
Abstract
Whenever an experiment yields a statistically significant outcome you should ask yourself: To what extent can I trust this result? This is especially important for pre-clinical drug studies because of the frequent failures of phase III clinical trials of neurological diseases, which has put the reliability of pre-clinical research into question. Two important factors, the pre-study likelihood of treatment benefit, and statistical power, affects the reliability of the result in a quantifiable way. This can be used to assess to what extent the result of a study can be trusted (discovery reliability), and to guide the design of pre-clinical research.
A statistically significant result from an experiment, a discovery, can be either a true discovery (TD) or a false discovery (FD), which means that the reliability of the discovery has to be considered when interpreting the result. Both the prior likelihood that the treatment is beneficial and the statistical power of the experiment affects reliability, but it is not immediately apparent how.
1
The reasoning becomes more concrete by considering the testing of compounds in a library,2,3 for example one that contains 100,000 compounds, and that 100 of those are beneficial treatments (BT), and the rest do not affect outcome (inert treatments, IT). The expected ratio between FDs and TDs, the false discovery ratio (FDR), can then be calculated to aid in the interpretation of the result.
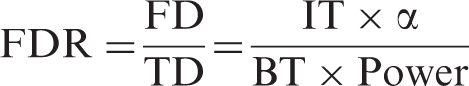
If the experiments in the first example above is run with α = 0.05 and power = 80%, the FDR would be about 62 to 1, which means that any statistically significant results obtained are highly likely to be false. A contrasting example is a series of 100 carefully selected compounds, which contains 50 BT. This results in an expected FDR of about 1 to 16, and you could be reasonably confident that statistically significant results are caused by actual treatment benefits. An experimental series can, of course, have any combination of statistical power and ratio of beneficial to inert treatments, and how this affects the FDR is illustrated in Figure 1(a).
The false discovery ratio is affected by both the power and the beneficial treatment ratio. Note that underpowered studies with unlikely hypothesis are highly likely to generate false discoveries (a). The reliability of a discovery is affected by both the statistical power of the study and the prior likelihood that the treatment is beneficial (b). Alpha is set to 0.05 in both graphs.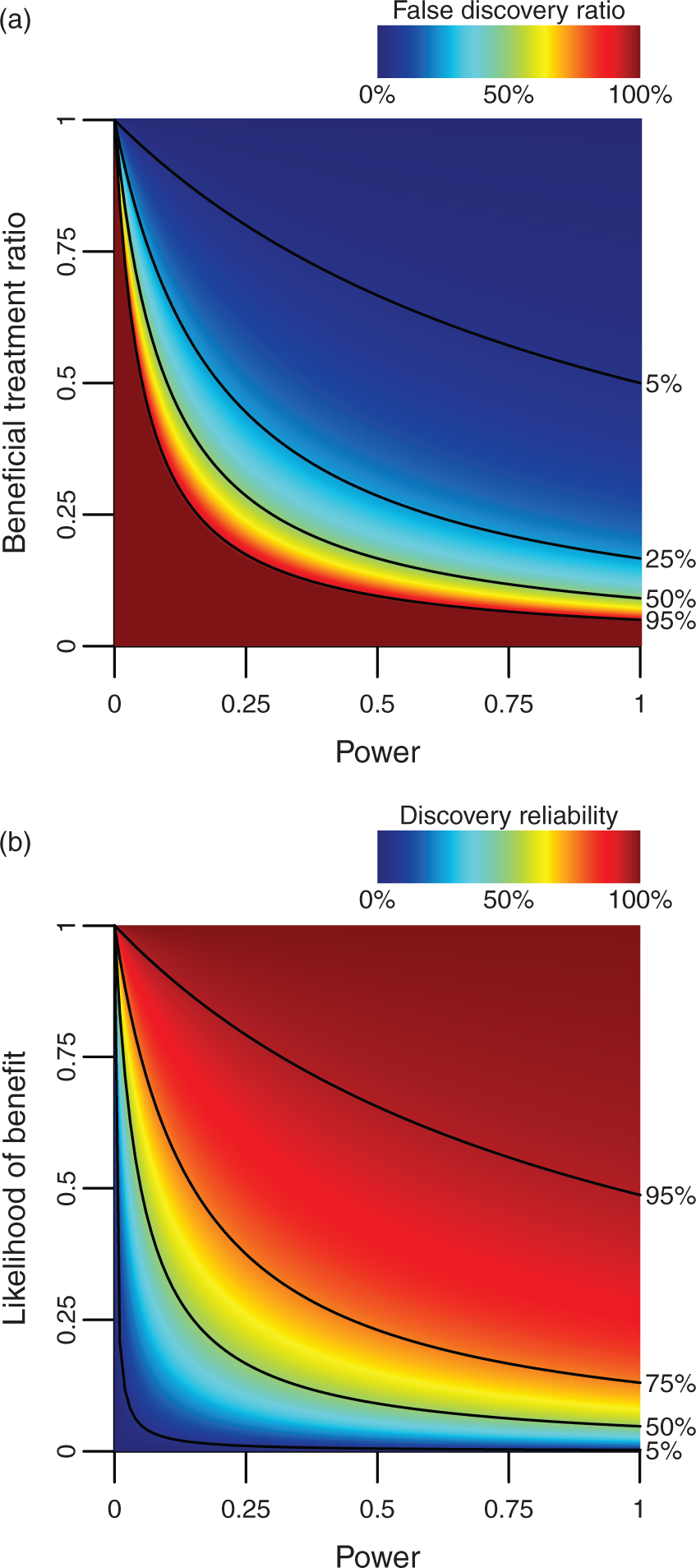
Having to test thousands of treatments before contemplating the results is, however, not very efficient, and it is clearly desirable to extend this concept to the testing of a single treatment. This can be done by substituting the fraction of BT for the likelihood that a particular treatment is beneficial. When randomly selecting compounds from a large library, this would be very low, in the example above, it is 0.1%. Testing carefully selected compounds would reasonably result in a higher likelihood of benefit (LOB), in the example above it is 50%. Knowing the LOB enables calculation of both the chance of a true discovery (CTD) and the risk for a false discovery (RFD). This can then be used to calculate the discovery reliability (DR), defined as the likelihood that a statistically significant result is caused by an actual treatment benefit.
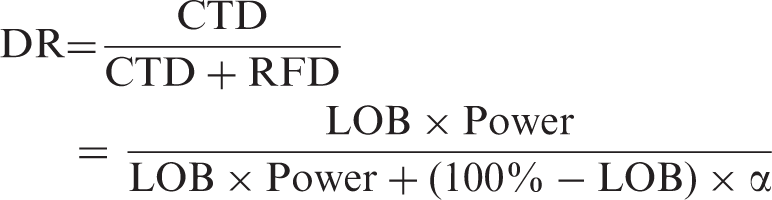
In the first example above, the DR is 1.6%, and in the second example 94%, consistent with the notion that findings from large screenings have to be verified in follow-up tests. The way LOB and power determines DR is illustrated in Figure 1(b).
The effect of LOB on DR can be understood by considering that the testing of random compounds is unlikely to yield convincing results. It is, however, difficult to estimate the LOB for compounds tested in pre-clinical neurological disease models. The number of compounds tested relative to the number of treatments approved for clinical use would indicate a very low value. 4 The fraction of pre-clinical research that report BT would, on the other hand, indicate a high value. While calculating exact values for LOB are likely beyond reach, the effect of various actions on the LOB can be reached by theoretical reasoning. Drugs with a known mechanism of action should, for example, in theory be more likely to work, and therefore also have a higher LOB. Careful pharmacokinetic analysis such as measuring the half-life, verifying passage over the blood–brain barrier, establishing the optimal concentration (dose–response curves), how much a treatment delay reduces the effect (delay–response curves), and the optimal duration of treatment (duration–response curves) should, in theory, also increase the LOB.
The effect of statistical power on DR may not obvious, but may be understood by considering that lower power reduces the CTD, while the RFD remains the same. In other words, the less likely you are to make a TD, the less likely it is that the discoveries you do make are true. This makes it desirable to increase power,5–8 which potentially could be done by adding more subjects, controlling for social hierarchy, physiological monitoring and aseptic technique during surgical procedures, increased observation times during behavioral testing results, 9 and by relying on behavioral tests with reduced levels of animal–experimenter interactions. 10
To conclude, there are strong arguments that the reliability of pre-clinical research can be improved by increasing the pre-study likelihoods of treatment benefit and the statistical power of the experiments. It can also be argued that there is a pressing need for this, given the frequent failures of phases III clinical trials. It is, however, important to notice that DR may be affected by several other factors, most notably various forms of bias,11,12 for example non-reporting of negative studies, p-hacking, and selective outcome reporting. DR will also be affected by the experimental design, for example choice of p-value thresholds, using multiple outcome measures, and repeated testing of the same compound. This makes it a daunting task to approach this problem, but a low hanging fruit would be to publish power calculations. These would allow a better estimation of the statistical power actually used and would be an important first step to improve the DR in pre-clinical neurological research.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funds from the Swedish Armed Forces (R&D).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.