
Abstract
A key challenge in classifying cholesteatoma images lies in the effective extraction and integration of both local and global features. This paper addresses this challenge by introducing a Gabor-local and contextual-global network. This network enhances local feature extraction through the incorporation of Gabor filtering alongside a ResNet architecture, which captures richer local information at varying scales and orientations. Moreover, the attention mechanism generates an importance score map, enabling the network to dynamically focus on the most relevant regions within the input image by normalizing scores into a weight matrix and supporting Generalized-Mean (GeM) pooling, resulting in a more robust global descriptor. Finally, a novel dynamic feature fusion strategy combines local features, global features, and outputs from the last residual block based on their computed importance scores, further enhancing the model’s overall performance. Experimental results show the network’s superior performance, effectively leveraging both local and global information for enhanced classification outcomes.
1. Introduction
Accurate differentiation between cholesteatoma and a normal middle ear is crucial, as cholesteatoma may cause progressive hearing loss (as shown in Figure 1), tinnitus, and structural damage,1,2 often necessitating surgical intervention. In contrast, a normal middle ear does not require treatment, highlighting the importance of precise diagnosis. Advanced imaging techniques, in combination with artificial intelligence (AI), play a pivotal role in this process. While imaging can reveal subtle anatomical differences, AI further enhances diagnostic accuracy by analyzing complex data patterns, thereby improving classification performance and supporting personalized treatment planning. Image samples of normal middle ear and cholesteatoma.
Early efforts in AI ear image classification employ deep learning on two dimensional Computed Tomography (CT) slices to detect chronic otitis media 3 and apply machine learning to tympanic membrane images for middle ear condition classification. 4 Subsequent CT approaches focus on cholesteatoma differentiation and pediatric temporal bone disease diagnosis using architectures such as VGG and hybrid models.5,6 Structure aware methods also improve classification accuracy. 7 In addition to CT, convolutional neural networks (CNNs) apply to intraoperative endoscopic and standard otoscopic images for cholesteatoma detection,8,9 while lightweight models such as MobileNetV2 support targeted predictive tasks. 10 Further methodological advances include deep feature fusion with graph isomorphism networks, explainable three dimensional CNNs, and hybrid CNN combined with machine learning strategies.11–13 These developments include comparative evaluations of architectures such as ResNet, MobileNetV2 and DenseNet against Magnetic Resonance Imaging (MRI),14,15 as well as systematic reviews of performance. 16 Bibliometric analyses indicate a growing integration of AI and medical imaging in cholesteatoma research. 17 Additionally, various works like DenseNet, 18 SE-ResNet, 19 Vision Transformer (ViT), 20 Bottleneck Transformer (BoTNet), 21 ConvNeXt, 22 iFormer, 23 TransNeXt, 24 and Visual Attention Network (VAN) 25 effectively utilized network architectures or attention mechanisms to achieve state-of-the-art results in multiple medical image classification tasks.
Previous methods in cholesteatoma image classification have achieved a certain degree of success; however, they still face challenges, particularly in effectively extracting and integrating local and global features. These approaches struggle to capture intricate spatial relationships and may overlook important contextual information, which can lead to less than optimal performance. To address these challenges, this paper introduces several innovative components. First, the proposed Gabor-local feature extraction, combined with a ResNet architecture, enhances local feature capture by obtaining richer information at varying scales. Second, a contextual-global feature extraction aggregation is developed, generating the importance score map that enables the model to dynamically focus on relevant image regions while normalizing scores into a weight matrix and supporting Generalized-Mean (GeM) pooling for a robust global descriptor that incorporates contextual significance. Lastly, a novel dynamic feature fusion strategy combines local features, global features, and outputs from the last residual block based on their computed importance scores. This synergy not only amplifies critical information but also strengthens the model’s capacity for multi-scale analysis, ultimately leading to improved classification performance in challenging cholesteatoma image analysis. Overall, the main contributions of this paper can be summarized as. - The proposed Gabor-local feature extraction within the network enhances local feature capture, enabling a more nuanced representation of relevant patterns in cholesteatoma images. - The developed contextual-global aggregation mechanism generates the importance score map, which enables the model to dynamically focus on relevant regions and supports robust global descriptors through GeM pooling. - A dynamic feature fusion approach combines local and global features together with outputs from the last residual block based on importance scores, which leads to superior classification performance in challenging cholesteatoma image analysis. - Experimental results demonstrate superior classification performance compared to conventional methods, showcasing the model’s effectiveness in leveraging local and global information.
The remainder of this paper is structured as follows: Section 2 reviews relevant works from various perspectives, establishing the foundation for our study. Section 3 introduces our proposed model, detailing its technical implementation and the underlying theoretical principles. In Section 4, we outline the experimental framework, including the datasets used for evaluation and the performance metrics applied. The paper concludes in Section 5 with a summary of the main findings and proposes possible directions for future research in this area.
2. Related works
2.1. Local feature extraction
CNNs have been frequently utilized for their inherent ability to capture local features across various applications. For example, Tian et al. 26 employed CNNs within a dual network structure to extract both local and global features for image denoising. Concurrently, the effectiveness of convolutional operations for capturing local details was implicitly studied by Utomo et al., 27 who compared models using explicit local feature descriptors against standard CNN performance on medical images. Subsequent research continued to integrate CNNs for their local feature extraction capabilities, often within hybrid models. For instance, Mou et al. 28 designated a CNN channel purely for local feature extraction in a multimodal driver distraction system, while Hu et al. 29 applied a CNN module to summarize local planar features in magnetic resonance images before integrating them. In other imaging areas, Li et al. 30 leveraged the strength of CNNs in computing local dependencies for mineral prospectivity mapping, Wang et al. 31 used CNN features to interactively capture local structural information for image super resolution, and Xu et al. 32 proposed a specific dynamic CNN branch to effectively encode local pixel features for hyperspectral image classification. MedViTV2 33 incorporated Kolmogorov Arnold Network layers into a transformer, achieving efficient global and local feature perception with improved performance.
2.2. Global feature extraction
Recognizing the limitations of CNNs in capturing long-range dependencies and global context, several approaches have sought to enhance their ability to model global features. He et al. 34 introduced a framework with distinct branches for local and global attention within a CNN architecture to learn comprehensive representations for depression recognition. Wang et al. 35 developed a multitask attention CNN with a global feature shared network designed to extract globally relevant information for tasks like fault diagnosis and working condition identification. Similarly, Li et al. 36 combined global information from the entire image with component details in a multiscale CNN to improve synthetic aperture radar target recognition. Further, Liu et al. 37 integrated a CNN focused on local features with a vision transformer for learning global features to address high-resolution synthetic aperture radar images’ challenges. Xiong et al. 38 designed a CNN model with separate branches for extracting and fusing global and local features from electromyography signals to enhance hand gesture recognition. To tackle the struggle with long distance dependencies, Li et al. 30 integrated a Transformer with a CNN for mineral prospectivity mapping. Khan et al. 39 introduced a model with global and local convolutional components for histopathological slide classification. Lastly, Duan et al. 40 combined transformers with CNNs for multi-focus image fusion, enhancing interaction between features using knowledge distillation.
2.3. Feature fusion strategies
Several studies have explored feature fusion techniques within CNN frameworks to enhance performance across various domains. For instance, Khan et al. 41 integrated low-level handcrafted features with multi-stage deep CNN features for image scene geometry recognition through fusion strategies. Extending this concept, Ding et al. 42 developed a multi-feature fusion network combining multi-scale graph convolutional networks and multi-scale CNNs to fuse their outputs for hyperspectral image classification. In a parallel development, Li et al. 43 presented a combined architecture of a CNN for spatial features and an LSTM network for temporal features, fusing these along with intermediate convolutional layer features for motor imagery EEG classification. Similarly, Ou et al. 44 designed a CNN framework incorporating feature fusion after applying band selection for hyperspectral image change detection. Xiao et al. 45 constructed a multi-scale CNN with an attention mechanism, employing feature fusion strategies to recognize the appearance of spot-welding surfaces. Further, Haq et al. 46 employed feature fusion within a deep CNN architecture, combined with ensemble learning, to improve the classification of abnormalities in mammographic images. Zhang et al. 47 developed a dual-channel CNN that enhanced feature representation by repeatedly fusing deep and shallow features for wildfire detection.
3. Methodology
In this paper, we present a classification method for cholesteatoma images that leverages a ResNet
48
architecture, integrating Gabor filtering for local feature extraction and an attention mechanism for contextual-global feature aggregation. As shown in Figure 2, the input image is first processed through residual blocks to generate feature maps. These feature maps are subsequently refined by Gabor filters, which further enhance local features. Concurrently, the attention mechanism produces an importance score map to identify relevant regions in the feature space. These scores are normalized into a weight matrix and applied using GeM pooling to create a robust global descriptor. Next, the local features, global features, and outputs from the last residual block are fused using the proposed dynamic feature fusion. Finally, this combined representation is passed through a fully connected layer to generate logits, which are then converted into class probabilities via Softmax. The input image is processed through residual blocks to create feature maps. Subsequently, Gabor-local feature extraction (GLFE) and contextual-global feature aggregation (CGFA) are applied to generate local and global features. Following this, dynamic feature fusion (DFF) is employed to combine the local and global features with the outputs from the last residual block, based on their significance scores. Finally, the fused features are passed through a fully connected layer to produce logits, which are then converted into class probabilities using the softmax function.
3.1. Gabor-local feature extraction
As illustrated in Figure 3, the Gabor-local feature extraction process begins with an input image The input feature X[l−1] is first processed by a residual block to produce the feature map X[l]. An adaptive parameter selection mechanism then analyzes the statistical characteristics of X[l] to determine the parameters for the Gabor filters. Using these parameters, multi-scale Gabor filters Gi,Re and Gi,Im are constructed, whose convolution with X[l] yields the multi-scale feature representation 








For each Gabor filter, the concatenated real and imaginary responses are computed as:

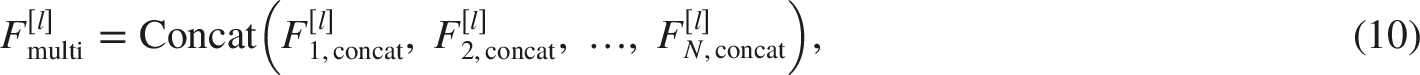



3.2. Contextual-global feature aggregation
As shown in Figure 4, contextual-global feature aggregation begins with GeM pooling applied to the feature tensor The contextual-global feature aggregation first applies GeM pooling to X[l] to obtain an initial global descriptor 







3.3. Dynamic feature fusion
To further enhance model performance, we develop a dynamic feature fusion approach that integrates local features, global features, and the output from the last residual block. Initially, these features are extracted from the preceding layers of ResNet. Subsequently, they are flattened into three distinct representations:



These weights are then normalized to ensure their sum equals 1:


Next, the normalized weights are combined with the three features to yield a composite feature:

Afterwards, a fully connected layer maps this fused feature into output space. The logits can be expressed as follows, where W
l
denotes the linear transformation matrix and b represents the bias term:

Finally, these logits are passed through a Softmax function to obtain class probability distributions:

During training, the cross-entropy loss function evaluates the discrepancy between predicted results and true labels, where y represents the true label:

4. Experiment
4.1. Datasets
Our dataset consists of 562 images obtained through CT scanning using a 128 channel multidetector SOMATOM Definition Edge CT scanner (Siemens Inc., Munich, Germany). Each scan is acquired with consistent imaging parameters, including an axial section thickness of 0.625 mm, collimation of 128× 0.6 mm, a field of view measuring 220× 220 mm, a pitch of 0.8, and a matrix size of 224× 224. Imaging is conducted at 120 kV and 240 mAs to maintain uniform image quality throughout the dataset. Clinical labels for each ear derive from definitive diagnoses recorded in patients’ medical records. The dataset maintains a balanced representation of cholesteatoma and normal cases. To safeguard against data leakage and ensure independence between training, validation, and test sets, we apply stratified 5 fold cross-validation at the patient level. This approach preserves the integrity of the evaluation process by preventing patient data overlap across folds. Finally, model selection relies on the average performance across validation folds, promoting robustness and generalizability in the results.
4.2. Implementation details
The proposed classification network is developed and evaluated using PyTorch 1.9.0 on an NVIDIA GeForce RTX 3090. Prior to training, all input CT scans are resampled to a uniform voxel size of 1mm × 1mm × 1mm to ensure consistent spatial resolution across subjects. Subsequently, intensity normalization is performed to achieve zero mean and unit variance throughout the dataset, standardizing the overall distribution of voxel values. To enhance model generalization and mitigate overfitting, various data augmentation strategies are applied, including random rotations, horizontal flips, and brightness adjustments. The network is optimized using the Adam algorithm with an initial learning rate of 0.001 and a weight decay of 1e-5, enabling efficient parameter updates while introducing L2 regularization for improved stability. A learning rate scheduler further refines the training process by reducing the learning rate by a factor of 0.1 every 15 epochs over a total of 100 training epochs, promoting smoother convergence. To prevent unnecessary training and further reduce overfitting, an early stopping strategy is employed, which monitors validation performance and halts training automatically when no improvement is observed over five consecutive epochs, ensuring optimal model performance.
4.3. Evaluation metrics
Accuracy quantifies the frequency with which a model correctly classifies instances. It is defined as the ratio of correctly predicted instances to the total number of instances:

Here, TP represents true positives, TN indicates true negatives, FP denotes false positives, and FN refers to false negatives.
Sensitivity measures the proportion of actual positive instances correctly identified by the model. It is calculated using the following formula:

Specificity assesses how effectively a model identifies negative instances, defined mathematically as:

The Area Under the ROC Curve (AUC) serves as a performance measure for classification models across various threshold settings. It quantifies how well a classifier distinguishes between different classes.
4.4. Validation of Gabor-local feature extraction
Validation of Gabor-local feature extraction.

4.5. Effectiveness of contextual-global feature aggregation
Effectiveness of contextual-global feature aggregation.

4.6. Impact of dynamic feature fusion
Influence of dynamic feature fusion.

4.7. Influence of pooling methods
Influence of pooling methods.

4.8. Effect of different residual network depths
This experiment investigates the relationship between the depth of residual blocks in the ResNet architecture and its performance on classifying normal middle ear and cholesteatoma images. Initially, as depicted in Figure 5, increasing network depth leads to improved performance. This gain is attributable to the enhanced feature extraction capabilities of deeper models, which allow them to capture more intricate patterns crucial for distinguishing between the two medical conditions. However, this positive trend reverses beyond a certain threshold (specifically, a depth of 50). At greater depths, the model becomes susceptible to overfitting by learning noise and specifics from the training data rather than generalizable patterns, which consequently diminishes its performance on unseen data. Effect of different residual network depths.
4.9. Effectiveness of various input sizes
As shown in Figure 6, the experimental results demonstrate variations in performance across different input image sizes. Through detailed analysis, we observe that larger input dimensions, particularly 112 × 112 and 224 × 224 pixels, generally yield superior classification performance compared to smaller input sizes, albeit at the cost of increased computational overhead. However, our experiments reveal an interesting phenomenon: the network shows diminishing returns in performance improvements beyond 224 × 224, suggesting this resolution represents an optimal balance point between performance and computational efficiency. Based on these findings, we ultimately adopt the size of 224 × 224 as it offers a compelling compromise, maintaining relatively high performance while effectively reducing computational requirements compared to larger input dimensions. Effectiveness of various input sizes.
4.10. Visualization of attention maps
As shown in Figure 7, the attention map visualizations demonstrate that the proposed model could concentrate on key pathological regions within cholesteatoma images. This suggests that the importance score mechanism effectively directs the model’s focus toward diagnostically relevant areas. By highlighting these critical regions, the model is able to integrate local and global features more accurately, thereby enhancing its overall representation ability. Consequently, this targeted attention contributes to the observed improvement in classification performance. Visualizations of attention maps.
4.11. Comparison with state-of-the-art models
Comparison with state-of-the-art models.

5. Discussion and conclusion
In this paper, our proposed model showcases superior performance in classifying cholesteatoma from normal middle ear images compared to state-of-the-art methods, emphasizing the efficacy of its integrated design. Specifically, the incorporation of Gabor filtering alongside the ResNet architecture effectively improves local feature extraction, enabling the model to capture nuanced textural and structural patterns critical for distinguishing cholesteatoma. Furthermore, the contextual-global feature aggregation enhances the model by generating an importance score map, enabling it to dynamically focus on the most salient image regions and facilitating the creation of a robust, global feature descriptor via GeM pooling. Additionally, the proposed dynamic feature fusion strategy combines Gabor-local features, contextual-global features, and deep semantic features from the final residual block based on their computed importance, supporting a more comprehensive multi-scale analysis. Clinically, this model holds promise by enhancing diagnostic performance, which is crucial for accurately distinguishing between cholesteatoma, requiring timely intervention, and a normal middle ear that does not. This improvement helps reduce misdiagnosis, ensure appropriate and timely patient management, and potentially decrease morbidity, avoid unnecessary surgeries, and optimize the use of healthcare resources in otolaryngology. Besides, this paper is conducted at a single center with a retrospective design, which introduces selection bias and limits the generalizability of the results. The dataset consists exclusively of CT images and does not include MRI data, which provides complementary diagnostic information. To address these limitations, we plan a prospective multicenter study to validate the model in a larger and more diverse patient population, incorporating multimodal imaging data, including MRI, for comprehensive evaluation.
Footnotes
Author contributions
Jianqing Chen contributed to investigation, data curation, conceptualization, writing the original draft, and project administration. Guokai Zhang was responsible for methodology, and formal analysis. Yanran Wang handled visualization, and writing review and editing. Yuqing Sun supervised the project, validated results, and contributed to writing review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding Sponsored by the Interdisciplinary Program of Shanghai Jiao Tong University (YG2019QNB12).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.