
Abstract
In the past decade, convolutional neural networks (CNNs) and transformers have achieved wide application in semantic segmentation tasks. Although CNNs with transformer models greatly improve performance, the global context modeling remains inadequate. Recently, Mamba achieved great potential in vision tasks, showing its advantages in modeling long-range dependency. In this article, we propose a lightweight efficient CNN-Mamba network for semantic segmentation, dubbed as ECMNet. ECMNet combines CNN with Mamba skillfully in a capsule-based framework to address their complementary weaknesses. Specifically, we design an enhanced dual-attention block for a lightweight bottleneck. In order to improve the representation ability of the feature, we devise a multi-scale attention unit to integrate multi-scale feature aggregation, spatial aggregation, and channel aggregation. Moreover, a Mamba enhanced feature fusion module merges diverse level feature, significantly enhancing segmented accuracy. Extensive experiments on two representative datasets demonstrate that the proposed model excels in accuracy and efficiency balance, achieving 70.6% mIoU on Cityscapes and 73.6% mIoU on CamVid test datasets, with 0.87 M parameters and 8.27G FLOPs on a single RTX 3090 GPU platform. Source code will be available at https://github.com/feixiangdu/ECMNet.
Introduction
Semantic segmentation aims to assign a label to each pixel in a given image, which is widely applied in autonomous driving, 1 remote sensing,2–5 agriculture, 6 and medical image, 7 and more. Early semantic segmentation primarily relied on convolutional neural networks (CNNs), employing techniques like large convolutional kernels, 8 dilated convolutions, 9 and feature pyramids 10 to extend receptive fields. However, these CNN-based approaches remained limited in capturing long-range dependencies. The advent of transformers 11 enabled more effective global context modeling in subsequent segmentation methods. Learning global context dependencies is essential for extracting global semantic features, particularly in intensive tasks like semantic segmentation. The rise of visual transformer (ViT) 12 has injected a new paradigm for semantic segmentation. Segmentation transformer (SETR) 13 slices images into sequences for the first time and captures global context feature through a self-attentive mechanism, outperforming traditional CNN models on complex scene datasets such as Cityscapes. Meanwhile, SegFormer 14 further optimized the architectural design by proposing a hierarchical transformer encoder with a lightweight multi-layer perceptron decoder to achieve multi-scale feature fusion. However, the square-level computational complexity of the transformer limits its application to high-resolution images with insufficient sensitivity to local details.
To tackle the limitation of the above single model and extract fine spatial details, some models treated semantic segmentation tasks by integrating CNN with a transformer. For instance, HResFormer, 15 PFormer, 16 and DMFC-UFormer 17 have achieved satisfactory results in the field of medical image segmentation. However, the self-attention mechanism in CNN-transformer methods still poses challenges in terms of speed and memory usage when dealing with long-range visual dependencies, especially when processing high-resolution images.
Unlike previous transformers, Mamba 18 shows great potential for high-resolution images by efficient sequence modeling with linear complexity. Vision Mamba 19 have recently demonstrated remarkable success in various computer vision tasks. For example, in the field of three-dimensional (3D) medical imaging, SegMamba 20 achieves real-time inference on the colorectal cancer dataset CRC-500, with a speedup of 30% compared to 3D UNet. In addition, CM-UNet 21 introduces a Mamba decoder into a CNN encoder to bridge local and global features through a channel-space attention mechanism, achieving higher mIoU on the ISPRS Vaihingen dataset.
To accommodate limited computational resources and mobile device applications, lightweight semantic segmentation models receive higher attention. For example, LEDNet 22 employed channel split-and-shuffle operations within residual blocks, significantly lowering computational complexity. While CFPNet 23 designed a channel-wise feature pyramid (CFP) module to significantly reduces model parameters and model scale by extracting various-level feature maps and contextual feature information jointly. LETNet 24 used a lightweight dilated bottleneck (LDB) module and feature enhancement (FE) module for enhanced efficiency and accuracy with reduced model complexity.
Motivated by the success of Mamba and lightweight approaches in semantic segmentation tasks, we propose ECMNet, an efficient CNN-Mamba hybrid network for lightweight semantic segmentation, optimized for minimizing model size and computational requirements. As depicted in Figure 1, the proposed ECMNet achieves an excellent balance between the accuracy, inference speed of the model, and model parameters. The main contributions of our article are fourfold:
We firstly propose a novel lightweight efficient CNN-Mamba network (ECMNet) for semantic segmentation. ECMNet utilizes a U-shape encoder-decoder structure as a backbone and regards the feature fusion module (FFM) as a capsule network to capture global context information. Specifically, FFM introduces a two-dimensional-selective-scan (SS2D) block, a variant of Mamba, to learn long-range dependencies. We design a lightweight enhanced dual-attention block (EDAB) to extract multi-dimensional semantic information. EDAB consists of dual-direction attention (DDA), channel attention (CA), and various convolution modules, realizing less model parameters and computational quantities. We develop a multi-scale attention unit (MSAU) to improve the representations ability of feature, which further refines the local details and global contextual information. ECMNet achieved 70.6% mIoU on the Cityscapes dataset on a single RTX 3090 GPU with only 0.87 M of parameters, realizing the better trade-off between performance and parameters. Meanwhile, our proposed method achieved 73.6% of the highest performance on the CamVid dataset, which demonstrates the effectiveness and generalization of our proposed ECMNet.

Accuracy and model parameters comparison of efficient convolutional neural network-Mamba network (ECMNet) and other lightweight models on the CamVid dataset. A larger circle denotes a faster inference speed.
Related work
Semantic segmentation methods based on CNN and transformer
Due to the efficient local feature representation capabilities of CNNs, semantic segmentation has also advanced tremendously. Following the revolutionary CNN, FCN, and U-Net, many new architectures have been refined on this basic principle. However, CNN-based methods face issues with the trade-off between image resolution and a limited receptive field. To address these challenges, DeepLab and PSPNet build atrous spatial pyramid pooling using atrous convolutions in a parallel way, which better utilizes various-level contextual feature information.
Additionally, researchers have drawn much interest in the self-attention mechanism because of the advantages in modeling feature dependencies. ECANet 25 introduced a local cross-channel interaction mechanism that operates without dimensionality reduction and an adaptive selection method for determining optimal kernel sizes in one-dimensional convolutions. In addition, DANet 26 employed ResNet as its backbone architecture, integrating parallel attention modules in both spatial and channel dimensions. This design effectively captures long-range feature dependencies, enhancing segmentation performance.
However, all these methods build an enormous computational challenge for the machine. So the lightweight semantic segmentation networks were proposed. For example, ICNet 27 captured high-level semantic information and low-level spatial details by utilizing multi-scale images as input. BiseNet 28 and BiseNet-v2 29 introduced a two-path architecture, which is responsible for providing detailed information supplement and extracting deep semantic information, respectively. Furthermore, in order to enhance the feature expression and reduce the computation, the point-wise attention was designed. ESPNet 30 and ESPNet-v2 31 fused decomposed convolution into point-wise convolution, which greatly reduces the number of parameters and computation. In addition, LEDNet 22 introduced an attention pyramid network in its decoder, effectively reducing overall model complexity while maintaining performance. To alleviate the limitation of the single model and extract fine spatial details, some methods combined CNN with transformer came into being. For instance, LETNet 24 incorporated two key components: a lightweight dilated bottleneck module and an enhanced feature refinement module combining CNN-transformer capsules. This architecture can capture long-range feature dependencies for better segmentation results. HAFormer 32 integrates CNN-based hierarchical feature learning and transformer-based global context modeling to further capture global representation. While existing methods still have room for enhancement in global feature representation and complexity.
Semantic segmentation methods based on Mamba
Mamba 18 has achieved great success because of sequence modeling with linear complexity. Meanwhile, Vision Mamba 19 have recently proved once again the possibilities in the field of computer vision tasks, especially in semantic segmentation. For example, CM-UNet 21 built the core segmentation decoder by employing channel and spatial attention as the gate activation condition of the vanilla Mamba, which enhances the feature interaction and global-local information fusion. RS3Mamba 33 utilized VSS blocks 18 to achieve better segmentation in remote sensing by constructing an auxiliary branch to enhance a convolution-based main branch. Sigma 34 introduced two novel modules, a Siamese encoder and a Mamba-based fusion mechanism, to achieving global receptive fields with linear complexity.
Although the above methods have achieved good results, the current Mamba-based segmentation methods applied to remote sensing without considering the model size, which results in large model parameters. In addition, a one-dimensional sequence input of Mamba in the image domain disrupted local structural relationships with global context information. On the other hand, the absence of fine-grained local features results in imprecise segmentation; CNN architectures effectively compensate by preserving spatial details through local feature extraction. In order to better handle the semantic segmentation task and reduce model parameters, we tend to explore a novel lightweight method integrating CNN with Mamba.
Proposed method
Overall network architecture
As shown in Figure 2, the overall network architecture of our proposed ECMNet consists of four components: a CNN encoder improved with EDABs, a CNN decoder with a subtle difference from the encoder, an efficient Mamba-based feature fusion module, and three long skip connections enhanced with a multi-scale attention unit. Specifically, the CNN-based encoder-decoder architecture extracts localized features for detailed spatial representation. The Mamba-based FFM can capture complex spatial information and long-range feature dependencies by a state space model (SSM) to optimize global feature representations and computational complexity. The three long-distance skip connections generate more high-quality segmentation by focusing on low-level spatial information and high-level semantic information, respectively. The above mentioned elaborated modules make it more efficient for ECMNet to fully integrate local and global feature information.
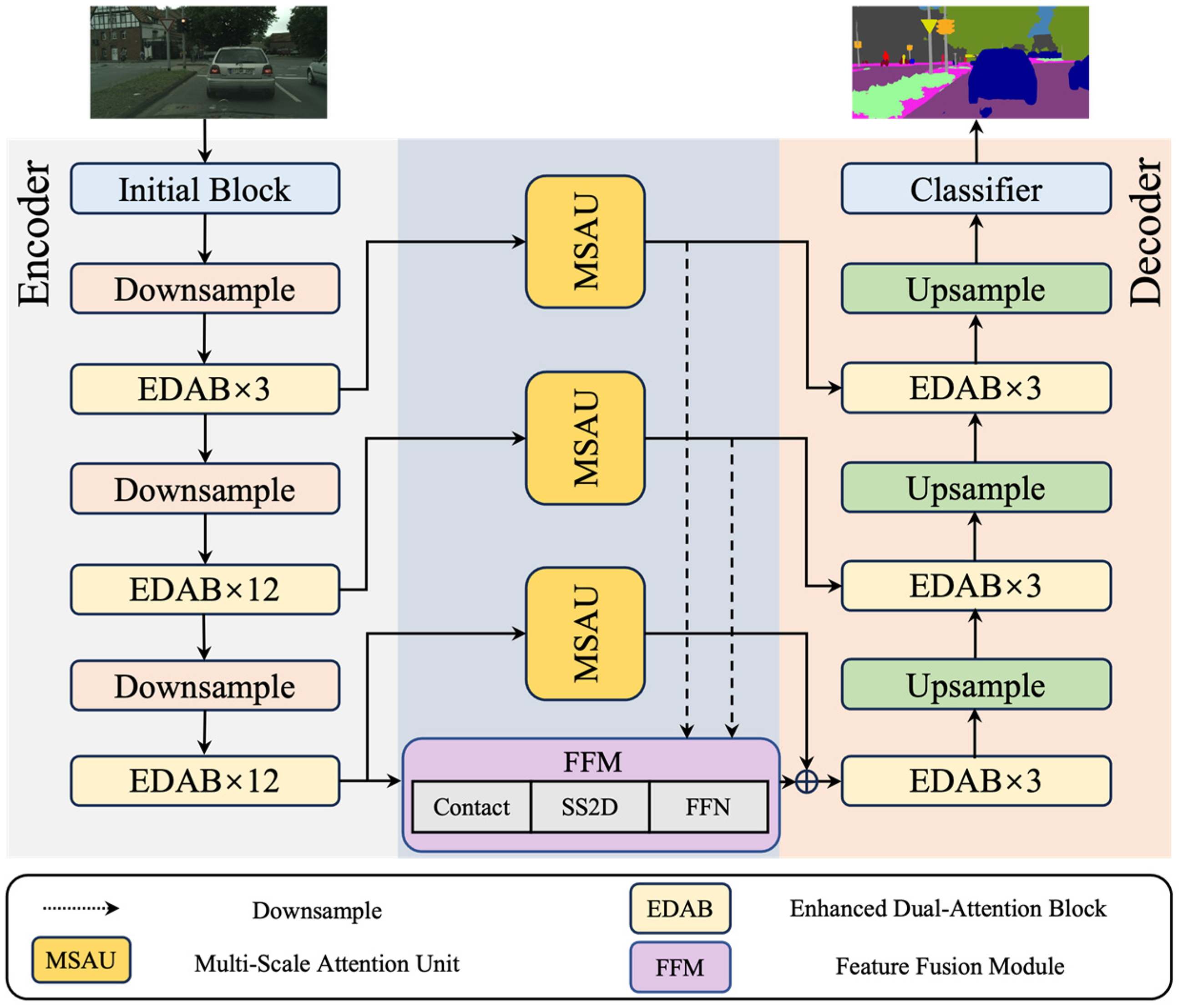
The overall network architecture of efficient convolutional neural network-Mamba network (ECMNet).
Enhanced dual-attention block
As shown in Figure 3, the structure of EDAB is inspired by the idea of a multi-head attention mechanism. The module is designed to focus different level feature information and keep network parameters as few as possible. Firstly, the input feature passes through a bottleneck structure that utilizes a 1 × 1 convolution to reduce the number of channels to half, significantly reducing the computational complexity and the number of parameters. Obviously, this will sacrifice a part of the accuracy, but it will be more beneficial to introduce 3 × 1 convolution and 1 × 3 convolution more than make up for the loss at this point. Meanwhile, the two decomposed convolutions not only obtain a wider respective field for capturing a larger range of contextual feature information but also consider the model parameters and calculation complexity. The core of EDAB lies in its two-branch path, which captures local and global feature information, respectively. Decompose the convolution in one branch with CA processes local and short-distance feature information, complemented by atrous convolution in the parallel branch with DDA for global feature integration. Then, the channel contains most of the feature information, and the spatial feature information is key to enhancing performance and suppressing noise interference. DDA precisely captures the bidirectional spatial correlations within feature maps by modeling pixel dependencies in both height and width dimensions, enabling refined representation and enhancement of spatial details. In the DDA module, Query, Key, and Value are the core components for implementing bidirectional spatial attention modeling. For the height direction (Key_h, Quer_h) and width direction (Key_v, Quer_v) branches, Key captures reference information about features, while Query initiates queries for key features. After multiplying these components and applying softmax to generate attention weights, an einsum operation is performed with the Value layer containing the features awaiting augmentation. This process models pixel dependencies in both the height and width dimensions. This complements CA, collectively enhancing the ability of EDAB to express multidimensional features and providing more discriminative feature support for subsequent visual tasks. Therefore, the two branches utilize CA and DDA, which aim to build different attention matrices to learn multidimensional feature information and improve feature expression. Finally, the outputs from both designed paths and intermediate features are integrated and processed by a 1 × 1 point-wise convolution to restore the original channel dimensionality. A channel shuffle strategy is applied at the end of EDBA to establish inter-channel correlations and overcome information fragmentation. The detailed operation is shown as follows:
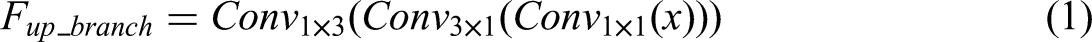




The overall architecture of the proposed enhanced dual-attention block (EDAB).
Multi-scale attention unit
On the one hand, lower layers preserve fine spatial details with limited semantics; on the other hand, higher layers offer strong semantic representation at lower spatial resolution. Therefore, it is an efficient strategy to combine the low-level rich spatial information and high-level rich semantic information for semantic segmentation tasks. Inspired by U-Net, we use the same resolution connections to integrate the high-level feature maps and low-level feature maps. In order to better process the three long connections, we design an MSAU to enhance the ability of feature representation. As shown in Figure 4, MSAU is carried out from two branches: one is the multi-scale spatial aggregation, the other is the channel aggregation.
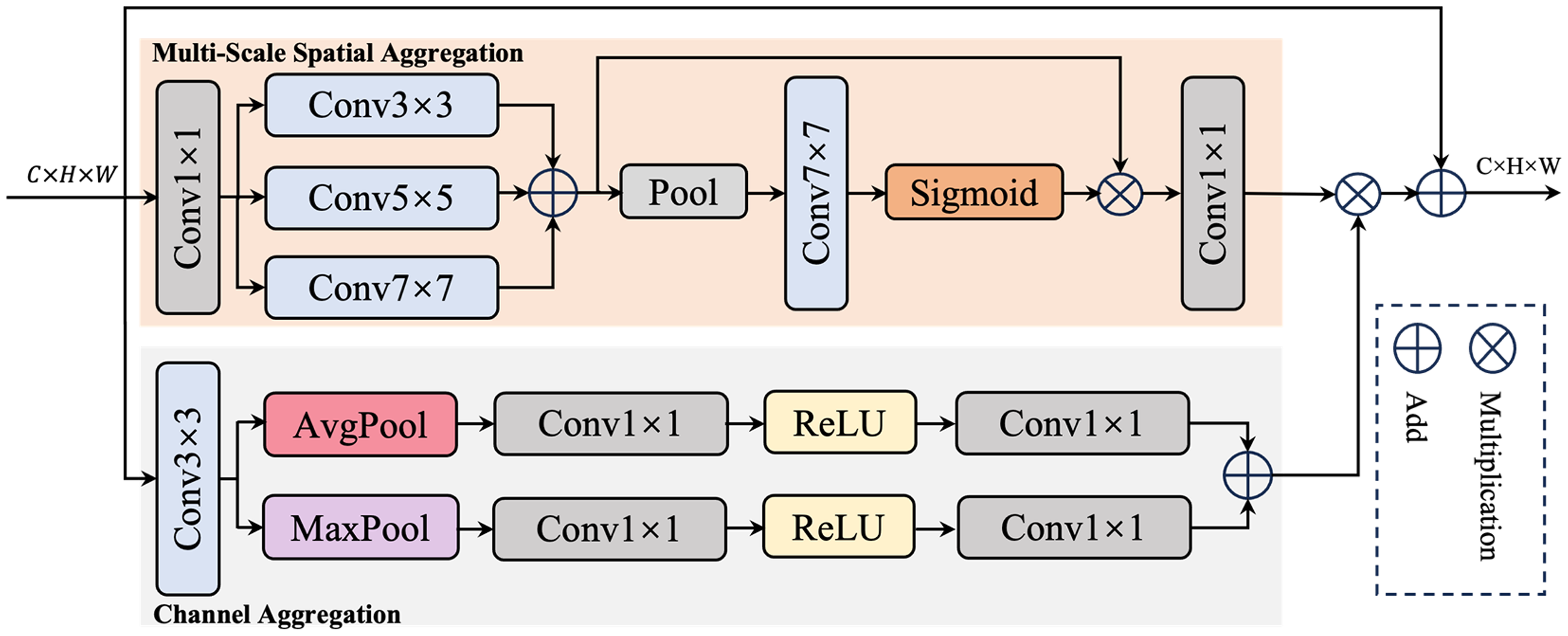
The architecture of our proposed multi-scale attention unit (MASU).
In the multi-scale spatial aggregation, the input feature map is utilized with a 1 × 1 convolution to convert from C channel to C/2 channel. In order to reduce the amount of parameters and computation while retaining the ability of multi-scale feature extraction, the next feature map goes through different sizes of depth-separable convolution, such as 3 × 3, 5 × 5, and 7 × 7. Meanwhile, the outputs of different scale convolutions obtain multi-scale feature information, enhancing the multi-scale perception capability of the model. Then, the multi-scale fused feature map compresses the height dimension to 1 by adaptive average pooling, and generates a spatial attention map by 7 × 7 depth separable convolution, 1 × 1 convolution, and sigmoid activation function. At the same time, by multiplying with the multi-scale fused feature map, the processed feature highlights the key spatial regions and suppresses the irrelevant information. At last, the channel of model is converted from C/2 back to C by using 1 × 1 convolution, and the attention map reflects the importance of the different locations of the feature map. For channel aggregation, the input feature map uses average pooling and maximum pooling to obtain average channel features and maximum channel features, respectively, which captures channel statistics from different angles. The MSAU multiplies the spatial and channel aggregation results and adds them with the original input feature maps to obtain the output feature maps.
This design allows the MSAU module to fuse the low-level spatial information with the high-level semantic information more effectively and further enhance the ability of feature expression. The detailed operation can be defined as follows:
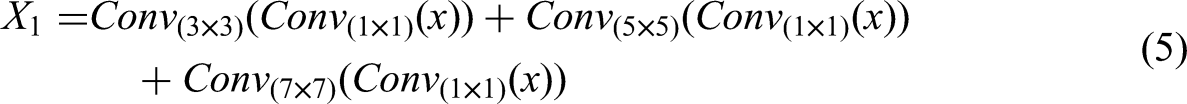




Feature fusion module
Motivated by the effectiveness of Mamba in linear-complexity sequence modeling, we design an FFM by introduce SS2D block for better capturing global representations with less network parameters and computational quantities. SS2D block serves as a powerful alternative to the self-attention mechanism in vision transformers, designed to capture long-range spatial dependencies with linear computational complexity. The SS2D block is built upon the framework of linear SSM, which model a dynamical system's evolution. The block utilizes a decomposed 2D scanning strategy involving horizontal scanning and vertical scanning. The feature map is scanned independently for each row by horizontal scanning. Two separate SSMs are typically used: one from left-to-right and another from right-to-left. This captures long-range dependencies within each row. The feature map is scanned independently for each column by vertical scanning, both top-to-bottom and bottom-to-top. This captures long-range dependencies within each column. The outputs from the two scanning directions are fused to integrate the holistic 2D spatial context. A simple yet effective fusion method is element-wise addition, followed by a non-linear activation. The detailed operation can be defined as follows:

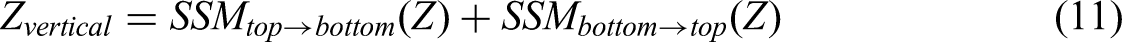
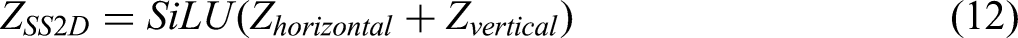
As shown in Figure 5, the FFM enriches the feature diversity by integrating different-scale feature information from the multi-level MSAU and the encoder through the concatenation operation. Then, the SS2D block further extracts and fuses the features through a series of linear transformations and 2D convolution operations, which employs a selective scanning mechanism to enhance the feature representation ability. Finally, a feed-forward network (FFN) performs a non-linear transformation to adjust the weight distribution of features, highlighting the key features and suppressing the redundant information, so as to improve performance in handling complex tasks. The designed FFM can effectively fuse multi-scale features and capture both local detail information and overall semantic features, great improving the performance of the model in semantic segmentation tasks. The complete operation is shown as follows:



The architecture of our proposed feature fusion module (FFM).
Experiments
Datasets
Cityscapes. This dataset is composed of high-quality 5000 images, annotated at the pixel level. The images are primarily scenes of driving within urban settings, captured across 50 different cities with a resolution of 2,048Œ1,024. The dataset was divided into training sets (2975 images), validation sets (500 images), and test sets (1525 images).
CamVid. The CamVid dataset, developed by the University of Cambridge, contains urban road scene images captured from a driving perspective (960Œ720 resolution). Its 700 + annotated samples support supervised learning, featuring 11 representative object classes that effectively capture urban road elements. This diversity in objects and well-annotated classes makes it particularly suitable for our segmentation accuracy research.
Implementation details
Our proposed ECMNet, implemented in PyTorch, was trained using an NVIDIA RTX 3090 GPU. We employ random initialization and full training from scratch, extending the maximum epoch count to 1000. In training the ECMNet model, different parameter configurations are used for the Cityscapes and the CamVid datasets. The parameter configurations for the Cityscapes dataset included a batch size of 6, the use of a cross-entropy loss function, a stochastic gradient descent optimizer with a momentum of 0.9, a weight decay of 1 × 10–4, an initial learning rate of 0.045, and the use of a polynomial learning rate strategy. The parameter configuration for the CamVid dataset included a batch size of 8, the same cross-entropy loss function, the Adam optimizer, a momentum of 0.9, a weight decay of 0.0002, an initial learning rate of 1 × 10–3, and a polynomial learning rate strategy as well. These parameters are set to adapt to the characteristics of different datasets with a view to obtaining the best training results.
Ablation studies
We design a series of ablation experiments to validate the effectiveness of each module in our proposed model. As shown in Figure 6, the baseline model used for comparison is structured as a simple U-shape type, including the standard encoder and decoder. The encoder and decoder consist of multiple lightweight EDABs, which are modeled to achieve an average mIoU of 69.92% on the CamVid validation set.

The simple structure of the baseline model.
In the long connection ablation experiments (A group), the effect of gradually adding Line 1, Line 2, and Line 3 is investigated. The observed 0.61% enhancement after adding Line 1 substantiates that shallow information effectively aids semantic feature information reconstruction. Meanwhile, with three long skip connections, the model achieves a 1.29% mIoU enhancement. These results further demonstrate the significance of long-range skip connections for the semantic segmentation task. In the MSAU ablation experiments (B group), the MSAU module is added gradually to the long connection. A comparison between B1 and A1 reveals that adding the MSAU module to long connections only adds 9.43 K parameters, but improves the performance by 0.92% of mIoU. In the last ablation experiments (C group), the introduction of the FFM improves the performance of the model by 1.11% of mIoU. Finally, as the finalized architecture (C3), our proposed ECM-Net improves performance by 3.7% mIoU compared to the baseline model. All the above experiments shown in Table 1 fully validate the efficacy of our proposed modules and strategies.
Extensive ablation study for the proposed ECMNet on the CamVid dataset.
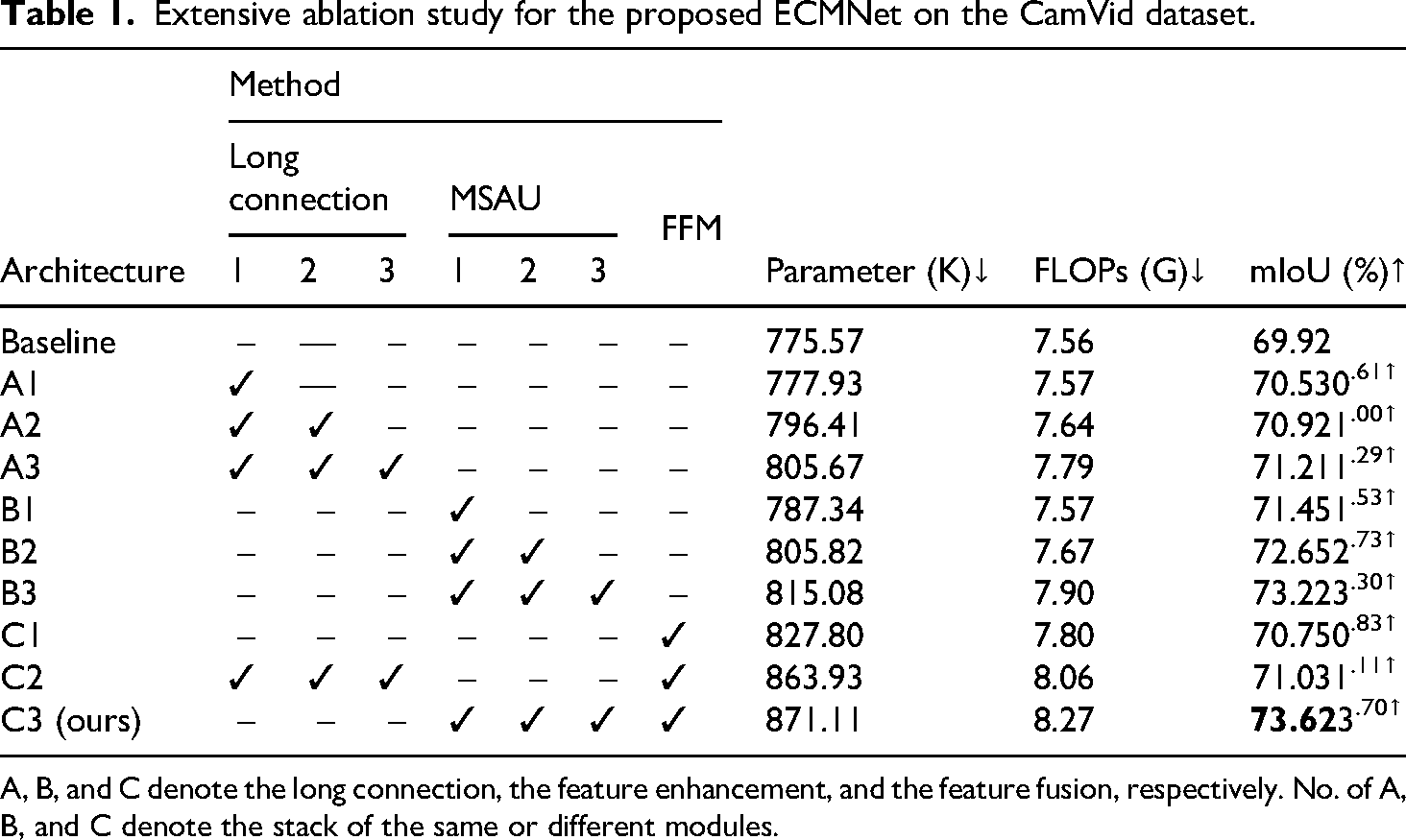
A, B, and C denote the long connection, the feature enhancement, and the feature fusion, respectively. No. of A, B, and C denote the stack of the same or different modules.
To further verify the efficiency and necessity of the proposed MSAU and FFM, we selected natural images featuring various scenes from the Cityscapes dataset, including cars, traffic signs, pedestrian streets, and pavements, to comprehensively investigate the impact of each module. So we visualized the layer-CAM (layer-wise class activation mapping) of results to illustrate the attention areas of different modules. As shown in Figure 7, it demonstrated our proposed FFM focuses on global details, achieving better segmentation boundaries. Meanwhile, our proposed MSAU refined local details feature by fully utilizing the attention mechanism. According to these layer-CAM, our proposed ECMNet both captured the global information and obtained more attention on detailed information, which result in achieving excellent performance.

The layer-wise class activation mapping (layer-CAM) visualization of different modules on Cityscapes.
Comparisons with state-of-the-art (SOTA) methods
In this section, we compare SOTA semantic segmentation methods in recent years on the Cityscapes and CamVid datasets to verify that our approach achieves a better balance between performance and parameters. Our evaluation is based on three key metrics: model parameters, floating-point operations (FLOPs), and mIoU.
Evaluation Results on Cityscapes Dataset.
As shown in Table 2, the model with a larger number of parameters and computation obviously achieves excellent segmentation results. However, the computational complexity of the model is high, and its operation speed is slow, which is unsuitable for real-time intelligent embedded devices. In contrast, lightweight models, such as NDNet, 35 CGNet, 36 CFPNet, 23 LEDNet, 22 and LETNet 24 are computationally efficient, but lack overall performance, especially in accuracy. Obviously, the LBN-AA 37 achieved the highest mIoU with 6.2 M model parameters, which are far more than our proposed approach. Meanwhile, the ESPNet 30 utilized the least parameters to realize 60.3% mIoU, which is significantly lower than the performance of our method. Our proposed ECMNet, with 0.87 M parameters, achieved a higher 70.6% mIoU. In Figure 8, we also show the visualization outcomes of these methods on the Cityscapes. Our proposed ECMNet achieves excellent results in natural image segmentation compared to CNN-based and transformer-based approaches, as shown in Figure 8. Meanwhile, our method obtains better detail features compared to other methods. Both the LETNet and the LEDNet exhibit missed small objects and achieve incorrect segmentation boundary comparison with the ground truth. For the proposed ECMNet, it can better segment objects and generate the improvement result closing to the ground truth, such as traffic signs. Our proposed ECMNet can get better segmentation results with less model parameters, which benefits from well-design structure and the utilization of the Mamba. These results fully demonstrate that our proposed model can achieve an excellent balance between model parameters and performance.

Visualization outcomes on the Cityscapes dataset. From top to bottom: original input images, ground truths, predictions of ECMNet, LETNet, 24 LEDNet, 22 ERFNet, 41 ESPNet, 30 and ENet. 39 Note that five examples are shown. Starting with the third line, each line has rectangular dashed boxes representing the segmentation results where a distinction exists.
Performance comparison of our proposed ECMNet and other representative methods on the Cityscapes dataset.
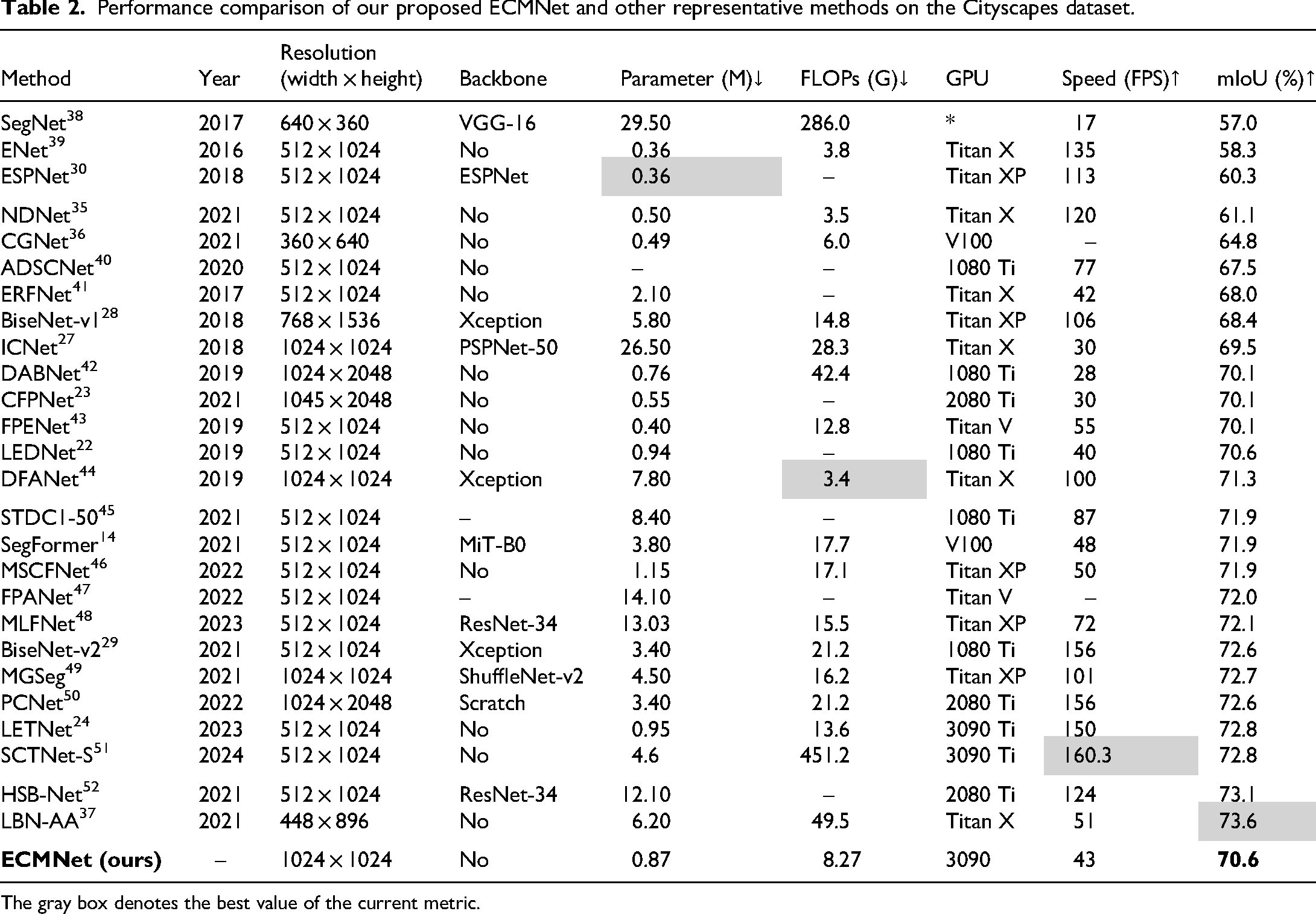
The gray box denotes the best value of the current metric.
Evaluation results on CamVid dataset
As shown in Table 3, to further verify the effectiveness and generalization capacity of our proposed ECMNet, we conducted comparative experiments with our method and other lightweight models on the CamVid dataset. Obviously, the MGSeg 49 just achieved the 72.7% mIoU with 13.3 M model parameters, which is lower performance and larger model parameters compared to our proposed method. Therefore, our method has achieved the best accuracy by only using 0.87 M parameters. Compared to Cityscapes, the higher overall performance on the CamVid dataset is due to our designed modules and strategies, which better capture feature of small-sized datasets. Per-class results are detailed in Table 4, further demonstrating the advantages of our proposed ECMNet.
Performance comparison of our proposed ECMNet and other representative methods on the CamVid dataset.

The gray box denotes the best value of the current metric.
Performance comparison of our proposed ECMNet and the state-of-the-art lightweight methods about per-class results on the CamVid dataset.
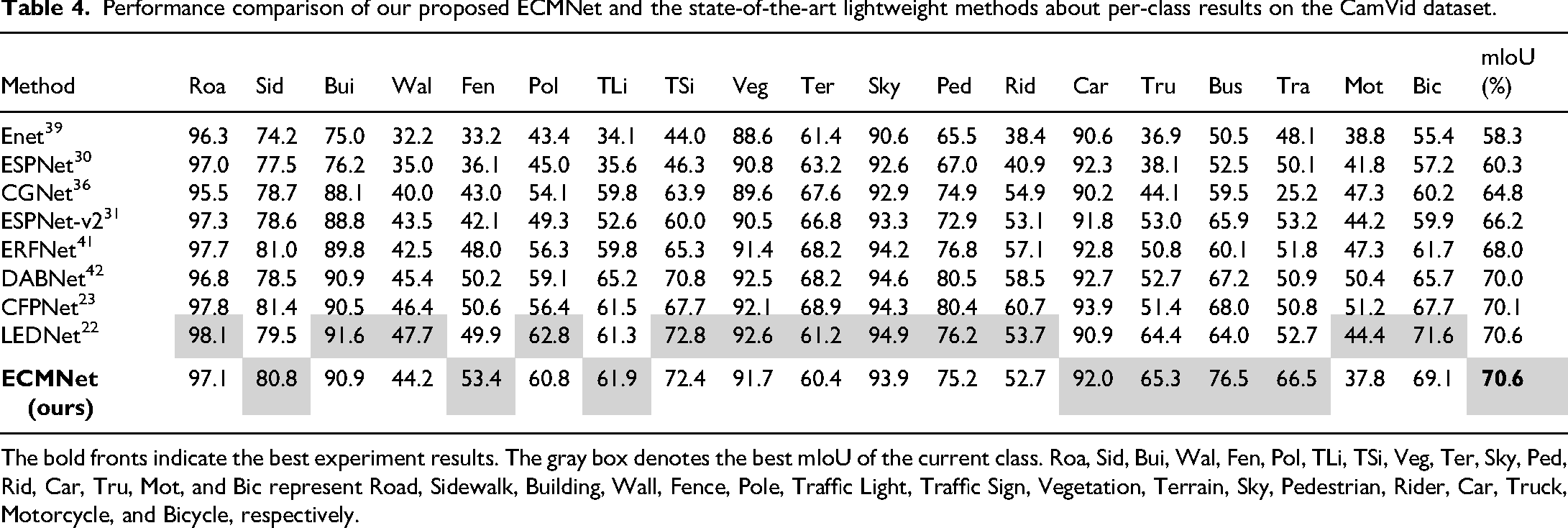
The bold fronts indicate the best experiment results. The gray box denotes the best mIoU of the current class. Roa, Sid, Bui, Wal, Fen, Pol, TLi, TSi, Veg, Ter, Sky, Ped, Rid, Car, Tru, Mot, and Bic represent Road, Sidewalk, Building, Wall, Fence, Pole, Traffic Light, Traffic Sign, Vegetation, Terrain, Sky, Pedestrian, Rider, Car, Truck, Motorcycle, and Bicycle, respectively.
Conclusion
In this study, we proposed a lightweight semantic segmentation network that combines Mamba and CNNs. We fused the local feature extraction capability of CNNs with the long-range dependencies of Mamba to model. Specifically, we introduced an FFM as a capsule-based framework in the middle of the model, which can better capture global feature information. Additionally, an EDAB module designed in the CNN learned more local feature information while ensuring simplicity and lightweight. Meanwhile, in order to compensate for the local feature information lost by CNNs, multi-scale long connections are utilized in the model. Moreover, we design an MSAU for cross-layer connections, effectively boosting discriminative features and attenuating noise. Extensive experimental results demonstrate that our proposed model achieves an excellent balance between model scale and performance.
Footnotes
Acknowledgements
The authors would like to acknowledge the assistance of the Engineering Technology Research Center of Optoelectronic Technology Appliance, AnHui Province.
Author contributions
Feixiang Du: conceptualization, writing–original draft, and writing–review and editing. Shengkun Wu: writing–original draft, validation, and visualization. Xiang Wang: validation and writing–original draft. Aoxue Ding: data curation and writing–original draft. Zhongliang Wang: investigation, writing–review and editing, and supervision. Joel CM Than: writing–review and editing and investigation.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the Natural Science Research Project of Anhui Educational Committee (2024AH051852, 2023AH040232) and College Students Innovative Entrepreneurial Training Plan Program (S202410383017). Furthermore, this publication has also been partially supported by the Teacher Secondment Training Project of Tongling University (2025GZDLSJ17).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.