
Abstract
Background
Monkeypox (mpox) is a zoonotic infectious disease caused by the mpox virus and characterized by painful body lesions, fever, headaches, and exhaustion. Since the report of the first human case of mpox in Africa, there have been multiple outbreaks, even in nonendemic regions of the world. The emergence and re-emergence of mpox highlight the critical need for early detection, which has spurred research into applying deep learning to improve diagnostic capabilities.
Objective
This research aims to develop a robust hybrid long short-term memory (LSTM)-convolutional neural network (CNN) model with a Convolutional Block Attention Module (CBAM) to provide a potential tool for the early detection of mpox.
Methods
A hybrid LSTM-CNN multi-stream deep learning model with CBAM was developed and trained using the Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0). We employed LSTM layers for preliminary feature extraction, CNN layers for further feature extraction, and CBAM for feature conditioning. The model was evaluated with standard metrics, and gradient-weighted class activation maps (Grad-CAM) and local interpretable model-agnostic explanations (LIME) were used for interpretability.
Results
The model achieved an F1-score, recall, and precision of 94%, an area under the curve of 95.04%, and an accuracy of 94%, demonstrating competitive performance compared to the state-of-the-art models. This robust performance highlights the reliability of our model. LIME and Grad-CAM offered insights into the model's decision-making process.
Conclusion
The hybrid LSTM-CNN multi-stream deep learning model with CBAM successfully detects mpox, providing a promising early detection tool that can be integrated into web and mobile platforms for convenient and widespread use.
Keywords
Introduction
Monkeypox (Mpox) is a zoonotic illness caused by the mpox virus, an Orthopoxvirus. 1 It is believed to be primarily transmitted to humans through contact with contaminated surfaces and infected animals, though human-to-human transmission is also possible primarily through direct contact with body fluids.2,3 Mpox was first discovered in 1958 when outbreaks occurred in monkeys kept for research purposes. 4 However, the first human case of the mpox disease was not detected until 1970 in the Democratic Republic of Congo. Since then, sporadic cases of mpox have been reported in humans, primarily in Central and West Africa, and the number of cases has steadily increased.5–9
In recent years, the concerning increase in the number of cases worldwide, especially in Africa, has been headlined by three outbreaks: the 2017 outbreak in Nigeria, the 2022 outbreak that spread beyond endemic regions, and the 2024 outbreak that has spread through Africa.10–12 The Nigerian outbreak was the first in the country, with 228 suspected cases (60 confirmed cases) reported in 24 out of the 36 states of the country. 13 The 2022 outbreak was even bigger and saw an unprecedented spread beyond endemic regions, affecting numerous countries across multiple continents beyond the traditional boundaries in Africa. The disease's ability to spread to non-endemic regions highlights the interconnectedness of our global community. According to the World Health Organization (WHO), 88,000 confirmed cases were reported globally, marking one of the most significant resurgences of the disease. Consequently, the WHO declared that mpox had become a Public Health Emergency of International Concern.14,15 The WHO reinstated the PHEIC status of the disease after it was dropped in 2023 when the 2022 outbreak died down. This was because of the 2024 outbreak, which has resulted in 3910 confirmed cases across Africa since January 2024. It was put under active monitoring with fear of its potential to spread across the world like the 2022 outbreak.12,16,17
The WHO continues to reiterate that effective treatment and management strategies are crucial in mitigating the impact of mpox outbreaks. 16 One of the challenges in controlling mpox outbreaks is the difficulty in diagnosing the virus. Mpox presents symptoms similar to other viral infections, such as fever, headache, muscle ache, and rash. This can make it challenging for healthcare providers to accurately diagnose mpox, especially in regions where the virus is not commonly seen. Owing to the similarities in symptoms of smallpox and mpox, laboratory diagnostics using polymerase chain reaction tests on collected lesion samples to detect the mpox virus have become the gold standard testing regime for mpox. 18 However, in Africa, where most disease cases have been reported, many health facilities in the endemic areas are under-resourced and unable to conduct the necessary lab testing. So, in the case of an outbreak, the spread in such communities could be grievous. Therefore, cheap, precise, and rapid diagnosis is needed to combat an outbreak. To address this challenge, researchers are developing rapid diagnostic techniques to quickly and accurately identify mpox infections. These tests would allow for early detection of the virus, which is crucial for implementing appropriate control measures and preventing further spread of the disease.
Artificial intelligence (AI) systems have emerged as powerful tools that aid in diagnosing diseases. A number of studies on mpox have investigated different deep learning architectures and enhanced models optimized for the early detection of mpox. Due to the unavailability of a large mpox training dataset, many of these studies have opted to use pretrained deep learning models.
Over the years, this research has moved from studies that simply compared and assessed the feasibility of convolutional neural networks (CNNs) to actively augmenting them with various techniques to make them better suited for mpox skin lesion detection. For instance, Pramanik et al. 19 combined predictions from multiple models to address class imbalance, a common challenge in image classification tasks. The group utilized a Beta function-based normalization scheme to assign appropriate weights to positive and negative classes during the ensemble process. This technique is particularly relevant when the dataset contains a significant imbalance between classes, such as in mpox detection, where there are usually fewer images of mpox lesions compared to healthy skin. The developed model was evaluated on a publicly available dataset using a fivefold cross-validation setup, achieving an average accuracy, precision, recall, and F1-score of 93.39%, 88.91%, 96.78%, and 92.35%, respectively. Another research group chose to augment the best-performing model in their study, which was InceptionV3. They added extra layers to the CNN, creating a new model called PoxNet22, which had an accuracy, precision, and recall of 100%. 20
Research into augmenting CNN models to be better suited to mpox skin lesion detection has brought about more accurate and better-generalized models. Our research introduces a novel hybrid deep learning approach by integrating a long short-term memory (LSTM)-CNN model with a Convolutional Block Attention Mechanism (CBAM). The LSTM component enables learning over long-term dependencies, enhancing feature extraction, while CBAM enhances feature extraction by selectively emphasizing informative regions in the input data, improving model focus during classification. Additionally, we employed local interpretable model-agnostic explanation (LIME) and heatmap to decrypt the hybrid model for model explainability and interpretability. The model was trained on the Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0) dataset and evaluated using standard metrics such as F1-score, accuracy, recall, and area under the curve (AUC) to properly report the performance of our proposed model. The AUC metric reflects the model's ability to discriminate between two classes, especially in imbalanced classes. AUC provides a more comprehensive evaluation than metrics like accuracy, which can be misleading in cases of class imbalance.
The major contributions of this study are as follows:
Design and implementation of an LSTM-CNN model with CBAM to enhance feature extraction and address class imbalance. Use of LIME and heatmaps to decrypt the hybrid model for model explainability and interpretability. Evaluation of the model against existing deep learning approaches using standard metrics such as F1-score, accuracy, recall, and AUC on the Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0).
By balancing interpretability, performance, and computational efficiency, our approach provides a promising alternative for early mpox detection, particularly in resource-constrained environments. This study contributes to the ongoing efforts to develop AI-driven diagnostic solutions for infectious diseases.
Paper organization
The paper is structured into five sections. Introduction is an introduction to the study, Literature review is a review of existing work, Methodology is the methodology of the study, Results presents the results of the study, Discussion is a discussion of the results, and Conclusion is a summary of the study and recommendations for future work.
Literature review
This section reviews literature that focuses on algorithm augmentation for CNN model enhancement in Mpox skin lesion detection. We took into consideration their results and methodologies when conducting this literature review.
Research groups augmenting CNNs have also integrated more advanced methods. By employing the Grey Wolf Optimizer (GWO) to enhance a CNN model, Eliwa et al. 21 achieved substantial improvements in accuracy, precision, recall, F1-score, and AUC. The optimized model's accuracy of 95.3%, which was a highlight of the work, showed that the GWO-enhanced CNN model was effective in differentiating between positive and negative cases. Haque et al. 22 integrated a convolutional attention block module (CBAM) mechanism into transfer learning-based models to highlight important regions and features in the images by focusing on spatial and channel-wise attention maps to improve the model's performance. Essentially, the group implemented five pretrained deep learning models (VGG19, Xception, DenseNet121, EfficientNetB3, and MobileNetV2) along with integrated channel and spatial attention mechanisms. With a validation accuracy of 83.89%, the Xception model – which incorporates a spatial attention mechanism and an integrated channel – performed better than the other models in detecting mpox. Similarly, Uysal et al. 23 created a hybrid AI system combining the two high-performing deep learning models, RepVGG-B0 and MnasNet-100, with a LSTM model. This system, trained on a multi-class dataset including mpox, achieved a test accuracy of 87% and a Cohen's kappa score of 0.8222.
Arshed et al. 24 moved away from CNNs and applied a patch-based vision transformer (ViT) model to differentiate between mpox and chickenpox using skin colour images. By leveraging transfer learning, the ViT model attained the same value of accuracy, precision, recall, and F1-score of 93%. The researchers also augmented a limited data set to enhance the model's generalizability and robustness. This study shows that advanced techniques like ViTs can be promising tools for mpox detection. Augmenting CNNs with other advanced methods is also seen in custom-designed models for mpox diagnosis. Demir et al. 25 proposed an automated mpox detection model using a new dataset with 910 images classified into five categories: healthy, mpox, chickenpox, smallpox, and zoster zona. With deep feature-engineered architecture, the model included nested patch division, feature extraction, feature selection, and classification using a support vector machine. The model's classification accuracy was 91.87%, sufficiently high to be considered for practical use. One group of researchers decided to look at how six CNNs and a ViT performed when augmentation was done specifically to reduce the risk of overfitting presented with such a small dataset. Ahsan et al., 26 with their methodology of combining transfer learning and algorithm augmentation, produced two algorithms with extremely high accuracies in their augmented MobileNetV2 and InceptionResNetV2 models. These reported F1-scores of 0.99 and 0.98, respectively. However, the ViT did not perform well in their research, with an F1 score of 0.87.
The literature revealed two patterns that stood out as points of concern. First is the reliance on pretrained models for early detection of mpox. Such models are often a practical response to the lack of large, high-quality mpox datasets. Utilizing pretrained models enhances the ability to generalize features pertinent to mpox detection. However, the typically large size and the vast number of trainable parameters can be a significant hurdle when deploying them in resource-limited environments. Secondly, there is a noticeable pattern in how model evaluation is conducted in these studies. While accuracy, F1-score, recall, and precision are frequently highlighted, there is an over-reliance on these metrics, particularly accuracy, as the primary performance indicator. This focus on accuracy, while helpful, often paints an incomplete picture, especially in scenarios where datasets are imbalanced. In such cases, accuracy alone can be misleading, giving a false sense of model efficacy while overlooking how well the model handles minority classes. The solution is adopting more robust evaluation metrics that comprehensively assess a model's ability to manage imbalanced data. Table 1 provides a summary of the related works.
Summary of related works: a summary of recent studies utilizing various deep learning models and enhancements for monkeypox classification. The table presents the model/approach, enhancements applied, dataset characteristics, and performance metrics.
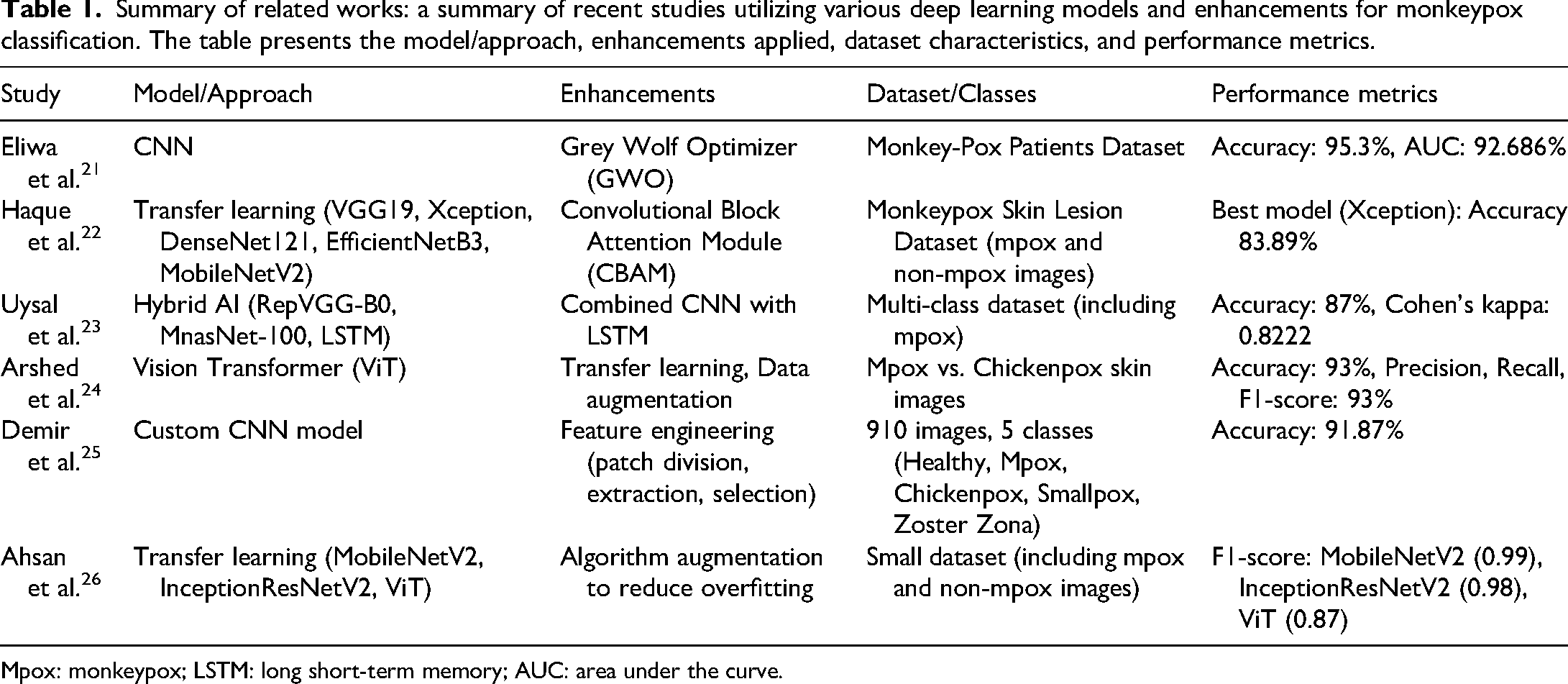
Mpox: monkeypox; LSTM: long short-term memory; AUC: area under the curve.
Methodology
This project focused on the development of a Hybrid LSTM-CNN multi-stream deep learning model with CBAM for Mpox detection. The model integrates batch normalization and reshaping for data pre-processing, LSTM blocks for preliminary feature extraction, and a residual network and convolutional block for further feature extraction. A convolutional attention mechanism (CBAM) enhances feature representation, followed by a classification block. The model was fine-tuned using Keras Tuner, with validation loss monitored to get the best performance on the Mpox dataset MSLD v2.0 from Kaggle. This work was conducted at Kwame Nkrumah University of Science and Technology, Ghana, from April to September 2024.
Overall model system flow
The system flow of the model is illustrated in Figure 1. The human mpox skin lesion image data was acquired and prepared by splitting the dataset into training, testing, and validation sets. Image pre-processing methods were applied to these images to ready the data for the model. These pre-processing techniques influence the performance of the deep neural network model. The hybrid LSTM-CNN multi-stream deep learning model with CBAM architecture was then defined and tuned using the training and validation sets to achieve optimal parameters. The model's performance was evaluated with a separate test set, utilizing metrics such as accuracy, F1-score, recall, precision, and the AUC to assess the efficacy of the hybrid LSTM-CNN multi-stream deep learning model with CBAM.

System flow diagram.
Dataset collection and statistics
The original dataset was taken from the Kaggle website,27,28 which was partitioned into mpox, normal, measles, cowpox, chicken pox, and hand, foot, and mouth disease (HFMD) as seen in Figure 2, but for this project, the normal, measles, cowpox, chicken pox, and HFMD datasets were combined to form the non-mpox category. The original dataset available on the Kaggle platform comprises images obtained from mpox outbreaks across Africa, Europe, and Asia, sourced from publicly accessible case reports, news portals, and reputable websites. A dermatologist verified the authenticity of these images. The data collection process was approved by the Ethical Review Committee of Popular Medical College (Ref: PMC/Ethicalrc/2023/02). For the MSLD v2.0 dataset, all images were resized to 224 × 224 pixels and subjected to standard augmentation techniques, including rotation, translation, reflection, shear, hue adjustment, saturation modification, contrast enhancement, brightness jittering, noise addition, and scaling. Additionally, colour augmentation was applied to enhance the dataset's generalizability and mitigate potential racial biases.
Accordingly, the dataset was grouped into two, namely, mpox and non-mpox. The dataset had different subfolders, including datasets with and without data augmentation. Images in both the augmented and non-augmented datasets were used in the study. Images in the non-augmented dataset folder were 730, while images in the augmented dataset folder were 7534. Among the total of 8264 augmented and non-augmented images, 8090 were selected for use in the training, validation, and evaluation processes. The remaining 174 images were excluded due to poor quality, such as excessive noise, which could adversely affect model performance.
Of the 8090 images (comprising both augmented and non-augmented), 60% were non-mpox images, while the remaining 40% consisted of mpox images. These images were subsequently combined and divided into training, testing, and validation sets, with 60% (4854 images) allocated for training, 20% (1618 images) for testing, and 20% (1618 images) for validation.

Dataset images (a) measles, (b) HFMD, (c) normal skin, and (d) Mpox, (e) cow pox, (f) chicken pox. Mpox: monkeypox; HFMD: hand, foot, and mouth disease.
Model architecture and tuning
Our proposed model is composed of five sections. First, the pre-processing phase, which includes batch normalization and reshaping functions, prepares the image data for the next phase, the pre-feature extraction phase. The batch normalization function adjusts inputs to have a mean of zero and a standard deviation of one for each mini-batch while also using learnable parameters to allow the network to retain flexibility and improve gradient flow in the network. The reshape function converts the input two-dimensional image data into one-dimensional data before it is fed to the LSTM block in the pre-feature extraction phase. To extract features from two-dimensional images with LSTMs, typically designed for one-dimensional sequential data, the images must first be converted into a sequence of one-dimensional features. This transformation is often achieved by reshaping each 2D image slice into a single feature vector. For example, if the image has two dimensions (height, width), it can be flattened into a one-dimensional vector with height × width features. Reshaping 2D data into 1D enables it to be processed as a series of steps (timesteps), letting the model capture patterns and relationships over time or depth. LSTMs can be leveraged to uncover hidden patterns and dependencies, enhancing the model's ability to extract meaningful information from the sequential data. The pre-feature extraction phase consists of an LSTM block followed by a CNN block. Next, the feature extraction block, which includes residual units and convolutional block, follows the pre-feature extraction phase. The outputs from the residual and convolutional blocks are combined through concatenation for the subsequent phase. The convolutional block attention, consisting of spatial and channel blocks, follows the feature extraction phase and processes the concatenated outputs from the feature extraction block. Finally, the classification block includes a global average pooling layer, flattening, and a SoftMax classifier.
In our proposed model, we leverage the special ability of the LSTM to capture sequential patterns and long-term dependencies to extract spatial features from raw images to be passed to the CNN block to further learn spatial hierarchies and patterns such as edges, textures, and shapes. The output of the LSTM-CNN block is passed to two separate blocks for further extraction (feature extraction phase). This prevents overfitting as different features learned from each block are combined for better model generalization. The two feature extraction blocks improve gradient flow during backpropagation, making training more stable. Other advantages of implementing and concatenating the output of two feature extraction blocks include diverse feature representation and multi-scale feature extraction (as different branches within the block may operate with different scales, i.e. filter sizes
The concatenated output of the two feature extraction blocks is transferred to the CBAM block to focus on only relevant feature channels and informative spatial regions on the feature map. The relevant map is passed on to a global average pooling layer to reduce the dimensionality of the feature maps and also preserve spatial information by computing the average of each feature map. The output of the global average pooling layer is then relayed to the flattening layer to transition to the classification layer by preserving the batch size while reshaping the input tensor. Finally, it is forwarded to the SoftMax classifier layer for classification. Figures 3 and 4 provide insight into the model architecture.

Simple model diagram.

Detailed model diagram.
Model tuning
The optimal hyperparameters and model depth were determined using the Keras hyperparameter tuner. Hyperparameter tuning is essential for enhancing machine learning and deep learning model performance. Properly adjusting hyperparameters, such as model depth, dropout rate, and activation functions, ensures optimal model performance and data generalization. 29 Model characteristics like complexity and optimization strategies were fine-tuned to avoid issues like the vanishing gradient and overfitting and to enhance model learning. Optimizers are algorithms that modify the neural network's parameters, such as weights and learning rates, to help lower overall loss and increase accuracy.30,31 The best optimizer was selected among other optimization strategies based on the strengths and suitability of our proposed model. The complexity of the model, defined by the number of layers and filter units, was carefully chosen to prevent overfitting and ensure effective learning.32–34 The tuning process, which used the Keras Hyperband algorithm along with early stopping and learning rate reduction callbacks, was performed over 20 epochs on the entire training and validation set. The best model was then selected and evaluated on the test set (Table 2).
Selected hyperparameters for the proposed model: optimal hyperparameter values were chosen for the proposed hybrid LSTM-CNN model after experimentation and tuning. These parameters were selected based on their impact on model performance and generalization ability.

CNN: convolutional neural network; LSTM: long short-term memory.
Evaluation metrics
Recall, precision, F1-score, and accuracy are the most widely used performance metrics to compare between models. In this study, we used these performance evaluation metrics to assess the performance of the proposed mode against other existing models. AUC was also used to provide insight into the model's ability to distinguish between the two imbalanced classes. Recall, precision, F1-score, accuracy, and AUC are all concepts related to true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN) in the predictions of the model. These evaluation parameters were computed using equations (1) to (4).
The F1-score is used against the trade-off between recall and precision metrics.



Explainability and interpretability
Model explainability and interpretability aim to help humans understand the decision-making process of an AI model, thereby establishing trust and transparency in the model operations. Whereas deep learning models in image classification make predictions based on learned features (pixels) relevant for the classification of the image, model explainability and interpretability techniques visualize these relevant features learned by the model for prediction to provide insight into how the model arrived at its decision. The most commonly used AI explainability techniques are the gradient-weighted class activation map (Grad-CAM) and LIME.35–38
The apparent ‘black box’ nature of deep neural networks makes it difficult to use them in vital applications like health sector diagnoses because practitioners may not understand the underlying processes that generate predictions. To assist people in comprehending the deep neural network's judgments, model explainability attempts to open up the ‘black box’. Since deep neural networks may be biased, model explainability is essential to building transparency and confidence in these systems. Verifiable safety and dependability techniques are necessary for deep neural network solutions to be accepted in industries like healthcare. The model explainability and interpretability techniques used in this study are LIME and Grad-CAM.
Results
As mentioned earlier, the proposed model is a hybrid LSTM-CNN multi-stream deep learning model with CBAM incorporated. The model was trained and evaluated on a mpox test dataset comprising 1618 images. Evaluation metrics were used to evaluate the performance of the proposed model. First, we used a confusion matrix to examine how well the proposed model performed across the different classes. The model's performance across the various classes is displayed in Figure 5.

Confusion matrix.
The dataset contained more non-mpox images than mpox images due to the combination of images from various categories into one non-mpox category. This imbalance contributed to our model's marginally better performance on non-mpox images compared to mpox images. In the test dataset, there were 646 mpox images, of which the model correctly identified 604 and misclassified 42, resulting in a 6.50% error rate for mpox images. Additionally, there were 972 non-mpox images in the test set, with the model correctly identifying 935 and incorrectly classifying 37, leading to a 3.80% error rate for non-mpox images. Despite the dataset imbalance, the model demonstrated strong performance across both categories, with a slightly higher error rate for mpox images by 2.70% compared to non-mpox images. The model achieved an overall accuracy of approximately 95% on the test set, comparable to existing mpox diagnosis models.
However, evaluating the performance of our proposed model requires considering more than just accuracy. Table 3 also provides metrics such as the average F1-score, recall, precision, AUC, and accuracy.
Performance metrics of our proposed model: evaluation metrics of our proposed model, including F1-score, recall, precision, AUC, and accuracy. The high values across all metrics indicate the model's robustness in distinguishing between mpox and non-mpox cases.

Mpox: monkeypox; AUC: area under the curve.
In this study, the LIME and Grad-CAM technique were used to interpret the decision-making of our proposed model. Figure 6 depicts the results of Lime with regard to our proposed model's decision; the green area in subfigure (b) and clear area in subfigure (c) indicate areas relevant to the model's decision-making process in predicting Mpox and non-Mpox images.
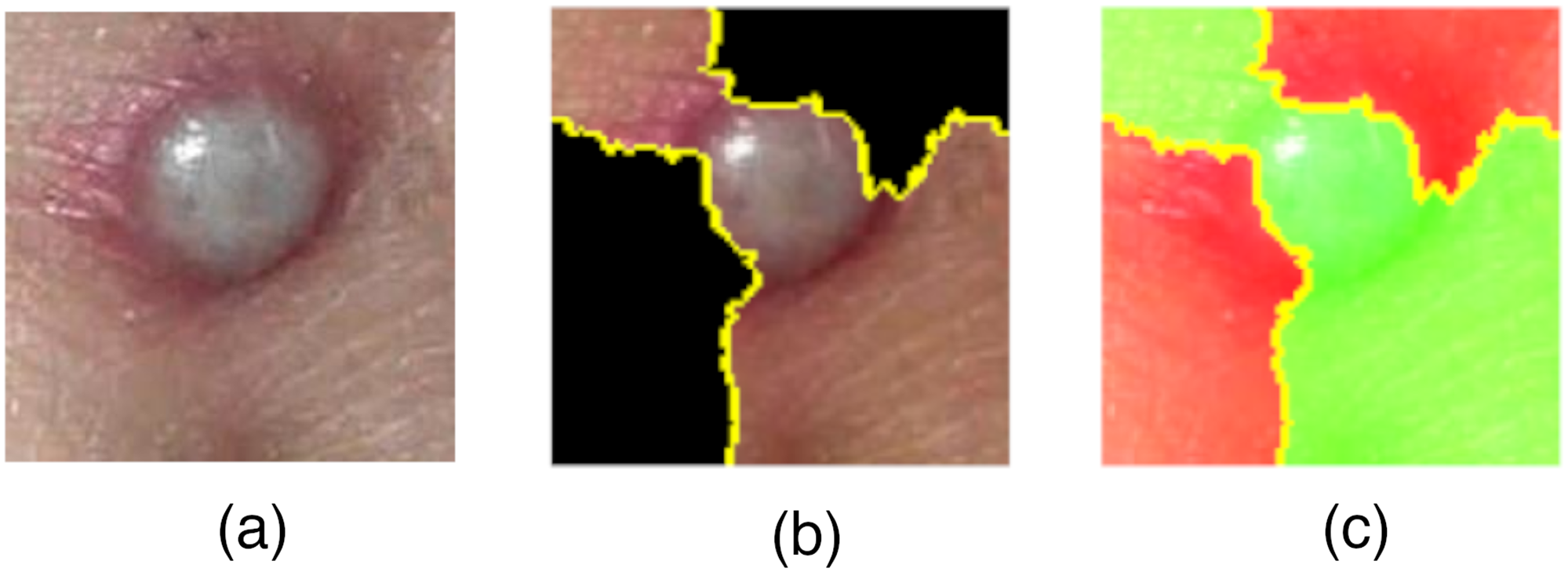
Mpox images. (a) Normal image, (b) and (c) LIME images. Mpox: monkeypox; LIME: local interpretable model-agnostic explanations.
Heatmaps were also generated using the Grad-CAM technique. In Figure 7, subfigure (b) indicates a higher activation intensity at the centre of the image where the lesion-like structure is present. The surrounding gradient of colours, particularly the red and yellow hues, indicates strong feature importance, while the blue and green regions represent lower activation areas.

Cow pox image. (a) Normal image, and (b) heatmap images.
Discussion
The results in Table 2 demonstrate the strong performance of the proposed model across all metrics despite being evaluated on an imbalanced dataset. The high F1-score, recall, and precision indicate a well-balanced classification, while the AUC of 0.9504 confirms robust discriminatory power. The accuracy of 94.84% further highlights the model's effectiveness. This strong performance is attributed to the model's well-structured architecture, which integrates feature extraction, attention, and classification to mitigate class imbalance. Batch normalization before reshaping stabilizes input distributions, ensuring that the LSTM-CNN pre-feature extraction layer receives well-scaled inputs. The LSTM component captures long-range dependencies, preserving minority class features, while CNNs extract localized patterns, preventing dominance by majority class features. Their combination produces diverse feature maps, enhancing class differentiation. The multi-stream feature extraction layer, consisting of residual and convolutional blocks, further diversifies learned representations. Feature concatenation prevents reliance on a single pathway, ensuring a more balanced learning process. The CBAM attention mechanism refines feature maps by emphasizing relevant spatial and channel-wise information, reducing bias toward majority class features and enhancing the representation of minority class patterns. This refined feature selection improves decision boundary clarity, ultimately contributing to the model's strong and balanced classification performance.
The performance of our proposed model was compared to existing pretrained models employed in other studies for mpox detection, CBAM-enhanced models for mpox detection, and other state-of-the-art models from various studies on the early detection of mpox. The variation in reported metrics arises from differences in study methodologies. Some studies emphasized accuracy as their primary performance measure, while others focused on F1-score, recall, or precision to assess model reliability in handling class imbalances. The inclusion of AUC in some tables but not others reflects whether studies explicitly evaluated model performance on imbalanced datasets. Our interpretation of the results has considered these differences to ensure a fair and meaningful comparison.
Table 4 compares our proposed model against various pretrained deep learning architectures trained on the same dataset. Our proposed model achieves an accuracy of 94.84%, with an F1-score, recall, and precision of 94.00%, and an AUC of 95.04%. This performance surpasses several state-of-the-art models, including InceptionResNetV2, 35 VGG16, 35 ResNet152V2, 35 and Xception. 35 While ResNet50V2 39 (98.74%) and DenseNet201 35 (97.63%) report higher accuracy, their respective F1-scores (99.00% and 90.51%) suggest potential overfitting to the majority class. Accuracy alone is insufficient for evaluating models trained on imbalanced datasets, as it may obscure poor performance in minority class predictions. The discrepancy between DenseNet201's high accuracy (97.63%) and its lower F1-score (90.51%) indicates challenges in effectively classifying minority class samples. Similarly, the near-perfect F1-score of ResNet50V2 39 (99.00%) raises concerns about overconfidence in predictions, especially with an imbalanced balanced dataset such as the MSLD v2.0. This could mean it has learned biases toward dominant class features, potentially which may limit its generalization in real-world applications. Unlike these models, our proposed architecture integrates an LSTM-CNN pre-feature extraction layer, effectively capturing both long-range dependencies and spatial features. This mitigates the dominance of majority class patterns and contributes to a more balanced classification. Additionally, the multi-stream feature extraction layer, combining residual and convolutional blocks, ensures diverse feature representations, reducing reliance on any single pathway. The incorporation of the CBAM attention mechanism enhances feature discrimination by prioritizing the most relevant spatial and channel-wise features, leading to improved recall and precision (both at 94.00%). Compared to MobileNetV2 39 (94.52% accuracy, 94.00 F1-score) and Xception 39 (95.46% accuracy, 95.00 F1-score), our proposed model demonstrates comparable accuracy while providing a more comprehensive evaluation across key metrics. Notably, MobileNetV2 39 and Xception 39 did not report recall, precision, or AUC, limiting their interpretability in terms of robustness and generalization. While Xception achieves a slightly higher accuracy (95.46%), the absence of key evaluation metrics raises concerns about its ability to maintain balanced classification. Our proposed model, by contrast, provides a complete assessment, achieving an AUC of 95.04%, which underscores its strong discriminatory power in distinguishing between classes. These results highlight the advantages of our proposed architecture in achieving balanced classification without excessive reliance on extensive pretraining, making it a robust and suitable model for real-world applications.

AUC: area under the curve.
Table 5 compares the performance of our proposed model with CBAM-enhanced deep learning architectures from previous studies. Our proposed model achieves an accuracy of 94.84%, outperforming all other CBAM-based models, including Xception-CBAM-Dense (83.89%) and EfficientNetB3-CBAM-Dense (81.43%). Notably, while Xception-CBAM-Dense reports a high precision (90.70%) and recall (89.10%), our proposed model achieves a more balanced performance across all key metrics, with precision and recall both at 94.00%, resulting in a consistently high F1-score (94.00%). These results demonstrate the advantages of our proposed model's architecture, which integrates an LSTM-CNN pre-feature extraction layer, a multi-stream feature extraction block, and CBAM for adaptive feature refinement. Unlike other CBAM-based models that primarily rely on convolutional feature extraction, our proposed model leverages the sequential learning capability of LSTMs alongside CNNs, capturing both spatial and long-range dependencies effectively. This enhances its ability to maintain high recall without sacrificing precision, ensuring robust classification performance. The superior F1-score and accuracy highlight the model's effectiveness in handling complex feature representations while mitigating potential overfitting to dominant class patterns.
Performance comparison of our proposed model with other CBAM-based models: comparison of our proposed model's performance with CBAM-enhanced deep learning models implemented in other studies. 40

CBAM: Convolutional Block Attention Module; AUC: area under the curve.
Table 6 provides a comparative analysis of the proposed model against state-of-the-art approaches for mpox detection. The proposed model achieves an accuracy of 94.84%, with precision, recall, and F1-score consistently at 94.00%. This positions it among the top-performing models while offering a comprehensive evaluation through an AUC of 95.04%, a metric absent in several prior studies. Although Kundu et al. 41 (97.90%) and Yadav and Qidwai 42 (97.41%) report marginally higher accuracy, their models rely on computationally intensive architectures, which may limit practical deployment in resource-constrained environments. In contrast, the proposed model balances high classification performance with computational efficiency, making it a viable option for real-world applications requiring both accuracy and resource-conscious implementation. Kundu et al. 41 achieved an accuracy of 97.90% by employing a flower-federated learning environment with ViT-B32, which enhances data security by training models across multiple clients without directly sharing data. However, federated learning introduces high computational and communication overhead, requiring significant synchronization across training nodes, which may lead to delays and inefficiencies. By comparison, the proposed model is trained in a centralized setting, where all data is processed on a single server. This eliminates synchronization challenges, reduces computational complexity, and ensures more stable training. While Kundu et al.'s federated approach enhances security, the proposed model achieves competitive accuracy while reducing computational costs, making it more suitable for settings where computational resources are limited. Similarly, Yadav and Qidwai's model, which attained a slightly higher accuracy of 97.41%, employs a multi-stage pipeline involving ResNet50 and Zero Phase Component Analysis for feature extraction, principal component analysis for feature fusion, and a modified Extreme Gradient Boosting (MXGBoost) classifier optimized with a statistical loss function. While this methodology yields strong performance (F1-score: 97.00, precision: 97.00, recall: 98.00), it introduces additional computational overhead due to multiple processing steps. In contrast, the proposed model achieves balanced classification metrics with reduced complexity, making it a more efficient alternative for real-world deployment. Despite slight differences in accuracy, the proposed model demonstrates a strong balance between computational efficiency and classification performance, making it particularly well-suited for resource-limited settings where high-performance models must operate within practical constraints.

AUC: area under the curve.
Explainability and interpretability
We employed LIME to assess the explainability of our proposed model in this study. LIME envelops potentially infected regions. The infected regions are depicted in Figure 8 in the green and clear areas in the image. This indicates that our proposed model can recognize areas important for classifying the images into mpox and non-mpox. To explain individual predictions of our proposed model, the local interpretable model-agnostic approach creates a simple local interpretable model that approximates our proposed model's behaviour specifically for the small neighbourhood around the input of interest, making it easier to understand why our proposed model made a particular prediction.46–48

Model decision-making described by LIME. LIME: local interpretable model-agnostic explanations.
The red and yellow regions in Figure 9 highlight the areas that significantly influenced the decision-making process of the proposed model. The red regions represent the most influential areas, while the yellow regions indicate moderately influential areas related to the model's decision. This demonstrates the model's ability to identify regions associated with mpox and other skin lesion diseases. The heatmap was generated by passing an image that depicted either mpox or non-mpox conditions through our proposed classification model. Feature maps were extracted from the model's last convolutional layer, and gradients of the output score with respect to these feature maps were computed. The gradients were then subjected to global average pooling to compute weights. These weights were multiplied with the corresponding feature maps and summed, followed by applying the ReLU activation function to produce heatmaps. Finally, the heatmaps were overlaid on the original image, highlighting the critical regions.

Heatmaps of model decision.
The heatmap in Figure 10, subfigure (b), highlights a limitation of the proposed model in distinguishing between mpox and non-mpox images, contributing to its overall accuracy of 94.84%. Despite its robust and balanced performance, the visualization indicates that the model struggles to fully differentiate certain overlapping visual characteristics between mpox and non-mpox lesions. This suggests that further refinements in the feature extraction process may enhance its discriminatory ability. Nevertheless, the strong overall performance of the proposed model supports its potential as a complementary tool for the early detection of mpox, aiding clinical decision-making.

Heatmaps of model decision. (a) Normal image and (b) heatmap.
Conclusion
In this paper, we implemented a hybrid LSTM-CNN multi-stream deep learning model with CBAM incorporated. The performance of the designed model with other pre-existing known models was compared using well-established evaluation metrics. The evaluation results show that the performance of our proposed model is competitive, and it is more accurate and reliable in identifying relevant instances, making it a highly robust solution for the early detection of mpox disease. Comparing our proposed model with pretrained models implemented in mpox detection and other proposed models from other studies demonstrated how highly competitive our proposed model is. Our proposed model outperformed most existing models with an accuracy of 94.84%, F1-score of 94.00%, precision of 94.00%, recall of 94.00%, and an AUC of 95%. Only a few models slightly surpassed the performance of our proposed model on certain performance evaluation metrics. Our proposed model demonstrates a reliable balance between precision and recall, effectively minimizing false positives and negatives, making it an excellent choice for the early detection of mpox disease. Even with some data gaps in other models, the comprehensive metrics underscore the robust performance of our proposed model compared to alternative solutions.
To bolster the credibility of our proposed model, we employed the LIME and Grad-CAM explainability techniques to interpret and visualize its decision-making process. This further enhances the trust and acceptability of our proposed model within the health sector. Our proposed model's results suggest a promising early detection tool for mpox that can be integrated into various platforms, including web and mobile applications, for convenient and widespread use.
In our future work, we plan to validate the performance of our proposed model on different clinical images to demonstrate its generalizability. We also plan to explore our proposed model architecture by further enhancing the feature extraction process and training it on a larger dataset.
Footnotes
Guarantor
Isaac Acquah is the guarantor.
Ethical considerations
The dataset used in this research was obtained from a publicly available dataset from Kaggle. This dataset had been ethically sourced and verified by expert clinicians. However, ethical approval was obtained from the Committee on Human Research, Publication and Ethics of the Kwame Nkrumah University of Science and Technology, with the approval reference number CHRPE/AP/1228/24.
Consent to participate
Not applicable because no participants were involved.
Consent for publication
Not applicable because no participants were involved.
Author contributions/CRediT
Benjamin Appiah Yeboah, Isaac Acquah, Kojo Sam Micah, and Kofi Ampomah Mensah did conceptualization; Benjamin Appiah Yeboah, and Kojo Sam Micah analysed the methodology; Benjamin Appiah Yeboah, Isaac Acquah, Kojo Sam Micah, and Kofi Ampomah Mensah did formal analysis and investigation; Benjamin Appiah Yeboah, Kojo Sam Micah, and Isaac Acquah wrote the original draft preparation; Isaac Acquah, and Kofi Ampomah Mensah helped in review writing and editing; Isaac Acquah did supervision.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the TensorFlow College Outreach Award, provided by Google Ireland Limited.
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.