
Abstract
Objective
This study aims to systematically review and synthesize the studies on the application of machine learning for classifying infant cry types, identifying pathological cries, and evaluating the accuracy of infant cry recognition.
Methods
This review followed the PRISMA guidelines and was registered in PROSPERO (CRD42024600969). The literature search was conducted on four data sources: PubMed, CINAHL, Embase, and IEEE Xplore. The included studies focused on machine learning-based classification of infants’ needs cries or pathological cries. These were published in English between January 1, 2014 and October 31, 2024. Study quality was assessed using the QUADAS-2 tool.
Results
Of 919 studies were identified, 17 were included in the final synthesis. Machine learning can classify infant cries into two main types: infant needs’ cries and pathological cries, with some studies addressing both. Needs-related cries comprised nine subtypes, while pathological cries included six subtypes. Classification accuracy varied by machine learning classifier and the features used, ranging from 44.5% to 99.82%. The highest accuracy for infant needs’ cries was hunger and pain cries at 99.82% using a Gaussian mixture model (GMM) classifier with constant-Q cepstral coefficients features. For pathological cries, the highest accuracy was for detecting deafness (99.42% to 99.82%), using a genetic selection of Fuzzy Model and a GMM classifier.
Conclusions
Machine learning shows strong potential for accurately classifying infant cries and detecting pathologies. Future research should prioritize developing diverse cry datasets to improve model generalizability, evaluating performance in real-world settings, and integrating cry analysis with physiological signals to enhance diagnostic accuracy.
Introduction
Infant cries are one of the infant cues, which are signals that infants communicate and interact with their caregivers. These signals can convey the needs of infants and reflect pathological disorders. 1 Crying can be considered as the natural behavior of an infant and is identified based on the infant's needs, such as hunger, pain, discomfort, diaper, and sleepiness.2,3 Moreover, an infant's cries can indicate health issues or illnesses, such as infections, respiratory distress syndrome (RDS), or neurological conditions.1,4,5 Since infants are unable to communicate verbally, it is essential for caregivers to interpret the meaning behind their cries. This understanding is the key to providing appropriate responses to infants. However, infant cries encompass a wide range of meanings, which can make it challenging to interpret them accurately, especially for first-time mothers who lack experience in caring for babies and are more likely to misinterpret than experienced mothers, leading to inappropriate responses. 6
The principles of the maternal sensitivity concept can explain the responsiveness to the infant's needs. 7 This framework includes the dynamic process of perceiving, interpreting, and responding to the infant's signals based on previous caregiving experience and the quality of caregiver–infant interaction. A responsive mother can accurately perceive the infant's signals, interpret, and respond appropriately to enhance infant development and attachment. On the other hand, difficulties in interpreting or responding to infant cries may increase stress and risk of psychological or physical health problems for caregivers. Petzoldt et al. 8 found that first-time mothers of excessive crying infants were more likely to develop anxiety disorders due to a lack of infant care experiences. Similarly, Oberlander and Rotem-Kohavi 9 indicated that an inability to respond to infant cries can contribute to postpartum depression. In terms of physical health effects, Brand et al. 10 indicated that caregivers who struggle with infant crying may experience sleep disturbances, depressive symptoms, and family strain.
The analysis of infant cries has demonstrated that pathological conditions can be evaluated through acoustic cry analysis. Valdes et al. 1 identified specific acoustic features that can distinguish normal cries from pathological cries based on the characteristics of the infant's voice. For instance, healthy cries are typically loud and exhibit an ascending–descending melody pattern with a frequency range of 400 to 650 Hz. In contrast, abnormal cries tend to have a shorter duration, monotonous melody, and a higher frequency than 650 Hz. Infant cries can serve as a valuable tool for identifying pathological conditions in medical diagnosis. For example, in diseases affecting the central nervous system, cries exhibit extremely high frequencies of 3000–4000 Hz. Conversely, in hypothyroidism, the cries have a lower fundamental frequency than normal cries, but the spectrogram is similar to healthy cries. While the differences between normal and pathological cries can be identified based on their acoustic characteristics, distinguishing them with accuracy remains challenging, particularly in medical diagnostics that require precise evaluation.
Traditionally, several studies on infant cries have assumed the existence of distinct cry types, such as hunger, pain, or discomfort cries, which can be acoustically differentiated and classified.2,3,11,12 However, this typological perspective has been challenged by the graded cry hypothesis, which proposes that infant cries vary along a continuum of arousal or distress rather than representing discrete categories.13,14 According to this view, acoustic differences primarily reflect the intensity of distress rather than specific needs. This debate is critical for cry classification studies: if cries are graded rather than categorical, then labeling them as fixed types may impose artificial boundaries. In medical or clinical practice, relying solely on distress levels can make it difficult to diagnose or detect pathological conditions, since pathological cries may share similar acoustic markers with highly distressed but otherwise healthy infants. 15 Therefore, before evaluating how effectively algorithms can classify infant cries, it is essential to consider how the cries are labeled. The labeling process is crucial and should account for how each cry was identified. In clinical and research settings, the practical approach to cry labeling often relies on contextual cues, such as the action that successfully stops the cry or the stimulus preceding it. For example, Liang et al. 16 labeled cries based on the action that stopped the crying (e.g. a hunger cry was identified when the infant stopped crying after being fed) or based on the event that caused the crying (e.g. a pain cry was labeled during invasive procedures). Similarly, Parga et al. 15 ensured labeling reliability by having two medical staff independently identify each audio recording, with pain cries captured during painful stimuli. However, identifying distinct cry types remains challenging, particularly under the graded cry hypothesis, which suggests that cries vary along a continuum of arousal or distress rather than existing as discrete categories. 14 This underscores the need to carefully consider how labels are defined and validated before they are used to train machine learning (ML) models. Additionally, ML approaches learn from acoustic features that vary along a continuum and transform these graded patterns into categorical outputs, bridging the gap between continuous vocal variation and relevant classifications. 17
In the current era of advanced technology, ML has been utilized to help recognize and differentiate infant cries, providing a helpful solution to these problems. ML is the subset of artificial intelligence, which uses algorithms based on the knowledge gained from past data to forecast and make decisions for a specific domain. 18 ML models can predict, categorize, and cluster through supervised learning that algorithms learn patterns from numerical values based on historical data. 19 For example, in adult patients, Jian et al. 20 studied ML classification algorithms to predict and classify eight diabetes complications, reaching 97.8% accuracy. In the field of pediatrics, Tesfaye et al. 21 developed ML to predict childhood anemia using sociodemographic, economic, and maternal and child variables. The accuracy of their predictive performance ranged from 60% to 66%.
In maternal and infant care, ML has been used to classify and recognize infant cries, enhancing caregivers’ understanding of an infant's signals. Although the human ability to understand an infant's cry should not be overlooked, a well-constructed computer system can provide more accurate solutions to audio classification. Mukhopadhyay et al. 22 compared the accuracy performance in differentiating infant cry types between human and ML, with humans achieving 33.09% accuracy. In contrast, ML achieved 80.56% accuracy on the same dataset. Moreover, ML is also utilized in healthcare systems to differentiate between the cries of healthy and sick infants. For example, Zayed et al. 23 applied ML to classify healthy, sepsis, and respiratory distress cries. Similarly, Rosales-Pérez et al. 24 used ML to distinguish between pathological cries (e.g. asphyxia and deafness) and specific need cries (e.g. hunger and pain).
From previous literature reviews on maternal and infant care, several studies have explored the application of ML in predicting neonatal mortality, 25 neonatal outcomes in neonatal intensive care units, 26 preterm birth, 27 and pregnancy complications. 28 However, there is a lack of systematic reviews specifically focusing on the application of ML to classify infant cries based on pattern recognition. Therefore, the purpose of this study is to systematically review the studies on the application of ML in classifying infant cry types and identifying pathological cries, as well as evaluating the accuracy of classification. This review focuses on research studies published between January 2014 and October 2024 to provide the most recent coverage of evidence. The research questions of this study are: (1) How has ML been used to classify infant cry types and pathological cries? (2) How accurately can ML classifier recognize patterns in infant cries?
Methods
Protocol and registration
This systematic review was conducted following the methodological guidelines of systematic reviews and reported according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA 2020) framework. 29 A narrative synthesis approach was employed to describe the findings. The study protocol has been registered with the PROSPERO database (registration number: CRD42024600969).
Eligibility criteria
Inclusion criteria: Studies were included if they focused on classifying infant cries based on needs or detecting pathological cries using ML algorithms. They must also employ observational designs, such as cohort studies, case-control studies, or cross-sectional studies, and infant's age no more than 2 years. The studies published in English between January 1st, 2014 and October 31st, 2024 were included.
Exclusion criteria: Studies were excluded if they did not specify the type of ML classifier, features, or did not report outcomes related to the crying type and performance data of the classifications (accuracy, sensitivity, or specificity rate). To ensure the rigorous and reliability of the review's findings, gray literature, conference proceedings, pilot studies protocols, case studies, dissertations, and editorials were excluded.
Search strategies
In this review, searches were conducted on October 31st, 2024, with the support of a health science librarian across four electronic databases: PubMed, CINAHL, Embase, and IEEE Xplore (Institute of Electrical and Electronics Engineers). The core search strategy focused on the concepts of ML and infant crying, combined with terms related to classification and pattern recognition. To ensure comprehensive coverage, additional search terms included “machine learning” OR “deep learning” AND “infant cries” AND “classification” OR “pattern recognition” along with various commonly used keywords (e.g. “convolutional neural network,” “support vector machine,” “newborn cry,” and “baby cry”). The search terms were applied using database-specific search methodologies and incorporated Boolean operators, Medical Subject Headings (MeSH), and free-text terms tailored to each database—using MeSH terms or title/abstract searches for PubMed, CINAHL, and Embase, and IEEE Terms for IEEE Xplore. For example, the MeSH term “machine learning” is used in various databases as follows: in PubMed it appears as (“Machine learning"[mh]), in CINAHL as (MH “Machine learning+”), in Embase as (“machine learning”/exp), and in IEEE as (IEEE Terms: “Machine learning”). All databases were last searched on October 31st, 2024. The full search strategy is provided in Table S1 of the Supplemental materials.
Selection process and data collection
All searched articles were imported to Rayyan (copyright © 2022), a web-based software application tool for screening studies for systematic reviews, and duplicate studies were removed. Two reviewers (SS and NK) independently screened the articles by title and abstract using a practical screening table developed from the inclusion and exclusion criteria. This table served to guide the reviewer through the screening process and minimize selection bias. Following this initial screening phase, the selected articles were reviewed in full text to assess eligibility and relevance. The articles that did not meet the eligibility criteria were excluded. Any disagreements between the two reviewers were resolved through discussion. If the conflict was not resolved through discussion, the reviewers will consult with a third opinion (SN). This systematic process ensured that only relevant studies were included in the further assessment.
Data extraction
Relevant data from the selected articles was extracted using a predeveloped data extraction form in Microsoft Excel. The main categories for data extraction include (1) General characteristics: this includes information such as the authors and the year of publication, the number of datasets, characteristics of the datasets, and sample size. (2) Performance: this category includes the ML algorithms used as classifiers. (3) Outcomes: this includes classifications of crying types and diagnostic performance metrics, specifically accuracy rate (%), sensitivity (%), and specificity (%). The characteristics of the included studies are presented in Table 2.
Quality assessment
Two reviewers (SS and NK) were assigned and independently assessed the quality of the included studies by using the Quality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) tool. 30 This tool is designed for assessing the quality of primary diagnostic accuracy studies in systematic reviews. The QUADAS-2 consists of four domains: (1) patient selection, (2) index test, (3) reference standard, and (4) flow and timing. Each domain is assessed for risk of bias, and the first three domains are also evaluated regarding applicability. There are 10 questions for assessing the risk of bias aspect and three questions for assessing the applicability. The results are reported as “low risk,” “high risk,” and “unclear risk.”
For the interpretation of overall quality, if all questions within a domain are answered “yes,” the study is judged as having a “low risk,” indicating that appropriate methods and safeguards against bias were clearly reported. A study is considered “high risk” if at least one question within the domain is answered “no,” reflecting evident methodological flaws. An “unclear risk” is assigned when the study provides insufficient information for a judgment. 30 The detailed results of the quality assessment are provided in the Supplemental materials.
Data analysis and synthesis
Data were extracted into an extraction form to tabulate and visually display the results of each study. This review plans to categorize the results into three parts: (1) infant cry type, (2) classifier type, and (3) the accuracy of classification. Moreover, a table was created to show the infant cry type and the ML classifiers used in each study, providing a clear visual representation of the different classifier types. Another table was created to provide the accuracy of classification for each classifier, helping to distinguish and synthesize evidence based on three main groups of ML models: supervised learning, unsupervised learning, and hybrid models. 31 A narrative synthesis has been used to describe the results of a systematic review. Additionally, a pie chart was used to illustrate the proportion of physiological and pathological cry classifications using ML.
Results
Search overview results
Figure 1 illustrates the study selection process, which involved a total of 919 studies identified across four databases. A total of 37 duplicate records were removed using Rayyan. The remaining 882 studies to be reviewed based on their titles and abstracts. There were 840 studies excluded due to not meeting the eligibility criteria. This process resulted in 42 studies being retrieved for full-text review, and two studies32,33 were excluded due to unavailability of full text. As a result, 40 studies were assessed for eligibility, and 23 studies were excluded for several reasons as described in the PRISMA diagram in Figure 1. There were 17 included studies in this systematic review.

PRISMA flow diagram of the included studies.
Included study characteristics
The search yielded the final 17 included studies that were cross-sectional study. The publication years ranged from 2014 to 2024. For the infant cries dataset, 11 studies2–5,11,15,16,23,34–36 utilized self-recorded sounds, five studies12,24,37–39 relied on public databases, and one study 40 did not specify the source as shown in Table 2. In total, there were around 113,677 infant cries, ranging between 300 and 54,744 sounds. For the ML classifiers type, 13 studies2–5,11,15,23,34,36,37,39–41 used supervised learning, two studies35,38 used unsupervised learning, and the remaining two studies12,24 used a hybrid approach, which is detailed in Table 4. Ten studies2,3,11,12,15,16,34,35,37,40 reported on specific cry types related to infants’ needs, four studies4,5,23,36 focused on pathological cries, and three studies24,38,39 addressed both categories.
The distribution of infant cry types is illustrated in Figure 2, which includes nine subtypes. The hunger cry represented the largest proportion, accounting for 29%, followed closely by the pain cry at 27%. Other notable types were the sleepy cry at 12%, the discomfort cry at 10%, the wet diaper cry at 7%, and the burp and fussy cry at 5%. The remaining cry types, holding and cold, constituted a smaller proportion of 3% and 2%, respectively. In Figure 3, the distribution of pathological cry types was presented, divided into six subtypes. The four most prevalent were the sepsis cry and respiratory distress cry, both at 22%, followed by asphyxia at 21% and deafness at 21% as well. The smallest proportions were hypoxic-ischemic encephalopathy (HIE) and asthma, each accounting for 7%.
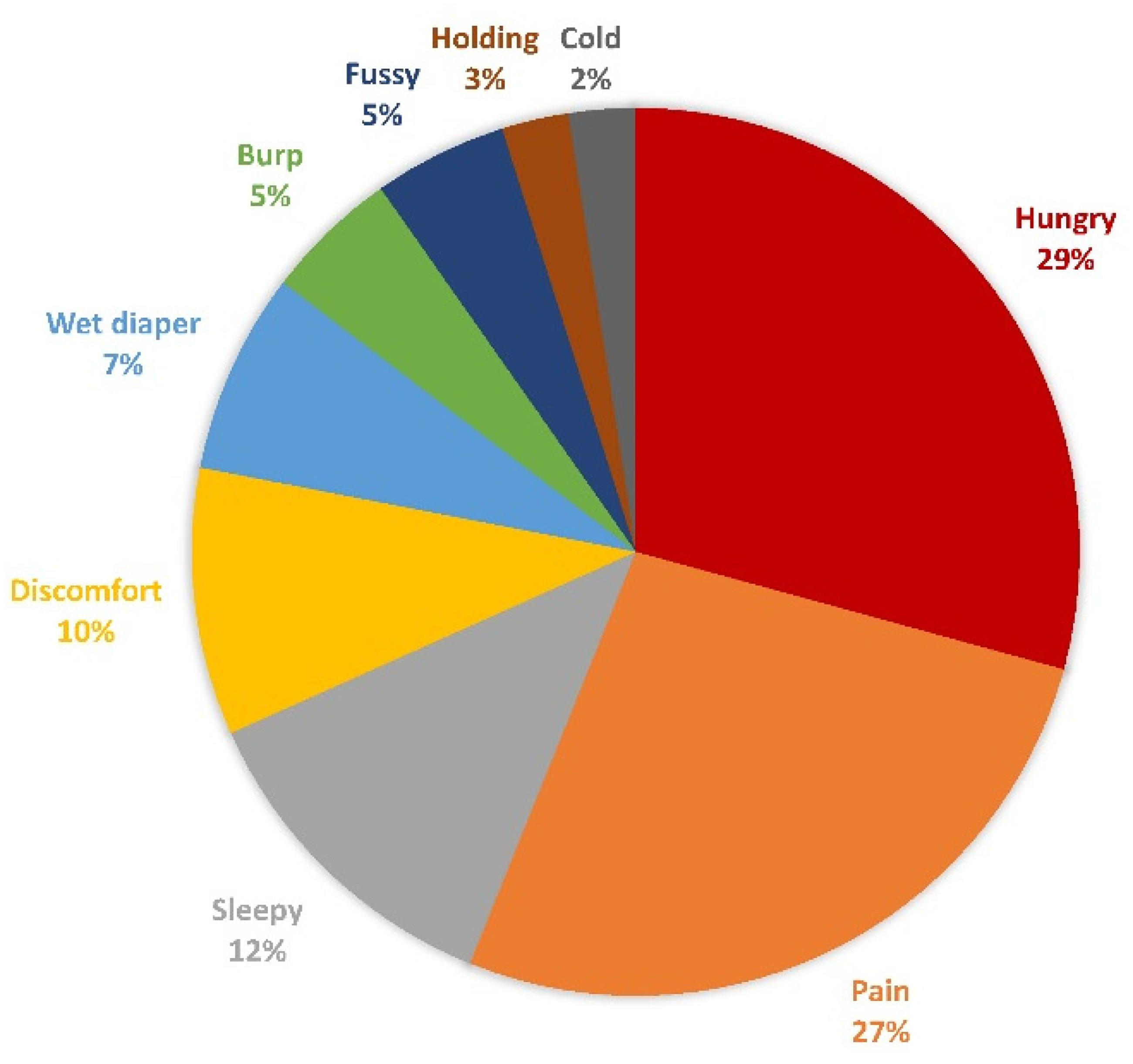
The proportion of infants’ need cry types using machine learning classification.

The proportion of pathological cry types using machine learning classification.
Overview and comparison of existing infant cry databases
The infant cry database from the 17 included studies can be divided into two main types: cry databases and self-recorded datasets. Five studies12,24,37–39 used cry databases, 11 studies used self-recorded datasets, and one study 40 did not specify the dataset source. To evaluate the quality and characteristics of the infant datasets used in this review, each database and self-recorded dataset will be described in detail below.
Infant cry databases in this review include four main datasets: Donate a Cry Corpus, 12 Baby Chillanto Infant Cry,12,24,38,39 Dunstan Baby, 37 and In-House Dhirubhai Ambani Institute of Information and Communication Technology (DA-IICT) Infant Cry. 38 Each database varies in the types of cries, the number of cry samples, and infant age ranges. Donate a Cry Corpus 42 demonstrates diversity across both cry contexts and infant age, as it was developed through a crowdsourced mobile application that enabled global parental participation. However, because it contains 457 audio files across five cry types: belly pain, burping, discomfort, hungry, and tired from an unspecified number of infants aged between 0 and 2 years, the lack of controlled recording environments and limited identity tracking may introduce acoustic variability and background noise that can affect feature extraction accuracy. 43 Baby Chillanto Infant Cry Database 44 was created by the Instituto Nacional de Astrofísica, Óptica y Electrónica in Mexico under the CONACYT program. This database provides medically supervised and structured data collection. It contains 2268 audio recordings with five classes: asphyxia, deaf, normal, hunger, and pain from newborns up to 6 months old, by specialized physicians under controlled conditions. Although it ensures high acoustic quality, the dataset does not fully specify the number of unique infants, limiting transparency into how many samples were obtained per individual. Dunstan Baby45,46 was developed by Priscilla Dunstan with her research team for commercial reasons. Dunstan had experience in opera and as a mother, which allowed her to recognize specific sounds in the human voice. The database contains infant cries from infants aged 6 months or younger in five types: hungry, burp, sleepy, pain, and discomfort. Approximately 83 infant cries in the video were recorded by 39 infants in a studio to eliminate noise. However, its small sample size restricts the dataset's variability and may lead to overfitting. 47 In-House DA-IICT Infant Cry was developed at the Dhirubhai Ambani Institute of Information and Communication Technology in India for research purposes. It includes 1190 cry samples in three categories: healthy, asthma, and HIE, but lacks documentation of the number of participating infants and their ages. Overall, existing infant cry databases differ widely in cry types, infant ages, and the number of recordings, reflecting diverse data collection methods. However, most databases lack detailed information on infant identity and standardized labeling, which limits data transparency and comparability across studies.
The self-recorded datasets created by the authors in each study included a variety of infant cry recordings that differed in several characteristics. The details of these datasets are shown in Table 1, which summarizes three key aspects: infant identity control, recording environment, and preprocessing procedures. For the infant identity control, all studies reported the number of infants in the study, except for four studies.2,3,23,34 Additionally, most studies did not specify how many cry samples were obtained from each infant; only three studies4,23,35 reported this information. This indicates limited control over infant identity and reduced transparency, as the use of multiple samples from the same infant may lead the ML model to recognize the baby's individual vocal characteristics rather than the true acoustic features of different cry types. Likewise, only one study 4 reported the number of exemplars derived from each recording, which further limits transparency. Without control, it is possible that multiple cry samples originated from the same recording session or environment, causing the classifier to rely on background or environmental noise instead of the infant's cry itself. 48 To reduce this limitation, almost all studies, except one, 34 implemented some form of preprocessing to improve the quality of cry recordings and minimize background interference, such as manual removal of noncry sounds, band-pass filtering, or noise suppression algorithms. Overall, most datasets demonstrated attention to noise reduction and preprocessing, which helped ensure that classifiers primarily relied on acoustic features of the infant cry rather than environmental or background noise (Table 2).
Characteristics of self-recorded datasets: infant identity control, recording environment, and preprocessing methods.

CNN: convolutional neural network; HDR: high dynamic range; RDS: respiratory distress syndrome; MFCC: Mel-frequency cepstral coefficient.
The characteristics of the included studies.

AdaBoost: adaptive boosting; AMSI: acoustic multistage interpreter; BCRNet model: bidirectional convolutional recurrent network; Classifier: the extracted features to categorize data into classes; CNN: convolutional neural network; Feature extraction: extracting key acoustic characteristics from audio signals; F-score results: a metric that evaluates a classification model's accuracy; GMM: Gaussian mixture model; LFCC: linear frequency cepstral coefficients; LMS: least mean squares; LPCC: linear predictive cepstral coefficient; MFCC: Mel-frequency cepstral coefficients; MLP: multilayer perceptron; ResNet: residual network; SE-ResNet-transformer: squeeze-and-excitation residual network with transformer module; SVM: support vector machine; VGG: visual geometry group; WOA-VMD: whale optimization algorithm-variational mode decomposition; ZCR: zero-crossing rate.
Infant cries type classification
In a review of 17 included studies, infant cries were analyzed using ML and categorized into two main types: infant's need and pathological cries. Specific need cries or nonpathological include nine types of crying, such as hunger, sleepiness, pain or distress, wet diaper, discomfort, fussiness, the need to burp, a desire for holding or touch, and feeling cold. Pathological cries include six types, such as sepsis, RDS, asphyxia, deafness, asthma, and HIE. Tables 3 and 4 illustrate an overview of these cries, displaying the types of crying, the ML classifiers used, and their performance rates. The two main categories of crying are compared based on the classifiers utilized and their performance rates.
Infant cries type classification and machine learning classifier.

AdaBoost: adaptive boosting; BCRNet model: bidirectional convolutional recurrent network; Classifier: the extracted features to categorize data into classes; CQCC: constant-Q cepstral coefficients; Feature extraction: extracting key acoustic characteristics from audio signals; GFCC: gammatone frequency cepstral coefficient; HIE: hypoxic-ischemic encephalopathy; HR: harmonic ratio; LFCC: linear frequency cepstral coefficient; LMS: least mean squares; LPCC: linear predictive cepstral coefficient; LSTM: long short-term memory; ResNet: residual network; RDS: respiratory distress syndrome; SE-ResNet-transformer: squeeze-and-excitation residual network with transformer module; VGG: visual geometry group; ZCR: zero-crossing rate.
Machine learning classifier types and performance rate.
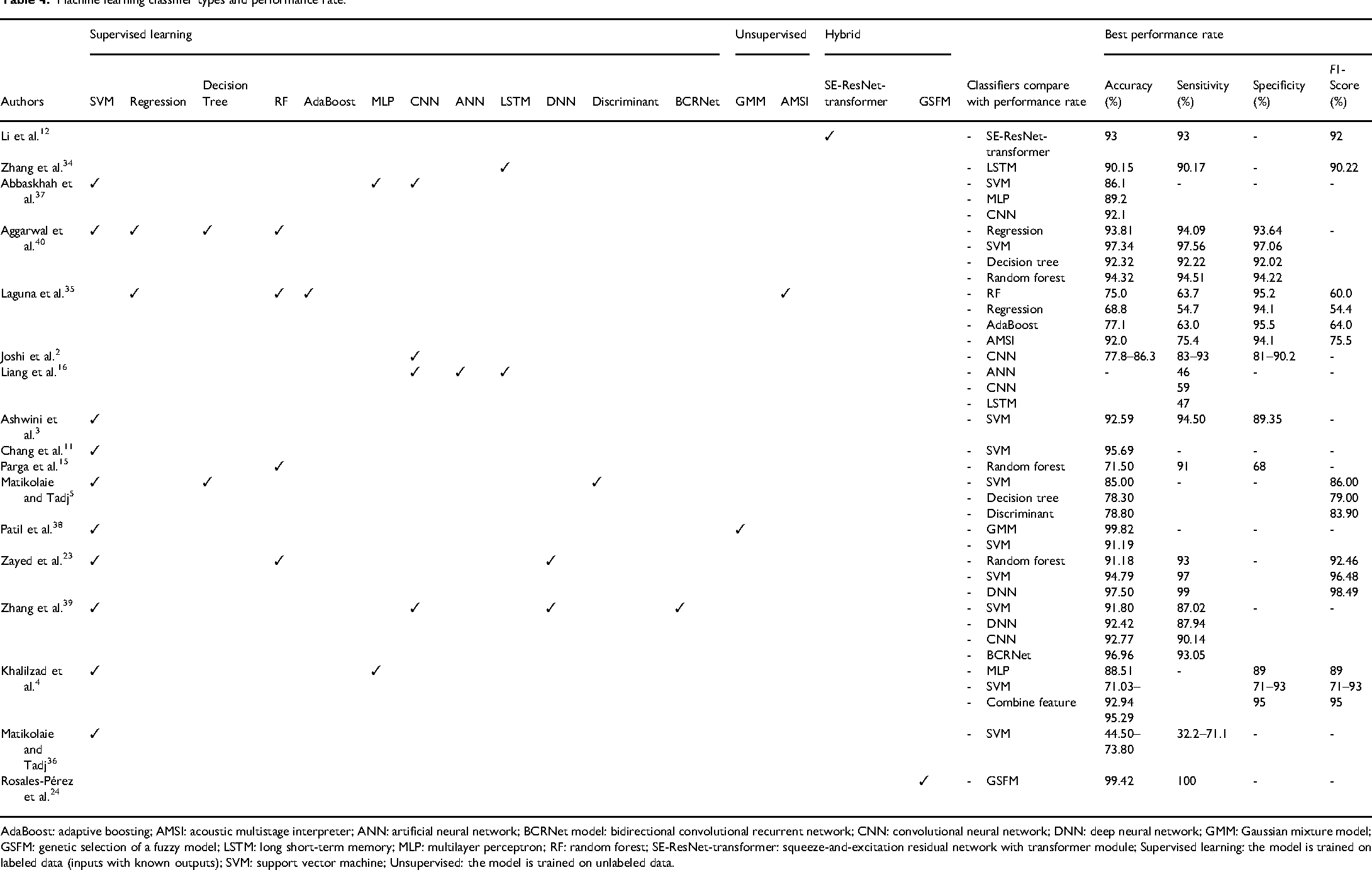
AdaBoost: adaptive boosting; AMSI: acoustic multistage interpreter; ANN: artificial neural network; BCRNet model: bidirectional convolutional recurrent network; CNN: convolutional neural network; DNN: deep neural network; GMM: Gaussian mixture model; GSFM: genetic selection of a fuzzy model; LSTM: long short-term memory; MLP: multilayer perceptron; RF: random forest; SE-ResNet-transformer: squeeze-and-excitation residual network with transformer module; Supervised learning: the model is trained on labeled data (inputs with known outputs); SVM: support vector machine; Unsupervised: the model is trained on unlabeled data.
Infant-specific need cry type or nonpathological cry
The studies on infant-specific cry types identified nine different types of crying that were classified using various classifiers. The performance rate of this classification varied significantly depending on the classifier used. There were 12 studies2,3,11,12,15,16,24,35,37–40 focused on hungry cry, which was the most commonly classified type. The accuracy of hungry cry classifications ranged widely, with performance rates between 68.8% and 99.82%. The highest accuracy of hunger cry was achieved at 99.82% by using a Gaussian mixture model (GMM). Five studies2,3,11,35,37 utilized ML to classify sleepy cry, with accuracy ranging from 66.8% to 95.69%. The best performance (95.69%) was achieved using a support vector machine (SVM). From 11 studies2,3,12,15,16,24,34,3537–39 that mentioned pain cry, the performance varied from 46.0% to 99.82%. The lowest performance rate was classified using an artificial neural network (ANN), while the highest was classified by a GMM. For wet diaper cry, three studies2,16,34 indicated that there was a performance rate ranging from 53.0% to 90.15%. Interestingly, both the highest and lowest performance rates were classified using long short-term memory (LSTM), but they utilized different features. The highest performance rate employed VGG16, while the lowest used Mel-frequency cepstral coefficients (MFCCs). Five studies3,11,12,37,40 reported high accuracy in discomfort cry classification, ranging from 86.1% to 97.34%, with SVM achieving the highest accuracy rate. Additionally, two studies35,37 mentioned burp cry, which showed accuracy from 68.8% to 92.1% that convolutional neural networks (CNNs) were found to be the most effective classifier. The other three specific needs cries of fussiness, a desire for holding, and feeling cold, were reported by a different study with the best performance rates at 92.0%, 35 59.0%, 16 and 90.15%, 34 respectively.
From the performance rate of each infant-specific cry type mentioned above, it is evident that different classifiers achieved the highest accuracy for each different cry type. The best classifiers of each cry type were as follows: a GMM for hungry cries, an ANN for pain cries, an LSTM for wet diaper cries, an SVM for discomfort cries, a CNN for burp cries, and an acoustic multistage interpreter (AMSI) for fussiness. The cries associated with a desire for holding or touch and feeling cold did not have a classifier for comparing accuracy rates. However, the cries indicating feeling cold achieved high accuracy rates when using an LSTM classifier. In contrast, the cries expressing a need for holding or touch had lower accuracy when employed with CNNs. It can be concluded that the best accuracy rate for classifying nonpathological cries was observed for hunger and pain cries, both reaching an impressive 99.82% accuracy by using a GMM classifier.
Pathological cry type
In this review, there were seven studies focused on pathological cry types, which can be classified into six distinct types using various classifiers. There were three studies4,5,16 focused on sepsis cry, revealing performance rates, ranging from 71.03% to 97.50%. Notably, a deep neural network (DNN) achieved the highest performance rate within this range. Three studies4,23,36 mentioned RDS cry and reported that classification accuracy varied significantly, from 44.50% to 97.50%. The highest accuracy was achieved using a DNN, while the lowest accuracy was noted with an SVM. Three studies24,38,39 reported findings for both asphyxia and deafness cries, revealing high accuracy rates. For asphyxia cries, accuracy ranged from 90.68% to 99.82%, while the accuracy for deaf cries was even higher, ranging from 99.42% to 99.82%. Furthermore, a GMM achieved the highest accuracy for both asphyxia and deaf cries. Other pathological cries, such as asthma and HIE, were reported in one study, 38 with performance rates ranging from 91.19% to 99.82%, where GMM achieved the highest accuracy.
From the performance rate of pathological cries mentioned above, it is evident that two classifiers stood out for their high classification accuracy: a DNN and a GMM. A DNN was particularly effective in detecting sepsis and RDS cries. In contrast, a GMM exceled in identifying cries linked to asphyxia, deafness, asthma, and HIE. Notably, the highest accuracy rate for classifying pathological cries was observed for deafness, ranging from 99.42% to 99.82% accuracy by using a GMM classifier.
ML classifier
Performance rate across classifier types
The most commonly used type of classifier for analyzing infant cries is supervised learning, with SVM being the most frequently utilized classifier. SVM has been employed in 10 out of 17 studies and showed a wide accuracy range from 44.50% to 97.34%, indicating high sensitivity to feature quality and combination. Among these, eight studies3,5,11,2337–40 achieved high-performance rates ranging from 85.00% to 97.34%. Five3,11,23,38,39 of these eight studies achieved high performance when multiple acoustic features were combined. For example, Chang et al. 11 achieved 95.69% accuracy using a combination of peak, pitch, MFCCs, ΔMFCCs, and linear predictive cepstral coefficients, while Matikolaie and Tadj 5 obtained 86% accuracy using spectrum features alone. However, when limited to single or less informative features, SVM performance decreased substantially. Two studies4,5 employed SVM as a classifier and reported medium- and low-performance rates. For instance, the study by Khalilzad et al. 4 relied solely on harmonic ratio features, while the research by Matikolaie and Tadj 36 focused on rhythm features, achieving accuracies of 71.03% and 44.50%, respectively. These results demonstrate that SVM can perform very well when supported by diverse, discriminative features, but lacks robustness when relying on narrow or low-quality inputs.
Seven other studies2,12,15,16,24,34,35 did not use an SVM as a classifier but instead employed alternatives, such as CNNs, GMMs, LSTM, regression, random forest, ANNs, and hybrid classifiers. Among these, CNN was the most commonly used for classifying infant cries. Four studies2,16,37,39 applied CNNs, but the performance levels varied, ranging from below 70% to 92.77%. Two studies37,39 achieved high accuracy rates, between 92.10% and 92.77%, while the other two studies reported medium accuracy (70–90%) 2 and low accuracy (less than 70%). 16 The differences in performance can be attributed to the fact that the first two studies,37,39 which achieved high accuracy, utilized high-quality datasets with a large number of infant cries, and the sounds were labeled by expert staff, nurses, or pediatricians who have experience to identify the meaning of infant cry. Additionally, one study 39 integrated advanced architectures such as a bidirectional convolutional recurrent network (BCRNet) model to enhance recognition. In contrast, CNN models trained with single feature or smaller datasets yielded moderate (70–90%) 2 or low (<70%) 16 accuracies. This pattern highlights the strong dependence of CNNs on both dataset quality and architectural complexity.
Among all the classifiers, the GMM demonstrated the highest performance rate in recognizing infant cries at 99.82%. 38 When comparing under the same feature conditions (MFCC), GMM clearly outperformed SVM (98.55% vs. 70.60%), demonstrating its superior capacity to model the probabilistic distribution of acoustic characteristics in infant cries. Similarly, hybrid or ensemble-based classifiers also achieved excellent results; for instance, genetic selection of a fuzzy model (GSFM; 99.42%) 24 and squeeze-and-excitation residual network with transformer module (SE-ResNet-transformer; 93%), 12 suggesting that combining statistical and deep-learning methods can yield near-optimal recognition accuracy.
Other classifiers, though less frequently applied, also showed promising results. Random forest15,23,35,40 and regression models35,40 demonstrated moderate-to-high accuracy (68.8–94.32%), with the best performances observed when integrated into ensemble frameworks. ANNs reported 46% accuracy, 16 while DNNs ranged from 92.42% 39 to 97.50%, 23 showing improvement as model depth increased. LSTM networks, which are designed to capture temporal dynamics, achieved up to 90.15% accuracy 34 but performed modestly (47%) 16 in studies with imbalanced datasets. These findings suggest that temporal models, such as LSTM can be powerful but require extensive data to realize the potential.
Overall, the comparative evidence across studies indicates that GMM consistently delivers the highest classification accuracy, followed closely by hybrid deep-learning architectures (GSFM, SE-ResNet-transformer). SVM remains the most commonly used classifier and can achieve competitive accuracy when multiple features are combined, such as MFCC, tilt, and rhythm yields better performance than using a single feature. Random forest and DNN approaches offer reliable mid-to-high performance, while simpler models such as basic ANNs or regression show moderate accuracy. In summary, integrating multifeature fusion with advanced or hybrid classifiers yields the most robust and accurate recognition of infant cries, whereas models using limited features tend to underperform.
Performance rate across datasets
In this review, the dataset came from two main types: infant cry databases and self-recorded data. For the databases, the infant cry sounds were recorded in hospitals or homes and labeled with the meaning of crying by doctors, nurses, or experts in infant vocalizations. In contrast, self-recorded cries were primarily recorded in hospitals, but many lacked clear labeling during the annotation process. To ensure data quality across different sources, almost all datasets underwent a standardized preprocessing. This involved removing noise, silence, segmenting, and standardizing audio amplitude levels to minimize variability across datasets. Out of 17 studies examined, 11 studies used self-recorded infant cry sounds, five studies12,2437–39 relied on cry databases, and one study 40 did not specify the data source. To evaluate the accuracy across the datasets, the performance rates of infant cries from both types were compared. Data from 11 self-recorded studies showed a performance rate ranging from 44.50% to 97.50%. In contrast, the cry databases exhibited a higher performance rate between 86.1% and 99.82%. In a comparison of self-recorded and cry databases using the same classifier and features with SVM and MFCC features, the self-recorded dataset from the study by Matikolaie and Tadj 5 achieved a performance rate of 86.00%. In contrast, the cry databases used in the study by Patil et al. 38 achieved a higher performance rate of 88.11%. Therefore, infant cries from cry databases tend to achieve slightly higher accuracy compared to self-recorded datasets. This is because datasets from cry databases undergo verification, data validation, and preprocessing by experts (pediatricians and nurses) with experience in interpreting infant cries and labeling the reason for crying by cause, and applying appropriate actions to stop it. This process enhances the quality of infant cries accuracy to understand the meaning behind the infant cries.
The comparison of the accuracy rate by the chance level across studies
When comparing the accuracy rates across studies, the chance level serves as a crucial reference point for interpreting algorithmic performance. Chance level, determined by the proportion of the majority class in each dataset, reflects the baseline accuracy that a naive classifier could achieve by always predicting the most frequent category. Table 5 presents the chance level accuracy, reported accuracy in each study, and the improvement above chance. From the included studies, chance levels varied, ranging from 21.64% to 61.71% for need-based cry classification and from 25.42% to 56.43% for pathological cry classification. Ten studies2,3,11,12,24,34,3537–39 demonstrated substantial improvements above chance of more than 50%, indicating that their reported accuracies were meaningful beyond random or naive prediction. The highest improvements were observed in studies by Patil et al., 38 which had more balanced datasets, resulting in improvements ranging from 65.77% to 74.4%, and provided more robust evidence of discriminative ability.
The chance level accuracy, reported accuracy, and the improvement above chance.

RDS: respiratory distress syndrome; Chance level: The estimated accuracy based on the largest class proportion in each dataset.
In contrast, five studies4,16,23,36,40 with high class imbalance (chance level greater than 50%), achieved high raw accuracies but relatively small improvements above chance, which may overestimate the actual discriminative ability of the models. One study 5 reported performances near or below chance level for subsets, indicating limited practical utility. These findings emphasize that the direct comparison of raw accuracy across studies is limited. Future work should consistently report classification performance relative to the chance level to allow for meaningful cross-study comparisons.
Quality assessment results
The Quality Assessment of Diagnostic Accuracy Studies-2 30 was utilized to evaluate the quality of the included studies, which can be divided into two parts: risk of bias assessment and applicability. Overall, 15 studies were considered as low risk, while two studies34,40 were classified as high risk. In the risk of bias assessment within the selection domain, 15 studies did not specify the process for the random selection of patients, resulting in an unclear risk. Furthermore, the two studies34,40 did not provide information about patient characteristics, which was considered a high risk that threatened internal validity. All 17 studies are considered to have a low risk in the index test, reference standard, and flow and timing domains. For the applicability assessment, 15 studies demonstrated a low risk in the selection domain, while two studies34,40 had an unclear risk, which reduces confidence in generalizing the results to the population and poses a threat to external validity. Regarding the index test and reference standard domains, all 17 studies had a low risk, as they employed a strong process for measure validation. Therefore, the results can be regarded as having high confidence for generalization and application in classifying infant cry types. A quality assessment of each study is provided in Table S2 of the Supplemental materials (see Figures 4 and 5).

Quality assessment results of risk of bias by domain in QUADAS-2. QUADAS-2: Quality Assessment of Diagnostic Accuracy Studies-2.

Quality assessment results of applicability by domain in QUADAS-2. QUADAS-2: Quality Assessment of Diagnostic Accuracy Studies-2.
Discussion
This systematic review synthesizes findings from 17 studies on the application of ML to classify infant cry types, as well as the accuracy of this classification. The results revealed that ML can differentiate between two main types of cries: infants’ needs cries and pathological cries. Various classifiers were employed for these cry types, with each being suited to specific cry types and impacting performance rates differently. For specific-need cries, the highest classification accuracy achieved was 99.82%, 38 with hunger and pain cries being the most accurately classified types by using GMMs. In pathological cries, GMMs also achieved the highest accuracy for detecting pathological cries related to deafness, which was the most accurately classified, ranging from 99.42% to 99.82%. 38 The results clearly show that GMMs can effectively classify both nonpathological and pathological cries with a high accuracy. This finding is consistent with the research conducted by Jebarani et al., 49 who used various ML classifiers, including GMMs, SVMs, and K-means, to detect breast cancer by categorizing magnetic resonance images as either cancerous or noncancerous. Their study indicated that GMMs achieved the best classification accuracy, reaching 93.80%. Additionally, Khlaifi et al. 50 applied GMMs to classify swallowing sounds and other sounds during food intake in adult patients recovering from stroke, achieving an accuracy ranging from 85.57% to 95.94% in distinguishing swallowing sounds. Therefore, GMMs are considered the best classifier for classifying specific conditions in both sound and image.
Nevertheless, an SVM was the most commonly used classifier for both specific-need and pathological cries; however, its performance rate varies depending on the features used and requires multiple features to enhance its performance. When comparing GMMs and SVMs using the same classifier, it was found that GMMs consistently outperformed SVMs. These results align with the findings of Sen et al., 51 who compared the classification performance of SVMs and GMMs in distinguishing between healthy and pathological pulmonary conditions based on pulmonary sounds. Their study revealed that GMMs achieved higher accuracy than SVMs in pulmonary sound classification. Therefore, it can be concluded that a GMM appears to be the best classifier to classify specific conditions.
Furthermore, dataset quality can affect the accuracy rate of infant cries classification. It was found that the infant cry databases have a higher accuracy of infant cries than self-record datasets. These results are consistent with the findings of Ji et al., 52 who reviewed infant cry analysis and observed that cry databases demonstrated higher accuracy compared to self-recorded datasets. Specifically, infant cry databases achieved accuracy rates ranging from 71.68% to 97.96%, whereas self-recorded datasets ranged from 62.1% to 91.58%. This difference is attributed to the fact that infant cry databases undergo a sound validation process and are annotated by experts to accurately label the meanings of the infant cries. The experts mentioned in the included studies refer to pediatricians and nurses who have experience in identifying the causes of infant crying and applying appropriate actions to stop it.
The dataset used in this review comprises four main databases: Donate a Cry Corpus, 12 Baby Chillanto Infant Cry,12,24,38,39 Dunstan Baby, 37 and In-House DA-IICT Infant Cry. 38 The Donate a Cry Corpus includes five cry types: belly pain, burping, discomfort, hunger, and tiredness. The Baby Chillanto dataset contains five types: deaf, asphyxia, normal, hunger, and pain. The Dunstan Baby dataset includes hunger, need for a burp, need to poop, discomfort, and sleepy. The In-House DA-IICT dataset consists of three types: normal, asthma, and HIE. While these datasets provide valuable resources for infant cry analysis, they also present potential biases. Several datasets are imbalanced, with some cry types (e.g. hunger or discomfort) being overrepresented, while others (e.g. asthma or HIE) are limited in size. This imbalance may reduce generalizability, with models favoring frequent cry types. Future work should address this through data augmentation, balanced sampling, present infant identity controls, or broader collection of representative cry samples.
There are some inconsistencies regarding the age of infants that should be considered when training and analyzing ML models. Some studies4,23,36 have indicated that newborns aged 1 to 53 days begin to gain control over their vocalizations during this period. Before this age, vocalizations are primarily regulated by independent biological rhythms and may indicate the newborn's health. Recent evidence from Lockhart-Bouron et al. 13 suggests that human infants gradually transition from producing mainly noisy and shrill cries to more tonal and melodious cries from birth up to nearly 4 months of age, with no significant differences observed between sexes. This underscores the importance of exploring the appropriate age of infants to be used in ML to enhance accuracy rates and facilitate broader development in the future. Additionally, future research on infant cry analysis should aim to develop a standard dataset that can be utilized globally as a gold standard.
The application of ML to identify and classify the meanings of infant crying is essential for enhancing real-world parenting support. Currently, numerous initiatives are underway to integrate ML systems into mobile applications, facilitating their use in everyday situations. A recent research conducted by Mekhfioui et al. 53 presented ML experiments that employed three models: CNNs, Wav2Vec 2.0, and DistilHuBERT, to classify infant crying sounds into distinct categories, including hunger, discomfort, tiredness, and belly pain. The findings demonstrated that while all models exhibited commendable performance, DistilHuBERT achieved the highest accuracy (86.95%) compared with CNNs (83.93%) and Wav2Vec 2.0 (81.52%), along with the best overall metrics. Due to its advantageous balance of high accuracy and low computational cost, DistilHuBERT has been identified as the most effective model for real-time implementation on embedded systems and mobile applications. Future research should explore ways to further improve the techniques tailored to real-world conditions and apply them to mobile applications.
Conclusion
ML has demonstrated significant potential in classifying infant cries, effectively differentiating between types of cries related to the infant's needs and pathological cries. The need-based cries have nine subtypes, while pathological cries are categorized into six subtypes. Various classifiers have been employed to recognize the patterns in these cries. The accuracy of recognizing infant cries varies depending on the ML classifier and the features used for analysis. According to the studies reviewed, the accuracy rates range from 44.5% to 99.82%. Among the classifiers tested, the GMM achieved the highest performance rates, reaching 99.82% accuracy for hunger and pain cries, and between 99.42% and 99.82% for deafness-related cries. These advancements indicate that ML shows strong potential for accurately classifying infant cries and detecting pathologies. This capability is crucial for healthcare and everyday life, as it supports the early detection of health issues and improves infant care. Future research should focus on developing diverse cry datasets to improve model generalizability, evaluating performance in real-world settings, and integrating cry analysis with physiological signals to enhance diagnostic accuracy.
Limitations
This systematic review excluded gray literature, such as conference proceedings, dissertations, and editorials, and was limited to studies published in English. The exclusion also omitted articles published in other languages or indexed in other databases, which may have introduced publication bias. Among the included studies, there were issues with unclear patient selection processes in the datasets, leading to an unclear risk of bias in the selection domain. One study 40 did not report the sources or characteristics of the infant's cries, limiting transparency. Additionally, the studies reviewed did not consider the baby's identity, including factors such as age, sex, height, and weight, nor did they account for how many infants were recorded crying or how many sounds came from a single infant in their analysis of baby cries. It is crucial to incorporate this information into classification models to avoid issues like overfitting, pseudoreplication, and the false inflation of recognition accuracy. For the comparison of the accuracy rate with the chance level, the findings highlight that a direct comparison of raw accuracy across studies can be misleading and reinforce the importance of reporting performance relative to the chance level to enable meaningful cross-study comparisons. The heterogeneity of datasets, including differences in cry categories, class balance, and recording environments, further limits the ability to directly compare algorithmic performance. Future research should consistently report chance-level baselines, include balanced datasets, and incorporate complementary metrics such as balanced accuracy, Cohen's kappa, or F1-score to better reflect actual model performance.
Implication
This systematic review can serve as a foundation for future research, which should include subgroup analyses or meta-analyses to compare the performance of different ML classifiers across various types of infant cries. Additionally, it should evaluate the accuracy and reliability of infant cry datasets from online databases to identify the most accurate and standardized dataset. Establishing a globally recognized standard dataset for infant cries could enhance the consistency and reliability of ML applications in this field.
In a cultural issue application, there is a concern about applying infant cries to different cultures. The study by Cornec et al. 54 examined the perception of infant crying across communities in the Democratic Republic of Congo, comparing it to analogous data from French and British samples to assess the perception by adults across diverse cultures. The findings revealed no significant differences between Congolese and European populations in the acoustic structure of babies’ cries. This finding is consistent with the study by Gustafson et al., 55 which found no difference in crying between infants born in a Mandarin Chinese-language environment and those born in an American English-language environment. Therefore, based on the evidence, it is reasonable to believe that ML can be applied to analyze infant crying across all cultures.
In clinical practice, ML can be applied to the early detection of infant conditions and the monitoring of infant health through cry analysis, enabling doctors and medical staff to promptly identify potential diseases. For example, ML systems can assist healthcare professionals in recognizing abnormal crying linked to specific medical conditions, such as asphyxia, asthma, or respiratory distress. Additionally, integrating ML-based cry analysis into bedside monitoring or mobile diagnostic devices would enable healthcare providers to receive real-time alerts for atypical cry patterns, complementing traditional clinical assessments. Beyond clinical facilities, ML-based cry analysis can also support parental education and telehealth applications, particularly for first-time parents or those in remote areas. When embedded in mobile health devices, ML algorithms can provide parents with immediate feedback, promoting appropriate caregiving responses.
However, several barriers may limit implementation in real-world settings. These include the high cost of developing and maintaining advanced ML systems, the need for well-labeled datasets, the need for validation across different clinical populations, and the need for specialized training for healthcare providers to correctly interpret and respond to system outputs. Additionally, disparities in access to technology across different healthcare settings can pose significant challenges. Therefore, effective clinical practice also necessitates training for healthcare providers and the development of technical systems for the application of infant cry analysis.
Supplemental Material
sj-docx-1-sci-10.1177_00368504251410776 - Supplemental material for The application of machine learning for infant cries classification and pathological cries detection: A systematic review
Supplemental material, sj-docx-1-sci-10.1177_00368504251410776 for The application of machine learning for infant cries classification and pathological cries detection: A systematic review by Sudhathai Sirithepmontree, Nattasit Katchamat and Sasitara Nuampa in Science Progress
Supplemental Material
sj-docx-2-sci-10.1177_00368504251410776 - Supplemental material for The application of machine learning for infant cries classification and pathological cries detection: A systematic review
Supplemental material, sj-docx-2-sci-10.1177_00368504251410776 for The application of machine learning for infant cries classification and pathological cries detection: A systematic review by Sudhathai Sirithepmontree, Nattasit Katchamat and Sasitara Nuampa in Science Progress
Footnotes
Acknowledgments
The authors sincerely thank Professor Dr. Hyekyun Rhee and Professor Dr. Lorraine Olszewski Walker for their invaluable guidance and support in elaborating this work.
Ethical considerations
This review was based on previously published literature available in public databases and did not involve any human participants or the collection of new data; therefore, ethical approval was not required.
Author contributions
SS conceptualized the study and designed the review protocol. SS and NK performed the literature search, screened articles, and extracted data. SN resolved any discrepancies. SS, NK, and SN contributed to data analysis and interpretation. SS drafted and revised the manuscript. All authors have read and approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.