
Abstract
The rotating component is an important part of the modern mechanical equipment, and its health status has a great impact on whether the equipment can safely operate. In recent years, convolutional neural network has been widely used to identify the health status of the rotor system. Previous studies are mostly based on the premise that training set and testing set have the same categories. However, because the actual operating conditions of mechanical equipment are complex and changeable, the real diagnostic tasks usually have greater diversity than the pre-acquired datasets. The inconsistency of the categories of training set and testing set makes it easy for convolutional neural network to identify the unknown fault data as normal data, which is very fatal to equipment health management. To overcome the above problem, this article proposes a new method, Huffman-convolutional neural network, to improve the generalization ability of the model in detection task with various operating conditions. First, a new Huffman pooling kernel is designed according to the Huffman coding principle and the Huffman pooling layer structure is introduced in the convolutional neural network to enhance the model's ability to extract common features of data under different conditions. Second, a new objective function is proposed based on softmax loss, intra-class loss, and inter-class loss to improve the Huffman-convolutional neural network's ability to distinguish different classes of data and aggregate the same class of data. Third, the proposed method is tested on three different datasets to verify the generalization ability of the Huffman-convolutional neural network in diagnosis tasks with multi-operating conditions. Compared with other traditional methods, the proposed method has better performance and greater potential in multi-condition fault diagnosis and anomaly detection tasks with inconsistent class spaces.
Keywords
Introduction
The continuous development of modern industrial technology has prompted more and more large-scale, complicated, integrated, and intelligent equipment to emerge. The above characteristics of modern industrial equipment not only makes higher operational reliability, safety, and economy become urgent needs, but also create new challenges for equipment condition monitoring and maintenance management.1–3 The fault diagnosis and anomaly detection technology developed under this background performs a vital function in ensuring the safe and sustainable operation of modern mechanical systems.
Fault diagnosis or anomaly detection is essentially a pattern recognition process that establishes a mapping of the measurement or feature space to the fault space. Generally, fault diagnosis methods can be divided into four categories: model-based method, signal-based method, knowledge-based method, and hybrid method.4–6
Traditional identification processes typically rely on a variety of ancillary maps of the monitoring signals and are ultimately diagnosed by a diagnostician. For example, the spectrum of the vibration signal, the envelope spectrum, and the demodulation spectrum are applied to diagnose the failure of the rotating machinery.7–11
Knowledge-based method is a very typical automatic fault identification method that requires a large amount of historic data to establish the system fault modes without prior known models or signal patterns. With the advent of the era of big data, knowledge-based fault diagnosis methods have been flourishing.12,13 The data-driven fault diagnosis method represented by machine learning (ML) and deep learning (DL) is especially typical. The vibration signals are projected into a nonlinear space by methods such as locally linear embedding, 14 sparse representation, 15 autoencoder, 16 and support vector machines (SVMs) 17 to obtain more significant features. Deep belief network (DBN), 18 convolutional neural network (CNN), 19 sparse autoencoder, 20 stacked denoising autoencoder, 21 sparse filtering, 22 and other DL methods can improve the accuracy of recognition without manual feature extraction.
The fault diagnosis methods based on ML and DL introduced above are all based on a common assumption that the class labels of the test data and training data are consistent.23,24 However, in the actual fault diagnosis task, different working conditions and even new fault types will lead to inconsistency between the test data and the training data category. 25 With the in-depth study of intelligent diagnosis technology, in the field of rotating equipment fault diagnosis, researchers’ attention on the diagnosis problem has gradually shifted from the consistent category space to the inconsistent category space. The category space inconsistency in the fault diagnosis problem mainly includes equipment inconsistency, working condition inconsistency, and fault class inconsistency. From this, techniques such as open-set fault diagnosis (OSFD) 26 and cross-domain fault diagnosis (CDFD) 27 are derived.
The OSFD is mainly used to solve fault diagnosis problems in which there are more fault classes in test data than in training data. This requires the diagnostic model to not only correctly classify known categories but also to identify new categories that have not been seen before. Therefore, the common solution of OSFD is to first build a feature extraction model, then design a feature measurement method such as a distance-based method, and further set a reasonable threshold to evaluate whether the tested data belongs to a known class. Tian et al. proposed a feature fusion method based on t-sne and kernel null Foley–Sammon transform (KNFST) to construct the state feature space of the equipment, and then designed an adaptive threshold based on the test data to improve the accuracy of classifying known faults and identifying unknown faults.
28
Lundgren and Jung employed a probability density function (PDF) to abstract the failure characteristics of the data and proposed a one-class classifier using the approximate distinguishability measure to test if a new PDF p can be explained by a known fault mode
Different from OSFD, CDFD focuses on solving fault diagnosis problems across working conditions or across equipment. The main idea of solving CDFD is domain adaptation (DA),30,31 which is a technique of transfer learning. 32 The core idea of DA is to reduce the distribution discrepancy between the source domain (SD) and the target domain (TD) to achieve the purpose of classifying the TD only by training the SD data or a small amount of TD data. Therefore, how to represent the features of the SD and the TD, how to measure the distribution difference between the SD and the TD, and how to reduce the distribution discrepancy between the SD and the TD have become the hot research directions of DA. Qin et al. adopted modified composite multi-scale fuzzy entropy (MCMFEs) as the fault features to express similar features information between the TD and the SD. 33 Further, they proposed a feature similarity measurement method based on minimum redundancy maximum relevance (mRMR), Kullback–Liebler divergence (KLD), and k-nearest neighbor (KNN) to improve the classification accuracy of CDFD for rolling bearing. Li et al. present a knowledge mapping-based adversarial domain adaptation (KMADA) method to learn a distance metric measured by a discriminator. 34 This method requires the construction of 2D feature images of each domain via short-time Fourier transform (STFT) and L2 normalization.
Both OSFD and CDFD are very complex in various stages of organizing data, building diagnostic models, and training diagnostic models. Because the models are too complex, the computational loss is also very large. Considering that in actual engineering, the occurring possibility of faults in the initial stage of equipment operation is relatively small. Before a device fails or new faults occur, we can often collect some valid data of the device. At the same time, for the equipment that fails, we usually shut down the equipment directly, and the technicians will conduct a detailed inspection to determine the specific fault mode and formulate maintenance strategies. Therefore, for an automatic diagnosis model, it is more engineering meaningful to be able to identify a new fault as an anomaly than to identify that the fault is a new fault.
In view of the abovementioned fault diagnosis engineering requirements, this article attempts to improve the generalization ability of simple networks, so that it can solve the problems of fault diagnosis and anomaly detection under the condition of multiple operating conditions and inconsistent class labels. This article mainly studies fault diagnosis and anomaly detection tasks under the condition that the category of testing data is larger than training data. It is found that Huffman coding can effectively reduce the noise of the vibration signal of the rotor equipment and enhance the impact characteristics of the vibration signal in our previous study. 35 Considering that some effective feature information will be lost in the preprocessing of vibration signal, we try to combine Huffman coding with CNN, and conduct Huffman coding on the data stream during the CNN feature extraction process. In view of CNN's weak ability to identify unknown test samples, we further enhanced CNN's ability to describe normal data by increasing the distribution difference between classes of known training data to isolate the characteristic space of normal data. For this reason, we introduce mixed loss into the new network objective function. With the help of the Huffman coding and mixed loss, the network could improve the accuracy on classifying the testing data which has more diversity than the training data.
The main contributions of the proposed method are as follows:
We propose a new pooling method called Huffman pooling according to the principle of Huffman coding and introduce it into the traditional CNN. Compared with traditional pooling methods such as max pooling and average pooling, the Huffman pooling method can not only preserve the numerical information within each pooling unit but also the complexity information within the pooling unit. The Huffman pooling process effectively retains more information related to the original data features so it can effectively enhance the robustness of the CNN model. We design a new H-CNN objective function based on softmax loss, intra-class loss, and inter-class loss. Compared with the traditional loss function, the new loss function can not only guide the model to learn the features of the same class of samples, but also guide the model to distinguish the features of different classes of samples so it can effectively improve the generalization ability of the model for fault diagnosis and anomaly detection under multiple operating conditions. To verify the generalization ability of the H-CNN in fault diagnosis and anomaly detection under multiple working conditions, the proposed method is tested on three different datasets which are the cylindrical roller bearings dataset, deep groove ball bearings dataset, and gearbox dataset. In the detection tasks for known faults and unknown faults, the accuracy rate reaches
The rest of this article is organized as follows. The basic theory of Huffman average code length (HACL) and the CNNs is presented in Basic theory section. Proposed method for fault diagnosis section elaborates on the pooling method based on Huffman coding theory, the structure of the fault diagnosis model based on Huffman pooling and CNN, and a new mixed loss function. In Case studies section, the identification performance of the proposed method is verified on three datasets. Finally, the concluding remarks are summarized in Conclusion section.
Basic theory
HACL
Huffman coding is a method of optimal prefix coding used for lossless data compression. Since David A. Huffman proposed the coding algorithm in 1952, 36 Huffman coding has been widely used in the field of computer science and information theory due to its high efficiency. The output of Huffman's algorithm is essentially a variable-length code table with which source symbols can be binary encoded. The algorithm derives the code table from the frequency of occurrence of all possible values of the source symbol.
Let the symbol set

For a set of source symbols

The process of Huffman coding.
Let the code length of the ith symbol in U is
CNNs
CNN is generally composed of three parts: input layer, hidden layer, and output layer. The input layer is the original data such as images. The output layer is the result of classifying the features. The hidden layers are neuron layers with complex multilayer nonlinear structure, including convolution layers, activate layers, subsampling layers, and perceptron layers. A convolution layer, an activate layer, and a subsampling layer are combined into a feature extraction unit. The perceptron layers classify features by mapping them to class labels. The classification ability of the CNN model can be improved by optimizing the feature extraction layers and the perceptron layers. The structure of the CNN is shown in Figure 2.

The structure of a convolutional neural network (CNN).
Figure 2 shows a simple CNN with two convolutional layers (C1, C2), two activate layers, and two subsampling layers (S1 and S2) in the feature extraction layer. After multiple feature extractions, the single-layer perceptron transforms the final 2D feature map into 1D matrix. The output layer divides the features into N classes. The single-layer perceptron is usually a fully connected structure.
Convolutional layer
Convolutional layers are the core component of hidden layers. A convolutional layer is composed of multiple stacked convolution kernels. The convolution kernel is like a filter, which can extract features at a smaller scale on the data input to the convolutional layer. The information of the input data is enhanced, and the interference of noise is suppressed. The size of the convolution kernel is called the receptive field. The input and output of a convolutional layer are both feature maps. The value of the output feature map can be calculated by equation (2).


Process of convolution operation.
Activate layer
CNN simulates the response of human brain nerves to different stimuli using nonlinear activation layers. The introduction of nonlinear activation layers enables CNNs to handle complex computational problems. Commonly used activation functions include sigmoid function, Tanh function, and ReLU function. The formulas of these functions are as follows:

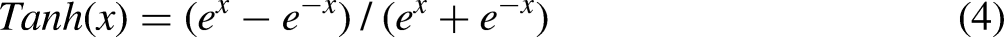

Subsampling layer
The subsampling layer reduces the amount of computation and abstracts the features by downsampling the output feature map of the convolution layer. Subsampling layers are also known as pooling layers. Commonly used pooling methods are max pooling and average pooling. For example, the size of a feature map processed by an activation layer is

Process of max pooling and average pooling operation.
Perceptron layer
The perception layer is usually a fully connected structure. The fully connected layers are the last few layers in the CNN and act as the classifier. Another main role of the perception layer connected to the hidden layer is to convert the 2D feature map into a 1D feature matrix. Each node of the fully connected layer is fully interconnected with the nodes of the previous layer. The fully connected layer performs weighted summation of the features output by the previous layer and inputs the result to the output layer. The formula of the fully connected layer is as follows:

Output layer
For classification issues, the softmax function is usually applied in the output layer. The formula of the softmax function is as follows:

Proposed method for fault diagnosis
CNN updates the weights of the network by the back-propagation algorithm based on the loss between the predicted label and the true label. The network could obtain a high identification accuracy once the loss function is converged to a global minimum value. Considering that the working conditions of rotating equipment in engineering practice are complex and changeable, this section proposes a new loss function and a new network structure to improve the generalization ability of CNN.
Generally, the objective function of CNN is defined to minimize the loss between the predicted table and the real table. When the loss function converges to the global minimum, CNN has a high recognition accuracy. Considering the complex and changeable working conditions of rotating equipment in engineering practice, the data categories to be detected are far more than the available data categories, so CNN cannot learn all the labels to be tested. Therefore, a new loss function and a new network structure are proposed in this section to improve the generalization ability of CNN and try to solve the problem of fault diagnosis and anomaly detection under the condition of insufficient categories of training data.
Signal to 2D image conversion method
Since most of the traditional data-driven methods for diagnosis cannot directly process the original data, many researchers design different data preprocessing methods to improve the feature expression ability of the original data. However, the characteristics obtained by different treatment methods are also different, so it has a great influence on the result. Wen et al. proposed an effective data preprocessing method to maximize the retention of the original data.
25
The idea of this method is to convert the time-domain signal into an image by fulfilling the pixels calculated by the value of the signal. For a signal

Figure 5 shows the image converted from raw signals.
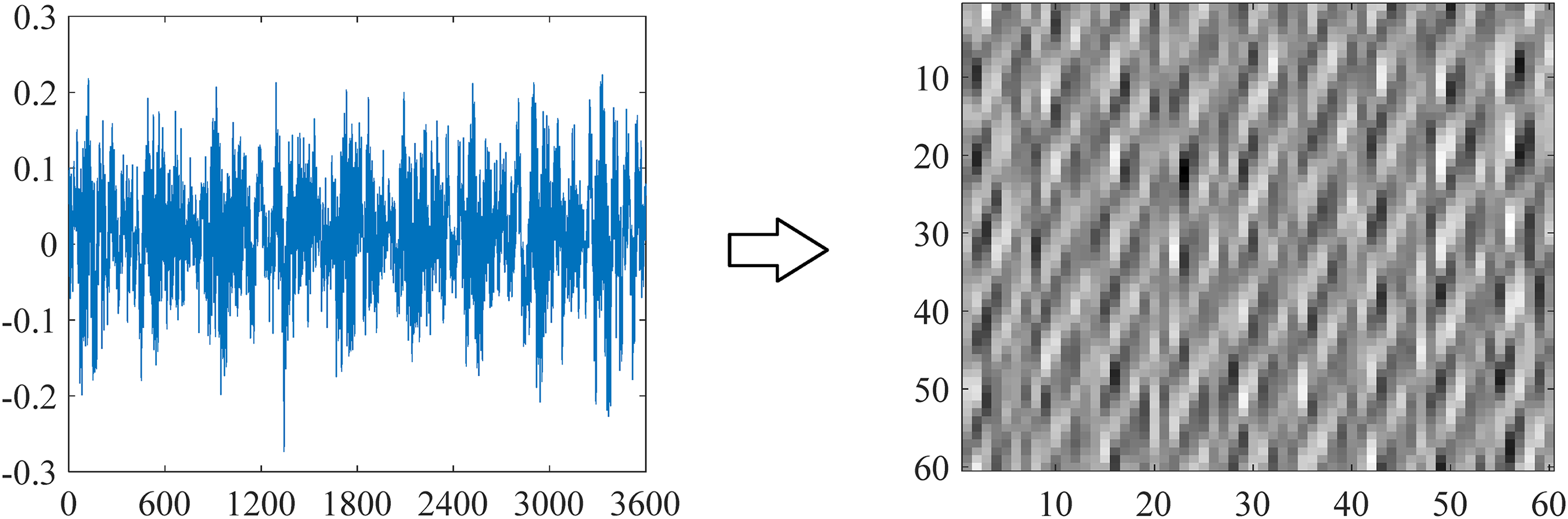
Signal to 2D image conversion.
Huffman pooling
It can be seen from the above Huffman coding process that if Huffman coding is performed on a time series, the amount of data can be effectively reduced, and the dimensionality reduction effect can be achieved.
To analyze the influence of Huffman coding on the data better, this article takes the famous dataset of bearing vibration signal of the famous Case Western Reserve University as an example. Since the vibration signal is a series of vibration amplitudes in the time domain, the data itself usually contains negative values. According to the method of solving the HACL, the signal needs to be converted into a discrete point sequence with probability meaning. Therefore, the original signal needs to be processed into a nonnegative sequence first and then converted into a probability sequence. As shown in Figure 6, the probability sequence is transformed into HACLs finally.

Probability sequence-to-HACLs conversion method.
For a signal data




To better illustrate the influence of HACLs on the signal, this article analyzes from three perspectives of time domain, frequency domain, and distribution in 2D feature space.
The waveforms of the raw signals and their HACLs with
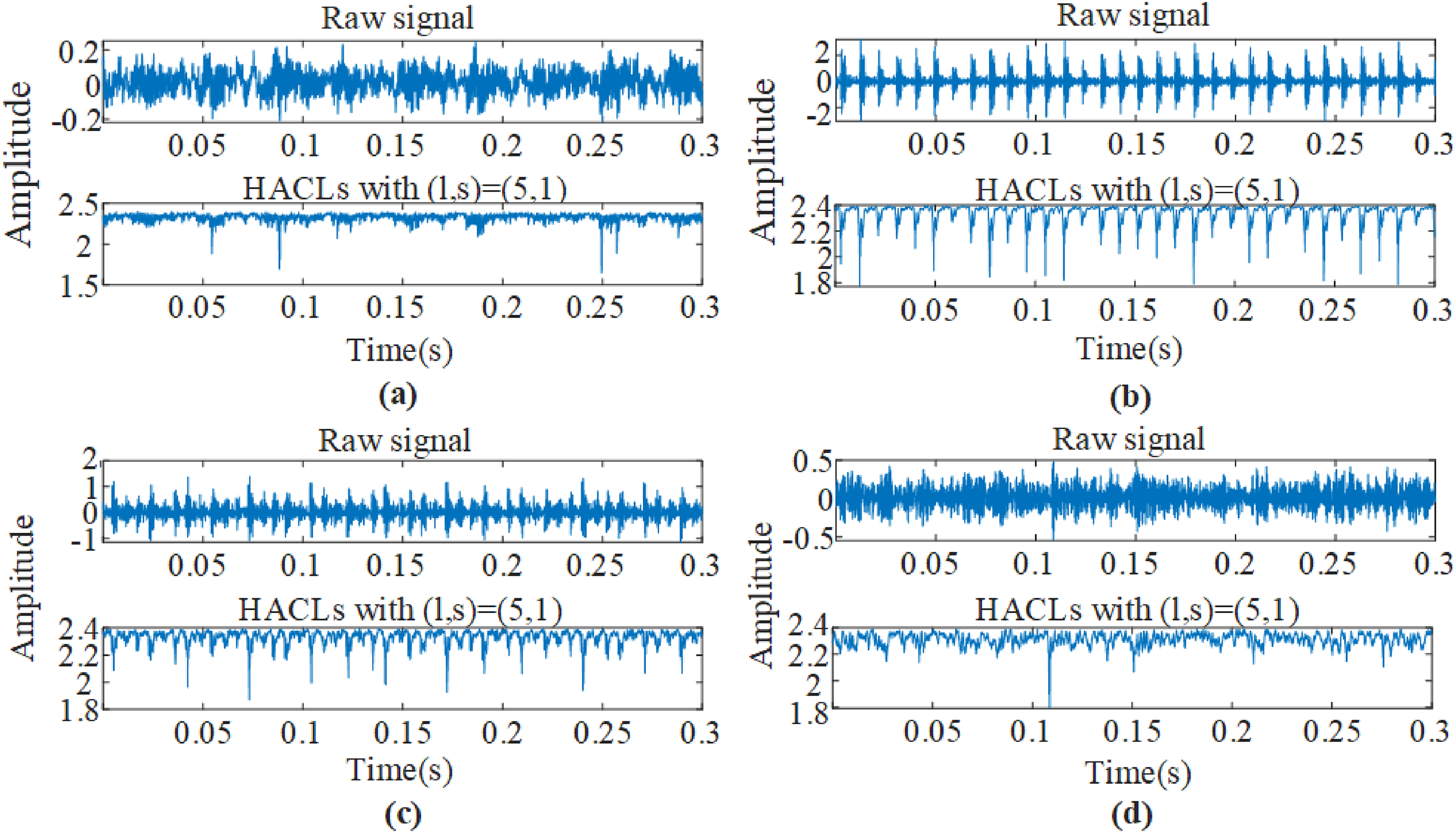
The waveforms of raw signals and their HACLs with
Combined with the relevant parameters used in the bearing experiment, it can be calculated that the rotating frequency is 29.95Hz under the 0hp load condition. The characteristic frequencies corresponding to IF, OF, and BF are 162.19Hz, 107.36Hz, and 141.17Hz respectively. For the raw signals as shown in Figure 7, the amplitude spectrum and envelope spectrum were analyzed respectively. For the HACLs, only the amplitude spectrum was analyzed. The results are presented in Figure 8.
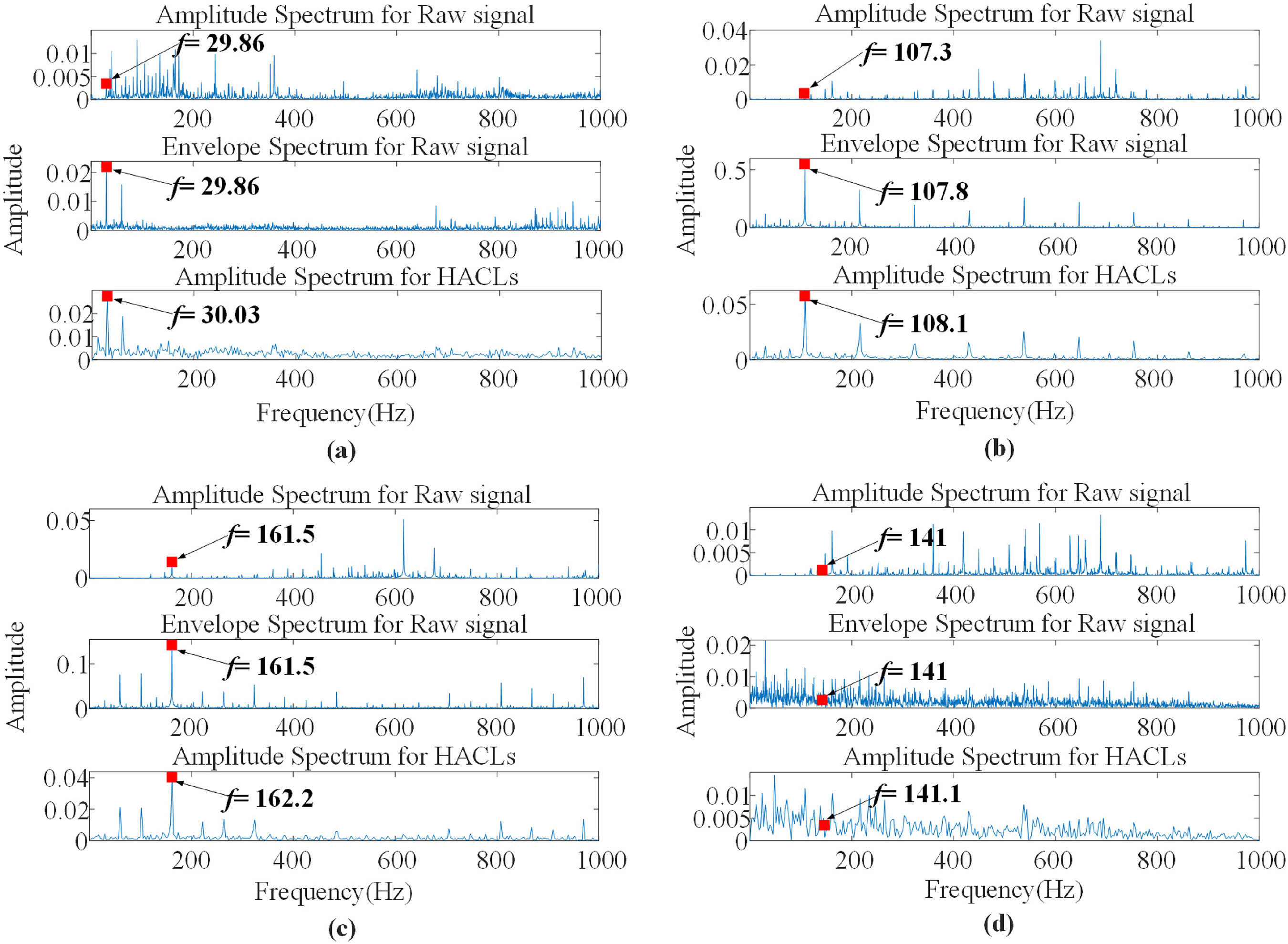
The frequency analysis results of raw signals and their HACLs. (a) Normal (N), (b) outer race fault (OF), (c) inner race fault (IF), and (d) ball fault (BF).
It can be seen from Figure 8 that it is difficult to obtain the characteristic frequency of the original signal in the low-frequency band by directly analyzing the amplitude spectrum. When Fourier spectrum analysis of the original signal is performed directly, the fault frequency will exist in the sideband of the high frequency, which makes it difficult to intuitively find the fault frequency in the low-frequency band. However, by calculating the envelope spectrum of the original signal, it can be found that the characteristic frequency can be observed very intuitively in the low-frequency band. By comparing the envelope spectrum for raw signals and amplitude spectrum for HACLs, it is not difficult to find that for HACLs, only amplitude spectrum analysis is needed to get the obvious fault characteristic frequency in the low-frequency band. It indicates that HACLs has a similar effect to the envelope spectrum.
To better illustrate the influence of HACLs on the distribution in 2D feature space, the t-sne method was applied to visualize the original data and their HACLs with different parameters. 38 The feature distribution in 2D space is presented in Figure 9.

The feature distribution of raw signal and HACLs in 2D space. (a) Raw signal and (b) HACLs with different parameters. The “-1”, “-2”, and “-3” in the legend means the damage size of the fault is 0.178 mm, 0.356 mm, 0.533 mm respectively.
It is obvious that the data of the same type and degree of failure in the original data are not concentrated in the feature space, but HACLs with appropriate parameters in the feature space show more concentration of the same type of data, and low concentration of different types of data. In addition, the distribution of HACLs in the feature space also has the following characteristics:
When the parameters are selected properly, HACLs can increase the degree of dispersion between normal data and abnormal data, which has guiding significance for quickly determining whether the rotor equipment is abnormal in engineering practice; No matter what parameters are selected, the distribution area of the rolling element failure samples is always close to the areas of the other three types of samples, which is consistent with the propagation mechanism of rolling element failures. Due to the particularity of the rolling element structure, when it fails, it will indirectly cause the abnormal vibration of the inner ring, the outer ring, and the entire experimental equipment by means of vibration transmission, and as the effect of the fault continues to spread, the failure energy of the rolling element itself will gradually decrease, so whether in the time-frequency domain analysis or in the characteristic distribution analysis, the fault characteristics of the rolling element itself are easily covered by the fault characteristics of the inner and outer rings; It can be seen from Figure 9 that when l is const and s has less influence on the distribution of HACLs in the feature space. But when s is constant and l changes from small to large, the concentration of HACLs of the same data varies greatly. For example, when
From the above analysis of the distribution of HACLs in the time domain, frequency domain, and feature space, the following conclusions can be drawn: HACLs can effectively enhance the impact components in the original signal, remove high-frequency components, and keep the fault characteristic frequency unchanged. At the same time, HACLs can enhance the degree of aggregation of the same type of original data in the feature space and provide convenience for further analysis of the health status and fault type of the equipment. However, different calculation parameters have a greater impact on the distribution characteristics of the data in the feature space.
In view of the characteristics of the abovementioned HACLs, this article proposes a method of fusing HACLs and CNN. By applying HACLs to the pooling operation of CNN, it can not only reduce the dimensionality in the pooling process, but also retain more features of the original signal.
According to the above introduction to the Huffman coding method, the process of solving HACL fully considers the impact of all data. Therefore, this method can be applied to the pooling process of the CNN.
CNN is a network connected layer by layer with three different functions: convolutional layer; pooling layer; fully connected layer. The convolutional layer applies multiple filters to obtain the feature map of the input image. The pooling layer abstracts the features by reducing the input feature dimension by means of downsampling. The features are extracted by alternating convolutional layer and pooling layer. The abstract features are finally input to the full connection layer to calculate the classification results
Set the output size of the ith convolutional layer is

The ith Huffman pooling layer.
According to the method of calculating HACL, the data needs to be converted into a discrete point sequence with probability meaning. Therefore, the output data of ith convolutional layer needs to be processed into a nonnegative data first and then converted into a probability sequence. As shown in Figure 10, the output of ith convolutional layer is normalized before pooling.
For a 2D data


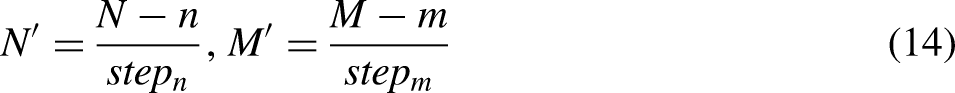
This article compares the differences between Huffman pooling and the traditional pooling methods with three sets of examples. The three sets and the results of different methods are listed in Table 1. Obviously, when the data length and shape change, the results calculated by the max pooling and average pooling methods may be the same, but the results calculated by the Huffman pooling method are significantly different. Therefore, the Huffman pooling method can effectively reduce the data dimension while retaining the differences between different data.
The results of different pooling methods.

It can be seen from Table 1 that for three different sets of data, the results of max pooling and average pooling methods are the same, which cannot reflect the difference of the original data, but the results of Huffman pooling on different data are obviously different. Therefore, the Huffman pooling presented in this article can not only achieve dimensionality reduction sampling, but also retain the different characteristics between the original data.
Huffman-CNN (H-CNN) construction
The ability of CNN to extract and classify features of research objects has been widely verified in the field of image recognition. For signals that have been converted to images, a CNN can train them and classify them well.
This article proposes the H-CNN based on the Huffman pooling and CNN mentioned above. The network structure includes a feature extraction stage and a classification stage. The feature extraction contains convolution layers, batch normalization layers, ReLU activation layers, and pooling layers. The classification stage is realized by the full connection layer.
The structures of the typical CNN and H-CNN for

The structure of the neural networks: (a) A typical convolutional neural network (CNN) structure for
Layer configurations of CNN and H-CNN models.

CNN: convolutional neural network; H-CNN: Huffman-convolutional neural network.
The new mixed loss function
Minimizing the distance between the distribution of training set and testing set is a common method to reduce generalization error on test set. When there are unknown faults in the diagnosis task, it is very difficult to predict the distribution of test set directly because no prior information about fault mode and fault degree can be obtained. To solve the above problems, a feasible solution is to make full use of the training set and establish the feature boundary between normal samples and fault samples by CNN. Although the feature boundary cannot be directly used to diagnose unknown fault types, it can be used to determine whether unknown data is abnormal. Therefore, a new mixing loss function is designed to improve the ability of the diagnostic model in homogeneous aggregation and heterogeneous differentiation. This is also an attempt to construct the feature boundary.
Generally, the loss function of CNN is designed according to the difference between the output of the network and the real label. As the training set of 
In practice, a softmax classifier is usually used to classify the output of CNN, so the loss function is usually designed as follows: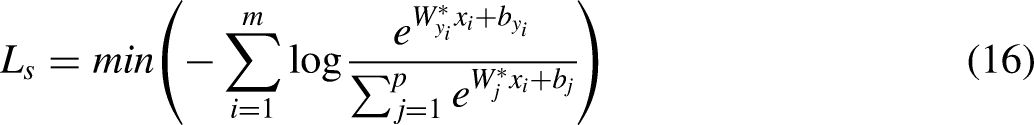
In this article, we introduce a mixture loss function considering homogenous clustering and heterogeneous differentiation in traditional CNN. By minimizing intra-class variation and maximizing inter-class variation, the new loss can distinguish the characteristics of normal data and fault data. Under the guidance of mixed loss and softmax loss, the network can explore some commonalities of feature spaces under different working conditions. By learning the characteristics of known health data, the ability to identify unknown data as abnormal data can be improved. In this way, the network has good generalization performance for unknown health data.
The mixed loss function is proposed with reference to the idea of center loss. In the DL method for face recognition, 39 the center loss is designed to enhance its recognition ability. The main idea behind center loss is to simultaneously learn the center of each class feature and penalize the distance between the feature and the corresponding class center.
In order to minimize the feature distance of intra-class and maximize the feature distance of inter-class, this article proposes a mixed loss function based on the distance between center point and feature. For the given set 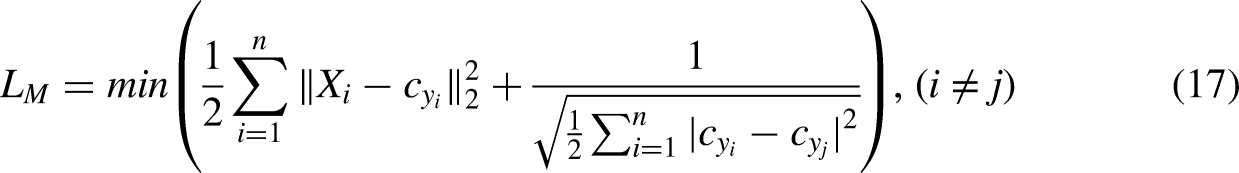


To ensure the features of clustering and dispersion between classes, a new mixed loss is added based on softmax loss. Finally, the new CNN is trained by optimization algorithm to minimize the loss function. The final loss function of H-CNN is defined as follows:
Case studies
This article focuses on the bearings and gears which are most widely used as rotor components in mechanical equipment for fault diagnosis and abnormal detection based on vibration signal drive.
In this section, the proposed method H-CNN is conducted on three different datasets, which are the cylindrical roller bearings dataset, deep groove ball bearings dataset, and gearbox dataset. The comparison test is mainly for the H-CNN and some other methods.
Data acquisition
Many types of faults and failure modes can occur to bearings and gears in various rotating machinery systems. Vibration signals collected from such a system are usually used to reveal its health condition. There are three datasets to verify the proposed method, including two bearing datasets and a gearbox dataset.
In two bearing datasets, experimental data were collected on a test rig with symmetrical structure and replaceable bearings as shown in Figure 12. The experimental device is mainly composed of a driving motor, a loading system, a shaft, a conveyer belt, and two bearings. The fault parts are prepared by means of electro-discharge machining. The bearing data used in this article are all vibration signals in the vertical direction.

The bearing experimental rig.
In the gearbox dataset, the time-domain fault vibration data of gear is downloaded from the FigShare website. Cao et al. completed the experiment. 40 The vibration signals are collected from a two-stage gearbox that is driven by a motor and loaded through a magnetic brake as shown in Figure 13. The torque is provided by a magnetic brake, which can be adjusted by changing the input voltage. A 32-tooth pinion and an 80-tooth pinion are mounted on the first stage input shaft. The second stage consists of a 48-tooth pinion and a 64-tooth pinion. The speed of the gears is controlled by an electric motor. Input shaft speed is measured by tachometer and gear vibration signals are collected by an accelerometer.

The gearbox experimental rig.
Case 1: Cylindrical roller bearing
In the first bearing dataset, the test bearing is N205, a cylindrical roller bearing. The sampling frequency is 20 KHz. Seven health conditions are set as: normal; inner race with wear fault; outer race with breakage fault; roller with pitting fault; roller with groove fault; roller with wear failure; roller with missing piece fault. Figure 14 shows the fault bearings. Cylindrical roller bearings were tested under 15 load conditions, with the speed ranging from 100 r/min to 1500 r/min. For each health condition under a single load condition, the vibration signals were processed into a series of samples with a length of 3600.

Six fault conditions of cylindrical roller bearings: (a) Inner race with wear fault, (b) outer race with breakage fault, (c) roller with pitting fault, (d) roller with groove fault, (e) roller with wear failure, and (f) roller with missing piece fault.
The samples are divided into training set and testing set. In order to prove that the method proposed in this article can identify whether the data of unknown health state is normal or not, we only use the normal data and four fault data, as shown in Figure 14(a) to (d) to train the network. The description of the cylindrical roller bearing data samples is listed in Table 3.
Label description of the cylindrical roller bearing dataset.

Case 2: Deep groove ball bearing
In the second bearing dataset, the test bearing is 6312, a deep groove ball bearing. The sampling frequency is 10 KHz. There are four load conditions, and the corresponding speeds range from 300 r/min to 1500 r/min (300/700/1100/1500). Five health conditions are set as normal; inner race with breakage fault; outer race with breakage fault; retainer with breakage fault; and ball with wear failure. The fault bearings are shown in Figure 15. For each health condition under a single load condition, the vibration signals were processed into a series of samples with a length of 3600.

Four fault conditions of deep groove ball bearings: (a) Inner race with breakage fault, (b) outer race with breakage fault, (c) retainer with breakage fault, and (d) ball with wear failure.
The samples are also divided into training set and testing set. We use the normal data and three fault data, as shown in Figure 15(a) to (c) to train the network. A detailed description of the samples is listed in Table 4.
Case 3: Gearbox system
In the gearbox dataset, the sampling frequency is 20 KHz. The nine different conditions are introduced to the pinion on the input shaft: normal; missing tooth; root crack; spalling; and chipping tip with five different levels of severity (“chip5a”, “chip4a”, “chip3a”, “chip2a”, and “chip1a”). Figure 16 shows the different health conditions. For each health condition, the vibration signals are sliced into a series of samples with a length of 3600.

Nine pinions with different health conditions.
Label description of the deep groove ball bearing dataset.

The samples are divided into training set and testing set. We use the normal data and six fault data (missing tooth/root crack/spalling/chip5a/ chip4a/chip3a) to train the network. A detailed description of the samples is listed in Table 5.
Label description of the gear dataset.

Comparison methods
To evaluate the performance of the proposed H-CNN model, traditional CNN and some other methods are used in this article to compare the prediction accuracy of the three cases.
The traditional CNN methods used for comparison in this article include CNN-2D and CNN-1D. CNN-2D uses the same input data as H-CNN. Compared to H-CNN, CNN-2D only differs in the pooling layer. The structure of CNN-2D is shown in Figure 11(a) and Table 2. The input of CNN-1D is a 1D raw signal that has not been converted into 2D image. Meanwhile, the handcrafted features are extracted in time domain and frequency domain. The time domain is characterized by peak, peak to peak, absolute mean, standard variance, margin index, peak index, impulse factor, skewness index, and kurtosis index. In the frequency domain, there are six features, which are frequency center, root mean square frequency, SD frequency, and CP1, CP2, and CP3.41,42 These statistical features are applied to shallow methods to classify health status. In this article, random forest (RF), SVM, KNN, and artificial neural network (ANN) are selected. In addition, some other advanced DL methods, including DBN, LSTM, and ResNet, are also used to compare and verify the effectiveness of the proposed method.
The average results of 10 tests are used as the evaluation basis in this article to reduce the error caused by randomness.
Results and discussion
Case 1: Cylindrical roller bearing
The images (

N205 cylindrical roller bearing raw signals conversion results: (a) Inner race with wear fault, (b) outer race with breakage fault, (c) roller with pitting fault, (d) roller with groove fault, (e) roller with wear failure, and (f) roller with missing piece fault.

The confusion matrices of different methods in case 1: (a) SVM, (b) CNN, and (c) H-CNN.
As shown in Table 3, the training data contains five classes of data and the testing data contains seven classes of data in case 1. The accuracy of the recognition, in this case, is defined as follows:
The results of case 1 are shown in Table 6. It is obvious that the proposed H-CNN method obtains a better result compared with other methods in this case. The average prediction accuracy is as high as 95.37% for known data and 91.93% for unknown data. It is obvious that the proposed H-CNN performs better to deal with the unknown data. Although the traditional CNN-2D achieves higher accuracy for the known data, it is weak in identifying the classes which do not exist in the training data.
Comparison result of Huffman-convolutional neural network (H-CNN) and other methods in case 1 (%).
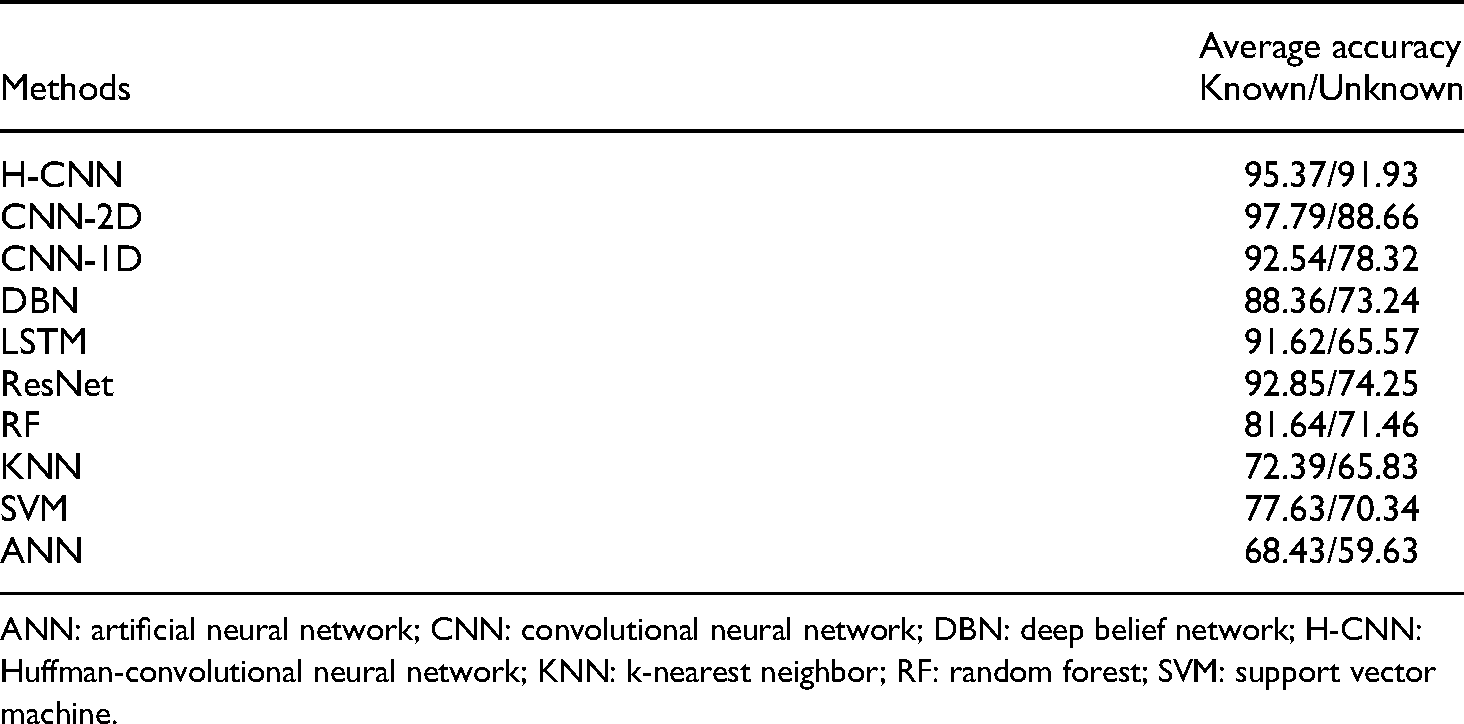
ANN: artificial neural network; CNN: convolutional neural network; DBN: deep belief network; H-CNN: Huffman-convolutional neural network; KNN: k-nearest neighbor; RF: random forest; SVM: support vector machine.
The confusion matrices of different methods in case 1 are shown in Figure18. SVM, CNN, and H-CNN mistake the data of fault (roller with wear failure) as normal data probability is 35.74%, 13.37%, and 9.65%, respectively. As for the fault (roller with missing piece fault), the misjudgment rates are 23.58%, 9.31%, and 6.49%, respectively. It is obvious that the traditional methods have poor ability to distinguish class labels 6–7. One of the possible reasons is that the proposed loss function can effectively enhance the difference between normal and abnormal data extracted by the network. So, the H-CNN has a better ability to identify fault data when the diversity of testing set is more than the training set.
Compared with case 2 and case 3, case 1 has more training data and test data, so case 1 is taken as an example to analyze the fault diagnosis performance of the proposed model under cross-working conditions. The dataset in Case 1 is reorganized into domains as shown in Table 7. The CDFD tasks are shown in Table 8.
Information of each domain in case 1.
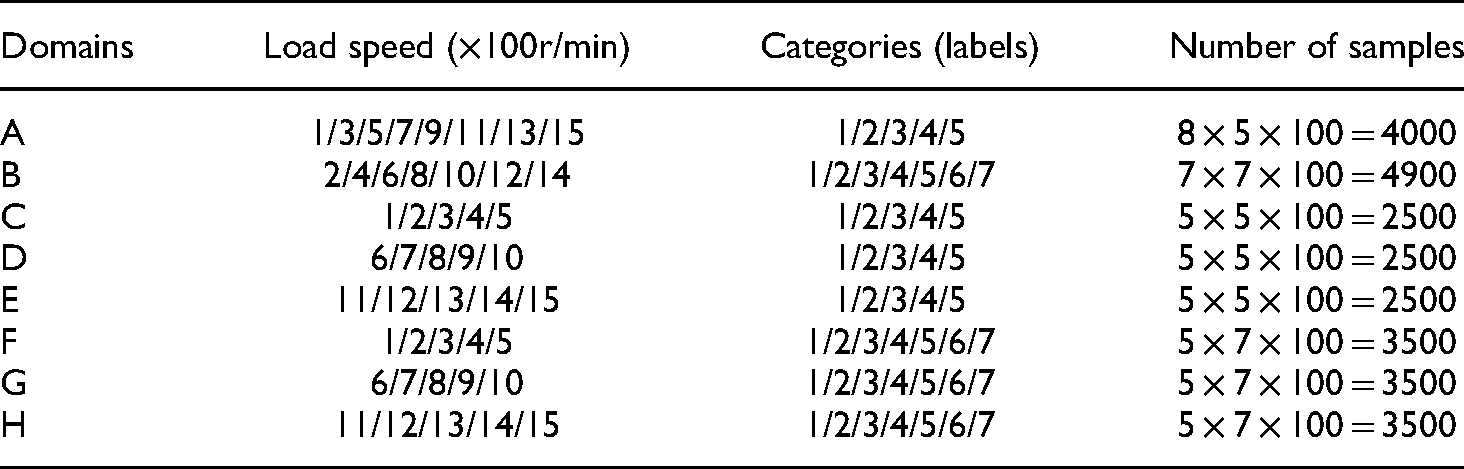
The cross-domain fault diagnosis (CDFD) tasks.

We compared the proposed method H-CNN with CNN-2D and CNN-1D on the above seven CDFD tasks. The comparison results are shown in Figure 19. In Figure 19, H-CNN performs better than CNN-2D to classify known faults on tasks T2, T3, T4, and T6. For identifying unknown fault, H-CNN outperforms CNN-2D and CNN-1D in all seven tasks. At the same time, compared with CNN-2D and CNN-1D, H-CNN has smaller accuracy deviation, more stable performance, and higher reliability of diagnostic results.

Comparison between H-CNN, CNN-2D, and CNN-1D for the seven cross-domain diagnosis tasks.
According to the trends shown in Figure 19, we grouped and analyzed the seven tasks according to the load speed of the SDs and TDs.
T2/T3/T5–T4/T6/T7: The average accuracy of T2/T3/T5 are lower than T4/T6/T7. In T2/T3/T5 tasks, the load speeds of the SDs are slower than that of the TDs. T4/T6/T7 tasks are just the opposite. T2/T3–T6/T7: The average accuracy of T3 is lower than T2 while the accuracy of T7 is higher than T6. When the load speed of the SD is lower than that of the TD, the greater the difference between the speeds, the lower the accuracy. Conversely, the greater the difference between the speeds, the higher the accuracy. T1–T2/T3/T4/T5/T6/T7: Compared with other tasks, T1 has the smallest difference between the working conditions of the TD and the SD, so the accuracy of T1 is higher than that of other tasks, which is in line with common sense.
Based on the above analysis, we guess that the fault features under high-speed conditions are more compatible than those under low-speed conditions. To further verify this conjecture, we independently trained and tested the data of each working condition. The results are shown in Figure 20. It is obvious that in the cylindrical roller bearing data set, the classification accuracy of low-speed conditions is always less than that of high-speed conditions. Under the test conditions of 100 r/min and 200 r/min, the classification accuracy of the known dataset is 86.39% and 90.47%, respectively. But it achieves to about 99% under the higher speed conditions. One possible reason is that the sampling frequency (20 khz) is too high, while the data length of the sample (3600) is too short. When the time domain signal is converted to the angle domain signal and the operating condition is 100 r/min, the rolling bearing rotates only 0.3 turns. Considering the fault frequency of rolling bearings, the fault characteristics are not obvious under the limited data length. It is difficult to extract useful features at low speeds. But when the proposed method H-CNN is utilized, the classification accuracy is improved under both low-speed conditions and high-speed conditions. This shows that the method proposed in this article can effectively enhance CNN's perception of less fault information.

The accuracy of CNN and H-CNN under different operating conditions: (a) The accuracy for the classes which are trained and (b) the accuracy for the classes which are not trained.
It can be seen from the calculation method of Huffman pooling that Huffman pooling fully considers the impact of each value in the filter. In order to intuitively show that Huffman pooling can weaken the common components of signals and strengthen the impact components, we calculate the HACL directly on the original signal and then transform the signal into 2D image. As shown in Figure 21, a raw signal is converted into 2D image by two different methods. It can be seen that HACL has a good capability of noise reduction. So the Huffman pooling method can effectively improve the noise reduction ability of CNN and the sensitivity of CNN to the shock component in the signal.

A raw signal converted into 2D image by different methods.
Case 2: Deep groove ball bearing
The images (

6312 deep groove ball roller bearing raw signals conversion results: (a) Inner race with breakage fault, (b) outer race with breakage fault, (c) retainer with breakage fault, and (d) ball with wear failure.
As shown in Table 4, the training data contains four classes of data and the testing data contains five classes of data. The accuracy of the recognition is defined as follows: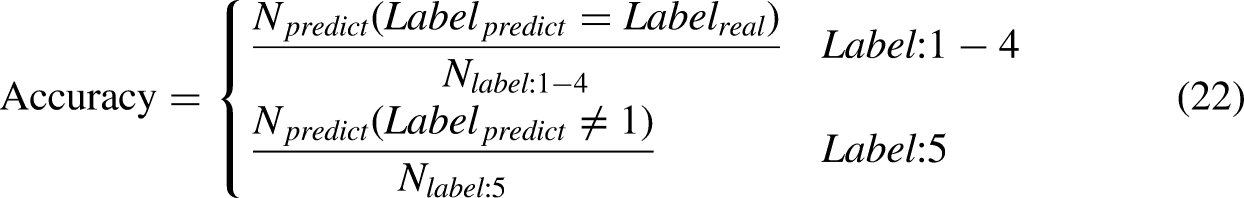
Comparison result of Huffman-convolutional neural network (H-CNN) and other methods in case 2 (%).

ANN: artificial neural network; CNN: convolutional neural network; DBN: deep belief network; H-CNN: Huffman-convolutional neural network; KNN: k-nearest neighbor; RF: random forest; SVM: support vector machine.
It can be seen that the proposed H-CNN method obtains a better result compared with other methods in this case. The mean prediction accuracy is as high as 98.62% for known data and 95.27% for unknown data. For the known data, the prediction results of CNN-2D, CNN-1D, DBN, LSTM, ResNet, RF, KNN, SVM, and ANN are 98.35%, 90.74%, 85.48%, 93.24%, 91.82%, 85.74%, 77.68%, 86.25%, and 70.24%, respectively. As for unknown data, the prediction results of CNN-2D, CNN-1D, DBN, LSTM, ResNet, RF, KNN, SVM, and ANN are 91.58%, 82.29%, 70.43%, 74.28%, 78.93%, 76.53%, 63.59%, 74.85%, and 63.65%, respectively. Table 9 shows that the proposed H-CNN has a good capability in fault diagnosis. Since there are fewer fault types in this case than in Case 1, the recognition accuracy, in this case, is generally higher than that in case 1.
The confusion matrices of different methods in case 2 are shown in Figure 23. SVM, CNN, and H-CNN mistake the data of fault (Figure 23(d)) as normal data probability is 25.15%, 8.42%, and 4.73%, respectively.

The confusion matrices of different methods in case 2: (a) SVM, (b) CNN, and (c) H-CNN.
Case 3: Gearbox system
The images (

Gearbox raw signals conversion results.
As shown in Table 5, the training data contains seven classes of data and the testing data contains nine classes of data. The accuracy of the recognition is defined as follows: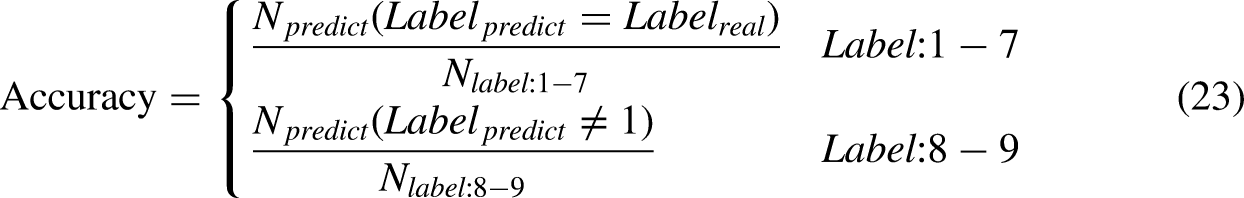
Comparison result of Huffman-convolutional neural network (H-CNN) and other methods in case 3 (%).

ANN: artificial neural network; CNN: convolutional neural network; DBN: deep belief network; H-CNN: Huffman-convolutional neural network; KNN: k-nearest neighbor; RF: random forest; SVM: support vector machine.
From Table 10, the proposed H-CNN method obtains a better result compared with other methods in this case. The average prediction accuracy is as high as 99.79% for known data and 96.32% for unknown data. For the known data, the prediction results of CNN-2D, CNN-1D, DBN, LSTM, ResNet, RF, KNN, SVM, and ANN are 98.63%, 93.13%, 80.67%, 90.28%, 92.44%, 83.57%, 75.34%, 89.76%, and 71.38%, respectively. As for unknown data, the results of CNN-2D, CNN-1D, DBN, LSTM, ResNet, RF, KNN, SVM, and ANN are 93.74%, 80.42%, 71.38%, 75.14%, 69.58%, 78.62%, 62.97%, 77.25%, and 65.82%, respectively.
The confusion matrices of different methods in case 3 are shown in Figure 25. SVM, CNN, and H-CNN mistake the data of fault (chip 2a) as normal data probability is 24.47%, 5.14%, and 3.54%, respectively. As for the fault (chip 1a), the misjudgment rates are 21.03%, 7.38% and 3.82%, respectively.

The confusion matrices of different methods in case 1: (a) SVM, (b) CNN, and (c) H-CNN.
In addition, as can be seen from Figure 25, since chip 2a and chip 1a belong to the same type of faults with different degrees, the three methods mentioned above are easy to identify them as chip-*a type. Moreover, the closer the fault degree is, the less accurate these identification methods can be in distinguishing them.
Conclusion
In this research, we mainly discuss the generalization ability of CNN when handling fault diagnosis tasks with more test data categories than training data categories. A new fault diagnosis method called H-CNN is proposed based on CNN and Huffman pooling for rotating assembly and a new objective function based on the mixed loss is designed for the H-CNN. Then, we apply the proposed method in three different datasets. To verify the effectiveness of the method proposed in this article, comparisons are made with some other state-of-the-art methods, including CNN-2D, CNN-1D, DBN, LSTM, ResNet, RF, KNN, SVM, and ANN. The average accuracy of classifying known faults under various working conditions are H-CNN—97.93%, CNN-2D—98.26%, CNN-1D—92.14%, DBN—84.84%, LSTM—91.71%, ResNet—92.37%, RF—83.65%, KNN—75.14%, SVM—84.55%, and ANN—70.02%. The average accuracy for unknown anomaly detection under various working conditions are H-CNN—94.51%, CNN—2D-91.33%, CNN—1D-80.34%, DBN—71.68%, LSTM—71.66%, ResNet—74.25%, RF—75.54%, KNN—64.13%, SVM—74.15%, and ANN—63.03%. Compared with other methods, the results show that the proposed method has a good performance in improving the accuracy of classifying the known data and detecting the unknown fault data as anomaly data. At the same time, compared with other advanced domain generalization methods, the proposed method does not need to adopt other complex auxiliary methods to extract fault features in advance, and only needs to use the simplest CNN network structure to achieve better generalization effect. Therefore, the method proposed in this article has a good development prospect in the field of fault diagnosis of rotating component of the mechanical equipment.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key R&D Program of China, National Natural Science Foundation of China and Science Research Project (grant numbers 2021YFA1003501, 52075117 and JSZL2020203B004).
Author biographies
Yuqing Li received the BE degree in mechanical design manufacturing and automation from the Harbin Institute of Technology, Harbin, China, in 2002, and the ME and PhD degrees in general mechanics from the Harbin Institute of Technology, in 2004 and 2008, respectively. He is currently an Associate Professor with the Harbin Institute of Technology. His main research interests are planning and scheduling of spacecraft, and spacecraft fault detection and diagnosis.
Mingjia Lei received the BS degree in Spacecraft Environment and Life Support Engineering in 2017, from the Harbin Institute of Technology, Harbin, China, where she is currently working toward the PhD degree in mechanics with the Deep Space Exploration Research Center. Her research interests include anomaly detection of spacecraft, fault diagnosis of machinery, intelligent fault diagnosis method, and spacecraft mission planning algorithm.
Yao Cheng received the PhD degree in general and fundamental mechanics from Harbin Institute of Technology, Harbin, China, in 2016. Since 2016, he has worked for Beijing Institute of Spacecraft System Engineering. His research interests include spacecraft reliability design and analysis.
Rixin Wang received the BE and ME degrees in computer science and the PhD degree in spacecraft design from the Harbin Institute of Technology, Harbin, China, in 1985, 1991, and 2003, respectively. He is currently an Associate Professor with the Department of Engineering Mechanics, Harbin Institute of Technology. His research interests include fault detection and diagnosis for machinery and spacecraft.
Minqiang Xu received the BE degree in electronics from Peking University, Beijing, China, in 1983, the ME degree in nuclear physics from Northeast Normal University, Changchun, China, in 1989, and the PhD degree in general and fundamental mechanics from the Harbin Institute of Technology, Harbin, China, in 1999. Since 2000, he has been a Professor with the Harbin Institute of Technology. His research interests include machinery and spacecraft fault detection and diagnosis, signal processing, and space debris modeling.