
Abstract
Health economic decision-analytic models are used to estimate the expected net benefits of competing decision options. The true values of the input parameters of such models are rarely known with certainty, and it is often useful to quantify the value to the decision maker of reducing uncertainty through collecting new data. In the context of a particular decision problem, the value of a proposed research design can be quantified by its expected value of sample information (EVSI). EVSI is commonly estimated via a 2-level Monte Carlo procedure in which plausible data sets are generated in an outer loop, and then, conditional on these, the parameters of the decision model are updated via Bayes rule and sampled in an inner loop. At each iteration of the inner loop, the decision model is evaluated. This is computationally demanding and may be difficult if the posterior distribution of the model parameters conditional on sampled data is hard to sample from. We describe a fast nonparametric regression-based method for estimating per-patient EVSI that requires only the probabilistic sensitivity analysis sample (i.e., the set of samples drawn from the joint distribution of the parameters and the corresponding net benefits). The method avoids the need to sample from the posterior distributions of the parameters and avoids the need to rerun the model. The only requirement is that sample data sets can be generated. The method is applicable with a model of any complexity and with any specification of model parameter distribution. We demonstrate in a case study the superior efficiency of the regression method over the 2-level Monte Carlo method.
Keywords
Health economic decision-analytic models are used to estimate the expected net benefits of competing decision options. The true values of the input parameters of such models are rarely known with certainty, and uncertainty in model parameters typically results in decision uncertainty. This may motivate decision makers to consider options for further data collection alongside the adoption of new technologies or to delay adoption until after data collection.1,2 The value of learning an input parameter (or a group of input parameters) can be quantified by its partial expected value of perfect information (partial EVPI).3–6 However, we are unlikely to be able to collect perfect information, and it is more useful to quantify the value of specific research designs that will inform the decision-making problem. The value of reducing, rather than eliminating, uncertainty through the collection of data is captured by the expected value of sample information (EVSI).4,7,8
The EVSI for any particular data collection exercise will depend not only on the study design in question but also on the decision context. 8 Important factors include whether there are costs associated with either delaying or reversing adoption decisions,1,9,10 whether the adoption decision will be fully implemented 11 and whether the proposed study extends across jurisdictions.12,13 Some of these factors arise in moving from EVSI per patient to population EVSI, but others also arise in estimating EVSI per patient. While recognizing these issues, we do not discuss them further in this article but concentrate on the problem of computing per-person EVSI within a single jurisdiction under the assumption of costless reversibility with perfect implementation and with no delay in either the study or the adoption.
The concept of EVSI was first discussed in the health economics literature well over a decade ago.4,7,14,15 Despite this, very few research funding or design decisions are informed by EVSI. This, at least in part, reflects the computational burden of calculating EVSI via generic Monte Carlo sampling-based methods. For example, in a recently published cost-effectiveness study, the authors noted that to compute EVSI without assuming an approximation that the model was linear, it would have taken 7.5 days. 16 In another example, the proposed EVSI analysis would have taken 37.5 days. 17 Clearly, computation times of this order are prohibitive.
The reason for the high computational cost of EVSI analysis is that, unless the model is of a certain form or unless certain parametric assumptions are made, a nested 2-level Monte Carlo scheme is required. In this scheme, plausible data sets are generated in an outer loop, and then conditional on each data set, samples are generated from the posterior distribution of the parameters in an inner loop. The model is run with each inner loop set of parameters to estimate the expected net benefits, conditional on the data sets that have been simulated in the outer loop. The computational cost arises primarily due to the repeated evaluation of the model within the inner loop but also due to the burden of repeated sampling in the inner loop. If the aim is to search over the study design space, then this problem is further compounded because EVSI itself must be repeatedly calculated. Another difficult arises with the 2-level Monte Carlo approach if the prior distribution of the model parameters is not conjugate to the data likelihood. In this case, generating the inner-loop samples will typically require Markov chain Monte Carlo (MCMC), and the repeated application of MCMC for each sampled data set adds to the computational burden.
A fast approximation scheme for the inner-loop step has been proposed,18,19 but this method requires repeated evaluation of partial derivatives of the log posterior density function and therefore considerable time and effort writing the necessary computer code on the part of the analyst. Computationally cheaper single-loop approaches are sometimes available, but these rely either on the model being of a certain form7,20,21 or on assumptions of Normality of the mean incremental net benefits. 1 Fast single-loop methods also exist for computing partial EVPI for single parameters,22,23 but these have not yet been extended to the computation of EVSI.
In this article, we present a method for calculating per-patient EVSI that avoids the nested 2-level scheme, requiring only the single set of sampled model inputs and corresponding model outputs (i.e., net benefits) that is generated in a standard probability sensitivity analysis (PSA). The method is based on a nonparametric regression of the net benefits on data samples that are generated conditional on the sampled input parameters in the PSA and follows closely the nonparametric regression method for computing partial EVPI described in Strong et al. 24 The method makes no assumptions regarding the form of the model, does not require the use of MCMC, and does not require that the parameter prior is conjugate to the data likelihood. All that is required is that the data likelihood can be sampled (but not necessarily evaluated). The article is structured as follows. In the second section, we introduce the method and describe its general application. In the third section, we demonstrate the method in the case study model that was used for illustrative purposes in Ades et al., 7 and in the fourth section, we present results. We conclude with a short discussion.
Method
EVSI is the expected difference between the value of the optimal decision based on some sample of data, informative for some subset of inputs, and the value of the decision made only with prior information.3,4,7 To express this, we first introduce some notation.
We assume that we are faced with D decision options, indexed d = 1, . . ., D, and have built a model NB(d,
We envisage that we can collect data that will be informative for some subset of parameters. We consider the (as yet uncollected) data as a vector of random variables and denote this as uppercase
We denote the expectation over the joint distribution of
The expected value of our optimal decision, made only with current information is
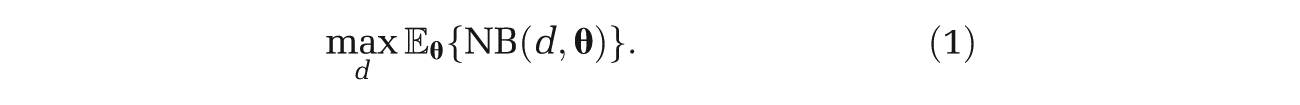
If we had data
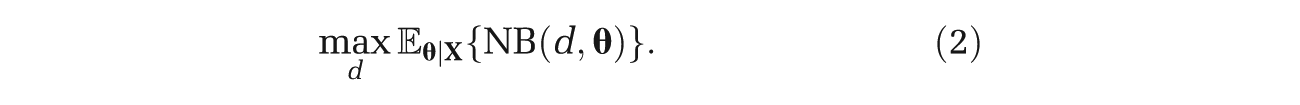
But, since
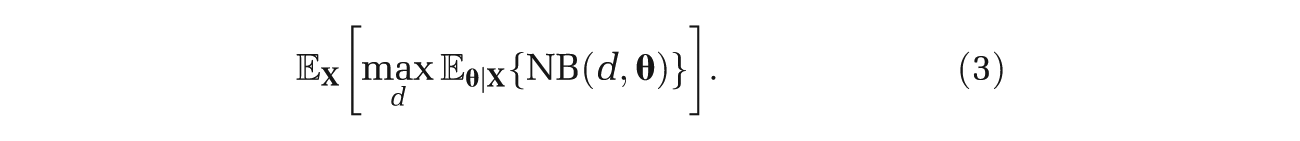
The distribution of
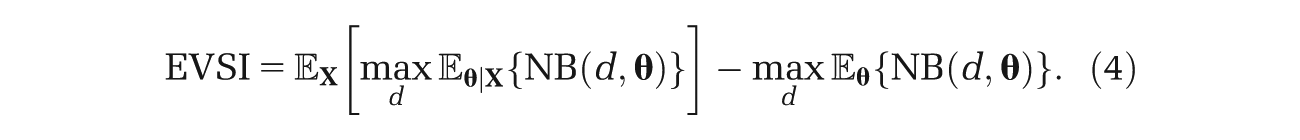
At this point, we note that we can reexpress (4) as
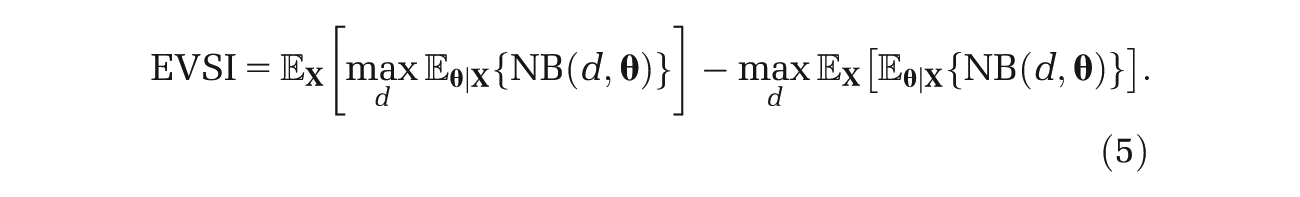
The reason for the reexpression will become apparent when we discuss Monte Carlo sampling schemes for estimating EVSI.
The Monte Carlo Approach to Computing EVSI
A probabilistic sensitivity analysis (PSA) takes N samples from the joint distribution of the input parameters, {
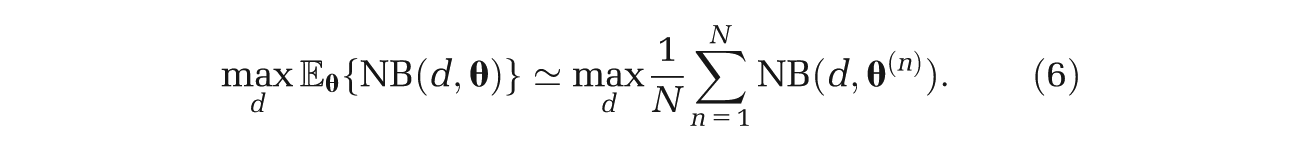
The first term in equation (4) requires more work, and unless there are analytic solutions to the expectations, the usual approach is to use a nested 2-level Monte Carlo method. 7 Here, the estimator is given by
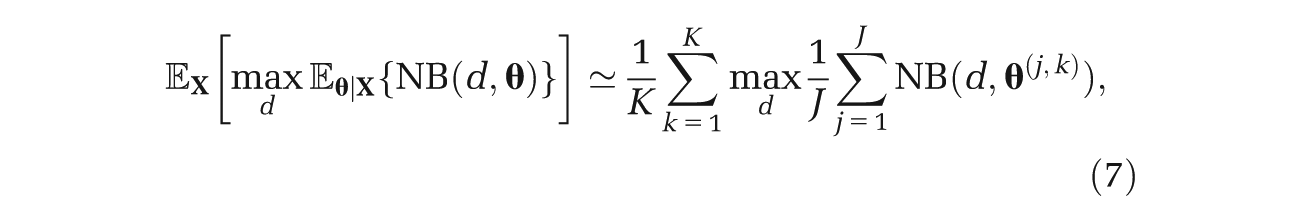
where
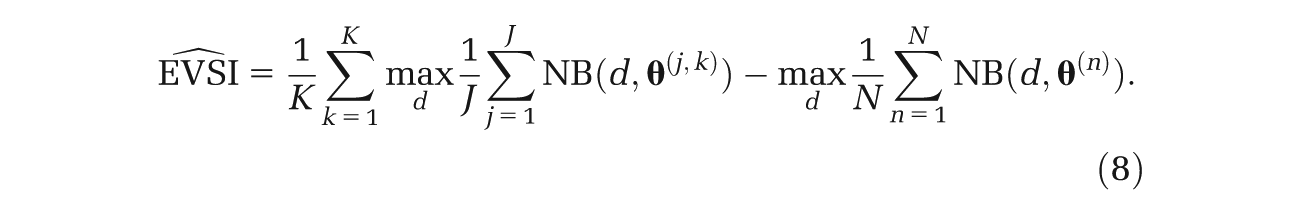
However, if we arrange our sampling scheme such that it reflects equation (5), we obtain instead
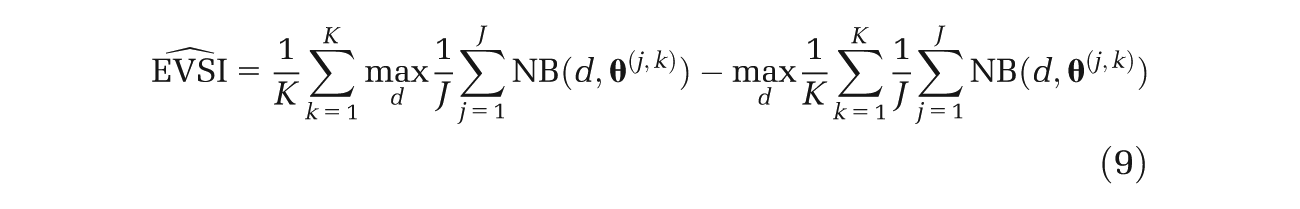
Here, both terms in the EVSI expression are evaluated using the same sampled values of
The first problem with the nested 2-level scheme is the requirement to evaluate the net benefit function (i.e., to run the model) at each iteration of the inner loop, resulting in J×K model evaluations. If the model is slow to run and/or if J and K are large (to obtain adequate precision), then the scheme will be computationally burdensome. A second potential problem is the requirement to sample from the posterior distribution of the input parameters, conditional on the sampled data, that is, obtaining the j = 1, . . ., J samples
We note at this point that in some restricted cases, we can avoid entirely the inner-loop Monte Carlo step. If the model is linear or multilinear (i.e., of “sum-product” form) in the parameters, and if the parameters are independent of one another (and retain this independence after updating with data), and if we can analytically compute the posterior expectations of the parameters given the data, then we can simply “plug in” the expected parameter values into the net benefit equation to obtain the expected net benefit.7,21,26
Nonparametric Regression Method
The problem with the 2-level Monte Carlo scheme is the need to compute the inner expectation in the first term in equation (4) via Monte Carlo. Not only does this require J model runs for each outer loop, but it is this step that requires the potentially problematic sampling from the conditional distribution p(
Consider generating a random parameter vector
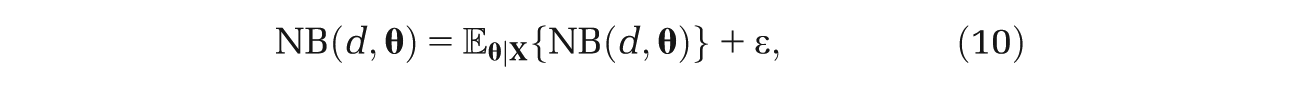
where the error ϵ is a function of both
To see why ϵ has zero mean, we rearrange to give
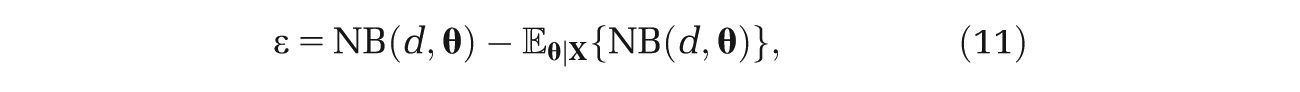
and then take expectations with respect to both
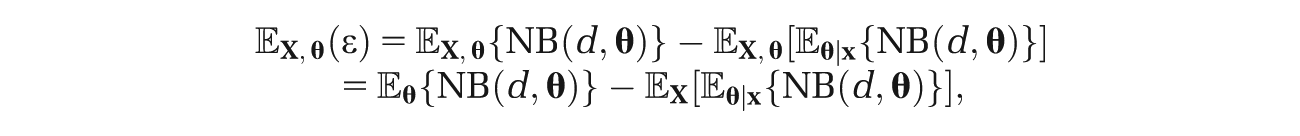
noticing that the first term in the right-hand side of equation (11) is a function only of
Next, we recognize that the expectation
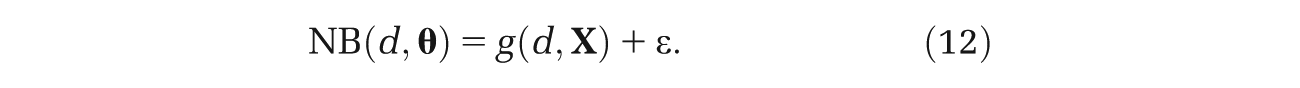
In some instances, the data
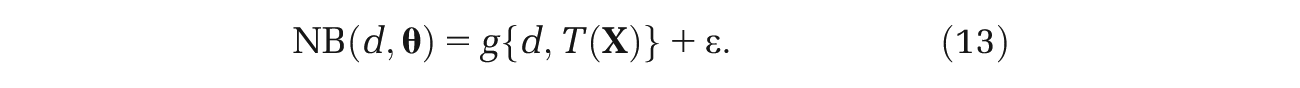
We discuss choice of summary statistic in the next section.
Last, for each decision option d = 1, . . ., D, we treat the net benefits in the PSA sample, NB(d,
When we adopt a GAM model, we usually represent the unknown underlying smooth function as some form of spline, a common choice being the cubic spline. In the simplest case, a univariate cubic spline represents an arbitrary smooth single-input function as a series of short cubic polynomials joined piecewise such that the function is twice-differentiable at the “knots” (i.e., join points). The same spline can also be represented as the weighted sum of a series of predetermined “basis functions” that extend over the whole range of the function input. Simple univariate cubic splines have natural extensions to higher dimensions and to a regression framework, where the spline parameters (i.e., the basis function weights) are estimated from noisy data. For an introduction to GAM models, see Hastie and Tibshirani 27 or Wood. 28
Returning now to the problem of estimating g{d, T(
We note here that EVSI is invariant to the reexpression of net benefits as incremental net benefits, relative to some chosen “baseline” option. Under this reexpression, the (incremental) net benefit of the baseline option is zero. This reduces the number of regression equations from D to D− 1.
Choice of Summary Statistic T(·)
Study data
If we wish to update beliefs about q > 1 economic model parameters {θ1, . . ., θ
q
}, then we would calculate q summary statistics T(
In the case of q > 1, we write the vector of scalar summary statistics as T(
Hypothetical Nonparametric Regression Example
To give an example, we imagine a hypothetical net benefit function NB(θ) = θ2 (for clarity, we have dropped the decision option index d in this example). The parameter θ represents a proportion (e.g., of people in the population who have a certain characteristic), and current knowledge about the proportion is expressed via a Beta(40,200) distribution. We want to know the value of doing a study with 500 participants to learn about the proportion. The number of people in the study with the characteristic of interest,
The PSA sample comprises samples {θ(1), . . ., θ(K)} with the corresponding samples from the net benefit function {NB(θ(1)), . . ., NB(θ(K))}. For each sample θ(k), we generate a sample of data
Figure 1 shows a scatter plot of sampled values of the incremental net benefit, NB(θ) = θ2, versus sampled values of T(
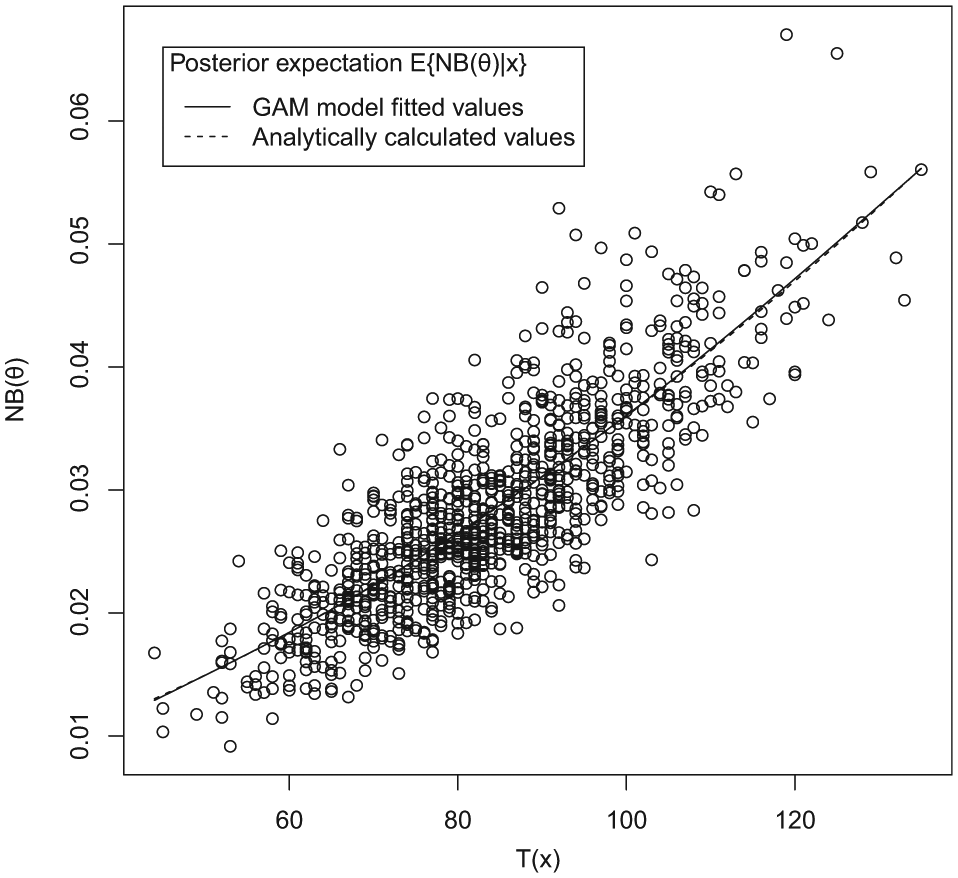
Hypothetical example. Generalized additive model (GAM) model fitted values of the posterior expected incremental net benefit versus analytic values. The lines representing the GAM fitted and analytic values are almost indistinguishable.
Regression Diagnostics
As with all regression analysis, it is important to check assumptions. Most important, we require that there is no structure in the residuals (e.g., a U-shaped or S-shaped pattern) since this would suggest unmodeled structure in the target function g and therefore bias in the fitted values. We note that for the purposes of calculating EVSI, we are seeking to estimate only the posterior mean net benefits. We do not require the posterior variance of the net benefits for the EVSI computation and therefore whether the residuals have equal variance and follow a particular distribution is of secondary importance. 29
In contrast to the estimator for the EVSI, the estimator for the Monte Carlo standard error of the EVSI given in the online Appendix does rely on the net benefits having approximately equal variance and approximate Normality if the number of rows of the PSA is small. However, if the size of the PSA is large, then the standard error estimator can be justified on large sample results, even in the absence of Normality of the net benefits (see Appendix). 28
EVSI Calculation
After fitting a GAM model for each decision option d, we then extract the regression model fitted values. The fitted values are estimates of g{d, T(
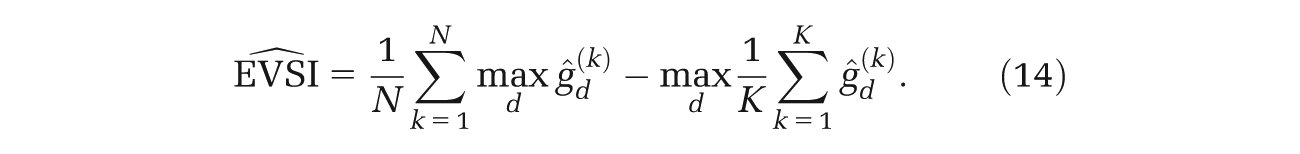
Note that we choose
The sampling scheme for the GAM regression-based EVSI is given in Box 1.
Generalized Additive Model (GAM) Regression-Based EVSI Algorithm

PSA, probability sensitivity analysis; EVSI, expected value of sample information.
Because we are averaging over k, we can think of this as a single-loop Monte Carlo method. The size of K will determine the precision of the estimate of the EVSI, and a method for estimating the standard error of the GAM-based approximation is given in the Appendix.
Case Study: Ades (2004) Decision Tree Model
Model
Our case study is based on the model that was used for illustrative purposes in Ades et al.
7
The decision problem has two options: d = 1 (standard care) and d = 2 (new treatment) and can be represented by a simple decision tree (Figure 2). There are 11 parameters in the model, which we write as the vector
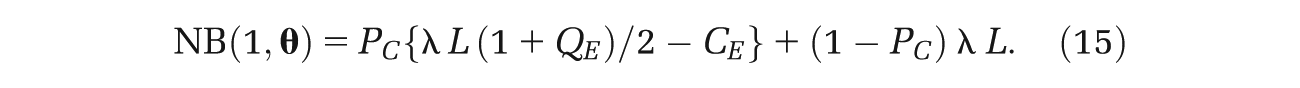
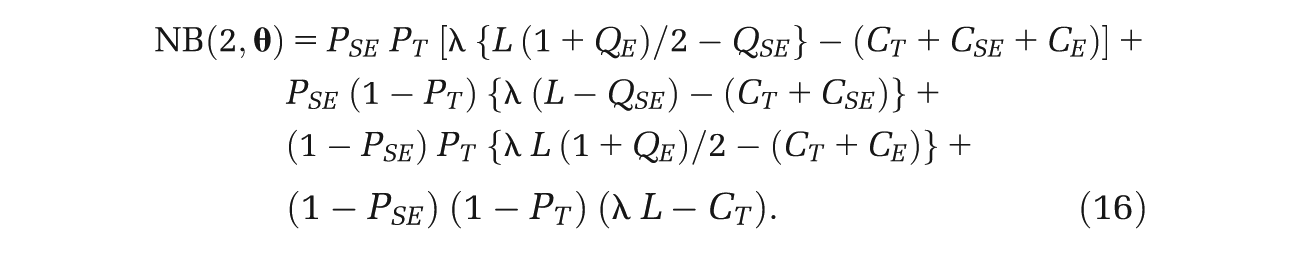
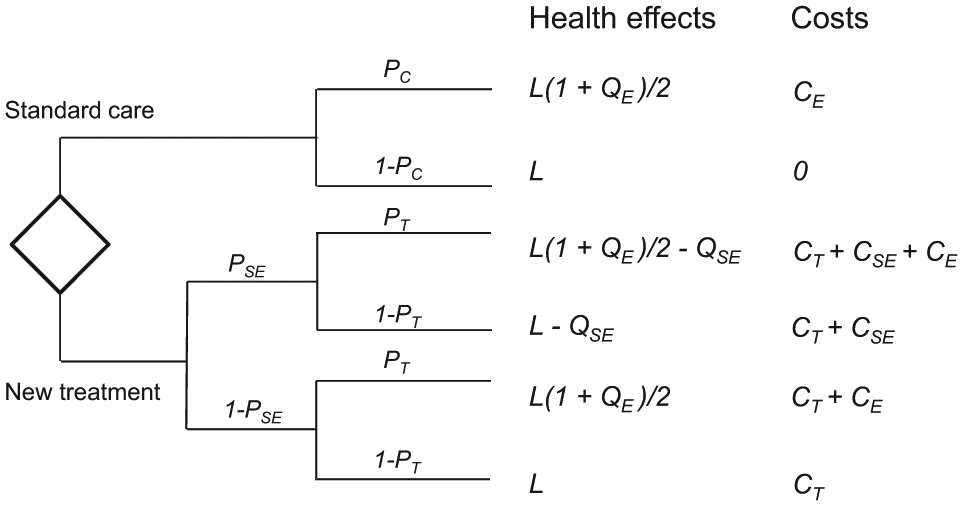
Decision tree model. From Ades et al., 7 copyright © 2004, Society for Medical Decision Making. Reprinted by Permission of SAGE Publishers.
Case Study Parameter Distributions
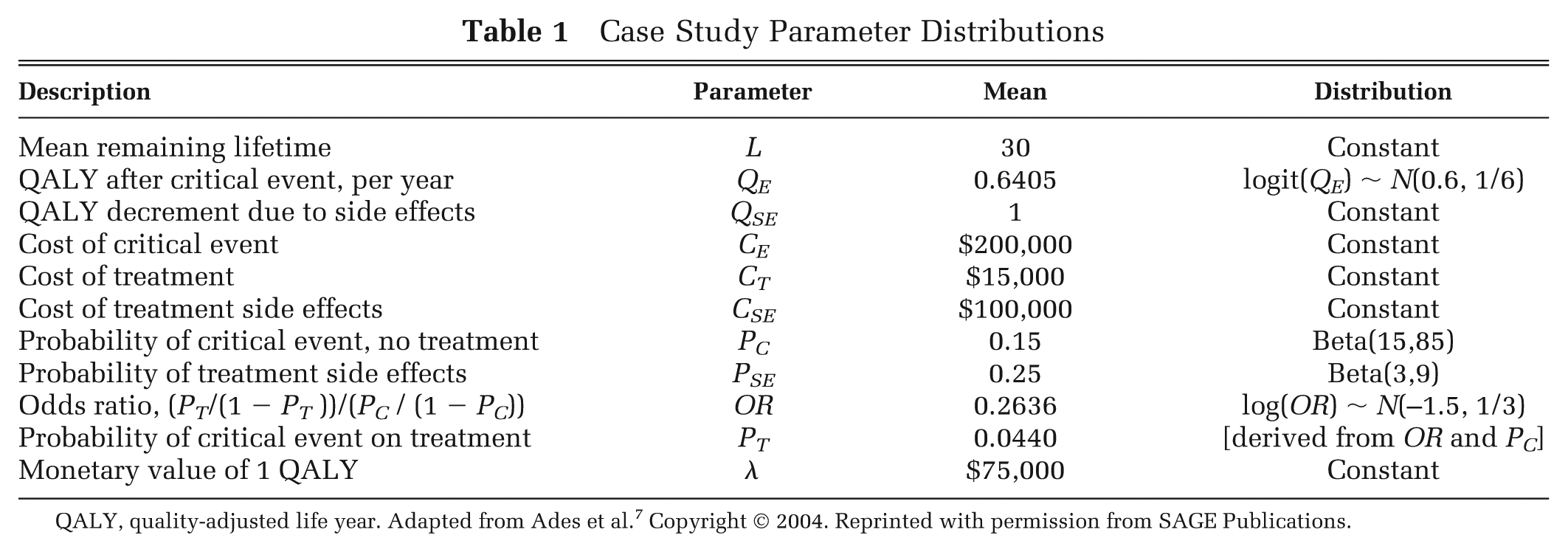
QALY, quality-adjusted life year. Adapted from Ades et al. 7 Copyright © 2004. Reprinted with permission from SAGE Publications.
The model is multilinear in the parameters, and all parameters are independent. Thus, the expectation of the net benefit,
For our case study, we consider the same 3 data collection scenarios presented in Ades et al. 7 —that is, data collection to inform the probability of side effects (PSE), the quality of life after critical event (QE), and the treatment effect size (OR). For each scenario, we calculated EVSI using 3 methods. First, we replicated the method presented in Ades et al. The method relies on the model being of multilinear form with independent parameters and that there are analytic solutions (or good approximations) to the posterior expectations of the parameters, conditional on simulated data. Hence, the method only requires a single-loop Monte Carlo scheme to evaluate the outer expectation in the first term in equation (4). Second, we used the 2-level Monte Carlo scheme outlined earlier, with an MCMC inner loop. This method does not rely on the model being multilinear with independent parameters or that there are analytic solutions to the posterior expectations of the parameters. However, it has high computational cost. Third, we used the GAM regression method presented earlier. As with the Ades et al. method, the GAM method uses Monte Carlo to evaluate the outer expectation in the first term in equation (4). For consistency, we use K to denote the size of the outer expectation Monte Carlo loop when reporting all 3 methods.
Because all 3 methods use Monte Carlo to estimate the outer expectation in equation (4), there will be a Monte Carlo sampling error that tends to zero as the outer-loop sampling size increases. For each estimated EVSI, we calculated the Monte Carlo standard error using the methods presented in the Appendix. We repeated each analysis with a range of values of K to demonstrate the relationship between K and the Monte Carlo standard error. We also recorded the total CPU time required to undertake the EVSI computation to compare the efficiency of each method at different values of K.
For the Ades et al. 7 method, we chose values of K equal to 104, 105, and 106. For the MCMC-based method, we chose an inner-loop sample size of J = 104 after an initial exploration to determine an adequate sample size to achieve stability of the inner-loop estimates. We then chose values of K equal to 104, 105, and 106. Values of K greater than this required prohibitively long runtimes. For the GAM-based method, we chose values of K equal to 104, 105, and 106.
Data Collection Scenario 1: EVSI for the Probability of Side Effects (PSE)
To reduce uncertainty about PSE, we considered the value of undertaking an observational study of n = 60 patients on the new treatment. The number of participants observed to experience a side effect is assumed to follow a Binomial(PSE, 60) distribution.
Method 1—single-loop method presented in Ades et al
In method 1, we replicated the single-loop method used in the case study in Ades et al.
7
First, we drew k = 1, . . ., K samples from the Beta(3, 9) prior distribution for PSE. Next, for each sampled value
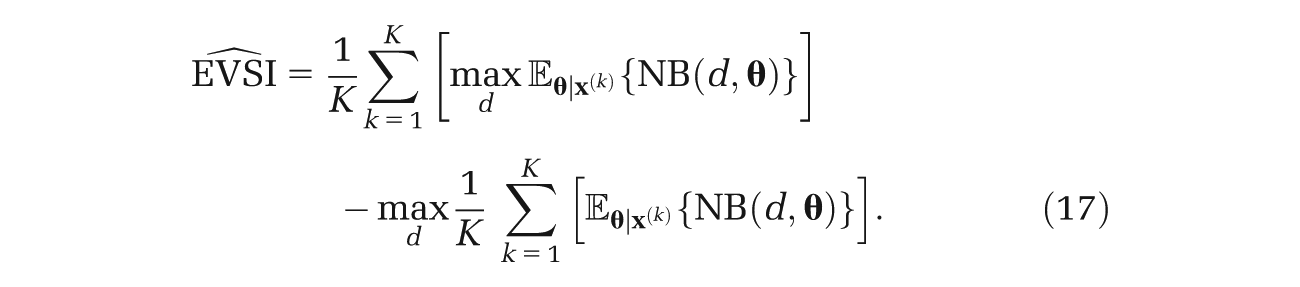
Method 2—2-level nested Monte Carlo/MCMC sampling scheme
In method 2, we implemented the generic 2-level Monte Carlo scheme outlined earlier. In an outer loop, we drew k = 1, . . ., K samples from the Beta(3, 9) prior distribution for PSE. For each value
Method 3—GAM regression
In method 3, we implemented the GAM regression scheme outlined earlier. First, we generated a PSA sample of size K. We calculated the incremental net benefit for each PSA sample. Next, for each parameter vector
Data Collection Scenario 2: EVSI for Quality of Life after Critical Event (QE)
To reduce uncertainty about QE, we considered the value of undertaking an observational study of n = 100 patients who have experienced a critical event. We assume that, conditional on QE, the sample mean of the logit transform of the quality of life reported in a single data collection exercise is Normally distributed with expectation logit(QE) and variance σ2/n, where σ2, the population variance, is assumed known and equal to 2 (see Ades et al. 7 for details).
Method 1—single-loop method presented in Ades et al
As in scenario 1, we replicated the single-loop method used in the case study in Ades et al.
7
First, we drew k = 1, . . ., K samples from the Normal(0.6, 1/6) prior distribution for logit(QE). Next, for each sampled value logit(QE)(k), we generated a sample of data
Method 2—2-level nested Monte Carlo/MCMC sampling scheme
In method 2, we implemented the 2-level Monte Carlo scheme outlined earlier. In an outer loop, we drew K samples from the Normal(0.6, 1/6) prior distribution for logit(QE). For each value logit(QE)(k), we generated a sample of data
Method 3—GAM regression
In method 3, we implemented the GAM regression scheme outlined earlier. First, we generated a PSA sample of size K. We calculated the incremental net benefit for each PSA sample. Next, for each parameter vector
Data Collection Scenario 3: EVSI for the Treatment Effect Size (OR)
To reduce uncertainty about the treatment effect size parameter OR, we consider the value of undertaking a randomized controlled trial with n = 200 patients allocated to the new treatment, and n = 200 patients allocated to standard care. We assume that, conditional on PC and PT, where logit(PT) = logit(PC) + log(OR), the number of critical events is
Method 1—single-loop method presented in Ades et al
Again, we replicated the single-loop method used in the case study in Ades et al.
7
The scheme for updating the model parameters conditional on the sampled data is rather more complex than in scenarios 1 and 2. We give a brief outline of the method here, and the reader is referred to the original study for full details. First, we drew k = 1, . . ., K samples from the Beta(15, 85) prior distribution for PC, and k = 1, . . ., K samples from the Normal(–1.5, 1/3) prior distribution for log(OR). For each k, we calculated
Method 2—2-level nested Monte Carlo/MCMC sampling scheme
In method 2, we implemented the 2-level Monte Carlo scheme outlined earlier. In an outer loop, we generated samples of data
Method 3—GAM regression
In method 3, we implemented the GAM regression scheme outlined earlier. First, we generated a PSA sample of size K. We calculated the incremental net benefit for each PSA sample. Next, for each parameter vector
Results
Table 2 shows the EVSI values, standard errors, and timings for the 3 data collection scenarios calculated by the Ades et al. 7 method, the 2-level Monte Carlo/MCMC method, and the GAM regression method. For comparison, Ades et al. report values of $5550, $1880, and $3260 for scenarios 1, 2, and 3, respectively, using the single-loop method with a sample size of 105. Partial EVPI values for PSE, QE, and OR (the parameters updated in scenarios 1, 2, and 3) are $6280, $2090, and $3890, respectively.
Estimated EVSI Values and CPU Run Times for the Three Case Study Scenarios
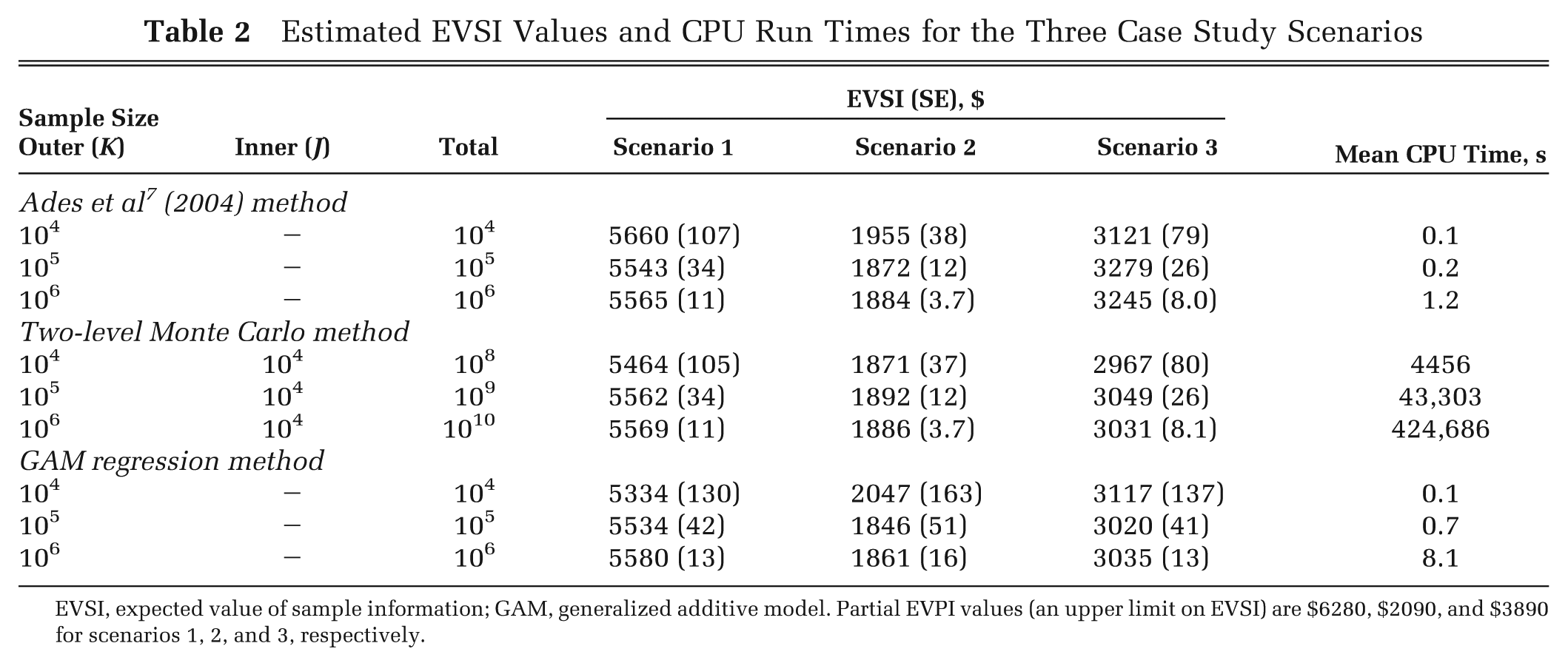
EVSI, expected value of sample information; GAM, generalized additive model. Partial EVPI values (an upper limit on EVSI) are $6280, $2090, and $3890 for scenarios 1, 2, and 3, respectively.
There is good agreement between all 3 methods in scenarios 1 and 2. In scenario 3, the most precise EVSI estimates obtained using the MCMC and GAM methods are in agreement with each other and are approximately $200 lower than the most precise estimate obtained using the Ades et al. 7 method.
The analytic method for computing the inner conditional expectation
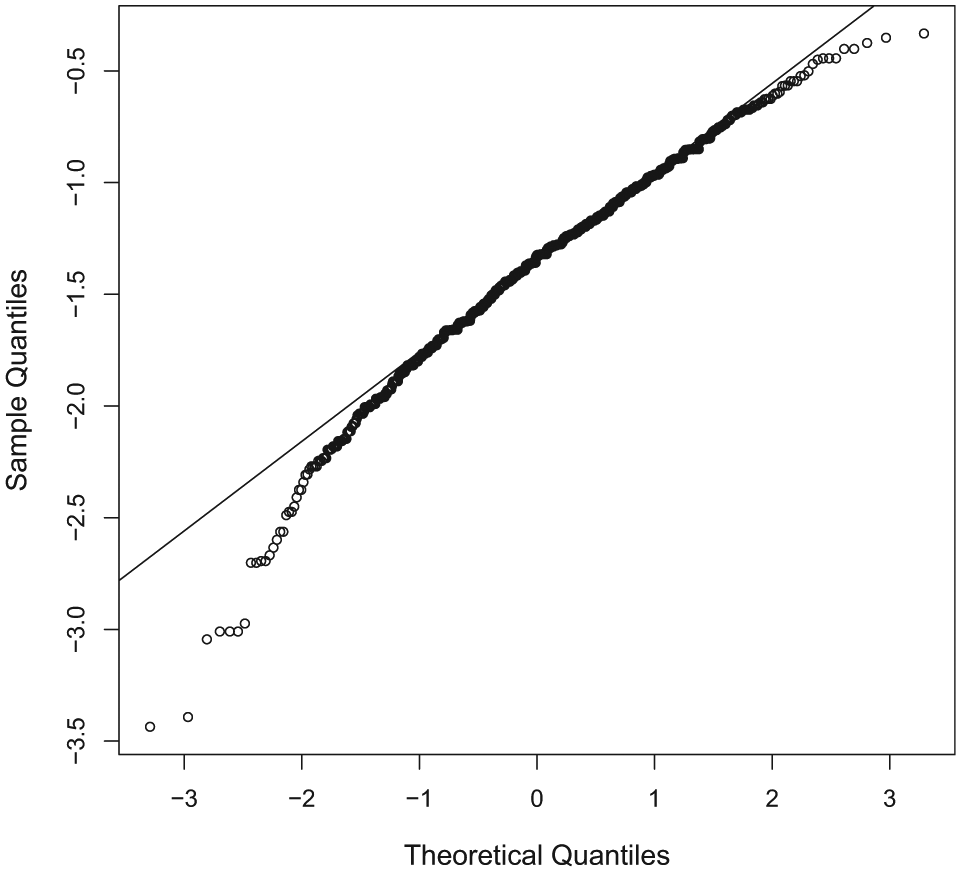
Normal QQ plot for samples of a study log odds ratio with PT = 0:044, PC = 0:15, and nT = nC = 200.
Precision and Computational Efficiency
For comparisons within each method, the Monte Carlo standard error scales in proportion to K−1/2 (as expected), and the computation time scales approximately in proportion to K.
For the same level of precision, the 2-level Monte Carlo method requires 104 (i.e., the inner loop size) times as many samples as does the Ades et al. 7 analytic method. This holds across all 3 scenarios. The 2-level method is roughly 5 orders of magnitude slower than the Ades et al. method for the same value of K, primarily due to the requirement for 104 model evaluations at each outer-loop run.
For scenario 1, the standard errors obtained using the GAM method are approximately 20% larger than those of the analytic method, given the same number of model runs. Thus, to achieve the same precision, the number of runs would need to be increased by approximately 1.22 = 1.44 times (this was confirmed empirically; results not shown). For scenario 2, the standard errors obtained using the GAM method are approximately 4 times larger than those of the analytic method, given the same number of model runs. Thus, to achieve the same precision, the number of runs would need to be increased by approximately 16 times. For scenario 3, the standard errors obtained using the GAM method are approximately 60% larger than those of the analytic method, given the same number of model runs. Here, to achieve the same precision, the number of runs would need to be increased by approximately 2.6 times.
The precision of the GAM estimate, as well as being related to the sample size, is related to the uncertainty in the model parameters that are not updated by the data. This uncertainty propagates through to the model output (the net benefit) in the PSA sample and causes the variability in the net benefit that is modeled by the error term in the regression. In the case of scenario 2, the GAM estimate requires relatively more samples (for some given precision) than does the GAM estimate for scenario 1 or 3. This suggests that in scenario 2, the uncertainty in the parameters not updated by data (i.e., PSE and log(OR)) is large. This is confirmed by the relatively high partial EVPI values for PSE and log(OR).
In terms of computational speed, the GAM method is roughly an order of magnitude slower than the analytic method but roughly 4 orders faster than the 2-level method.
Discussion
Our key idea is that instead of estimating, for each decision option, the posterior expected net benefits via a computationally burdensome repeated (inner-loop) Monte Carlo step, we estimate the functional relationship between the posterior expected net benefit and the simulated data via a nonparametric regression.
Strengths and Limitations
The value of the nonparametric regression method over the 2-level Monte Carlo approach is 2-fold: it is straightforward to implement, requiring less detailed mathematical thinking on the part of the analyst for any particular application, and is several orders of magnitude faster for any given precision. Due to the method’s ease of use and the fact that it only requires the PSA sample and not the model itself, we would suggest that the regression method is applicable in even the simplest of modeling contexts.
In common with other established methods for computing EVSI, we must be able to generate sample data sets, conditional on samples from the prior distribution of the model parameters. For complex study designs, this may not be straightforward. For our method, we must also be able to summarize the sampled data in either a scalar, or low-dimensional, summary statistic. Again, for complex study designs, this may not always be easy.
How This Fits with Existing Literature
One option for computing EVSI is to assume that the incremental net benefit is Normally distributed with parameters that are known functions of study sample size. Under this assumption, EVSI can be calculated using fast analytical methods. This “parametric” approach is most appropriate in settings in which cost-effectiveness analysis is undertaken alongside a single 2-arm randomized controlled trial (RCT). In this setting, the mean incremental net benefit is derived directly from individual-level costs and effects, and the central limit theorem can be used to justify the assumption of Normality. The method has been explored in theoretical investigations9–13 and applied in real clinical decision problems. 30 However, the approach is not straightforward for decision problems with more than 2 options and may not be appropriate when a more complex decision-analytic model has been used to estimate incremental net benefit. A nonlinear cost-effectiveness model with non-Normal input parameters may generate notably non-Normal incremental net benefits. It may be difficult to predict the relationship between the size of a proposed study that informs some particular subset of parameters and the net benefits of a range of competing decision options. Deriving the parameters of the Normal distribution(s) that the parametric approach requires may therefore be difficult.
The nonparametric regression approach that we propose has some similarities to the model emulation method proposed in Oakley, 31 and in one sense, the GAM model can be viewed as an emulator for the posterior expectation of the net benefit, conditional on the data. The important difference between the 2 approaches is that in Oakley, the net benefit function itself is emulated. Emulating the net benefit function allows for the rapid evaluation of a slow economic model, but it does not address the problem of how to sample from a difficult posterior distribution of the parameters conditional on the data. Our method also has some similarities to the spline-based approach for computing partial EVPI that has been proposed by Madan et al. 21 Here, a spline is used to approximate the conditional expectation of some predefined subfunction of the net benefit function, given some sampled value of a parameter of interest. Although the method by Madan et al is shown to perform well, it requires algebraic manipulation of the net benefit function to identify the appropriate subfunctions for the spline approximation. This may be difficult in complex models.
Implications for Practice and for Research
At present, commissioners and funders of research are not using EVSI methods as part of their day-to-day decision-making processes (although there are exceptions to this30,32,33). However, it is becoming more common for early economic evaluation models to be requested by research funders to establish the potential benefits of proposed new interventions. One barrier to implementation of EVSI at this stage has been the complexity of calculation, and we hope that our method can help to remove this barrier. We do recognize, though, that there are other important barriers to the widespread use of EVSI, including a lack of understanding of value of information methods, a mistrust of mathematical models, and a requirement for trialists to work within a frequentist hypothesis test-based framework.
Throughout the article, we have assumed that the decision maker’s utility is equal to net benefit and that the decision problem is to maximize net benefit over a set of discrete treatment options. This is the typical decision problem faced by government agencies such as the National Institute for Health and Care Excellence (NICE), but the type of decision problem faced by the pharmaceutical industry is somewhat different. Here, utility is profit, and under value-based pricing, the decision problem is to choose price to maximize profit, subject to the constraint that additional health benefits do not cost more than the funder’s willingness to pay. EVSI from an industry perspective has been explored by Willan 34 and by Willan and Eckermann, 35 as well as more recently within a value-based pricing context by Breeze and Brennan. 36 Our nonparametric regression method for computing EVSI will apply equally well in this context.
Further research could extend to testing the nonparametric regression method in other cost-effectiveness models, including Markov cohort models and more complex patient-level models. An important feature of our method is that all variation in the net benefit function that is not due to the data is taken up by the error term in the regression analysis and “averaged out.” Thus, any variation in the net benefit that arises due to poor convergence of a patient-level model is also averaged out in the regression. 24 This means that, to calculate EVSI for a patient-level model (in which patients do not interact), only a single patient needs to be “run” through the model at each evaluation of the PSA. We look forward to more research in this area.
Footnotes
Mark Strong is funded by a postdoctoral fellowship grant from the National Institute for Health Research (PDF-2012-05-258). The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report. This report is independent research supported by the National Institute for Health Research (PDF-2012-05-258). The views expressed in this publication are those of the author(s) and not necessarily those of the NHS, the National Institute for Health Research, or the Department of Health.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.