
Abstract
In peer-to-peer (P2P) social lending, it is important to predict the repayment of borrowers. P2P lending data are generated in real-time, but most of them are pending to decide the repayment because the deadline is not yet expired. Adding the unexpired data with appropriate labels into the training set could improve the performance of a prediction model, but the pseudo-labels cannot be certainly precise. In this paper, we propose an ensemble classifier composed of diverse convolutional neural networks (CNNs) of GoogLeNet, ResNet and DenseNet for the repayment prediction in social lending with the pseudo-labels approximated by an uncertainty handling scheme. The additional data labeled by Dempster-Shafer fusion of two semi-supervised learning methods boost up training of various models of CNNs, which are combined by weighted voting. A diversity measure is applied to constructing a pool of different models of CNNs that extract the effective features in the social lending data with labeling noise and predict the borrower's loan status. The experiment with the real dataset of 855,502 cases from Lending Club confirms that the diverse ensemble combined with weighted voting achieves the highest performance and outperforms conventional methods.
Introduction
Peer-to-Peer (P2P) social lending is one of the FinTech services that directly match borrowers with lenders. 1 In P2P lending, the lenders lend money to the borrowers by selecting them directly. If the borrower fails to complete the repayment, the lenders will suffer a financial loss. It is important to predict repayment in order to reduce the financial risk of the lenders.2,3
P2P lending platforms provide the borrower information such as demographic information, credit history, applied loan products, and current loan status to address information asymmetry or transparency issues4,5 since transactions occur online. The availability and prevalence of P2P social lending data have attracted many researchers. However, most of the data do not include whether the repayment will be completed because the repayment period has not expired. In the Lending Club dataset (https://www.lendingclub.com) for the past three years (2015–2017), the data that the repayment period has expired accounts for about 37% of the labeled data ("fully paid" and "charged off 1 ") and the data that the repayment period has not expired account for about 63% of the unlabeled data ("current", "in grace period", "late", and "default 2 "). Here, the data is considered as unlabeled if we do not know the label at the time of constructing a prediction model. The detailed specification of the data used for this study will be given in “Dataset”. 3
The performance of the model can be improved by utilizing the unlabeled data for training. 6 Many researchers employ the approach that trains the model as supervised learning with labeled and unlabeled data simultaneously by using the pseudo-labels, 4 which selects the class with the highest expected probability for the unlabeled data, as the actual label in relation to the low-density separation assumption between classes in semi-supervised learning.7,8 We adopt this approach and design a model for repayment prediction using unlabeled and labeled social lending data. However, this approach implies a problem that the pseudo-labels of unlabeled data may have label noise. 9
On the other hand, convolutional neural networks (CNN) can provide predictive models for large and complex data 10 and are known to be robust to label noise. 11 The CNN automatically extracts features by stacking the convolutional layer and the pooling layer several times. Discriminative features can be captured by constructing architectures with different depths and widths.12–14 Recently, a model for combining convolutional neural networks (CNNs) in various fields has been proposed. 15 The ensemble method is generally employed to improve the performance of the individual base classifiers. The strength of the ensemble method lies in its ability to correct errors caused by some of the members, such as class noise. 16 Several researchers discussed that ensemble members should be diversified in terms of errors.17,18 Ensembles with members of high diversity tend to have higher prediction performance.
In this paper, we propose a heterogeneous ensemble composed of diverse CNNs for repayment prediction in social lending with pseudo-labels. We exploit two semi-supervised learning methods to generate pseudo-labels from the unlabeled data 8 and predict the loan status of the borrowers using the ensemble model of the CNNs, where members of the ensemble are constructed based on a diversity measure and combined with weighted voting. Weighted voting also improves performance by weighing high-performance classifiers. The proposed ensemble model that consists of diverse classifiers extracts different features by using unlabeled data with pseudo-labels and predicts the loan status robustly regardless of label noise.
The Lending Club dataset has been used for experiments. We conduct the comparison with the individual classifiers and the homogeneous ensemble methods in order to evaluate the performance of the proposed method in the dataset with some pseudo-labels. The performance of the ensemble model is presented with diversity measures. The main contributions of this paper are as follows.
A novel method is proposed for predicting repayment in social lending by adopting the ensemble approach with deep learning models and achieving state-of-the-art performance compared with the conventional methods. The idea is confirmed by the real dataset of 855,502 cases from Lending Club to reflect the inherent complexity of the problem. We focus on finding a solution to the problem of societal sustainability to encourage economic growth with a new field of financial technology.
This paper is organized as follows. “Related works” reviews the studies related to social lending. “The Proposed Method” presents the structure and description of the proposed method. “Experiments” shows the experimental results to verify the usefulness of the proposed method. Finally, “Conclusions” concludes this paper and discusses future work.
Related works
Many researchers have attempted various approaches to predict repayment in P2P social lending. Table 1 shows the studies related to repayment prediction in social lending so far. Most studies use various feature engineering algorithms to improve the performance or predict repayment using a simple model or ensemble model.
Related studies in P2P social lending.

Feature engineering has been widely used to improve the performance of repayment prediction models. Lin et al. proposed a credit risk assessment model using Yooli dataset, P2P lending platform in China. 22 They used the nonparametric statistical method to identify the borrowers’ demographic characteristics and extract the features that affect the default. A total of 10 variables including gender, age, marital status, and loan amount were extracted and a credit risk assessment model was designed using logistic regression analysis. Malekipirbazari et al. used the random forest to assess risk in social lending. 29 Through sophisticated preprocessing, they extracted 15 features and evaluated the performance according to the number of features. As the number of features increases, a higher performance is achieved.
Recently, various ensemble methods have been introduced instead of a single model for predicting repayment. In particular, the random forest, the ensemble model of the decision trees, leads to high performance for repayment prediction. Fu predicted defaults by combining neural networks with random forests to capture non-linearity. 25 Li proposed an ensemble model composed of heterogeneous classifiers in order to effectively predict the imbalanced data and achieved a high performance by weighted fusion of XGBoost, DNN, and logistic regression. 20
The approach to designing a predictive model that considers the characteristics of social lending data is rare. Existing feature engineering and statistical techniques are not suitable for managing the big data of social lending that are increasing every year, 30 and ensemble models are favored to improve the performance. In this paper, we propose a novel approach to design a predictive model with CNNs adapted with the additional data that the repayment period has not expired to predict the repayment of borrowers.
The proposed method
Figure 1 shows the overall scheme of the proposed method. The unlabeled data that the repayment period has not expired is labeled as "fully paid" or "charged off" by two semi-supervised learning methods with different approaches, and the final label is assigned based on the Dempster-Shafer theory.31,32 Unlabeled data with pseudo-labels and labeled data are learned together in feature space by various CNNs. The feature space is used to train the classifier to model the features of the borrower. The social lending data is projected into the representation space learned by diverse base CNNs. In the base classifier pools with four different architectures of CNN, classifiers are selected using Q-statistic as a diversity measure. We combine the probability values from the various classifiers using weighted voting and finally predict the borrowers’ loan status.
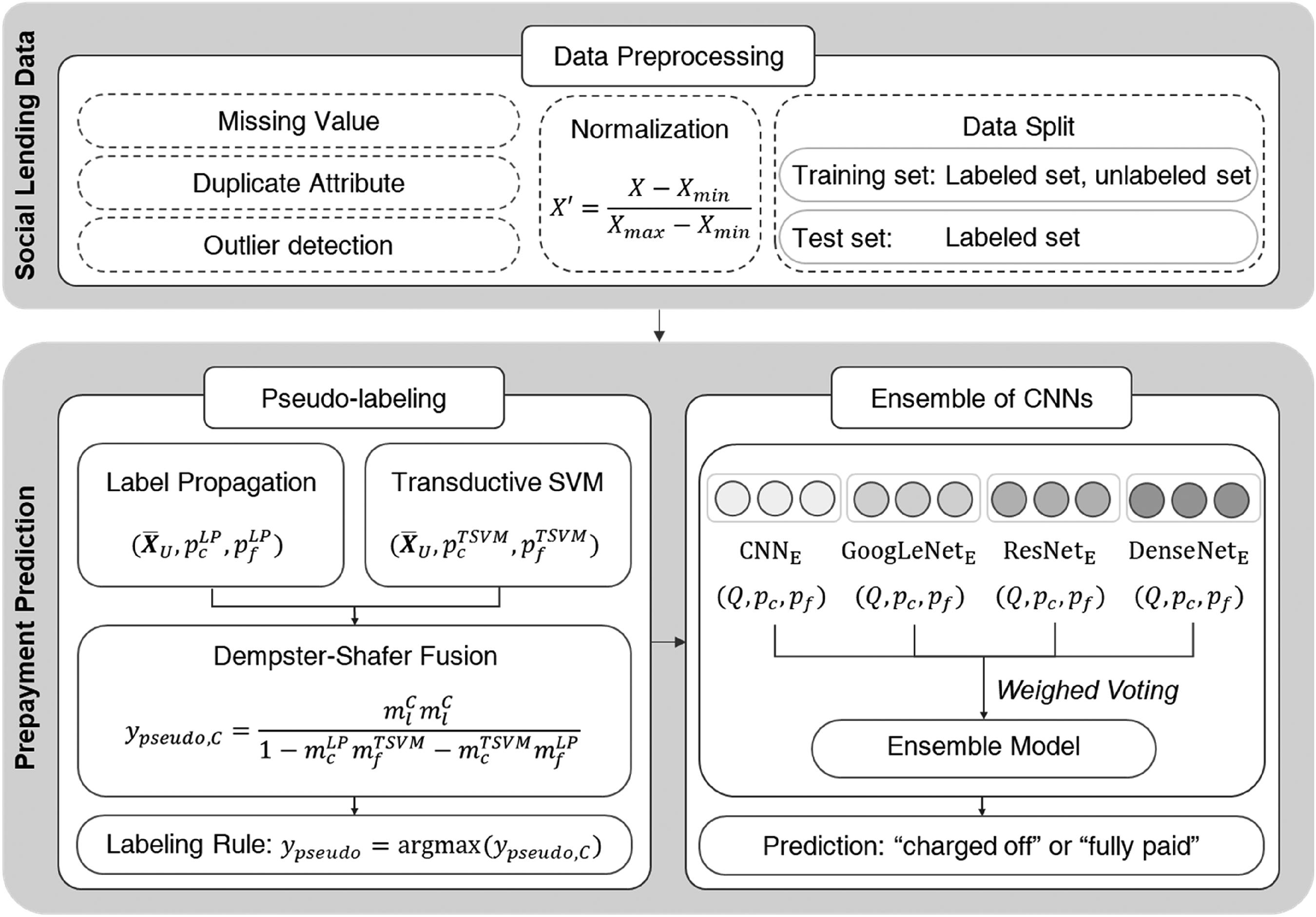
The overall scheme of the proposed method.
Pseudo-labeling
Label propagation
33
and transductive support vector machine (TSVM)
34
assign classes for loan status to unlabeled data, respectively. We then combine the probability values for each class using Dempster-Shafer fusion.
8
Figure 2 shows the pseudo-labeling process. Suppose that

The process of pseudo-labeling.
Label propagation
Label propagation is a method of labeling by propagating label information about repayment of the borrowers based on the similarity distance between observations.
33
It is estimated based on cluster assumptions that closely located observations belong to the same class.
35
Transition matrix 

Transductive support vector machine
TSVM learns to increase the margin of decision boundaries as in the existing support vector machines 34 using a large amount of unlabeled data. Salient features of the borrower are transferred by learning feature space considering both labeled and unlabeled data.
TSVM generates the initial classifier by performing inductive learning using the labeled data. It then uses the classifier to assign labels to unlabeled data, exchange classes of two observations and train the classifier until a pair of observations in each class with a slack value more than zero does not exist
Dempster-shafer fusion
Dempster-Shafer's theory is a probabilistic inference method in uncertain situations.31,32 Dempster-Shafer fusion (DSF) combines the class probabilities of two semi-supervised learning to carefully determine the classes for the loan status. This theory computes the class probabilities for all possible cases ({"fully paid"}, {"charged off"}, {"fully paid", "charged off"}) based on the power set of classes. DSF inforces more precise labeling by considering the case that two classes are mixed together.


Ensemble of CNNs
Diverse CNNs
This section presents the four models of CNN employed in the ensemble as a base classifier. Each model has a different network topology and extracts diversified features. Some models except plain CNN have a bottleneck layer as a 1 × 1 convolution, and ResNet 13 and DenseNet 14 use shortcut connections. Figure 3 shows the structure of each network employed in the ensemble.

The structures of base classifiers employed in the ensemble.
Convolutional Neural Network. Unlabeled data with pseudo-labels and labeled data are used as input to the CNNs. CNNs extract discriminative features through a local connection in the borrowers and loan product information of a large amount of social lending data. CNNs perform convolution operations instead of matrix multiplication and generate output values from social lending data through the convolutional layer as the following equation (6).
36


Several convolutional and pooling layers can be stacked up to play a role of feature extraction hierarchically. The feature-maps generated by repeating the convolutional layer and the pooling layer from the social lending data are arranged one-dimensionally through the fully connected layer, and the loan status is predicted through the softmax classifier.
The structure of the CNN is stacked twice with alternating convolutional and pooling layers. Followed by two fully connected layers and a dropout 38 with a probability of 0.25 to prevent overfitting. Finally, the class probability for each loan status is output through the softmax classifier.
GoogLeNet. The key idea of GoogLeNet 12 is to construct a sparse structure in the conventional CNN model to process the dense elements. Several inception modules are used to combine convolution operations with filters of various sizes in parallel. Using different size filters can extract features from various aspects of social lending data and form discriminative feature representation.
The inception module consists of 1 × 1 convolution, 1 × 3 convolution, 1 × 5 convolution, and 1 × 2 pooling layer. The 1 × 1 convolution used in GoogLeNet has a role to merge similar features from multiple feature maps and reduce the number of feature maps. The structure of GoogLeNet initially controls the number of feature maps with the convolutional layer and pooling layer, and two inception modules are applied. Followed by two fully connected layers, and the final probability is output through the softmax classifier.
ResNet. Residual network
13
learns the difference between input and output and performs convolution operation with the value added to the input using shortcut connections. The general CNN considers the output of the 

DenseNet. It has direct connections to all subsequent layers as dense connectivity.
14
The low-level and high-level features extracted in the social lending data are reused using dense connectivity. Suppose that the output through the 
The DenseNet initially passes through a convolutional layer and a pooling layer to resize the feature-map. The structure consists of two dense blocks and one transition layer therebetween. The dense block includes a directly connected convolutional layer, and diversified features are extracted from the characteristics of the borrower or inherent property of the loan product in the social lending data. The transition layer for the down-sampling layer consists of a convolutional layer and a pooling layer, merging the representative features of social lending data. Each feature-map passes through two fully connected layers and outputs a probability value through the softmax classifier.
Diversity and similarity
One of the important steps in designing an ensemble model is ensemble selection, and it is also important to construct diverse classifiers. 39 The selection criteria can be diversity, similarity, and data handling, 40 which can be measured in different ways: Pairwise and global diversity measures. The pairwise diversity measure is computed for each pair of classifiers and averaged over two or more classifiers. The pairwise diversity is calculated for two repayment prediction algorithms from the relative amounts between the correct and incorrect predicted values. Table 2 shows the notation for the percentage of data instances in the classified dataset.
The notation of the predicted values from two classifiers.
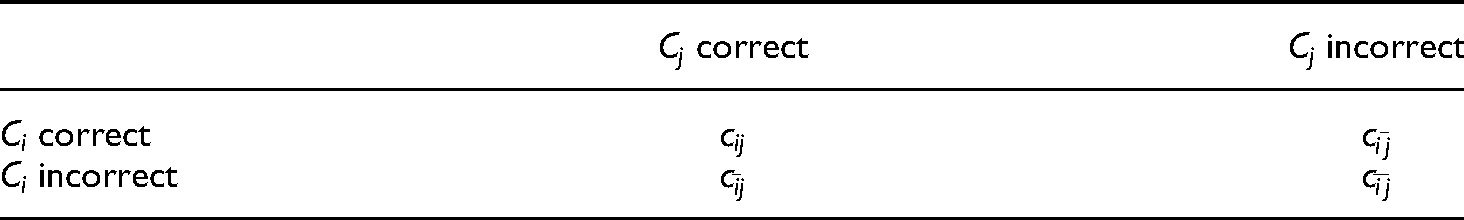
Here, i and j mean classifiers,
Two pairwise diversity measures are introduced. Q-statistic 

We introduce an entropy measure as a global diversity measure.
43
The entropy measure assumes the most diverse when the correct member prediction is equal to 
The similarity is measured in the output of the classifier. Euclidean distance
Ensemble based on diversity using weighted voting
This section describes the proposed ensemble method. The proposed ensemble algorithm consists of two parts. First, we select the classifier subsets to construct the final ensemble in the four base classifier pools using the diversity measure. Second, we combine selected classifiers using weighted voting. Figure 4 shows the overall procedure for the ensemble of base classifiers.

Overall procedure for the ensemble of CNNs.
First, we set an arbitrary initial weight for locally connected edges of CNNs with four architectures using the training set. The backpropagation algorithm is used to perform training in a number of epochs and the weights of CNNs are adjusted. Then, we construct a homogenous ensemble in four base classifiers pool using Q -statistic 41 as a pairwise diversity measure. The diversity Q is calculated for the validation set. The four models are combined by increasing the number of classifiers. The number of ensemble members is fixed when the Q value is closest to zero (when diversity is the greatest). We improve the prediction performance using the ensemble with a large diversity, and the ensemble with four different structures extract diverse features from social lending data.
Second, we combine the ensemble models of the four CNNs to determine the final prediction. Heterogeneous ensembles are more diverse
44
and known to provide better results.
45
It has also been shown that ensembles of heterogeneous models in credit scoring improve performance.
46
In this paper, a weighted voting scheme
47
is utilized, in which weights are assigned according to the classification accuracy over validation data. Weighted voting is applied to the output generated from the ensemble of CNNs. The ensemble method based on weighted voting generates the final output for the loan status, and the weight is determined by the accuracy 

Experiments
Dataset
In this paper, we use P2P social lending transaction data provided by Lending Club. The data consist of 111 attributes such as loan amount, amount of payment, loan period, and loan status as a predictor variable. Only the "Current" data is used for data that the repayment period has not expired, and "fully paid" and "charged off" are used for data that the repayment period has expired. A total of 855,502 data are collected from 2015 to 2016.
63 attributes and 679,596 data are used by excluding the attributes that cannot be used for prediction such as borrowers’ ID, URL, description of loans, attributes with more than 80% of missing values, duplicate attributes, and attributes that are filled after the borrower starts to repay. 48 Table 3 shows the used variables.
The list of used attributes.

CNN has an input format in the range [0, 1]. The 63 attributes used for prediction are preprocessed. Categorical variables are encoded as dummy variables, and continuous variables are min-max normalized by removing 1% of outliers.
Results
In this section, before presenting other experimental results, we briefly describe the results of pseudo-labeling. Then, we present the performance of ensemble models according to diversity. Experiments show that the greater the diversity, the better the performance. In addition, we demonstrate the performance comparison with single classifiers, an ensemble of homogeneous classifiers, and an ensemble of heterogeneous classifiers. The ensemble model achieves higher performance, especially when constructed with heterogeneous classifiers, outperforming homogeneous ensembles.
We conduct LP, TSVM, and DSF using 322,536 unlabeled data and 249,942 labeled data. About 26% of pseudo-labels were labeled as "unknown," and about 94% except "unknown" was labeled "Fully Paid." Based on the pseudo-labeling results, the training set used for repayment prediction is 488,012 (249,942 labeled data + 238,070 unlabeled data with pseudo-labels). Table 4 shows the pseudo-labeling results.
The result of pseudo-labeling.

We constructed an ensemble model based on a diversity measure. As new classifiers are added to the ensemble for four single models, we measure the diversity to check the contribution of the last classifier. If diversity increases, we construct an ensemble until the maximum size of the ensemble is reached. Figure 5 shows the relationship between diversity and performance according to the number of new classifiers in the validation set. The ensemble method employs weighted voting. CNN and DenseNet show that the greater the diversity, the better the performance. We combine the classifiers with the largest diversity.

The performance and diversity of base classifiers.
The base classifiers for constructing the ensemble include 24 CNNs, 24 GoogLeNets, 6 ResNets, and 25 DenseNets. Table 5 shows the comparison of the performance with single models, ensemble models of the homogenous classifiers, and a combination model of four ensemble models using weighted voting. Here, n denotes the number of classifiers to be constructed. The proposed method achieves higher performance than the other models, except for the recall that it is the second-best followed by DenseNet. Even though the difference is slight, we need further analysis of the results because this kind of decision support system can be ethically controversial.
The comparison of performance with base and ensemble models.
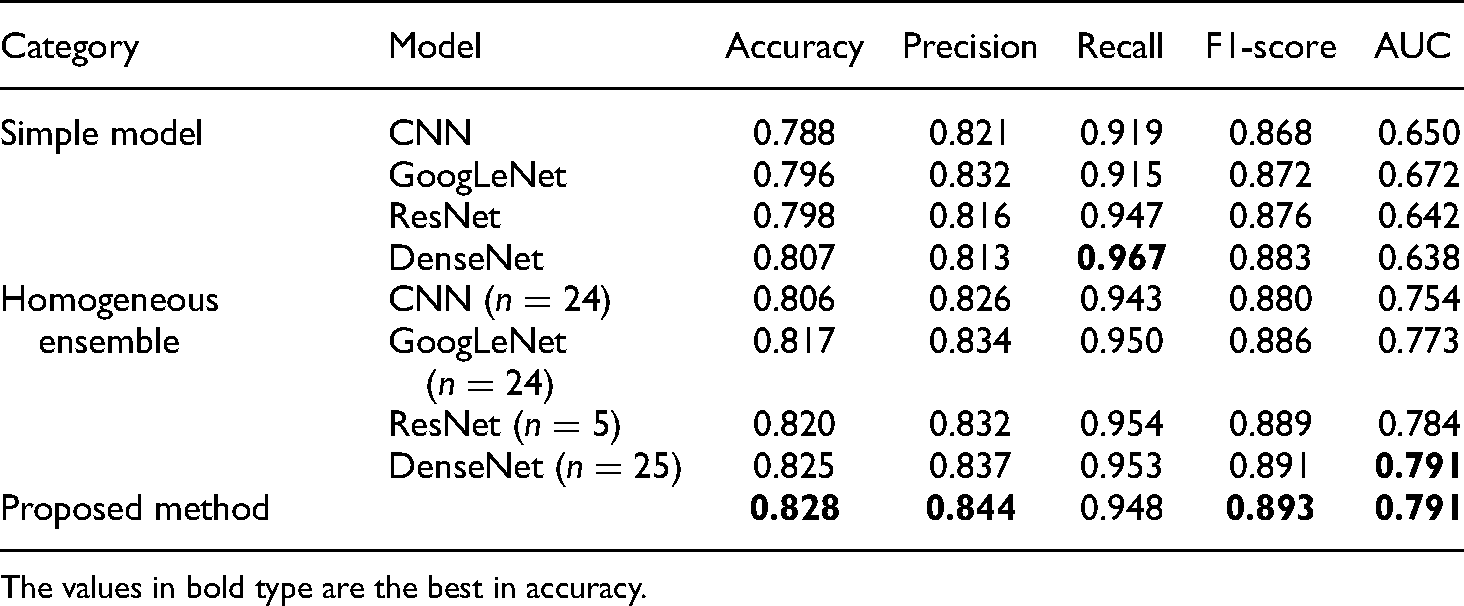
The values in bold type are the best in accuracy.
We measure the diversity, similarity, and performance according to a combination of heterogeneous ensembles using weighted voting in the validation set. Table 6 shows the performance for all combinations of heterogeneous ensembles. The darker the color; the greater the diversity, the lower the similarity, and the higher the performance. Experimental results show that the performance of the four heterogeneous models outperforms the other ensemble models and the combination of the models is diverse. The combination of CNN, GoogLeNet, and ResNet is the most diverse and the combination of ResNet and DenseNet are the most similar. The combination of the four models is presented as achieving higher performance than the combination of CNN, GoogLeNet, and ResNet models because DenseNet has achieved the highest performance among single models.
Comparison of diversity, similarity, and performance with ensemble models.


c: CNN, g: GoogLeNet, r: ResNet, d: DenseNet.
Conclusions
In this paper, we have presented CNNs with pseudo-label data for repayment prediction in P2P social lending and proposed an ensemble model which consists of diverse CNNs. Large amounts of unlabeled data are available in social lending. In order to improve the performance of the repayment prediction, diverse CNN models have demonstrated high performance compared with other methods by adding unlabeled data with pseudo-labels combining the two semi-supervised learning methods. The proposed heterogeneous ensemble model, which is composed of diverse classifiers, extracts additional features by adding the information of the borrowers whose repayment period has not expired and can help to select the borrower for future lenders.
The deep learning model has difficulty understanding the internal operation. Future studies should be conducted to explain the factors that have a significant impact on repayment prediction. Alternatively, an approach like case-based reasoning might be another option that frames the problem differently to predict a risk category to be associated with a loan request and addresses some of the implied ethical concerns. 49 In addition, the ensemble approach accompanies the overhead of computation for inference as well as training. We need to reduce the computational cost to deploy the method of practice. Another research issue is that social lending is traded online so we can use the additional dataset from social networks like Facebook and Twitter. We expect that combining borrowers' social lending data with social network data will improve the performance of repayment prediction to encourage economic growth.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2021-0-02068, Artificial Intelligence Innovation Hub; No. 2022-0-00113, Developing a Sustainable Collaborative Multi-modal Lifelong Learning Framework).
Notes
Author biographies
Ji-Yoon Kim received the MS degree in computer science from Yonsei University, Seoul, Korea, in 2019. Her research interests include probabilistic recognition models, and deep learning.
Sung-Bae Cho received the BS degree in computer science from Yonsei University, Seoul, Korea and the MS and PhD degrees in computer science from KAIST (Korea Advanced Institute of Science and Technology), Taejeon, Korea. He was an invited researcher of Human Information Processing research laboratories at ATR (Advanced Telecommunications Research) institute, Kyoto, Japan from 1993 to 1995, and a visiting scholar at University of New South Wales, Canberra, Australia in 1998. He was also a visiting professor at University of British Columbia, Vancouver, Canada from 2005 to 2006, and at King Mongkut's University of Technology at Thonburi, Bangkok, Thailand in 2013. Since 1995, he has been a professor in the Department of Computer Science, Yonsei University, and a Underwood distinguished professor from 2021. His research interests include neural networks, pattern recognition, intelligent man-machine interfaces, evolutionary computation, and artificial life. He was the recipient of the Richard E. Merwin prize from the IEEE Computer Society in 1993. He received several Distinguished Investigator Awards from Korea Information Science Society in 2005, and Gaheon Sindoricoh in 2017. He is also a recipient of Service Merit Medal from Korean government in 2022.