
Abstract
As a pivotal task within computer vision, object detection finds application across a diverse spectrum of industrial scenarios. The advent of deep learning technologies has significantly elevated the accuracy of object detectors designed for general-purpose applications. Nevertheless, in contrast to conventional terrestrial environments, remote sensing object detection scenarios pose formidable challenges, including intricate and diverse backgrounds, fluctuating object scales, and pronounced interference from background noise, rendering remote sensing object detection an enduringly demanding task. In addition, despite the superior detection performance of deep learning-based object detection networks compared to traditional counterparts, their substantial parameter and computational demands curtail their feasibility for deployment on mobile devices equipped with low-power processors. In response to the aforementioned challenges, this paper introduces an enhanced lightweight remote sensing object detection network, denoted as YOLO-Faster, built upon the foundation of YOLOv5. Firstly, the lightweight design and inference speed of the object detection network is augmented by incorporating the lightweight network as the foundational network within YOLOv5, satisfying the demand for real-time detection on mobile devices. Moreover, to tackle the issue of detecting objects of different scales in large and complex backgrounds, an adaptive multiscale feature fusion network is introduced, which dynamically adjusts the large receptive field to capture dependencies among objects of different scales, enabling better modeling of object detection scenarios in remote sensing scenes. At last, the robustness of the object detection network under background noise is enhanced through incorporating a decoupled detection head that separates the classification and regression processes of the detection network. The results obtained from the public remote sensing object detection dataset DOTA show that the proposed method has a mean average precision of 71.4% and a detection speed of 38 frames per second.
Introduction
Remote sensing object detection, as a fundamental visual task, has found widespread applications in various domains such as national defense and security inspections, maritime ship detection, and disaster prediction.1,2,3,4 With the advent of deep learning technologies, remote sensing object detection networks have witnessed remarkable progress, achieving significant improvements in both detection accuracy and speed. 5 However, compared to standard object detection images, remote sensing images present challenges such as large scale, complex backgrounds, varying object scales, and severe interference from background noise as shown in Figure 1. The variability in object orientations also makes it difficult for object detection networks to accurately locate bounding boxes. These issues collectively hinder the further enhancement of remote sensing object detection network performance.1,6 In response to the above problems, researchers have put forward distinct solutions. Su et al. proposed a multiscale striped convolutional attention mechanism (MSCAM) that reduces the introduction of background noise, fuses multiscale features, and enhances the model's focus on various-sized foreground objects. 7 Li et al. strengthened the fused features of the neural network through the use of spatial and channel attention mechanisms, transforming the original network's fusion structure into a weighted structure for more efficient and richer feature fusion. 8 Shen et al. integrated the Swin Transformer into the neck module of YOLOX, enabling the recognition of high-level semantic information and enhancing sensitivity to local geometric feature information. 9 However, while some existing methods have achieved improvements in accuracy, they ignore the adaptive adjustment ability of the network and the positioning function of the rotating box in the large-scale background. To tackle the challenges outlined above, this paper introduces an enhanced lightweight remote sensing object detection network, denoted as YOLO-Faster. Firstly, to minimize network parameters and enhance inference speed, we integrate the lightweight FasterNet10,11 into YOLOv5 as the foundational network. Secondly, to tackle the issue of detecting objects of varying scales in large-scale scenes, an adaptive multiscale feature fusion network is introduced. This is achieved by embedding a receptive field adaptive adjustment (RFAA) block within the original YOLOv5 feature integration network. The RFAA block utilizes a gated selection mechanism to refine and filter features extracted by large-scale convolutional kernels, dynamically adjusting the large receptive field to capture dependencies among different scales. This approach facilitates better modeling of object detection scenarios for various objects in remote sensing scenes. Lastly, a Decoupled Head is employed at the network's output, utilizing two parallel prediction branches for bounding box regression and target category classification, respectively. The decoupled head enhances the expressive capabilities and convergence speed of the object detection network in complex backgrounds with noise. To this end, YOLO-Faster ensures both the lightweight requirements for mobile deployment and maintains detection accuracy for remote sensing object detection networks.

Remote sensing object detection data samples in the detection scene.
To sum up, our contributions can be summarized as follows:
We introduce YOLO-Faster, a lightweight remote sensing object detection network that merges the strengths of YOLOv5 and FasterNet. Results from experiments conducted on the public dataset DOTA showcase YOLO-Faster's success in achieving network lightweighting without compromising accuracy in object detection tasks. To address the challenges of complex backgrounds and varying object scales in remote sensing object detection scenarios, we introduce an adaptive multiscale feature fusion network to replace the original YOLOv5 feature integration network. This network utilizes a gated mechanism to filter features extracted by different large-scale convolutional kernels, dynamically adjusting the receptive field of the object detection network. Through the integration of a decoupled object detection head into YOLOv5, we elevate remote sensing object detection by separating the responsibilities of bounding box regression and classification. This strategy enhances both the expressiveness and convergence speed of the object detection network, especially in challenging scenarios characterized by noise.
Related works
Method of deep learning object detection
Presently, deep learning-based object detection networks can be primarily categorized into one-stage object detection networks and two-stage object detection networks. 12 On the one hand, one-stage object detection networks, exemplified by the SSD, YOLO series (YOLOv3, YOLOv4, YOLOv5),13,14,15,16 eliminate the generation of object candidate regions and instead directly predict the object's bounding boxes and categories through the grid where the object center resides. On the other hand, two-stage object detection networks, represented by the RCNN series of algorithms (including Fast R-CNN and Faster R-CNN),12,17 utilize a region proposal network to generate candidate regions for the objects to be detected. These candidate regions are then refined to accurately locate the object's bounding boxes. Both one-stage and two-stage object detection networks have their respective advantages and disadvantages. One-stage detection algorithms achieve quicker detection speeds but frequently compromise on detection accuracy due to the absence of a refinement process for bounding boxes, typically inferior to that of two-stage object detection networks. In contrast, two-stage object detection networks deliver superior detection accuracy but tradeoff for slower detection speeds, attributed to the dual-stage procedure employed in bounding box localization. The above mentioned existing general object detection algorithms are primarily applied to land-based object detection, and have good detection performance on datasets such as the COCO 18 dataset and the PASCAL VOC 19 dataset. However, when faced with remote sensing object detection tasks that involve large-scale scenes and varying object sizes, their performance is often limited.
Application in deep learning remote sensing object detection
With the development of deep learning technology, its application in remote sensing object detection tasks is increasing. To solve the above-mentioned problems encountered in deep learning for remote sensing object detection. Li et al. proposed RSI-YOLO, 20 which integrated channel attention mechanism and spatial attention mechanism into YOLOv5 network and modified the loss function to improve the detection accuracy of the object detector in remote sensing object detection tasks ; Su et al. proposed MSA-YOLO, 7 which proposed an MSCAM to reduce the introduction of background noise and fuse multiscale features, enhancing the focus of various sizes of foreground objects; Chen et al. embedded a pyramid squeeze attention mechanism for key feature extraction and designed a context information module to enhance the network's context understanding ability 21 ; Lang et al. constructed efficient channel attention layers to improve channel information sensitivity. 22 Differential evolution algorithm can automatically find the optimal anchor configuration to solve the problem of large target scale changes. Gao et al. propose a novel global-to-local scale-aware detection network for remote sensing object detection. 23 Nevertheless, deep learning models often require a large amount of computational resources, which is not conducive to deployment at the edge.
Research on lightwight networks
As mentioned above, despite the substantial enhancement in detection accuracy brought about by deep learning-based object detection networks, they frequently incur larger parameter sizes and heightened computational demands in contrast to conventional methods. Lightweighting object detection networks for deployment on low-power processors on mobile devices for real-time object detection remains a prominent research focus. Mark et al. proposed the MobileNet network, 24 which introduces a residual structure to reduce parameter sizes while maintaining the network's feature extraction capabilities. Zhang and their team introduced the ShuffleNet network,25,26 which enhances interaction between features extracted by depthwise separable convolutions through a channel shuffle method. Chen et al. pointed out that although lightweight networks based on depthwise separable convolutions reduce the number of floating-point operations (FLOPs), their effective FLOPS are often lower due to frequent memory access. To address this, they proposed an efficient lightweight network called FasterNet, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. 11
In order to address the detection challenges in remote sensing objects, this paper aims to research on enhancing network lightweight design, large-scale background adaptive adjustment capability, algorithm robustness, and other aspects.
Methods
In this Section, we will provide a detailed introduction to the proposed YOLO-Faster. Its overall structure is visually depicted in Figure 2. Specifically, in Section Review of YOLOv5, we will revisit the theoretical foundations of YOLOv5. Following that, Section The backbone of YOLO-Faster will elucidate the backbone network, FasterNet, employed by YOLO-Faster. Section Adaptive multi-scale feature fusion network will introduce the proposed adaptive multi-scale feature fusion network. In Section Multi-scale decoupled object detection head, we will delve into the application of decoupled detection heads within YOLOv5. Finally, Section Loss function will outline the utilized loss function.

The overall structure of YOLO-Faster. “Faster Block” represents backbone feature extraction module whose detail structure is introduced in the following section; “RAFF Block” denotes receptive field adaptive adjustment block; “Conv2d” denotes standard convolution operation; “BatchNorm” denotes batch normalization; “SiLU,” “GELU,” and “Hardsigmoid” denote activation function; and “Adaptive Avgpool2d” denotes adaptive average pooling operation.
Review of YOLOv5
YOLOv5, positioned as a pioneering object detection algorithm, achieves a remarkable equilibrium between detection precision and processing speed. The YOLOv5 network architecture consists of four main components: the Input, Backbone, Neck, and Output. Figure 3 illustrates the structural configuration of YOLOv5.

The structure of YOLOv5.
At the input stage, data Augmentation techniques such as random flipping, random rotation, and Mosaic augmentation are employed to enrich the training dataset and mitigate the risks of overfitting during the training process. Notably, the Mosaic data augmentation method involves randomly stitching together four images, which are then fed into the YOLOv5 network. For feature extraction, YOLOv5 utilizes the CSPDarkNet, incorporating modules like Focus slices, convolutional residual blocks, and the spatial pyramid pooling module. 27 In the Neck for feature aggregation, the pyramid attention network (PANet) 28 is employed to blend high-level semantic information from different scales with low-level semantic details. Finally, at the output stage, cascaded convolutional modules are used to predict object bounding boxes, confidence scores, and category information. The integration of these techniques and architectural components allows YOLOv5 to maintain a robust detection performance while optimizing detection speed, making it a popular choice for various real-world applications.
The backbone of YOLO-Faster
Despite the robust feature extraction capabilities of the CSPDarkNet employed in the original YOLOv5 object detection network, it carries a substantial parameter size and demands significant computational resources. This paper aims to explore a lightweight backbone network for integration into the YOLOv5 architecture, enabling the deployment of object detection networks on low-power processors for mobile applications. FasterNet, through its examination of memory access mechanisms in convolutional operators, introduces an efficient convolutional operator called PConv to enhance the effective operations per second. For feature maps containing significant primary information, conventional convolutional operators are used for feature extraction. However, for feature maps with redundant feature information, identity mappings are employed to directly transfer these to the next layer's feature map, preventing unnecessary computations on ineffective information. The calculation formula is as follows:
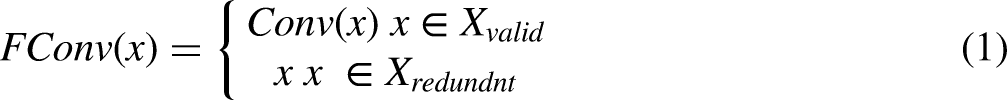

Compared to conventional convolution operations, the computational cost (FLOPs) of PConv in FasterNet is significantly reduced. The formulas for calculating the computational cost of both regular convolution operations and PConv in FasterNet are as follows:

Based on PConv, an efficient convolutional module called Faster Block is further proposed. The final lightweight backbone network, FasterNet, is constructed by stacking multiple layers of Faster Blocks. By replacing the backbone network of YOLOv5 with FasterNet, the operational efficiency of the object detection network is enhanced while maintaining detection accuracy. A schematic diagram illustrating the structures of PConv and Faster Block is provided in Figure 4.

Diagram of the structure of PConv and faster block.
Adaptive multiscale feature fusion network
The original YOLOv5 object detection network employs PANet as the neck network to concatenate features of different dimensions in the channel dimension, followed by convolutional operations to integrate semantic information of various scales. For land-based images with rich target features, PANet effectively fuses multiscale semantic information flows. However, when dealing with remote sensing images with large-scale complex backgrounds, a substantial amount of irrelevant background noise causes significant interference during the multiscale feature fusion process. To address this issue, this paper introduces an RFAA module that adaptively adjusts the receptive field of the object detection network to filter out ineffective semantic information from the background. A schematic diagram of the RFAA Block structure is provided in Figure 5. Within this block, GAP and GMP denote Adaptive Global Average Pooling and Adaptive Global Max Pooling, respectively, while S represents the sigmoid activation function. The RFAA Block follows a Transformer architecture design, initially performing adaptive adjustments to the features and then refining them through a feed-forward neural network (FFN) consisting of two multilayer perceptrons. The calculation formula for this process is as follows:
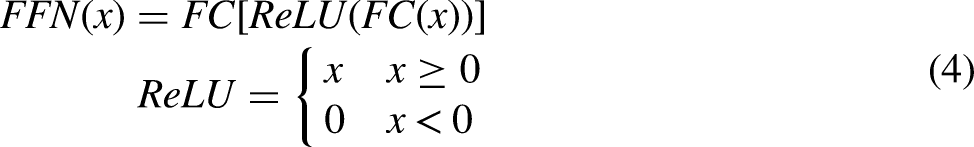

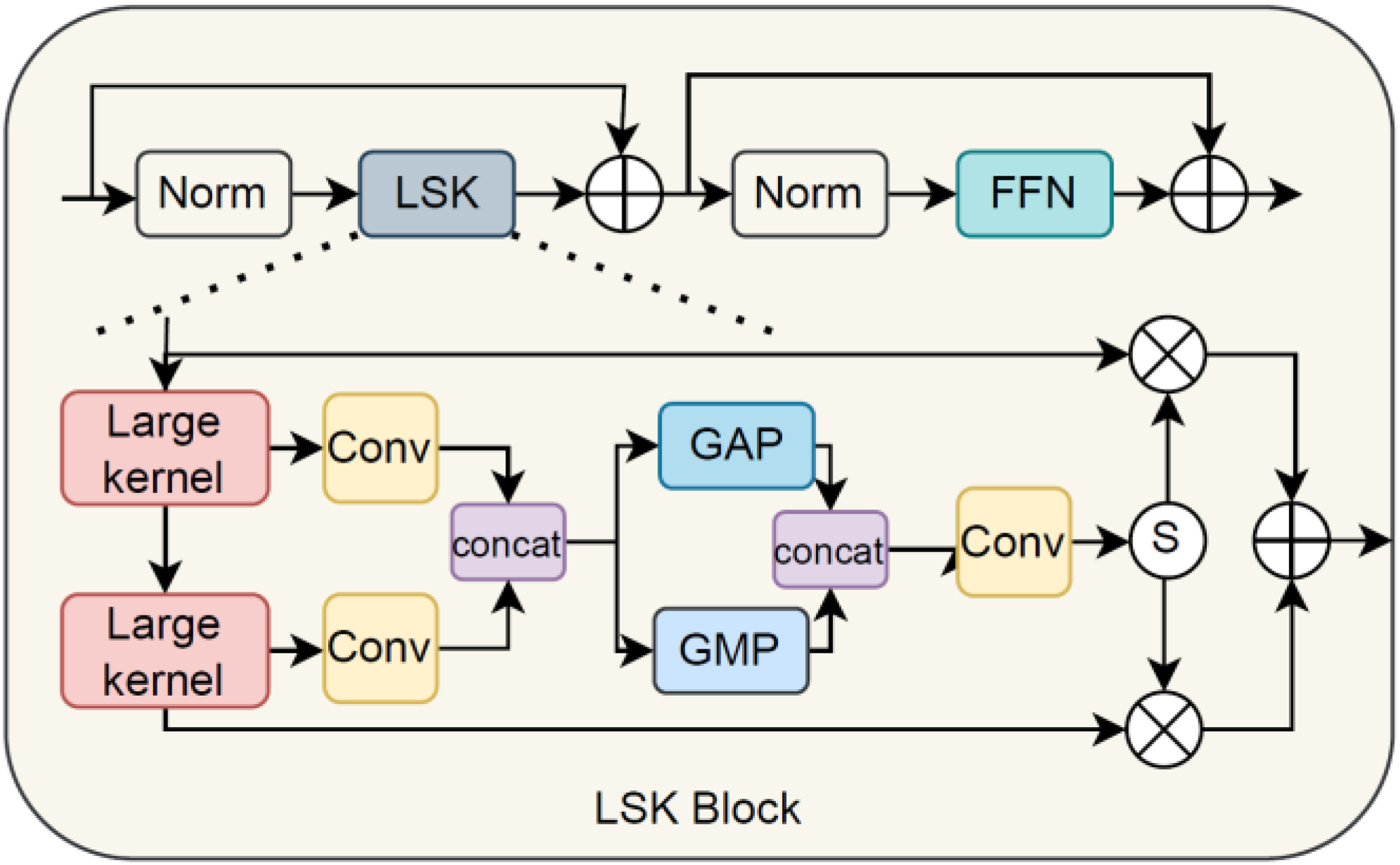
Schematic diagram of the RFAA block structure. Norm represents layer normalization, S represents sigmoid function, GMP and GAP denote global max pooling and global average pooling, respectively.
Multiscale decoupled object detection head
YOLOv5 adopts different detection heads to detect targets of different scales, and fuses features of different scales through an adaptive multiscale feature integration network to obtain a set of feature maps. The backbone and the feature synthesis network AMFFN produce a total of three different scales of feature maps
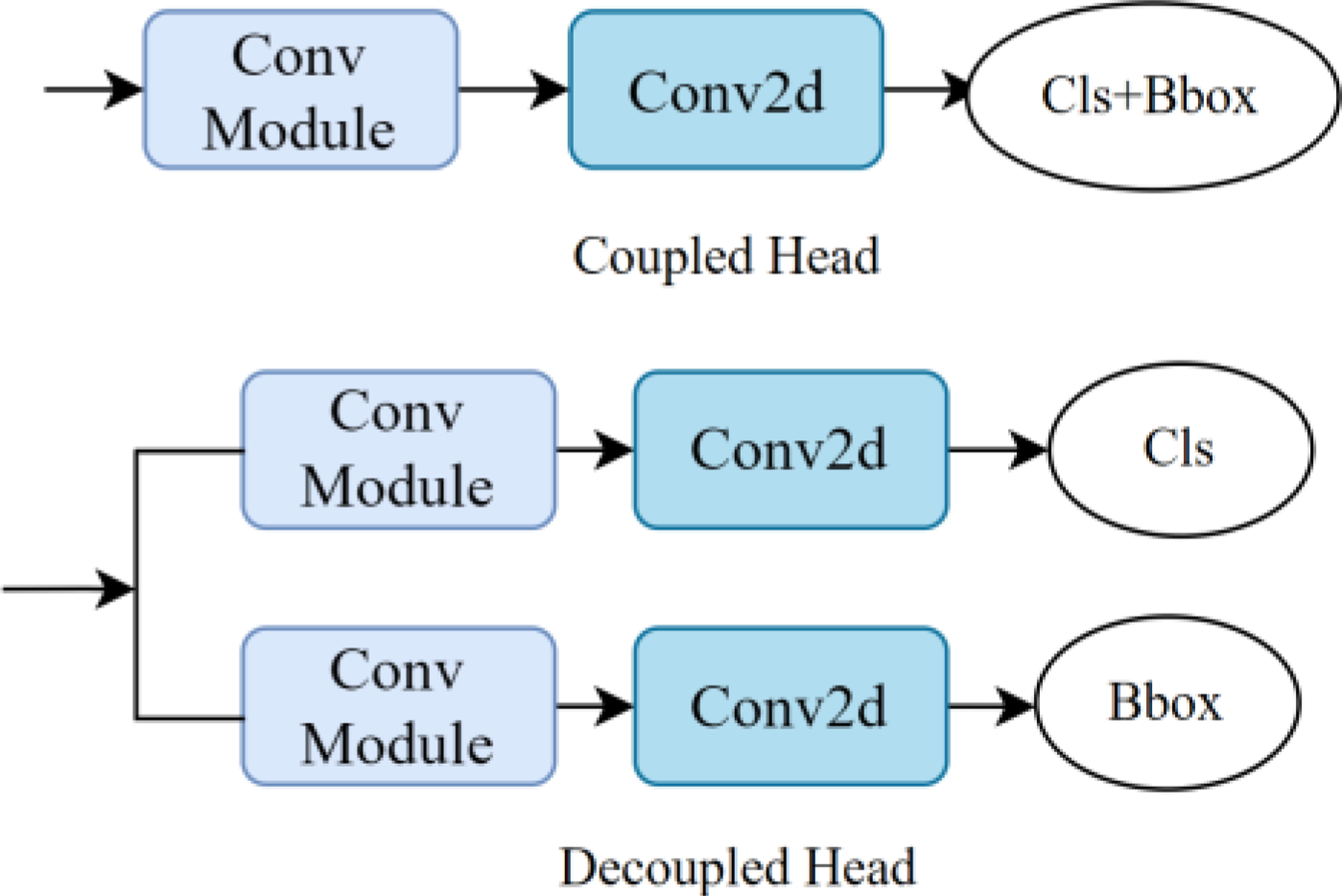
The difference between coupled and decoupled detection heads. Cls denote the class of target and Bbox denotes the bounding box of target.
Loss function
We propose YOLO-Faster to address the problem of rotating object detection in remote sensing images. Compared to ordinary object detection tasks, rotating object detection is more complex as it requires additional regression parameters, such as rotation angle

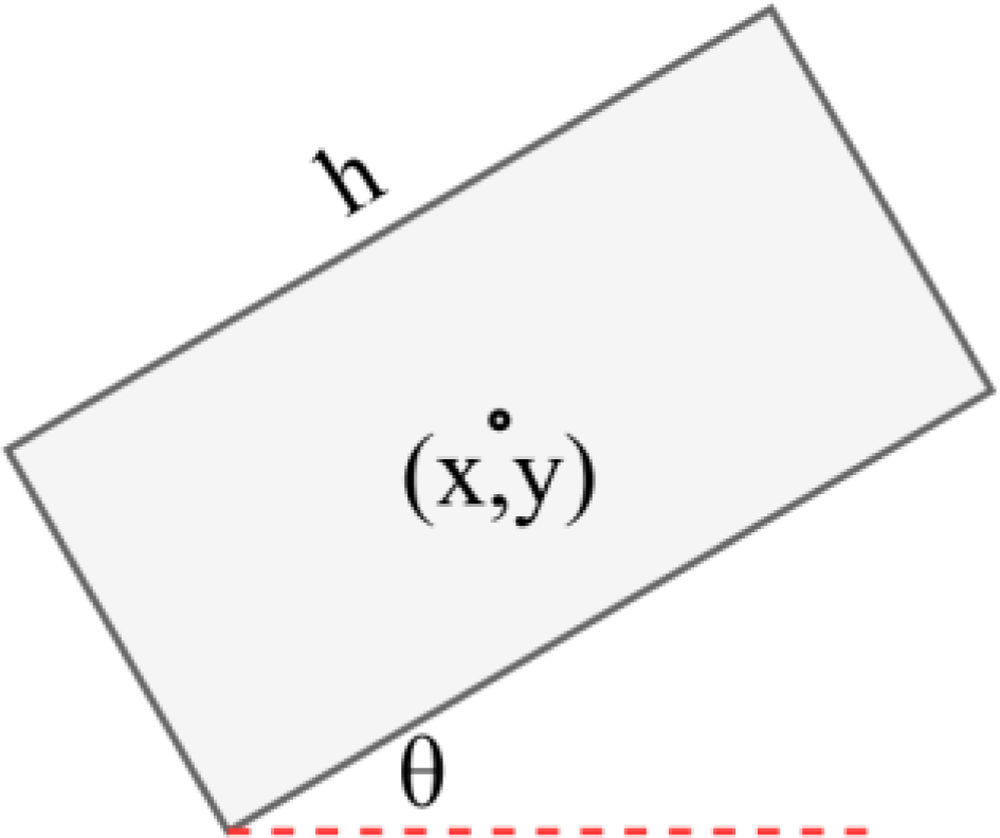
Prediction box parameters for rotating object detection.
Experiments and results
Dataset
In this paper, we adopt the commonly used public dataset DOTA 30 in the field of remote sensing object detection for training and testing the object detection network. The DOTA dataset contains 2806 images with a resolution of 4000 × 4000, including a total of 15 object categories and 188,282 object instances. During the training process, we use image cropping to preprocess the DOTA dataset to increase the sample size. By cropping the original 4000 × 4000 resolution images into multiple images with a resolution of 1024 × 1024, the DOTA dataset finally contains 19,472 training images and 5297 test images. Some cropped images are shown in Figure 8.

Cropped images in c dataset.
Evaluation metrics
This article uses the average precision (AP) of each category, the mean average precision (mAP) of all categories, and the detection speed of the target detection network. AP can be obtained from the precision-recall (P-R) curve in target detection, where recall and precision are defined as follows:

Implementation details
The experimental environment setup of this paper is shown in Table 1. The operating system used is Ubuntu 20.04, while Python 3.8 and PyTorch 1.10 are adopted as the deep learning framework for the deployment of remote sensing object detection networks. In the training process, the size of the training image is set to 1024 × 1024, the batch size is set to 8, the initial learning rate is set to 0.00025, and the Adam optimizer is used to update the network parameter weights. In addition to random flipping, no data augmentation techniques are used in this paper.
The quantitative results on the DOTA dataset.

Quantitative analysis of experimental results
This paper compares the improved remote sensing object detection network with the mainstream object detection networks to verify the effectiveness of the proposed method, including SSD, 13 Faster-RCNN, 17 RetinaNet, 31 YOLOv3, 14 YOLOv4, 15 YOLOv5, and TPH-YOLOv5. 32 The comparison results are shown in Table 2. As can be seen from the table, compared with mainstream object detection methods, the network proposed in this article has achieved advanced results in terms of average detection accuracy. Compared with the baseline network YOLOv5 s, the accuracy has improved by 1.9%. In terms of running efficiency and detection speed, due to the use of the efficient backbone network which takes into account both the FLOPs and memory access for higher FLOPS, YOLO-Faster not only improves accuracy but also ensures network detection speed. Compared with the one-stage networks such as YOLOv5 s and SSD algorithms, the detection frame rate remains at a similar level, concurrently achieving a higher mAP. Compared with TPH-YOLOv5 s, which has similar detection accuracy, the detection frame rate of this article has a significant improvement of 20 FPS. In addition, compared with other two-stage or single-stage target detection networks, the proposed YOLO-Faster has better performance in both detection accuracy and detection speed.
The quantitative results on the DOTA dataset.

mAP: mean average precision.
To verify the generalization of YOLO-Faster, we further evaluated its performance on DOTAv2 dataset. DOTAv2 dataset includes a total of 18 object categories. We select Faster-RCNN, Retinanet, FCOS, ATSS, Oriented RCNN as comparison networks. The quantitative comparison results are shown in Table 3. As can be seen from the table, the performance of YOLO-Faster is still better than that of the general object detection network represented by Faster-RCNN. Although YOLO-Faster is lower than Oriented RCNN in mAP metric, it has an advantage in lightweight performance.
The quantitative results on the DOTAv2 dataset.

mAP: mean average precision.
In order to verify the lightweight property of the proposed object detection network YOLO-Faster, we further compare the parameter count and computational complexity of YOLO-Faster with other object detectors. The results are shown in Table 4. As can be seen from the table, compared with other general-purpose object detectors, the proposed YOLO-Faster achieves the best results in terms of network parameter count, computational complexity, and detection speed, which demonstrate its lightweight design. Upon the replacement of the original YOLOv5 backbone network with the lightweight counterpart, there is a precipitous decline in both parameter count and FLOPs.
Lightweight comparison of different methods.

In theory, this substitution should augment the detection speed of the target detector. Nevertheless, owing to the substantial computational intricacy introduced by the large convolutional kernels and gated selection mechanism within AMFFN, the inference speed of the network experiences a deceleration, thereby mitigating the speed advantages conferred by the lightweight backbone. However, the inference speed remains comparable to that of YOLOv5 s.
In addition, we visualized the trend of the loss function during the training process, as shown in Figure 9. As can be seen from the figure, our YOLO-Faster can converge quickly and remain stable in future training sessions and mAP metric shows a steady upward trend, without suffering from the overfitting problem that often occurs during the training of small models.

The loss curve during training processing.
Ablation study
The article sets up ablation experiments to verify the effectiveness of the proposed improved modules. The results are shown in Table 5. As can be seen from the table, after replacing the original YOLOv5 s backbone network with FasterNet, the average detection accuracy of the detector increased from 69.5% to 70.6%. When replacing the original PANet neck network with the AMFFN proposed in this article, the average detection accuracy of the target detector increased from 70.6% to 71.0%. Furthermore, by replacing the original YOLOv5 detection head with the multiscale decoupled detection head proposed in this article, the detection accuracy of the detector increased from 71.0% to 71.3%. From the above ablation experiments, it can be seen that all the improved methods proposed in this article have a positive effect on improving the detection accuracy of remote sensing object detection networks, which further proves the effectiveness of our proposed method. We also visualize the mAP curve in Figure 10. As can be seen from the figure, YOLO-Faster has a leading mAP trend in almost all stages compared to other settings.
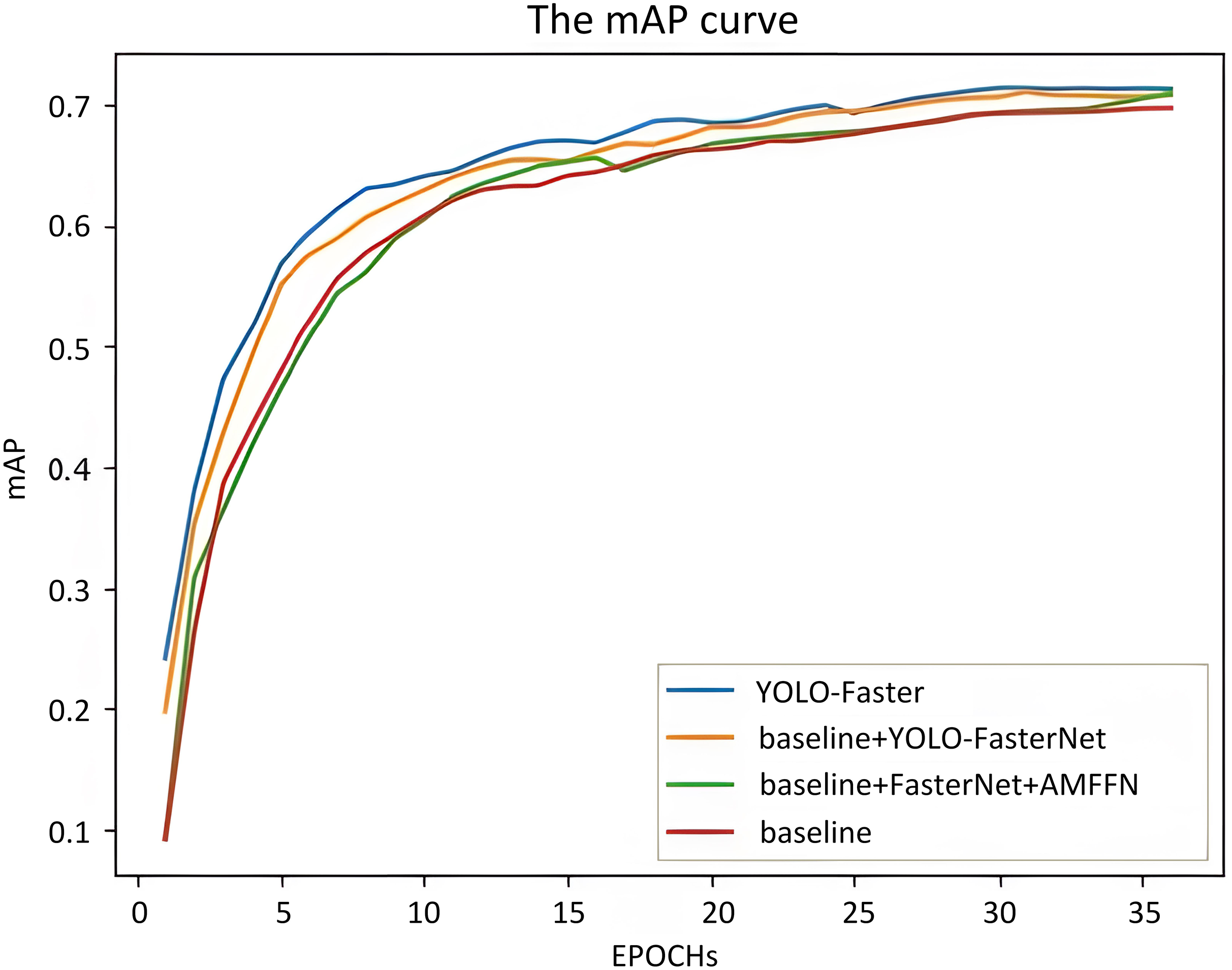
The mAP curve.
Ablation experiments for different modules.

AMFFN: adaptive multiscale feature fusion network; mAP: mean average precision.
Qualitative visual analysis
In this section, the effectiveness of the proposed remote sensing object detection network YOLO-Faster is further verified through visualizing the detection results. Figure 11 shows the visual detection result plots of YOLOv5 s, Faster- RCNN, and our YOLO-Faster. The regions where YOLO-Faster is more accurate than the other two networks are marked with red boxes. For example, in the first column, YOLOv5 s misses the “plane” target marked by the red box, and Faster-RCNN incorrectly detects it as a target of other categories, while our method accurately classifies and locates this target; In the second column, YOLOv5 s does not locate the “harbor” target precisely, and Faster-RCNN performs a large number of repeated detection of the “harbor” target, while our YOLO-Faster avoids these problems and detects the target accurately. This visualization also shows our advantage in false detection, recall, and localization accuracy.

The visualization results compare with YOLOv5 s and Faster-RCNN.
In addition, we visualize the detection results of ablation experiments. The visualization results are shown in Figure 12. In the first row, the detection results of the original YOLOv5 s object detection network are shown, while the second row demonstrates the results after embedding the multiscale adaptive feature synthesis network. The third row demonstrates the detection results after further using FasterNet as the backbone network and multiscale adaptive feature synthesis network. Compared to the first and second rows, it can be observed from the third row that using FasterNet as the backbone network and multiscale decoupled detection head improved the detection accuracy for targets of different sizes. This further demonstrates the effectiveness of our proposed method.

The visualization of detection results. “AMFFN” represents embedding AMFFN in the YOLOv5 s network.
Discussion
YOLO-Faster is predominantly geared toward adaptively detecting targets in large-scale complex backgrounds. However, there are a large number of small target objects in remote sensing images.33,34,35,36 Our YOLO-Faster is suboptimal at detecting small size targets, and some failed detection cases are shown in the Figure 13. As shown in the figure, (a) and (c) show that our YOLO-Faster misses the car running on the road, which is usually considered as small targets. In (b) and (d), YOLO-Faster mistakenly detects small vehicles as big vehicles. This also shows the limitations of our method in detecting small targets.

Failure cases. (a) and (c) show that YOLO-Faster misses the car running on the road. (b) and (d), YOLO-Faster mistakenly detects small vehicles as big vehicles.
Improving the detection accuracy of small target objects is a key factor in improving the overall detection performance of the target detector. In future work, we will also explore more small target detection methods and combine them with our networks.
Conclusions
In response to the challenges of large-scale complex scenes, varying target scales, and severe interference from background noise in remote sensing images, this paper introduces an improved lightweight remote sensing object detection network called YOLO-Faster. Firstly, the lightweight backbone feature extraction network is used to replace the original YOLOv5 backbone network CSPDarkNet. This not only improves the lightweight nature of the target detection network but also maintains its detection accuracy. Secondly, a multiscale adaptive feature fusion network is proposed, in which an RFAA module is embedded to adjust the receptive field of the target detection network to filter out invalid semantic information from the background. Additionally, this paper suggests a decoupled object detection head that replaces the coupled object detection head. Two parallel branches are used for classification and box regression tasks, respectively, to further improve the detection accuracy of the object detector. Experimental results on common remote sensing object detection datasets demonstrate that the proposed improved object detection algorithm achieves an average detection accuracy improvement of 1.9% compared to the original object detection network, while maintaining the same inference time. These innovations and improvements provide effective solutions for the field of remote sensing object detection and offer important references for subsequent research and applications.
Footnotes
Author contributions
The contribution of each author to this research article is specified as follows: conceptualization: Congling Tian; methodology: Yicheng Tong, Guan Yue, and Longfei Fan; validation: Deya Zhu and Yan Liu; data curation: Guosen Lyu and Boyuan Meng; formal analysis: Shu Liu and Xiaokai Mu; investigation: Deya Zhu, Yan Liu, Shu Liu, and Xiaokai Mu; writing—original draft preparation: Yicheng Tong and Guan Yue; project administration: Congling Tian; writing—review and editing: all authors. All authors have read and agreed to the published version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 52301369).