
Abstract
Currently, purely deep learning-based agents struggle to make optimal decisions within a short timeframe in problems with a vast decision-making space. Human planning knowledge is required to assist agents in making better decisions. This manuscript proposes a novel knowledge-guided and data-driven decision-making framework, utilizing hierarchical task network as the carrier of knowledge, deep learning as the trainer for data, and the Monte Carlo Tree Search as the connector between hierarchical task network and deep learning. The experiments on the MiniRTS environment validated that the proposed framework in this manuscript can replace humans in collecting high-quality data, and it can train neural networks that perform equally well as the compared network even with only 20% of the available data, which provide a new direction for future research.
Introduction
With the advancement of computer hardware technology, the powerful computing power has been brought, and collecting large amounts of data has been easier compared to the past. Thus, Deep Learning (DL) has accomplished achievements beyond humanity in multiple fields, such as image processing,1,2 speech recognition,3,4 natural language processing,5,6 and Go.7,8 In recent years, due to the increasing demand for mental entertainment, a growing number of high-level computer games have been developed. Among them, Real Time Strategy (RTS) games have gained a significant share. As a result, DL has started to be applied in the development of interactive intelligent agents,9–11 providing opportunities for human players to compete and train, and to some extent, addressing challenging issues in intelligent task planning.
Due to the characteristics of a large decision-making space and short response time in RTS games, traditional DL methods have struggled to achieve high accuracy, resulting in weak performance of trained intelligent agents. With the ease of data collection and breakthroughs in key technologies such as attention mechanisms, deep neural networks (DNNs) trained with large amounts of data have achieved superhuman performance in some RTS games, such as defeating professional players in StarCraft 9 and surpassing professional players in the game Honour of Kings. 10
However, the aforementioned data-driven intelligent planning methods still cannot completely solve the problem of making decisions in a super large decision space within a short response time. The main reason is that such methods cannot be widely applied. In terms of real-time performance, high-performance networks often come with larger depths. Therefore, for complex game environments and decision tasks, more computing resources and time are needed to make accurate decisions under real-time requirements. In terms of the large decision space, a huge amount of data is required to train a super intelligent agent, and the hardware resources required for training are also high, which general research institutions cannot meet. Moreover, when the conditions of training and decision-making environments are insufficient, the speed of training and using the intelligent agent will be slow, and the performance of the intelligent agent will also decrease. Therefore, it is urgent to find a new decision-making framework to enhance the planning capabilities of DL methods in problems with large decision-making spaces and short response time.
Traditional knowledge-based decision-making methods have been widely applied in various fields, such as emergency planning in government departments, 12 security-durability evaluating of web applications,13–16 and portfolio optimization problems.17,18 These decisions are mainly solved using existing traditional decision-making methods to address specific domain challenges. For example, Kumar R's team used the analytic hierarchy process (AHP) to solve a series of security issues in web application development. However, in the field of task planning, traditional knowledge-based decision-making methods primarily involve converting expert knowledge into domain-specific knowledge usable by planning algorithms to generate concrete action sequences, known as courses of action (COA). Although the performance of these planning methods relies heavily on the richness of domain knowledge and falls short of superhuman performance, classical task planning methods have the advantages of fast planning speed and no need for pre-training. Therefore, by combining knowledge-driven planning methods with data-driven approaches, a novel planning method can be developed guided by knowledge and data, resulting in more efficient and accurate interactive agents.
Currently, researchers have successfully combined knowledge-driven planning with data-driven planning by incorporating human prior knowledge into DL models, achieving certain achievements. For example, researchers like Hu and Yarats, 19 Xu and Wang 20 use human natural language instructions to guide DNNs to fit towards a faster and more efficient direction. However, the drawback is that human instructions need to be manually provided, which incurs significant data collection costs. Similarly, Chen and Gupta 21 utilize demonstration data to guide deep reinforcement learning, enabling faster convergence of trained intelligent agents. Nonetheless, the disadvantage lies in the substantial human and resource costs associated with collecting demonstration data.
To address the challenge of making decisions in a large decision-making space within short response times and better incorporate human prior knowledge into DL, this manuscript presents a novel decision-making framework that integrates knowledge guidance and data-driven approaches, leveraging the Monte Carlo tree search (MCTS) as a connector between hierarchical task network (HTN) planning and DL. Experiments conducted in the MiniRTS environment show that it is possible to train an average-level interactive intelligent agent by solely using MCTS and HTN guidance for self-play with minimal human-generated data. This illustrates that utilizing MCTS as a connector between HTN and DL can effectively integrate knowledge into data, providing a new perspective for future research.
The remaining structure of this manuscript is as follows: Section 2 provides a brief introduction to related work and presents an overall framework diagram of the proposed method. Section 3 describes the decision-making framework that combines HTN and DL using MCTS as a connector in detail. Section 4 validates the reliability of the proposed method through experiments conducted in the MiniRTS environment. Section 5 summarizes the work presented in this manuscript and provides future research prospects.
Related work
Using demonstration data to guide DNNs training
After AlphaGo was proposed, DNNs has been widely used and has made some progress in developing interactive intelligent agents. Similar to AlphaGo, DNNs’ role in developing interactive intelligent agents is mainly reflected in two aspects: training value networks to evaluate the environment of intelligent agents, and training policy networks to directly guide the next action of the intelligent agents. Although the above two types of networks can achieve performance beyond human in AlphaGo with the assistance of MCTS, their application cannot be popularized and generalized in applications such as RTS games due to the characteristics of large decision-making space and short response time. For example, the training time and cost required for AlphaStar are enormous, 9 and Tencent needs to train a specific agent for each hero in the Honour of Kings. 10 Therefore, researchers have begun to use human demonstrated data as a basis for guiding DNNs training.
The work combining intelligent agent behavior with natural language instructions has been proposed as early as in the last century. 22 With the development of DL, this technology has gradually demonstrated its advantages. It started with the success of template-based compositional language in solving simple navigation problems for intelligent agents. 23 Then, it achieved success in utilizing human demonstration data to train intelligent agents in maze exploration,21,24 visual navigation, 25 and robot control. 26 Subsequently, researchers trained high-level intelligent agents in high-dimensional environments like MiniRTS using human demonstration data 19 a few years ago. Finally, ChatGPT 6 appears. All of these demonstrate that human knowledge based on demonstration data can enhance the capability of DL in training interactive intelligent agents. 20
HTN planning
HTN is a type of intelligent planning technology that seeks feasible solutions for tasks through task decomposition and conflict resolution. The basic idea is to extract specialized knowledge from the planning domain, which is used to recursively decompose complex abstract tasks into increasingly smaller subtasks until the decomposed subtasks can be directly completed through specific planning actions. Due to the similarity between the HTN planning process and human problem-solving thinking process, it has a wide range of applications in the planning domain, including emergency plan formulation in government departments, 27 intelligent robot task planning in industry, 28 web service composition, 29 and first-person shooter games and RTS games in the gaming field.30,31
In recent years, there have been advancements in utilizing the MCTS method to guide HTN planning. Wichlacz and Holler 32 proposed applying MCTS to HTN planning, and experiments demonstrated that using MCTS as the search algorithm for HTN leads to better or faster planning results compared to traditional search algorithms or heuristic search algorithms. Around the same time, Shao and Zhang 33 also proposed an MCTS-based HTN planning approach, using MCTS to select the best decomposition method for compound tasks. They addressed the issue of HTN planning relying on the order of decomposition methods and extended the approach to planning problems with uncertain action outcomes. Goldman 34 also employed the idea of using MCTS to select decomposition methods and applied it to the online HTN planning algorithm for partially observable Markov decision processes. The application of MCTS in HTN essentially leverages its look-ahead technique to provide trial-and-error possibilities for search-based HTN planning, thereby reducing the search branches of HTN. 35
Motivation
Although using demonstration data to guide DNNs training has achieved some success, its drawback lies in the fact that collecting human demonstration data requires a significant amount of manpower and resources. Additionally, due to the subjectivity of humans, the collected demonstration data may hinder the convergence of the network during the training process. If it is possible to use other intelligent means instead of humans to collect demonstration data with human knowledge, the cost of data collection can be greatly reduced, and the negative impact caused by human subjectivity on the dataset can be avoided.
On the other hand, although MCTS was used in AlphaGo to assist the value network and policy network in providing more accurate results, it did not have specific human knowledge to guide the network training. Therefore, this method is not suitable for high-dimensional spaces. Even though it may perform well in high-dimensional environments, it lacks universality and generalization. If knowledge-driven planning methods can be integrated into the MCTS-based DNNs, it may further enhance the performance of DNNs in high-dimensional applications such as RTS games.
To solve the aforementioned problems, this manuscript proposes a novel decision-making framework that integrates knowledge-guided and data-driven techniques, which leverages the MCTS as a connector between HTN and DL. By integrating MCTS with HTN, the planning performance of HTN can be improved. Additionally, combining MCTS with DL enhances the prediction accuracy of DNNs. Therefore, by using MCTS as a connector between HTN and DL, the strengths of both approaches can be utilized, allowing knowledge to more effectively guide the training of DNNs. Furthermore, challenging problems in intelligent decision-making can be addressed.
The diagram in Figure 1 illustrates the model trained using human natural language demonstration data to guide DNNs. The high-level instruction network is used to generate a natural language instruction, which is then inputted along with the state encoding to the low-level execution network. This network is responsible for generating specific actions and parameters that can be directly executed by the agent.

Schematic diagram of natural language embedding in deep learning.
The proposed method in this manuscript is built upon the model shown in Figure 1, and the proposed model diagram is illustrated in Figure 2.
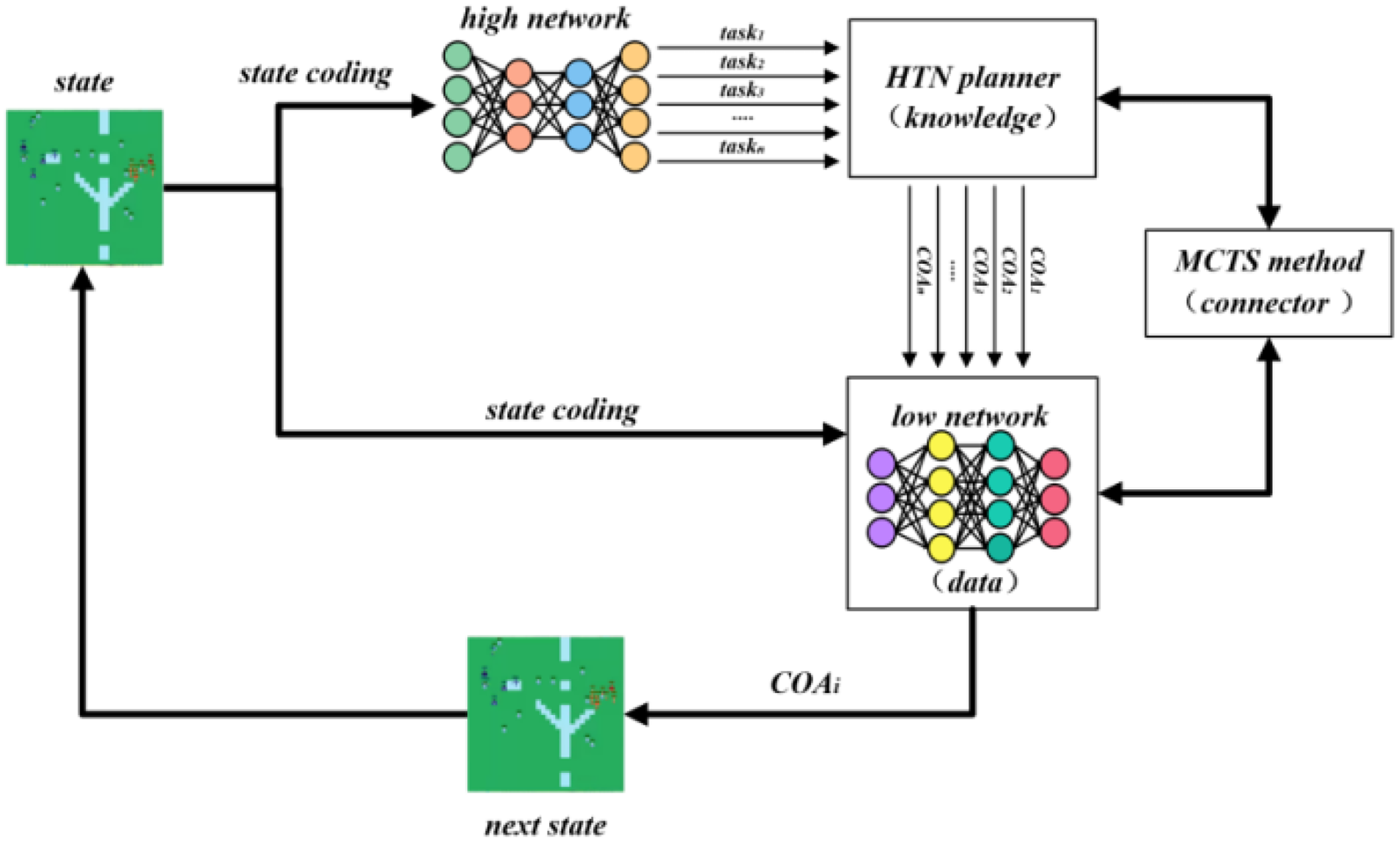
Schematic diagram of a model combining knowledge and data.
The innovation of the proposed method lies in two aspects: Firstly, in terms of training, unlike the use of human natural language demonstration data as shown in Figure 1, the model depicted in Figure 2 incorporates domain knowledge of HTN, and knowledge-containing data can be collected through self-play, which replaces the need for human demonstration data and reduces data collection costs. Secondly, in terms of usage, unlike directly using the network output as the execution action in Figure 1, the model depicted in Figure 2 leverages HTN and MCTS to handle multiple “tasks” generated by the high-level network. It provides corresponding COAs, then MCTS and the low-level network are utilized to simulate and evaluate these COAs, and finally the optimal sequence of execution actions is analyzed. The existence of action sequences gives the proposed method an advantage in terms of overall planning.
Method
This section will provide a detailed introduction to the technical details of the proposed knowledge-guided and data-driven decision-making framework in this manuscript. Firstly, it will introduce the knowledge-based planning method, HTN planning. Then, it will explain how to use MCTS-based HTN planning for high-level task decomposition. Finally, it will discuss how to evaluate low-level COA using MCTS-based neural networks.
Technical details of HTN planning
As a method of intelligent planning, HTN takes the given initial state, initial task network, and domain knowledge as input, and provides specific COA as output. The formal description of HTN typically includes three elements: state space, task network, and domain knowledge.
The state space refers to the mapping space in the computer where the real-world space of a planning problem is represented. In HTN, it is typically represented using predicate logic. A predicate expression p consists of terms

In HTN, the task network

Domain knowledge in HTN is the core of its encoding and planning, and it can be defined as a binary tuple D:

HTN operations are actions used to execute atomic tasks and have a certain impact on the state space. Define operation o as a quadruple:

HTN decomposition methods refer to the rules for decomposing a composite task into a network of subtasks. Define the decomposition method m as a triplet:

With these three elements mentioned above, HTN can define a specific planning task as
High-level task decomposition in HTN based on MCTS
The core of HTN planning lies in hierarchical decomposition. Therefore, if we need to use the HTN method to guide DNNs to obtain better actions, we also need to train the corresponding high-level neural network, whose output corresponds to the compound tasks in HTN.
MCTS is a simulation method based on probability and mathematical statistics, which has been widely applied in Atari games, RTS games, Go, and other practical applications. The MCTS method consists of four steps: selection, expansion, simulation, and backpropagation. Figure 3 illustrates one iteration process of MCTS.

Schematic diagram of iteration process of MCTS. 36
Selection refers to MCTS traversing the search tree starting from the root node and continuously choosing the next lower-level node based on the tree policy until a leaf node (or terminal node) is selected.
Expansion refers to MCTS probabilistically simulating the execution of an action at the leaf node, reaching a new state, and adding the newly represented state as a child node.
Simulation refers to MCTS simulating and executing the complete problem based on the default policy (rollout policy) at the expansion node, until a terminal state (or a specified depth) is reached, and obtaining specific rewards.
Backpropagation refers to MCTS propagating the obtained rewards from the simulation phase, starting from the expansion node to the root node, and updating the statistical information along the entire path.
Figure 4 represents a schematic diagram of high-level task decomposition in HTN based on MCTS.

Schematic diagram of high-level task decomposition in HTN based on MCTS.
From Figure 4, it can be seen that after the state encoding is inputted into the high-level neural network, it will probabilistically output compound tasks. By selecting multiple compound tasks with higher probabilities as inputs to the HTN planner, specific COAs can be obtained to complete these compound tasks. In Figure 4, the role of the HTN planner is similar to a value network, which evaluates the impact (or reward) on the current state when completing a certain compound task given the state s. The difference is that a value network is a data-driven model, which requires a large amount of data for training, while HTN planning is knowledge-driven, which utilizes pre-encoded domain knowledge.
Since a compound task in HTN can have multiple planning solutions, in Figure 4, HTN planning can also utilize MCTS to obtain the optimal COA. In this manuscript, the MCTS-HTN algorithm proposed in reference 33 is used to simulate the decomposition planning of compound tasks. By applying this algorithm, the optimal planning solution for compound task c under the current state s can be obtained, which is the optimal COA. This process is illustrated in Figure 5.

Schematic diagram of MCTS-HTN.
The time complexity formula for the MCTS-HTN algorithm is:

Evaluation of low-level network based on MCTS
High-level task decomposition based on HTN can decompose several compound tasks outputted by the high-level neural network into the optimal COA for each compound task. However, during actual execution, only one compound task and its corresponding COA can be selected (or even just the first action in the COA). Therefore, it is necessary to evaluate each compound task and its corresponding COA, which can be accomplished using MCTS and the low-level neural network.
For RTS games, low-level actions typically involve parameters. For example, in StarCraft, each unit needs to select an enemy unit as a parameter when choosing an attack action, or select a specific coordinate as the destination for gathering resources. If these parameters are included as part of the COA in HTN, it would result in a vast amount of domain knowledge, thus having difficulty in coding. Therefore, the COA generated by the HTN planner only contains specific low-level actions, while the specific parameters can be provided by the low-level neural network.
Figure 6 represents one iteration of the MCTS process in the evaluation of the low-level network based on MCTS. For each compound task and its corresponding

Schematic diagram of one evaluation of low-level network based on MCTS (
Figure 6 represents one iteration of MCTS, which is a branch from the root node to a leaf node in the MCTS search tree. It is well known that for classification problems, the results provided by DNNs are typically probabilistic. The advantage of MCTS is that it can select several parameters with higher probabilities as branches for expansion, as shown in Figure 7.

Schematic diagram of search tree construction.
The search tree shown in Figure 7 is constructed by branching with the top three parameters in terms of probability output by the low-level network. Each node represents a state, and the edges represent parameters. The search tree becomes richer as the number of MCTS simulations increases, until the number of simulations approaches infinity, at which point the Q values of the tree nodes tend to converge. When computational resources are exhausted or a specified number of simulations is reached, the MCTS simulations terminate. Then, the path from the root node to a leaf node with the highest Q value is selected as the COA with parameters, which corresponds to the optimal actions for the compound task.
After conducting MCTS simulations for all compound tasks, the best COAs with parameters (each COA having its corresponding Q value obtained from the search tree) are compared. The overall best COA with parameters among all compound tasks is selected as the final action to be executed in the real environment.
The time complexity formula for evaluating action sequences based on MCTS is:

This section elaborates on the specific details of the framework shown in Figure 2. First, HTN planning and MCTS are used to evaluate each task output from the high-level neural network instead of a value network and generate the optimal COA. Then, MCTS and the low-level neural network evaluate the COA of each task to obtain the final optimal COA for execution in the real environment. As shown in Figure 8, unlike previous methods, this framework can output a COA rather than just a single action when receiving a state as input. This is one of the advantages of the HTN approach. The COA enables the agent to have some foresight. Moreover, when there is human intervention, it can provide better assistance and stronger interpretability in decision-making compared to single actions.
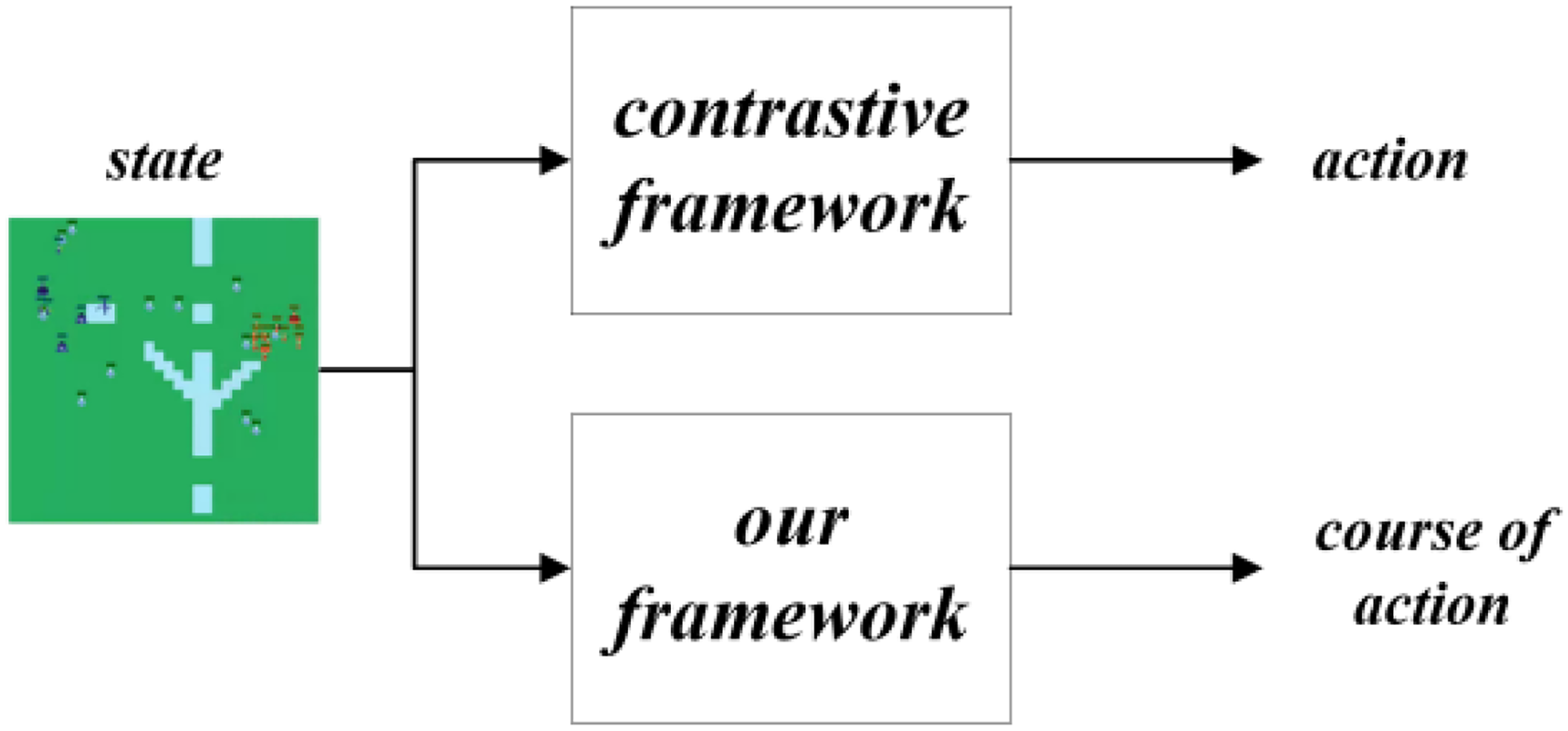
Contrastive diagram of output from different frameworks.
Evaluation of experimental results
To demonstrate the effectiveness of the framework proposed in Section 3 in enhancing the decision-making capability of DNNs, we conducted experiments in the MiniRTS environment and compared it with a planning framework based on human natural language instructions.
Experimental environment
MiniRTS is a grid-based strategic adversarial environment, as shown in Figure 9. It captures the important key features of complex RTS games and to some extent represents the problem of decision-making within a large decision-making space with short response times.

Schematic diagram of MiniRTS environment.
In MiniRTS, there are two agents: Blue and Red. Both agents can be controlled by humans, AI strategies, or built-in bots. The opposing agents gather resources, construct buildings, train various types of units, and engage in combat. The ultimate goal is to destroy the enemy's base and win the game.
There are seven types of units in MiniRTS that can attack enemy units, including six types of offensive units and defensive tower structures. The attack rules resemble a simplified version of the game “Jungle” (or “Dou Shou Qi”), as shown in Figure 10. For example, swordsmen can defeat spearmen, spearmen can defeat cavalry, and cavalry can defeat swordsmen. Apart from the defensive tower structures, there are also five types of building structures used to train different offensive units in MiniRTS. The training rules for these units are illustrated in Table 1. Among them, the workshop is the only building capable of producing three types of offensive units. Additionally, MiniRTS includes a unit called the peasant, which is used to build buildings. All building structures can only be constructed by peasants, and peasants can only be produced by town hall (base).
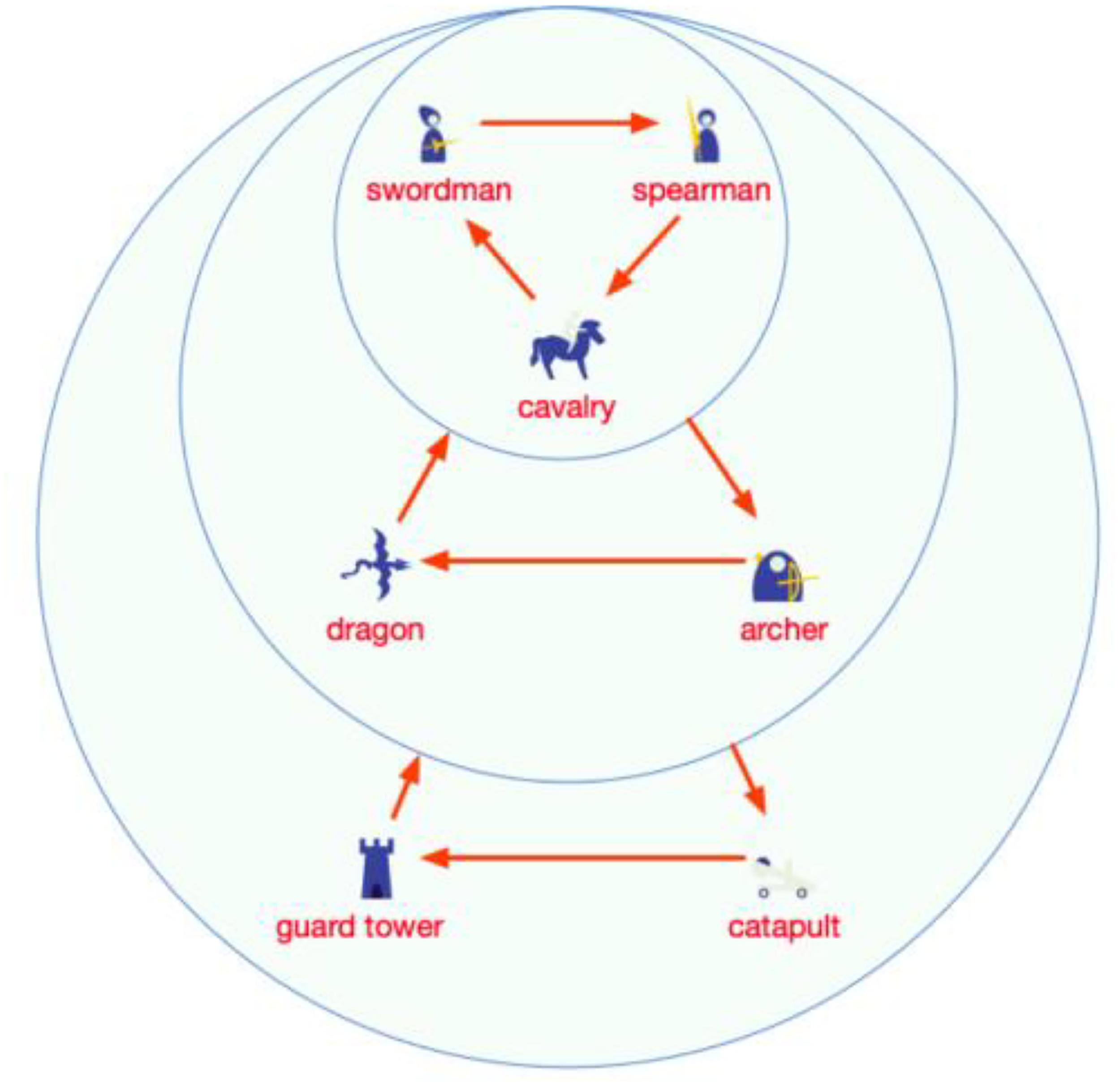
Schematic diagram of attacking rules. 20
Table of training rules.

The experiments in this manuscript are built upon the work of Hu and Yarats, as shown in Figure 1. They collected training data from nearly 5400 games and trained two DNNs: an instruction network and an execution network. The specific network structures can be found in reference. 19 We selected the RNN (recurrent neural network) structure and trained a network with a relatively small amount of training data generated based on HTN, which achieved comparable performance to the contrast network. Our experiments were running on a Tesla V100 server.
The top 5 probability outputs from the higher-level network are considered. When writing HTN domain knowledge, each composite task is given 3 decomposition methods, and the average number of subtasks after decomposition is 3. Therefore,
Figure 11 shows an example of HTN domain knowledge writing. When the composite task “destroy the enemy's cavalry” needs to be completed, subtask decomposition can be performed through methods, ultimately leading to different action sequences.
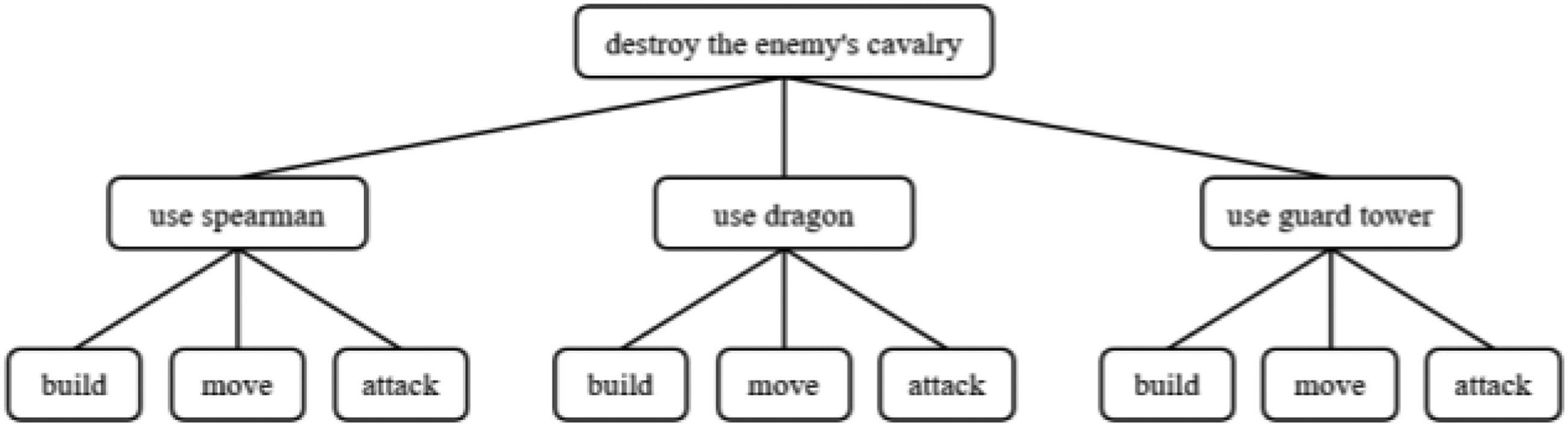
HTN domain knowledge example.
This manuscript demonstrates the effectiveness of the proposed framework through four experiments. Experiment 1 uses MCTS to select the optimal network output, demonstrating that integrating the MCTS method into the network can improve its performance to some extent. Based on the results of Experiment 1, Experiment 2 verifies that a neural network integrated with MCTS can self-adversarially generate high-quality training data. Building on the first two experiments, Experiment 3 embeds HTN planning into the network following the procedure shown in Figure 2. This experiment successfully demonstrates that the proposed framework can effectively integrate knowledge and data, thereby enhancing the agent's performance. Experiment 4 is conducted to verify whether the proposed framework can operate effectively in complex environments with incomplete information.
To validate the effectiveness of the framework proposed in this manuscript, subsequent experiments are conducted in four aspects: MCTS-assisted neural network decision-making, collection high-quality replay data based on MCTS, effectiveness of the collaborative-driven planning method, and the effectiveness of the framework under incomplete information.
MCTS-assisted neural network decision making
Reference
19
collected data from nearly 5400 matches by letting humans play against the rule-based built-in AI in MiniRTS. Each competition required two individuals, where the high-level decision makers provided a natural language instruction to the lower-level executors, instructing them to perform specific actions, and the lower-level executors controlled specific units to carry out the actions based on understanding the instructions. Each match yielded multiple training data pairs in the format of
The experiments conducted by reference 19 demonstrated that a hierarchical neural network guided by human natural language instructions outperformed a non-hierarchical neural network mapping states directly to actions. However, the drawback of their approach is the difficulty in collecting human natural language instructions, as well as the inconsistency in the collected data quality, which hindered the network training process.
To demonstrate the effectiveness of the knowledge-guided and data-driven decision-making framework proposed in this manuscript, a series of comparative experiments were conducted based on the aforementioned experimental framework. The main comparison object was the layered model encoded in RNN mode, using a 500-instructions library. This network was referred to as
One of the objectives of the experiments in this manuscript was to demonstrate that the addition of HTN planning could improve the quality of training data. On one hand, the training efficiency could be improved, and on the other hand, humans can be replaced in data collection. To achieve this, an initial network,
To demonstrate that the addition of the MCTS method can also improve the network performance to some extent. This experiment used the MCTS method to select the DNNs’ output results. The pseudocode for this is shown below.

The state represents the state coding,

The MCTS_simulate function performs multiple simulations, each starting from the root node and continuously selecting child nodes until there are unexpanded child nodes (lines 2 to 6). Then, the selected child node is expanded (line 7), which includes the rollout process and the evaluation process. Finally, the evaluation result of the child node is backpropagated to update the entire tree (line 8), and the next simulation begins. The model that uses the MCTS method to filter the results of the
The

The confrontation results of different networks against
From Figure 12, it can be seen that the
Collecting high-quality replay data based on MCTS
From the results of the previous experiment, it can be observed that the MCTS method can assist the DNNs in achieving better outputs. However, the drawback is that incorporating the MCTS method makes the adversarial process slower because simulations require a significant amount of time. This does not meet the real-time requirements of RTS games, making it difficult to expand and generalize in practical applications.
Although the MCTS method sometimes cannot meet the high-level real-time requirements, it can be applied to offline adversarial scenarios to generate high-quality training data. Based on the results of the previous experiment, the
The purpose of this experiment is to demonstrate that the DNNs enhanced with the MCTS method can indeed obtain higher-quality training data. In this experiment, the

Schematic diagram of iterative training.
In this experiment, when the number of adversarial matches reached 200, a new DNN was trained, and the new DNN was used for offline adversarial scenarios, thus iteratively improving network performance. The iteratively trained new networks are named
The
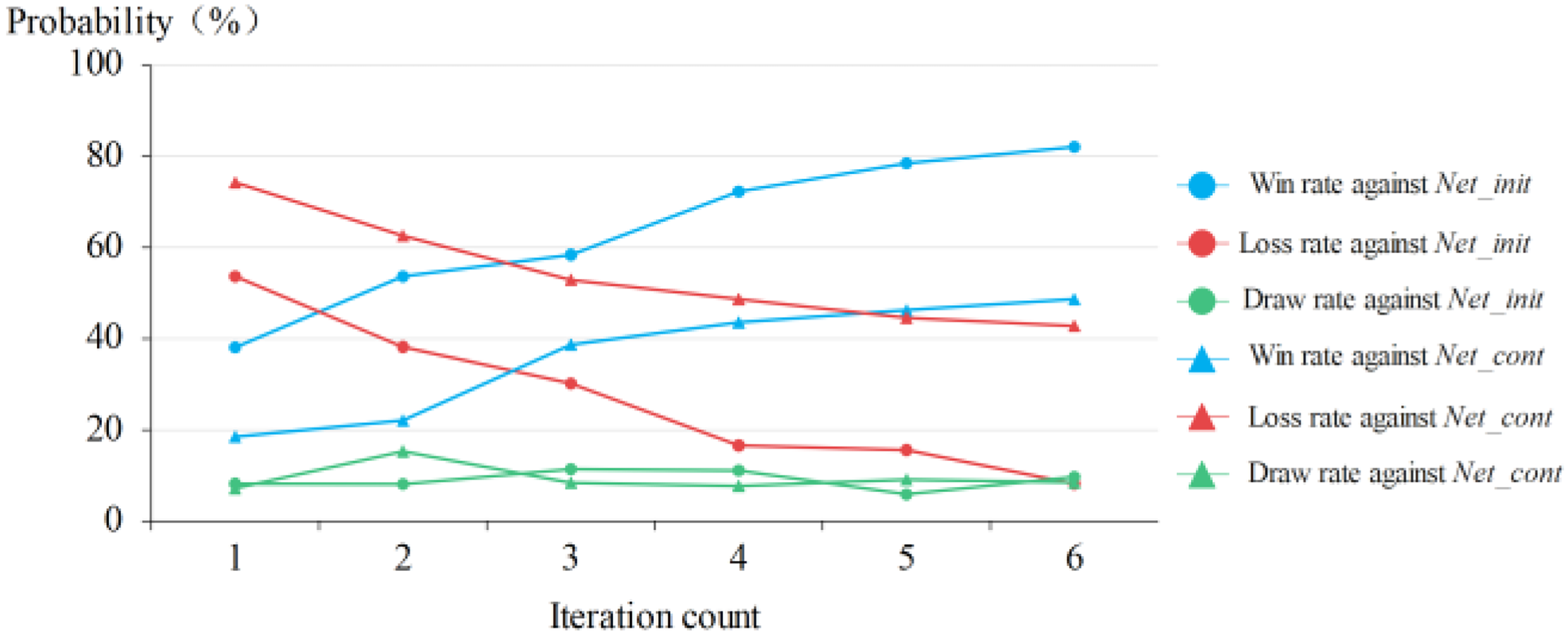
Results of
From Figure 14, it can be seen that initially, the win rate of the
To make a comparison from a horizontal perspective, human demonstration data with the same data volume as
Adversarial results table for

From Table 2, it can be seen that the win rate of
Effectiveness of collaborative-driven planning method
To demonstrate the scientific validity and effectiveness of the framework proposed in this manuscript. This experiment follows the flow outlined in Figure 2. It treats the natural language instructions generated by the high-level neural network as compound tasks in HTN planning. By writing decomposition methods for different instructions, HTN planning is embedded into the original framework as described in reference. 19 The pseudocode for this integration is given below.

The
After incorporating HTN planning, offline self-play is still conducted according to the flow shown in Figure 13 to generate high-quality training data and train the DNNs. The iteratively trained new networks are named
Similar to the previous experiment, the
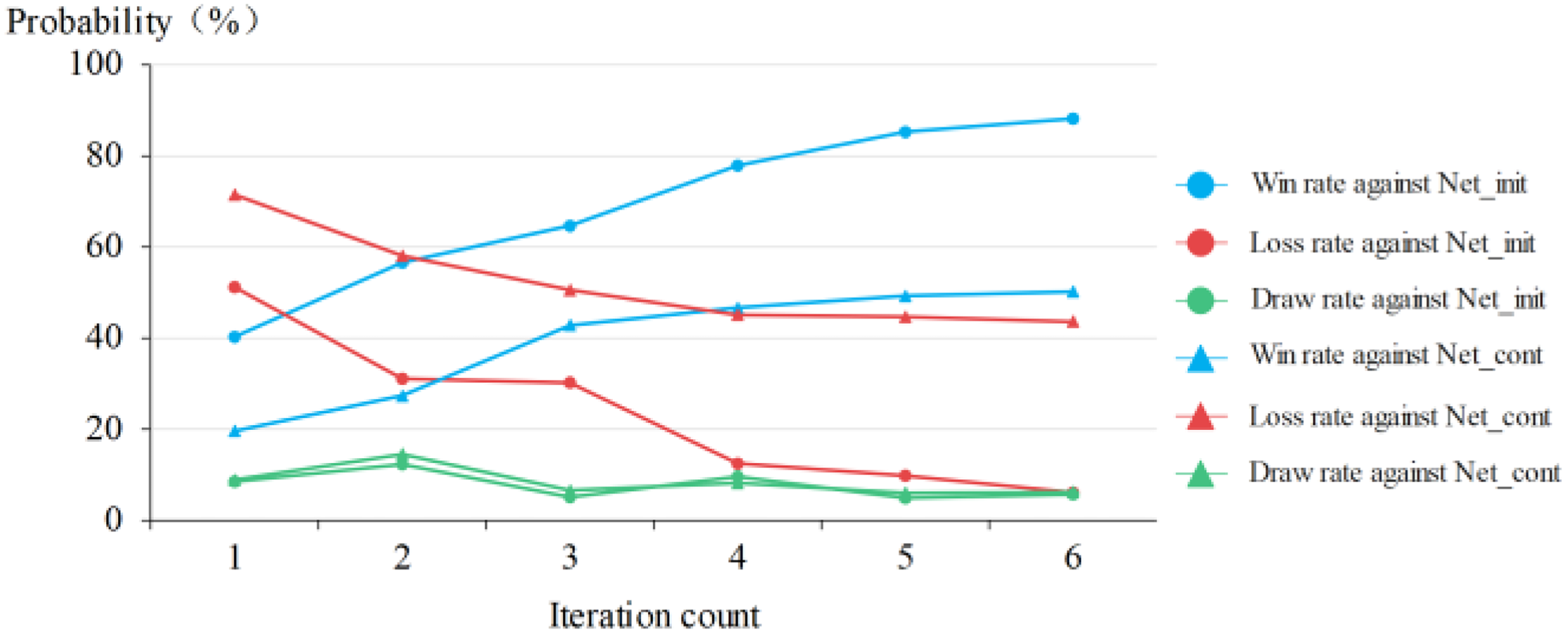
Results of
Adversarial results table for

The trends of the curves in Figure 15 are very similar to those in Figure 14, but the performance improvement of the
Figure 16 shows a comparison of the training data volume required for the

Comparison of the data volume required to reach
From Figure 16, it can be seen that the
Effectiveness of the framework under incomplete information
Another feature of the MiniRTS platform is the ability to change the adversarial environment to be partially observable, meaning that the states received by both adversaries are not complete, as shown in Figure 17. The black parts represent unexplored unknown environments, while the gray parts represent areas that have been explored but are currently not visible. As the intelligent unit explores, the environment will gradually become visible.

Schematic diagram of partially observable environments.
In this experiment, the
Adversarial results table for partially observable environment.

From the results in Table 4, it can be seen that compared to the previous three experiments, the win rate of the
Although the framework proposed in this manuscript has only been experimentally validated in the MiniRTS environment, it can essentially be extended to most game environments or real-world problems. For different environments and problems, the only part of the framework that needs to be modified is the writing and encoding of HTN domain knowledge. If a problem can be solved by training a neural network and has HTN domain knowledge, the framework proposed in this manuscript can quickly combine knowledge-based and data-driven algorithms, thereby enhancing the problem-solving capability. If the environment complexity is very high, the framework can also reduce the convergence difficulty of the neural network by adding domain knowledge, i.e. by balancing knowledge and data, which will be an important area of future research.
Conclusion
Studies have shown that decision-making is one of the top five directions for current researchers. 37 In this manuscript, we propose a new decision-making framework that combines knowledge-driven and data-driven approaches using the MCTS method as a connector between HTN and DL. It provides a new approach to solve the problem of decision-making in a large decision space with short response time. We conducted experiments on the MiniRTS environment and found that, compared with networks trained using high-quality retrospective data collected by humans, networks trained based on our proposed framework achieved equivalent performance with only 20% of the training data. This indicates that as a carrier of expert knowledge, HTN can be well combined with DL with the help of MCTS to achieve the goal of knowledge-driven and data-driven approaches. Our proposed framework provides researchers with a knowledge and data-driven planning approach and offers new research perspectives for efficient decision-making.
There are two limitations to our proposed method in this manuscript. Firstly, the initial network training still relies on a small amount of high-quality data collected by humans, which is beyond the scope of the framework proposed in this manuscript. Further investigation is needed to train the initial network without relying on human-collected data entirely. Secondly, the compilation of HTN domain knowledge still requires the involvement of domain experts. However, these experts may not be proficient in writing HTN code. If domain knowledge cannot be encoded effectively, the quality of self-play data will be compromised. Therefore, a key research direction for the future is to explore how to better represent expert knowledge in HTN form.
Apart from the improvements to the two limitations mentioned above, future research can focus on the following two aspects. Firstly, improving the model's generalization and interpretability by exploring whether a single neural network can adapt to multiple planning scenarios with the addition of HTN knowledge, and interpreting the output of the neural network from a hierarchical perspective. Secondly, improving sample efficiency by developing strategies to select high-quality self-play samples, as the quality of these samples can vary. This can speed up network training and improve its efficiency.
Footnotes
Author contribution statement
Tianhao Shao: Conceptualization, Methodology, Writing - original draft. Ke Zhang: Conceptualization, Methodology, Writing - review & editing. Kai Cheng: Data curation, Software, Funding support. Hongjun Zhang: Validation, Supervision.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (No. 61806221) and the Young Scientists Fund of Army Engineering University of PLA.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.