
Abstract
Glaucoma diagnosis at an early stage is vital for the timely initiation of its treatment for and preventing possible vision loss. For glaucoma diagnosis, an accurate estimation of the cup-to-disk ratio (CDR) is required. The current automatic CDR computation techniques attribute lower accuracy and higher complexity, which are important considerations for diagnostics system design to be used for such critical diagnoses. The current methods involve a deeper deep learning model, comprising a large number of parameters, which results in higher system complexity and training/testing time. To address these challenges, this paper proposes a Residual Connection (non-identity)-based Deep Neural Network (RC-DNN), which is based on non-identity residual connectivity for joint optic disk (OD) and optic cup (OC) detection. The proposed model is emboldened by efficient residual connectivity, which is beneficial in several ways. First, the model is efficient and can perform simultaneous segmentation of the OC and OD. Second, the efficient residual information flow permeates the vanishing gradient problem which results in faster converges of the model. Third, feature inspiration empowers the network to perform the segmentation with only a few network layers. We performed a comprehensive performance evaluation of the developed model based on its training in RIM-ONE and DRISHTIGS databases. For OC segmentation, for the images (test set) from {DRISHTI-GS and RIM-ONE} datasets, our proposed model achieves the dice coefficient, Jaccard coefficient, sensitivity, specificity, and balanced accuracy of {92.62, 86.52}, {86.87, 77.54}, {94.21, 95.36}, {99.83, 99.639}, and {94.2, 98.9}, respectively. These experimental results indicate that the developed model provides significant performance enhancement for joint OC and OD segmentation. Additionally, the reduced computational complexity based on reduced model parameters and higher segmentation accuracy provides the additional features of efficacy, robustness, and reliability of the developed model. These attributes of the developed model advocate for its deployment of population-scale glaucoma screening programs.
Keywords
Introduction
Glaucoma is a retinal disorder that belongs to the class of diseases which affect the optic nerve. Any damages caused to or any pressure imposed on the optic nerve leads to the loss of vision. When the eye fails to drain the excess/waste fluid, the accumulated fluid causes intra-ocular pressure, which harms the optic nerve. Such conditions thicken the layers of retinal nerve fibers leading to an enlarged optic cup (OC) size relative to the optic disk (OD) size, which is usually referred to as “cupping.” Besides, the thinning in the layers of retinal pigment epithelium surrounding the OD called peripapillary atrophy leads to myopia condition (i.e. nearsightedness). 1 Individuals with myopia condition are at high risk of developing glaucoma. Glaucoma is ranked as the second-largest cause (i.e. after cataracts) among the leading causes of blindness worldwide. 2 Accurate and early glaucoma diagnosis can prevent the patient from blindness. To this end, machine learning-based automated diagnosis of glaucoma and other critical eye diseases has become an essential constituent. 3
Significance and challenges of automated optic disk/optic cup segmentation
Multiple diverse types of clinical methods are practically employed to diagnose different types of eye diseases (e.g. glaucoma) and to access their modalities. In conventional glaucoma screening approaches, the experts (i.e. optometrists and ophthalmologists) manually evaluate the measured retinal fundus images and mark the images with handwritten labels. This manual grading approach is tiresome, and it vastly depends on the availability of experts and their level of expertise. Another primary disadvantage of such grading is the limited amount of manually extractable information from the retinal images. Moreover, the manually graded retinal fundus images include significant variations in the judgments because of various humanistic factors such as exhaustion of the experts, etc.
Furthermore, the accuracy of manual grading also vastly varies based on the inter-observer variation. These limitations in manual glaucoma detection procedures imply the need to develop automated glaucoma screening and diagnosis methods. To this end, computer-aided tools can play a primary role in assisting clinicians in the diagnosis of glaucoma and other eye diseases.
Machine/deep learning-based approaches are regarded as capable of delivering consistent accuracy and efficiency in the performance of automated disease diagnosis systems. Additionally, such machine learning-based automated screening methods have a strong potential to be considered for large-scale screening programs (e.g. for the entire population) that are considered of high importance (worldwide) for timely diagnosis of different diseases (e.g. eye diseases) and for supporting widespread corroborative screening initiatives. 4 Different underlying models/algorithms of machine/deep learning-based detection methods have various associated advantages and limitations for the detection of OD, OC, and other vascular structures in the retinal images. The segmentation of retinal images for accurate OD and OC detection is a challenging problem because of numerous reasons related to the constituent parts of these images and the shape and diameter of OD/OC. The cup-to-disk ratio (CDR) is one of the primary parameters clinically studied to gauge the enlargement of OC for the screening of glaucoma. Automated segmentation of OD and other focal regions of OC in the fundus images is of vital importance in determining different primary clinical parameters. Most of the existing approaches developed for glaucoma detection perform separate OD and OC segmentation and usually rely on handcrafted visual features of the retinal images. The issues that complicate the OD/OC detection process include centerline reflex, vessels’ presence, and crossing points of vessels. Furthermore, there exist several other problems associated with the retinal image acquisition process, which make the OD/OC detection a challenging task, for example, camera calibration, image brightness, and noise in the retinal images. These problems lead to various other challenges in achieving high performance and efficiency of machine/deep learning-based automated eye disease diagnosis systems.
Contributions to the work
In this work, we present a novel Residual Connection enabled Deep Neural Network (RC-DNN) based on non-identity residual connectivity for OD and OC segmentation in retinal images. The RC-DNN is an efficient architecture, which eliminates the need for localization of OD/OC and the steps for pre/post-processing. It helped us in reducing the computational complexity of the proposed model. The RC-DNN architecture is intelligently modeled/designed by promoting the feature propagation and the reuse policy of the information bypassed through skip-connections in ResNet.
5
The boundary preservation through skip-connections is guaranteed, which eventually led to robust and enhanced segmentation. Both down-sampling block (DSB) and up-sampling block (USB) are connected based on non-identity residual mapping, which allows the network to map the information from higher depth to lower depth. Unlike Badrinarayanan et al.'s work,
6
RC-DNN is only based on three USBs followed by three DSBs. Each block only consists of two convolutional layers, with a total of 12 convolutional layers for the overall network. The low number of layers with residual connectivity helps to reduce the number of parameters as well as preserving semantic information. The proposed network is compact and efficient compared to famous semantic segmentation architectures like SegNet, U-Net, and DeepLab. The contributions of our approach are as given below:
Reduced computational complexity: we aimed for a low-complexity deep learning model to reduce both computation and complexity for training and testing by avoiding pre-processing. Higher accuracy: adopting the information reuse policy in the network for spatial loss compensation enabled the proposed model to achieve significantly higher accuracy with a simple architecture compared to rivals from the literature. The non-identity mapping benefits: the proposed method exploits the benefits of non-identity residual mapping that allows the beneficial edge information flow in the network with the connectivity of a few layers. The improved segmentation performance: we have achieved significantly improved segmentation performance for both OD and OC detection compared to the literature.
Literature review on machine and deep learning for glaucoma disease diagnosis
Glaucoma is an eye disease that gradually damages the optic nerve resulting in complete or partial vision impairment if it evolves to advanced stages. Researchers and ophthalmologists observed that inappropriate intravascular pressure is a deciding factor that can be altered (corrected) to avoid vision impairment. The disease does not develop any symptoms in the initial stages, necessitating early and accurate diagnosis through continuous/effective screening programs.
The OD/OC and the changes in their morphological features enable the ophthalmologist to detect glaucoma. The manual assessment of the patients is prone to errors due to the inter-observer discrepancy and is time-consuming, which limits the large-scale screening of a large population. Consequently, designing/developing an efficient machine/deep learning-assisted computer-aided detection (CAD) tool is necessary for the accurate and reliable diagnosis of glaucoma. Deep learning-based CAD tool is highly effective and can be employed to assist ophthalmologists in relieving their workload significantly. The CAD tool-based detection of glaucoma is non-invasive and effective in the initial stage and could be employed for large-scale screening programs.
The design and implementation of such a CAD tool necessitate a miscellaneous large database of digital fundus images for achieving optimal performance. Fundus photography is cost-effective for achieving a large number of digital fundus images, which is broadly used by optometrists/ophthalmologists for early detection of the disease. Below, we unfold the details and features of the recently developed deep learning-based computerized tool for glaucoma detection.
Glaucomatous optic neuropathy, a leading cause (the second one) of vision impairment, is the most commonly acquired optic neuropathy faced by ophthalmologists in their clinical practice. However, the autoimmune pathogenesis of this vision impairment disease is still unknown. In the elegant review conducted by Hagiwara et al. and Rizzo et al.,1,7 the authors dwelled on aspects, which are generally not covered by other studies. The aspects covered by the authors in 7 include the changes in profiles of serum antibodies, downregulation, and upregulation. They mentioned that diabetes, hypertension, and hearing syndromes are also linked. Hagiwara et al. 1 provided a detailed discussion about the building blocks of the CAD tool, which include pre/post-processing, image segmentation, extraction of features and their ranking, and disease classification.
Raghavendra et al. 8 developed a deep learning-based CAD tool for the accurate diagnosis of glaucoma. Their developed deep learning model contains 18 convolutional neural network (CNN) layers for the extraction of vigorous features from input images. During the testing phase, the extracted features are used for classifying input images into glaucomatous or normal. They evaluated their developed model using a database of 1426 digital fundus images containing 837 glaucomatous and 589 normal. Through extensive experimental evaluation and testing, they obtained an accuracy of 98.13%, which is sufficiently high and implies that it can be used to aid clinicians in validating their observations/decisions.
Edupuganti et al. 9 developed a deep learning-based method for OD/OC segmentation in retinal images for determining CDR, which is needed by the clinician for diagnosing glaucoma. They adopted several strategies using FCN-based deep learning models for performing automatic segmentation of OC and OD regions. They demonstrated through experiments on the Drishti-GS database that their developed model achieved a competitive F-score compared to the previous explorations on the OC and OD segmentation.
Qin et al. 10 modified inception building blocks from GoogleNet and Fully Convolutional Network in their developed deep learning-based approach for joint OC and OD segmentation. The FCN is highly efficient for segmentation tasks, due to which it has been selected in numerous studies. To enhance the performance of their proposed strategy, they have also introduced localization of OD and pre-processing algorithms. Their obtained simulations show improved results compared to other approaches.
Wang et al. 11 presented a new approach called pOSAL for robust and joint OD/OC detection. They adopted an efficient and lightweight segmentation approach at the backend. Based on the morphological features of the OC and OD, they proposed morphology with segmentation loss for smooth and accurate segmentation of the fundus images. Furthermore, they adopted a patch-based method in the design of pOSAL, to enable it for fine-grained refinement in local segmentation. They demonstrated the effectiveness of their developed framework by evaluating its segmentation performance using three publicly available retinal image databases, namely, RIM-ONE, Drishti-GS, and REFUGE. Most importantly, pOSAL got first place in MICCAI 2018 competition, which aims to develop and compete with the best models for OD and OC segmentation.
Badrinarayanan et al. 6 proposed SegNet, which is a segmentation model based on encoder–decoder architecture. In SegNet architecture, the output of the encoder–decoder is fed into a block of classification (pixel-wise). The architecture of SegNet is comparable to the architecture of VGG16 in regards to the number of convolution layers at the encoder side. The SegNet model has been used in many different ways by many researchers for the segmentation of retinal fundus images.
An ensemble approach using a CNN model was adapted in 12 for the segmentation of retinal images. To reduce the training and testing time of the model, they employed an entropy sampling method for selecting informative points. These sampled points are used to design a boosting-based learning approach for CNN filters, which is done in many layers with a strategy of feeding the results of one layer to the next adjacent layer. A classifier named Softmax was trained on the filters’ results, whose output is subject to a graph cut method (unsupervised) along with a convex hull transformation for achieving the overall segmentation of the retinal image. Their developed approach achieved superior performance compared to other rivals in the literature for OD and OC segmentation.
Yu et al. 13 proposed a robust segmentation framework for OC and OD segmentation by introducing some modifications to the standard U-Net model. They adopted an approach by employing the standard ResNet-34 model (pre-trained) for encoding and the standard U-Net for decoding. They achieved superior performance using a developed approach compared to the existing best methods in the literature for OD and OC segmentation. The most valuable thing about their developed approach is the usage of pre-trained U-Net and ResNet for decoding and encoding, respectively. This combination avoids the training of the combined model from scratch, which reduces network training time.
In 14 , a CNN-based approach called DenseNet was proposed, which, in turn, employed a U-shaped (symmetric) architecture for classification (pixel-wise). They used the detected OC and OD boundaries for estimating CDR, to accurately diagnose glaucoma. They evaluated their developed model using retinal fundus image datasets and achieved better performance compared to other methods in the literature. Additionally, they generalized their model and assessed its performance for segmenting images from four retinal image databases without retraining. In this case study, they achieved better performance compared to the reported works in the literature on two datasets and comparable performance on the other two.
Jiang et al. 15 proposed a multi-label Deep CNN named GL-Net using generative adversarial networks (GANs). Their proposed model is composed of two structures, which are Discriminator and Generator. In the Generator part, they applied skip-connections to reduce the difficulty of regaining (preserving) detailed information about each feature in the upsampling stage. The skip-connections in the Generator part also help in reducing the loss of feature information. They have also applied data augmentation and transfer learning to reduce the constraints of over-fitting and insufficient data.
A method has been put forward by Fu et al. 16 , which is a deep learning-based architecture for gaining more information from the fundus images for glaucoma screening. They designed and developed a Disk-aware Ensemble Network called DENet, which incorporates both the local information of the OD and the global hierarchical information of the fundus images. They considered four streams (deep) in different modules and at various levels: segmentation-guided network, global image stream, disc polar transformation stream, and local disk region stream. In the end, they fused the output probabilities of these four streams to achieve the final screening output. They evaluated their proposed model based on two datasets, that is, SINDI and SCES and achieved better performance than the rivals from the state-of-the-art.
The researchers in 17 developed M-Net, which is a deep learning-based approach for joint OD and OC segmentation using a process termed as one-stage multi-label system. Their developed model is composed of various layers, including multi-scale input, side-output layer, U-shape convolutional layer, and finally, the multi-label loss function. The input layer (multi-scale) makes an image pyramid for obtaining receptive fields of various sizes at multiple levels. The U-shape convolutional layer is used for learning the rich hierarchical information in the images. The purpose of side-output is to use it as a classifier for producing a local prediction map. Lastly, the multi-label loss function is used for generating the output segmentation map. They used polar transformation to achieve a polar representation of the original image. They assessed their proposed model on the ORIGA dataset and achieved better performance compared to the literature.
Kar et al. 18 proposed a method for segmenting retinal vessels by using a multi-scale residual CNN in combination with GANs. By eliminating features from different sizes, their proposed model enhances its capability for feature extraction. More precise and more accurate vessel segmentation maps are produced using the GANs. They assessed the performance of their model using publicly accessible datasets and achieved improved results.
Elangovan and Nath 19 proposed a framework employing an ensemble of deep CNNs called En-ConvNet for diagnosing glaucoma from color fundus images. The proposed model combines many deep CNNs with a weighted voting system to increase classification accuracy. On a benchmark dataset, the suggested strategy outperformed numerous cutting-edge glaucoma detection techniques and showed promise for clinical use.
Elangovan and Nath 20 developed a framework with a combination of a CNN, a feature extraction module, and a decision-making module for color fundus image segmentation. The suggested technique separates the images into glaucomatous and non-glaucomatous categories. When tested on a publicly available dataset, the proposed method showed great accuracy in identifying glaucoma.
Nath and Dandapat 21 developed a glaucoma assessment method using differential entropy in the wavelet sub-band analysis of color fundus images. The proposed method extracts features from the wavelet sub-bands and uses differential entropy to quantify changes in the texture and morphology of the optic disk. The proposed method was evaluated on a dataset containing 144 images, for which it demonstrated enhanced results for glaucoma diagnosis.
Elangovan et al. 22 proposed a glaucoma detection method using statistical parameters extracted from color fundus images. The proposed method extracts features such as mean, standard deviation, and skewness from the images and uses a support vector machine classifier for glaucoma detection. The developed technique was also assessed on a publicly available dataset containing 144 images, for which it achieved improved glaucoma diagnosis in comparison with similar previous models.
The recent works from the literature are summarized in Table 1 provided below for glaucoma detection based on publicly available retinal image databases.
The pros and cons of some representative models from the literature.

Despite the tremendous enhancement in the efficiency and accuracy of supervised machine/deep learning models, numerous issues still require the research community's proper attention. These issues and problems put a limitation on the wide usage of machine/deep learning approaches for automatic large-scale screening programs. One such issue is the pre and post-processing functions required by the supervised machine/deep learning model, which increase not only the development time but also the model training and testing time. Usually, these pre- and post-processing functions are based on heuristic algorithms, which require modifications for different noises, pathology, and other factors affecting the retinal fundus images. Furthermore, the previously explored best models overlooked the tunable hyper-parameters, the memory requirement, and the training/testing duration of the developed models. The considerably higher training/testing time (based on higher computational complexity) of the deep learning model and its hyper-parameter tuning hinder its application for large-scale automatic screening programs. All these issues and factors require considerable attention from the researchers for their future investigations.
The careful analysis and study of the previous investigations reveal that their sensitivity has been considerably affected because of the inaccurate detection of the OD and OC. Furthermore, most of the previous works targeted separate OD and OC detection. In this study, we aim to develop a deep learning model (RC-DNN) for joint segmentation of OC and OD. Furthermore, the focus has been on eliminating the need for pre- and post-processing and on reducing the computational complexity of the developed model.
Method and materials
The proposed model and the databases used for its assessment are unfolded in this section of the manuscript. The developed deep learning model is assessed quantitatively using standard evaluation metrics and qualitatively by visualizing the output images.
Retinal fundus image databases
We have used two publicly available retinal image databases for the performance evaluation of our developed model for the tasks of semantic segmentation (pixel-wise) of both OD and OC, which are DRISHTI-GS 23 and RIM-ONE. 24
Drishti-GS
This database contains 101 retinal images, which were captured with a centered-optical disk and dilated pupils at a field of view of 30 degrees. All of these captured images were annotated by an expert at Aravind Eye Clinic (Madurai, India). All the images have a common resolution of 2896*1944, which was stored in PNG format but with no compression. The average OD and OC borders are shown in all images of the DRISHTI-GS1, which are based on four manual labels performed by professionals.
RIM-ONE
This retinal dataset contains 159 images and is publicly available to researchers for evaluating OD/OC segmentation models. Among 159 retinal images, 74 images belong to glaucoma-infected eyes, and the remaining 85 images belong to healthy individuals. These images were collected at three Spanish hospitals, which were graded by two experts.
Proposed model for optic disk/optic cup segmentation
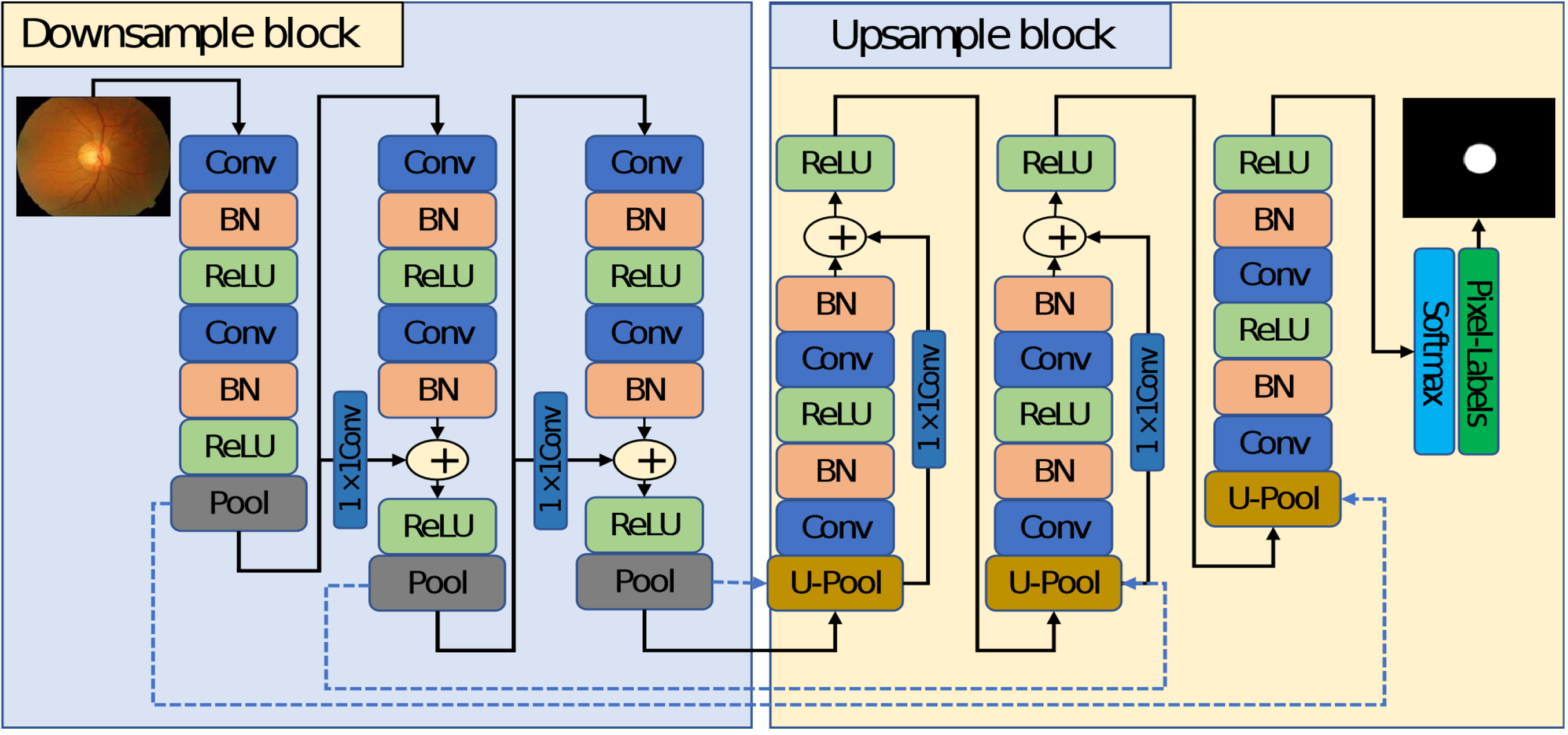
The proposed model for semantic segmentation of OD and OC is unfolded in this subsection. Figure 1 presents the block diagram of the automatic semantic segmentation approach for OD/OC segmentation. The RC-DNN is developed, which is powered by residual connectivity that allows the model to perform robust segmentation using prior pre-processing of the images. The RC-DNN takes the original image and applies semantic segmentation to it. The output of the RC-DNN is the pixel-wise classification map.

Block diagram of the proposed framework.
In the last stage, noise removal is done by applying morphological operations. An open morphological operation followed by a closing morphology operation is performed to remove the few pixel noise and filling the gap in the desired areas, respectively. The output of the proposed method is a mask where the white region represents the candidate class, and the black region presents the background pixels.
Semantic segmentation is a dual process in which the classification network is used without the fully connected layers to down-sample the image and an USB to resize the image back. The detailed diagram of the proposed RC-DNN is shown in Figure 2. It applies step by step convolution process in combination with pooling to represent the image by the features using the DSB. The DSB results in the smaller image feature with full image representation. The output of the DSB is very small and cannot be used directly, so up-sampling is required to resize the image feature back to the original size. RC-DNN uses an USB to up-sample the small feature map of DSB back to the original size.
The detailed representation of the proposed Residual Connection enabled Deep Neural Network (RC-DNN) model.
Considering the OD and OC segmentation of retinal fundus images, the OC boundary is not very distinctive, so it is very difficult to identify it with pre-processing overhead. To deal with the above-mentioned issue of robust segmentation, RC-DNN considers three main architectural design principles. First, keeping the network simple/lightweight and performing the segmentation with a total of twelve convolution layers for DSB and USB both to make a cost-effective and faster network. Second, the pooling layers reduce the size of the feature maps much smaller than the image, due to which it is not enough to deal with OC boundary, unlike conventional encoder–decoder networks.6,25 The RC-DNN uses only three pooling layers and keeps the smallest feature map size at 41 × 46. Third, the model faces an over-fitting problem, where the residual networks 5 are famous for dealing with the vanishing gradient and over-fitting problems effectively. Compared to 26 , RC-DNN uses four non-identity-based skip-connections for feature enhancement and to deal with the over-fitting problem.
As shown in Figure 2, RC-DNN consists of three DSBs, and three USBs, both with non-identity residual mapping. Each DSB starts with a convolution layer and ends with a pooling layer. The pooling layer in each DSB provides three connections to the first convolutional layer of the next block, skip connection to the next block, and transfers the pooling indices (represented by dotted arrows in blue color) to the un-pooling layer of the corresponding USB. As shown in this figure, each pooling layer transfers the non-identity-based residual information to the next DSB. The residual connectivity of each DSB and USB is also shown in this figure.
It can be observed in Figure 3 that each first convolutional layer DSBi−Conv−1 of the candidate DSB receives Di as the input feature. This Di feature passes through two convolutional layers combined with batch normalization (BN) and ReLU (where BN represents batch normalization and ReLU represents rectified linear unit) and provides the T(Di) feature at the output of the second convolution DSBi −Conv−2. This T(Di) feature is degraded by passing through continuous convolutions. Therefore, an imported feature Di is combined with T(Di) by element-wise addition through a non-identity residual skip connection to make empowered feature FDSB given by equation (1).

Details of residual connection in our developed model.
Similarly, each first convolutional layer of the candidate USBi−Conv−1 receives Ui as the input feature. This Ui feature passes through two convolutional layers in a combination of BN and rectified linear unit (ReLU) and provides the T(Ui) feature at the output of the second convolution DSBi−Conv−2.
This T(Ui) feature is degraded by passing through continuous convolutions, so an imported feature Ui’ is combined with T(Ui) by element-wise addition through a non-identity residual skip connection to make empowered feature FUSB given by equation (2):
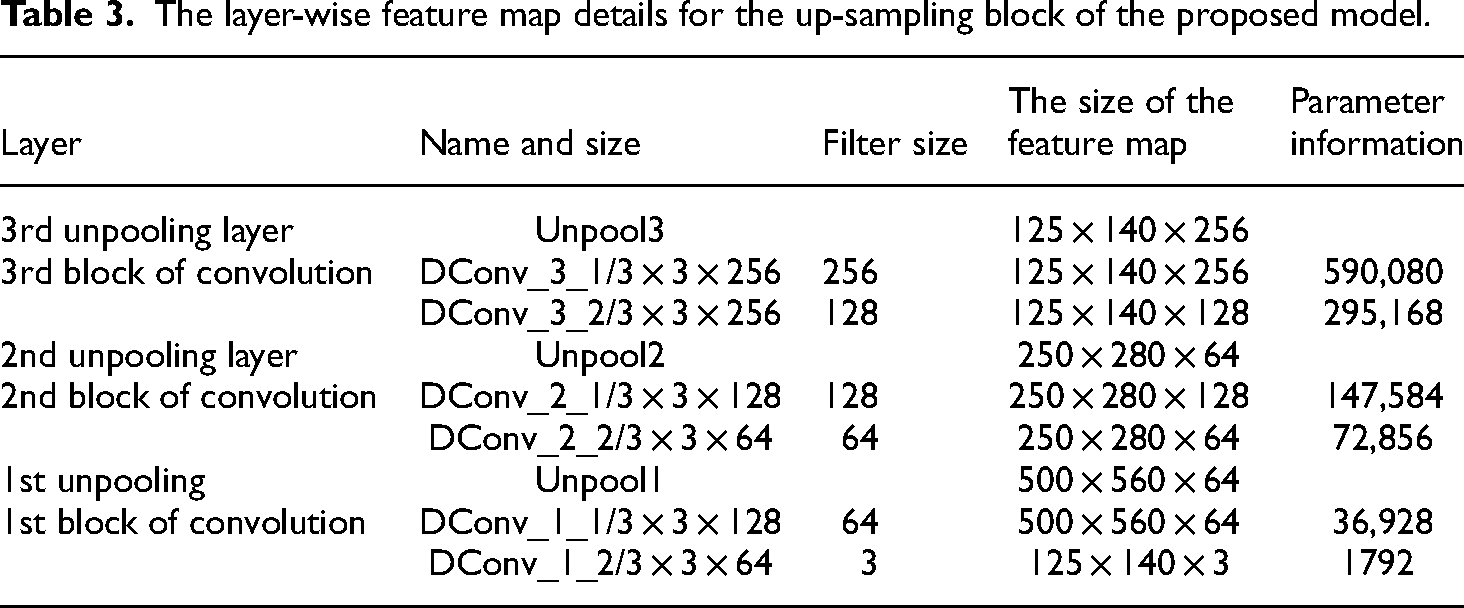
Tables 2 and 3 show the layer-wise feature map details for the encoder and decoder blocks for RC-DNN, respectively.
The layer-wise feature map details for the down-sample block of the proposed model.

The layer-wise feature map details for the up-sampling block of the proposed model.
Results and comparison
We present our experimental results both graphically and in tabular form in this section. Furthermore, the details of the databases and the evaluation metrics used are also unfolded.
Performance metrics
We have used standard evaluation metrics for assessing the performance of our developed model on the publicly available datasets of Drishti-GS and RIM-ONE. We have used the evaluation metrics, including dice coefficient (F1 score), Jaccard (O), specificity, sensitivity, overlapping error (E), and balanced accuracy (BA). We aim to evaluate our developed RC-DNN model for the OC/OD segmentation compared to the graded ground truth from experts. The selected evaluation metrics are as given below:





The Dice coefficient in equation (3) is a statistical metric used to represent the similarity between two sets of data/images. In our case of retinal fundus image segmentation, it assesses the performance of machine/deep learning models that produce binary segmented images. It is used to determine the ratio of the intersection of detected pixels in two images to the average number of pixels in both images. Its value ranges from 0 and 1, indicating no overlap to full overlap respectively.
Jaccard index in equation (4) is a statistical evaluation metric, which is used for comparing the similarity/diversity between two sets of data/images. It is calculated as a ratio of the intersection of the two sets to their union. Simply, the Jaccard index processes the quantity of shared elements between the two sets, in comparison with the total number of elements of the two sets. The resulting value ranges from 0 to 1, representing fully dissimilar to fully identical sets. Sensitivity of equation (6) is an evaluation metric representing the accuracy of a classification/diagnostic test. In the case of retinal fundus image segmentation, it is the ratio of correctly identified positive pixels to the total number of actual positive pixels in an image. In simple words, it indicates how well a machine/deep learning model can correctly identify individuals with a specific disease. In medical scenarios, it is the capability of a diagnostic test to appropriately identify individuals suffering from a specific disease. Specificity shown in equation (7) is an evaluation metric, which indicates the accuracy of a classification model or a diagnostic test. It measures the ratio of the proportion of correctly recognized negative cases to the total number of actual negative cases in a sample. Simply, the specificity shows how well a model or test can correctly identify people who do not have a specific disease.
Accuracy is the extent of the overall correctness of a classification/prediction model. It is the ratio of the number of correct predictions to the total number of predictions made by the model. Simply, the accuracy measures how well a machine/deep learning model is able to correctly identify the true positive and true negative cases among all the cases. BA of equation (8) is an evaluation metric that is used for assessing the performance of a classification machine/deep learning model that considers both sensitivity and specificity and determines their average.
Data augmentation
Data augmentation is a widely used approach to resolving the problem of insufficient graded images for effectively training a deep learning model. In general, the investigators use several types of data augmentation to get sufficient images to perform successful training of a deep learning model. The data augmentation assists in avoiding over-fitting problems of the developed deep learning model.
Arsalan et al. 27 described various methods of producing an adequate amount of images artificially using data augmentation approaches, which is required for the most effective training of any developed deep learning model. They used numerous data augmentation techniques on the 20 retinal images and their associated graded samples of the DRIVE database. These processes included flipping (vertical/horizontal) and translation with crop-resize (nearest-neighbor interpolation), which we have illustrated in Figure 4. 27 The images in figure show graphically all the different data augmentation processes.

The data augmentation approach for creating adequate images to avoid over-fitting.
They created 20 images using the horizontal flip operation and 20 images using the vertical flip operation as part of the first step of their data augmentation. As a result, the flipping process generated the 40 images in Figure 4(a). In the second stage of the data augmentation, the 60 images were used in various data augmentation steps of translating both vertically and horizontally, flipping, and resizing repeatedly, creating 480 images as shown in Figure 4(b). The final step involved translating the resulting 480 images independently in both the vertical and horizontal directions, flipping each image, and resizing them without repeating the process. This resulted in the 480 + 480 + 480 = 1440 images that are shown in Figure 4(c).
Furthermore, it is highly suggested to execute mirroring and rotation to attain an adequately large database of retinal images. This will help in solving the class imbalance issue and the over-fitting issue of the deep learning model.
Using the mentioned data augmentation approach, we generated 1920 for training of the proposed RC-DNN. From this pool of images, 70% of images were used for training the developed model whereas 15% of images were reserved for each of the validation and testing purposes. Furthermore, the stochastic gradient descent with 0.001 learning rate was applied during the training phase. Also, just 20 epochs with shuffling and a mini-batch size of 6 images are enough for the RC-DNN, as it converges faster.
Quantitative and qualitative analysis for comparison with representative models from literature
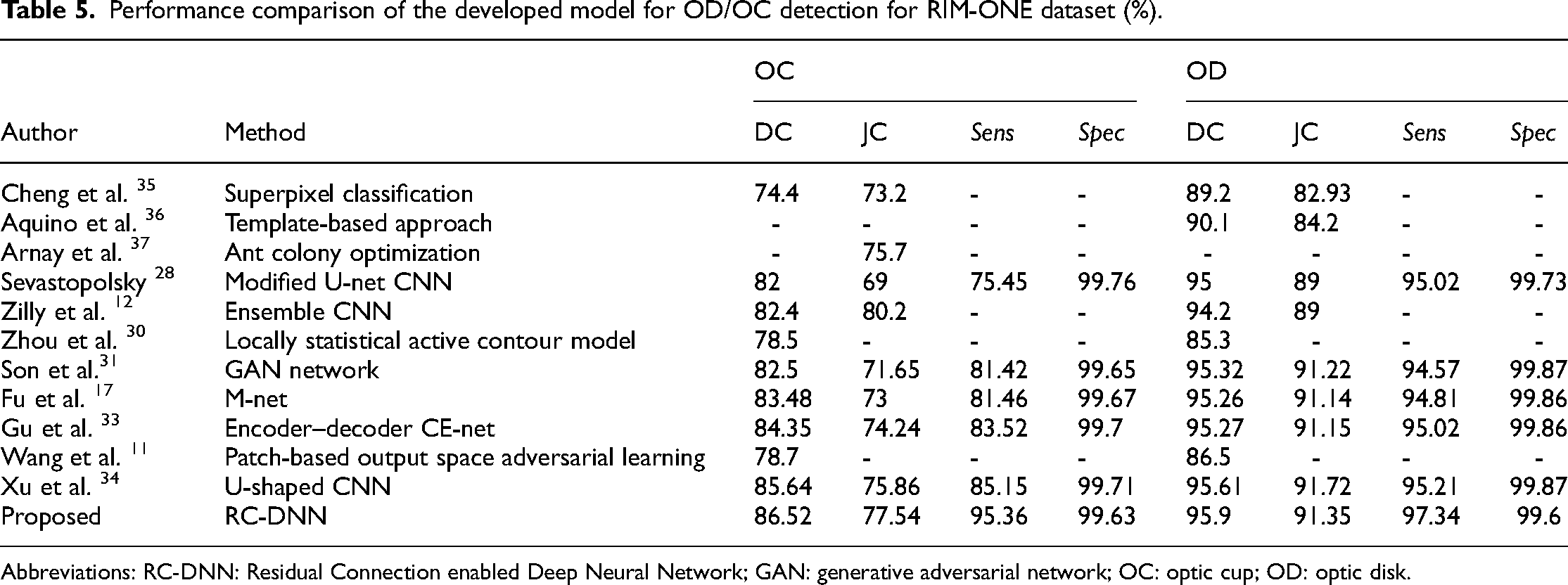
We evaluated our developed model for segmentation using two databases i.e. Drishti-GS and RIM-ONE, and presented the results in Tables 4 and 5, respectively. Table 4 indicates that the proposed model achieved the highest dice coefficient, Jaccard coefficient (O), sensitivity for OC detection, and comparable results for OD detection on test images from the Drishti-GS dataset.
Performance comparison of the developed model for OD/OC detection of the Drishti dataset (%).

Abbreviations: CNN: convolutional neural network; RC-DNN: Residual Connection enabled Deep Neural Network; Abbreviations: OC: optic cup; OD: optic disk.
Performance comparison of the developed model for OD/OC detection for RIM-ONE dataset (%).
Abbreviations: RC-DNN: Residual Connection enabled Deep Neural Network; GAN: generative adversarial network; OC: optic cup; OD: optic disk.
Table 5 shows that the proposed model achieved the highest dice coefficient (F1 score) and sensitivity while the second-highest Jaccard coefficient (O) for OC detection on test images from the RIM-ONE dataset. It is also evident from this table that the proposed model achieved the highest dice coefficient and sensitivity while the second-highest Jaccard coefficient (O) for OD detection on test images from the RIM-ONE dataset.
We observed that the proposed RC-DNN performed much better for OC segmentation than the state-of-the-art methods. For OD segmentation, the proposed RC-DNN performance is comparable with the state-of-the-art methods. These results proved that the proposed model is robust and reliable and advocates for its use for glaucoma diagnosis.
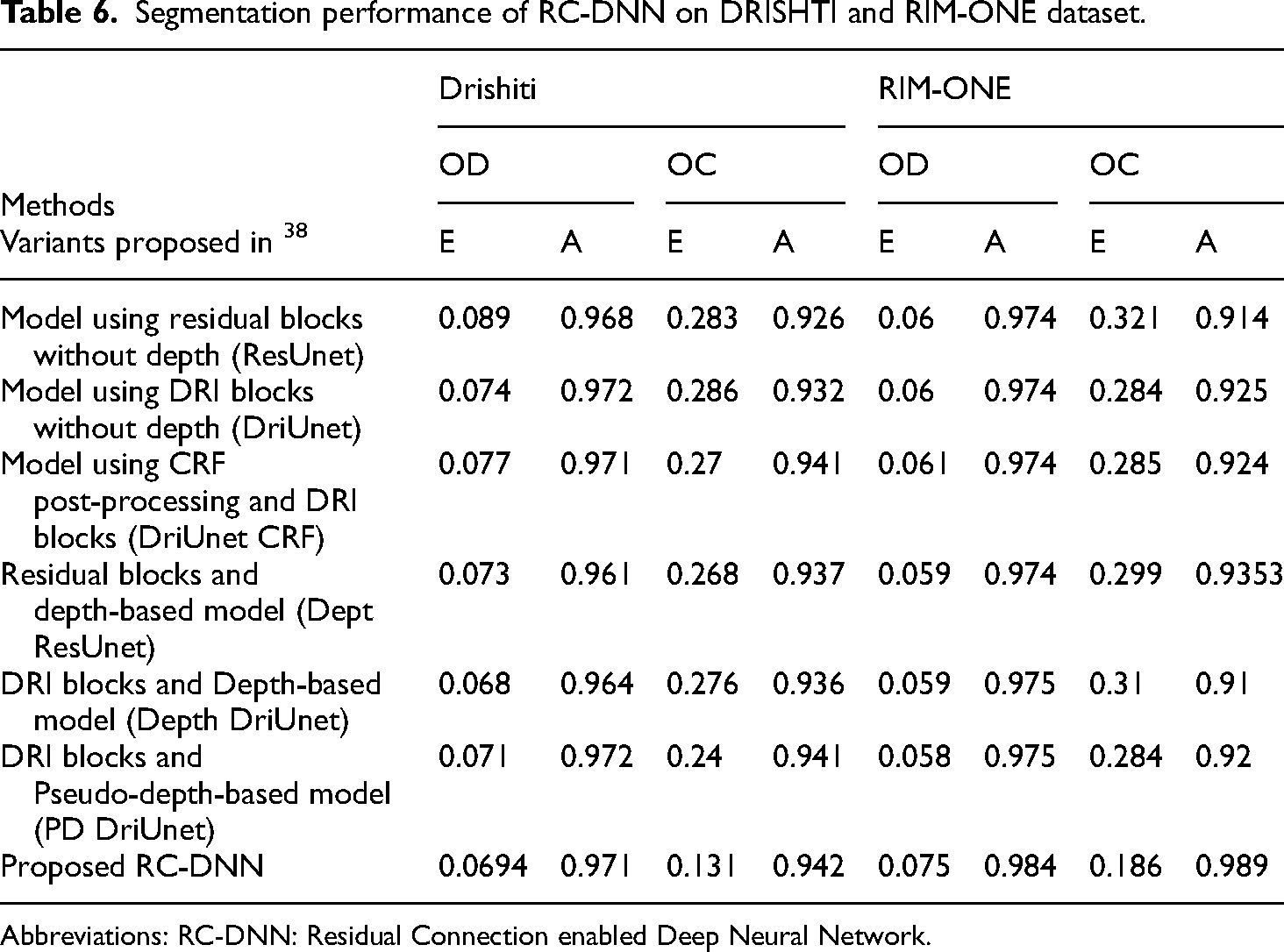
The segmentation performance of the developed model for the tasks of OD and OC detection using Drishti-GS and RIM-ONE for the evaluation metrics of error and balance accuracy (equations (5) and (8)) is shown in Table 6. It is evident from this table that the developed model achieved better BA for both OC and OD detection based on test images from both the considered datasets. Furthermore, it also obtained comparable results for the error metric for both OD and OC detection on the test images from both datasets.
Segmentation performance of RC-DNN on DRISHTI and RIM-ONE dataset.
Abbreviations: RC-DNN: Residual Connection enabled Deep Neural Network.
For visual analysis, the OD and OC segmentation results of the developed model for RIM-ONE and DRISHTI-GS datasets are shown in Figures 5 and 6, respectively.

Segmentation performance of the proposed Residual Connection enabled Deep Neural Network (RC-DNN) on the DRISHTI dataset.

Segmentation performance of the proposed Residual Connection enabled Deep Neural Network (RC-DNN) on RIM-ONE dataset.
Conclusions and future work
In this work, we have designed, implemented, and evaluated a Residual Connection-based Semantic Segmentation network (RC-DNN) with a valuable feature empowerment policy based on non-identity residual mapping for the joint OC and OD segmentation. We have employed the information reuse policy through skip-connections from the preceding layers, ensuring both higher accuracy and quicker convergence of the model. Furthermore, the computational complexity (the number of parameters) is reduced by limiting the number of DSB and USB, due to which it can be trained quickly with fewer epochs. For evaluating the proposed model's performance, we have considered two publicly available datasets DRISHTI-GS and RIM-ONE. We used an effective augmentation process to increase the number of training samples for the network. We have obtained significantly better evaluation metrics of F1 score, Jaccard and sensitivity, and BA for the OC segmentation with the comparable performance of OD segmentation on the test images from both the considered databases. Furthermore, the obtained results indicate high-quality OD/OC segmentation performance, indicating the high efficiency of the developed model and advocating for its use for early diagnosis of glaucoma. In future work, we aim to optimize the model further to be tested/validated on other retinal databases and extend it for other eye diseases.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This Research is funded by Researchers Supporting Project Number (RSPD2023R947), King Saud University, Riyadh, Saudi Arabia.
Author biography
Khursheed Aurangzeb is Associate Professor in Department of Computer Engineering at College of Computer and Information Sciences, King Saud University, Riyadh, Kingdom of Saudi Arabia. He received his Ph.D. in Electronics Design from Mid Sweden University Sweden in June 2013 and MS in Electrical Engineering (System on Chip Design) from Linkoping University, Sweden in 2009. He received his B.S. degree in Computer Engineering from COMSATS Institute of Information Technology Abbottabad, Pakistan in 2006. Dr. Khursheed has authored and co-authored more than 90 research publications including IEEE / ACM / Springer / Hindawi / MDPI journals, and flagship conference papers. He has obtained more than 15 years of excellent experience as an instructor and researcher in data analytics, machine/deep learning, signal processing, electronics circuits/systems, and embedded systems. He has been involved in many research projects as a principal and co-principal investigator. His research interest is in the diverse fields of computer architecture, signal processing, wireless sensor networks, embedded and pervasive computing, and mobile cloud computing emphasizing big data, machine and deep learning with applications in smart grids, precision agriculture, and healthcare.