
Abstract
A novel feature fusion module, named TriNeXt, is proposed to enhance multi-scale representations in object detection frameworks. TriNeXt integrates local, nested, and global context-aware pathways, enabling effective spatial and semantic feature enrichment. The module is seamlessly incorporated into (You Only Look Once (YOLO)) YOLOv5 s and evaluated under various configurations. Extensive experiments on the Cityscapes dataset demonstrate the superiority of TriNeXt. Compared to baseline detectors, the full version (TriNeXt-Full) consistently improves detection performance: mean Average Precision (mAP)@0.5 increases from 61.7% (YOLOv5 s) and 62.3% (YOLOv8 s) to 63.2%; recall improves from 54.5%(YOLOv5 s) and 54.9%(YOLOv8 s) to 55.9%; precision rises from 77.2%(YOLOv5 s) and 75.8%(YOLOv8 s) to 79.2%. Despite introducing slight computational overhead, TriNeXt-Full maintains real-time inference speed, achieving a favorable balance between detection accuracy and efficiency. Progressive evaluations of TriNeXt variants further confirm the effectiveness of each design component, particularly in enhancing small object detection. To further validate its generalization capability, TriNeXt is evaluated on the KITTI dataset, where TriNeXt-Full achieves an improvement in mAP@0.5 from 94.0% to 95.0%, recall from 87.3% to 90.1%, and precision from 95.2% to 95.7%, demonstrating consistent performance gains across diverse and complex urban driving scenarios. These results establish TriNeXt as a robust and versatile module for small object detection in real-world applications.
Introduction
In recent years, object detection has become a cornerstone technology in numerous real-world applications, including intelligent surveillance, medical diagnosis, and particularly autonomous driving.1,2 As autonomous vehicles operate in complex and dynamic environments, reliable object detection is crucial for safe navigation and decision-making. Among the various challenges in this domain, small object detection—such as distant pedestrians and cars (as shown in Figure 1)—remains a persistent bottleneck due to limited pixel information and contextual ambiguity.3–5

Typical small objects in urban environments.
In practice, small objects are typically defined based on the proportion of their pixel area relative to the entire image. Following common standards like COCO and Cityscapes, objects are considered “small” if their area A satisfies:

Alternatively, in relative terms, objects occupying less than 1% of the total image area are also categorized as small. Detecting such objects is inherently challenging due to the minimal spatial support and limited semantic context available in feature representations.
Similar difficulties have also been reported in other domain-specific tasks, such as overhead transmission line inspection, where small targets play a critical role in ensuring system safety. 6
Conventional two-stage object detectors, such as R-convolutional neural network (CNN), 7 Fast R-CNN, 8 and Faster R-CNN, 9 have demonstrated strong accuracy through region proposal mechanisms and fine-grained feature extraction. However, their high computational complexity restricts deployment in real-time systems. One-stage detectors, notably the You Only Look Once (YOLO) series10–12 and Single-Shot MultiBox Detector (SSD), 13 offer faster inference by directly regressing object coordinates and classes from dense prediction maps. Among these, YOLOv5 s has been widely adopted in practice for its favorable trade-off between speed and accuracy. 14
Despite these advances, small object detection remains problematic even for state-of-the-art one-stage models. Notably, the deficiency in multi-scale feature fusion directly hinders the accurate localization and classification of small objects, which motivates our architectural improvements. A key limiting factor is the insufficiency of multi-scale feature fusion: shallow features retain fine localization details but lack high-level semantic abstraction, whereas deep features encode semantics at the expense of spatial precision. Architectural enhancements such as the Feature Pyramid Network (FPN), 15 Path Aggregation Network (PANet), 16 and Bidirectional Feature Pyramid Network (BiFPN) 17 have been introduced to address these challenges. In particular, BiFPN has also been adopted in domain-specific contexts. For example, Danso et al. 18 integrated BiFPN into YOLOv5 s for terahertz image detection, showing that weighted multi-scale fusion can improve detection performance under challenging low-resolution conditions.
While FPN enables top-down information flow with lateral connections, it primarily emphasizes semantic refinement and lacks efficient bottom-up reinforcement. PANet extends this by introducing a bottom-up pathway, but its symmetric structure can lead to redundancy and increased computational burden. BiFPN further improves fusion flexibility by introducing weighted feature combination; however, it uniformly fuses multi-scale features without explicit differentiation between spatial and semantic hierarchies, which is suboptimal for detecting small objects in dense and complex environments.
In this work, we specifically address the challenge of small object detection in autonomous driving scenarios by enhancing the multi-scale feature aggregation capacity of YOLOv5 s. We propose a plug-and-play module, called TriNeXt, designed to selectively reinforce spatial and semantic cues through context-aware multi-branch processing. Rather than uniformly modifying all feature layers, TriNeXt is strategically integrated at P3 and P5, targeting fine-grained spatial detail and high-level semantic abstraction. This selective enhancement strategy ensures a better balance between design flexibility and detection performance, catering to the scale-specific demands of real-world urban scenes.
We conduct extensive experiments on the Cityscapes dataset, 19 comprising high-resolution urban street scenes with diverse object sizes and occlusion patterns. Experimental results demonstrate that our modified YOLOv5 s model achieves significant improvements in detecting small objects, while maintaining real-time inference speed suitable for autonomous driving applications.
Unlike prior multi-scale fusion designs such as BiFPN and PANet, which focus on uniform feature aggregation or heavily emphasize global context modeling, our TriNeXt module introduces an asymmetric three-path fusion strategy. By selectively integrating local, nested, and global cues, TriNeXt achieves a finer balance between spatial precision and semantic consistency. This design particularly enhances the detection of small and densely distributed objects, while preserving computational efficiency.
This study builds upon the existing research discussed earlier and focuses on improving the detection of dense small targets in complex road backgrounds using YOLOv5 s as the baseline. The main contributions of this paper can be summarized as follows:
Related work
Object detection frameworks
Two-stage object detectors first generate region proposals and then extract features for classification and localization. 20 One of the earliest and most influential methods is R-CNN, 7 which uses selective search for proposal generation and CNNs 21 for feature extraction and classification independently. While effective, it suffers from high computational cost. Fast R-CNN 8 improves efficiency by sharing convolutional features and introducing RoI pooling. Faster R-CNN 9 further integrates proposal generation via a Region Proposal Network, allowing end-to-end training. Later variants such as R-FCN 22 leverage position-sensitive score maps for more efficient localization, and FPN 15 enhances multi-scale feature learning using a top-down pathway with lateral connections. Extensions like Mask R-CNN 23 and Cascade R-CNN 24 demonstrate the adaptability of this architecture to segmentation and refined localization. Although these methods achieve strong accuracy, they often fall short in real-time settings. Our work draws on their multi-scale representation strengths while emphasizing a one-stage, lightweight design for improved efficiency.
Unlike two-stage frameworks, one-stage object detectors perform classification and localization in a unified pipeline without relying on an intermediate region proposal stage. This design leads to significantly faster inference and reduced architectural complexity. One of the earliest and most influential works in this paradigm is YOLO, 9 which divides the image into grids and directly predicts bounding boxes and class probabilities. Later versions such as YOLOv2, 25 YOLOv3, 11 YOLOv5, 14 and YOLOv8 26 improved various aspects including multi-scale prediction, anchor optimization, and backbone efficiency. SSD 13 adopts a similar one-stage principle and detects objects across multiple feature layers for better scale coverage. RetinaNet 27 introduces Focal Loss to handle foreground–background imbalance effectively, achieving high accuracy in dense object detection.
More recently, YOLOv11 28 and RT-DETR 29 have further advanced the frontier of real-time object detection by improving architectural efficiency and context modeling. YOLOv11 introduces a dynamic head and an optimized multi-scale fusion strategy, achieving better accuracy without incurring significant computational overhead. Building on this, Liang et al. 30 further enhanced YOLOv11 for cooperative autonomous driving by integrating a Channel Transposed Attention module, a Diffusion Focusing Pyramid Network, and a Lightweight Shared Convolutional Detection Head, significantly improving detection robustness for small and occluded targets in complex road scenarios. Meanwhile, RT-DETR adopts a real-time optimized DETR-style framework that mitigates the inefficiency of standard self-attention through architectural simplification. These developments illustrate that performance gains can still be realized while maintaining low inference latency.
However, despite their advantages, such methods still lack flexibility in handling diverse spatial and semantic contexts across detection stages. For example, the backbone and neck structures often apply uniform processing across all feature scales, limiting their ability to adapt to fine-grained contextual demands—especially for small or occluded objects in complex scenes like autonomous driving. This limitation is consistent with the observations summarized in a recent comprehensive survey on small object detection, 31 which emphasizes that challenges such as low resolution, occlusion, background clutter, and class imbalance remain unsolved across diverse domains, from autonomous driving to remote sensing
Multi-path fusion
In object detection, multi-scale feature fusion is essential for handling objects of varying sizes, especially in complex environments like urban driving scenes. The FPN enhances multi-scale representations via a top-down architecture with lateral connections, enabling semantic features from deeper layers to guide localization in high-resolution feature maps. However, its purely top-down structure limits bottom-up information flow, which is critical for accurate spatial reasoning.
To overcome this limitation, PANet was proposed as an extension of FPN. It introduces a bottom-up path augmentation, allowing low-level spatial cues to refine deep semantic features. Additionally, PANet employs adaptive feature pooling and full fusion strategies to strengthen multi-level interactions, particularly benefiting small object detection and fine-grained localization. The architecture of FPN and PANet is shown in Figure 2.

The architecture of FPN and PANet. FPN: Feature Pyramid Network; PANet: Path Aggregation Network.
Building on these advances, YOLOv5 s adopts a hybrid neck design, the architecture of baseline shown in Figure 3, combining the top-down pathway from FPN and the bottom-up enhancement from PANet. Specifically, feature maps at P5, P4, and P3 are sequentially fused in a bidirectional manner, facilitating both semantic abstraction and spatial precision. This structure serves as a strong foundation for real-time detection. However, while effective, the default YOLOv5 s struggles with capturing rich multi-scale context and global semantics, especially for small and occluded objects.
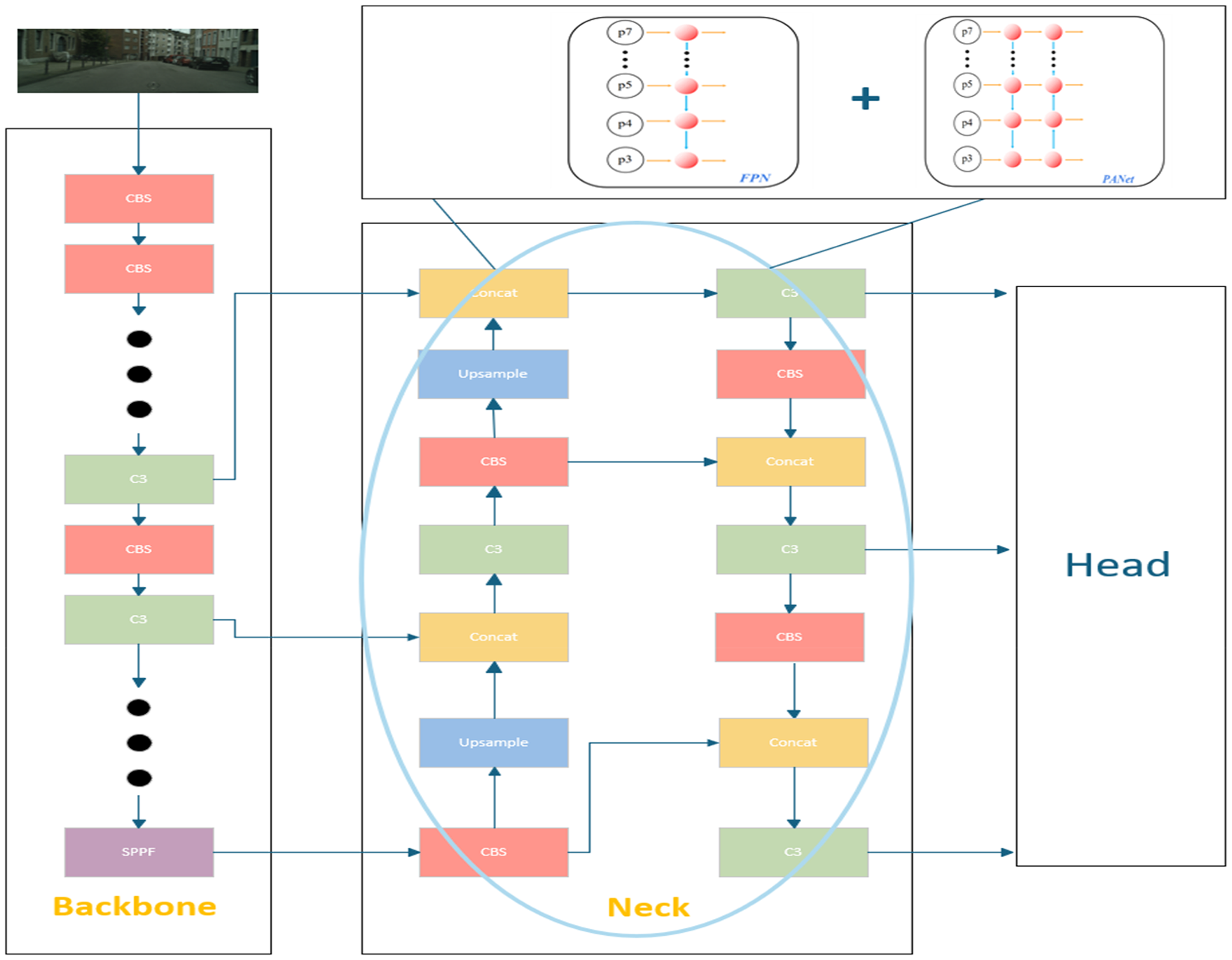
The architecture of YOLOv5 s baseline. YOLO: You Only Look Once.
These challenges point to the need for a feature enhancement module that combines flexibility, context sensitivity, and computational efficiency—qualities not fully achieved by current plug-and-play designs.
Transformer and feature enhancement modules
Transformer-based object detectors have achieved state-of-the-art accuracy by modeling global dependencies and contextual information. DETR 32 introduced an end-to-end transformer framework for detection, yet its convergence speed and computation demands limit its practicality. Deformable DETR 33 addressed these issues via sparse, multi-scale attention mechanisms. Subsequent models such as DINO, 34 DINOv2, 35 and ViTDet 36 further enhanced performance through query refinement, distillation, and hierarchical vision transformers. Despite their success, these methods often incur high latency, making them less suitable for real-time or edge deployment.
To mitigate such limitations, a variety of plug-and-play modules have been proposed for CNN-based detectors. Attention modules like CBAM 37 and SE 38 improve spatial and channel focus, while SPP 39 aggregates multi-scale information via parallel pooling layers. Transformer-inspired modules also offer contextual modeling benefits but generally introduce heavier inference costs.
However, most existing modules suffer from static topologies, limited adaptability across network stages, and insufficient granularity in semantic routing. They often treat all spatial positions and channels uniformly, failing to account for semantic imbalance and feature redundancy in dense prediction tasks.
Summary and motivation
The above discussions reveal a common limitation among both fusion strategies and enhancement modules: insufficient flexibility in handling diverse spatial and semantic contexts across different detection stages. Most existing approaches either focus on a single direction of information flow or apply uniform operations across all feature levels, failing to dynamically adapt to the varying demands of small, large, or occluded objects.
These observations motivate the development of TriNeXt, a lightweight, plug-and-play enhancement module designed to address spatial-semantic imbalance and improve feature adaptability. It introduces three parallel paths: A local path to refine edge-level cues and spatial details; A global path for capturing high-level semantic context; A nested fusion path enabling progressive cross-scale interaction.
By selectively integrating these paths at key fusion stages (e.g. P3 and P5) within YOLOv5 s, TriNeXt enables efficient, context-aware feature enhancement while preserving real-time inference speed. The module's design and implementation are detailed in the following section.
Method
In this work, we adopt YOLOv5 s as our base detector and integrate our proposed TriNeXt module into its feature fusion pathway. The TriNeXt module is introduced at two specific layers—corresponding to shallow and deep semantic features (P3 and P5 levels, respectively)—while deliberately omitting the intermediate scale (P4) based on experimental performance. This hybrid integration enables both enhanced spatial sensitivity and semantic abstraction with minimal computation overhead.
Modified architecture with TriNeXt
The proposed TriNeXt module is embedded at two specific fusion points: the shallow (P3) and deep (P5) branches of the neck. These two locations are empirically chosen to enhance both spatial awareness and semantic abstraction. Based on experimental findings, we deliberately omit integration at the intermediate level (P4), as it leads to suboptimal performance due to redundancy and possible overfitting.
As illustrated in Figure 4, the integration preserves the overall structure of YOLOv5 s while introducing targeted improvements through plug-and-play design. Each TriNeXt module processes the incoming feature maps through three complementary paths: Local, Nested, and Global. These paths are jointly designed to improve object localization, contextual reasoning, and semantic consistency.

YOLOv5 s with TriNeXt integration. YOLO: You Only Look Once.
To clarify the internal workings of our module, a detailed schematic of the full TriNeXt-Full structure is provided in Figure 5.

Internal architecture of the proposed TriNeXt module (Full).
The input feature map is first processed by a standard Conv–BN–ReLU module to unify the channel dimensions. This projection not only reduces redundancy but also aligns the feature space in preparation for subsequent multi-branch processing. The processed features are then routed through the Local Path, which employs a lightweight 1 × 1 convolution followed by a 3 × 3 convolution to enhance shallow spatial context. This design is particularly effective in preserving fine-grained boundaries and texture details, which are critical for small object detection. The enhanced local features are split into two streams: one is directly forwarded as a shortcut connection to the fusion stage, while the other is integrated into the subsequent multi-scale fusion, providing complementary spatial cues.
In parallel, another stream is processed by a Dilation-Based Path, which includes three atrous convolutions with increasing dilation rates (3, 6, and 9). Inspired by the success of the SPPF module, we adopt a novel hybrid parallel-cascaded strategy: while the dilated convolutions are arranged in parallel, a cascading mechanism is introduced wherein the output of the dilation-3 branch is fed into the dilation-6 branch, which in turn feeds into the dilation-9 branch. This design improves multi-scale feature interaction while preserving spatial consistency.
The outputs from all branches, including the nested dilated features, are then forwarded to the Global Path, which captures long-range semantic dependencies to complement the local and dilated streams. This path utilizes global average pooling (GAP) and bilinear upsampling to project global context back into the spatial domain.
Finally, all active path outputs are concatenated and passed through a 1 × 1 convolution to project the aggregated features back to the target channel dimension. This compression step enables effective fusion of diverse contextual representations while maintaining computational efficiency. The resulting representation is then used for subsequent prediction stages.
TriNeXt module design
In complex visual scenes, particularly those involving small objects, occluded targets, or densely packed instances, modern object detection frameworks still face significant representational challenges. These limitations are especially prominent in the following three aspects:
Loss of fine-grained spatial details in deep layers due to repeated downsampling in the backbone. While one-stage detectors such as YOLOv5 achieve excellent inference speed, the shallow features containing precise spatial cues are often suppressed during deep-layer fusion, making it difficult to accurately localize small objects. Limited receptive field and insufficient multi-scale context integration. Approaches like FPN primarily propagate top-down semantic information, while PANet introduces bidirectional paths but lacks architectural heterogeneity. BiFPN, despite its learnable weighting strategy, performs uniform fusion across feature levels without explicit functional separation, which compromises contextual modeling—especially for medium-scale and occluded objects. Lack of global semantic awareness. YOLO-based detectors are primarily designed for fast, local target localization, and their feature extraction and fusion mechanisms are typically constrained to short- or mid-range dependencies. This design leads to poor modeling of long-range relationships and semantic consistency, making them prone to false detections or omissions in complex backgrounds.
To address these challenges, we propose TriNeXt, a modular and context-aware feature enhancement architecture designed to augment existing backbones. The TriNeXt module consists of three functionally complementary stream, each specifically tailored to enhance one of the following representational capacities: fine-grained spatial detail, hierarchical multi-scale context, and global semantic consistency. The overall architecture is illustrated in Figure 6.

The architecture of three streams.
Local-Stream
In multi-scale detection frameworks, low-level features provide rich spatial cues such as edges and textures but are often marginalized in deeper layers due to repeated downsampling and compression. In YOLOv5 and similar architectures, shallow features are typically passed into the neck with minimal refinement, leading to inadequate preservation of fine-grained spatial information—especially detrimental for small object detection.
To explicitly enhance shallow spatial representations, the Local-Stream applies a 1 × 1 convolution for channel adaptation followed by a 3 × 3 convolution to reinforce local receptive fields. This enables accurate preservation of spatial boundaries and structural details.
Importantly, the Local-Stream serves as the entry point of the TriNeXt module. Its outputs are fed into the high-level branches (e.g. Nested-Stream), forming the first layer of the hierarchical dependency chain, where local features are progressively enriched through multi-stage context fusion.

Nested-Stream
While spatial refinement is crucial for small objects, effective detection across diverse scales requires robust mid-range context modeling. Existing designs like PANet and BiFPN attempt bi-directional feature fusion, but they often perform uniform, layer-agnostic aggregation, lacking explicit hierarchical structure or dependency modeling. Additionally, single-branch dilated convolutions commonly adopted for context expansion are prone to semantic inconsistency and gridding artifacts, limiting their effectiveness in dense or occluded scenarios.
To address this, the Nested-Stream incorporates three atrous (dilated) convolutional layers with increasing dilation rates (3, 6, and 9). These layers are connected in a nested, cascaded configuration (3→6→9), enabling both lateral scale-aware encoding and vertical information flow through progressively enlarged receptive fields.
This branch plays a pivotal role in establishing a hierarchical context propagation pathway. It integrates low-level features from the Local-Stream and builds upon them with expanding receptive fields, creating a layer-wise dependency chain from spatial detail to contextual abstraction.
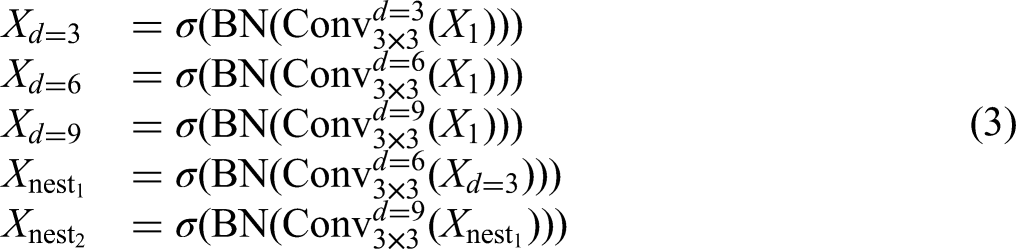
Global-Stream
Although local and mid-level cues help with precise localization and intermediate-scale modeling, they may fail to resolve ambiguities in cluttered scenes without broader semantic awareness. Most one-stage detectors like YOLOv5 lack explicit mechanisms for modeling long-range dependencies and global context.
The Global-Stream addresses this by applying GAP to condense image-wide semantics into a compact feature vector. Optionally, a fully connected layer refines this global descriptor, which is then broadcast back to the spatial domain via bilinear upsampling to match the original feature resolution.
Functionally, the Global-Stream acts as the semantic apex of the TriNeXt module. It complements the Local and Nested paths by providing top-down semantic guidance, closing the loop in the hierarchical structure and reinforcing consistency across spatial locations. This mirrors a reverse dependency flow, wherein coarse semantic priors guide the interpretation of finer features.

TriNeXt variants: progressive enhancement strategy
To explore the contribution of each component within the TriNeXt architecture, we define three progressively enhanced variants by selectively enabling the Local, Nested, and Global paths. This design not only allows for detailed ablation studies but also reflects a step-wise strategy to balance performance, complexity, and generalizability.
TriNeXt-L: This configuration activates only the Local-Stream, which focuses on capturing fine-grained details and spatial boundaries. It is designed to strengthen low-level representation and improve small object detection performance.
TriNeXt-LN: In this variant, both the Local and Nested streams are enabled. The nested dilation structure introduces hierarchical contextual fusion, expanding the receptive field while preserving spatial alignment, which improves medium-scale object recognition.
TriNeXt-Full: This is the most comprehensive version, integrating all three branches: Local, Nested, and Global. The Global-Stream introduces long-range semantic guidance and improves global consistency, particularly beneficial in scenes with occlusion and scale variance.
An overview of the configurations for each variant is summarized in Table 1
Configurations of the TriNeXt variants.

Experiments
Dataset
We conduct our experiments on a subset of the Cityscapes dataset, which is a large-scale benchmark for semantic urban scene understanding. It comprises high-resolution images collected across 50 cities in diverse weather and lighting conditions. The dataset offers fine-grained annotations and has been widely adopted for training and evaluating object detection and semantic segmentation models. For detailed dataset statistics and collection methodology, please refer to Cordts et al. 19
In our work, we select 10,000 images from Cityscapes and split them into 8000 training, 1000 validation, and 1000 testing images using an 8:1:1 ratio.
To simplify the detection task and improve generalization, we remap the original fine-grained object categories into three coarse-grained classes:
This class grouping mitigates category imbalance and semantic overlap, while preserving the essential structural diversity of road scene entities.
The experimental results are evaluated using Precision (P), Recall (R), Frames Per Second (FPS), and mean Average Precision (mAP) across all object categories. The corresponding formulas are given in Equations (4) to (7). Precision, Recall, and mAP are presented as percentages in all experiments.



Analysis of experimental results
Experiments and analysis of neck improvement
To evaluate the effectiveness of the proposed TriNeXt module,we implemented a series of ablation experiments by incrementally enabling its three key components: local,nested,and global streams. The resulting variants are denoted as follows:
TriNeXt-Min(no_local_nested_global): A minimal structure retaining only the backbone's three dilated branches,without any additional fusion. TriNeXt-L(no_nested_global): Incorporates the local stream, enhancing shallow spatial cues. TriNeXt-LN(no_global): Builds upon TriNeXt-L by adding the nested stream, which deepens contextual fusion through hierarchical dilation. TriNeXt-Full(Ours-full): Activates all three streams—local, nested, and global—forming the complete TriNeXt architecture.
These variants were integrated into Yolov5 s. Experimental results comparing variants and the original baseline are presented in Table 2.
Comparison of the multi-scale module on the Cityscapes dataset.

The bold values indicate the best results in each column are indicated in bold.
YOLO: You Only Look Once; FPS: Frames Per Second; mAP: mean Average Precision.
As summarized in Table 2, the TriNeXt variants demonstrate progressively improved performance compared to the baseline YOLOv5 s. TriNeXt-Min maintains the same mAP@0.5 (61.7%) as YOLOv5 s but improves recall and precision by 0.3% and 1.1%, respectively, indicating slight gains with reduced speed.
TriNeXt-L introduces a more substantial improvement, achieving a 0.7% increase in mAP@0.5, a 0.9% gain in recall, and a 1.6% boost in precision, while still maintaining real-time capability.
Building upon this, TriNeXt-LN further enhances all metrics, reaching 62.6% mAP@0.5, 55.6% recall, and 79.1% precision, marking cumulative gains of 0.9%, 1.1%, and 1.9% over the baseline, respectively.
The full configuration, TriNeXt-Full, achieves the most significant improvements: a 1.5% increase in mAP@0.5, 1.4% in recall, and 2.0% in precision. These results validate the effectiveness of the full three-path fusion strategy in jointly enhancing both localization and classification performance.
Notably, all variants maintain over 60 FPS, demonstrating their potential for real-time applications such as autonomous driving.
The evolution of mAP during training across different models is illustrated in Figure 7, where it is evident that TriNeXt variants converge faster and achieve higher ultimate performance compared to the baseline YOLOv5 s. Furthermore, Figure 8 and Table 3 illustrate the class-wise precision distribution across all model variants. Among them, TriNeXt-Full demonstrates consistently strong performance, especially in the “two-wheeler” category, where it achieves the highest precision. While TriNeXt-LN and TriNeXt-L exhibit leading results in the “vehicle” and “pedestrian” categories, respectively, TriNeXt-Full maintains a well-balanced and competitive performance across all object types.

mAP 50during training across different models. mAP: mean Average Precision.

Class-wise precision comparison.
Class-wise precision comparison of different TriNeXt variants on the Cityscapes dataset.
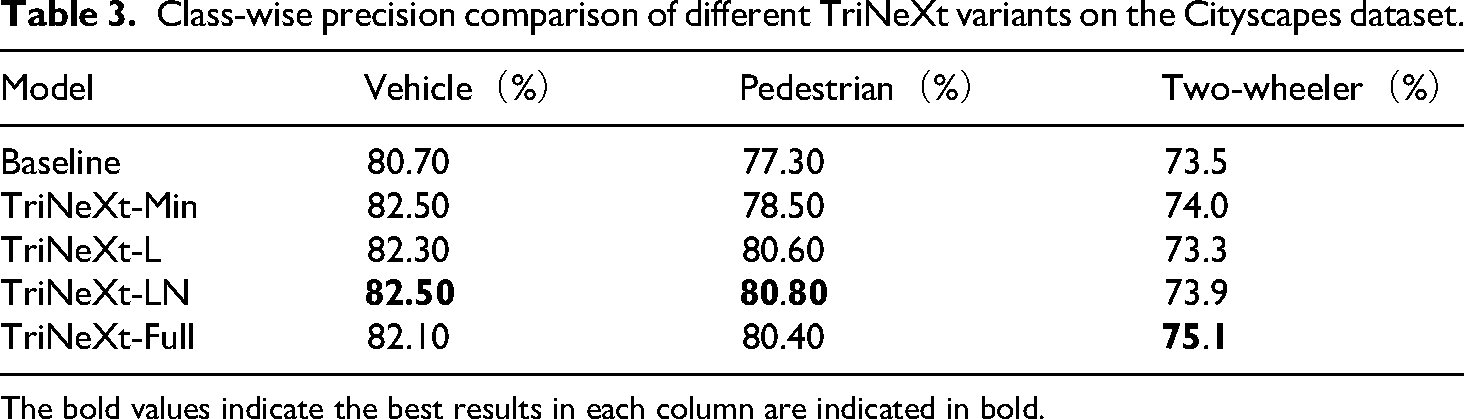
The bold values indicate the best results in each column are indicated in bold.
These results collectively demonstrate that each additional path (Local, Nested, Global) provides complementary gains, and the full design delivers a well-balanced improvement across multiple evaluation metrics.
To further illustrate the advantages of the proposed TriNeXt module, we conduct a series of visualization analyses. Specifically, we present both the class activation heatmaps (Figure 9) and the detection output images (Figure 10) for different models. The baseline model tends to focus on irrelevant background regions, such as the sky and road surfaces, resulting in suboptimal localization. In contrast, the TriNeXt-Full model concentrates more accurately on target objects, especially on small and occluded instances. This improvement highlights the enhanced feature extraction and multi-scale fusion capability brought by the TriNeXt architecture. Meanwhile, the detection results qualitatively demonstrate the improvements in localization accuracy and object recognition, particularly for small and occluded targets.

Grad-CAM heatmap comparisons between the baseline model and the proposed TriNeXt-Full model.

Detection results.
The visual comparisons between the baseline model and the TriNeXt-Full variant clearly showcase the enhanced feature extraction and multi-scale fusion capabilities enabled by the TriNeXt architecture.
Feature visualization and distribution analysis
To further understand the internal behavior of the proposed TriNeXt module, we visualize the activation distributions of its five branches—Baseline, Local, Global, Nested-1, and Nested-2—at key feature levels (P3-entry, P3-core, and P5-core). As shown in Figure 11, these histograms provide qualitative insights into the distinct roles each path plays in enhancing feature representation.

Activation distribution visualization of TriNeXt branches at key feature levels.
At the P3-entry stage, where early spatial features dominate, the Local branch exhibits a pronounced concentration of activations around lower intensities, effectively enhancing edge and texture sensitivity. The Nested-1 and Nested-2 branches introduce progressively broader activation distributions with visible long-tail behavior, indicative of multi-scale receptive field expansion and fine-grained contextual modeling. The Global path maintains a flatter, dispersed distribution, injecting coarse global semantics into the feature maps.
At the P3-core stage, this trend intensifies. The Nested branches demonstrate increasingly multi-modal activation patterns, capturing richer contextual dependencies through hierarchical dilation. The Local branch maintains moderate sharpness, supporting structure preservation, while the Global stream continues to provide wide-ranging semantic context. In contrast, the Baseline path shows relatively compact unimodal distribution, suggesting limited diversity in feature responses.
By the P5-core level, where semantic abstraction is predominant, the distinction between branches becomes more apparent. The Global branch yields the most dispersed activation spectrum, aligning with its role in capturing global object-level semantics. Nested paths still preserve a degree of multi-modality, reflecting their capability in aggregating long-range context. Meanwhile, the Local and Baseline branches exhibit narrower distributions, emphasizing their reduced spatial emphasis at higher layers.
These distributional patterns empirically validate the intended functional decomposition of TriNeXt: the Local stream sharpens spatial boundaries, the Nested stream diversifies context through progressive dilation, and the Global stream embeds semantic consistency. Furthermore, the increasing activation variability observed at P3 and P5 supports our selective integration strategy and confirms that TriNeXt enhances representational richness without compromising architectural efficiency.
To complement the feature visualization, we further perform detailed error analysis through confusion matrices and precision-recall (PR) curves, aiming to provide a deeper understanding of the detection performance across different object classes.
Analysis via confusion matrix and PR curves
Confusion matrix analysis
To further evaluate the impact of the proposed TriNeXt module, we conduct an error analysis based on the confusion matrices of the baseline YOLOv5 s and our TriNeXt-Full models. The confusion matrices, presented in Figure 12, visualize the prediction accuracies and misclassification patterns across four major categories: vehicle, pedestrian, two-wheeler, and background.

Confusion matrices of the YOLOv5 s baseline (right) and the proposed TriNeXt-Full model (left) on the Cityscapes dataset. YOLO: You Only Look Once.
As summarized in Table 4, TriNeXt-Full achieves consistent improvements in correct classification rates across all object classes compared to the baseline. Specifically, the correct classification rate for vehicles increases from 72% to 73%, pedestrians from 57% to 59%, and two-wheelers from 52% to 57%. Moreover, TriNeXt-Full effectively reduces the background misclassification rates by 2% for vehicles, 2% for pedestrians, and 5% for two-wheelers, demonstrating enhanced robustness against false positives in dense urban environments.
Class-wise correct classification rates for YOLOv5 s baseline and TriNeXt-Full on the Cityscapes dataset.

The bold values highlight the performance improvement trends.
YOLO: You Only Look Once.
These results indicate that TriNeXt not only improves overall detection accuracy but also significantly reduces misclassifications, particularly for small and occluded objects, thereby enhancing the reliability of the detection system in real-world applications.
Precision-recall curve analysis
In addition to confusion matrix analysis, we further examine the PR curves of the baseline YOLOv5 s and the proposed TriNeXt-Full models, as shown in Figure 13.
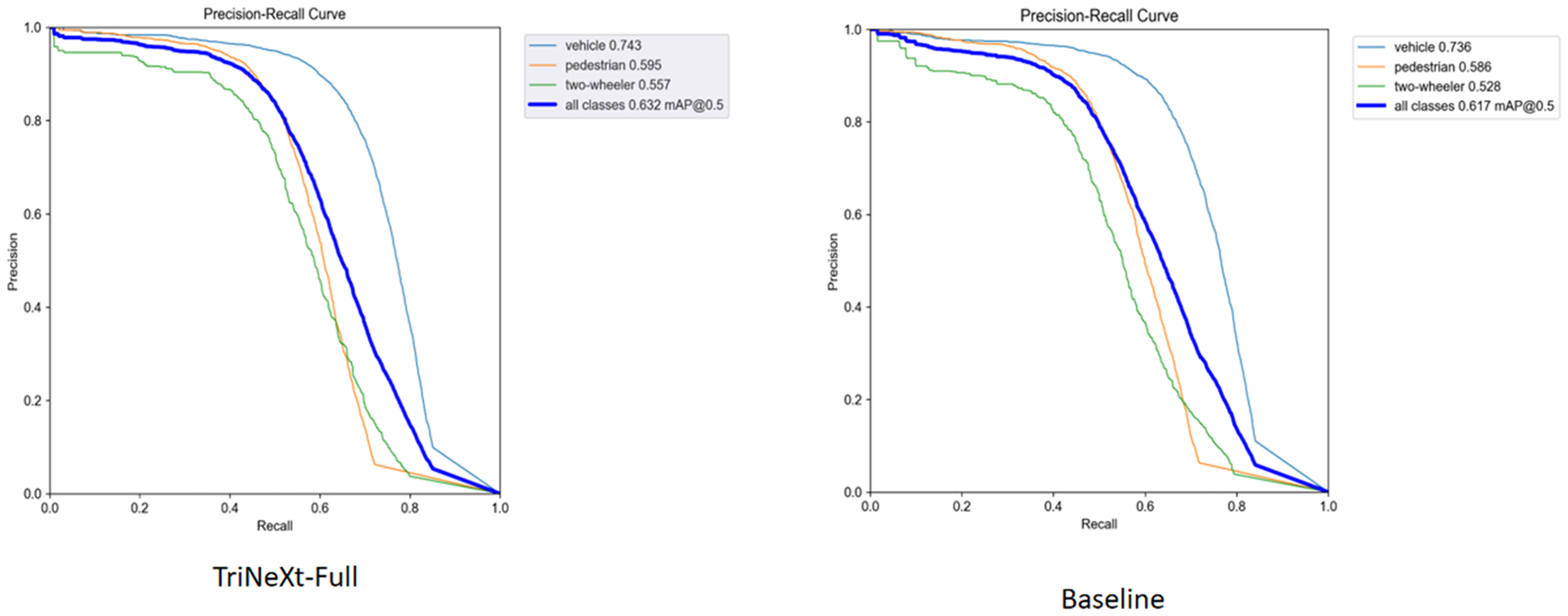
Precision-recall (PR) curves for the YOLOv5 s baseline (right) and the proposed TriNeXt-Full model (left) on the Cityscapes dataset. YOLO: You Only Look Once.
From the PR curves, TriNeXt-Full consistently maintains higher precision across a broader range of recall values compared to the baseline. As detailed in Table 5, the area under the PR curve (AP@0.5) improves for all object categories, with the overall mAP@0.5 increasing from 61.7% to 63.2%. Notably, AP for pedestrians and two-wheelers—representing smaller and more challenging objects—improved by 0.9% and 2.9%, respectively.
Comparison of area under the precision-recall curve (AP@0.5) for YOLOv5 s baseline and TriNeXt-Full on the Cityscapes dataset.

The bold values highlight the performance improvement trends.
YOLO: You Only Look Once.
These improvements suggest that TriNeXt-Full not only enhances the overall detection performance but also maintains better precision at higher recall levels, which is critical for real-world deployment where both high precision and high recall are required to ensure safe and reliable object detection.
Size-specific performance analysis
To further examine whether the improvements in small object detection are achieved at the expense of detection accuracy for medium or large objects, we performed a fine-grained evaluation based on object sizes. Following COCO-style thresholds, we divided the Cityscapes validation results into three categories: small (area ≤ 32² pixels), medium (32² < area ≤ 96²), and large (area > 96²). We report per-size performance metrics—True Positives (TP), False Positives (FP), False Negatives (FN), Precision, and Recall—for all variants in Table 6.
Performance comparison across different object sizes for baseline and TriNeXt variants.
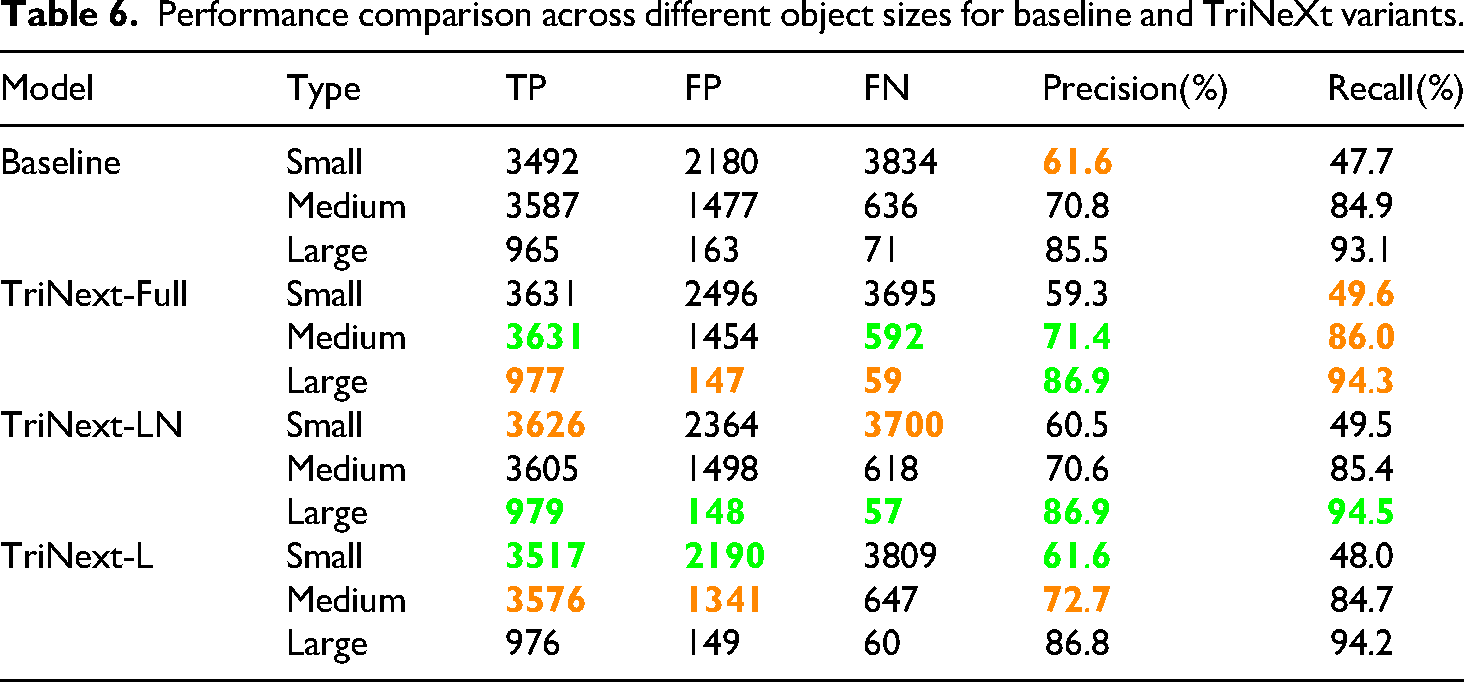
From the results, we observe the following: Small objects: All TriNeXt variants achieve improved Recall over the baseline. For instance, TriNeXt-Full reaches 0.496 Recall (vs. 0.477 in the baseline), and TriNeXt-LN achieves 0.495. However, this comes with a slight trade-off in Precision, which drops from 0.616 (baseline) to 0.593 in TriNeXt-Full, indicating increased False Positives (+316). This trend suggests that the model is more sensitive to small object presence but may trigger more false alarms, a common trade-off in dense object scenarios. Medium objects: The improvements are consistent and stable across all variants. TriNeXt-L achieves the best Precision (0.727) and TriNeXt-Full shows the highest Recall (0.860) for medium objects. Both metrics are superior to the baseline (0.708 / 0.849), demonstrating that the proposed multi-scale design not only enhances small object detection but also benefits medium-sized object performance. Large objects: All models maintain high Precision and Recall, with negligible fluctuation. The Precision for large objects remains around 0.868–0.869 across all variants, slightly higher than the baseline (0.855), and Recall is consistently ≥ 0.942. This confirms that our improvements on smaller objects did not compromise the reliability of large object detection.
In summary, the TriNeXt architecture achieves a balanced improvement across all object sizes. While small object recall improves substantially, medium and large object precision and recall are also preserved or slightly enhanced. This validates that the design does not sacrifice the performance of critical targets (e.g. large vehicles or pedestrians) in urban driving scenes, thus satisfying real-world safety and reliability demands.
Notation explanation (see Table 6): Green Highlight: Indicates the best value among all models under the corresponding metric. Orange Highlight: Represents the second-best value or a value close to the best, providing a reference for comparative advantages. Bold font is used to emphasize highlighted values.
Performance on KITTI Dataset
To further validate the model's deployment robustness, we conduct cross-platform testing on a secondary workstation equipped with an Intel CPU and NVIDIA RTX 4070Ti GPU. Despite hardware differences from the original training environment (AMD CPU + RTX 4070), the TriNeXt-Full model maintains consistent detection accuracy and stability on the KITTI dataset. This confirms that the proposed structure is hardware-agnostic and suitable for practical deployment.
On the KITTI dataset, we conducted a comparative evaluation between the YOLOv5 s baseline and our proposed TriNeXt-Full model. Results demonstrate consistent performance improvements across all metrics. The overall mAP@50 increased from 0.940 to 0.950, and mAP@50:95 improved from 0.703 to 0.724. Notably, the Pedestrian and Cyclist categories saw substantial gains in recall and fine-grained accuracy. For Pedestrian, recall increased by 4.2% and mAP@50:95 rose by 3.0%, indicating that TriNeXt significantly enhances the model's ability to capture small and ambiguous targets. These findings validate TriNeXt as an effective and robust feature refinement module that enhances representational diversity and detection quality without incurring substantial computational overhead.
A detailed comparison of precision, recall, and average precision metrics for each object class is provided in Table 7, while a visual comparison is illustrated in Figure 14.

Comparative evaluation of YOLOv5 s baseline and TriNeXt-Full on the KITTI dataset across different metrics. YOLO: You Only Look Once.
Performance comparison between YOLOv5 s baseline and TriNeXt-Full on the KITTI dataset.

The bold values indicate the best results in each column are indicated in bold.
YOLO: You Only Look Once; mAP: mean Average Precision.
Qualitative Comparison on KITTI Dataset
As shown in Figure 15 we compare detection results between the YOLOv5 s baseline and TriNeXt-Full across several challenging scenes in the KITTI dataset. The baseline model frequently misses small or occluded targets and exhibits a higher rate of false positives, resulting in imprecise or redundant bounding boxes. In contrast, TriNeXt-Full not only successfully detects additional objects—particularly distant or partially occluded cars and pedestrians—but also significantly reduces false detections. These results validate that TriNeXt's multi-branch design effectively enhances fine-grained spatial representation and contextual awareness, leading to superior detection performance in complex real-world scenarios.

Detection between the YOLOv5 s baseline and TriNeXt-Full. YOLO: You Only Look Once.
Exploring spatial-semantic enhancement via TriNeXt integration in YOLOv11s
To further evaluate the complementary advantages of spatial and semantic enhancement, we introduce a dual insertion strategy of the TriNeXt module within the YOLOv11 s architecture. Specifically, the TriNeXt block is inserted at two points: (1) after the C3k2 module at the P4-stage, targeting medium-resolution features; and (2) after the SPPF module, before the C2PSA block, focusing on global receptive field aggregation. This configuration is carefully designed to maintain channel consistency and minimize computational redundancy.
Empirical results on the Cityscapes dataset are summarized in Table 8 and Figure 16. Compared with the baseline YOLOv11 s, the TriNeXt-enhanced variant significantly improves across all detection metrics. Notably, mAP@0.5 improves from 63.0% to 64.3%, precision rises from 74.7% to 78.3%, and recall from 56.6% to 58.4%. Despite the increased complexity (48.2 GFLOPs vs. 21.3 GFLOPs), the parameter size remains manageable, demonstrating a favorable trade-off between accuracy and efficiency.

Performance comparison of YOLOv11 s baseline and TriNeXt-enhanced model on the Cityscapes dataset. YOLO: You Only Look Once.
Performance comparison between YOLOv11 s baseline and TriNeXt-enhanced model.

YOLO: You Only Look Once; mAP: mean Average Precision.
These results confirm the effectiveness of leveraging multi-branch fusion at both mid- and high-level stages, allowing TriNeXt to better capture fine-grained spatial cues and semantic context simultaneously. More importantly, the consistent performance gains across different datasets and architectures (e.g. KITTI and Cityscapes, YOLOv5 s and YOLOv11 s) further validate the strong transferability and generalization capability of the TriNeXt module.
Comparative experiments
To demonstrate the effectiveness of the proposed method, we compare it with several representative object detection algorithms on the Cityscapes dataset, including anchor-based (YOLOv5 s/v8 s/v11 s/v12 s), two-stage (Faster R-CNN), and anchor-free Transformer-based models (RT-DETR). The results are shown in Table 9.
Comparative analysis of algorithm performance on the Cityscape dataset.

CNN: convolutional neural network; YOLO: You Only Look Once; mAP: mean Average Precision.
Our method consistently achieves the best performance across all metrics. Ours-Full reaches a mAP@0.5 of 63.20%, with a balanced recall (55.90%) and high precision (79.20%), outperforming all YOLO variants and significantly exceeding RT-DETR and Faster R-CNN.
Notably, faster R-CNN achieves the highest recall (57.56%) but suffers from low precision, indicating over-detection. RT-DETR is more conservative, with lower recall and mAP. Our design offers a better balance between precision and recall, benefiting from the TriNeXt module's multi-scale feature fusion.
Overall, these results verify that our method not only improves detection accuracy but also maintains efficiency and general applicability across different detection paradigms.
Conclusion
In this paper, we presented TriNeXt, a novel plug-and-play feature enhancement module designed to improve multi-scale representation in object detection tasks. TriNeXt introduces an asymmetric three-path fusion strategy that selectively enhances spatial details, hierarchical context, and global semantics through its Local, Nested, and Global branches. This design addresses the scale-dependent imbalance commonly encountered in dense and small object detection.
We integrated TriNeXt into the neck of YOLOv5 s without modifying the detection head, ensuring compatibility with existing architectures and maintaining real-time inference capabilities. Extensive experiments on the Cityscapes and KITTI datasets demonstrate that TriNeXt consistently improves detection performance across multiple metrics, achieving notable gains in mAP, precision, and recall, especially for small and occluded targets. Comparative analyses with baseline models and progressive ablation studies further validate the effectiveness and efficiency of the proposed design.
Furthermore, visualization of feature activations confirms that the TriNeXt module successfully enriches the internal feature representations, promoting better spatial localization and semantic consistency. Cross-platform validation also highlights the model's robustness and deployability in real-world autonomous driving scenarios.
Although TriNeXt leads to an increase in computational cost and the growth in parameter count. We argue that the substantial performance gains, particularly for small and hard-to-detect objects, justify this trade-off. In autonomous driving scenarios, missing small or occluded objects such as pedestrians or cyclists can lead to critical safety risks. Therefore, even a moderate increase in computational load is acceptable if it significantly improves detection reliability. Moreover, the TriNeXt module is designed in a modular and hardware-agnostic manner, enabling flexible deployment and potential for pruning or quantization in resource-constrained environments.
In future work, we plan to extend TriNeXt to other vision tasks such as instance segmentation and 3D object detection. Additionally, we aim to explore dynamic path selection mechanisms based on input characteristics, further enhancing the adaptability and efficiency of the proposed module in diverse deployment environments.
Discussion
The proposed TriNeXt module has demonstrated significant improvements in small object detection, achieving consistent gains in mAP, precision, and recall across the Cityscapes and KITTI datasets. By selectively enhancing spatial, hierarchical, and global features, TriNeXt effectively addresses the common limitations of conventional multi-scale fusion methods, especially in dense urban environments with frequent small and occluded targets. The plug-and-play design ensures seamless integration with existing detection frameworks such as YOLOv5 s without necessitating major architectural modifications, maintaining practical deployment flexibility.
However, despite these promising results, several limitations remain. First, while TriNeXt introduces substantial performance gains, it does so at the cost of increased computational complexity, leading to a reduction in inference speed compared to the baseline. Although the model retains real-time capability (over 60 FPS), there is still a noticeable drop from the baseline YOLOv5 s (88 FPS), which could pose challenges for latency-sensitive applications such as autonomous driving in highly dynamic environments.
Furthermore, the current design employs a fixed three-path structure without dynamic adaptation to input complexity or scene context. This static configuration may limit its efficiency under varying operational conditions.
In future work, we aim to address these limitations by:
Exploring dynamic path selection strategies, where the activation of each TriNeXt branch can be adaptively determined based on input characteristics, reducing unnecessary computation for simpler scenes. Optimizing the module with lightweight convolutional techniques and model compression strategies to further enhance inference speed without sacrificing detection accuracy. Extending the TriNeXt architecture to other vision tasks such as instance segmentation and 3D object detection, investigating its generalizability across diverse application domains.
By tackling these challenges, we expect to further improve the balance between accuracy and efficiency, making TriNeXt even more suitable for real-world, resource-constrained deployments.
Footnotes
Author contributions
The authors’ contributions to this paper are as follows: experimental design and paper writing: XZ and XY; experimental supervisor: JF; thesis supervisor: WC and LZ. All authors reviewed the results and approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.