
Abstract
Person re-identification technology has made significant progress in recent years with the development of deep learning. However, the recognition rate of models in this field is still lower than that of face recognition, which is challenging to implement in practical application scenarios. Therefore, improving the recognition rate of the pedestrian re-identification model is still a critical task. This paper mainly focuses on three aspects of this problem. The first is to use the characteristics of the multi-branch network structure of person re-identification to dig out the most effective online self-distillation scheme between branches without increasing additional resource requirements, making full use of the information contained in each branch. Secondly, this paper analyzes and verifies the pros and cons of knowledge distillation based on mean squared error (MSE) loss function and Kullback-Leibler (KL) divergence from theoretical and experimental perspectives. Finally, we verified through experiments that adding a specific value of noise perturbation to the model weights can further improve the recognition rate of the model. After several improvements in these areas, we obtained the current state-of-the-art performance on four public datasets for person re-identification.
Introduction
In recent years, with the emergence of vision transformer (ViT), 1 the transformer network structure has also shown explosive development in computer vision after the outstanding achievements in natural language processing. 2 In computer vision research, video surveillance systems consider person re-identification to be a crucial task. Deep learning techniques have significantly enhanced recognition outcomes in this domain.3–10 However, many problems still exist, such as the presence of different viewpoints,11,12 occlusion,13,14 and changes in pedestrian poses.15,16 Several approaches within this field rely on extracting dependable feature representations.17–28 There are also methods based on distance metric learning.29–34
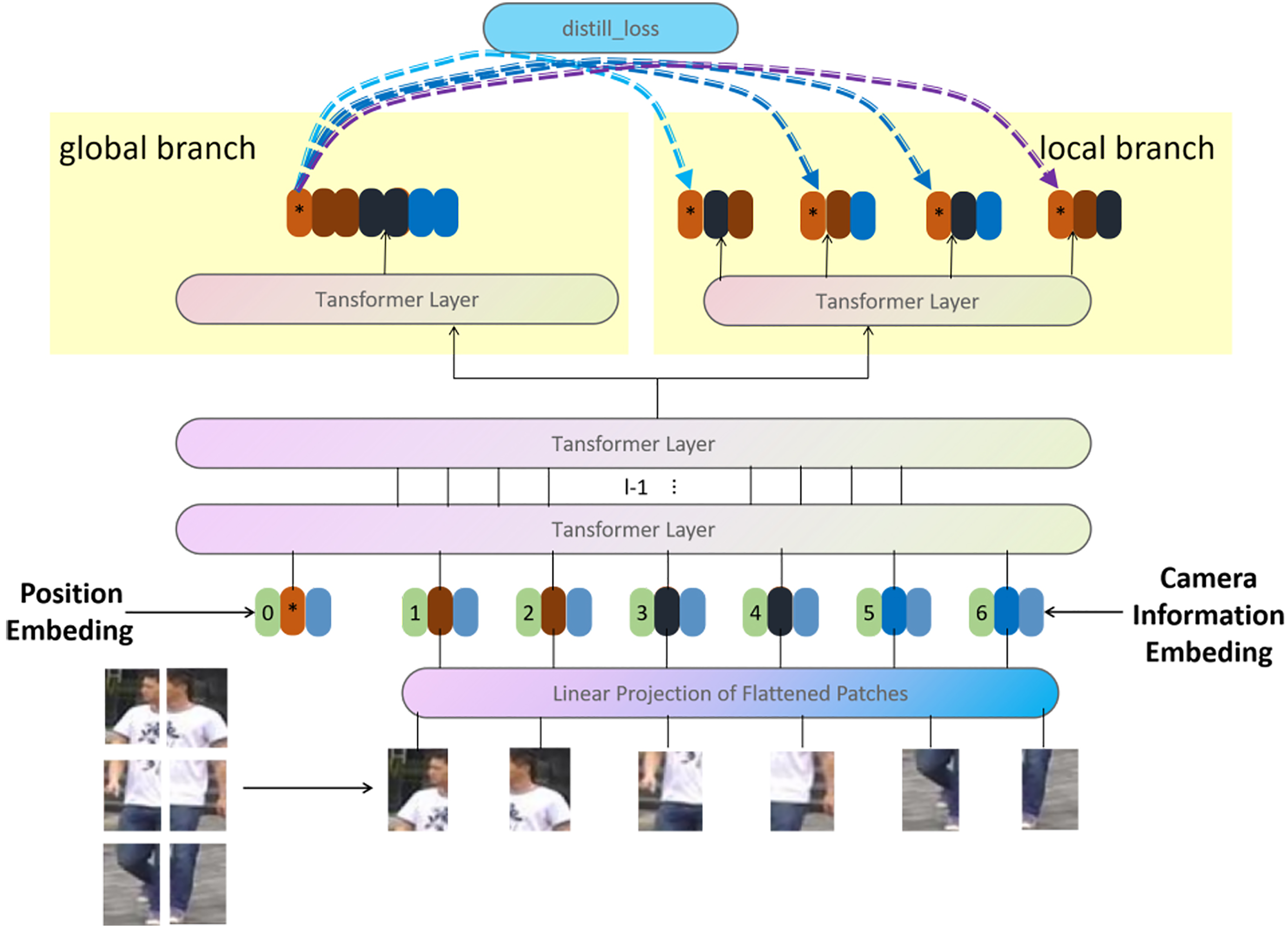
TransReid 35 is the first to use transformers for person re-identification. TransReid has demonstrated strong performance on various publicly available person re-identification datasets. This paper’s primary innovation is the introduction of transformer architecture to pedestrian re-identification by utilizing it for the first time in ViT. 1 The authors also propose the Side Information Embeddings (SIE) and Jigsaw Patch Module (JPM) modules to enhance the re-identification performance. The SIE module mainly sets the corresponding embedded features for different cameras. The JPM module divides the entire image’s patches into different areas for processing. This partition processing scheme is a prevalent practice in pedestrian re-identification. In TransReid, these partitions are turned into embedded features one by one at the beginning and then are extracted separately in the last transformer structure and processed with their loss function.
Therefore, TransReid essentially performs partition processing on pedestrian images. The factual information in the different branches of JPM is the characteristics of different partitions of the human body. All in all, the network structure of TransReid, similar to other early pedestrian re-identification network structures based on convolutional neural network structure, will eventually have several branches, representing the global features and several local features of pedestrian images, respectively. The primary motivation of our paper stems from our belief that in TransReid, the cross-entropy and triplet loss are calculated separately for these branches, but these branches have the same goal: to distinguish pedestrian images with different IDs. Since everyone has the same goal, the power of working together must be greater than the power of individual efforts. Theoretically, if these different branch associations can be effectively integrated, the overall model’s recognition effect can be improved.
Furthermore, the research on knowledge distillation has been highly active in the associated domain of deep learning.36–45 Many knowledge distillation methods have been developed.36–45 For person re-identification network structures with different branch structures with both global branches and local branches, this structure can naturally be used for online knowledge distillation. However, because our structure is different from the parallel branch structures constructed in the literature, 45 our branches are not the same, so it is a question of which one is the teacher and which is the student for distillation learning. This is one of the main issues that our paper aims to address. In addition, among the methods of knowledge distillation, literature 36 is distilled with Kullback-Leibler (KL) divergence, and literature 43 is distilled with an mean squared error (MSE) loss function. Among them, the former needs to set an appropriate temperature parameter, T, which needs to be selected through relevant experiments on the specific dataset and network structure and requires a certain amount of extra work. The latter is more convenient, but literature42 said this method has some defects if used to distill softmax output.
In summary, our contributions can be summarized as follows. Firstly, this paper obtains the most suitable online distillation scheme through extensive experiments based on the TransReid 35 network structure and several public person re-identification datasets. Using this scheme, we can effectively improve this network structure’s recognition effect based on global and local branches without adding additional parameters. Secondly, this paper makes a relevant derivation for this problem and proves that this defect can be avoided if the batch normalization (BN) layer is added before the softmax and relevant experiments are done to verify our inference. Experiments show that when there is a BN layer in front of the softmax, we can use the MSE loss function to distill the output of the softmax to obtain the same effect as the KL divergence distillation of the carefully set temperature parameter T. Thirdly, we suggest monitoring for signs of overfitting in the network and introducing interference noise to the network weights if it occurs, in order to prevent getting stuck in a suboptimal solution. Finally, through our improvement schemes, we obtain the state-of-the-art recognition performance on four public datasets for person re-identification.
Related work
Partitioned pedestrian re-identification
In the research of person re-identification, it is a standard scheme to perform feature extraction after partitioning the human image. In literature 22 , the author proposes a method called Part-based Convolutional Baseline (PCB), which divides the human body image into six regions uniformly horizontally before global pooling and treats each part as a human body part. Next, conduct global pooling to acquire the characteristics of every regional zone. The author proposed a method named Multi-Granularity Network (MGN), 23 which utilizes three parallel branch network architectures to process the feature map of human images after several convolutional layers. The first branch extracts the overall features of the complete image, while the second branch splits the human body image into two regions and extracts the corresponding local features.
Similarly, the third branch splits the human body image into three regions and extracts the local features of each region. In the testing phase, the final feature is obtained by merging the features from the three branches. The author in the literature 24 still partitions pedestrian images, but the network learns the specific partitioning scheme from a specific dataset. A common feature of these schemes is that the final output layer is not a simple output but has several branches simultaneously, representing pedestrian images’ global and local information, respectively.
The transformer-based image recognition method
Convolutional neural networks have dominated almost all computer vision (CV) fields in the past time. At the same time, an algorithm called transformer 2 began to develop rapidly in natural language processing (NLP). Finally, the ViT 1 algorithm was born, and the hurricane of the transformer was blown into the CV field. In just a few years, many algorithms have used the transformer structure to solve problems in the CV field. Literature 46 adopts almost the same network structure as ViT, 1 adding better hyperparameter settings, multiple data augmentation, and knowledge distillation to improve the effectiveness of ViT. Literature 47 proposes a transformer-based end-to-end object detection without non-maximum suppression NMS postprocessing steps, prior knowledge, and constraints such as anchors, and the entire network is implemented end-to-end. The implementation of target detection greatly simplifies the pipeline of target detection. In literature 48 , a feature pyramid transformer (FPT) is proposed to exploit feature interactions across spaces and scales fully. FPT incorporates three transformer types: the self-transformer, grounding transformer, and rendering transformer. These transformers encode the information from the feature pyramid’s self-level, top-down, and bottom-up paths. FPT leverages the self-attention module in the transformer to augment the feature pyramid network’s feature fusion process.
TransReid 35 is the first method to use the transformer structure to solve the person re-identification problem. The underlying structure is similar to that of ViT. 1 It divides the input image into several patches, converts each patch into an embedded feature, and then passes through several transformer block structures for the final output. Different from ViT, TransReid adds SIE modules that represent relevant information, such as cameras and perspectives for the particularity of pedestrian re-identification. In addition, one output from ViT becomes a multi-branch structure with a global branch and several local branches. The method proposed in this paper is mainly realized based on TransReid combined with various improvement schemes. Finally, state-of-the-art recognition outcomes were achieved in person re-identification across four publicly available datasets.
Knowledge distillation
Over the years, the techniques for knowledge distillation have developed. In the academic literature, 36 KL divergence has been utilized to evaluate the resemblance between the probability distributions of the teacher and student network’s softmax output. The objective is for the student network to attain a probability distribution that resembles the teacher network. Literature 37 is to perform knowledge distillation on the intermediate features of each layer in the network. The primary purpose is to hope that the student network can obtain output similar to the teacher network at different levels of the entire network and guide the learning using the mean square error metric function. Literature 38 proposes to use attention as a knowledge carrier for knowledge distillation. A paper in the field of literature 39 suggests incorporating similarity-preserving knowledge into the teacher and student networks, ensuring that they produce comparable activations for the same input samples. To measure this similarity, the paper employs mean square error, which calculates the inner product of the corresponding feature maps of the two networks. Literature 40 uses mutual information to measure student and teacher networks’ differences. Mutual information can indicate the degree of the mutual dependence of two variables, and the larger the value, the higher the degree of dependence between the variables. Mutual information is the teacher model’s entropy minus the teacher model's entropy given the known student model. The aim is to increase mutual information. In reference 42 , comparative learning is incorporated into knowledge distillation to achieve this objective. The approach seeks to acquire a representation that minimizes the distance between the teacher and student networks for positive sample pairs and maximizes it for negative sample pairs.
Some of these knowledge distillation methods are online distillation. The teacher and student networks are trained simultaneously, but the online distillation method, such as literature 45 , must manually construct additional parallel branch structures. Although redundant branches will be removed in the prediction stage, the computational complexity of the training stage will be doubled in the training stage. The method proposed in this paper also belongs to the category of online knowledge distillation. We combine the particularity of person re-identification field, that is, there is often a global branch and multiple local branches in the network structure, to explore the application of online knowledge distillation scheme in this particular structure. TransReid has achieved an improved recognition rate on various public datasets related to person re-identification without increasing computational requirements during training and testing. In addition, we analyze some problems with knowledge distillation of softmax output using the MSE loss function. When there is a BN layer in front of softmax, the effect of using the MSE loss function for knowledge distillation is the same as using KL divergence for knowledge distillation. However, the former does not need time to select the appropriate temperature parameter, T. Through a series of comparative experiments, the correctness of our inferences is verified.
Method
Self-distillation structure
Our self-distillation network structure does not add other redundant network structures based on TransReid 35 but uses knowledge distillation to fully exploit the potential information on the network structure of TransReid, which has both a global branch structure and multiple local branch structures. We tried several different combinations of self-training.
First, we believe global features should be more informative than local ones. We hope that the local branch structure should not only pay attention to the local features themselves during training but also consider the constraints of the relevant information of the global features of the image so that they can reduce the ill effects of some locally noisy images. During the training process, we employ the output of the global branch as the teacher network’s structure and the four local branch structures as the structure of the student network. The loss function of this network structure is shown in the following formulas:





The distill function in the above formulas represents a specific knowledge distillation function. This function, such as KL divergence or MSE loss, can be selected differently. Please refer to the following chapters for the selected analysis of this function. The
The first self-training network structure.
The second is that we believe that the global branch should pay attention to not only global features but also some noticeable local features, and for the capture ability of local features, the local branch should be stronger than the global branch because it only needs to focus on a local area. Therefore, during training, we use the local branch structure as the teacher network structure and the global branch structure as the student network structure. The loss function of this network structure is very similar to the first case above, only the form of the knowledge distillation loss function is slightly different. The specific form is as follows:


The second self-training network structure. In order to avoid excessive similarity with Figure 1, we only depicted the parts that are different from it.
The third one is inspired by literature
44
and combined with the ideas of the first and second schemes above. When the network is trained, each local branch and global branch serve as both the student and teacher network structures. Each branch learns from the other and progresses with each other so that the global branch can learn from the local feature extraction ability, and the local branch can also learn from the overall view of the global branch and finally obtain a better recognition effect. The loss function in this network architecture closely resembles the one in the first scenario. However, the structure of the loss function varies for knowledge distillation. The precise structure of the knowledge distillation loss function is as follows:





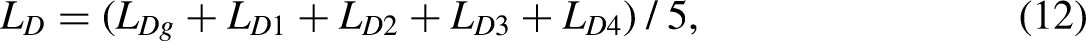
In the above formulas,

The third self-training network structure. In order to avoid excessive similarity with Figure 1, we only depicted the parts that are different from it.
The fourth is inspired by literature
45
. We believe that although the concerns of different branches may differ, the goals are the same, so if we integrate the outputs of all different branches, we should get better recognition results. Moreover, this better result incorporates all the valuable information from the local and global branches. Using this comprehensive information as the teacher network structure and then teaching each branch structure, in turn, should improve each branch’s feature extraction ability. The loss function for this network architecture is similar to the one described in the previous case, but the function used in knowledge distillation differs in its form. The precise form of the knowledge distillation loss function is as follows:
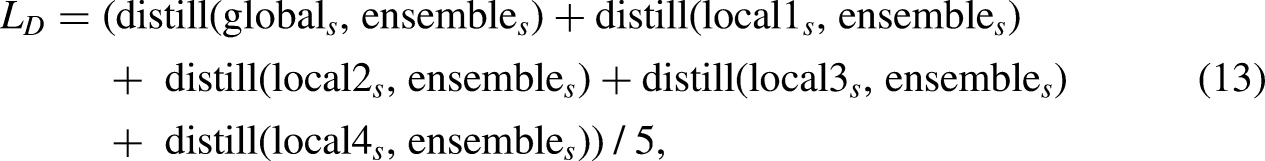
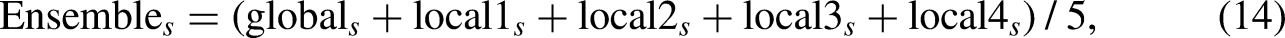
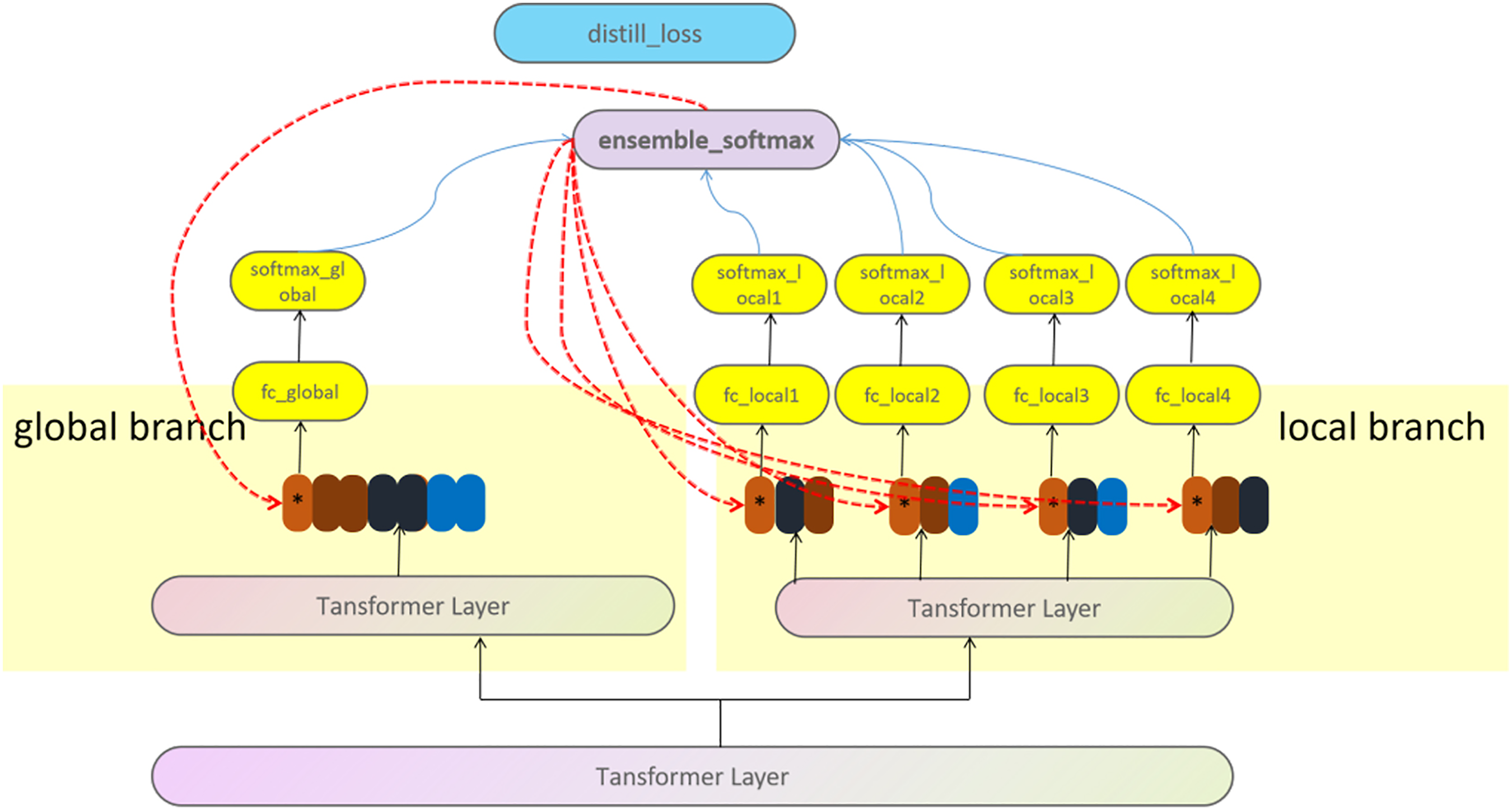
The fourth self-training network structure. In order to avoid excessive similarity with Figure 1, we only depicted the parts that are different from it.
It should be noted that the different self-training schemes we mentioned earlier have different methods and effects, but generally, each scheme does not increase the amount of extra computation. At the same time, the recognition efficiency of the original network structure is improved. Please refer to the related content in the following chapters for the experimental results.
Compared with other online distillation methods, our method has obvious advantages and differences. For example, in literature 45 , multiple branch network structures parallel to the original network structure are additionally constructed, and these parallel network structures are used for information distillation, thereby improving the recognition effect of the original network structure. While achieving higher performance, there is a trade-off with exponentially increasing the computational requirements during training.
The approach presented in literature 54 does not introduce additional network structure. However, this paper proposes a method of rearranging the sampling order by constraining half of each mini-batch with the previous iteration while the remaining half coincides with the upcoming iteration. In this way, the first half of the mini-batch distills the soft targets generated in the previous iteration. This method performs self-distillation from the perspective of the input timing of the data. Literature 50 uses the perspective of different network parameters at different times to do self-distillation. The methods of these articles are different from ours.
Choice of the distillation method
The distillation method proposed in literature 36 is the most commonly employed technique among the various knowledge distillation methods. It employs KL divergence as a loss function to quantify the distribution difference between the softmax output results of the teacher and student networks. However, this method needs to set a suitable temperature parameter, T. If the set parameter value is not suitable, a harmful distillation effect may be obtained. Moreover, the appropriate temperature parameter T may be inconsistent in different datasets.
However, in literature
43
, it is proposed that MSE loss can be used to measure the difference between the teacher and student networks so that the parameter T can be avoided. However, the paper also pointed out that the softmax output cannot be directly distilled using MSE loss. The example they gave is that the two data inputs to the softmax function are [10, 20, 30] and [–10, 0, 10], and the output of softmax is precisely the same, but the two datasets are different. Therefore, only the data before entering the softmax can be regressed, and the softmax output cannot be regressed. For this problem, we analyze that if there is no BN layer, the output of the softmax of [10, 20, 30] and [–10, 0, 10] are indeed the same [2.0611e-09, 4.5398e-05, 9.9995 e-01]. As shown in Figure 5a. In this case, if the output of softmax is regressed on the MSE loss function, there is a problem of not reflecting the difference between the two sample features, as mentioned in literature
43
. However, since a BN layer normalizes all the data before entering the softmax activation function, this problem does not exist in our model. Let us analyze the calculation formula of the BN layer:




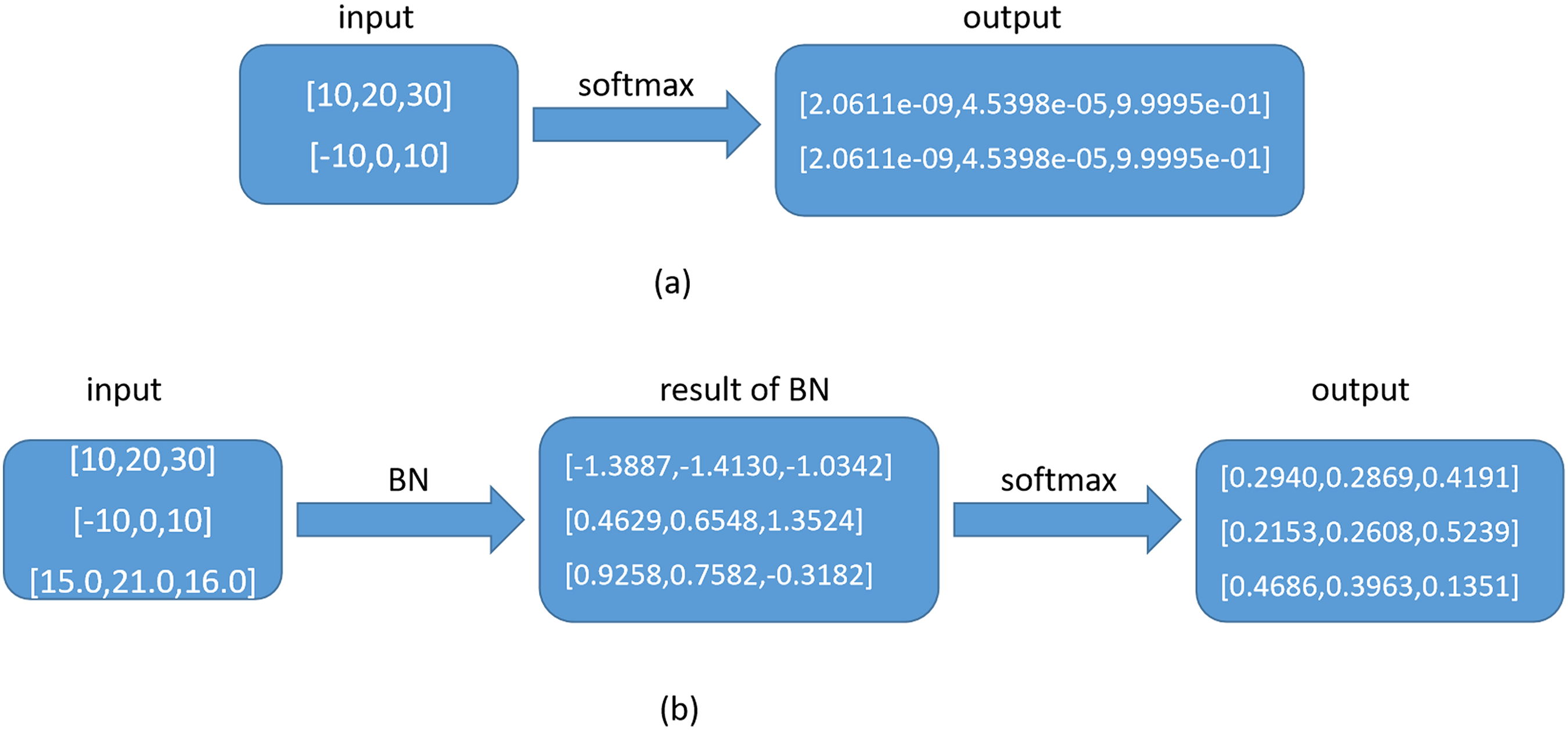
Illustration of the difference in adding a BN layer before the softmax layer for special input data: (a) without BN layer and (b) with BN layer.
After the BN layer, there must be other data besides these two in a batch of input data, and we assume it is [15.0, 21.0, 16.0]. According to the calculation formula of the BN layer, the input data entering the softmax is calculated by the four parameters
At the same time, considering that using KL divergence as the distillation scheme requires selecting the appropriate temperature parameter T through experiments, and different datasets may require different appropriate parameter T, we believe that the MSE loss function is a simpler and more appropriate scheme for distillation of softmax output. Therefore, in our final experiment, we used the MSE loss function to distill the output data of softmax. It is worth noting that if we use the MSE loss function for knowledge distillation, the first network structure and the second network structure mentioned earlier in this article are equivalent because in our network, due to the online self-distillation do not fix the parameters of the teacher network structure. Hence, Equations 1 and 6 are entirely equivalent. However, for KL divergence, since the formula of KL divergence clearly defines the concept of the probability distribution to be fitted and the target probability distribution for the two probability distributions involved in the calculation, Equations 1 and 6 can represent different ideas.
For the case that the BN layer is not connected, we have also done relevant experiments, and the results show that, as we have analyzed, if the BN layer is not connected, the effect of direct regression on the output value of softmax is worse than that on the input value of softmax. For specific experimental results, please refer to relevant content later.
Add noise to network weights
The complexity of the transformer network structure used in this paper is very high, and it is easy to overfit compared to the tens of thousands of pictures in the public dataset in person re-identification. There are many approaches to mitigating overfitting, with regularization applied to the network being common. Adding noise to the network weights can be seen as a regularization technique added to the network structure. Following this idea, this paper treats adding noise to the network weights as a scheme to avoid getting stuck in local minima. We observed that when the network gets stuck in a local minimum, there is usually overfitting with 100% test accuracy on the training set, so we can observe whether the test accuracy on the current training set tends to be 100%. If so, add noise to the network weights to help it jump out of the current local minimum. In this way, the network can be prompted to jump out of the current local minimum and try more local extreme points to converge to a relatively good local minimum and obtain a better recognition effect. For related experimental analysis, please refer to the related content later in this article.
Experimental results and analysis
Introduction to experimental datasets
This article uses four public datasets, namely Market-1501, 3 DukeMTMC-reid, 4 MSMT17, 6 and Occluded-Duke, 51 to evaluate the proposed methods. Market-1501 3 is a dataset of 1501 pedestrians captured by six cameras on the campus of Tsinghua University in 2015, with a training set of 751 people and a test set of 750 people. DukeMTMC-Reid 4 is a subset of the DukeMTMC dataset, containing 1404 people and 36,411 images captured by eight cameras. MSMT17 6 was collected from 15 cameras on campus, with a training set of 1041 pedestrians and a test set of 3060 pedestrians. Finally, unlike other datasets, the images in Occluded-Duke 51 are selected from DukeMTMC-reID, and the training/query/gallery set contains 9%/100%/10% occluded images, respectively.
The Market-1501 dataset is fascinating because it includes high-resolution and low-resolution images captured by multiple cameras. 3 The training set averages 17.2 images per person, while the test set averages 26.3 images per person. The query images are manually annotated, while the gallery images use a DPM detector for pedestrian detection.
DukeMTMC-Reid is a valuable dataset for pedestrian re-identification research, as it contains many images captured by multiple cameras. 4 The training set and test set both include 702 people, with the training set containing 16,522 images and the test set containing 17,661 images.
MSMT17 is notable for using 15 cameras covering indoor and outdoor areas, with video collected over four days with varying weather conditions. 6 The dataset was annotated by three human annotators and contained a training set of 1041 pedestrians with 32,621 bounding boxes and a test set of 3060 pedestrians with 93,820 bounding boxes. The test set also includes query images randomly selected from the bounding boxes.
Finally, Occluded-Duke is a unique dataset focusing on occluded images, with 9% of the training set and 10% of the query/gallery sets containing occluded images. 51 The dataset was selected from DukeMTMC-Reid and included 1812 people with 36,411 images.
These datasets provide valuable resources for researchers studying pedestrian re-identification and related areas, such as object detection and image recognition.
Experimental parameters and testing metrics
This paper’s experimental environment and parameters are designed as follows: using ubuntu16.04 system, python3.6 for programming, the deep learning framework used is pytorch1.7.0 version, and the computing graphics card is 2080ti. The input image is scaled to 384 × 128 and 256 × 128 sizes (for Occluded-Duke). The batch size is set to 64. Since the triplet loss function is used, 16 pedestrian IDs are sampled each time, and each pedestrian samples four pictures. The learning process employs the cosine annealing method to adjust the learning rate, starting with an initial rate of 0.008. The weight decay factor is 0.0005, and the backbone model is based on the TransReid model pre-trained on ImageNet as literature 35 . Data augmentation utilizes three methods: random horizontal flip, crop, and erasure. The triplet loss function uses the soft margin approach. We use stochastic gradient descent (SGD) with a momentum value of 0.9 to optimize the model.
By established practices within the person re-identification community, we assess all approaches using cumulative matching characteristic curves and the mean Average Precision (mAP).
Analysis of the results of the experiment
Experimental analysis of self-distillation learning structure
As the previous relevant chapters mentioned, our self-distillation learning network structure is divided into four types. The first is to use the information of the local branch as a teacher to train the global branch. It is hoped that the global branch can learn some classification capabilities based on local features while learning global classification. This method is represented by ltg. The second is to use the information of the global branch as a teacher to train the local branch. It is hoped that the local branch will pay attention to the local features and consider the implicit information of the global image to which the local image belongs. This method is represented by gtl. The third is inspired by mutual teaching, 44 allowing each branch to perform mutual online distillation learning as both student and teacher to allow them to learn from each other and improve. This way is represented by mt. The fourth is to integrate the output information of the global branch and all local branches and use the probability distribution information obtained by their integration as a teacher to guide the training of the global branch and all local branches. This paper uses the method to verify the superiority of the method under the network structure of TransReid, which has different branch structures without adding computational burden. This method is represented by st. We use KL divergence as the loss function of knowledge distillation for the experiments in these cases.
According to the experimental data in Table 1, it is apparent that the self-distillation learning network structure utilizing “st” performs the best on the public datasets. As a result, our final network structure employs this method. Among the other three methods, “mt” has a slightly better effect, while “ltg” and “gtl” have a similar effect. Overall, all four methods outperform the original TransReid network structure. This demonstrates the significance of our proposed approach, which utilizes online knowledge distillation to fully extract information from different branches without increasing the computational burden.
Self-distillation learning structure comparison experimental results. The baseline data in the table come from the data of TransReid.

Experimental analysis of the choice of the distillation method
To prove the network structure with BN layers deduced in this paper, using the MSE loss function to distill the output of softmax does not have the disadvantages mentioned in literature 43 . We conducted experiments on the fourth self-distillation network structure described earlier in this paper. The experimental results are shown in Table 2. From the experimental results on the three public datasets in this table, we can see that in our network structure, since there is a BN layer before the softmax layer, it is better to use the MSE loss function to distill the output of softmax than to distill the features before the input of softmax. To verify our inference, we remove the last BN layer in the network structure and then compare the difference between using the MSE loss function to distill the output of softmax and the features before input to softmax. We found that in this case, as stated in paper 44, the effect of directly distilling the softmax output is worse. Through the experimental data of these two cases, we have proved the correctness of our inference.
Comparison of experimental results for distillation method selection. The letter T in the table indicates that knowledge distillation is performed using KL divergence. The number after the letter T indicates the specific temperature parameter value. The representation with the keyword MSE uses the MSE loss function for knowledge distillation. The representation with the keyword BN has the BN layer in front of the softmax layer. The representation with the keyword logit performs knowledge distillation on the features before the softmax input, and the representation without the keyword logit performs knowledge distillation on the output value of the softmax.

In addition, we compare the distillation method for KL divergence with different temperature parameters T and the method for distillation using the MSE loss function. From our experimental results, it can be seen that after carefully setting the value of the temperature parameter, the KL divergence is no worse than using the MSE loss function, but there is no absolute advantage. The method of distillation using the MSE loss function is more straightforward. It does not require any verification experiments of the temperature parameter T. So, we believe that in the case of having a BN layer before the softmax layer, the distillation using the MSE loss function is better than the KL divergence.
Experimental analysis of adding noise to network weights
In the experiment of adding noise to the network weights, considering that the backbone network structure has been pre-trained with a large amount of data on the ImageNet dataset, it already has good feature extraction and generalization capabilities, so we do not do noise perturbation to the backbone weights. The classifier layer of each branch we added on the backbone has not been pre-trained by the dataset ImageNet, and it is easier to overfit the training set, so noise needs to be added to the classifier layer of each branch.
To be more specific, our approach involves primarily adding Gaussian noise to the data with a mean of 0 and a variance of 1. We have considered the impact of directly adding Gaussian noise with a mean of 0 and a variance of 1 to the network weight and have found that this can cause excessive disruption to the network, impeding its ability to converge appropriately. Therefore, the generated random noise data must be multiplied by a small coefficient, which should not be too small. If it is too small, the purpose of perturbing the network weight will not be achieved. So we multiply the Gaussian noise with a mean of 0 and a variance of 1 by a series of smaller coefficients, add them to the weights, and compare them with the recognition effect without noise (the baseline data without noise are shown in Table 3). The e0 in Figure 6 means adding noise with a mean of 0 and a variance of 1 directly. The e1 means multiplied by the minus one power of 10, e2 means multiplied by the minus two power of 10, and so on. Based on the experimental results depicted in Figure 6, it can be inferred that adding Gaussian noise with a mean of 0 and a variance of 1 directly to the network weight produces adverse effects. However, when the coefficient begins from a negative power of 10 to the third power, the mAP and Rank-1 indicators on these datasets show an improvement. Although these improvements are not very large, from the overall effect of these datasets, adding appropriate noise to the weights still improves the model’s recognition rate. We found that adding Gaussian noise with a coefficient of negative seven to the power of 10 and a mean of 0, along with a variance of 1, is the most effective method when working with multiple public datasets for person re-identification. As a result, we have incorporated this approach into our final model training scheme.
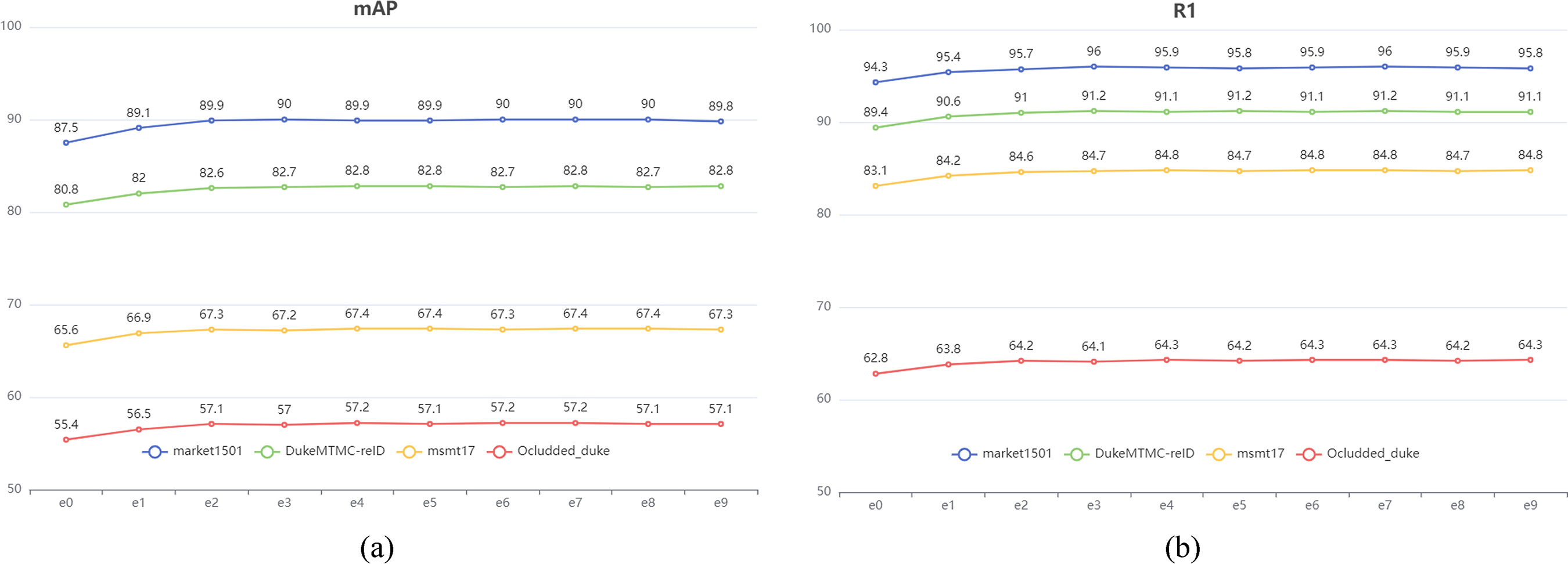
Experimental data with added noise. (a) Experimental data on the mAP indicator; (b) Experimental data on the rank-1 indicator.
Baseline data for adding noise experiments.

Comparison with state-of-the-art methods
Table 4 displays the experimental results of this paper’s approach, which combines all the methods discussed compared with state-of-the-art techniques on four publicly available person re-identification datasets. To facilitate comparison with other approaches, the table includes input images with two different resolutions, 384 × 128 and 256 × 128, indicated in the size column. Regarding the experimental results of the Occluded_duke dataset, since other articles only have the experimental results of 256 × 128 input data, we also only did 256 × 128-related experiments on this dataset. The training images are augmented with random horizontal flipping, padding, cropping, and erasing. The other related training parameters are as follows: the initial learning rate is set to 0.008, and the learning rate is adjusted using cosine annealing. The batch size is set to 64, where 16 IDs are sampled each time, and four samples are taken from each ID. The weight decay is set to 1e-4, the momentum is set to 0.9, and the optimization method is SGD. The PyTorch (Version 1.7) training framework is used, and the training is conducted on an NVIDIA 2080ti GPU. We used a pre-trained ViT model on the ImageNet dataset to initialize the backbone of our network structure. The margin of the triplet loss was set to 0.3. Other losses were weighted equally, including the cross-entropy loss and the knowledge distillation loss.
The performance of the proposed method is compared with state-of-the-art techniques.

The asterisk (*) indicates that the backbone is configured with a sliding-window setting. The bold values indicate the maximum values in their respective columns in the table.
Our approach achieves superior results on various datasets. On the Market1501 dataset, we surpass the previous best method by 0.7% points for the map metric and 0.9% points for Rank 1. Similarly, on the DukeMTMC-reID dataset, our method outperforms the previous state-of-the-art approach by 0.4% points for the map metric and 0.5% points for rank 1. On the MSMT17 dataset, our method outperforms the previous state-of-the-art approach by 0.4% points for the map metric and 0.1% points for rank 1. Finally, on the Occluded-Duke dataset, our method outperforms the previous state-of-the-art method by 0.4% points for the map metric, while the rank-1 metric remains the same.
Regarding these experimental data, it should be noted that in literature 35 , the author proposed the sliding-window method, which can effectively improve the recognition rate of the model but significantly increases the resource requirements. Since the best result at present is the method of adding this setting, we also adopted the same experimental setting for the convenience of comparison: setting the sliding window size to 12. The above results represent the state-of-the-art results achieved through the method proposed in this paper when used with the prescribed settings. However, it is worth noting that our approach still delivers state-of-the-art results on Market1501 and DukeMTMC-reID, even when the sliding window is not set to 12. This outcome validates the efficacy of our methodology. Nevertheless, with the sliding window set to 12, we achieved state-of-the-art results on all four public datasets. These experimental results demonstrate that our approach enhances person re-identification through visual transformers and multi-branch network structures like TransReid without additional resource requirements.
Analyze the reasons for improved performance
The previous experimental data on four public datasets have shown that our method can improve the model's recognition rate. However, we hope to understand better why our model recognition rate can be improved for some specific pictures. Therefore, we adopt the method of literature 56 to visualize the attention map of the input image. The visualization results are shown in Figure 7.

Heatmap analysis of experimental data. We give a total of six sets of experimental data, and each set of experimental data has three pictures. These three images visually represent the performance comparison between the TransReid model and the proposed method. By analyzing the heatmaps, we can observe the strengths and weaknesses of each approach in identifying and localizing persons of interest in the image.
There are a total of six sets of experimental data in Figure 7. For the first group, our model and TransReid's model have a similar focus on the data, both are upper body clothes and backpacks, but as seen from the heatmap, our model pays more attention to this part of the area. For the second group, the focus between the two models is different. Our model mainly focuses on the clothes on the upper body, especially the logo on the top of the clothes, which is more reasonable than focusing on pure black pants. In the third group, although both models paid more attention to black pants, our model also paid more attention to the clothes marks on the upper body. In the fourth set of experimental data from the human eye’s perspective, the green area in the middle of the dress and the shoes are more prominent, and our model captures these features. Compared with the previous four sets of experimental data, the advantages of our model are more evident in the fifth and sixth sets of experimental data. First, our model extracts more obvious heatmap regions in both experimental datasets. Secondly, the red bag in the fifth dataset is a very prominent sign, and it is very reasonable to pay attention to it. In the sixth dataset, our model can pay attention to the unique texture features of most clothes, especially the right shoulder strap of the backpack, and even its outline can be seen from the heatmap. It can be seen from these example data that our model can improve the recognition rate because it pays more attention to some of the more iconic positions in pedestrian images, which is more in line with the mechanism of the human eye. So it is reasonable to get better results.
Conclusion
The work done in this paper is mainly based on the network structure like TransReid and makes full use of the characteristics of this network structure with global branches and local branches. While not adding any additional resource requirements, the method of online self-distillation is introduced. We conduct a detailed experimental comparison of various possible online self-distillation methods. The best online self-distillation scheme effectively improves the recognition rate of network structures such as TransReid on four public datasets in person re-identification. Secondly, this paper proves through theoretical analysis and experimental verification, at least on the four public datasets of person re-identification, on the premise that there is a BN layer in front of softmax, the effect of using MSE loss function for knowledge distillation and using KL Divergence for knowledge distillation is about the same. So, we think using the MSE loss function for knowledge distillation is more straightforward and effective. In addition, we judge whether it is necessary to add noise to the network weights by checking whether the recognition rate on the training sample set tends to be 100% and conduct a series of experiments to compare and analyze the magnitude of the added noise, which further improves our recognition effect. By incorporating the aforementioned improvement strategies, we have achieved the most advanced recognition performance on four publicly available datasets for person re-identification.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Chongqing College of Electronic Engineering Project (grant number XJWT202107).
Author biographies
Wenjie Chen received a BS degree from the School of Environmental Engineering, Nanchang University, Nanchang, China, in 2008 and an MS degree from the School of Technology of computer application, Nanchang University, in 2012. He is currently a lecturer at the Chongqing College of Electronic and Engineering, China. His research interests include computer vision, machine learning, and deep learning.
Kuan Yin received an MS degree in Computer Science and Technology from the School of Computer Science, Sichuan Normal University in 2020. Currently, he is pursuing a PhD degree in Computer Science and Technology at Chongqing University of Posts and Telecommunications. His research interests encompass pattern recognition and intelligent systems, object tracking and detection, real-time image processing, and embedded systems.
Yongsheng Wu is a student at Chongqing College of Electronic and Engineering, China. His research interests include computer vision, and deep learning.
Yunbing Hu received an MS degree from Chongqing University in 2007. He is currently pursuing a PhD degree with Xiamen University in an Australia-China Joint Cultivation Program. He has experience working for higher education institutes. His research interests are indoor navigation and multi-source positioning, and navigation.