4) by averaging over k = 1, . . . ,K, that is,
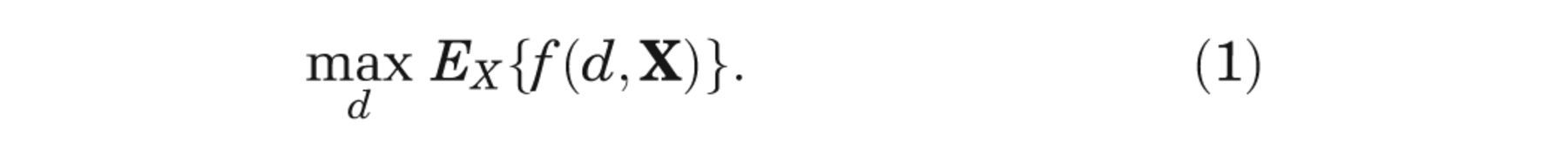
Stage 5
We estimate the second term on the right-hand side of equation (4) using simple Monte Carlo sampling, that is,
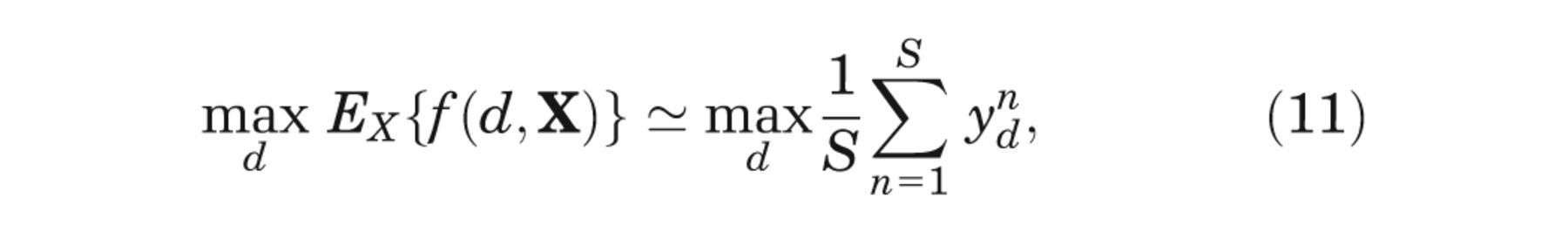
where the order of the xn is irrelevant.
Stages 2 to 4 are repeated for each parameter of interest, noting that only a single set of model runs (stage 1) is required.
Choosing Values For J And K
We assume that we have a fixed number of model evaluations S and wish to choose values for J and K subject to the constraint J × K = S.
First, we note that for small values of J, the EVPI estimator is upwardly biased due to the maximization in equation (9). 7 Indeed, for J = 1 (and K = S), our ordered input estimator for the first term on the right-hand side of equation (4) reduces to
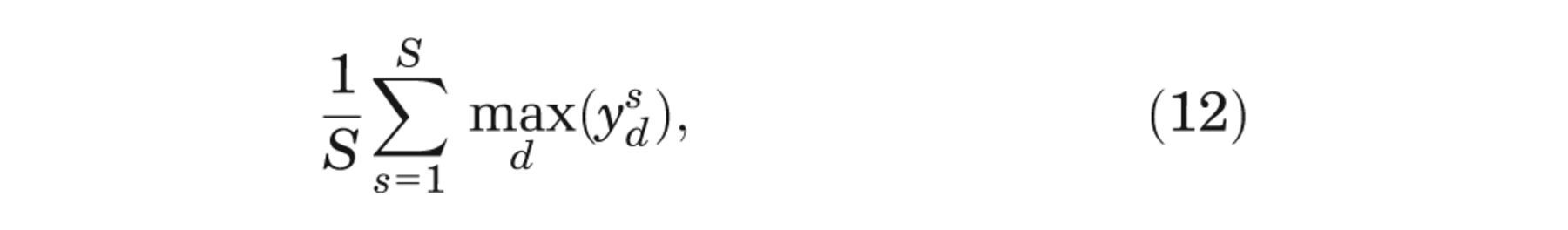
which is the Monte Carlo estimator for the first term in the expression for the overall EVPI,
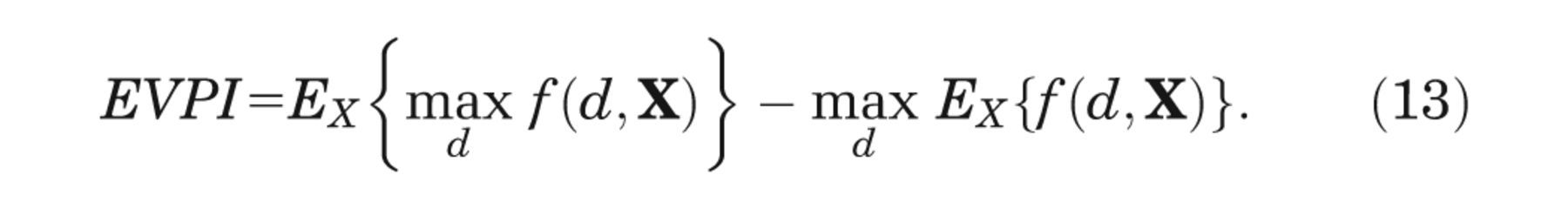
Second, we note that for very large values of J, and hence small values of K, the EVPI estimator is downwardly biased and converges to zero when J = S. In this case, our ordered input estimator for the first term on the right-hand side of equation (4) reduces to

which is the Monte Carlo estimator for the second term on the right-hand side of Equation 4.
The precision of the partial EVPI estimate only depends on S and not on
J and K (see Appendix C for the derivation of an expression for the variance of the estimator). We
therefore only need to consider the minimization of bias in our choice of J and
K when S is fixed. Because the upward bias due to small
J converges to zero as J increases, a sensible choice of
J is that which is just large enough such that the estimated bias
We estimate the upward bias in the following manner, using the method proposed by Oakley and
others.
7
First, we write the
vector of Monte Carlo estimators for the conditional expected net benefits from equation (8) as
Unless J is very small,
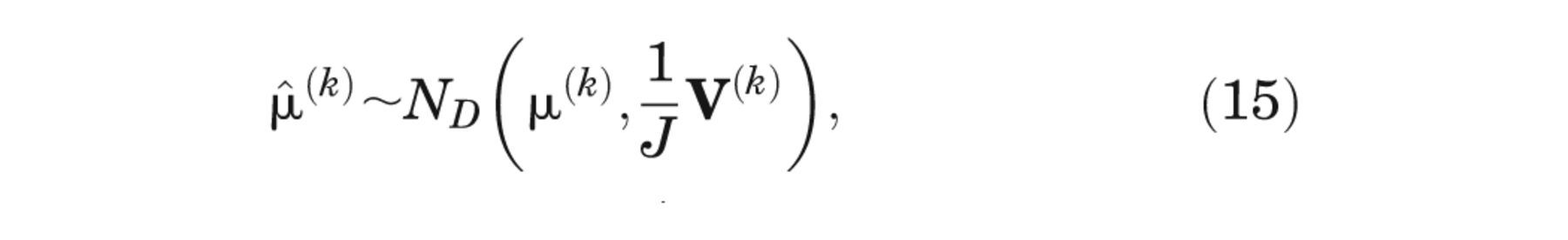
where
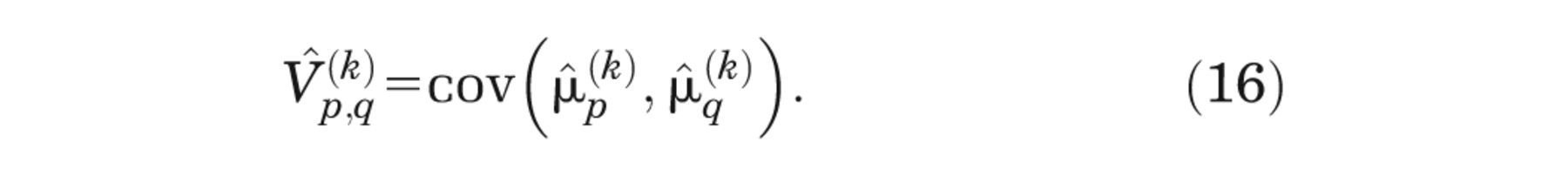
To estimate the bias in
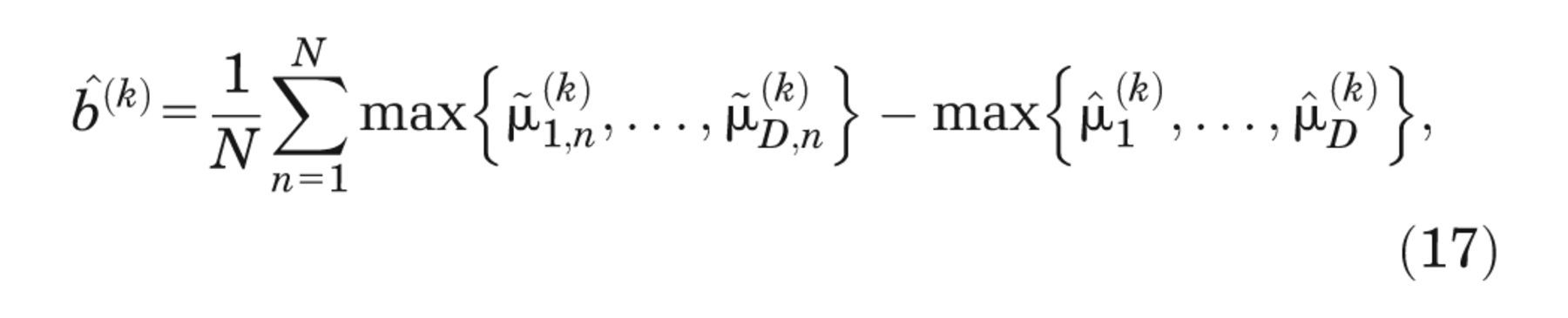
and the expected bias in

R code for computing the bias estimate is available for download at http://www.shef.ac.uk/scharr/sections/ph/staff/profiles/mark.
The left panel of Figure 1 shows
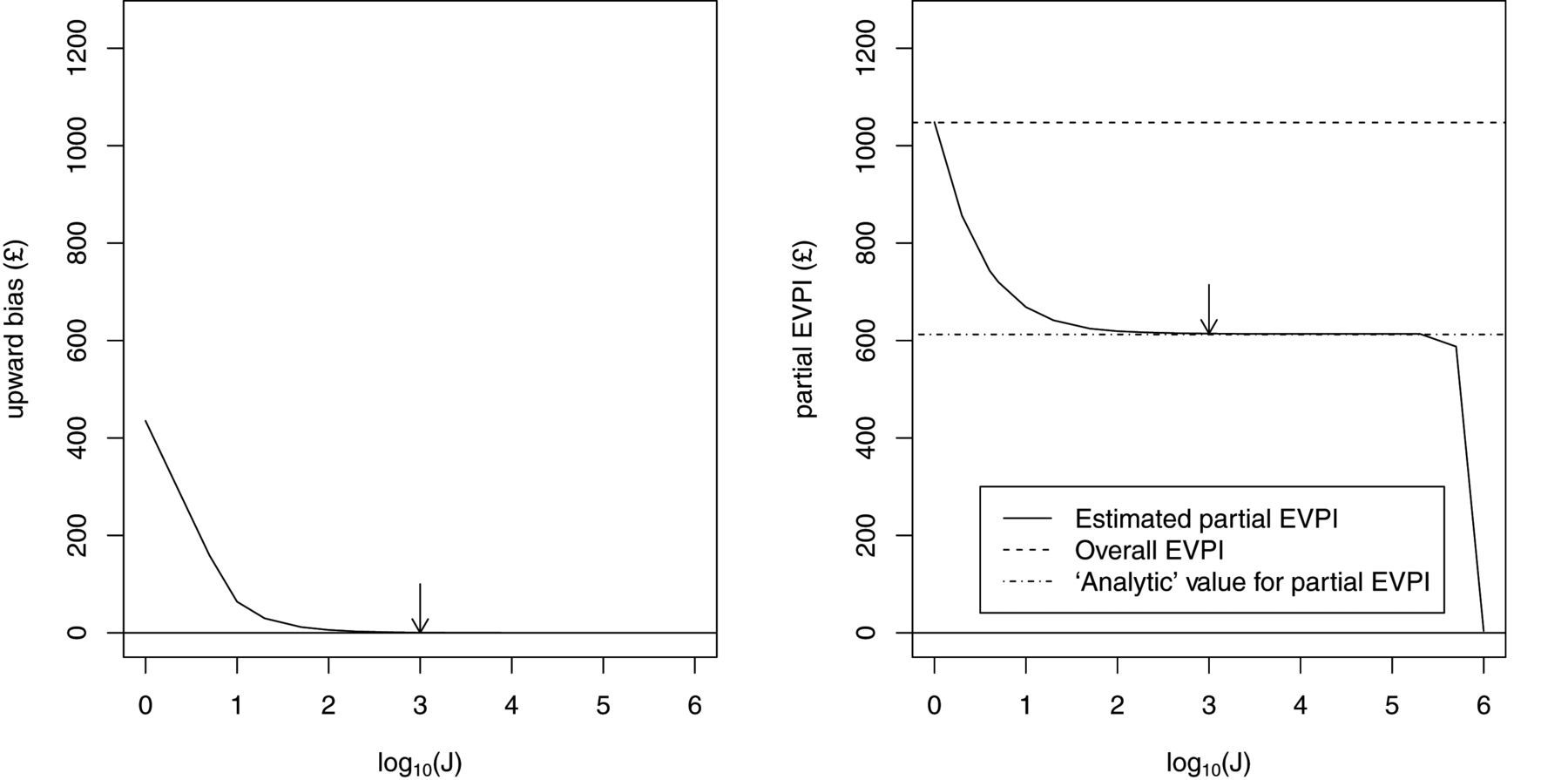
Left panel: upwards bias in partial expected value of perfect information (EVPI) estimator
against log10 (
The right panel shows values for the estimated partial EVPI against J (on the log10 scale). In scenario 1 of the case study, the inner expectation of equation (4) has an analytic solution, and we were therefore able to compute a value of the partial EVPI values for all parameters to high precision using a simple 1-level Monte Carlo sampling scheme. This “analytic” value is shown in the figure, as is the overall EVPI for all parameters. The total number of model evaluations S is again 1,000,000, with K = S/J. Note the upward and downward biases at extreme values of J but also the large region of stability between J = 100 (K = 10, 000) and K = 100, 000 (K = 10). The arrow is placed at J = 1000, the smallest value of J for which the bias is less than £1. At this point, the estimated partial EVPI is £612.63 compared with the analytic value of £612.38.
Case Study
The case study is based on a hypothetical decision tree model previously used for illustrative purposes in Brennan and others, 5 Oakley and others, 7 and Kharroubi and others. 9 The model predicts monetary net benefit, Yd , under 2 decision options (d = 1, 2) and can be written in sum product form as
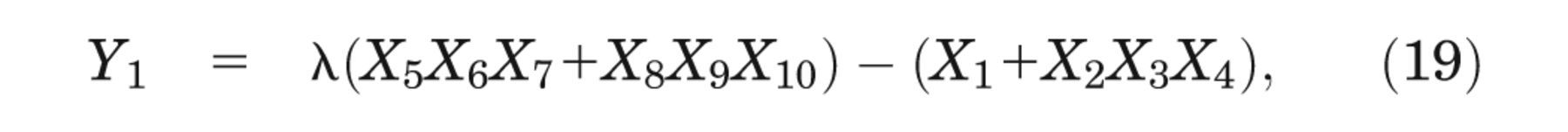
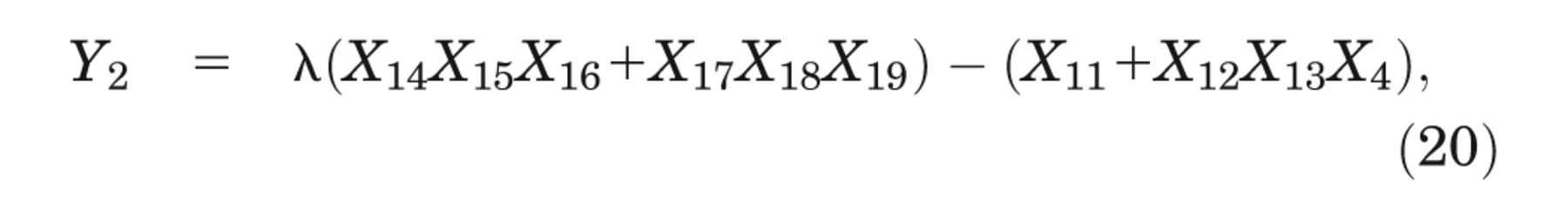
where
Summary of Input Parameters
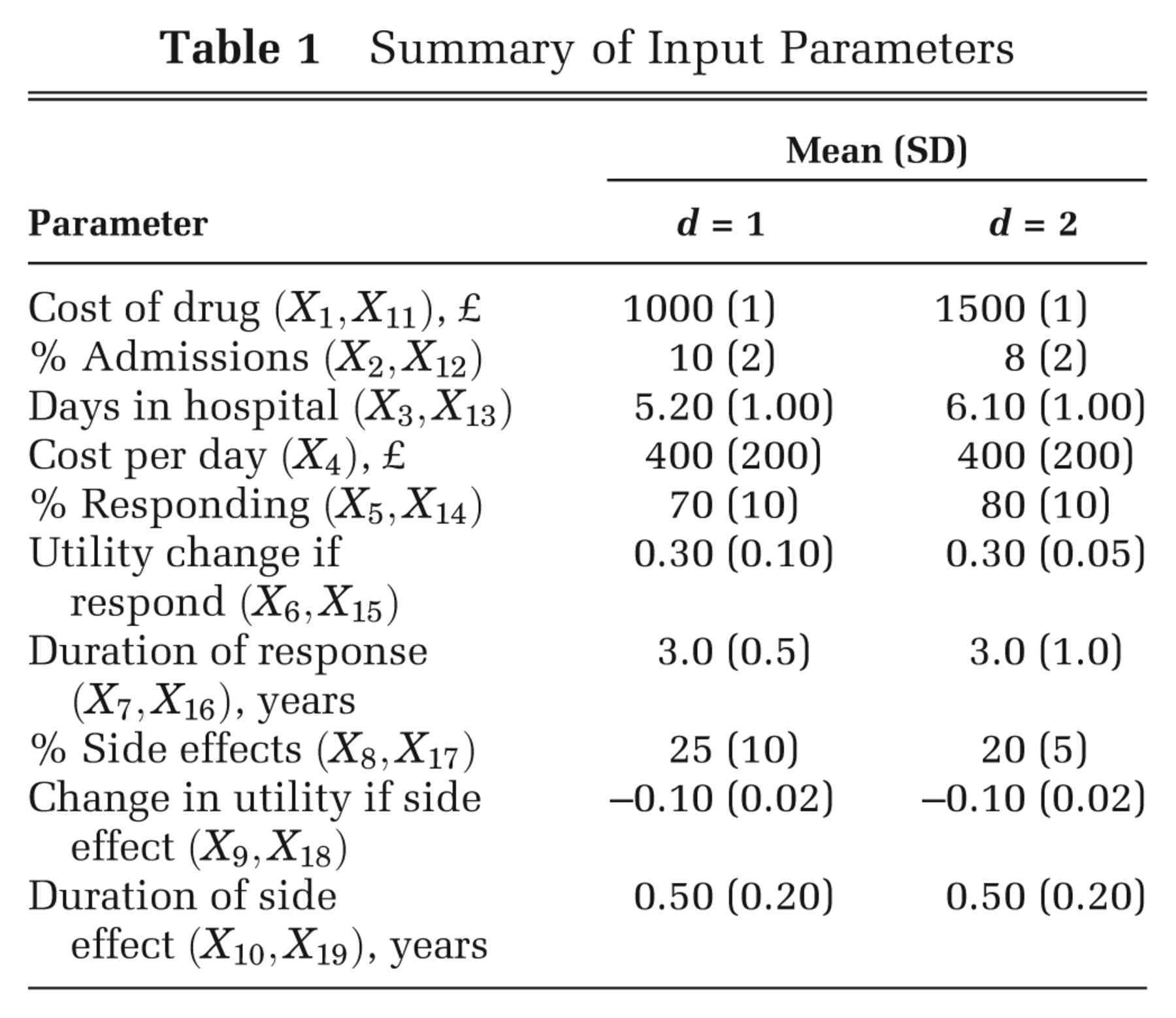
Scenario 1: Correlated Inputs with Known Conditional Distributions
In scenario 1, we assume that a subset of the inputs are correlated but with a joint distribution
such that we can sample from the conditional distributions of the correlated inputs without the need
for MCMC. We assume that the inputs are jointly Normally distributed, with
X
5, X
7, X
14, and
X
16 all pairwise correlated with a correlation coefficient of 0.6 and
with all other inputs independent. In a simple sum product form model, the assumption of
multivariate Normality allows us to compute the inner conditional expectation analytically, as well
as allowing us to sample directly from the conditional distribution
We calculated partial EVPI using 3 methods. First, we calculated the partial EVPI for each parameter using a single-loop Monte Carlo approximation for the outer expectation in the first term of the right-hand side of equation (4) with 106 samples from the distribution of the parameter of interest, as well as an analytic solution to the inner conditional expectation. Next, we calculated the partial EVPI values using the standard 2-level Monte Carlo approach with 1000 inner-loop samples and 1000 outer-loop samples (i.e., 1000 × 1000 = 106 model evaluations in total). Finally, we computed the partial EVPI values using the ordered sample method with the same number of model evaluations, S = 106, and values of J = K = 1000.
Standard errors and bias estimates for the 2-level Monte Carlo partial EVPI estimates were obtained using the methods presented in Oakley and others. 7 The standard errors for the ordered input method partial EVPI estimates were obtained using the method presented in Appendix C. The bias estimates for the ordered input method partial EVPI estimates were obtained using the method presented in the Methods section above. We measured the total computation time for obtaining EVPI values for all 19 parameters.
Results for Scenario 1
Calculating the expected net benefits for decision options 1 and 2 analytically results in values of £5057.00 and £5584.80, respectively, indicating that decision option 2 is optimal. Running the model with 106 Monte Carlo samples from the joint distribution of the input parameters results in option 2 having greater net benefit than option 1 in only 54% of samples, suggesting that the input uncertainty is resulting in considerable decision uncertainty. The overall EVPI is £1046.10.
The partial EVPI values for parameters X 1 to X 4, X 8 to X 13, and X 17 to X 19 were all less than £0.01 and therefore considered unimportant in terms of driving the decision uncertainty. Results for the remaining parameters are shown in Table 2. The standard errors of the partial EVPI values estimated via the ordered input method are considerably smaller than those estimated via the 2-level method, whereas the estimated bias for each parameter is similar. The ordered input method is approximately 4 times faster than the standard 2-level Monte Carlo method in this case.
Partial Expected Value of Perfect Information (EVPI) Values for Scenario 1
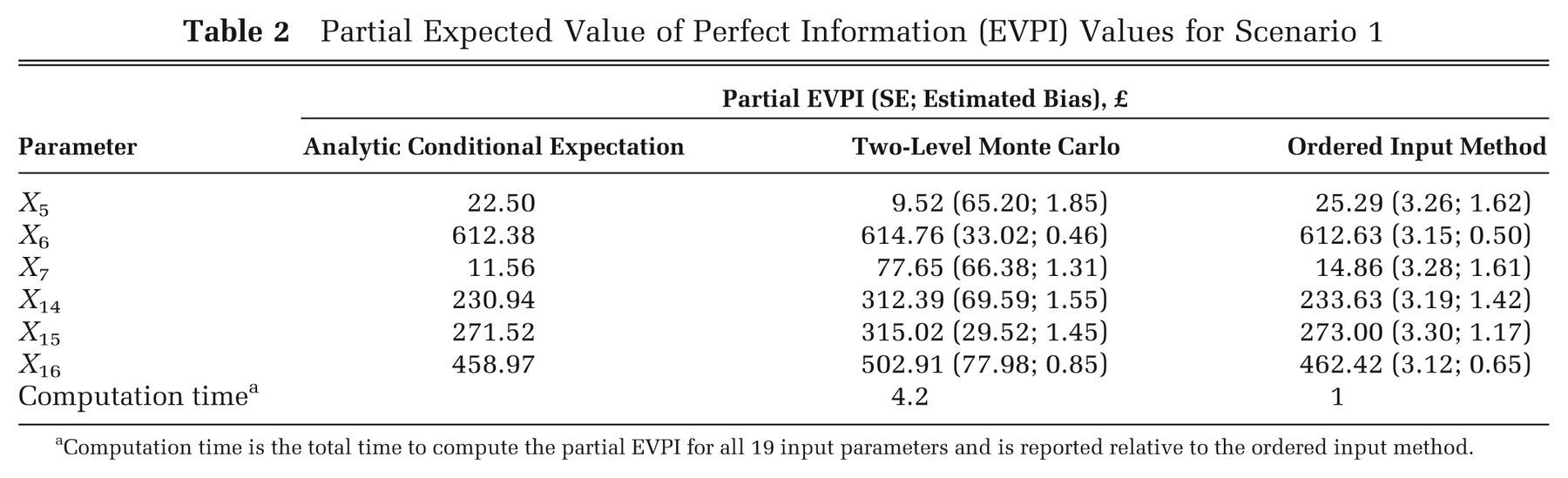
Computation time is the total time to compute the partial EVPI for all 19 input parameters and is reported relative to the ordered input method.
Scenario 2: Correlated Inputs with Conditional Distribution Sampling Requiring MCMC
In scenario 2, we assume that a subset of the inputs are correlated but with a joint distribution
such that we can only sample from the conditional distributions of the correlated inputs using MCMC.
We assume, as in scenario 1, that X
5, X
7,
X
14, and X
16 are pairwise correlated, but
with a more complicated dependency structure based on an unobserved bivariate Normal latent variable
We calculated partial EVPI for each parameter using the standard 2-level Monte Carlo approach
with 1000 inner-loop samples and 1000 outer-loop samples (i.e., 1000 × 1000 = 106
model evaluations in total) using OpenBUGS
10
to sample from the conditional distribution of
Results for Scenario 2
Running the model with 106 samples from the joint distribution of the input parameters resulted in expected net benefits of £5043.12 and £5549.93 for decision options 1 and 2, respectively, indicating that decision option 2 is optimal, but again with considerable decision uncertainty. Based on this sample, the probability that decision 2 is best is 54%, and the overall EVPI is £1240.33.
Partial EVPI results are shown in Table 3. Values for parameters X 1 to X 4, X 8 to X 13, and X 17 to X 19 were again all less than £0.01 and are not shown. Standards errors for the partial EVPI values estimated via the ordered input method are again smaller than those estimated via the 2-level method. The estimated bias is marginally smaller for the ordered input method. The ordered input method is approximately 800 times faster than the 2-level Monte Carlo/MCMC method in this case.
Partial Expected Value of Perfect Information (EVPI) Values for Scenario 2
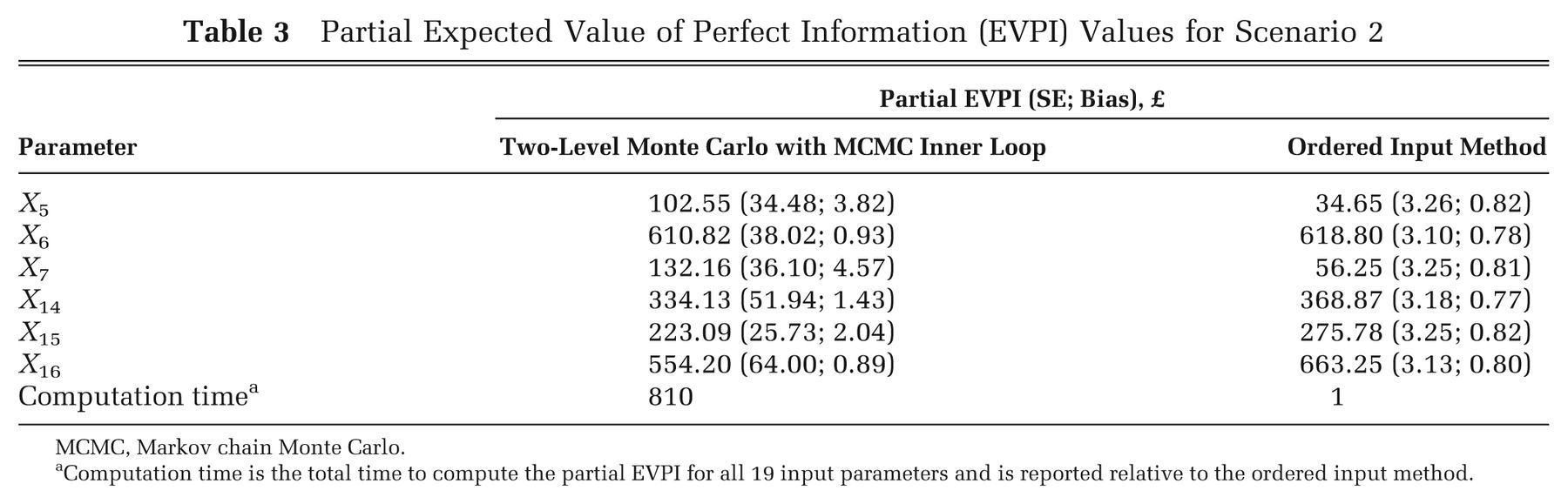
MCMC, Markov chain Monte Carlo.
Computation time is the total time to compute the partial EVPI for all 19 input parameters and is reported relative to the ordered input method.
How Many 2-Level Monte Carlo Inner- and Outer-Loop Samples Are Required to Achieve a Bias and Precision Similar to the Ordered Input Method?
We compared the bias and precision of the partial EVPI estimated via the ordered method with that estimated via the 2-level method with a range of inner- and outer-loop sizes. Our comparator was the partial EVPI for input parameter X 6 for scenario 1 computed using the ordered 1-level method with a total sample size of 106 and J = K = 1000. Using this method, the upward bias was estimated to be £0.50, and the standard error of the estimate was £3.15 (Table 2). Table 4 shows the bias and standard error for the 2-level Monte Carlo method for different inner- and outer-loop sizes, which were estimated using the method proposed by Oakley and others. 7 The reported computation times are relative to the time taken for the ordered input method with a sample size of 106 and J = K = 1000.
Standard Error and Bias for Parameter X 6 in Scenario 1, Computed via the 2-level Monte Carlo Method for a Range of Inner- and Outer-Loop Sizes
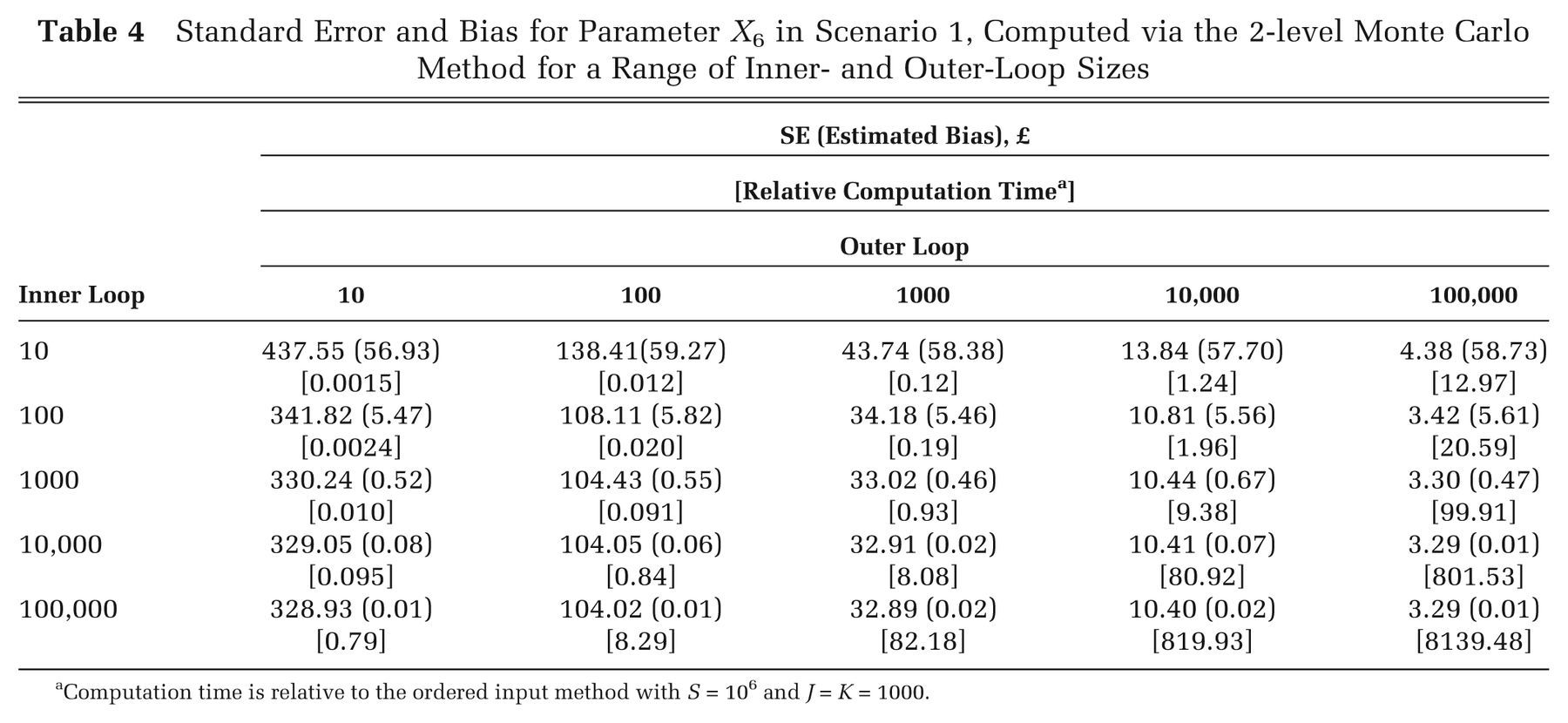
Computation time is relative to the ordered input method with S = 106 and J = K = 1000.
To achieve a similar precision and bias via the 2-level Monte Carlo method, the outer loop must be of the order of 100,000 and the inner loop of the order of 1000. This therefore requires 108 model evaluations and is approximately 100 times slower to compute than the ordered input method.
Discussion
We have presented a method for calculating the partial expected value of perfect information that is simple to implement, is rapid to compute, and does not require an assumption of independence between inputs. The saving in computational time is particularly marked if the alternative is to use a nested 2-level EVPI approach in which the conditional expectations are estimated using MCMC. The method is straightforward to apply in a spreadsheet application, even with little programming knowledge.
Our approach requires only a single set of model evaluations to calculate partial EVPI for all inputs, allowing a complete separation of the EVPI calculation step from the model evaluation step. This separation may be particularly useful when the model has been evaluated using specialist software (e.g., for discrete event or agent-based simulation) that does not allow easy implementation of the EVPI step or when those who wish to compute the EVPI do not “own” (and therefore cannot directly evaluate) the model. The method does require that, if any inputs are correlated, the inputs are sampled from their joint distribution, rather than from their separate marginal distributions. However, this is unlikely to be an important limitation. When inputs are correlated, sampling from their joint distribution is usual practice, for example, when sampling Dirichlet distributed transition probabilities or multivariate Normal distributed regression parameters.
As presented, the method calculates the partial EVPI for single inputs one at a time. We may, however, wish to calculate the value of learning groups of inputs simultaneously. There are good reasons for this. First, for certain forms of model, we may find that learning single inputs alone has little value, but learning a group of inputs has high value due to the interactions between those inputs within the model. It is important to note that interactions result from nonadditive effects within the model and can occur even if inputs are uncorrelated. Second, a certain subset of model inputs may be derived from a single study, and therefore learning one input in this set (by conducting the “perfect” study) implies learning them all. If we are considering the value of a study in reducing uncertainty about inputs, we will consider the value of all the information that arises from the study, not just the information that informs a single input. The value of our method may then be in drilling down to specific inputs or small groups of inputs within some larger group of inputs that is judged to be policy relevant. If inputs can be partitioned into broad policy-relevant groups (i.e., those that might be considered together when a decision is made to commission further research), and if these groups can be treated as uncorrelated, then calculating the EVPI for each group of inputs using 2-level Monte Carlo methods is straightforward. At this point, the ordered approximation method could be used to compute the value of single inputs (or small groups of inputs) if this was felt necessary.
Although it is possible to extend our approach to groups of inputs, we quickly come up against
the “curse of dimensionality.” This is because the method relies on partitioning the
input space into a large number of “small” sets such that in each set, the parameter
of interest lies close to some value. This works well where there is a single parameter of interest,
but if we wish to calculate the EVPI for a group of parameters, the samples quickly become much more
sparsely located in the higher dimensional space. Given a single parameter of interest, imagine that
we obtain adequate precision if we partition the input space into K = 1000 sets of
J = 1000 samples each. With 2 parameters of interest, we would need to order and
partition the space in 2 dimensions, meaning that to retain the same marginal probabilistic
“size” for each set, we now require
We show in Appendix A that the
approximation method relies on the smoothness of the function
In conclusion, the ordered sample method for calculating partial EVPI is simple enough to be easily implemented in a range of software applications commonly used in cost-effectiveness modeling, reduces computation time considerably when compared with the standard 2-level Monte Carlo approach, and avoids the need for MCMC in nonlinear models with awkward input parameter dependency structures.
Footnotes
Appendix A
Appendix B
Appendix C
MS was funded by the UK Medical Research Council fellowship grant G0601721 while undertaking this study.