
Abstract
In response to the challenges of complex background interference, inadequate feature utilization, and model redundancy in multispectral crown extraction, this paper proposes a dual-channel crown detection and segmentation approach based on an improved YOLOv7 architecture, named Dual-YOLOv7. First, a dual-branch feature extraction network is designed, integrating visible light and infrared spectral information and dynamically weights key features through an attention mechanism. Second, the D-SimSPPF module is introduced, which employs depthwise separable convolution to optimize spatial pyramid pooling, thereby enhancing the capability to capture fine details while reducing the number of parameters. Furthermore, the CIoU-C loss function is developed, incorporating a shape penalty factor to improve the accuracy of bounding box regression. Experimental results demonstrate that the improved model achieves detection and segmentation mAP50 scores of 91.6% and 90.1%, respectively, representing increases of 7.7 and 7.6 percentage points over YOLOv7-seg. After channel pruning, the model parameter count is reduced by 14.2%, offering a lightweight solution suitable for unmanned aerial vehicle platforms.
Introduction
The crown of a tree directly reflects its health and is closely associated with its growth, development, and reproduction. 1 The crown is also the most visually prominent feature of the tree. It performs photosynthesis, providing nutrients essential for tree survival. 2 Additionally, for wild animals such as macaques, the crown offers activity space beneath tree canopies. For humans, it serves as a source of building materials and food, offers protection from wind and sand, beautifies and purifies the environment, and generates oxygen for the atmosphere. Consequently, crown extraction has become increasingly significant in forest resource management. However, due to the complexity of forest structure, accurately obtaining crown shape and edge information remains a significant challenge. 3
In recent years, significant scientific advancements have been achieved in utilizing unmanned aerial vehicles (UAVs) for forest remote sensing. 4 Widely applied in fields such as military, 5 agriculture, 6 and environmental monitoring, 7 UAVs, as a low-altitude airborne platform, facilitate many research activities, including tree height extraction, 8 tree diameter estimation, 9 and forest health status evaluation. 10
Additionally, as a low-altitude flight platform, unmanned aerial vehicles (UAVs) can carry various sensors, including RGB, multispectral, hyperspectral, and light detection and ranging (LiDAR), 11 providing rich data sources for forest resource surveys. In particular, multispectral imaging technology, which captures spectral information across multiple bands, can comprehensively reflect biophysical parameters of tree canopies, such as structural characteristics, water content, and chlorophyll distribution. This capability effectively overcomes the limitations of visible light imaging in complex backgrounds. 12 Consequently, the combination of UAVs and multispectral imaging has emerged as a research hotspot in the field of forest resource management.
Although UAV-based imaging techniques can acquire high-resolution data, they still face numerous practical challenges. One prominent issue is the difficulty of accurately delineating the precise shapes and boundary edges of tree canopies. 13 Early research primarily employed image segmentation techniques for crown information extraction, including visual interpretation, 14 object-based image analysis, 15 local maximum filtering, 16 and watershed segmentation algorithms. 17
With the development of artificial intelligence, traditional machine learning methods have been introduced into crown extraction research due to their simple model structures and low computational requirements. For example, support vector machine (SVM)-based algorithms perform crown classification by integrating spectral and texture features, 18 optimize visible light image processing by combining object-based image analysis (OBIA) with random forest algorithms, 19 and enhance feature stability with edge-preserving filters (EPF). 20 However, these methods depend on manually designed features and are susceptible to interference from lighting, shadows, and occlusions in complex backgrounds, which can introduce biases in feature extraction. Particularly when relying solely on visible light data, traditional machine learning approaches encounter performance bottlenecks. To address this issue, researchers have explored combining multispectral imagery with machine learning to enhance feature representation through complementary multi-band information,21,22 thereby laying the groundwork for subsequent explorations of deep learning methodologies.
UAV-based multispectral remote sensing systems enable the simultaneous acquisition of high-resolution spectral imagery by integrating multiple spectral channel sensors. By capitalizing on the low-altitude flight capabilities of UAVs, this technology significantly enhances the spatiotemporal resolution of data collection.23,24 In recent years, considerable advancements have been achieved in the extraction of tree crowns using UAV multispectral data. For example, Li et al. 25 employed UAV-captured multispectral data of broad-leaved forests, combining bilateral filtering with multi-scale segmentation algorithms to accurately delineate individual crowns in densely vegetated areas. Similarly, Zhang et al. 26 determined the east-west and north-south dimensions of apple tree canopies by applying multi-scale segmentation and threshold classification techniques to UAV multispectral imagery and further quantified the influence of flight altitude on crown width measurement accuracy, thereby providing a valuable foundation for parameter optimization in UAV-based forestry surveys.
In recent years, deep learning methods have emerged as powerful tools for tree crown information extraction. Existing approaches can be categorized into two primary types: two-stage detection algorithms (e.g. Faster R-CNN) and one-stage detection algorithms (e.g. YOLO and SSD series). Two-stage methods generate region proposals via a Region Proposal Network (RPN) before conducting classification and regression, thereby offering high accuracy but incurring substantial computational complexity. In contrast, one-stage methods perform end-to-end detection directly on feature maps, achieving a balance between speed and accuracy. For instance, Cai et al. 27 proposed an enhanced Faster R-CNN algorithm incorporating ResNet-101 and Feature Pyramid Network (FPN) to form an FPN_ResNet101 architecture, which improved shallow-layer feature extraction for positional modeling. Ma et al. 28 optimized the Faster R-CNN framework by substituting VGG16 with Inception-ResNet-V2 as the feature extractor, resulting in a significant enhancement of discolored tree crown recognition, although computational efficiency remained constrained in dense crown scenarios. Compared to two-stage methods, one-stage approaches are more suitable for UAV platforms requiring high real-time performance. Agarwal et al. 29 employed the Darknet-19 model as a feature extractor in combination with the single shot MultiBox detector (SSD) algorithm for object detection and localization. Building upon YOLOv7, Huang et al. 30 integrated the lightweight MobileNetV3 network with a semi-supervised sample mining strategy, which effectively reduced manual annotation costs and improved detection speed. Colkesen et al. 31 employed the YOLOv7 model to detect and count individual poplar trees from multispectral orthomosaics, adopting an enhanced and efficient layer aggregation network (E-ELAN) framework in the backbone. Their research demonstrated the strong performance of YOLOv7 in individual poplar tree detection. Cemalettin Akdoğan et al. 32 introduced the PP-YOLO model as an innovative solution for crown extraction, which integrated image preprocessing techniques such as histogram equalization (HE) and wavelet transform (WT) to significantly enhance the performance of YOLO in cherry and apple tree detection tasks. Additionally, the inclusion of a spatial attention module (SAM) emphasized branch-leaf structures and color features of crowns, further improving detection accuracy. However, single-modality methods relying solely on visible light data remain vulnerable to variations in illumination and background interference, particularly under conditions of shadow occlusion where feature extraction capabilities are limited.
To address the limitations of single-modality approaches, researchers have increasingly explored multimodal fusion strategies that integrate visible and infrared imagery, leveraging cross-spectral feature complementarity to enhance model adaptability in complex environments. Li et al. 33 proposed a hybrid fusion network that integrates CNN and Transformer architectures, coupled with a two-stage training strategy for visible-infrared image fusion. Gao et al. 34 introduced EfficientFuse, a multi-level cross-modal fusion network designed to capture both local dependencies and global contextual information from shallow to deep layers. This architecture effectively integrates complementary features from both modalities and incorporates the AFI-YOLO detection network to mitigate background interference in fused imagery. Building upon this foundation, Guo et al. 35 developed a cosine similarity-based image feature fusion (CSIFF) module, which was integrated into a dual-branch YOLOv8 architecture to construct the lightweight and efficient MMYFNet detection network. Experimental evaluations demonstrated that MMYFNet achieved superior performance on both the VEDAI and FLIR datasets.
Therefore, to address the issues of missed and false detections in crown extraction in multispectral images captured by drones, as well as insufficient adaptability in complex backgrounds. This study proposes an enhanced YOLOv7-based crown extraction method leveraging deep learning. The main contributions of this work are as follows:
Two independent feature extraction channels and a fusion module were designed to mitigate false alarms and missed detections during crown extraction. The fusion of visible texture and infrared thermal features is achieved via a SE weighting mechanism combined with Inception-based multi-scale extraction. This strategy effectively integrates cross-spectral feature information, reducing false alarms and missed detections arising from the limitations of single-spectrum data. A lightweight D-SimSPPF module is introduced to enhance model adaptability in complex environments. This module replaces the conventional SPPCSPC structure and incorporates depthwise separable convolutions, enabling improved capture of fine-grained image details, enhanced adaptability to intricate scenes, and reduced computational complexity. To further improve convergence speed, detection accuracy, and performance in detecting small targets, a novel boundary regression loss function, CIoU-C loss, is proposed. Additionally, a shape penalty factor γ is introduced to address bounding box deviations caused by the variability of crown shapes, thereby enhancing overall detection performance. To meet the deployment requirements of UAV platforms, while ensuring high detection speed and accuracy, a channel pruning strategy is employed to compress the improved model. This approach simplifies the network architecture and ensures that the model maintains lightweight characteristics without sacrificing detection accuracy, thereby supporting deployment on UAV platforms with constrained computational resources.
Materials and methods
Overview of the research area and the unmanned aerial vehicle multispectral image acquisition system
This study focuses on the typical artificial forest area of Cunninghamia lanceolata located in Dawu County, Hubei Province, China, with geographical coordinates ranging from latitude 31°23′ to 31°51′N and longitude 114°02′ to 114°35′E. The region falls within a subtropical monsoon climate zone, with an average annual temperature of 15.5–16.5°C and annual precipitation between 1100–1300 mm. The rainy season is concentrated from June to August. The distribution of Chinese fir forests in the study area is continuous, with trees aged 20–30 years, an average height of 15–20 meters, a crown width of 4–6 meters, and a crown closure of 0.7–0.8. Due to the high stand density characteristic of artificial forests, there is significant spatial competition and local crown overlap, providing ideal conditions to validate the adaptability of crown extraction algorithms under complex multispectral imaging scenarios.
The data were collected using the Elf 4 multispectral version UAV, which integrates one visible light camera and five multispectral cameras (blue, green, red, red edge, and near-infrared) responsible for capturing visible and multispectral imagery. Each camera has a resolution of 2 million pixels, and the imaging system is mounted on a three-axis gimbal to ensure precise and stable data acquisition. The flight altitude ranged from 60–80 meters, with a heading overlap of 85% and a lateral overlap of 75%. The coverage area of each image is approximately 0.03 km². Data collection was conducted in May 2024 under uniform lighting conditions (between 10:00 and 14:00) and without cloud interference, ensuring radiometric consistency of the multispectral images. The specific parameters of the data acquisition system are summarized in Table 1.
Parameters of UAV multi-spectral image acquisition system.

Improved model structure
The core innovation of the proposed Dual-YOLOv7 architecture lies in the construction of a dual-branch feature extraction backbone designed to enhance crown extraction performance through multispectral feature fusion. The network processes dual-modality inputs—visible light and infrared—where feature extraction is conducted through symmetrical hierarchical structures in each branch, followed by cross-spectral feature fusion in the neck network.
The visible light branch utilizes RGB three-channel images to capture morphological details of tree canopies, including foliage textures and edge contours. The infrared branch processes the near-infrared (NIR) band from UAV multispectral imagery, capitalizing on the strong reflectance of vegetation in the NIR spectrum (indicative of chlorophyll content) to enhance the contrast between tree canopies and the background. Although the infrared branch shares the same hierarchical topological structure as the visible light branch, it employs spectrum-specific convolution parameter configurations to optimize feature extraction. Both branches adopt the improved YOLOv7 hierarchical structure, progressively extracting spatial features through six stages (P1-P6).
Each branch comprises six feature processing stages (P1-P6). The P1 stage incorporates a PentaConv module that enhances local feature extraction capabilities through a combination of five convolutional layers, specifically: a 5 × 5 convolution (stride 1), followed by two consecutive 3 × 3 convolutions (stride 1), and two 1 × 1 convolutions (stride 2). As represented in equation (1), where FFF denotes the original input feature map, this structure effectively reduces dimensionality while preserving detailed features through the collaborative operation of multi-scale convolutional kernels. The P2 stage integrates an enhanced ELAN1 module, where the number of channels in the ELAN structure is increased to improve the capacity of the model for feature extraction, addressing the unique complexity of tree canopies. The ELAN1 structure is illustrated in Figures 1 and 2. The P3 stage designs a MEConv hybrid module that combines max-pooling convolution (MPConv) operations with ELAN components. As shown in equation (2), MPConv realizes channel-wise concatenation of max-pooled features and 1 × 1 convolution outputs, as shown in equation (3). The P6 layer utilizes an enhanced D-SimSPPF structure. The D-SimSPPF module aims to further enhance feature representation capability through more efficient spatial pyramid pooling operations while reducing computational and model complexity.

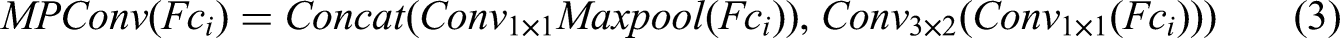

ELAN1 structure.
Architecture of the improved Dual YOLOv7 crown extraction model.
Additionally, a fusion module is incorporated into the neck network, comprising two sub-modules: attention fusion and fusion shuffle. The attention fusion module integrates squeeze-and-excitation (SE) modules and Inception structures to dynamically weight features from the infrared and visible light channels. The SE module generates channel attention weights via global average pooling, effectively suppressing irrelevant background information. Inception captures multi-scale crown features through multi-scale convolutional kernels (1 × 1, 3 × 3, 5 × 5). The Fusion Shuffle module concatenates dual-branch features and applies dilated convolutions (with dilation rates of 1, 3, 5, 7) to expand the receptive field. It further enhances cross-modality information exchange through channel random shuffling, mitigating interference from redundant features on crown boundary extraction. After effectively integrating features from the infrared and visible light images, the fused feature maps are transmitted to subsequent network components, specifically the detection head, for object detection tasks. (Figure 2)
Subsequently, upsampling operations are introduced to restore spatial details lost during downsampling, thereby enhancing the detection capability for small-scale tree crown targets. The extracted features undergo upsampling to produce high-resolution feature maps. This process aims to recover the spatial resolution of feature maps for subsequent feature fusion and detection. The generated feature maps are integrated through concatenation, combining information from different sources or levels to achieve comprehensive feature representation. These concatenated feature maps are then processed by the ELAN1 module, which adjusts channels and fuses information via a CBS module (Conv + BN + SiLU), outputting feature maps with unified dimensions. Finally, the fused feature maps are directly fed into the detection head, generating crown position and confidence predictions at the corresponding scale. In dense crown regions, conventional three-scale detection heads often suffer from false positives or false negatives due to scale overlap. The four-scale detection head proposed here mitigates prediction conflicts in dense target scenarios by enabling finer-grained scale partitioning.
Fusion model
The Fusion module integrates the Attention Fusion and Channel Shuffle modules, embedding the SE module within the Inception structure of the Attention Fusion component. Initially, visible-light and infrared images are introduced into a dual-branch backbone network. The Inception architecture employs convolution kernels of varying sizes and pooling operations to extract multi-scale features from these input images, as illustrated in Figure 3.

Inception structure.
Following the Inception processing, global average pooling is applied to the feature maps of both visible-light and infrared branches. The resulting globally pooled feature vectors undergo dimensionality reduction via a fully connected layer, followed by activation through the ReLU function. Subsequently, a second fully connected layer restores the dimensionality of the ReLU-activated feature vectors to their original channel count, generating channel-specific weight coefficients. The Sigmoid activation function then compresses the outputs of the second fully connected layer for both inputs into the [0,1] interval, yielding channel-specific weight coefficients. For the visible-light input, these coefficients reflect the relative importance of color and texture features in crown detection and segmentation tasks. For the infrared input, the coefficients capture the significance of temperature-related features. Finally, the channel weights derived from the SE modules for the visible-light and infrared inputs are applied through element-wise multiplication to the corresponding feature maps from their respective Inception modules. The detailed structure of this feature-fusion module with attention mechanisms is depicted in Figure 4.
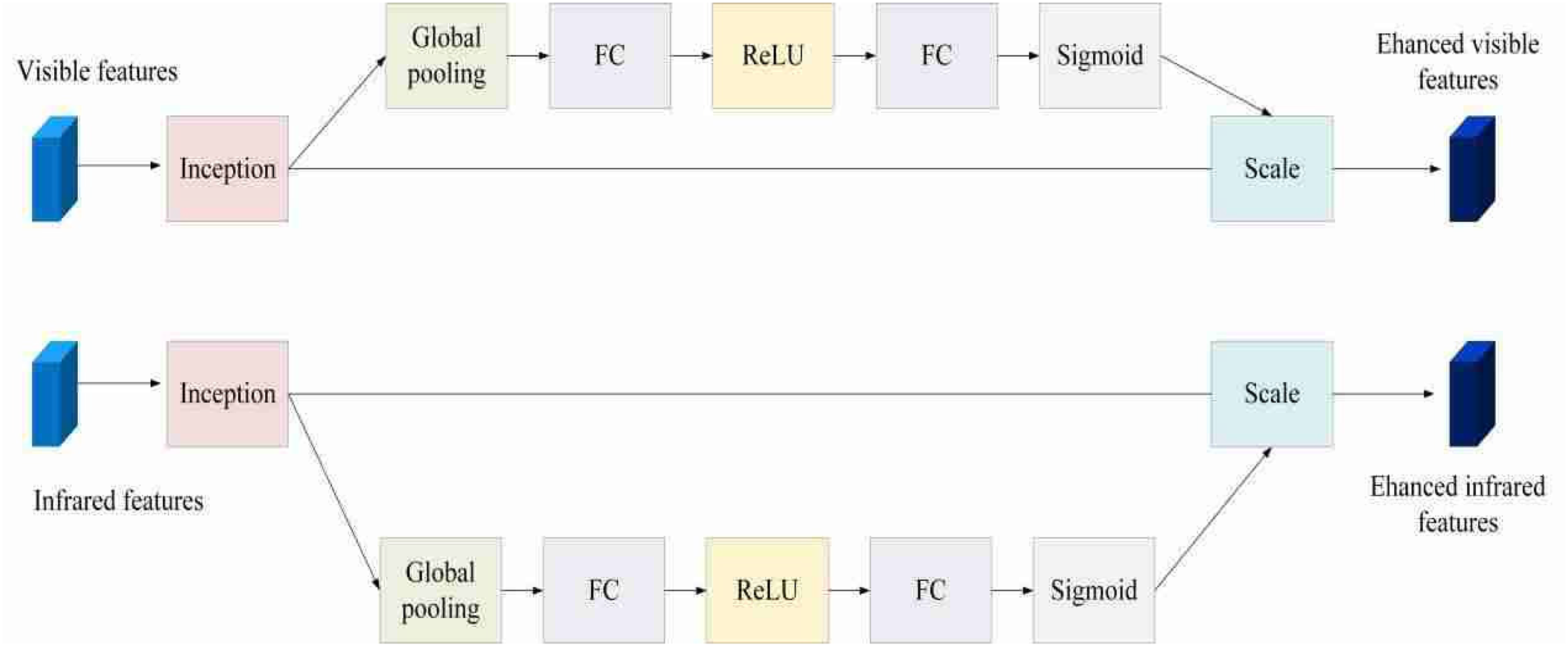
Feature-fusion module of attention mechanism.
The Channel Shuffle module is a technique used to enhance feature communication and information transmission in neural networks. In this study, the fusion-channel shuffle module, a feature fusion component, is incorporated to further improve the extraction and utilization of crown features. The core idea of the channel shuffle module is to divide the input feature map into multiple channel groups and then recombine these channels to promote information exchange between different channels. After obtaining the initial features of the crown image, features from different levels and sources are concatenated. These features may originate from observations of the crown at varying perspectives and scales or from different feature extraction algorithms. The concatenated features form a rich and comprehensive feature combination. A convolutional structure with multiple branches is then constructed. Convolution layers with smaller kernels focus on detailed crown structures, such as leaf edges and fine branches, while larger kernels capture the overall crown shape and texture features over larger areas. Specifically, convolution operations are applied using kernels of sizes 1 × 1, 3 × 3, 5 × 5, and 7 × 7. Following each convolution layer, corresponding dilated convolutions are added with dilation rates of 1, 3, 5, and 7, respectively. The dilated convolution operation expands the receptive field of the feature map without significantly increasing computation, allowing each branch to capture broader context information and better understand the spatial distribution of crown features. After the above convolution and expansion convolution processing, the output characteristics of each branch are stitched together again. At this time, these features have been strengthened and enriched in different ways. Subsequently, we introduced a special shuffle operation. The purpose of this operation is to disrupt the order of these stitched features so that the features extracted from different branches can be thoroughly mixed. In this way, the features that might have been relatively independent can be fused and supplemented with each other, avoiding the local aggregation of features and information redundancy, thus forming a more comprehensive, balanced, and representative crown feature representation. Finally, a 1 × 1 convolution operation is used to reshape the fused feature outputs. The designed fusion-channel shuffle module is illustrated in Figure 5. The input feature dimension is C × H × W.

Channel-shuffle module structure.
D-SimSPPF model
In YOLOv7, the SPPC4SPC module, which integrates spatial pyramid pooling (SPP) and cross stage partial connection (CSP), demonstrates strong performance. However, its large parameter count and high computational cost adversely affect network inference speed. To address this issue, we propose an enhanced D-SimSPPF module, where SimSPPF streamlines the traditional SPPF structure by conducting feature pooling with a fixed-size pooling kernel, followed by concatenation or fusion of the pooled feature maps to extract multi-scale features. Compared with the SPPCSPC module, SimSPPF adopts a simpler architecture, omitting complex cross-stage connections and multi-branch configurations. It primarily processes features through fixed pooling operations and straightforward fusion techniques.
In addition, the SimSPPF module replaces the original SiLU activation function with ReLU to accelerate processing speed. Although the fixed-size pooling kernel can capture multi-scale features to some extent, it often results in the loss of large-scale feature information, particularly in scenarios requiring detailed multi-scale analysis, where its feature extraction capacity may be limited. To further reduce model parameters and improve detection efficiency, we replace the conventional convolution in the CBL module with depthwise separable convolution. Depthwise separable convolution (DSC) decomposes standard convolution into two steps: depthwise convolution and pointwise convolution. The depthwise convolution performs spatial filtering on each input channel independently, focusing on extracting local details such as crown edges and leaf textures. The pointwise convolution then fuses cross-channel information through 1 × 1 convolutions, enhancing semantic feature representation. This approach improves the capability of the model for feature extraction, allowing for more accurate extraction of target features such as crowns, reducing interference from complex backgrounds, and enhancing adaptability to complex scenarios. Additionally, it decreases computational and parameter complexity, enhances computational efficiency, and contributes to model lightweight design and optimization. The process of implementing depthwise separable convolution is shown in Figure 6. The structure of the D-SimSPPF module is presented in Figure 7.

Implementation of depthwise separable convolution process.

D-SimSPPF module structure.
Border regression loss function CIoU-C loss
As an optimization of the original IoU loss function, the CIoU loss enhances the assessment of overlap relationships between predicted and ground-truth bounding boxes. It focuses particularly on complete intersection scenarios by introducing a correction factor, enabling a more precise measurement of the similarity between bounding boxes. Compared to traditional IoU, the CIoU loss function involves a more complex calculation process. However, this complexity provides a robust framework for the model to effectively capture the precise position and shape of target bounding boxes during training. The specific calculation formula is presented in equation (4).
Among them, IoU represents the intersection-over-union ratio between the predicted box and the ground-truth box, reflecting the degree of spatial overlap. The ratio is computed by dividing the intersection area of the predicted and ground-truth boxes by their union area. And represent the predicted box and the actual box, respectively, 
However, the CIoU loss function exhibits limitations when applied to targets with irregular shapes and complex structures, such as tree crowns. To address this, we propose a new loss function, CIoU-C, which introduces a shape penalty factor that specifically accounts for the unique characteristics of crown-bounding boxes. The calculation formula is provided in equation (6).
In this formulation, 
As shown in equation (7), w and h are the predicted box's length and width and the actual box's length and width, respectively. 
As shown in equation (8). Its function is to adjust the weighting of the shape penalty within the overall loss. By incorporating the CIoU-C Loss, the diversity of crown shapes can be handled more effectively, optimization efficiency can be improved, and the detection performance for small targets can be enhanced.
Channel pruning
Considering the dual constraints of model computational capacity and the onboard resources of the UAV platform, channel pruning serves as an effective solution. It can significantly reduce the number of parameters and computational complexity while maintaining model performance, thereby decreasing the hardware demands of the UAV, accelerating model inference, and enhancing UAV responsiveness. The core of this technique involves decomposing the output feature map of the convolutional layer into multiple channels and selectively removing certain channels to achieve model compression. To achieve this goal, sparse training is first applied with the aim of gradually driving some of the model weights to zero through L1 regularization. This involves introducing a regularization term that adds the sum of the absolute values of the weights to the loss function, which facilitates the identification and removal of irrelevant weights during pruning. However, excessive regularization may increase the value of the loss function and weaken the capacity of the model for fitting, making it challenging to accurately capture data features. This, in turn, can cause a rapid decline in accuracy or even lead to overfitting, thereby negatively affecting the performance of applications such as crown extraction. Therefore, to balance sparsity and model performance, it is crucial to appropriately adjust the strength of L1 regularization, monitor the changes in performance metrics during training, and dynamically modify the regularization strength based on the observed performance. This approach ensures that while reducing the number of parameters, the performance of the model can be stable or only a small decrease, and to avoid the emergence of a poor sparsification or the number of parameters has not been reduced effectively. The specific way to implement L1 regularization is by using the L1 regularization method. Regularization is realized by adding a term that multiplies the sum of the absolute values of the weights by the coefficients in the loss function in order to push the weights closer to zero, and the specific formula can be found in equation (9).
Where
Once the sparsification training is completed, it is necessary to determine the channels to be removed. Considering that the designed model is a convolutional structure and each convolutional layer is equipped with a batch normalization layer BN, in this paper, we use the scaling factor γ in the BN layer to measure the importance of the channels. 36 By applying L1 regularization to the γ parameter, we
can effectively evaluate and quantify the importance of each channel. The objective function of L1 regularization is chosen as
In equation (10),

Channel pruning process.
Experimental results
Dataset creation and data augmentation
The dataset was collected from five typical terrain types within the study area (plains, hills, mountains, open forest zones, and dense forest zones), encompassing diverse lighting conditions (sunny, cloudy, and shaded environments) and seasonal characteristics (spring new-leaf stage and summer peak foliage stage). The crown distribution density ranges from 80 to 320 trees per hectare, ensuring the generalization capability of the model across various scenarios. Aerial surveys yielded a total of 3180 raw images, including 530 images for each spectral band.
Given the challenge of limited training samples, this study employed data augmentation techniques to expand the dataset. Deep learning models typically require a large number of training images to achieve optimal accuracy. However, the data collected in this study were limited. Therefore, a series of transformations were applied to the images using data augmentation methods to increase the sample size and enhance the generalization capability of the model. Specifically, for the original 3180 multispectral images, data augmentation was applied to the RGB true-color images and infrared grayscale images. Geometric transformations, including translation, rotation (±90°), flipping (with a 50% probability), and scaling (0.8–1.2 times), were performed to generate a substantially larger number of augmented RGB and infrared images. For each original RGB and infrared grayscale image, multiple new images were created through these transformations. After statistical analysis, a total of 2120 RGB and infrared images were obtained after augmentation. The data augmentation process is illustrated in Figure 9.

Data enhancement.
To develop a tree crown detection segmentation network model for the study area, tree crown contours were manually annotated in each visible image and the corresponding multispectral image using the Labelme annotation tool to obtain precise labels. The integrated annotated JSON files were incorporated into the network model training dataset to enable the model to effectively learn the features of tree canopies. In total, 2120 images were annotated. The dataset was partitioned as follows: 1484 images for the training set, covering scenes with varying densities and background complexities; 425 images for the test set, used for final performance evaluation; and 211 images for the validation set, used for hyperparameter tuning and model verification. The annotations included the following specific scenarios: complete tree crowns with clear contours and no occlusion; partially occluded crowns where adjacent crowns overlap or branches and leaves intertwine; and complex backgrounds containing ground vegetation, rocks, or buildings. In total, 12,480 crown instances were labeled.
Evaluation indicators
To comprehensively assess the performance of the network, this study utilizes precision (P), recall (R), average precision (AP), and Intersection over Union (IoU) as evaluation metrics. The formulas for precision and recall are provided in equations (11) and (12).

Accuracy refers to the probability of positive samples among all predicted positive samples, while recall refers to the likelihood of positive samples being predicted among positive samples. Among them, TP, FP, and FN, respectively, represent the number of correctly detected targets (true positive), the number of incorrectly detected targets (false positive), and the number of undetected targets (false negative).
mAP is the average of AP values for all categories. AP can reflect the accuracy of each category prediction, the calculation formula is shown in equation (13), and mAP is the average of AP for all classes, which is used to reflect the accuracy of the entire model. The larger the mAP, the larger the area enclosed by the PR curve and coordinate axis. The calculation formula is shown in equation (14).

Among them, P(R) represents the P-R curve, and m represents the number of target categories.
IoU is a simple measurement standard that can measure any task that generates a bounding box in the output. This standard measures the correlation between reality and prediction, and the higher the correlation, the higher the value. The calculation formula is shown in equation (15).
Model training
To comprehensively evaluate and validate the model, the image resolution was set to 640 × 640 pixels, and the expanded image dataset was divided into training, testing, and validation sets at a ratio of 7:2:1. The model was subsequently trained on this dataset. The Adam optimization algorithm was employed to adjust the training process. The IoU threshold during training is set to 0.2, the batch size of the model is set to 16, the number of training sessions is set to 300, the initial learning rate is 0.0001, the momentum is 0.947, the eps is 1 × 10−8, and the weight decay is 0.0001. The model was configured using these parameters and trained iteratively on the dataset. After 300 training epochs, the resulting training parameter outcomes for both the improved and original models were obtained. The detailed results are presented in Table 2. An example of the detection results is provided in Figure 10. Additionally, examples of detection and segmentation outcomes of the improved model in two distinct scenarios are illustrated in Figure 11.

Improved effect picture.

Detection and segmentation performance of the improved model in different scenarios.
Model detection and segmentation results.

Figure 11 depicts two distinct scenarios. The improved model can recognize all tree species in a simple scenario with wide tree spacing and negligible background interference. Conversely, in complex scenes where trees grow densely and vary in size, the enhanced feature-extraction capacity of the improved model, enabled by the D-SimSPPF module, allows it to capture intricate details within images better, thereby enhancing its adaptability to such complex scenarios. As a result, the model can detect all tree species, even in densely populated areas. In summary, the improved Dual-YOLOv7 model demonstrates robust generalization, enabling accurate target detection across diverse scenarios and achieving single-tree detection and tree-species extraction within the study area.
Upon examining the performance metrics of the two models within the training set, it is evident that the enhanced Dual-YOLOv7 model demonstrates significant improvements across multiple metrics compared to the original YOLOv7 base model. Specifically, compared to the YOLOv7-seg model, the accuracy increased by 8%, and the recall improved by 3.8%. These enhancements can be attributed to the bounding-box regression loss function, CIoU-C Loss, which effectively mitigates bias in bounding-box regression and thereby enhances the detection performance of the model. Following the integration of the D-SimSPPF and fusion modules, the average detection accuracy of the model improved by 7.9 percentage points, and the average segmentation accuracy increased by 8 percentage points. These results highlight the strong adaptability of the D-SimSPPF module, which significantly enhances the capability of the model to recognize tree crowns. Furthermore, the reduction in the number of parameters of Dual-YOLOv7 compared to YOLOv7 further confirms the lightweight nature of the Dual-YOLOv7 model. This characteristic facilitates its efficient deployment on unmanned aerial vehicle platforms with limited computational resources, underscoring the superiority of the improved model.
Ablation experiment
In this section, YOLOv7 was employed as the baseline model to conduct ablation experiments on a custom dataset, thereby validating the feasibility and effectiveness of the proposed model enhancements. The Fusion module, D-SimSPPF module, and modified loss function were successively integrated into the YOLOv7 network for progressive experimentation. Utilizing the same dataset and training parameters, the experiment aimed to systematically analyze the impact of these improvements on both detection and segmentation performance. The results of the ablation experiment are summarized in Table 3.
Detection/segmentation results under different improvement strategies.

The experiment results demonstrated that the baseline model achieved an accuracy, recall, and average precision of 87.9%, 81.4%, and 83.9%, respectively. When the Attention Fusion module was integrated independently, the detection accuracy, recall, and average precision improved to 89.2%, 83.9%, and 85.1%, representing increases of 1.3, 2.5, and 2.1 percentage points compared to the baseline. This improvement can be attributed to the unique feature-weight allocation mechanism of the module, which emphasizes key features essential for crown recognition and segmentation, effectively suppressing irrelevant or interfering features. Consequently, the model achieved substantial gains in detection and segmentation accuracy, enabling a more precise focus on crown targets. When the Channel Shuffle module was incorporated independently, detection accuracy increased to 90.1%, and segmentation accuracy reached 83.8%. This module promotes multispectral feature interaction through channel-mixing operations, effectively reducing feature redundancy and significantly enhancing segmentation accuracy, particularly in complex backgrounds. When the D-SimSPPF module operated alone, the detection accuracy increased from 87.9% of the baseline model to 88.7%, and the segmentation accuracy improved from 82.5% to 83.1%; it optimizes the feature-extraction efficiency through depthwise separable convolution and a parameter-free attention mechanism. When the Fusion Channel Shuffle module was integrated into the Attention Fusion module, detection accuracy reached 88.4%, and segmentation accuracy rose to 87.9%, indicating that the synergistic effect of attention mechanisms and channel mixing enables the model to capture both local details and global morphological features of the crown with greater precision. When the Attention Fusion module was combined with the D-SimSPPF module, detection accuracy increased to 91.5%, highlighting the combined benefits of enhanced computational efficiency and improved feature-expression capability. The combination of the D-SimSPPF module and the Fusion Channel Shuffle module further elevated segmentation accuracy to 84.6%, validating the complementarity of channel mixing and lightweight design in complex scenarios. When all enhanced modules were employed simultaneously, the detection accuracy reached 91.8%, and the segmentation accuracy rose to 90.5%, representing increases of 7.9 and 8 percentage points, respectively, compared to the baseline model. These results demonstrate that the collaborative integration of multiple modules fully exploits the multispectral information from infrared and visible light sources, significantly reduces model complexity through lightweight design, and ultimately achieves a balance between accuracy and efficiency. This improvement provides robust support for achieving high-precision crown detection and segmentation.
As shown in Table 4, the D-SimSPPF module significantly reduces computational complexity compared to the traditional SPPCSPC module, the basic SimSPPF module, and the ASPP module. This reduction is achieved by replacing the standard convolution in the CBL module with depthwise separable convolution, effectively mitigating the risk of overfitting of the model, rendering the model more suitable for deployment on resource-constrained unmanned aerial vehicle platforms and thus significantly enhancing the applicability of the model. Concerning inference time, the D-SimSPPF module alone requires only 7.42 ms, a substantial decrease from the 29 ms of the SPPCSPC module. This allows the model to rapidly process image data during actual operation, effectively boosting the real-time response capacity of the system and satisfying the demands of application scenarios with stringent timeliness requirements. Additionally, the D-SimSPPF module exhibits a modest advantage in computational complexity, underscoring its potential competitiveness in practical applications, particularly in scenarios where high efficiency is essential.
Performance comparison of D-SimSPPF modules.

According to Table 5, various combinations of the Inception and SE modules were investigated. When neither module was integrated, the mAP50 and mAP50:95 of the model were 83.9% and 69.6%, respectively. Introducing the Inception module alone improved these indicators, demonstrating its capacity to enhance feature representation. Similarly, the integration of the SE module alone yielded performance gains. Notably, the optimal performance was achieved when both modules were applied simultaneously: the mAP50 values for detection and segmentation reached 85.1% and 84.2%, respectively, while mAP50:95 reached 73.5% and 70.7%. These findings demonstrate that the synergistic application of the two modules can substantially enhance crown recognition accuracy, optimize feature processing, and bolster the robustness and precision of the model, thereby providing a practical solution for crown extraction.
Ablation experiment of attention module.

As shown in Table 6, an ablation experiment was conducted to compare the YOLOv7 model with the model integrated with CIoU-C. The results revealed that incorporating CIoU-C increased the segmentation accuracy mAP50:95 from 68.2% to 69.9%. This demonstrates that the CIoU-C loss function can significantly improve the accuracy of the model in crown extraction tasks by effectively addressing the bias issue in bounding-box regression and playing a crucial role in enhancing model performance. As depicted in Figure 12, as the number of training epochs increases, the box loss of both CIoU-C and CIoU gradually declines and eventually converges; however, CIoU-C converges more rapidly and reaches a smaller loss value. Consequently, CIoU-C was selected as the loss function for this study.

Comparison of loss function convergence.
Ablation experiment of CIoU-C loss function.

Model compression
After the ablation experiments, it was observed that integrating all modules significantly enhanced model performance compared to using individual modules. Therefore, to maintain high performance while improving model efficiency, channel pruning was applied to the integrated model to achieve a lightweight design. Firstly, sparse training is carried out, and the initial regularization factor is set to
In terms of the pruning method, an overall proportion setting is employed. The scale factors of all channels were sorted in sequence, and a threshold was calculated based on a predefined pruning proportion. Channels with scale factors below this threshold were pruned. To avoid selecting a threshold that is too high—potentially resulting in complete pruning of convolutional-layer channels—the maximum scale factor of each layer was determined, and the smallest maximum scale factor across layers was chosen as the pruning threshold. The proportion of channels with scale factors below this threshold was calculated and used as the maximum pruning ratio, ensuring that at least one channel was retained in each layer. Given the moderate scale of the pre-pruned model, a relatively low pruning proportion was selected. By adjusting the pruning ratio within the range of 0.1–0.5 and evaluating the variations in model parameters, computational complexity, and mAP, the impact of different pruning ratios on performance is presented in Table 7. Subsequently, the pruned model is acceptable-tuned with the number of epochs set to 100 to recover the detection accuracy of the model. The final performance of the model is shown in Table 8.
Effects of different pruning ratios on performance.

Network model performance.

When the pruning ratio is 0.2, mAP50 slightly decreases, and the number of parameters falls by 14.2%. When the ratio is 0.3, mAP50 significantly decreases. Therefore, the pruning ratio of 0.2 is chosen as the optimal value.
The performance of the network model is shown in Table 8. Among them, Base represents the model without model compression operation. It can be observed that, following pruning and fine-tuning, the model exhibited a substantial reduction in the number of parameters while incurring only a minor loss in detection accuracy. After channel pruning, the observed decrease in mAP50 can be attributed to the loss of detailed information resulting from the pruning of shallow feature channels. This issue can be mitigated by dynamically adjusting the pruning threshold during the fine-tuning stage. During the fine-tuning process, the mAP value of the validation set is periodically assessed. If the mAP value of the validation set decreases by more than 0.5%, the partially pruned channels are gradually restored layer by layer. The restoration ratio is dynamically calculated based on the extent of performance degradation, and the corresponding formula is provided in equation (16).
In this formula, the adjustment coefficient is set to 0.1.
Comparison of segmentation performance with the original model detection
Tests were conducted on the test set to evaluate the performance of the model. Figure 13 presents a comparative analysis of the crown detection and segmentation performance between YOLOv7-seg and the improved model. In scenarios involving mutual obstruction among tree crowns, the enhanced model accurately identifies targets and minimizes missed detections. Additionally, the original YOLOv7 detection and segmentation algorithm tends to exhibit missed and false detections in areas with densely distributed crowns. In contrast, the improved algorithm effectively mitigates these issues, resulting in a substantial increase in detection and segmentation extraction rates.

Comparison of crown detection and segmentation effects between two models.
Visualizing module-wise contributions via detection/segmentation maps
To comprehensively validate the effectiveness of the Dual-YOLOv7 module design, this section analyzes the contributions of key modules to detailed feature capture, multispectral complementation, and complex crown extraction based on the performance of the thermal map visual evaluation model.
As shown in the visualization analysis in Figure 14, the attention fusion module dynamically weights multispectral features, significantly reducing background false positives and repairing shadow-induced missed detections. However, this comes at the cost of slight detail smoothing, specifically manifested in the breaking or disappearance of clear end branches in the segmented image following fusion. The D-SimSPPF module leverages depthwise separable convolution to enhance edge pixel recall, reduce crown holes, and sharpen boundaries, though it demonstrates limited sensitivity to small targets. The channel mixing module effectively addresses the issue of densely adhered tree crowns through feature recombination. However, it may introduce micro-serrations in the segmentation contours, resulting in the tree contours being divided into several small areas by these serrations.

Visual analysis of different modules.
Comparison of different detection and segmentation algorithms
As shown in Table 9, Dual-YOLOv7 exhibits the highest mAP50 value compared to other methods. Notably, its segmentation accuracy is 7.6% higher than that of YOLOv7-seg. Additionally, when compared with Mask R-CNN, YOLOv8l-seg, RT-DETR, YOLOv9-seg, YOLOv10-seg, YOLO11-seg and YOLOv5l-seg, the detection accuracy of Dual-YOLOv7 improved by 10.3, 4.4, 2.1, 1.8, 1.2, 0.5 and 8.5 percentage points, respectively. Similarly, segmentation accuracy improved by 9.5, 4.5, 1.5, 1.2, 0.7, 0.2 and 8.1 percentage points compared to these methods. While achieving the highest detection and segmentation accuracy, the model also demonstrates favorable performance in terms of parameter count and memory consumption. Although computational demands are slightly elevated, the model achieves a high inference speed of 50 FPS through the application of channel pruning and depthwise separable convolution optimization, making it suitable for deployment on UAV platforms with limited computational resources. It is believed that this improvement is not solely a result of architectural advancements within YOLOv7. Instead, it highlights the validity of the proposed approach of fusing detection and segmentation of infrared and visible-light images. Through detailed analysis, it is evident that the integration of visible and infrared modalities in the proposed Dual-YOLOv7 architecture enables the network to more effectively capture texture features. This enhancement in texture representation significantly optimizes both detection and segmentation performance.
Comparison of different segmentation algorithms.

Discussions
This study proposes an enhanced Dual-YOLO model based on unmanned aerial vehicle (UAV) multispectral data for crown extraction. The experimental results demonstrate that the model achieves significant improvements in crown detection accuracy. Compared to traditional single-spectral detection methods, multispectral data provide richer information, enabling the model to more precisely identify crown contours and boundaries. This is particularly advantageous in scenarios with low contrast between the crown and background or complex crown morphologies, where the introduction of multispectral data substantially enhances detection accuracy and robustness. We noticed that during the process of crown extraction, there are differences in the shape, size, and color of the crown across different spectra. Therefore, the improved Dual-YOLO model fully utilizes differential information by fusing the features of infrared and visible light images.
The attention fusion module and fusion shuffle module effectively reduce redundant feature information, thereby improving both the efficiency and accuracy of feature extraction. Moreover, the incorporation of the Inception and SE modules further enhances the representational capacity of the model, allowing it to better adapt to complex and diverse crown shapes and background environments.
To address the limitations of traditional methods in complex scenes, the proposed D-SimSPPF module integrates depthwise separable convolution, which enhances the ability of the model to capture image details and improves its adaptability to complex scenarios.
Additionally, to more accurately represent the gap between predicted and actual bounding boxes and to enhance the optimization efficiency and accuracy of the target detection network, the CIoU-C loss function was proposed. This loss function accounts for the overlap area between predicted and actual bounding boxes, the distance between their center points, and the shape parameters. By incorporating these factors, the model can more comprehensively optimize prediction results during training. Experimental findings confirm that the CIoU-C loss function significantly improves both the accuracy and convergence speed of crown extraction in UAV aerial images.
Finally, considering that traditional models exhibit high computational complexity and are often unsuitable for deployment on platforms with limited computational resources, this study employs a channel-pruning strategy to compress the enhanced model. This approach further simplifies the network structure, ensuring that the model remains lightweight while maintaining high detection accuracy.
However, although the model performs well in most scenarios, it still has the following limitations:
Limited adaptability in dense and overlapping crown scenarios: Experimental results indicate that when crown density is high or significant overlap exists between adjacent crowns, the segmentation boundaries of the model become blurred due to feature confusion, occasionally resulting in missed or false detections. This limitation is primarily due to the weakened crown edge information in densely populated areas and the inherent spatial resolution constraints of multispectral data. Performance fluctuations under extreme lighting conditions: Although the model enhances robustness to lighting variations by integrating infrared spectra, the dynamic range compression of visible images under extreme lighting conditions can result in texture detail loss, thereby affecting detection accuracy. For example, the accuracy of cloudy scenes in the test set is lower than that observed under uniform lighting conditions. Dependence on data diversity: The generalization ability of the model largely depends on the diversity of training data. When applied to novel tree species or heterogeneous vegetation types (e.g. mixed coniferous and broad-leaved forests) that are absent from the training data, the feature fusion strategy may require reconfiguration; otherwise, performance may degrade due to differences in spectral responses.
In future research, we aim to optimize the model through the following strategies: introducing a dynamic multi-scale attention mechanism to enhance the capacity of the model to focus on local features in dense crown scenarios; integrating time-series multispectral data to incorporate seasonal change information, thereby improving adaptability to varying lighting conditions, and exploring a cross-species transfer learning framework to reduce the reliance of the model on specific data distributions.
Conclusion
The existing crown extraction methods exhibit limited adaptability to complex backgrounds, often resulting in false detections, missed detections, and increased model complexity when processing multispectral images. In this study, an improved dual YOLOV7-based crown extraction method utilizing UAV multispectral data is proposed. To address the issue of missed and false detections caused by the weak discriminative power of single spectral information, a dual-feature extraction channel is designed. This approach simultaneously processes infrared and visible images, leveraging the complementary advantages of different spectral information and enhancing target detection capability. To improve crown extraction performance in complex environments, the D-SimSPPF module is introduced to replace the traditional SPPCSPC module. This module incorporates depthwise separable convolution, which more effectively captures image details and enhances model adaptability to challenging scenes. Furthermore, a novel bounding box regression loss function, CIOU-C loss, is proposed to mitigate deviation issues in bounding box regression, thereby improving final detection accuracy, particularly for small targets. In addition, channel pruning technology is applied to compress the enhanced model, making it more suitable for deployment on UAV platforms with limited computational resources.
Experimental results demonstrate that the improved Dual-YOLO algorithm exhibits superior performance in crown extraction tasks, achieving high detection and segmentation accuracy compared with similar approaches. Moreover, the model is better suited for UAV deployment. In conclusion, the proposed dual YOLOv7-based crown extraction method utilizing UAV multispectral data offers significant advantages and broad application potential. Future research will focus on further optimizing the algorithm to enhance detection speed and accuracy, as well as exploring its potential applications in other domains.
Footnotes
Acknowledgements
The authors would like to express appreciation to the anonymous referees and the editor for their helpful comments.
Author Contributions
Conceptualization, P.S.; methodology, H.X. and P.S.; software, H.X.; validation, P.S.; formal analysis, T.L.; investigation, K.M.; resources, H.X. and Y.L.; data curation, T.L. and Y.L.; writing—original draft preparation, P.S.; writing—review and editing, H.X.; visualization, H.X. and K.M.; supervision, W.L. and H.C.; project administration, W.L. and G.W.; funding acquisition, W.L. All authors have read and agreed to this version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the The Natural Science Foundation of China, The Central Government Guides Local Funds for Science and Technology Development, (grant number No. 52305002, No. 236Z7201G).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data presented in this study are available on request from the corresponding author.