
Abstract
Real-time object detection on mobile platforms is a crucial but challenging computer vision task. However, it is widely recognized that although the lightweight object detectors have a high detection speed, the detection accuracy is relatively low. In order to improve detecting accuracy, it is beneficial to extract complete multi-scale image features in visual cognitive tasks. Asymmetric convolutions have a useful quality, that is, they have different aspect ratios, which can be used to exact image features of objects, especially objects with multi-scale characteristics. In this paper, we exploit three different asymmetric convolutions in parallel and propose a new multi-scale asymmetric convolution unit, namely MAC block to enhance multi-scale representation ability of CNNs. In addition, MAC block can adaptively merge the features with different scales by allocating learnable weighted parameters to three different asymmetric convolution branches. The proposed MAC blocks can be inserted into the state-of-the-art backbone such as ResNet-50 to form a new multi-scale backbone network of object detectors. To evaluate the performance of MAC block, we conduct experiments on CIFAR-100, PASCAL VOC 2007, PASCAL VOC 2012 and MS COCO 2014 datasets. Experimental results show that the detection precision can be greatly improved while a fast detection speed is guaranteed as well.
Keywords
Introduction
Object detection is a hot topic of computer vision and digital image processing, which is widely used in robot navigation, intelligent video monitoring, industrial detection and many other fields. In 2019, Wu et al. 1 proposed a novel object detection framework using spatial-frequency channel feature. In Wu et al., 2 a novel and efficient framework (FRIFB) was presented for geospatial object detection. Experiments demonstrated the superiority and effectiveness of the FRIFB compared to previous state-of-the-art methods.
In recent years, Convolutional Neural Networks (CNNs) are increasingly applied to a variety of vision problems, such as object detection3–5 and image classification.6,7 Thanks to the huge development of deep neural networks, a large number of object detection methods have emerged. CNN-based object detectors are commonly classified into two-stage detectors and one-stage detectors. The two-stage detector such as Fast R-CNN 8 and R-FCN 9 has achieved great success in recent years. Fast R-CNN 8 employed several innovations to improve training and testing speed while also increasing detection accuracy. R-FCN 9 proposed position-sensitive score maps to address a dilemma between translation-invariance in image classification and translation-variance in object detection. Compared with the two-stage approach, the one-stage approach, such as YOLO, 10 SSD 11 and YOLOv3 12 have a better real-time performance while maintaining better detection accuracy. In Redmon et al., 10 training and detection were placed in a network, and object detection was solved as a regression problem. SSD 11 predicted objects at multiple layers of the feature hierarchy without combining features or scores. YOLOv3 12 improved the detection ability of small objects and reduced the overfitting of the network. In 2020, Yang et al. 13 proposed a new lightweight one-stage generic object detector to improve the detection accuracy of object detectors while maintaining a high detection speed.
Previous research Asymmetric convolutions have an obvious advantage on reducing the computational cost of CNNs. Kim et al. 14 proposed a macro unit, which employed asymmetric convolutions to reduce heavy computations and the number of model parameters. Jiang and Jin 15 designed a multiple asymmetric convolutional layer of different scales to extract nonlinear features of multi-granular n-gram phrases. Denton et al. 16 exploited the redundancy present within the convolutional filters to derive approximations based on Singular Value Decomposition manner, thereby significantly reducing the required computation. Jaderberg et al. 17 found that the set of horizontal and vertical filters can be learnt by explicitly minimizing the reconstruction error of the original filters. Jin et al. 18 applied structural constraints in 1D separated filter learning to achieve significant reduction in parameters. Szegedy et al. 19 have shown that a 7 × 7 convolution can be replaced by a 1 × 7 convolution. In practice, the authors found that using this factorization did not work well on earlier layers, but it gives good results with a grid size of 12–20. Ding et al. 20 proposed a new deep neural network (ACNet), which employed asymmetric convolutions to explicitly enhance the representational power of a standard square-kernel layer.
According to the above analysis, these researches on object detection methods based on asymmetric convolutions can reduce the computation cost significantly and improve the detection speed by network compression and acceleration. However, the amount of network parameters is reduced during the compression and acceleration process of the convolution network; therefore, the detection precision of the object detectors is sacrificed. It is a big challenge for object detection to achieve a fast detection speed while guaranteeing a high detection precision.
Actually, image features of objects usually present at multi-scale in natural scenes. The vision pattern of objects may appear with different sizes and aspect ratios in a single image. In order to improve detecting precision, it is beneficial to extract complete multi-scale image features in visual cognitive tasks. Asymmetric convolutions have another useful quality, that is, they have different aspect ratios, which can be used to exact image features of objects, especially objects with multi-scale characteristics. In this paper, we propose a new multi-scale building block for object detectors, namely “multi-scale asymmetric convolution” (MAC) block based on the different aspect ratios of asymmetric convolutions to enhance multi-scale representation ability of CNNs. By using the MAC block, the multi-scale problem of different sizes and aspect ratios in the image can be handled more effectively.
Our main contributions are summarized as follows:
we exploit three different asymmetric convolutions in parallel and propose a new multi-scale asymmetric convolution unit, namely MAC block to enhance multi-scale representation ability of CNNs.
The proposed MAC block can adaptively merge the features with different scales by allocating learnable weighted parameters to different asymmetric convolution branches.
The rest of this paper is organized as follows. The proposed MAC block and its mathematical formulation are described in section 2. The new multi-scale backbone network, MAC-ResNet-50, is given in section 3. Experiments and analysis are presented in section 4, and conclusions are drawn in section 5.
MAC block
MAC module
Considering the image features of objects usually appear at multiple scales in an image, we propose to construct MAC block to enhance the multi-scale representation ability of backbone network for object detectors. As shown in Figure 2, a MAC block has three parallel scales with kernel sizes of 1 × 3 and 3 × 1, 1 × 3, 3 × 1, respectively, which take the same input. The first scale: Asymmetric convolution with kernel sizes of 1 × 3 and 3 × 1, respectively; The second scale: Asymmetric convolution with a kernel size of 1 × 3; The third scale: Asymmetric convolution with a kernel size of 3 × 1. We fuse the features with three parallel scales. However, the features with three parallel scales usually contribute to the output unequally. Hence, as shown in Figure 1, a learnable weight is added to the MAC block. Suppose

The structure of MAC block.
To illustrate the MAC block more intuitively, we use a sliding window to provide the specific convolution process of the MAC block as shown in Figure 2. We only depict the sliding window at the top-left and bottom-right corners of the input feature map. The yellow part in the Figure 2 is the convolution kernel, and the rectangular frame surrounded by the red line represents the sliding window.
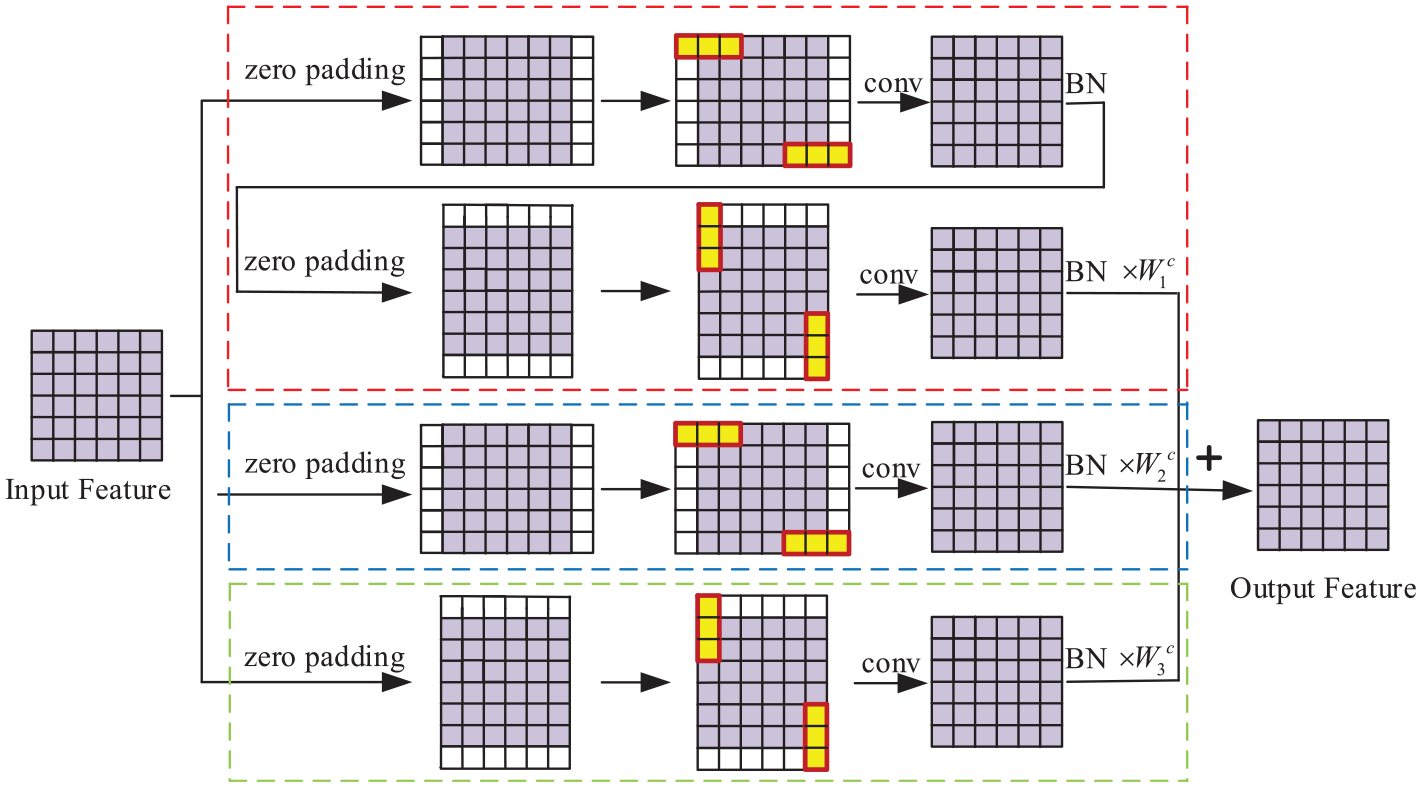
The convolution process of MAC block.
For the first scale of the MAC block, this scale consists of asymmetric convolution kernels of two sizes of 1 × 3 and 3 × 1, which can be equivalent to a 3 × 3 square convolution kernel. In this way, the network reduces the amount of parameters while obtaining the same effect of the 3 × 3 square convolution kernel. For the second scale of the MAC block, the aspect ratio of the 1 × 3 asymmetric convolution kernel is 1–3. When convolution operation is performed, 1 × 3 asymmetric convolution is more effective for processing objects with small aspect ratio. For the third scale of MAC block, the aspect ratio of 3 × 1 asymmetric convolution kernel is 3 to 1. When performing convolution operation, 3 × 1 asymmetric convolution is more beneficial for processing objects with large aspect ratio. Image features of different scales can be extracted by summarizing the feature maps output of the three scales. The three different asymmetric convolution scales of the MAC block make it more robust when dealing with multi-scale feature extraction of objects.
Mathematical formulation
As shown in Figure 1, for a scale in a MAC block,

Here * denotes convolution,
To reduce overfitting and accelerate the training process, we adopt a batch normalization 21 operation after the convolutional layer. As a common practice, in order to enhance the representation ability, we perform a linear scaling transformation after a batch normalization layer. Compared to (1), the output of the feature map channel then becomes
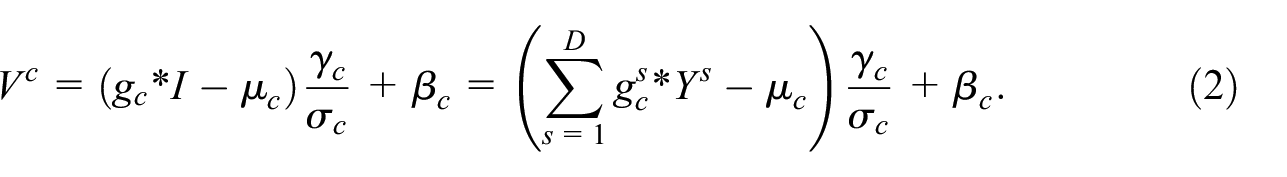
Where
Finally, we fuse the features with three parallel scales. The corresponding fused output feature map channel can be calculated as

Where
MAC-ResNet-50
The backbone network used to extract image features is an important part of object detectors based on CNNs. By analyzing the mathematical model of the MAC block, it illustrates the feasibility of employing asymmetric convolutions in parallel to enhance multi-scale representation ability of CNNs. In this section, we will introduce a new backbone network, called MAC-ResNet-50, by integrating the MAC block into an existing backbone network.
MAC blocks can be integrated into a state-of-the-art architecture by simply replacing every 3 × 3 layer such as residual modules. By making this change to the residual module, we can obtain a MAC-ResNet module. Figure 3 depicts the schema of the original residual module and a MAC-ResNet module.
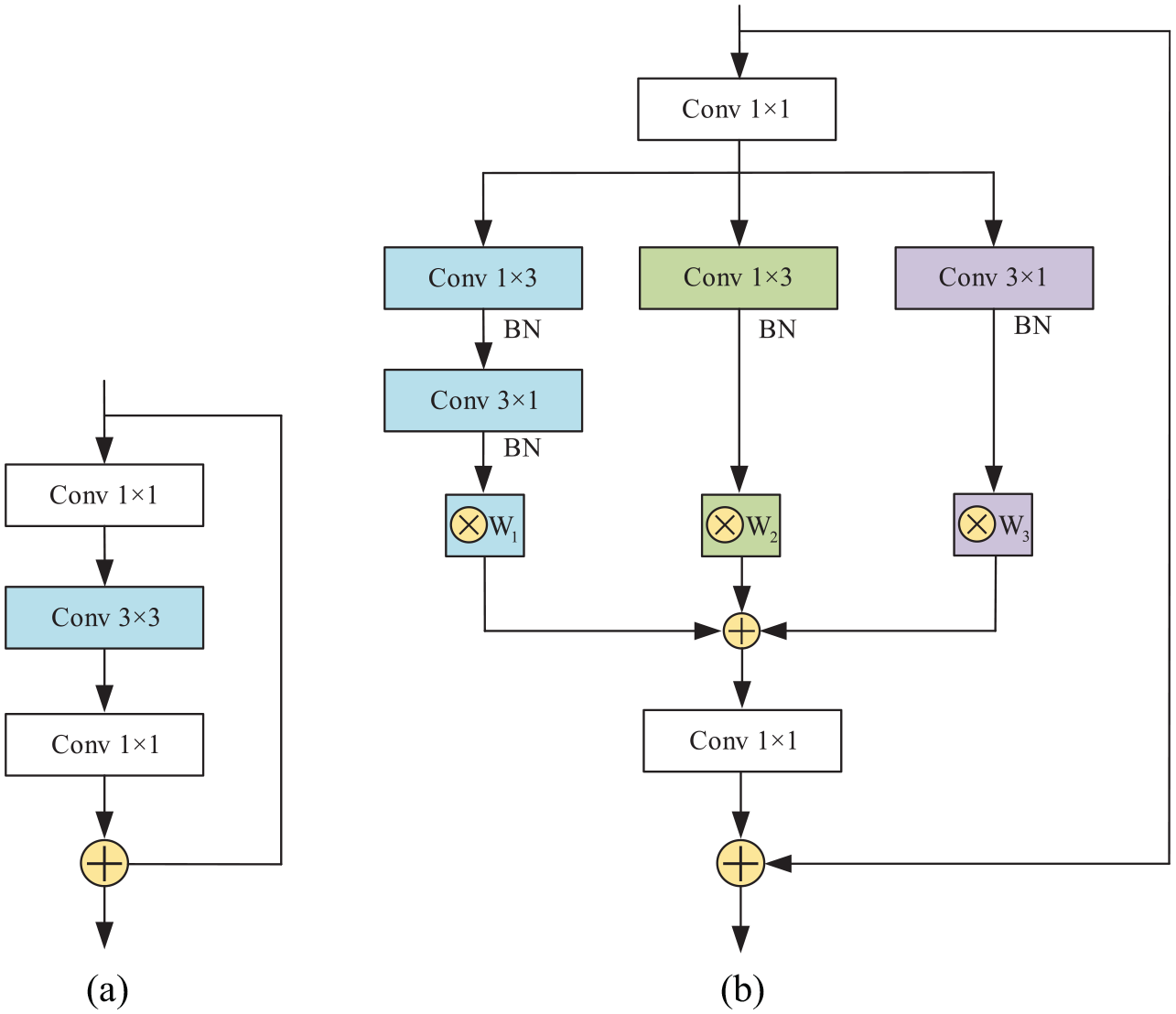
(a) The schema of the original residual module and (b) the schema of a MAC-ResNet module (right).
The new backbone network, called MAC-ResNet-50, is formed by stacking a set of repeated MAC-ResNet blocks, which are termed “MAC-ResNet units”. For a concrete example of MAC-ResNet-50 backbone architecture is presented in Table 1. Each MAC-ResNet unit consists of a sequence of 1 × 1 convolution, MAC block, and further 1 × 1 convolution. MAC-ResNet-50 uses {3, 4, 6, 3} MAC-ResNet units. The first column shows the size of the output feature map at each stage of MAC-ResNet-50. The second column shows the architecture of ResNet-50 with a 32 × 4d template. The third column shows the architecture of MAC-ResNet-50 based on ResNet-50 with a 32 × 4d template. Filter sizes, feature dimensionalities, and strides of a MAC-ResNet module are shown inside the brackets; the number of stacked blocks for each stage is shown outside the brackets.
MAC-ResNet-50 backbone network architecture based on the ResNet-50.

Experiments
In this section, we first conduct experiments to study the effectiveness of MAC block on the CIFAR-100 22 dataset. Besides, we adopt YOLOv3 12 as our detection method and MAC-ResNet-50 as our backbone network to form our object detector MACNet. We compare MACNet with other detection methods with the parameters of the Mean Average Precision (mAP) and the number of Frames per Second (FPS) on PASCAL VOC 2007, 23 PASCAL VOC 2012, 23 and COCO 2014 24 datasets. We implement the proposed models using the Pytorch framework. All experiments are performed on AMD 2700× CPU and GTX 1080Ti (11GB) GPU and use the Pytorch framework. We use a weight decay of 0.005 and a momentum of 0.9. The resulting model is fine-tuned using SGD.
CIFAR
In order to study the effectiveness of the MAC block, we conduct experiments on the CIFAR-100 dataset and evaluate single crop top-1 error rate. For the CIFAR-100 dataset, every model is trained 200 epochs and starts from a learning rate of 0.1 and divided by 10 every 60 epochs. The CIFAR-100 dataset consists of 60 k 32 × 32 color images drawn from 100 classes, which contain 50 k training images and 10 k testing images. During the training process, the image is flipped horizontally, filled with four pixels on each side, and then randomly 32 × 32 cropped. We use the implementation of ResNet-18, ResNet-50, and ResNet-101, as the representatives for the residual model architecture.
We compare the single-crop top-1 error rate of each baseline and our backbones on CIFAR-100. As shown in Table 2, MAC-ResNet-50 achieves significant performance gains over the ResNet-50 with 0.72. Compared with the ResNet-18, MAC-ResNet-18 has an improvement of 0.44 in terms of top-1 error rate. Remarkably, MAC-ResNet-50 achieves 20.43 top-1 errors, although ResNet-101 is 28.59% larger in parameter. The results show that MAC blocks are consistent in improving the performance of state-of-the-art CNNs. Testing curves comparisons for different architectures are shown in Figure 4. The plot in Figure 4 shows that compared to ResNeXt-29 with 23.68 M parameters, the MAC-ResNet-50 with 30.49 M trainable parameters is able to achieve higher accuracy.
Top-1 test error (%) and model size on the CIFAR-100 dataset.

#P denotes the number of parameters.

Testing curves on CIFAR-100. The parameters of ResNet-50 and MAR-ResNet-50 are 23.68 and 30.49 M, respectively.
VOC 2007
For VOC 2007 task, we use VOC 2007 trainval for training and VOC 2007 test for testing. MACNet and YOLOv3 are trained 200 epochs and start from a learning rate of 0.001 and divided by 10 every 60 epochs. The corresponding mAP is obtained by calculating the AP of each category when IOU = 0.5. As can be seen from the results in Table 3 and Figure 5, Faster DPM 25 improves detection accuracy compared to DPM, 25 but it sacrifices 2 times real-time performance. DPM has lower detection accuracy than neural network approaches. R-CNN minus R replaces Selective Search with static bounding box proposals. 26 R-CNN minus R has higher detection accuracy than Fastest DPM, but it still falls short of real-time. Faster R-CNN uses RPN to generate region proposals, which has greatly improved the detection accuracy. The detection accuracy and detection speed of Faster R-CNN reach 69.9 mAP and 7 FPS, respectively. Compared with Faster R-CNN, R-FCN has a 5.8 improvement on mAP. MACNet has a mAP of 75.7, which is 4.9 higher than YOLOv3’s 70.8. As for detection speed, MACNet has the similar detection speed with YOLOv3.
PASCAL VOC 2007 test detection results. Training data key: VOC 2007 trainval. “impl.”: the model we implemented.


Time-mAP comparison chart on the VOC 2007 test. Training data key: VOC 2007 trainval.
VOC 2012
For VOC 2012 task, we follow the same experimental setting of VOC 2007, but use 2007+2012 consisting of VOC 2007 trainval and VOC 2012 trainval for training. As can be seen from the data in Table 4 and Figure 6, the MACNet has a 6.1% improvement in detection precision over the YOLOv3. Compared to the ZF model based Faster R-CNN, the two-stage approach, Faster R-CNN VGG-16 and Faster R-CNN ResNet, has a certain improvement in precision, but has a reduced detection speed. Compared with the two-stage approach, the one-stage approach greatly improves the detection speed. YOLO achieves good detection precision, and detection speeds up to 45 FPS. Because the SSD draws on the regression idea of YOLO and the anchor boxes mechanism of Faster R-CNN, its detection speed and precision are better realized. Compared with other methods, MACNet has a detection precision of 81.7 mAP while maintaining good real-time detection.
PASCAL VOC 2007 test detection results. Training data key: “2007 + 2012”– VOC 2007 trainval and VOC 2012 trainval.


Time-mAP comparison chart on the VOC 2007 test set. Training data key: “2007 + 2012”– VOC 2007 trainval and VOC 2012 trainval.
As can be seen from the data in Table 5, on the VOC 2012 test, the detection precision of SSD is lower than R-CNN, Fast R-CNN, and Faster R-CNN. However, compared with the two-stage object detection method, YOLOv3 improves the detection precision to 73.4 mAP. Besides, compared with other methods, MACNet achieves the detection precision of 77.8 mAP. In addition, as can be seen from Table 5, MACNet has a better detection effect for objects such as bus and people with different aspect ratios and large differences in sizes such as airplane and bottle.
PASCAL VOC 2012 test detection results. Training data key: “2007 + 2012”– VOC 2007 trainval and VOC 2012 trainval.

COCO 2014
For the MS COCO 2014 dataset, it contains 80 k images for training, 40 k for validation and 20 k for testing. We use the 80 k training set plus a 35 k val subset for training, minival (a 5 k val subset) for validation. MACNet and YOLOv3 are trained 140 epochs and start from a learning rate of 0.001 and divided by 10 every 40 epochs. Table 6 shows the AP of the YOLOv3 and MACNet models. The detection results of the YOLOv3 and MACNet models are shown in Table 5. The mAP is calculated by averaging the AP on the IOU [0.5, 0.95]. MACNet achieves a mAP of 30.0%, which outperforms the YOLOv3 by 2.1 points while maintaining good real-time detection. The detection effect of the MACNet model on the COCO 2014 val is shown in Figure 7.
Detection results of the YOLOv3 and MACNet on the COCO 2014 val. Training data key: COCO 2014 train.


The detection effect of MACNet model on COCO 2014 val. Training data key: COCO 2014 train.
Conclusions
In this paper, we propose a new building block for CNNs, namely “multi-scale asymmetric convolution” (MAC) block, by exploiting asymmetric convolutions in parallel to enhance multi-scale representation ability of CNNs. MAC block can merge the features with different scales by allocating learnable weighted parameters to three different asymmetric convolution branches. In addition, MAC blocks can be inserted into an existing backbone such as ResNet-50 to form a new backbone network MAC-ResNet-50. Experimental results on different datasets show that the object detector using MAC-ResNet-50 has a higher detection precision while satisfying good real-time detection requirement comparing with some state-of-art detectors.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Shanghai Science and Technology Development Foundation under grant number 19511103402.