
Abstract
Software with increasingly complex structures plays a vital role in our lives, and our dependence on it continues to grow. As software failures and defects can cause serious problems, it is critical to measure and improve software reliability. Previous software reliability models were derived under the assumption that no failures exist at the initial point in time. However, this study developed a model that predicts software failures by setting the observation point to the initial stage and assuming that a certain number of defects already exist. Various possibilities for this have been proposed. These possibilities can arise in increasingly complex and diverse software. The proposed model assumes that software failures are not only independent it also assumed that software failures occur in a dependent manner. To demonstrate the superiority of the proposed model, we compared it with 15 traditional models across three datasets using nine criteria. The results confirmed the excellence of the proposed model by demonstrating that it achieved the best performance across all datasets. The results of this study contribute to enhancing software reliability by enabling investigation into what causes problems at the beginning of software development and creating software reliability models that are applicable in the real-world.
Introduction
Software plays diverse roles in all fields. It performs basic functions in many areas, from simple document processing, calculations, and repetitive tasks to specialized programs, such as statistical analysis, image and video editing, and web browsers. It also oversees all systems such as databases and operating systems. The advancement of generative AI technology has further expanded the role of software, and experts expect its importance to grow even more in the future. In today's environment, in which software has become increasingly crucial, the impact of software defects and failures can be significant. Even a minor flaw can potentially disrupt the entire system and cause widespread social disruption.
In 2017, the Equifax data breach occurred. The cause was announced to be failure to apply for a vulnerability patch. This stemmed from the problem of not patching a known vulnerability in a timely manner. Based on this, the data breach occurred along with various other causes, including inadequate network segmentation and expired certificates. Consequently, the personal information of approximately 143 million U.S. citizens was compromised. This causes extremely serious damage, as it exceeds the recorded monetary losses and carries the potential for future harm.1,2
Although identifying and addressing the causes of software failures is crucial, predicting and preparing for software defects before they occur are equally vital. To assess this, software reliability, which measures how long software can operate without failure, was calculated. Software reliability has been calculated through software failure prediction using various research methodologies such as time-series models and failure rate models.3,4 Among these, the software reliability model based on the nonhomogeneous Poisson process is a representative research methodology for improving software reliability. It assumes that the number of failures and defects occurring per unit time is not constant, but exhibits a time-dependent relationship. This methodology originated from research by Goel and Okumoto in 1979, which assumed that the cumulative occurrence of software failures and defects over time follows an exponential function. 5 It has since been expanded to include studies assuming that failures and defects occur in various forms such as S-shaped, concave, and convex patterns.6,7 Furthermore, research has been conducted to enhance software reliability through detailed failure prediction using assumptions tailored to increasingly complex software environments such as operational uncertainty and imperfect debugging.8–10
This study extends this approach by proposing a new type of software reliability model to enhance software reliability. Conventional software reliability models assume that software failures occur independently. This assumes that failure does not affect subsequent failures. However, in integrated systems, the combination of multiple software components creates a structure in which the occurrence of a defect in one software affects or causes failures in the other software. 11 This study proposes a software reliability model that assumes the occurrence of dependent failures or defects. Furthermore, whereas past research assumed initial software failures and derived mathematical formulas, this study developed a model that predicts failures based on an initial observation point that does not necessarily start at zero. 12 This can be described as a general situation because the test and observation points can be measured differently depending on the observation point of the analyst or software operator. Therefore, this study proposes a general software reliability model that uses dependent failures and observation time as the initial time to enhance the reliability of today's increasingly complex software.
The remainder of this article is organized as follows. The related research for software reliability model section summarizes previous research on software reliability models. In the “a new software reliability model” section, the proposed model is introduced. The numerical examples section presents the data and goodness-of-fit analysis used to evaluate the model's performance and the resulting analysis. Finally, the last section concludes the article.
Related research for software reliability model
Software reliability is the ability of a software to function without failure over an extended period.13,14 The function used to evaluate this is defined as the probability that the software will remain operational after a specific time t. Assuming that the lifetime is a random variable T, the reliability function

The reliability function
Research has also been conducted on models that reflect the various efforts invested during the testing phase to determine whether software failures will occur. Yamada et al. (1986) proposed a model that incorporated the testing effort required to correct defects discovered during the testing phase, including manpower, time, and CPU. 18 Huang et al. (2007) integrated a logistic failure detection rate function with an S-shaped curve into a software reliability model. 19 This curve shows that under variable testing effort conditions, the effectiveness of fault-detection diminishes as testing progresses beyond the early and middle stages. Peng et al. (2014) proposed a model in which the occurrence of simple software failures depends on both time and testing effort. 20 They defined this as a cumulative effort function and developed a model in which resource input patterns, such as manpower, time, and CPU, were reflected in the defect detection process. This model also considers imperfect debugging in which new defects can potentially arise.
Many studies have assumed a complete debugging model in which all faults and defects are corrected upon detection. However, it is extremely difficult to correct all the faults and defects in real environments, and it is unrealistic to prepare for every possibility. Therefore, research has been conducted on software reliability models that assume imperfect debugging to reflect realistic scenarios. These models assume that when errors are corrected, they may not be perfectly corrected or that additional errors may arise from the original error. Yamada et al. (1992) assumed that software defects and failures occur at a constant rate per unit time. 21 They modified the form of the software failure number function to derive a software reliability model that incorporated imperfect debugging. Pham and Zhang (1997) and Pham et al. (1999) proposed a model assuming that the number of software defects and failures occurring per unit time increases according to an S-shaped curve over time.22,23 Roy et al. (2014) proposed a model with an exponentially increasing defect function and a constant defect detection rate per unit time. 24 This reflects the rapid increase in defects early in testing, followed by a gradual increase as the efficiency improves over time. Pham (2007) assumed imperfect debugging and derived a model using functions in which both the defect detection rate and total number of faults gradually increase over time. 12 The test-start condition of the model assumes an arbitrary initial point. This model assumes that defects may be detected at the beginning of testing, thereby providing a more generalizable approach.
The software released a testing phase to maximize improvements before calculating the optimal release timing for deployment. However, even the released software experiences defects and failures owing to differences between the actual and test environments. These failures incur higher costs than those incurred during testing, ultimately yielding poor results. Therefore, a software reliability model that considers the uncertainty of the operating environment, including the randomness arising from the differences between the actual and test environments, was developed. Teng and Pham (2006) proposed the incorporation of an operating environment uncertainty parameter that follows a gamma distribution into the differential equation of an existing model. 25 Building on this work, Honda et al. (2017) and Asraful Haque and Ahmad (2021) conducted studies in which the failure detection rate function followed an S-shaped curve.26,27 Chang et al. (2014) proposed a composite assumption software reliability model. This model simultaneously assumes testing coverage and operating environment uncertainties. 28 Song et al. (2017) expanded the model developed by Teng and Pham by creating a model in which the failure rate per unit time followed an S-shaped curve with three parameters. 29 Furthermore, it converts the uncertainty parameter of the operating environment, which follows a gamma distribution, and the fault-detection rate function into a testing coverage function.
The reliability of software is enhanced by models that assume dependent failure occurrences. This is because of the increasingly complex nature of software owing to technological advancements. This assumes that software errors affect other types of errors. Huang et al. (2006) presented a model that integrated defect dependency and debugging time delay. 11 This model incorporates parameters for defect dependency and removal rate, as well as parameters for delay time. Chatterjee et al. (2021) focused on dependent defects arising from imperfect debugging under defect dependency, which is a type of defect that can occur during software operation. 30 Their model considered the impact of change points caused by alterations in test strategies and environments during the evolution of software through testing. Samal et al. (2024) extended this research by proposing a model that considered defect dependency detection, imperfect debugging, and the maximum number of defects present in the system. 31 Additionally, Hussain et al. (2025) conducted research assuming both complex software structures and differences between actual and test environments. 32
Among the introduced models, the model proposed by Pham (2007)
12
is novel and reflects realistic problems. This model assumes that testing in the software development phase does not always start from
A new software reliability model
This study presents a software reliability model that assumes a nonhomogeneous Poisson process to improve software reliability. Unlike a Poisson process, a nonhomogeneous Poisson process does not have a constant mean failure rate
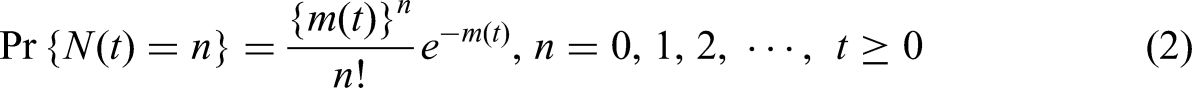

Dependent failure software reliability model
Many previous software reliability models have assumed that software failures and faults occur independently, with one failure not affecting the other. However, software has become vastly complex, encompassing everything from the smallest components to the entire system. When a defect occurs in such complex software, the resulting failure causes dependent failures within the software. A dependent failure indicates that a failure increases the probability of other failures occurring either by directly affecting other failures or by affecting failures in other complexly integrated software components. This manifests as either a common-cause failure, where multiple software components fail simultaneously due to a single cause, or a dependent failure, where a failure in one software component within the overall system affects other software components as well.34,35 To model this, we assume a dependent defect occurrence using differential equation (4).
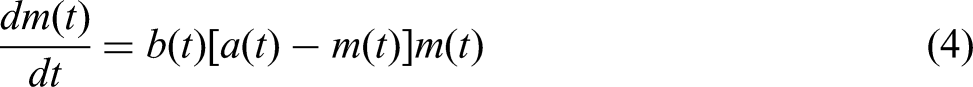
This assumes a dependent defect occurrence through a structure in which the mean value function
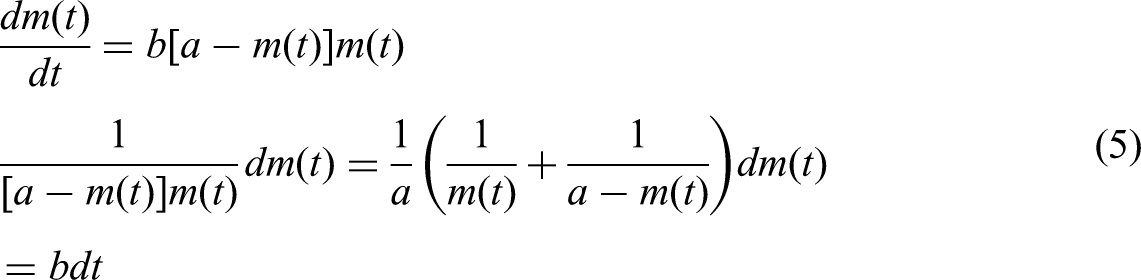
Integrating both sides of equation (5) yields equations (6–8) as follows:



Simplifying equation (8) to


To define the integration constant, we assume an initial value
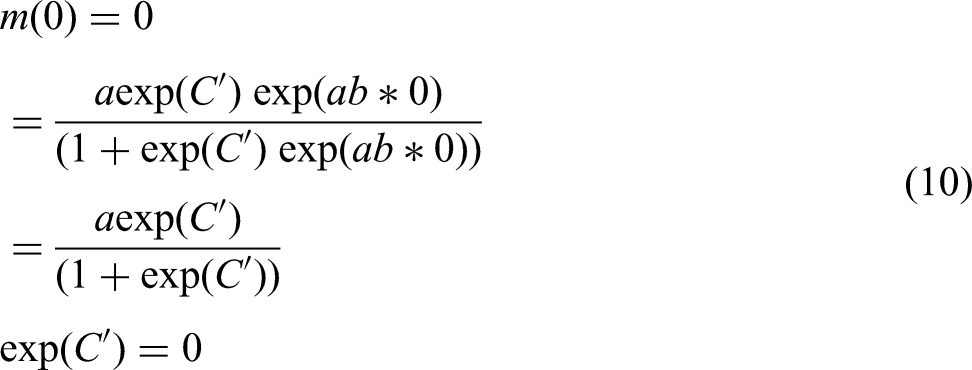
Substituting the integration constant obtained from equation (10) into equation (9) yields equation (11).
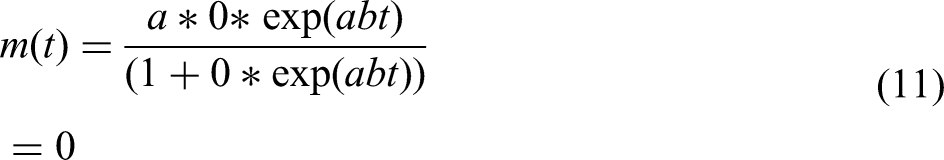
Assuming
Proposed dependent failure software reliability model
To address the issue of the final model

Substituting equation (12) into equation (9) yields the final model equation proposed in this study, given by equation (13) as follows:

Here, the proposed model includes four parameters: the total number of failures a, failure detection rate b, time point
Software reliability models.

Numerical examples
Data introduction
Three datasets were used in this study. The first and second datasets are telecommunications system data, which are system test data for telecommunications systems. 36 Data collection was divided into two phases: Phase 1 and Phase 2. Both automated and human-involved tests were performed on multiple test beds. Phase 1 recorded 26 failures over 21 weeks, whereas Phase 2 recorded 43 failures over 21 weeks. The third dataset is a fault dataset recorded from an online communication system project at the ABC Software Company. 37 The project team consisted of one unit manager, one user interface software engineer, and 10 software engineers and testers. The dataset generated from this project was collected over a total of 12 weeks, during which 110 failures occurred. Error detection involves the development and testing teams prioritizing the most critical change requests and organizing them into subcategories to facilitate resolution. This allowed for classification based on severity, resulting in a dataset that simultaneously considered both major and minor issues. Table 2 presents the weekly number of observed failures for the three datasets introduced above.
Datasets.

Criteria
Nine criteria were used to evaluate model performance. These criteria were calculated based on the difference between the actual data and estimated values obtained from the model. Among the nine criteria,
Table 3 lists the formulae for the criteria used to compare the models. The first criterion, the mean squared error (MSE), was obtained by dividing the sum of squares of the differences between the actual data and estimated values by the number of observations. The second criterion, mean absolute error (MAE), was obtained by dividing the sum of the absolute values by the number of parameters.38,39 The third and fourth criteria, predictive ratio risk (PRR) and predictive power (PP), were defined as the difference between the actual and estimated values divided by the estimated and actual values, respectively.
40
This expresses the difference between the actual and estimated values as a ratio, and serves as a criterion to demonstrate superiority through PP. The fifth criterion is the predicted relative variation (PRV), which is the standard deviation of prediction bias. The sixth criterion, the tail statistic (TS), is the mean percentage deviation across all time points.41,42 The seventh criterion is Akaike's information criterion (AIC), and the eighth is the Bayes information criterion (BIC).
43
These two metrics are used to compare the maximization of the likelihood function and are judged by the Kullback–Leibler divergence between the model and probability distribution of the data. BIC incorporates a modified form of the AIC penalty. Here, logL denotes
Criteria for comparison of model.
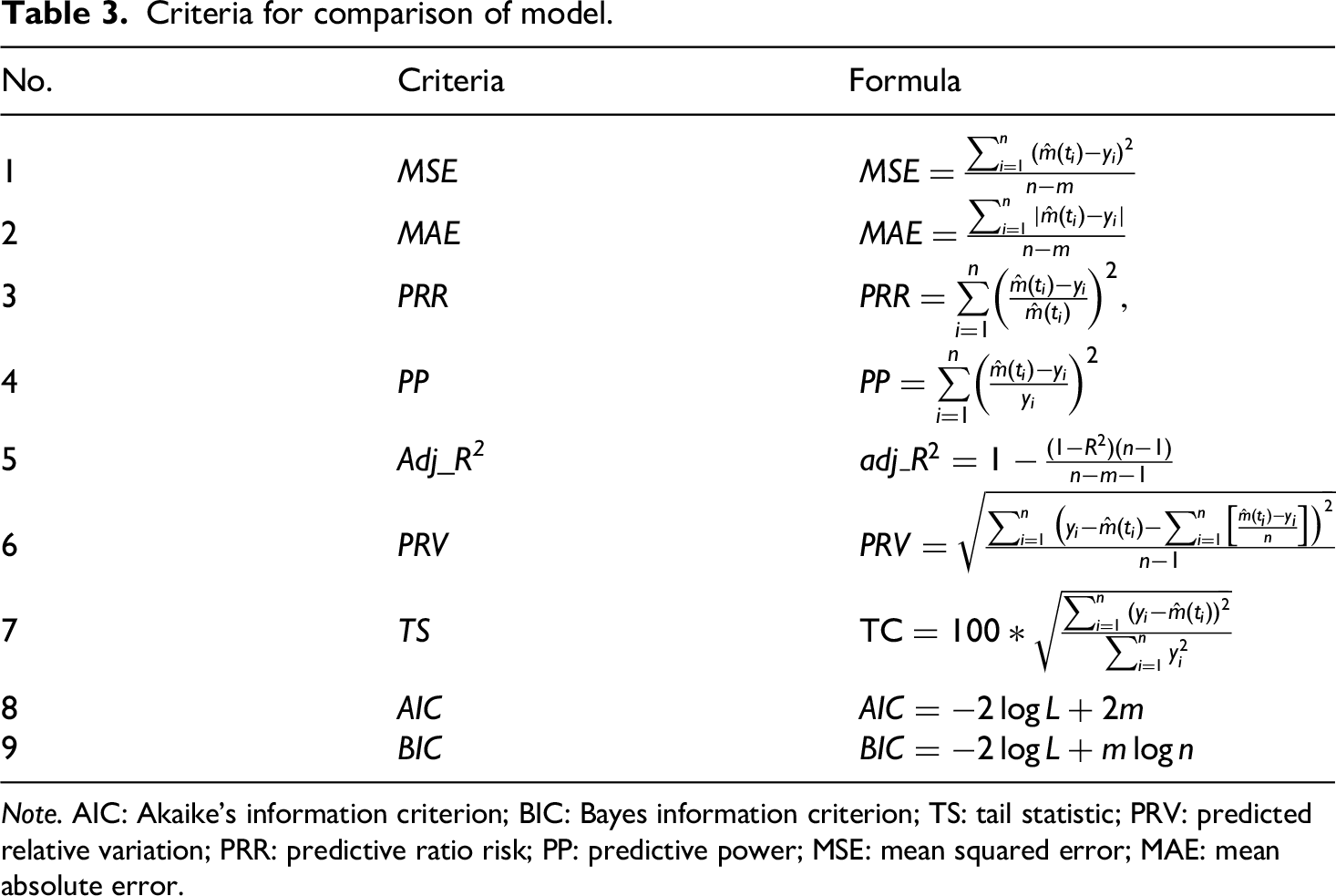
Note. AIC: Akaike's information criterion; BIC: Bayes information criterion; TS: tail statistic; PRV: predicted relative variation; PRR: predictive ratio risk; PP: predictive power; MSE: mean squared error; MAE: mean absolute error.
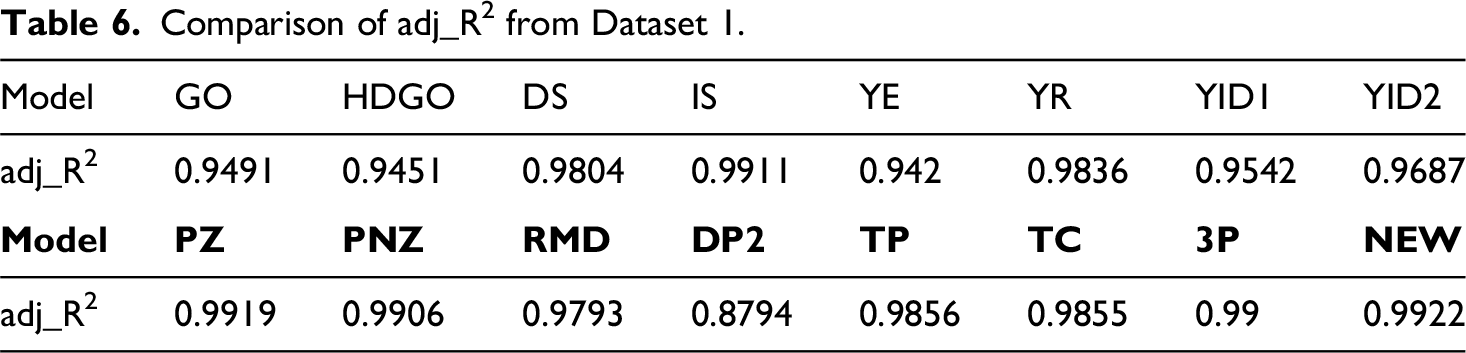
The ninth criterion, adj_R2 is the adjusted coefficient of determination, which reflects the number of parameters in the coefficient of determination of the regression equation,
Nine criteria indicated a better fit when adj_R2 approached one, whereas the other eight criteria indicated a better fit when they approached zero. These nine criteria were combined to demonstrate model superiority. We estimated each model's parameters using the least squares estimation (LSE) method, which calculates the difference between the values estimated using R and Matlab and the actual data. Subsequently, we computed their fit to compare their superiority. 45
Analysis results
Analysis results for Dataset 1
Table 4 lists the parameter values estimated from Dataset 1 for the traditional NHPP software reliability models and the proposed NHPP software reliability model. The proposed model includes four parameters: the total number of failures a, failure detection rate b, time point
Parameter estimation of model from Dataset 1.

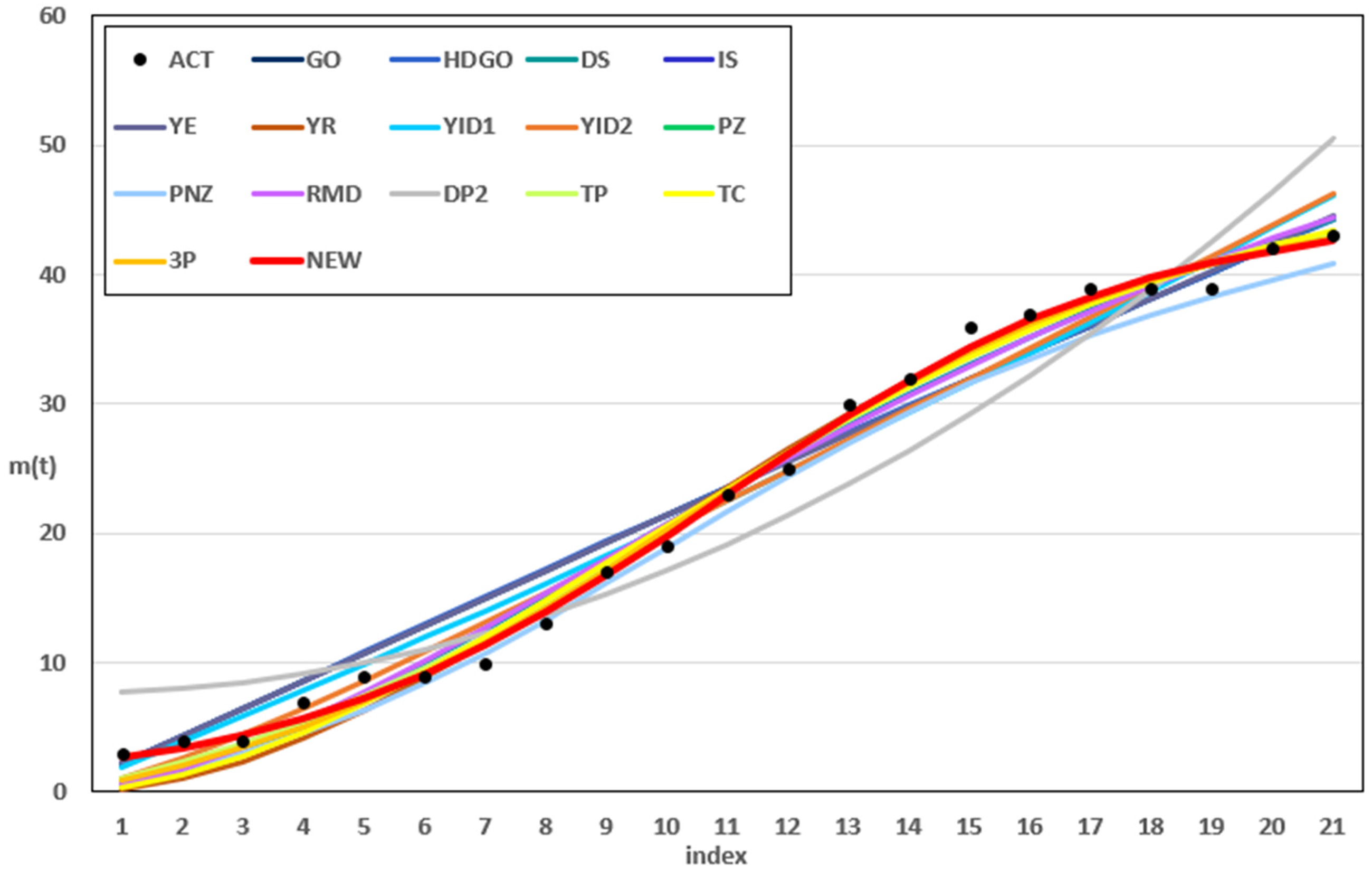
Figure 1 shows the results for the estimated values of all compared models and the cumulative number of failures in Dataset 1. The dashed line represents the actual data, whereas the thick red solid line represents the values estimated from the proposed software reliability model, which considers the initial conditions and dependent failure occurrence assumptions. The proposed model closely followed the trend of the actual data compared with the other models, showing very small differences from the actual values, except at points where failures occurred particularly frequently. Figure 2 shows the difference between actual and predicted values for Dataset 1 based on the top five models: DS, IS, PZ, PNZ, and the proposed model. Compared to other models, the proposed model yielded results closer to 0.

Results for the estimated values of all compared models in Dataset 1.

Difference between actual and predicted values for Dataset 1.
Based on the parameter estimates in Table 4,

Comparison of models based on normalized metrics for Dataset1.
Comparison of criteria from Dataset 1.

Comparison of adj_R2 from Dataset 1.
Analysis results for Dataset 2
Table 7 lists the parameter values estimated from Dataset 2 for 15 traditional models and the proposed model. The four parameters of the proposed model were
Parameter estimation of model from Dataset 2.

Figure 4 shows the estimated values of all the models compared and the cumulative number of failures for Dataset 2. The legend is the same as that shown in Figure 1. The results are very similar to the actual data trend compared with the other models, and the difference from the actual values at all points, except where the cumulative number of failure changes is small. Figure 5 shows the differences between actual and predicted values for Dataset 2 based on the top five models: IS, PZ, TP, 3P, and the proposed model. Compared to the other models, the proposed model yielded results closer to 0. In particular, the proposed model showed highly suitable results from the outset compared to the other four models.
Results for the estimated values of all compared models in Dataset 2.

Difference between actual and predicted values for Dataset 2.
Tables 8 and 9 list the results of evaluating the 16 models using nine criteria to assess the superiority of the model. The MSE, MAE, PRR, PP, PRV, TS, AIC, and BIC values were 1.1042, 0.9485, 0.1958, 0.1535, 0.9668, 3.5269, 75.603, and 79.781, respectively, which were close to zero. The value of adj_R2 was 0.9943, which was the closest to 1. The proposed model demonstrated the most optimal outcomes compared with the other 15 models. Figure 6 compares the normalized metric-based models on Dataset 2 and shows that the new model performed better overall.

Comparison of models based on normalized metrics for Dataset 2.
Comparison of criteria from Dataset 2.

Comparison of adj_R2 from Dataset 2.

Analysis results for Dataset 3
Table 10 lists the parameter values estimated from Dataset 3 for the 16 models. The parameters for the proposed model are as follows:
Parameter estimation of model from Dataset 3.

Figure 7 shows the estimated values of all compared models and the cumulative number of failures for Dataset 3. It has the same legend as that shown in Figure 1. Similar to the other datasets, the results closely resembled the actual data trend, showing a very small difference from the actual values. Figure 8 shows the difference between actual values and predicted values for Dataset 3 based on the top five models (IS, PZ, PNZ, 3P, and the proposed model). Unlike other models, the proposed model exhibited a trend close to 0 from the outset because it reflected results assuming an initial number of failures.

Results for the estimated values of all compared models in Dataset 3.

Difference between actual and predicted values for Dataset 3.
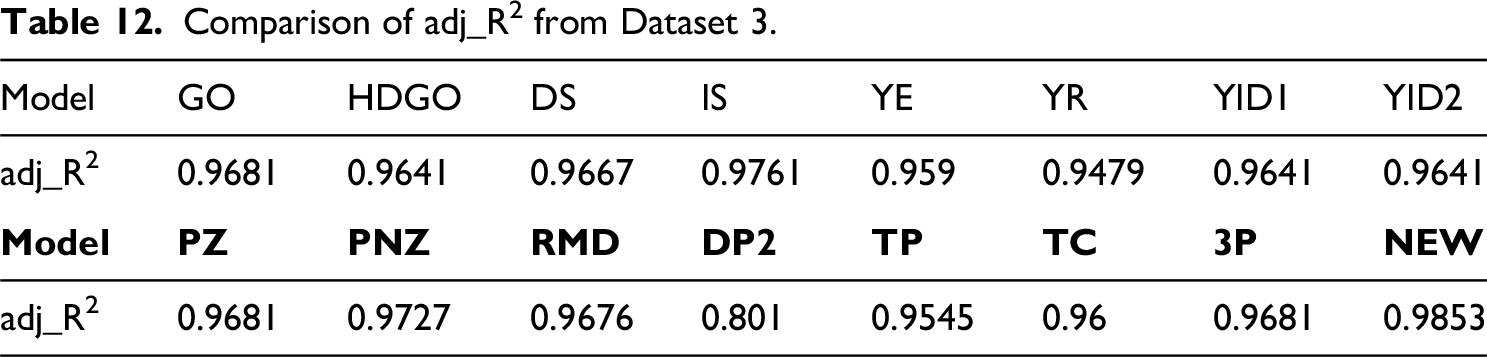
Tables 11 and 12 list the results of calculating nine criteria for the 16 models. Similar to Dataset 2, the MSE, MAE, PRR, PP, PRV, TS, AIC, and BIC were 15.2098, 4.2097, 0.081, 0.0701, 3.3235, 4.2571, 83.004, and 84.94, respectively. These values were close to zero. The value of adj_R2 was 0.9853, which was the closest to 1. Among the 16 models tested, the proposed model exhibited the best results. This study improved the model and achieved superior results. Figure 9 compares the normalized metric-based models on Dataset 3 and shows that the new model performed better overall.
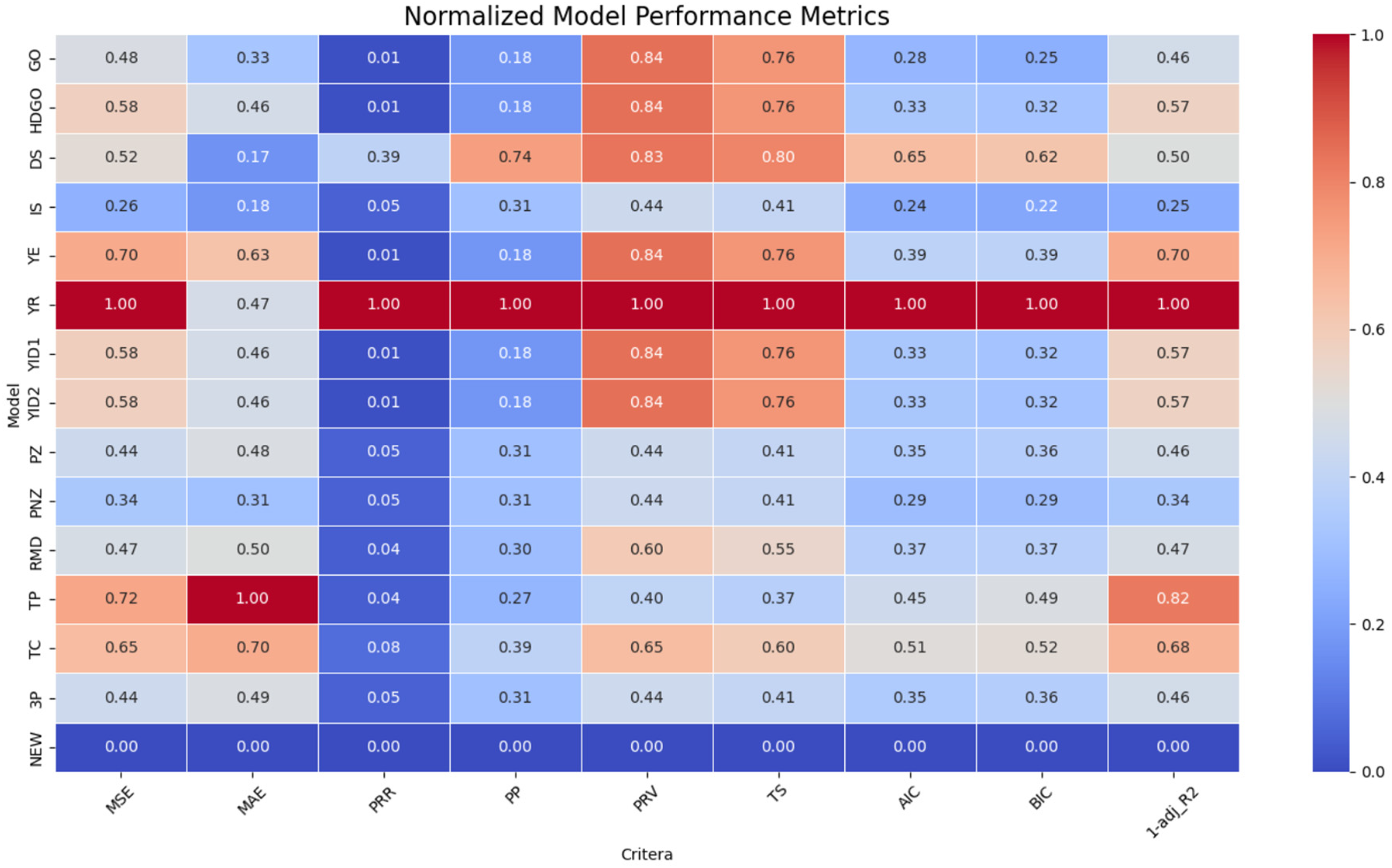
Comparison of models based on normalized metrics for Dataset 3.
Comparison of criteria from Dataset 3.

Comparison of adj_R2 from Dataset 3.
Conclusion
Advancements in software have made it an integral part of our daily lives. The importance of software, ranging from very small tasks to the management and operation of entire systems, will become more critical with each passing day. Consequently, software reliability is of paramount importance, and considerable research has been conducted to improve it. This study proposes a model for enhancing software reliability. The proposed model reflects the potential for failures arising from increasingly complex software structures, and considers realistic scenarios. To address the potential for failure in complex software structures, the model considers both independent and dependent failures. To reflect a real environment, it was assumed that a certain degree of initial failure existed during the testing and operational stages. The superiority of the proposed model was demonstrated through three datasets using nine criteria, which yielded the best results. Note that it performed better than previous models, which assumed that the observation point was the initial point. By including the assumption of dependent failures, we created a model suitable for realistic situations. As dependence on software continues to increase, the importance of software also increases significantly. Consequently, research on software reliability models to enhance software reliability is expected to increase in importance. Therefore, we aim to extend the assumptions of this study to a software reliability model that can effectively address specific situations. This extension will incorporate assumptions such as changes in failure detection rates based on software time dependency, imperfect debugging, and operating environment uncertainty.
Footnotes
Acknowledgments
The authors would like to thank the National Research Foundation of Korea and CSU G-LAMP Project Group for their valuable support in this work.
Author contributions
Chang, I. H. and Pham, H conceived and designed the study; Song, K. Y. and Kim, Y. S. collected the data; Song, K. Y. and Kim, Y. S. performed the data analysis; Kim, Y. S. contributed to data interpretation; Song, K. Y. contributed to visualization; Song, K. Y. and Kim, Y. S. drafted the initial manuscript; Song, K, Y., Chang, I. H., and Pham, H. revised the manuscript critically for important intellectual content; and Chang, I. H. supervised the overall research process and managed the project. All authors read and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Global-Learning and Academic Research Institution for Master's and PhD students and the Postdoctoral Program of the National Research Foundation of Korea funded by the Ministry of Education (Grant No. RS-2023-00285353).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The datasets generated and/or analyzed the current study are not publicly available bur are available from the corresponding author on reasonable request.