
Abstract
Accurate plant counting is essential for tobacco yield estimation and planting density regulation. However, manual quadrat surveys are inefficient and error-prone, and conventional detectors often suffer from feature loss and background confusion under complex field conditions. This study proposes an improved YOLOv8n framework, YOLOv8-AKConv-MLCA, tailored for UAV imagery of plain-field and mountain-field tobacco. First, an Alterable Kernel Convolution (AKConv) module is embedded inside the original C2f blocks to replace all conventional convolutions, enabling adaptive sampling and richer multi-scale representation of small and densely distributed targets. Second, a mixed local channel attention (MLCA) module is inserted between the last C2f-AKConv block and SPPF to fuse local spatial cues with global channel dependencies, suppressing clutter and occlusion effects. Extensive experiments on UAV datasets show that the proposed model achieves counting accuracies of 97.20% (plain-field) and 96.13% (mountain-field), improving over baseline YOLOv8 by 3.98% and 3.25%, respectively. Detection metrics likewise improve: mean average precision (mAP) reaches 0.936 and 0.914 in the two scenarios, surpassing SSD (0.844, 0.827), Faster R-convolutional neural network (0.865, 0.842), and a Transformer-based variant (YOLOv8-Trans, 0.923, 0.907). Relative to YOLOv8, maximum gains of 12.1% in precision, 1.9% in recall, and 7.3% in mAP are observed. Crucially, real-time throughput is preserved, with inference speeds of 219–227 frames per second across datasets. Grad-CAM visualizations further confirm that YOLOv8-AKConv-MLCA concentrates attention on canopy regions and suppresses background interference, offering intuitive evidence of enhanced feature learning. Overall, the proposed framework delivers a strong accuracy–efficiency trade-off and robust generalization under complex terrain, providing an effective solution for automated tobacco plant counting and supporting precision cultivation and smart agricultural management. Code and trained weights are available upon reasonable request for replication and evaluation.
Introduction
Tobacco is an important economic crop in China, and the accurate estimation of its yield is directly related to industrial benefits. The number of transplanted plants serves as a key indicator for yield prediction and planting density regulation, making precise quantification essential. 1 At present, plant counting in tobacco fields largely relies on manual quadrat surveys, which are labor-intensive, time-consuming, and highly susceptible to human error. These limitations are particularly evident in large-scale plantations and mountainous tobacco-growing areas, where the method fails to meet the requirements of modern agriculture for efficient and real-time monitoring. 2
With the rapid advancement of smart agriculture, deep learning techniques—owing to their strong feature extraction and pattern recognition capabilities—have achieved remarkable progress in crop recognition, pest and disease monitoring, and growth assessment. 3 Among these, the You Only Look Once (YOLO) series of single-stage detection models has gained wide attention due to its balance between detection accuracy and inference speed. 4 Nevertheless, traditional YOLO models still face limitations in tobacco plant detection: in densely planted fields, mountainous terrain, and complex backgrounds, targets are often occluded, vary in scale, or overlap, leading to missed and false detections and reducing the model's stability and reliability. 5 UAV remote sensing technology, with its advantages of low cost, high resolution, and operational flexibility, has become an important tool in agricultural monitoring. Against this background, combining UAV imagery with deep learning for automatic tobacco plant counting has gradually become a research hotspot. 6
Previous studies have shown the potential of such methods across different crops and environments. For instance, Wang et al. 7 utilized UAV imagery to detect sugarcane plants by extracting white midribs and applying clustering analysis to locate plant centers, achieving an average recognition accuracy of about 86%. Zhu et al. 8 proposed an improved YOLOv5 model that replaced the conventional prediction head with a Transformer and introduced a self-attention mechanism, enhancing contextual modeling and achieving an average precision (AP) of 39.18% on the VisDrone dataset. Shahid et al. 9 developed a UAV-based tobacco plant counting framework that bypassed traditional orthomosaic construction, directly performing image-level detection and counting. This framework integrated U-Net segmentation, YOLOv7 detection, and SORT tracking, achieving F1 scores ranging from 0.947 to 0.967 across multiple fields. In addition, Wu et al. 10 proposed the AAPW-YOLO model, which improved the YOLOv8 backbone with Alterable Kernel Convolution (AKConv), optimized feature fusion with ASFP2, and employed a Wise-IoU loss function. Their approach reduced parameters by 30% in UAV small-object detection while increasing mean average precision (mAP)@0.5 by 3.6% and 2.5%, achieving a good balance of accuracy and robustness. Recent studies have increasingly explored Transformer-based and attention-enhanced models in agricultural vision tasks. Dai et al. 11 developed a lightweight Vision Transformer optimized with a Lite-AVPSO strategy, showing that combining local and global attention can improve feature generalization in complex agricultural environments. However, these Transformer-based methods mainly focus on classification and segmentation, and their high computational cost limits their suitability for real-time UAV-based small-object detection and counting.
In the field of small-object detection, existing approaches predominantly rely on techniques such as super-resolution reconstruction,
12
multi-scale feature fusion,
13
contextual information modeling,
14
and attention mechanisms
15
to enhance detection performance. In addition, several studies have introduced novel network designs, such as the SSAM attention module and the MPFPN structure,
16
which further improve detection accuracy. Nevertheless, in complex terrain conditions, the detection of tobacco plants still faces considerable challenges, including recognition difficulties and limited precision, indicating the need for further advancements
17
:
In dense or small-target scenarios, objects are small and frequently occluded, making feature extraction more difficult; Repeated down-sampling operations often cause fine details of small targets to be lost, reducing detection accuracy; In both plain-field and mountain-field environments, visual similarities among weeds, soil, and tobacco leaves cause background interference.
To address these issues and improve detection performance, this study proposes an improved lightweight YOLOv8s-based method. Specifically, an AKConv module is introduced into the backbone, embedded into the original C2f modules and replacing all Conv layers. Through its adaptive sampling mechanism, AKConv enhances multi-scale feature extraction, particularly for small and densely distributed plants. Furthermore, a mixed local channel attention (MLCA) module is inserted between the final C2f-AKConv block and the SPPF structure, enhancing the model's capability to detect small and dense targets. This design improves accuracy and robustness under complex backgrounds, while maintaining computational efficiency.
Materials and methods
Study area and data acquisition
The study was conducted in the tobacco-growing region of Xiyi Township, Longyang District, Baoshan City, Yunnan Province, China (24°55′43.11″N, 99°19′18.89″E). A total area of 4 hm² of tobacco fields was selected for investigation. UAV imagery was acquired using a DJI M3 M equipped with a high-resolution camera. The flight was conducted at an altitude of 30 m, with a horizontal velocity of 3 m/s, a forward overlap of 75%, a side overlap of 80%, and a gimbal pitch angle of −90°. Data collection was performed under clear-sky conditions 20 days after transplanting, between 10:00 and 14:00 local time. Representative field tobacco and mountain tobacco plots are shown in Figure 1. Field tobacco was cultivated in relatively flat areas with slopes less than 5°, whereas mountain tobacco was grown in hilly areas with slopes greater than 5°. The topographic distribution of field and mountain tobacco is illustrated in Figure 2, where the average slope of the mountain tobacco planting area was approximately 15°.

Tobacco field image. (a) Plain-field tobacco; (b) mountain-field tobacco.

Topography map of the tobacco field. (a) Plain-field tobacco; (b) mountain-field tobacco.
Dataset construction
The UAV-acquired tobacco images were manually annotated using LabelImg 1.8.6 software. All tobacco plants were labeled under a single category, “T,” and enclosed with rectangular bounding boxes. The annotations were saved in .txt format and the dataset was randomly divided into training, validation, and test sets at a ratio of 7:2:1. During the image acquisition stage, environmental variability was fully considered to ensure dataset representativeness and robustness, Table 1. The dataset covered diverse conditions, including strong sunlight, backlighting, cloudy weather, rainy and foggy conditions, wind disturbance, and image blurring. 18 After data augmentation, a total of 8350 field tobacco images and 7910 mountain tobacco images were obtained, Figure 3

Illustration of data augmentation.
Dataset division statistics for plain-field and mountain-field tobacco.

Detection methods
YOLOv8 model
As illustrated in Figure 4, YOLOv8 was released by Ultralytics in 2023 as a further extension of the YOLO series, aiming to achieve a balance between practicality and performance. This version integrates the lightweight characteristics of YOLOv5 with the structural optimization advantages of YOLOv7. 19 It adopts a new backbone structure, YOLOX-P, and fully transitions to an anchor-free detection paradigm, thereby simplifying the anchor box configuration process and improving detection efficiency. YOLOv8 also incorporates an enhanced SimOTA-v2 label assignment strategy, which accelerates training convergence and improves accuracy. In addition, diverse data augmentation techniques and lightweight design further strengthen its deployment capabilities on edge devices. With an emphasis on engineering usability and inference performance, YOLOv8 is well-suited for a wide range of real-world application scenarios. 20

Overview of the YOLOv8 network structure.
Improved YOLOv8 framework
The application of deep learning networks in complex real-world scenarios has significant practical value for detection tasks. In this study, an optimized strategy based on YOLOv8 was proposed to effectively detect tobacco plants under diverse and complex terrain conditions. The main improvements are summarized as follows: First, a lightweight dynamic convolution module, AKConv, was incorporated into the backbone network. Specifically, AKConv operators were embedded within the original C2f modules, replacing all conventional convolutional layers inside them while retaining the C2f's residual and feature aggregation structure. Through its adaptive sampling mechanism, AKConv enhances multi-scale feature capture and significantly improves the representation of small and densely distributed targets. Second, a MLCA module was inserted between the final C2f-AKConv block and the SPPF structure in the backbone. By fusing local spatial details with global channel dependencies, MLCA strengthens the model's robustness against complex background interference and enables more precise attention to key regions. Together, these improvements provide a balanced optimization between detection accuracy and computational efficiency. The overall architecture of the improved YOLOv8-AKConv-MLCA model is illustrated in Figure 5.
AKConv Module

YOLOv8-AKConv-MLCA network structure. AKConv: Alterable Kernel Convolution; MLCA: mixed local channel attention.
Classical convolutional neural networks (CNNs) utilize fixed-shape convolutional kernels to slide across input images for local feature extraction. However, in scenarios with complex backgrounds, large variations in target scales, or blurred boundaries, the static sampling nature of conventional convolutions often fails to sufficiently capture critical regions, thereby limiting detection performance. 21 To address this issue, the AKConv module with dynamic adjustment capability was introduced in this study. By incorporating deformable sampling structures and weight-learning mechanisms, AKConv enables the convolution process to flexibly adapt to variations in image content, thereby enhancing both the accuracy and adaptability of feature extraction.
Unlike standard convolution, the weights in AKConv are trainable and the sampling positions can be dynamically adjusted, thereby overcoming the spatial constraints of traditional regular sampling (Figure 6). The input feature map is defined as (C, H, W), where C represents the number of channels, and H and W denote the height and width of the image, respectively. 22 The workflow of AKConv includes initial feature sampling, offset generation, resampling, feature fusion, and normalization. Specifically, convolutional layers are first employed to generate sampling offsets (Offset). These are combined with the original coordinates through weighted summation to form new sampling positions (Modified Coordinates), thereby enabling spatially adaptive sampling and enhancing the perception of details such as boundaries and textures. The resampled feature maps are then processed and fused for subsequent extraction. 23

AKConv network structure. AKConv: Alterable Kernel Convolution.
AKConv provides three distinct feature-processing schemes (Figures 7–9), designed for strong local perception, lightweight networks, and improved sensitivity to irregular targets, respectively. By integrating spatial attention mechanisms with offset-control strategies, AKConv effectively suppresses interference from irrelevant regions. This advantage is particularly pronounced in low-level feature extraction, where AKConv demonstrates stronger spatial responsiveness than standard convolution, allowing the network to focus on discriminative regions and thereby improve detection accuracy.24,25

C, N, H, W algorithm.

C (N, H, W) calculation*.

Feature interaction and adaptive aggregation process in the AKConv module. AKConv: Alterable Kernel Convolution.
In this study, AKConv modules were incorporated into the backbone of YOLOv8 by embedding them within the C2f blocks and replacing the conventional convolutional layers. This modification enhances the model's ability to capture critical regions at lower feature levels, mitigating recognition difficulties caused by complex backgrounds, while simultaneously reducing redundant computations and parameters. Consequently, AKConv not only improves detection performance but also supports lightweight design and efficient inference.
MLCA—mixed local channel attention
The Squeeze-and-Excitation (SE) attention mechanism was first proposed by Jie Hu et al. in 2018, 26 aiming to enhance the discriminative capability of neural networks by adaptively learning the importance weights of feature channels. As illustrated in Figure 10, the SE structure consists of two key operations: “Squeeze,” which aggregates global spatial information into a channel descriptor, and “Excitation,” which adaptively recalibrates channel-wise feature responses through learned weights.

SE attention structure diagram.
In the squeeze stage, the input feature map (U) undergoes global average pooling, which compresses the original feature map of size (H × W × C) into a single vector of dimension (1 × 1 × C). This process captures the global contextual information across channels by aggregating spatial features, thereby generating a compact channel-wise descriptor of the feature map.
27
The computation can be expressed as follows:
In the excitation stage, two fully connected layers are employed to learn channel weights and achieve feature recalibration. The first layer compresses the global descriptor into a lower dimensional space, thereby reducing the number of parameters while extracting inter-channel relationships, with nonlinearity introduced by the ReLU activation function.
28
The second layer restores the representation to its original channel dimension, and a Sigmoid function is applied to constrain the output within the range [0, 1], yielding the attention coefficients for each channel. The formulation is expressed as follows:
After completing the squeeze and excitation operations, the SE module multiplies the generated channel-wise weight coefficients with the corresponding channels of the input feature map (U), thereby achieving feature reweighting. This operation strengthens the response to salient information while suppressing redundant features, enhancing the network's selective attention capability. As a result, the model becomes more focused on task-relevant regions, thereby improving its discriminative power.
29
The channel-wise reweighting is computed as follows:
Traditional channel attention mechanisms rely on global average pooling, which tends to overlook local spatial variations within channels, thereby weakening the representation of salient regions. The local SE (LSE) approach addresses this by partitioning the feature map into multiple patches and applying SE operations independently to each patch, thus preserving spatial information. However, this strategy substantially increases the number of parameters and computational cost. As illustrated in Figure 11, the MLCA module refines this approach by balancing channel modeling, spatial preservation, and computational efficiency.
30
Specifically, the feature map is first divided into spatial patches (e.g. 5 × 5 or 7 × 7), and each patch is reweighted using a LSE mechanism, thereby retaining structural textures and semantic features of subregions. Furthermore, a one-dimensional convolution is introduced to enable neighborhood interactions across channels, where the kernel size k is determined by the number of channels C according to the following equation: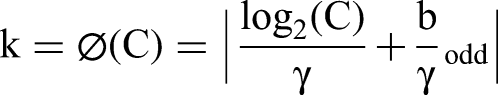

Principle of the mixed local channel attention (MLCA) algorithm.
At the same time, MLCA computes global channel attention to capture long-range dependencies, fusing local and global attention maps. After upsampling to restore the original dimensions, the fused attention is reweighted with the input feature map to generate enhanced representations. By appropriately configuring the patch size, the computational cost of MLCA remains comparable to that of conventional lightweight attention mechanisms. Compared with ECA, MLCA preserves spatial information while capturing fine-grained channel interactions, and relative to LSE, it significantly reduces the number of parameters and GFLOPs. Overall, MLCA demonstrates a favorable balance under multiple configurations.31,32
Experimental environment and configuration
The experiments were conducted on a desktop computing platform equipped with a GeForce RTX 4060 GPU and running the Windows 11 operating system. The deep learning framework adopted was PyTorch 2.1, with Python 3.9.2 as the programming language. During model training, the total number of epochs was set to 200, with a weight decay coefficient of 0.005 and a batch size of 8. The initial learning rate was 0.001, and a cosine annealing learning rate decay strategy was applied, reducing the minimum learning rate to 0.01 to balance convergence speed and training stability. For detection, the confidence threshold was set to 0.5 to ensure the reliability and accuracy of the predictions.
Model evaluation
To evaluate the deviation between the predicted and measured values and to reflect the overall correctness of the prediction results, the relative error and accuracy were calculated.

To evaluate the performance of the proposed model in object detection, four metrics were employed: Recall, Precision, mAP, and Frames Per Second (FPS).
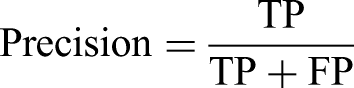
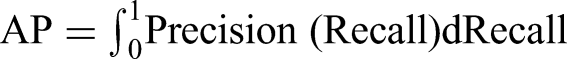

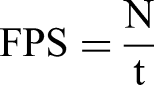
Here, TP (True Positive) denotes the number of tobacco plants correctly identified by the model, FN (False Negative) represents the number of tobacco plants that were not detected, and FP (False Positive) refers to the number of non-tobacco targets that were incorrectly classified as tobacco plants. AP indicates the AP of the i-th category, and N refers to the total number of tobacco plants.
Results
Experimental results of the improved model
As shown in Tables 2 and 3, the recognition accuracy of the three models—YOLOv8, YOLOv8-AKConv, and YOLOv8-AKConv-MLCA—was compared across two scenarios: flatland tobacco and mountainous tobacco. The results indicate that the improved YOLOv8 models consistently outperformed the original YOLOv8 under different conditions.
Accuracy of different models for plain-field tobacco.

AKConv: Alterable Kernel Convolution; MLCA: mixed local channel attention.
Accuracy of different models for mountain-field tobacco.

AKConv: Alterable Kernel Convolution; MLCA: mixed local channel attention.
For flatland tobacco recognition, YOLOv8-AKConv-MLCA achieved an accuracy of 97.20%, representing an improvement of 3.98% over the baseline YOLOv8, with a prediction error of only −2.80%. In the mountainous tobacco scenario, its accuracy reached 96.13%, which is 3.25% higher than that of YOLOv8. In terms of modular contributions, the AKConv module improved accuracy by 1.72% in flatland and 1.67% in mountainous tobacco detection. Upon further integration of the MLCA module, performance was significantly enhanced. These findings demonstrate that the AKConv module effectively strengthens multi-scale feature extraction, particularly for dense and scale-varying small targets, while the MLCA module enhances the model's ability to focus on task-relevant features by incorporating hybrid channel–spatial attention mechanisms. Consequently, the integration of both modules reduces the risk of missed and false detections, thereby improving overall detection robustness.
Ablation study
To evaluate the independent contributions and combined effects of the proposed modules, ablation experiments were conducted under identical training configurations and dataset conditions (Table 4). The results demonstrate that both the AKConv and MLCA modules consistently enhanced model performance, and their integration produced a cumulative improvement.
Ablation experiment results for different types.
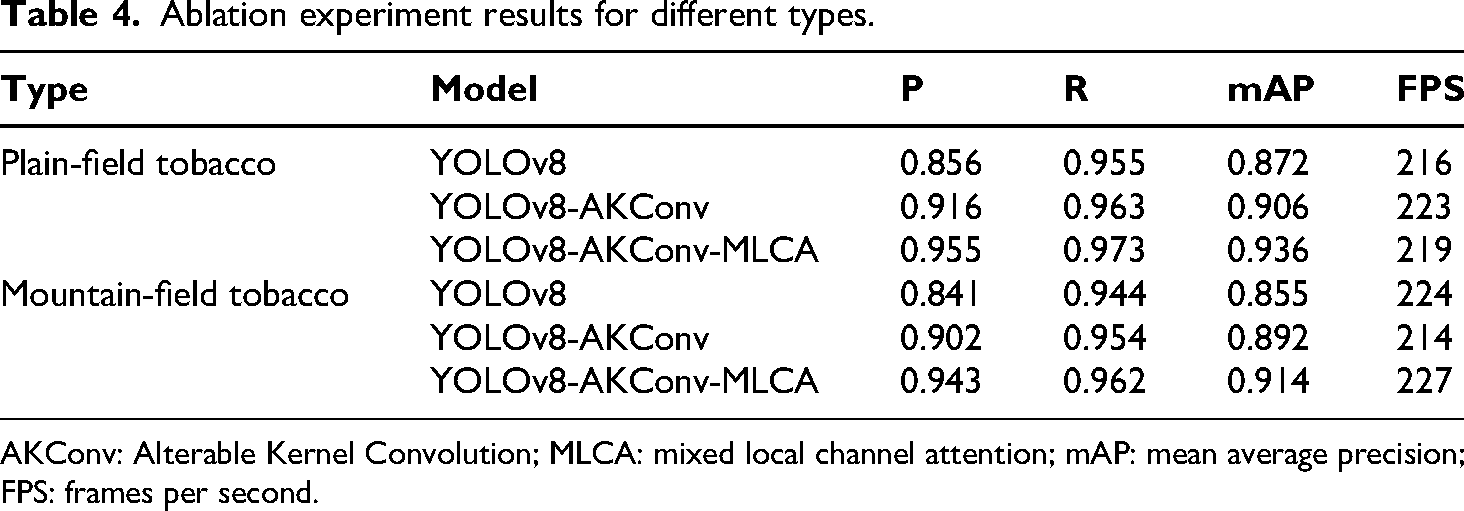
AKConv: Alterable Kernel Convolution; MLCA: mixed local channel attention; mAP: mean average precision; FPS: frames per second.
In the flatland tobacco scenario, YOLOv8-AKConv achieved improvements of 7.0%, 0.8%, and 3.9% in Precision, Recall, and mAP, respectively, compared with the baseline YOLOv8. With the additional integration of the MLCA module, the overall gains increased to 11.6%, 1.9%, and 7.3% for the three metrics. In the mountainous tobacco scenario, YOLOv8-AKConv yielded improvements of 7.2%, 1.1%, and 4.3%, while YOLOv8-AKConv-MLCA achieved total increases of 12.1%, 1.9%, and 6.9%, respectively.
It is noteworthy that all three models maintained high real-time performance in terms of FPS. Specifically, YOLOv8 operated at an average of 216–224 FPS, while YOLOv8-AKConv and YOLOv8-AKConv-MLCA fluctuated between 214 and 227 FPS. These findings indicate that the performance enhancements did not come at the expense of inference speed, thereby ensuring a balanced trade-off between accuracy and efficiency.
Figure 12 illustrates the training comparison results of different models on the flatland tobacco dataset. The loss function curves indicate that, with the progressive introduction of adaptive convolution kernels (AKConv) and MLCA, the models exhibited markedly accelerated convergence and enhanced stability. Among them, YOLOv8-AKConv-MLCA achieved the lowest loss values, highlighting its superiority in strengthening feature representation and suppressing background interference. YOLOv8-AKConv also outperformed the original YOLOv8, as reflected by lower loss values and faster convergence. The validation set mAP curves further demonstrate that YOLOv8 achieved the lowest accuracy, while the integration of AKConv significantly improved precision. With the additional incorporation of MLCA, the mAP reached the highest level, remained stable, and converged more rapidly.

Plain-field tobacco training and validation chart.
Figure 13 presents the ablation results on the mountainous tobacco dataset, which reveal trends consistent with those observed in the flatland scenario. YOLOv8-AKConv-MLCA exhibited superior convergence, the lowest final loss values, and the highest mAP, with the latter approaching 1.0. These results validate the effectiveness and robustness of the proposed improvements across different cultivation environments.

Mountain-field tobacco training and validation chart.
Figures 14–17 present a comparative analysis of YOLOv8 and its improved variants in detecting and counting tobacco plants under both flatland and mountainous conditions. In the flatland scenario, YOLOv8 produced relatively regular detection bounding boxes with confidence scores ranging from 0.4 to 0.7, whereas the YOLOv8-AKConv-MLCA model achieved the highest accuracy with the lowest missed detection rate, demonstrating its suitability for large-scale field monitoring. In the mountainous scenario, although YOLOv8 generated orderly bounding boxes, the improved YOLOv8-AKConv-MLCA model again exhibited superior performance, highlighting its stronger generalization ability and better adaptability to complex terrain environments. Moreover, through Grad-CAM visualization, the YOLOv8-AKConv-MLCA model showed a more concentrated focus on the canopy regions of tobacco plants and effectively suppressed background interference compared with the YOLOv8 and YOLOv8-AKConv models, providing intuitive evidence of its enhanced feature extraction and attention capabilities.

Comparison of detection effects for plain-field tobacco.

Comparison of Grad-CAM heatmaps for plain-field tobacco.

Comparison of detection effects for mountain-field tobacco.

Comparison of Grad-CAM heatmaps for mountain-field tobacco.
Comparison with other algorithms
As shown in Table 5, all YOLOv8-based models consistently outperformed the traditional SSD and Faster R-CNN frameworks across both plain-field and mountain-field tobacco datasets. In the plain-field scenario, the baseline YOLOv8 achieved a mAP of 0.872, while the introduction of the AKConv module increased mAP to 0.906 by enhancing multi-scale feature extraction. Incorporating a lightweight Transformer structure, YOLOv8-Trans further improved the global contextual modeling capability, achieving an mAP of 0.923. Nevertheless, the proposed YOLOv8-AKConv-MLCA achieved the highest performance with a precision of 0.955, recall of 0.973, and mAP of 0.936, which represent overall improvements of 0.099, 0.018, and 0.064 over the baseline YOLOv8, respectively, while maintaining a real-time inference speed of 219 FPS.
Comparison results of different models.

AKConv: Alterable Kernel Convolution; MLCA: mixed local channel attention; mAP: mean average precision; CNN: convolutional neural network; FPS: frames per second.
In the mountain-field scenario characterized by higher background complexity and steeper slopes, the same trend was observed. YOLOv8-Trans reached an mAP of 0.907 but incurred a lower frame rate (205 FPS) due to its Transformer encoder, whereas the proposed YOLOv8-AKConv-MLCA attained the best balance between accuracy and efficiency, with precision, recall, and mAP of 0.943, 0.962, and 0.914, respectively, at 227 FPS. In contrast, SSD and Faster R-CNN produced mAP values below 0.865 in both environments and failed to maintain real-time performance. These results clearly demonstrate that while Transformer-based architectures enhance feature representation, the hybrid convolution–attention design of YOLOv8-AKConv-MLCA achieves superior accuracy, robustness, and computational efficiency for multi-terrain tobacco plant detection and counting.
Conclusion
This study developed an improved YOLOv8 framework, named YOLOv8-AKConv-MLCA, for accurate and efficient tobacco plant detection and counting across plain-field and mountain-field conditions. The model integrates an AKConv module into the backbone, replacing all conventional convolutional layers inside the original C2f blocks, and introduces a MLCA module between the final C2f-AKConv block and the SPPF structure. These two modules jointly enhance multi-scale feature representation and adaptive attention allocation, enabling the model to handle small, dense, and occluded targets effectively under complex terrain conditions.
Experimental results demonstrated significant performance improvements. On the plain-field dataset, the model achieved a precision of 0.955, a recall of 0.973, and an mAP of 0.936 at 219 FPS, corresponding to a counting accuracy of 97.20%. On the mountain-field dataset, the model achieved a precision of 0.943, a recall of 0.962, and an mAP of 0.914 at 227 FPS, with a counting accuracy of 96.13%. These results verify that YOLOv8-AKConv-MLCA achieves a better balance between detection accuracy and inference efficiency than the baseline YOLOv8.
Compared with classical detectors (SSD and Faster R-CNN) and a Transformer-based model (YOLOv8-Trans), the proposed method obtained higher precision and mAP values while maintaining real-time detection capability. Grad-CAM visualizations further confirmed that YOLOv8-AKConv-MLCA concentrates attention on canopy regions and effectively suppresses background interference. Overall, the proposed model demonstrates superior robustness and generalization across diverse terrain conditions, providing a reliable foundation for UAV-based tobacco plant counting, planting density regulation, and intelligent agricultural monitoring. Future work will focus on integrating multi-temporal UAV data and lightweight Transformer modules to further improve model adaptability and scalability.
Footnotes
Acknowledgment
The authors acknowledge the financial supports of Yunnan Provincial Technology Project of China Tobacco Corporation (2022530000242001, 2021530000242013) and the Project of China Tobacco Hunan Industrial Co., Ltd (KY2022JD0001, KY2020JD0008, KY2025JD0002).
Author contributions
Conceptualization was done by XZ and YZ; methodology was done by YL; validation was done by KY and JZ; formal analysis was done by YL; investigation was done by XZ; resources was collected by HL, JF, and ZH; data curation was done by YL; writing—original draft preparation was done by XZ; writing—review and editing was done by YZ; visualization was done by ZH; supervision was done by KY; project administration was done by JZ; funding acquisition was done by XZ. All authors have read and agreed to the published version of the manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Yunnan Provincial Technology Project of China Tobacco Corporation (2022530000242001, 2021530000242013) and the Project of China Tobacco Hunan Industrial Co., Ltd (KY2022JD0001, KY2020JD0008,KY2025JD0002).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/ or publication of this article.
Data availability statement
The datasets generated and analyzed during the current study are not publicly available due to confidentiality agreements with the cooperating agricultural institutions but are available from the corresponding author on reasonable request.