
Abstract
The paper proposes improvements to YOLOv8n to enhance small target detection capabilities and introduces coordinate attention (CA) to the C2f module to improve focus on spatial information and local details. CA enhances spatial feature representation and small object recognition and replaces Path Aggregation Network with Bidirectional Feature Pyramid Network (BiFPN) in the neck to better fuse multi-scale features. BiFPN enables more effective fusion of features at different scales and adds a smaller detection head to improve perception of very small targets. The additional detection head utilizes more shallow feature information and incorporates Omni-dimensional Dynamic Convolution (ODConv) to adaptively adjust convolution kernels. ODConv allows flexible capture of critical information for various target patterns and sizes. Experimental results show the proposed improvements lead to better performance on small object detection tasks, with increases in metrics like average precision mean (mAP), precision, and recall. The combined enhancements aim to address common challenges in small target detection such as low contrast, large-scale differences, and the need for fine-grained feature capture. Compared to the original YOLOv8n algorithm, this algorithm improves the average accuracy on small targets by 3.2% for mAP@50, 4.4% for mAP@75, 3% for Precision rate, and 4% for Recall.
Introduction
Recent improvements in YOLOv8 focus primarily on attention mechanisms, multi-scale feature fusion networks, and regression loss. To identify fruits, the YOLOv8 model 1 employs cross-stage partial (CSP) and C2f (CSP2) modules to facilitate lightweight processing. The incorporation of these modules is aimed at improving efficiency and performance.
Small object detection has important application value in the fields of computer vision and artificial intelligence, especially in areas such as security monitoring, autonomous driving, and disease treatment. Small targets usually refer to targets that occupy small areas in an image, such as distant pedestrians, cancerous areas, and lesion areas. Due to the limited feature information of small targets and frequent interference from background noise, traditional object detection algorithms perform poorly in handling small targets. Small object detection poses significant challenges in the field of computer vision, and common issues can be summarized in detail as follows. Small targets occupy a small area in the image and contain less feature information, making it difficult for traditional convolutional neural networks (CNNs) to capture sufficient useful information during feature extraction. Deep neural networks typically rely on higher-level features, where small targets may have already been eliminated. After multiple downsampling and pooling operations, the information of small targets may be lost, even on high-resolution inputs. Small targets are prone to interference from complex backgrounds or occlusion by objects, which can affect detection accuracy. The scale variation of small targets in different scenarios increases the difficulty of detection. The distance between the object and the camera causes significant changes in the size of the target, and the detection model needs to be able to adapt to this multi-scale problem. There is limited annotated data for small targets, which affects the training effectiveness of the model. Small targets have a relatively small proportion in the dataset, making it susceptible to class imbalance during model training. The data collection and annotation of small targets are more difficult, especially for certain specific fields such as military and remote sensing images. Multiple downsampling in deep learning (DL) models reduces the resolution of small targets, making them more difficult to detect. The downsampling operation in the network structure will result in a loss of spatial resolution, further weakening the ability to detect small targets. By using spatial and channel attention mechanisms to weight features, the accuracy of small object detection has been improved. 2 Feature pyramid network (FPN) improves the detection performance of small targets by constructing a bottom-up feature pyramid, extracting high-resolution small target features from low-level feature maps, and further integrating these features into high-level feature maps. 3 An innovative plug-and-play feature enhancement module that incorporates multi-scale local contextual information to bolster detection performance for small objects. 4 Reference 5 developed an efficient detection framework that improves the detection performance of small targets at different resolutions through fine parameter adjustments and network design. Based on Feature Aggregation and Propagation Network, effectively integrating the features of adjacent layers and utilizing cross-level correlations, a multi-scale feature aggregation module was designed to improve the accuracy of small target recognition. 6
To address the misdetection and missed detection of small targets, the Bi-PAN-FPN approach 7 is introduced to enhance the neck part of the YOLOv8-s model and the backbone of the benchmark model incorporates the GhostblockV2 structure, which replaces part of the C2f module. To enhance the network's ability to extract diverse features, the Multi-Head Self-Attention mechanism is utilized in MHSA-YOLOv8. 8 In the intermediate neck layer, the traditional convolution process is replaced 9 by the Ghost Shuffle Convolution mechanism. This substitution reduces the number of model parameters and improves the convergence speed. In, 10 the authors modify the structure of the FPN-Path Aggregation Network (PANet) in the YOLOv8 to achieve multi-level feature fusion among different layers by strengthening the multipath fusion of the networks. In order to detect brain tumors in, 11 a Convolutional Block Attention Module (CBAM) was added to YOLOv7 to enhance feature extraction capabilities and enable the model to better focus on significant regions related to brain tumors. Twins 12 and CAT 13 alternatively perform local and global attention at different layers. Swin transformers 14 execute local attention within a window and introduce a shift-window partition method for cross-window connections.
For more research on YOLO, refer to the following literature.15,16
In the healthcare sector, researchers have employed a diverse array of machine learning algorithms to enhance cancer diagnosis. These methods include traditional algorithms such as support vector machines, k-nearest neighbors, decision trees, and Naive Bayes, as well as DL techniques, including CNNs, VGGNets 17 GoogleNet, 18 and ResNets, 19 to aid in the diagnosis of cancer. However, existing classification methods often exhibit limitations in precision and recall, leading to inefficiencies and prolonged classification times that may delay the initiation of treatment. 20 These limitations mainly include overfitting, data imbalance, insufficient feature extraction and computational constraints. Furthermore, these techniques have also been applied to the diagnosis of neurological disorders and the analysis of brain tumor images,21,22 To solve the above problem, we introduce the following improved YOLOv8 scheme.
The main contributions of this article are summarized as follows. Effective solutions have been proposed to address the following shortcomings of YOLOv8n.
YOLOv8n has low detection accuracy for small targets, often leading to missed detections. This is due to the features of small targets being diluted or lost in deep networks, making it difficult for the detector to capture these tiny defects. YOLOv8n has limitations in feature fusion, especially when dealing with complex backgrounds and small targets. Traditional FPNs have limited effectiveness in multi-scale feature fusion and fail to fully utilize shallow features to improve the detection accuracy of small targets. Although YOLOv8n optimizes computational complexity while maintaining high detection accuracy, further optimization is still needed when applied to high-density tumor detection to meet real-time detection requirements.
To address the aforementioned issues, an improved tumor detection solution has been proposed, which includes the following innovative designs.
The Efficient Coordinate Attention Network (ECANet) is utilized to improve the C2f module (from CSPDarknet53 to 2Stage FPN), strengthening the channel attention mechanism and effectively enhancing the detection accuracy of small targets. Adopting Bidirectional Feature Pyramid Network (BiFPN). By replacing the Neck component in the original network, the utilization of shallow features is enhanced, thereby improving overall detection performance. A dedicated small target detection head with a coordinate attention (CA) is added to the network to enhance its ability to perceive small targets, reducing the incidence of missed detections for small targets. Omni-dimensional dynamic convolution (ODConv) Technology is applied. Through multi-dimensional dynamism, ODConv can adaptively extract delicate and complex features, effectively responding to various input changes.
Compared to the original YOLOv8n algorithm, this algorithm improves the average accuracy on small targets by 3.2% for average precision mean (mAP)@50, 4.4% for mAP@75, 3% for Precision rate, 4% for Recall.
YOLOv8
As shown in Figure 1, YOLOv8n consists of Backbone (backbone network), Neck (neck network) and Head (head network).

YOLOv8 network structure.
The backbone network uses the C2f module, which is an improved CSPBottleneck (cross-stage partial bottleneck) structure. The core idea of the CSPBottleneck structure is to split the input feature maps of the traditional convolutional layers or residual blocks and have them processed through different paths, and then in the later part then fuses these two paths of features. 23 On the basis of CSPBottleneck, the C2f module extracts features through cross-stage connections, effectively reducing the number of model parameters and computational complexity. This design not only improves the running speed of the model, but also maintains efficient feature extraction capability.
In the Neck network of YOLOv8n, a PANet structure is adopted. PANet is an improvement based on the FPN, which adopts a top-down feature pyramid structure, while PANet introduces a bottom-up information transmission mechanism, allowing low-level signals to be transmitted to high-level features, thereby enhancing the expressive power of the entire feature hierarchy. In addition, PANet also introduces the Adaptive Feature Pooling Module, which can aggregate feature maps from different levels, allowing useful information from each layer to be directly transmitted to subsequent sub-networks.
In the Head section of YOLOv8n, a Decoupled Head structure is adopted, which can separate the classification head and detection head, making the model more flexible in processing objects of different sizes. In addition, YOLOv8n also adopts an anchor free method, abandoning the traditional anchor based design concept and directly predicting the position and other attributes of the target from image pixels. This simplified detection process significantly improves inference speed and further enhances the overall performance of the model.
The aforementioned model's ability to detect small targets still needs improvement. To address this issue, we will focus on the following aspects to enhance small target detection capabilities. With the introduction of CA, the network can pay more attention to local details in the image, enhancing its ability to recognize small targets, especially in complex backgrounds. BiFPN is not just about simply fusing features of different scales; it improves the complementarity between shallow and deep features by gradually optimizing the feature fusion process. This helps to solve common challenges in multi-scale object detection, such as low contrast of small targets and large-scale differences, thereby improving the detection accuracy of small targets. In traditional convolution, the convolution kernel is fixed and may not effectively capture the detailed information of small targets. By dynamically adjusting the convolution kernel, Full Dimensional Dynamic Convolution can perform adaptive convolution based on the characteristics of small targets, enabling better capture of their features and improving the accuracy of small target detection. To address the above problems, this paper proposes an improvement strategy YOLOv8n Figure 2 to enhance the detection capability of YOLOv8n for small targets.

Improved YOLOv8 network structure.
Coordinate attention
The C2f module is a part of CSPDarknet53 (Cross-Stage Partial Darknet53),24,25 mainly used for feature extraction and transmission. It improves the expressive power and efficiency of the model by dividing the feature map into two parts for parallel processing and then merging them. This structure can effectively reduce computational overhead while maintaining the representational power of the model. CA is a commonly used attention mechanism in computer vision tasks, aimed at enhancing the network's ability to focus on spatial information. It enhances feature expression by introducing coordinate information, enabling the network to more effectively capture important spatial location and contextual information. Combining the C2f module (CSPDarknet53 to Stage 2 FPN), the introduction of CA can significantly improve the performance of the network.
The core idea of CA is to enhance the network's attention at specific locations by encoding the spatial positions of feature maps. Specifically, CA is achieved through the following steps. Divide the input feature map into two channels, one for horizontal information and the other for vertical information. Perform global average pooling on the feature maps of each channel to obtain two one-dimensional coordinate vectors, representing the attention distribution in the horizontal and vertical directions, respectively. Mapping one-dimensional coordinate vectors to the channel dimension through two fully connected layers to generate corresponding attention weights. These weights reflect the relative importance of feature maps at different spatial positions. Multiply the original feature map with the generated attention weights channel by channel to achieve feature recalibration, allowing the network to focus more on important feature regions.
First, CA (Coordinated attention) 28 is used to improve C2f(CSPDarknet53 to 2-Stage FPN) 26 module. CA aggregates global information along spatial dimensions, allowing each pixel to consider global contextual information when generating attention weights. This aggregation of global information significantly improves the richness and discriminability of feature representation. Due to the ability of CA mechanism to accurately locate and enhance important spatial positions and channels, it helps to capture more refined and meaningful features, which is particularly important for complex image tasks. By focusing on important spatial positions and channels, CA mechanism can effectively suppress the interference of noise and irrelevant features, and improve the sensitivity of the model to key information in the input image.
Many attention mechanisms, such as self-attention, typically consider the relationships between features on a global scale, but may overlook subtle differences in local spatial information. Channel attention mainly focuses on the interrelationships between channels, but its attention to spatial information is not as direct as CA. Self-attention mechanism complexity is O((H × W)2 × C), and CA complexity is O(H × W × C), where H and W are the spatial dimensions of the feature map, and C is the number of channels. Compared to traditional self-attention mechanisms, CA has lower computational complexity because it only requires the calculation of two one-dimensional global average pooling, without involving the calculation of the interrelationships between all positions on the feature map, thereby reducing computational costs. By comparing the structures of SE, CBAM, and CA, we observe that SE uses only channel features, CBAM uses channel features and location features, but CA uses not only channel features and location features, but also direction-aware features. Although other attention mechanisms also attempt to capture contextual information, CA enhances the spatial relationships of features through clear coordinate directions, further improving the performance of the model in complex scenes. CA can effectively adjust the focus on various directions when dealing with targets of different sizes, shapes, and poses, making the model more adaptable. Some attention mechanisms may perform well on specific types of targets, but may be limited in complex scenes. The design of CA makes it more universal and able to maintain good performance in various scenarios.
For the problem of small target leakage detection, this paper adds a smaller detection head to enhance the network's perception of small targets. In order to enhance the utilization of shallow features, the original network in the Neck part is replaced with BiFPN 27 network. In order to reduce the significant increase in network layers caused by the changes of the first two, GSConv 32 (Cross-Stage Channel wise Convolution) technology is introduced in the Neck section.
CABiFPN structure
In order to further enhance the utilization of shallow features, this paper replaces the original PANet structure with BiFPN structure in the Neck section, as shown in Figure 3.

CABiFPN.
BiFPN introduces bidirectional connections, allowing the network to effectively fuse features across different scales through both top-down and bottom-up pathways. This bidirectional nature ensures that high-level features and low-level features can complement each other, enhancing the richness of feature representation. BiFPN also adds additional connections between the same layers, further improving feature fusion capability. In contrast, PANet primarily relies on top-down paths, which makes it difficult to fully leverage low-level feature information.
BiFPN allows the network to dynamically adjust the weights of input features based on their importance during the feature fusion process. This adaptive weighting strategy enables the network to flexibly select and integrate features, leading to better performance across different scenarios and target sizes. By dynamically adjusting weights, BiFPN effectively avoids the information loss that can result from fixed-weight fusion and reduces the risk of overfitting.
One of the design principles of BiFPN is to eliminate nodes with only one input edge, thereby simplifying the network structure and reducing unnecessary computational overhead. This simplification not only improves the computational efficiency of the model but also accelerates inference speed. BiFPN excels at processing multi-scale features, allowing YOLOv8 to more effectively utilize low-level features in small object detection tasks, thereby improving detection accuracy for small objects. This is particularly important in object detection tasks, as small objects are often overlooked or misclassified.
Combining CA mechanism with BiFPN can further enhance the effectiveness of object detection through the following methods. In the feature fusion process of BiFPN, CA mechanism is applied to adjust the weight of features in 50/10,000 real-time translation, so that specific regions of features receive higher attention. In the feature fusion process of BiFPN, CA mechanism is applied to adjust the weights of features, so that specific regions of features receive higher attention. Before the input features of each BiFPN module, CA processing is performed to enhance the expressive power of the features, thereby obtaining more effective feature representations during fusion. The multi-level feature fusion combined with CA mechanism can better capture the spatial information of the target and improve the complementarity of features between different levels.
Detection head
The original model is designed with three detection heads, in the small target detection task; there are often very small targets to be detected, especially in the brain tumor defect dataset. There are more targets smaller than 3*3 pixels, and in the backbone network and the Neck end of the shallow feature maps contain richer information about the small targets that are not fully utilized. In order to fully apply the small target information, we elicit the new detection head on the YOLOv8 model by the features after the second downsampling. In order to highlight the positional features, CA mechanism is integrated here. YOLOv8 was downsampled a total of five times, and after each downsampling, the feature map becomes 1/2 of the original image. In this paper, the initial image size is set to 640*640 pixels. The size of the detection head feature map is 160*160 pixels, which contains richer underlying feature information of the target due to two downsamplings.
Omni-dimensional dynamic convolution
ODConv 29 is an innovative convolution method aimed at improving the adaptability of neural networks in feature extraction and representation. ODConv dynamically adjusts the weights of convolution kernels in spatial dimension, input channel, output channel, and kernel dimension. ODConv can dynamically adjust the weights of convolution kernels based on the features of input data, enabling the network to better adapt to different inputs. Multi-dimensional dynamic convolution kernels are used for convolution operations, including the following. The spatial dimension adjusts the convolution kernel based on the spatial variation of the input feature map. The channel dimension adaptively adjusts weights on each channel. Convolutional window dimension adjusts the weights of convolution windows of different sizes. ODConv introduces a novel multi-dimensional attention mechanism that can simultaneously learn four types of attention, targeting the four dimensions of position, channel, filter, and kernel of the convolutional kernel. These four types of attention are learned in parallel, and by applying them sequentially to different dimensions of the convolution kernel, the feature extraction ability of the convolution operation can be enhanced. Position attention makes convolution operations different for all spatial positions. Channel attention makes the convolution operation different for all input channels. Filter attention adjusts the behavior of each filter (or convolution kernel) based on input features. Kernel attention adjusts the weights of convolutional kernels at a finer granularity.
Position attention focuses on spatial positions within feature maps. It generates a weight for each location that determines the contribution of that location to the final feature map. In a concrete implementation, a positional code can be used to weight the input feature map so that the features at each spatial location are different during convolutional computation. By assigning different weights to each spatial location, positional attention allows convolutional operations to capture spatial information more flexibly, enhancing the model's sensitivity to detail. It can be represented mathematically as follows:

The channel attention mechanism focuses on the different channels of the input feature map. It generates a weight for each channel that reflects the importance of that channel in feature extraction. The global features for each channel are usually obtained by performing global average pooling or global maximum pooling on the feature graph, and then the channel weights are generated by a small network (e.g. a fully connected layer). Channel attention adaptively adjusts the contribution of each channel, thereby reinforcing the impact of important feature channels and suppressing unimportant ones. It can be defined as follows:

Filter Attention focuses on the output of each convolutional filter, adjusting the response of each filter to the input feature map. The global features of the output feature maps of each filter are computed; and these features are used to generate the weights of the filters. Filter attention allows the model to adaptively adjust the influence of each convolutional filter to improve sensitivity to specific features. It can be represented as

The kernel attention focuses on the weights and properties of the convolutional kernels themselves. By weighting the weights of each convolutional kernel, this mechanism is able to dynamically adjust the performance of the convolutional kernel in the feature extraction process. Kernel attention can be achieved by combining the weights of a convolutional kernel with specific input features to generate a new convolutional kernel that can be used to enhance or inhibit the extraction of specific features. Kernel attention allows the model to dynamically adjust the behavior of the convolution kernel according to changes in the input features, thus improving the flexibility and adaptability of feature extraction.

Through multi-dimensional dynamism, ODConv can adaptively extract delicate and complex features, effectively responding to various input changes. Due to weight adjustments in multiple dimensions, ODConv can capture and fuse more feature information, thereby improving the overall representation ability of the network. The adaptability of multi-dimensional dynamic convolution kernels can reduce overfitting and improve the generalization performance of the network on different test data, making it suitable for various tasks and scenarios. This flexibility helps improve the performance of the model on various datasets, especially in scenarios where feature distributions vary greatly. Due to its ability to simultaneously optimize the weights of convolution kernels in multiple dimensions, ODConv is typically more effective than traditional convolution methods in capturing complex feature relationships, thereby improving the overall performance and accuracy of the model. The combination of ODConv and attention mechanism enables the model to dynamically adjust the weights of convolution kernels during feature extraction, and better focus on the information required for the current task during feature selection, thereby enhancing the interpretability of the model.
Motivated by VoVGSCSPC 32 architecture, we proposed VoVODCSPC architecture. As shown in Figure 4(a), ODConv introduces a novel multi-dimensional attention mechanism that can simultaneously learn four types of attention, targeting the four dimensions of position, channel, filter, and kernel of the convolutional kernel. The concatenation operation then combines these features, followed by a shuffle mechanism to mix multi-dimensional channel features from both convolutions. This ensures comprehensive exchange and integration of information between channels. This design promotes efficient interaction of information between network channels while reducing the overall computation time and resource consumption, thus improving efficiency while maintaining model performance.

VDC.
As depicted in Figure 4(b), the ODBottleneck architecture is an innovative design that integrates the core components of two ODConv units along with a DWConv module. In this architecture, raw input feature data is fed in parallel to both ODConv modules and a separate DWConv module for independent processing. Each module uniquely extracts and transforms the input features. Subsequently, the outputs of these three modules are overlaid and combined to form the final feature representation.
As shown in Figure 4(c), the VoVODCSPC architecture adopts a more efficient one-time aggregation strategy based on the ODBottleneck design. This means that VoVODCSPC optimizes and integrates the operation of multiple ODBottleneck structures, refining key features through a single computation process. This aims to significantly reduce the overall computational load and parameter size of the network while maintaining the model's prediction accuracy.
By using these designs, ODConv modules and their derivatives ensure a high level of efficiency and accuracy in CNNs, providing enhanced performance for various neural network applications.
Experiment result
Configuration and network environment are presented in Table 1. The dataset established in this article comes from the publicly available Kaggle competition dataset, Data set source: https://www.kaggle.com/sartajbhuvaji/brain-tumor-classifica, which includes four categories: pituitary adenoma, meningioma, glioma, and no-tumor. By enhancing the original data images, we used a total of 7500 images. 4500 images were randomly selected as the training set; randomly select 2000 images as the validation set; randomly select 1000 images as the test set; appearing in different positions, postures, and angles. The proportion of the four categories of pituitary adenoma, meningioma, glioma and non-tumor in the dataset is 25%, respectively.
Configuration and network environment.

In order to verify the model performance, the precision rate (P), recall rate (R), average precision (AP), mAP are selected to evaluate the detection performance of the model. If a positive instance is predicted correctly as positive, it is counted as a True Positive (TP). If a negative instance is predicted correctly as negative, it is counted as a True Negative (TN). If a negative instance is incorrectly predicted as positive, it is counted as a False Positive (FP) (Type I error). If a positive instance is incorrectly predicted as negative, it is counted as a False Negative (FN) (Type II error). For more details of these metric indicators, see. 31
Based on Table 2, the experimental results show that all features contribute to the performance improvement of the model. Each feature plays a positive role in improving model accuracy, recall, and mAP, and their combined effect improves the performance more than the individual features alone. Especially, the activation of ODConv has a significant impact on improving accuracy and recall, which is related to its role in optimizing convolutional layer processing, helping the model better identify targets and reduce false positives. C2f ECA and CAHead also perform well in improving model accuracy and recall, as they enhance the model's contextual understanding ability in object detection. Compared with other methods, Table 3 demonstrates the effectiveness of the proposed method Improved YOlOv8.
Comparison of ablation experiments.

ODConv: omni-dimensional dynamic convolution; mAP: average precision mean.
Comparison with several typical networks.
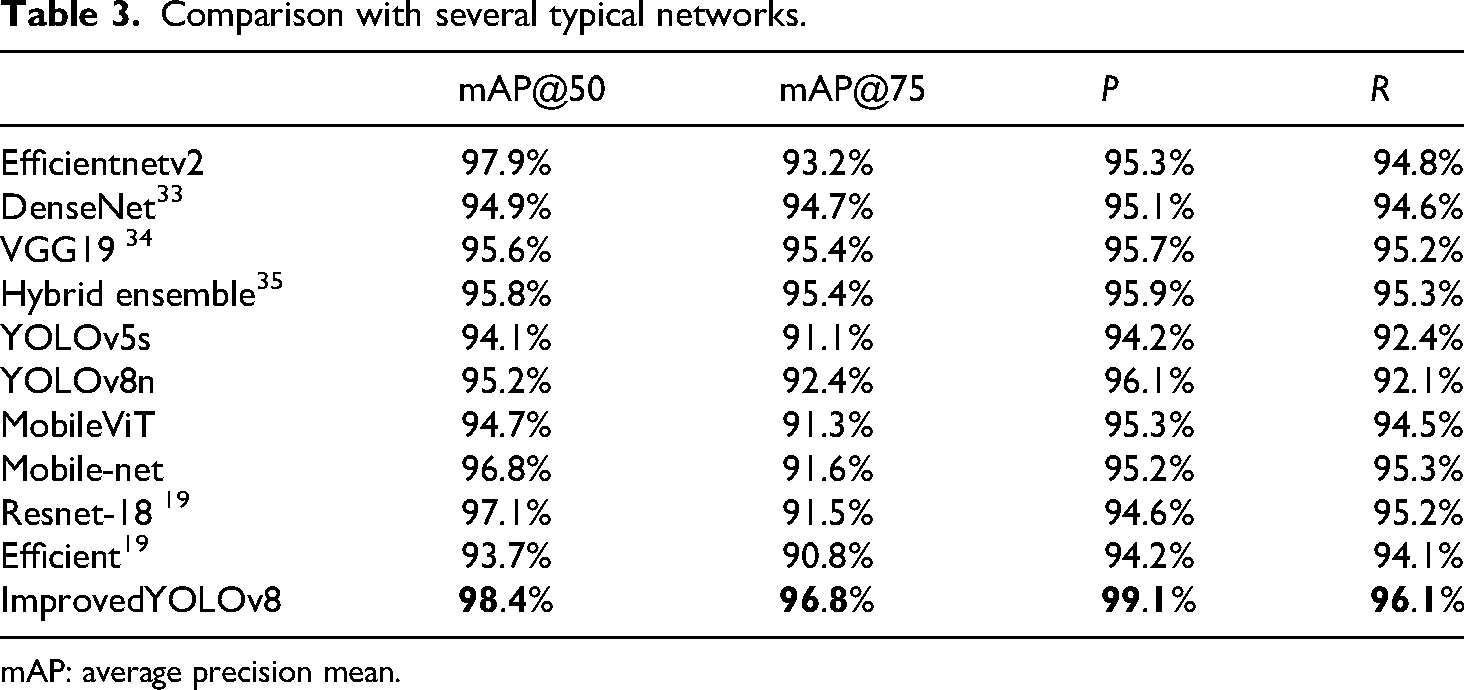
mAP: average precision mean.
Figures 5 and 6 provide visual renderings, demonstrating the effectiveness of our pro-posed method. In Figure 5, the precision rate of most images is less than 95%, while in Figure 6, the precision rate of most images is greater than 98%.

YOLOv8 image.

Improved YOLOv8.
To demonstrate the effectiveness of the method, we also tested it on the following dataset: 879 mammography images from the DDSM dataset region of interest (ROI) imaging was used for tumor and non-tumor recognition experiments, with 703 ROIs used as training samples to train CNN models, leaving the remaining 176 ROIs to be used as test samples, and the data partitioning method is as follows Table 4.
Dataset partitioning and augmentation.

The AP value of each model reflects its ability to distinguish between categories on the test set. A higher AP value indicates a better balance between accuracy and recall. Based on the results shown in Figure 7, the model proposed in this study exhibits the best performance, demonstrating its ability to maintain high accuracy across most recall rates. This suggests that the model performs well in identifying positive samples. In comparison, the overall performance of the ResNet series is commendable, particularly ResNet34 and ResNet101. However, the ConvNext series performs slightly less well in comparison.

Pr curve.
In order to comprehensively compare the effectiveness of the methods, we also compared multiple methods on the second dataset. From the experimental results Table 5, our methods have performed better than other models.
Comparison with several typical networks.

Conclusion
In conclusion, this paper presents effective solutions to address the shortcomings of YOLOv8n in small target detection, feature fusion, and computational efficiency. The proposed improvements are presented as follows.
CA enhances the representation of spatial information in feature maps, enabling better integration of spatial positions and contextual information, thus improving feature representation capabilities. By introducing global contextual information for each pixel and focusing on important spatial locations in the image, CA improves the ability to recognize small objects. BiFPN enables efficient feature fusion, allowing features of different scales to combine more effectively. This is especially crucial for small object detection, as it helps the network leverage shallow, fine-grained features to improve the accuracy of small object detection. CA, by enhancing attention to specific spatial positions, contributes to improving object localization accuracy, particularly when the target position is complex or the target scale is small, allowing for accurate identification and localization of object boundaries. CABiFPN optimizes multi-scale feature fusion, improving localization accuracy, especially for complex multi-object detection tasks, where CABiFPN effectively enhances precise localization of objects. Dynamic Convolution, by dynamically adjusting the convolution kernel weights based on input features, allows the model to flexibly capture critical information when dealing with targets of varying patterns and structures. This has a significant impact on precise localization and classification in object detection, particularly in complex backgrounds or small object detection tasks. By dynamically adjusting the convolution kernels, ODConv can perform adaptive convolution based on the characteristics of small objects, enabling better capture of small object features and thus improving the precision of small object detection.
By incorporating a dedicated small target detection head with CA, the model's ability to perceive and accurately detect small targets is significantly improved, reducing the incidence of missed detections.
The ECANet is utilized to improve the C2f module (from CSPDarknet53 to 2Stage FPN), strengthening the channel attention mechanism and effectively enhancing the detection accuracy of small targets.
Through these comprehensive improvements, the enhanced YOLOv8n model achieves better detection accuracy for small targets, more effective feature fusion, and higher computational efficiency, making it more suitable for real-time detection applications, especially in high-density tumor detection tasks.
Limitations and future research directions
The spatial resolution, if not sufficiently high, weakens the ability to detect small targets accurately. Research can focus on enhancing the spatial resolution or utilizing more advanced multi-scale attention mechanisms to further improve small target detection. In complex scenes, where both small targets and intricate backgrounds exist, the fusion of multi-scale features is not fully effective, leading to suboptimal detection accuracy. Developing more advanced feature fusion techniques that better integrate shallow features with deeper layers may help address this issue. The current system may not be fast enough for real-time applications, particularly in cases where detection needs to be performed on dense or rapidly changing data. Future research should focus on balancing the trade-off between accuracy and computational efficiency, potentially exploring lightweight models or optimization algorithms tailored to real-time detection. While ECANet enhances the channel attention mechanism, there may still be limitations in handling highly complex and noisy scenes. Further refining the attention mechanisms, particularly for handling small targets in noisy or cluttered environments, could improve model performance. While ODConv helps with feature extraction in complex scenarios, the model may not yet fully address the issue of handling extreme variations in target size, shape, and pose. Research can explore more adaptable or context-aware convolution techniques that further enhance feature extraction capabilities for small target detection in diverse environments.
Footnotes
Acknowledgements
The authors would like to acknowledge the support from Jiangsu Second Normal University for providing the necessary resources and funding to conduct this research.
Ethical committee approval
Not applicable.
Author contributions/CRediT
LB was involved in conceptualization, methodology, software, validation, formal analysis, investigation, writing—original draft, writing—review and editing, and visualization. ZS was contributed to supervision, project administration, funding acquisition, and resources.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Jiangsu Second Normal University, Grant Number 927801/013 and Jiangsu Province Engineering Research Center of Basic Education Big Data.
Competing interest
The author declares that he has no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.