
Abstract
Machine Learning (ML) has been proposed for tissue fate prediction after acute ischemic stroke (AIS), with the aim to help treatment decision and patient management. We compared three different ML models to the clinical method based on diffusion-perfusion thresholding for the voxel-based prediction of final infarct, using a large MRI dataset obtained in a cohort of AIS patients prior to recanalization treatment. Baseline MRI (MRI0), including diffusion-weighted sequence (DWI) and Tmax maps from perfusion-weighted sequence, and 24-hr follow-up MRI (MRI24h) were retrospectively collected in consecutive 394 patients AIS patients (median age = 70 years; final infarct volume = 28mL). Manually segmented DWI24h lesion was considered the final infarct. Gradient Boosting, Random Forests and U-Net were trained using DWI, apparent diffusion coefficient (ADC) and Tmax maps on MRI0 as inputs to predict final infarct. Tissue outcome predictions were compared to final infarct using Dice score. Gradient Boosting had significantly better predictive performance (median [IQR] Dice Score as for median age, maybe you can replace the comma with an equal sign for consistency 0.53 [0.29–0.68]) than U-Net (0.48 [0.18–0.68]), Random Forests (0.51 [0.27–0.66]), and clinical thresholding method (0.45 [0.25–0.62]) (P < 0.001). In this benchmark of ML models for tissue outcome prediction in AIS, Gradient Boosting outperformed other ML models and clinical thresholding method and is thus promising for future decision-making.
Introduction
In the last two decades, multiple attempts have been made to predict the fate of the ischemic tissue resulting from acute occlusion of an intracranial artery. 1 Specifically, magnetic resonance (MR) parameters derived from diffusion-weighted imaging (DWI) and perfusion-weighted imaging (PWI) have been shown to correlate well with the voxel-wise defined final infarct. 2 Thus, the ischemic core and the at-risk hypoperfused tissue are mapped using the apparent diffusion coefficient (ADC) <620 × 10−6 mm2/s threshold and the timepoint of the maximum of the residue function (Tmax) >6 seconds threshold, respectively. 3 Thanks to commercially available automated software that use these thresholds, maps of the at-risk tissue can be quickly generated and are now widely used to select optimal candidates for reperfusion therapy. 4 However, such uniform thresholding approach has several shortcomings. First, the above fixed thresholds remain debated and alternative thresholds have been proposed for both the ADC5–7 and Tmax.8–11 Second, these thresholds rely on rather simplistic physiological assumptions and do not encompass the broad information range obtainable from DWI and PWI that may hold further clues to tissue fate. 12 Last, spatial information is neglected, i.e., the clinical thresholding method essentially considers all voxels in the same way although gray and white matter have different sensitivity to prolonged hypoperfusion, 13 and each voxel is analyzed independently of regional information. One of the challenges with voxel-based prediction is that underlying tissue characteristics likely have an influence on the ultimate fate of the ischemic tissue. 14
Machine Learning (ML) is a class of computer algorithms that automatically learn to classify observations from data of a training set. Several ML framework have been proposed for tissue outcome prediction to find more flexible decision approaches than hard thresholding rules such as Random Forests classifiers, 15 , 16 or Gradient Boosting model. 17 These models combine image features in nonlinear ways to obtain more flexible decision boundaries. Another type of ML approach, termed Deep Learning, does not require a priori assumptions of what image features are important. Image features are automatically identified and encoded in the network of hidden layers. 14 U-Net, a class of Deep Learning method, have been proposed for tissue outcome predictions. 18 , 19 It enjoys the prestige of recent achievements in the Ischemic Stroke Lesion Segmentation 2017 challenges, 20 in which different Deep Learning architectures were compared for lesion outcome prediction, and which was won by a multiscale U-Net.
The main benefit expected from Deep Learning models for segmentation tasks, such as U-Nets, is their ability to consider global image context for image features extraction. By contrast, other ML models, such as Random Forests or Gradient Boosting classifiers, only incorporate previously defined information and commonly do not consider regional information for predicting the fate of a given voxel. To overcome this limitation, voxel patches surrounding each predicted voxel can be integrated as additional input dimensions. 21 However, the voxel patch size is limited by the computational cost that will markedly increase with patch size. Besides the computational cost entailed, the comparison between these different predictive models is complicated because of the various ground truths used in previous studies (i.e., early 19 or delayed 1 , 15 , 18 follow-up imaging), and the various metrics used for model evaluation (i.e., area under the curve [AUC], 1 , 15 , 18 infarct volume, 15 , 18 Dice score 15 or accuracy 19 ).
Here, we aim to compare for the first time the accuracy of three ML approaches (namely Random Forests, Gradient Boosting and U-Net) to that of the clinical diffusion-perfusion thresholding paradigm for the prediction of final infarct based on a large pretreatment MR dataset of AIS patients. In order to compare the predictions of final infarct on a voxel basis, we used several of the most popular metrics, including Dice Score, AUC and Absolute Volume Error.
Material and methods
Patients selection
We carried out a retrospective single-center study on consecutive AIS patients who received reperfusion therapy between 2002 and 2019. Inclusion criteria were: i) baseline stroke MRI including DWI and PWI, obtained before reperfusion therapy (MRI0); and ii) follow-up MRI scheduled around 24 hrs later including DWI (MRI24h). As per French recommendations, 22 MRI has been implemented in our institution since 2001 as first line diagnostic work-up in candidates to reperfusion, while follow-up MRI is systematically scheduled around 24 hrs after treatment.
Both MRI0 and MRI24h include DWI with identical acquisition parameters. All MRIs were acquired on a 1.5-Tesla unit (GE Healthcare, Madison, Wis), using gradient strength of 33 mT/m and an eight-channel head coil. For both MRI0 and MRI24h, echo-planar DWI sequences were acquired with 128 × 128 matrix, 24 cm field-of-view, 6-mm thick slices, with b = 0 s/mm2 and b = 1000 s/mm2 with gradients applied in 3 orthogonal directions, TE = 84 ms, TR = 6675ms, and parallel imaging with acceleration factor = 2, no partial Fourier. ADC maps were computed based on DWI acquisition. On MRI0, PWI was acquired after injection of a contrast bolus of gadolinium-based contrast agent using an echo-planar T2* sequence with a 96 × 64 matrix, 24 cm field-of-view, 6-mm thick slices, 25 temporal phases, TE = 60 ms, TR = 2000 ms, flip angle = 90°, no acceleration factor.
Patient consent
In accordance with French legislation, patients were informed of their participation in the study, and offered the possibility to refrain from the use of their data. A commitment to compliance (Reference Methodology MR-004 no. 4708101219) was filed to the French national information science and liberties commission (CNIL), in full respect of the General Data Protection Regulation. As the present study only involved retrospective analysis of anonymized data collected as part of routine care, formal approval by an Ethics Committee was not required.
Dataset preprocessing and image analysis
All MRI data were anonymized and exported from the Picture Archiving and Communication System. DWI24h sequences were registered onto DWI0, and DWI0 and PWI were registered onto a reference brain scan in MNI space using 12-parameters affine registration using FSL FLIRT, 23 , 24 because affine MNI registration 17 and symmetry features 15 improve the quality of prediction by providing useful context on voxel location. Registration was conducted using global optimization 23 with trilinear interpolation, and correlation ratio as similarity metric. Registration results were overlayed onto the MNI mask and manually checked by an experienced neuroradiologist. Whenever needed, the registration procedure was repeated using mutual information metric. Regarding the registration of DWI24h, a concatenation of the two computed registration matrices was used to prevent doubling the interpolation errors. A brain mask was computed using Otsu-based thresholding on DWI0 in order to select in-brain voxels. Image intensity normalization was then applied for DWI0 and DWI24h on each volume by mean centering and standard deviation scaling, using the mean signal and standard deviation of in-brain voxels contralateral to the ischemic lesion. Perfusion maps were computed using Olea Sphere® (Olea Medical, La Ciotat, France) based on oSVD deconvolution method with an oscillation index threshold of 0.02375. 25 Arterial input function was automatically selected using an algorithm based on a clustering method classifying curves using their area under the curve, their roughness, and their first moment in order to distinguish arterial from tissue signal. 26
ML models inputs and ground truth
Model inputs included DWI, ADC and Tmax maps obtained from MRI0 (Tmax-only models). We primarily focused on Tmax as the sole surrogate for perfusion imaging because it correlates with clinical 27 and tissue outcome, 18 and is widely used in clinical trials. 4 In order to test the added value of embedding other PWI maps, we also trained Extended-Perfusion models using Mean Transit Time (MTT), Cerebral Blood Flow (CBF) and Cerebral Blood Volume (CBV) as additional inputs. The ADC and PWI maps were not thresholded for ML model training. On MRI24h, the final infarct was defined as the hyperintense lesion on DWI24h, and was manually segmented and considered ground truth for our study. 28 Given the high reproducibility of stroke volume measurements on DWI, 29 segmentations were done by the same experienced neuro-radiologist, blinded to all clinical information.
Clinical thresholding model
As done in clinical care, core and tissue at risk were segmented from pretreatment DWI and PWI, respectively. An ADC threshold <620 × 10−6 mm2/s and Tmax > 6 sec were used to segment the core and the hypoperfused tissue-at-risk from MRI0, respectively. 4 Regions of interest were manually segmented using MANGO software version 4.0.1 using a combination of thresholding and manual drawing tool for suppression of artifacts. 30
The union of core and hypoperfused tissue-at-risk regions of interest on MRI0, was considered as the predicted final infarct for the clinical thresholding model, as previously proposed by others. 31 These segmentations were not used for ML models training (see below).
ML models
Three different supervised ML models were tested: Random Forests and Gradient Boosting (patch-based models), and U-Net (Deep-Learning model). The models were trained to predict final infarct based on model inputs. In order to avoid the arbitrariness of splitting the population into a train and test set, 32 the training was cross-validated with 10 folds, a reasonable compromise between computation time and bias reduction. Cross-validation consisted in equally partitioning the patients in 10 folds. For each fold, the model was trained on 81% patients (training set), hyperparameters were adjusted on 9% of the patients (validation set) and metrics were evaluated on the 10% remaining patients (test set). The cross-validation splits were identical between models in order to ensure comparability.
The U-Net model was a fully convolutional network with 5 contracting blocks and 5 expanding blocks linked together by skip connections and ended with a sigmoid activation layer. It operated slice-by-slice with additional input from adjacent slices (2.5 dimensions). For each given slice, the U-Net provides a parametric output, which can be interpreted as a voxel-wise probability map of infarction on DWI24h. The training process consisted in learning model weights by comparing the output of the model to the segmented brain infarct maps on DWI24h. Loss was evaluated on the validation dataset, and the training was early stopped whenever validation loss increased in order to avoid model overfitting. 33 The architecture of the U-Net model is detailed in online-only Data Supplement and will be published as open source software on https://github.com/NeuroSainteAnne/StrokePrediction.
Patch-based models (Gradient Boosting and Random Forests) combined features from each MRI0 voxel to predict the final infarct on MRI24h. The following features were computed for each voxel and each input volume: i) normalized signal intensity issued from 5 × 5 × 3 patches on each input sequence (75 features for each input volume); ii) normalized signal intensity issued from contralateral voxel patches (75 features for each input volume) selected by flipping x-coordinates of ipsilateral patches; iii) voxel coordinates in MNI space. The total feature cardinality was 453. After applying a subsampling factor of 5% in-brain voxels in train dataset, Gradient Boosting and Random Forests were trained to predict DWI24h segmentation based on these features. Details about models implementation are given in online-only Data Supplement.
Probability maps issued by U-Net, Gradient Boosting and Random Forests were collapsed into a binary outcome prediction map using a 0.5 threshold.
Study endpoints
The main metric used for model evaluation was the patient-level Dice score. The Dice score reflects the amount of overlap between the prediction (i.e., the tissue outcome predicted by ML or clinical thresholding models) and the ground-truth (i.e., the segmented final infarct); it ranges between 0 and 1, with higher figures representing more overlap. It provides information not only on the predicted volume accuracy but also on its location. Other metrics were evaluated to keep comparability with previous studies: 1/Area Under the Curve (AUC); 2/AUC weighted on hypoperfused areas according to Jonsdottir et al. 1 (AUC0); and 3/Absolute Volume Estimation Error between predicted and ground-truth segmentation. Patient age, National Institutes of Health Stroke Scale (NIHSS) at admission, type of revascularization therapy (Intravenous Thrombolysis [IVT] and/or Mechanical Thrombectomy [MT]) were recorded. Training time for each model and inference time for each patient were recorded.
Reperfusion status
In the subgroup of patients who underwent MT, we analyzed the effect of adding reperfusion status onto model performance. Reperfusion status was evaluated on angiograms acquired immediately after MT using the modified Thrombolysis In Cerebral Infarction (mTICI) Score, 34 with mTICI 2 b-3 considered successful reperfusion.
For the clinical thresholding model, the final predicted infarct was defined as the combination of infarct core and hypoperfused volumes in patients with unsuccessful reperfusion, given that the lesion typically expands to the boundaries of the initial hypoperfused region. In patients with successful reperfusion, the final predicted infarct was defined as infarct core only, given that most of the initial hypoperfused region should be salvaged. 31
For Gradient Boosting and Random Forests, reperfusion status as a binary variable was concatenated along with the other features. For U-Net, reperfusion status variable was tiled on a 256 × 256 map and concatenated along with the other inputs. Each model was trained in two different setups: with or without adding the Reperfusion status and the performance was assessed by 10-fold cross-validation.
Statistical analysis
The patient-level metrics were compared across models using a pairwise Wilcoxon test with p-value adjusted for multiple comparisons with Holm method. Given that large infarct volumes may bias prediction performance, 31 we also plotted predicted and true infarct volumes using a Bland-Altman graph and analyzed predictions using two predefined final infarct volume cut-points (50 mL, 100 mL). 35 , 36 Tmax-only models and Extended-Perfusion models were compared using pairwise Wilcoxon test. In the subgroup of patients who underwent MT, Dice scores issued from models with and without taking into account reperfusion status were compared with pairwise Wilcoxon test.
Patient-wise results are expressed as median and Interquartile Range (IQR) or mean ± standard deviation (SD) if needed for comparison with literature. Model overfitting was evaluated by comparing Dice score in the test and training sets. Statistical analyses were computed using R version 3.5.1 with ggplot2 37 and BlandAltmanLeh 38 packages.
Results
Population
During the study period, of 788 AIS patients who received reperfusion therapy and in whom both MRI0 and MRI24h were performed, 394 had complete datasets including DWI0, PWI and DWI24h. Patients and stroke characteristics at admission and ≈24 h are summarized in Table 1.
Clinical and radiological characteristics.

Note: Values shown are numbers (percentages), unless stated otherwise.
aIn patients with available cause in medical file (n = 320).
bIn patients with known stroke onset time (n = 368).
cIn patients who received IVT (n = 335).
dIn patients who underwent MT (n = 87).
eIn patients with known modified Rankin Scale score (n = 355).
IQR: interquartile range; IVT: intravenous thrombolysis; MT: mechanical thrombectomy; NIHSS: National Institutes of Health Stroke Scale; DWI: diffusion weighted imaging.
Final infarct prediction performance
Gradient Boosting had significantly better Dice score as compared to all other models (P < 0.001), with a median score of 0.53 [IQR 0.29–0.68] (Table 2). Dice scores significantly differed among models, except between U-Net and Random Forests and between U-Net and clinical thresholding model (P = 0.13) (Figure 1). Using the AUC, AUC0 and Mean Absolute Error, Gradient Boosting and U-Net performed equally well and outperformed Random Forests and clinical thresholding model (P < 0.001). There was no major overfitting for any of the studied models, as shown by the differences between Dice scores obtained in the training and test sets (Table 3). Dice scores were lower for volumes <50mL (0.44 [0.18–0.61] and 0.33 [0.03–0.58] for Gradient Boosting and U-Net, respectively; n = 253) than for volumes ≥100mL (0.70 [0.58–0.80] and 0.74 [0.60–0.80], respectively; n = 83). Adding other PWI maps as inputs did not modify model comparisons and none of the Extended-Perfusion models yielded significantly higher Dice scores than Tmax-only models (p > 0.1) (Table 3).
Final infarct prediction performance for each model.

IQR: interquartile range; AUC: area under curve; SD: standard deviation.
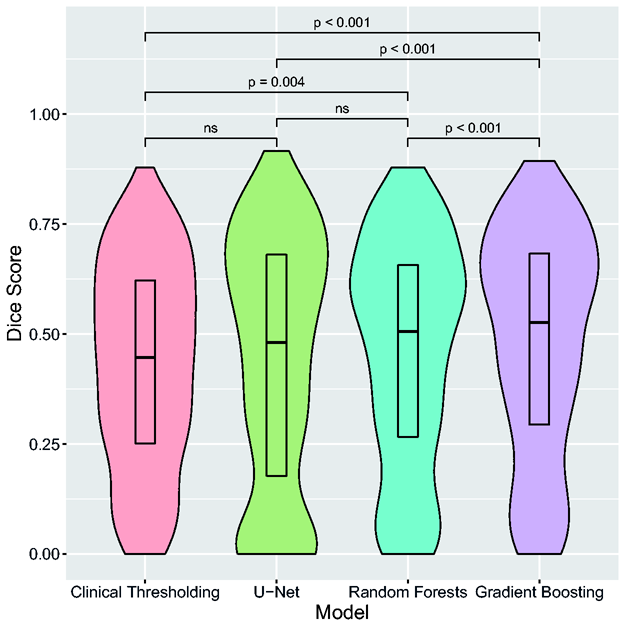
Final infarct volume prediction performance for each model.
Comparison of dice scores between training and test sets.
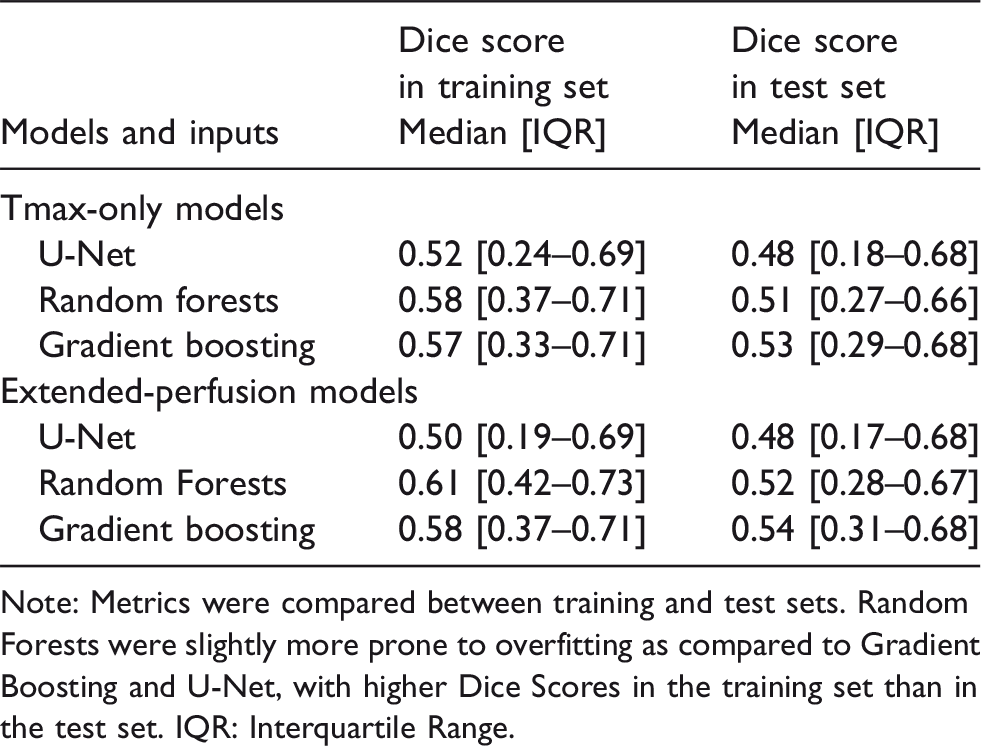
Note: Metrics were compared between training and test sets. Random Forests were slightly more prone to overfitting as compared to Gradient Boosting and U-Net, with higher Dice Scores in the training set than in the test set. IQR: Interquartile Range.
Reperfusion status
In the subgroup of patients treated with MT in which reperfusion data were available (n = 87), adding the reperfusion status as input significantly improved the performance of all models: Gradient Boosting (median Dice score 0.55 [IQR 0.28–0.64] vs. 0.47 [0.28–0.63], P = 0.008), Random Forests (0.48 [0.25–0.61] vs. 0.46 [0.23–0.61], P < 0.001), U-Net (0.46 [0.29-0.63] vs. 0.38 [0.12–0.55], P = 0.038), and clinical thresholding (0.49 [0.31–0.63] vs. 0.39 [0.22-0.59], P = 0.002).
Qualitative and quantitative assessment of final infarct volume
Illustrative examples of prediction maps are presented in Figure 2. By simple visual inspection, Random Forests and Gradient boosting yielded sharper and better contrasted but noisier prediction maps than U-Net. Bland-Altman analysis (illustrated only for Gradient Boosting and U-Net in Figure 3) demonstrated an underestimation of predicted volumes (mean difference: −18 mL [limits of agreement: −107-70mL] for Gradient Boosting and −14mL [−101-74mL] for U-Net), which was more prominent for larger volumes.
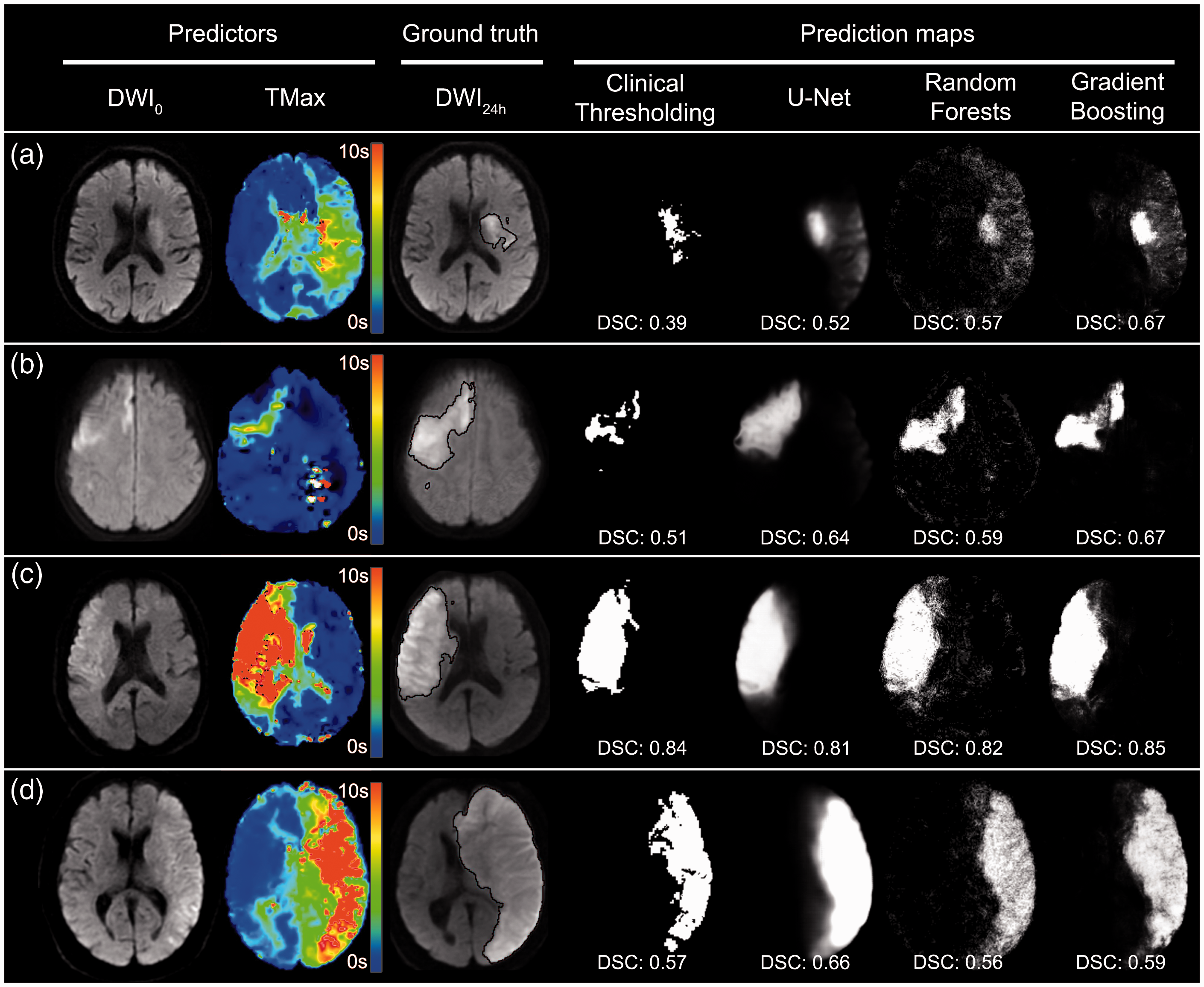
Examples of prediction maps with different models.
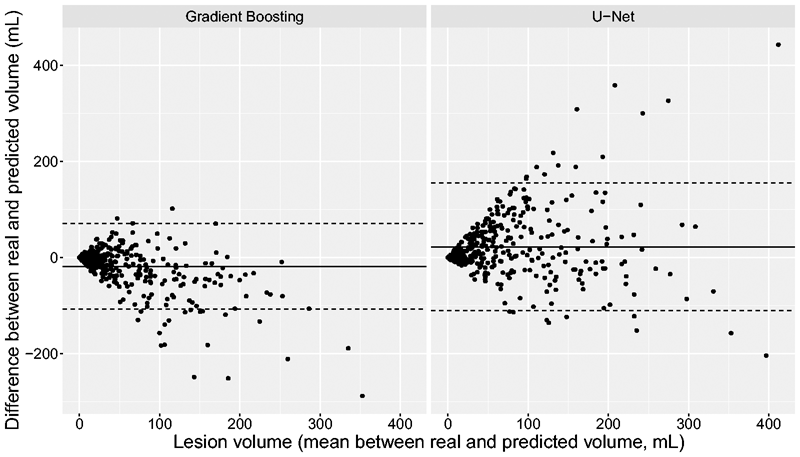
Bland-Altman plots for the Gradient Boosting and U-Net models.
Computation time
Training time was longer for U-Net (median duration per cross-validation fold: 160 minutes) than for Gradient Boosting (89 minutes) and Random Forests (19 minutes). Inference times for each patient were shorter for U-Net (median duration: 0.3 seconds) than for Gradient Boosting (21 seconds) and Random Forests (2 seconds).
Discussion
In this study, the three most popular ML segmentation models and the clinical thresholding method were compared for their performances in predicting final infarct, using a large single MRI dataset of AIS patients treated with reperfusion therapies. We found that Gradient Boosting model outperformed all other tested models including clinical thresholding method. Thus, Gradient Boosting produced better spatially defined and contrasted prediction maps, and accordingly would seem most suitable for clinical application. Of note, Gradient Boosting and U-Net yielded similar results with respect to absolute volume and AUC. Finally, all models tended to underestimate final infarct volume, especially for large infarcts.
Metrics analysis
Our results highlight the limitations of standard metrics for the evaluation of predictive models. The Dice score, which measures the overlap between predicted and ground-truth volumes, is theoretically the best metric to assess accuracy of both extent and spatial location of infarct prediction, 39 which are important determinants of stroke severity and long-term functional outcome. 40 Models with highest Dice score would thus best predict the fate of clinically relevant regions, although this metric in inherently unstable for small-size infarcts, as confirmed in our study.
Alternatively, AUC, although widely used, suffers from a large imbalance between (far more prevalent) healthy brain tissue and infarcted tissue. Hence, this metric carries limited information as all models reach very high AUC. The AUC0, weighted on hypoperfused areas, is better adapted for small volumes and has the advantage of being threshold independent. 1 As for the AUC, it was markedly skewed to high values (between 0.89 and 0.98 across our models) and may as such afford lesser discrimination for model selection than Dice scores. Finally, Mean Absolute Error has the advantages of i) straightforward clinical significance given that infarct volume is known to correlate with clinical scores and outcome, 41 and ii) invariance to spatial registration errors, but does not take into account spatial location errors.
Model comparisons
Overall, we obtained higher Dice scores than previously reported for both Random Forests 15 or Gradient Boosting. 17 This may be due to the fact that our models were trained and tested on large datasets with a wide range of infarct volumes, including larger ones (mean 60 mL ± 75 in our study vs 28 mL ± 79 in Grosser et al., 17 and median 28 mL in our study vs. 7.36 mL in McKinley et al. 15 ). The overlap between predicted and real volume is indeed expected to increase with larger infarcts, irrespective of the model, as also shown here.
We found that Gradient Boosting outperformed Random Forests, in line with a recent study on 99 AIS patients. 17 In this latter study, the difference in Dice scores between Gradient Boosting and Random Forests was comparable to ours (0.39 and 0.37 vs 0.53 and 0.51, respectively). This rather small gain in performance has to be put in balance with the additional computational cost, which in our study was 5 times longer with Gradient Boosting.
As compared with U-Net, Gradient Boosting had higher Dice score. This superiority might be due to differences in receptive fields between models. Patch-based models, such as Gradient boosting used here, have small receptive fields (patch: 5 × 5 voxels) as compared to U-Net (here, 32 × 32 voxels). Larger receptive fields should theoretically capture regional perfusion defects at a larger scale, and this may explain the better performance of U-Net for large infarct volumes. However, convolutional architectures use translation equivariance (i.e., the fact that the phenomenon of interest is equally likely to occur in all part of the image) as an inductive bias, which may be inadequate for AIS where lesions are not randomly localized but constrained by arterial territories. Moreover, U-Net prediction method did not outperform clinical thresholding model in our study. Although Deep Learning methods have been previously proposed in literature for tissue outcome prediction, 18 , 19 , 31 it seems to outperform standard clinical thresholding methods in terms of Dice Score only in a patients with major reperfusion. 31 It is however likely that the performance of Deep Learning methods, such as U-Net, being data-greedy, will continue to improve with access to very large amount of data whereas other ML approaches such as Gradient Boosting and Random Forests will tend to plateau despite access to the same amount of data. 14 Future much larger multicentric datasets may thus be necessary to demonstrate the superiority of Deep Learning over other techniques. Beside its accuracy, the critical point for a clinically compatible software in AIS patients is the speed necessary to obtain prediction maps. Owing to their fast inference once trained, as shown in our study, Deep Learning models that do not require patch segmentation might better translate into clinically usable software.
The best performing models proposed in literature are presented in Table 4. Of note, all models outperformed linear models whenever compared. 17 , 18 , 42 , 43 This was not unexpected since linear models combine linear transformations of voxel intensities and have limited expressive power. Accordingly, we chose to omit the comparison with linear models in our study.
Comparison with current literature.
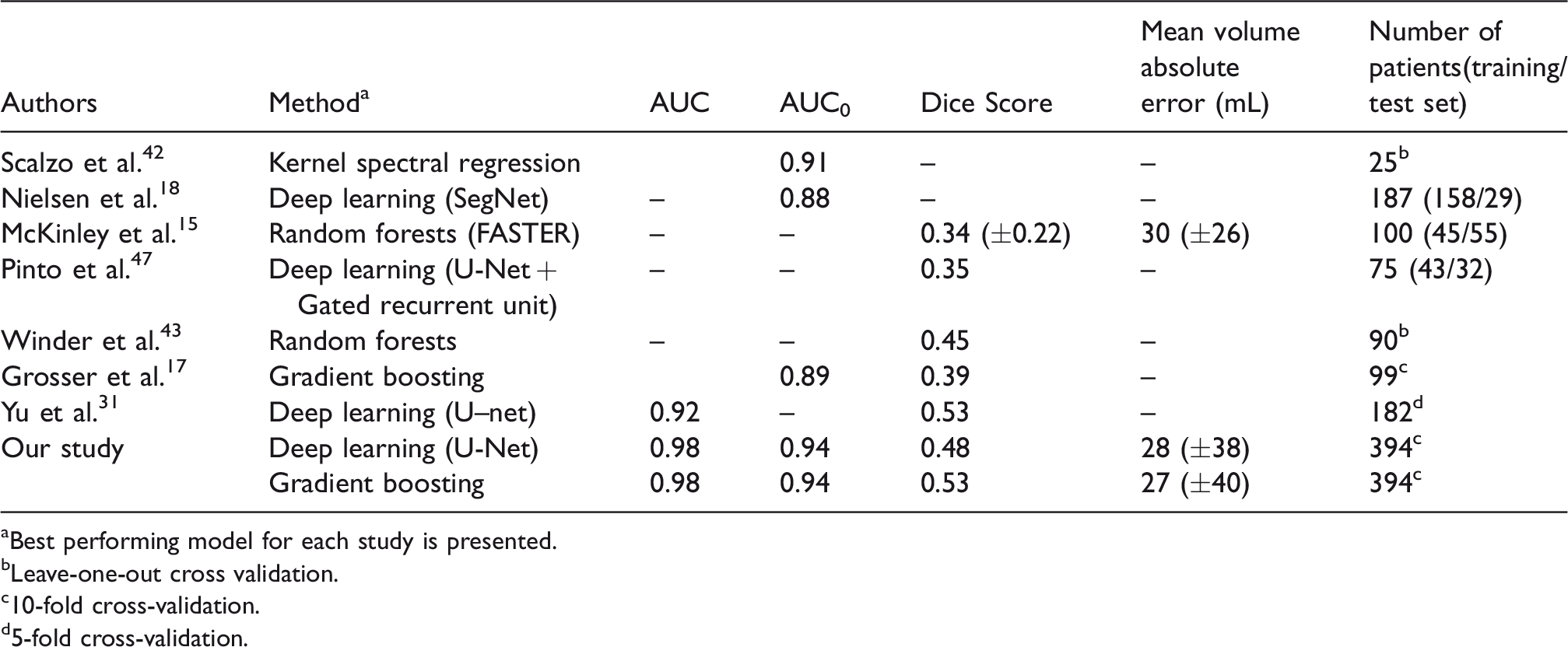
aBest performing model for each study is presented.
bLeave-one-out cross validation.
c10-fold cross-validation.
d5-fold cross-validation.
A recent large study reported better performance of a U-Net model than found in our study (Dice score: 0.53 vs 0.48, respectively). 31 This could be explained by the use of a U-Net model with attention-gating units, which may improve U-Net performance. More likely, higher Dice score in this study are linked to larger final infarcts (median [IQR] 54 mL [16-117] vs. 28 mL [8-88] here) and more severe strokes that were imaged and treated later than in our study. Nielsen et al. 18 have investigated another deep convolutional network (SegNet) for infarct prediction but obtained lower AUC0 values (0.88 ± 0.12 vs. 0.94 for U-Net in our study). The ISLES 2016 and 2017 challenges compared many algorithms for final infarct prediction based on multimodal MRI in smaller populations (75 patients). 20 The best performing Deep Learning model yielded a lower Dice Score (0.32) than all the models tested in our study. However, these comparisons should be interpreted with caution given that population characteristics and sample size differ between studies. The raw metrics indeed appear highly dependent on the population studied, which emphasizes the importance of comparing concurrent models in the same sample. Although it is beyond the scope of the study to compare all existing models, we performed post-hoc supplementary analyses by comparing the performance of our U-Net model to the deep convolutional network proposed by Nielsen et al. 18 on our data set. Performances were comparable, with similar median Dice scores (0.48 [0.19-0.66] for the network proposed by Nielsen et al vs. 0.48 [0.18-0.68] for our U-Net, P = 0.07). Other Deep Learning models, such as X-Net 44 or multi-path U-Net 45 have been proposed for acute AIS segmentation and may also be tested for prediction. Taking into account additional information regarding stroke texture might also be valuable. 15 Furthermore, combining the results of different models with ensemble methods might boost the performances of individual models, as suggested in the ISLES 2017 challenge. 20
Patient heterogeneity and model interpretation
All ML models tested in this study underestimated true final infarct volume. This underestimation was more prominent for large infarcts, in line with a previous study of infarcts imaged in the subacute stage (3–7 days). 31 Conversely, volume overestimations were observed in studies using ground truth infarct volume at later time points (1 month 18 and 3 months 15 ). These apparent discrepancies are likely explained by the natural evolution of necrotic lesions, which are characterized by peripheral vasogenic edema appearing ∼24hrs after stroke onset and peaking during the first week, followed by lesion shrinkage toward the chronic stage (1-3 months). Accordingly, volume underestimation observed in studies where ground truth is defined soon after treatment, including ours, likely reflects failure to capture vasogenic edema, 31 while volume overestimation in studies with delayed ground truth reflects failure to capture lesion shrinkage. 15 , 18
Reperfusion effect
Successful reperfusion is associated with limited infarct growth and better functional outcome. 46 As expected, integrating reperfusion status in our models improved their performance. This approach has been proposed in previous studies 15 , 47 using different frameworks. In the FASTER algorithm, McKinley et al. trained two separate models for reperfused and non-reperfused subjects. 15 Pinto et al. integrated reperfusion status into their neural network using gated-recurrent unit. 47 We found a similar gain in performance (Dice score increment +0.07 here with Gradient boosting model vs. +0.05 in Pinto et al. 47 ) although we chose to concatenate reperfusion status with imaging data to ensure a similar architecture of all models for the sake of comparability. These results emphasize the potential clinical application of such prediction models. Indeed, for a given patient, creating differential prediction maps with and without reperfusion may have a direct application in treatment decision. Moreover, incorporation of other input parameters such as age, admission NIHSS, and glycaemia may improve prediction accuracy, although careful variable selection would be needed to limit model overfitting.
Limitations
Our study has limitations. First, we mainly focused on Tmax because of its known correlation with clinical outcome 27 and final infarct volume. 48 Moreover, it was the predominant contributing feature among other perfusion maps in a large ML study predicting tissue outcome in AIS. 15 We however checked that Extended-Perfusion models did not outperform Tmax-only based models. One might consider other inputs, such as the CBF/Tmax ratio 49 which may be a marker of collateral status. An alternative approach entails the use of the source PWI images 12 instead of the parametric maps, which avoids the use of proprietary deconvolution software and integrates all information contained in the PWI dataset without the need for preliminary perfusion modeling. Second, our clinical thresholding model used predefined ADC and Tmax thresholds as done previously, 31 although they are likely imperfect.5–11 However, they represent the state-of-the-art for estimation of ischemic core and at-risk tissue, and are now used routinely in the clinical setting to select patient for MT beyond 6 hrs after stroke onset. 4 Third, final infarct was defined on 24 hr follow-up MRI, an earlier time point than that used in previous studies. 15 , 18 This approach was driven by consensus recommendations 28 and has the advantages of allowing more reliable segmentation thanks to the high natural contrast of infarcted tissue on DWI, of minimizing the risk of final infarct overestimation due to vasogenic edema that peaks around day 3-5 28 and of reducing the odds of both early stroke recurrence and drop-outs. Fourth, we limited our analysis to the effect of reperfusion status in the subgroup of patients who underwent MT, since documentable early reperfusion status was not available in patients treated with IVT only. Fifth, binary outcome prediction maps were generated using an arbitrary fixed threshold (0.5) applied on ML probability maps. However, Dice scores were not significantly improved using a threshold optimization method (see Online-Only Data Supplement, Supplemental Table 1). Sixth, we used a cross-validation scheme, which increases the statistical power but reduces the interpretability of trained models. In order to check the robustness of our findings, we conducted an additional analysis using a single train/validation/test split with a larger test set (25%). Results were similar in terms of Dice scores (see Online-Only Data Supplement, Supplemental Table 2) but statistical power was insufficient to conclude regarding differences between ML models (e.g. 0.54 for Gradient Boosting vs. 0.52 for U-Net, P = 0.06) (see Online-Only Data Supplement, Supplemental Figure 1). Finally, this was a single-center study, and all patients had a standardized stroke MR protocol. While this increases data homogeneity and hence model performance, the trained models may not perform equally well on a more heterogeneous multi-center dataset.
Conclusion
The present work reports a benchmark of ML models for tissue outcome prediction in acute stroke using a large dataset. All models outperformed the thresholding PWI-DWI methods used in clinical practice. Among the three ML models, Gradient Boosting appeared particularly relevant for predicting tissue fate after AIS, followed closely by Random Forests and U-Net. These novel approaches appear promising for predicting tissue outcome and hence decision-making.
Supplemental Material
sj-pdf-1-jcb-10.1177_0271678X211024371 - Supplemental material for Tissue outcome prediction in hyperacute ischemic stroke: Comparison of machine learning models
Supplemental material, sj-pdf-1-jcb-10.1177_0271678X211024371 for Tissue outcome prediction in hyperacute ischemic stroke: Comparison of machine learning models by Joseph Benzakoun, Sylvain Charron, Guillaume Turc, Wagih Ben Hassen, Laurence Legrand, Grégoire Boulouis, Olivier Naggara, Jean-Claude Baron, Bertrand Thirion and Catherine Oppenheim in Journal of Cerebral Blood Flow & Metabolism
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Acknowledgements
Not applicable.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Authors’ contributions
JB made a substantial contribution to the concept and design of the study, acquisition and analysis of the data, drafted the article and approved the version to be published
WBH made a substantial contribution to the concept of the study and acquisition of data, revised critically the article and approved the version to be published
SC, GT, LL, GB and ON made a substantial contribution to the concept and design of the study, revised critically the article and approved the version to be published
JCB made a substantial contribution to the concept of the study and data analysis, revised critically the article and approved the version to be published
BT and CO made a substantial contribution to the concept and design of the study, analysis and interpretation of data, revised critically the article and approved the version to be published
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.