
Abstract
To improve the network performance of radial basis function (RBF) and back-propagation (BP) networks on complex nonlinear problems, an integrated neural network model with pre-RBF kernels is proposed. The proposed method is based on the framework of a single optimized BP network and an RBF network. By integrating and connecting the RBF kernel mapping layer and BP neural network, the local features of a sample set can be effectively extracted to improve separability; subsequently, the connected BP network can be used to perform learning and classification in the kernel space. Experiments on an artificial dataset and three benchmark datasets show that the proposed model combines the advantages of RBF and BP networks, as well as improves the performances of the two networks. Finally, the effectiveness of the proposed method is verified.

Highlights
An integrated neural network model with pre-RBF kernels is designed.
The proposed network model can effectively combine the local nonlinear mapping ability of the hidden nodes of the RBF network with the global nonlinear classification ability of the BP network.
The proposed network model improves the network performance of single RBF network and BP network obviously.
The learning algorithm can effectively adapt to the proposed network model.
Introduction
In the field of machine learning, feedforward networks have been used extensively to solve various problems, including image classification, 1 medical diagnosis,2,3 water quality inspection,4–6 where back-propagation (BP) neural networks and radial basis function (RBF) networks are typically used. The hidden nodes of BP neural networks generally use the unified sigmoid kernel to map the input samples, where the sigmoid kernel affords good generalization performance; however, the learning of BP networks involves repeated updating of weight parameters, which often results in slow convergence and converges to a local minimum. The optimization methods of BP neural networks primarily include the optimization of initialization weight,7–9 design of adaptive learning rate, 10 addition of momentum term,11,12 correction of error cost function. 13 Although these methods improve the shortcomings of BP neural networks, the effects of these methods are limited for more complex nonlinear problems.
In contrast to BP neural networks, the RBF network generally uses a Gaussian kernel with different parameters to map the input samples, where the Gaussian kernel exhibits good local response characteristics. The optimization process of the RBF network primarily includes the optimization of kernel parameters and linear output weights, which can be categorized into two stages: stage one improves the separability of samples by mapping the original samples through the hidden layer Gaussian kernels, and stage two completes the pattern classification by optimizing the linear hyperplane. Typical methods for optimizing the hidden nodes of RBF neural networks include fuzzy c-means clustering,14,15 sensitivity analysis, 16 particle swarm optimization, 17 and the dynamic adjustment of the number of hidden nodes 18 ; however, when these methods are used to optimize complex nonlinear problems, they often increase the burden of the subsequent linear output weight optimization.
The optimization BP and RBF networks are based on a single network model, from which relevant optimization algorithms are established. Because of the characteristics of BP and RBF network models, the adaptability of these different optimization algorithms to different nonlinear problems is often limited. Hence, scholars have investigated the cascade neural network model, 19 which is composed of several independent sub-networks. However, the essence of a cascade neural network is to establish relevant learning algorithms for each independent sub-network. For a complex classification problem, the integration and effective connection of different sub-networks to form an entire network model is worth investigating.
In this context, convolutional neural networks (CNNs) 20 can be regarded as a network that integrates different sub-networks and establishes effective connections. In the CNN, convolution kernels are used to extract features, and then the connected multi-hidden layer BP neural network is used for classification. Tang et al., 21 the BP neural network connected with convolution kernels is replaced by extreme learning machines, which improves the convergence speed of the CNN.
Inspired by the study above, an integrated neural network model with pre-RBF kernels is proposed herein. The main motivation of this research is to effectively combine the advantages of RBF network and BP network, and restrain the disadvantages of single RBF neural network and BP neural network. By integrating and connecting the RBF kernel mapping layer and BP neural network, a complementary network can be constructed. In the proposed integrated neural network model, the local features of the sample set can be effectively extracted to improve separability; subsequently, the connected BP network can be used to learning and classification in the kernel space. Therefore, the proposed network model effectively combines the local response ability of hidden nodes in the RBF network with the generalization ability of hidden nodes in the BP neural network, as well as effectively overcomes the shortcomings of the single RBF neural network and BP neural network in complex nonlinear problems.
Integrated neural network model with pre-RBF kernels
Network structure
The construction principle of the proposed network structure is as follows: First, the original samples are input into the RBF kernel mapping layer, which extracts the local features of the original samples in different spatial regions and forms new feature vectors; subsequently, the BP network connected by the RBF hidden layer is used to complete the effective classification of samples in the feature space. Compared with the BP network, the proposed network structure improves the separability of input samples, which can accelerate the convergence speed of network weights and reduce the risk of falling into a local minimum; compared with the RBF network, the proposed network structure changes the linear weight optimization connecting the hidden and output layers to the nonlinear BP neural network, which exhibits better adaptability to complex nonlinear problems. Even if a certain deviation occurs in the original space mapping, the nonlinear BP network can compensate for the kernel mapping effect of the RBF hidden layer. Therefore, the proposed model can effectively combine the local nonlinear mapping ability of the hidden nodes of the RBF network with the global nonlinear classification ability of the BP network and improve the shortcomings of single RBF and BP neural networks.
To effectively demonstrate the characteristics of the proposed network model, Figure 1 shows a schematic diagram of the integration of the Gaussian kernel with different parameters and the BP neural network. As shown, the pre-RBF kernels in the integrated network can improve the separability of the sample set; subsequently, the nonlinear BP network can be classified more effectively in the mapped kernel space.

Construction principle diagram of proposed model.
Figure 2 shows the proposed neural network model constructed in this study. The proposed model comprises four parts: an input layer, an RBF kernel mapping layer, a BP hidden layer, and an output layer, where the number of BP hidden layers can be set to 1 or 2 depending on the actual problem. The RBF hidden layer is composed of a set of Gaussian kernel functions with different parameters. Let the number of Gaussian kernels in the RBF hidden layer be

where
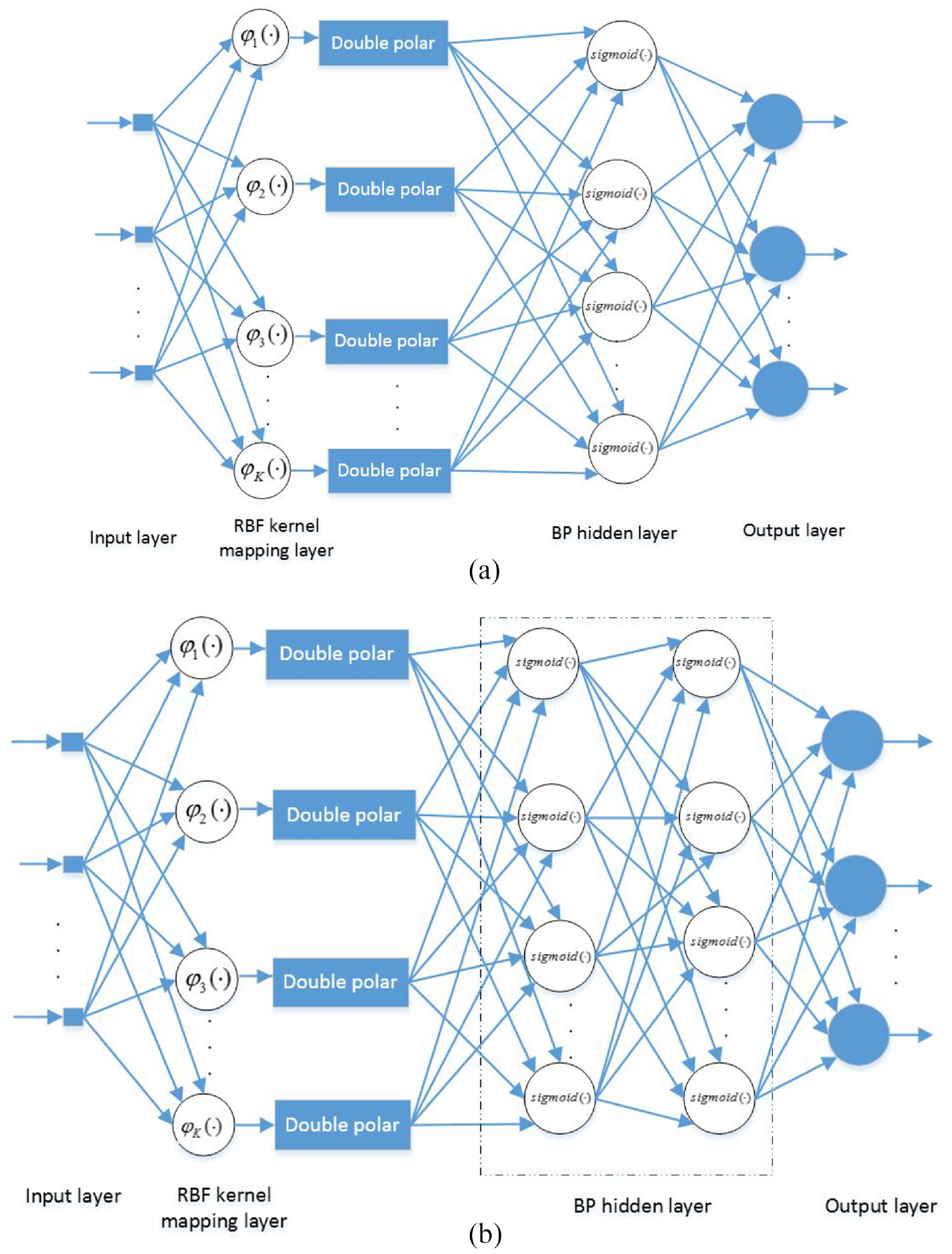
Structure diagram of integrated neural network with pre-RBF kernels: (a) with single BP hidden layer and (b) with two BP hidden layers.
After using the Gaussian kernels of the RBF kernel mapping layer to map the original samples, to use the obtained kernel mapping value as the input of the subsequent connected BP network, dual polarization processing is required to obtained the kernel mapping value. The formula for the dual-polarization transformation is

In the proposed integrated network structure, the BP hidden layer is composed of nodes from the RBF kernel mapping layer to the network output layer. Because the sigmoid function of the BP hidden layer is the hyperbolic tangent function, the output signal of node j in the cth BP hidden layer can be expressed as

where parameters a and b are constants.
The output

The induced local region of the jth node of the cth BP hidden layer can be expressed as

where
The output signal at node k in the output layer can be expressed as
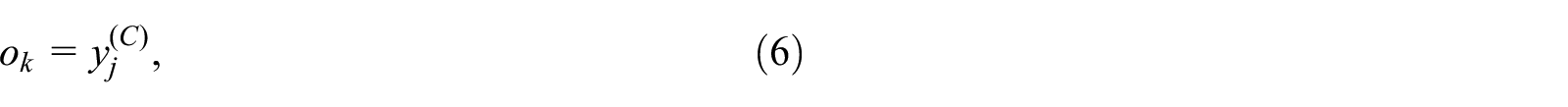
where C is the sum of the input, hidden, and output layers of the BP network component.
Algorithm implementation
When the network model is established, the subsequent task is to establish a corresponding learning algorithm to optimize the network parameters. The algorithm implementation of the proposed network process includes these steps: (1) Initialize parameters and preprocess samples; (2) Optimize the parameters of RBF kernel mapping layer; (3) Double polarize each input sample; (4) Forward calculation of BP network; (5) Backward calculation and update the weights of each layer of BP network; (6) Decision output of sample label value. In this study, the parameters of the Gaussian kernel in the RBF kernel mapping layer are optimized using a fuzzy c-means clustering algorithm, and the weights of each layer of the BP network are optimized using the existing BP algorithm based on gradient descent.
Figure 3 shows the implementation algorithm of the proposed network, where the optimization of the Gaussian kernel parameters is provided in Table 1.

Learning algorithm of integrated neural network with pre-RBF kernels.
Algorithm implementation of fuzzy c-means clustering.

In Figure 3, the formula to calculate for the overall mean square error of the BP network is

where
The back calculation of the BP network is the updating process of the local gradient and can be expressed as

The weight updating process of layer c in BP network is expressed as follows:

where m is the iteration step, and
Experimental comparison and analysis
In this section, the performance of the proposed method is evaluated using an artificial dataset, namely the Concrete Circle and three benchmark datasets
22
from University of California, Irvine (UCI): climate, heart disease, and blood transfusion. Table 2 provides a description of the classification datasets. The performance of the proposed method is compared with a BP algorithm based on stochastic gradient descent (SGBP),
11
a constrained optimization method based on a BP neural network (CO-BP),
23
an RBF network based on fuzzy c-means clustering (FCRBF),
14
and an optimized RBF network based on fractional order gradient descent with momentum (FOGDM-RBF).
24
In each dataset, all data samples in each dataset are scaled to [−1, 1], the number of kernels in the RBF mapping layer is adjusted manually based on the distribution of the sample space, and the number of BP hidden layers is set to one and two layers; the number of BP hidden layer nodes was set between two and nine, the network learning rate was adjusted iteratively using the simulated annealing algorithm, and the sigmoid kernel parameters were set as
Information description of different classification datasets.

Concrete circle classification problem
Figure 4 shows a graphical representation of the Concrete Circle classification dataset, where the two classes of samples are mixed interactively and can be used to measure the characteristics of the proposed method. Figure 5 shows a comparison of the mean square error (MSE) learning curves of the proposed method involving SGBP and FCRBF. The MSE of SGBP in the training set is relatively large, which indicates that the learning effect of BP network on complex nonlinear problems is limited. Compared with SGBP, FCRBF has the advantages of good stability, the learning effect is improved to a certain extent. Compared with SGBP and FCRBF, the MSE of the proposed method was smaller, and the learning curve converged faster; therefore, the proposed method exhibited better learning performance for the training sample set.
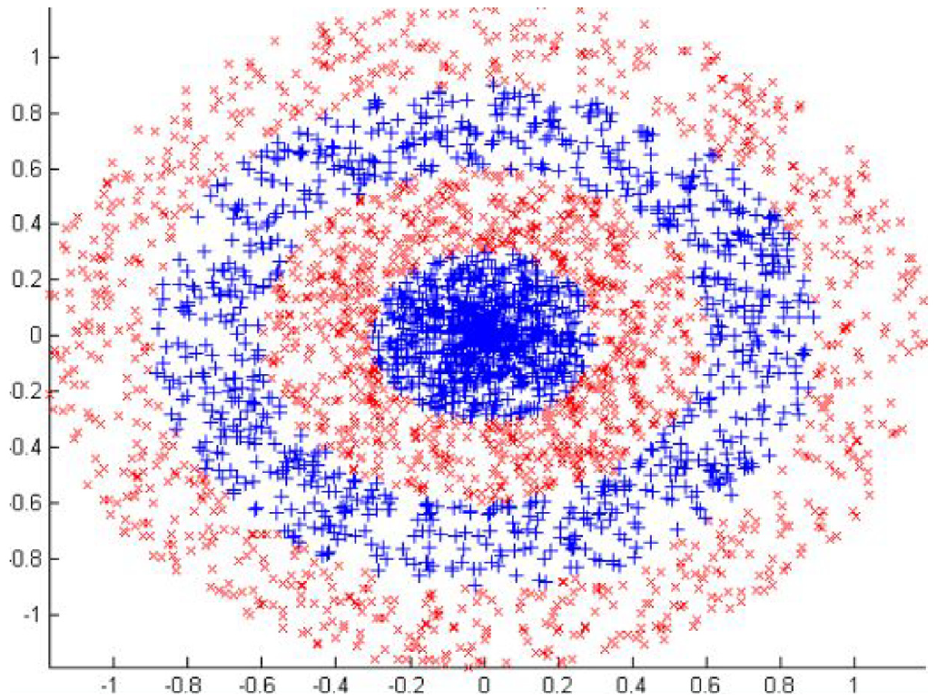
Concrete Circle classification dataset.
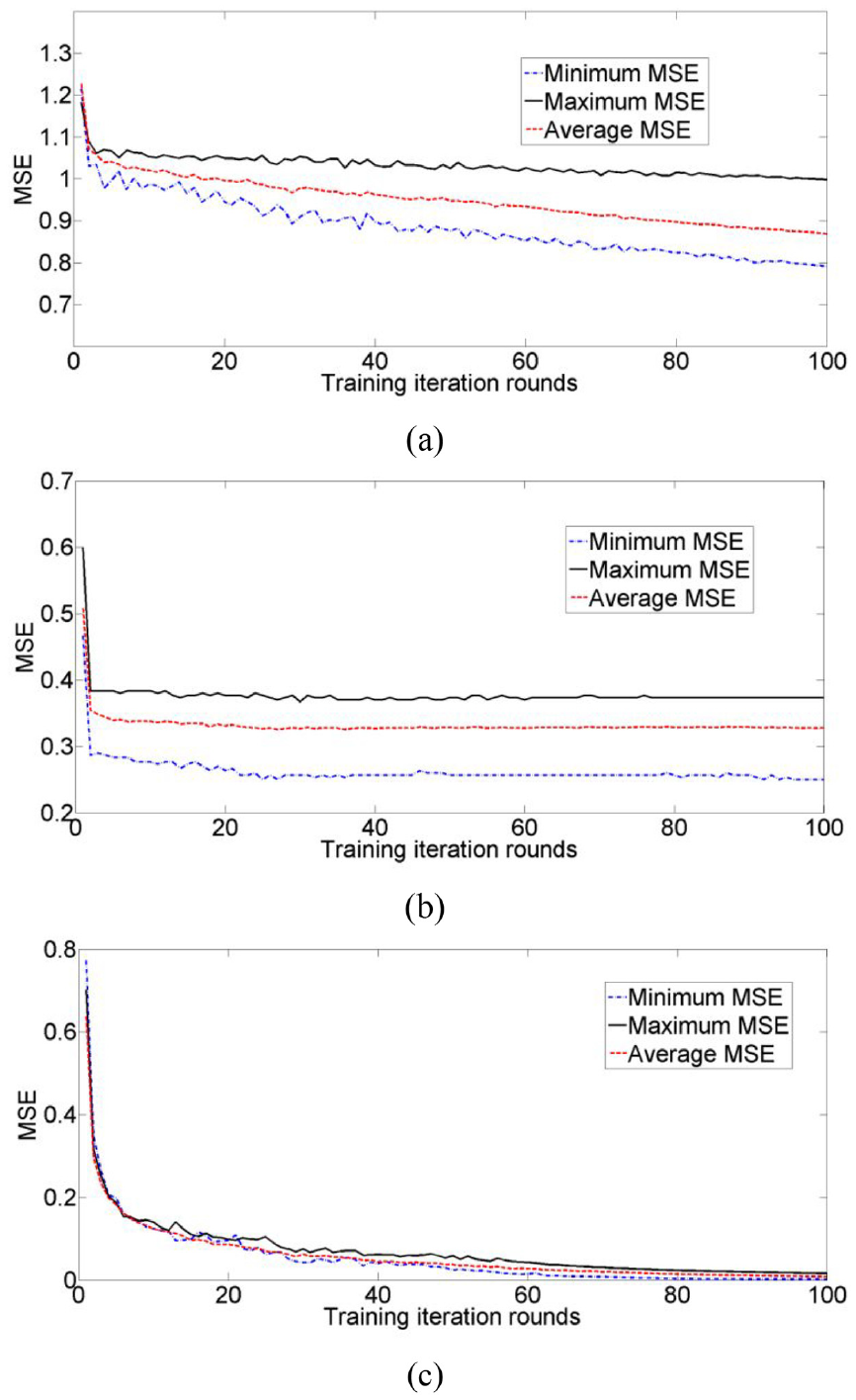
Comparison of MSE learning curves of different methods on Concrete Circle dataset: (a) SGBP, (b) FCRBF, and (c) proposed method.
Compared with the SGBP and FCRBF, Figure 6 and Table 3 show that the classification effect of the proposed method is better. From the classification accuracy of the test set, when the number of BP hidden layers is set to 1, the proposed network is approximately 6.7% and 31% higher than FCRBF and SGBP respectively; when the number of BP hidden layers is set to 2, the proposed network is approximately 7.5% and 21.3% higher than FCRBF and SGBP respectively. This shows that the proposed method can adapt well to the complex sample set, as evident by the better learning performance, and the classification effect on the test set was significantly higher.

Comparison of classification effects of different methods on Concrete Circle dataset: (a) SGBP, (b) FCRBF, and (c) proposed method.
Experimental comparison of different methods on Concrete Circle dataset.

UCI benchmark classification problems
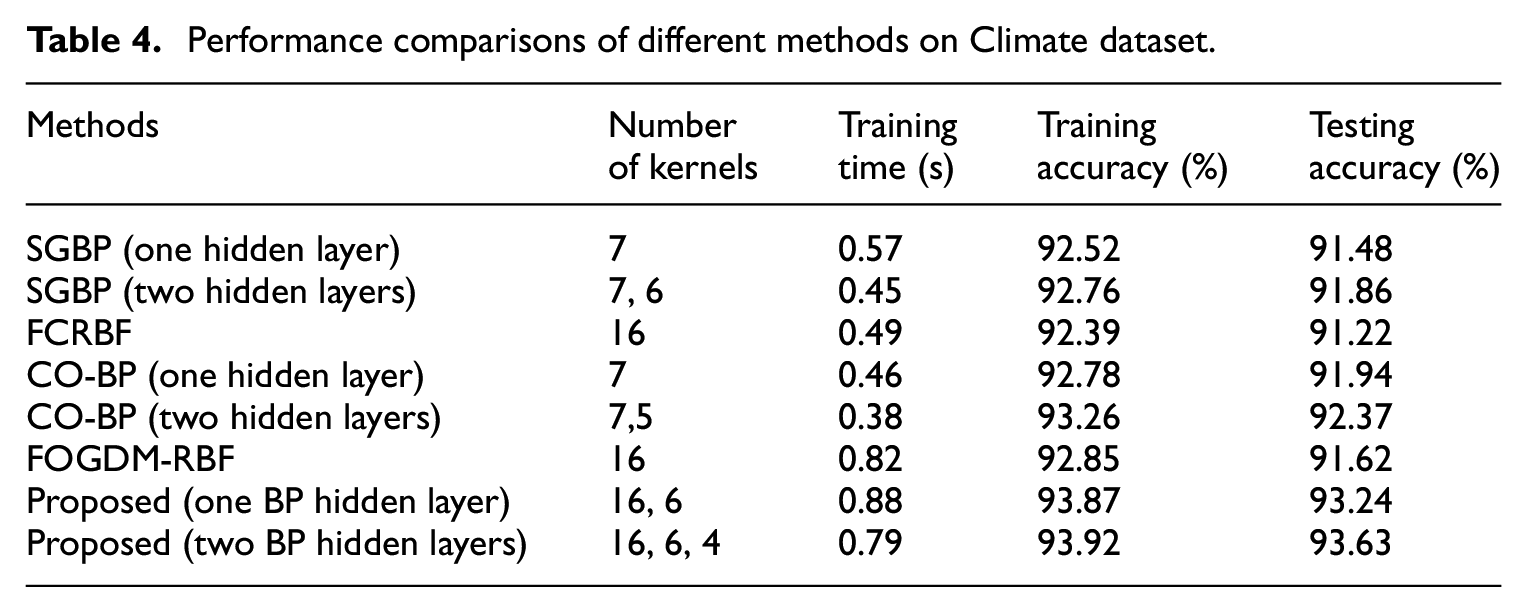
Under the benchmark datasets, the performance comparison results of the proposed method and other methods are shown in Tables 4 to 6. The classification accuracy of the proposed method outperform SGBP, FCRBF, CO-BP, and FOGDM-RBF in varying degrees on the benchmark datasets. For the Climate dataset, when the number of BP hidden layers is set to 1, the testing accuracy of the proposed method is approximately 1.3%–2% higher than those of SGBP, CO-BP, FCRBF, and FOGDM-RBF. When the number of BP hidden layers is set to 2, the testing accuracy of the proposed method is approximately 1.3%–2.3% higher than those of SGBP, CO-BP, FCRBF, and FOGDM-RBF. For the Heart Disease data set, the testing accuracy of the proposed method is higher than that of SGBP obviously. When the number of BP hidden layers is set to 1, the testing accuracy of the proposed method is approximately 1.6%–5% higher than those of CO-BP, FCRBF, and FOGDM-RBF. When the number of BP hidden layers is set to 2, the testing accuracy of the proposed method is approximately 2.3%–4.3% higher than those of CO-BP, FCRBF, and FOGDM-RBF. For the Blood Transfusion data set, the testing accuracy of the proposed method is higher than those of SGBP obviously. When the number of BP hidden layers is set to 1, the testing accuracy of the proposed method is approximately 0.6%–9.6% higher than those of CO-BP, FCRBF, and FOGDM-RBF. When the number of BP hidden layers is set to 2, the testing accuracy of the proposed method is approximately 1%–10% higher than those of CO-BP, FCRBF, and FOGDM-RBF. As shown, compared with other methods, the proposed method adds new kernel parameters and training time in the learning process; however, its training accuracy and classification performance were significantly higher than those of other methods, indicating that the proposed method exhibits better adaptability to different classification problems, and the effectiveness of the proposed method was further verified.
Performance comparisons of different methods on Climate dataset.
Performance comparisons of different methods on Heart Disease dataset.

Performance comparisons of different methods on Blood Transfusion dataset.

Parameter analysis and discussion
In this study, the RBF and BP networks were effectively connected and integrated to construct the proposed network model. The construction of the proposed network primarily includes three parameters: number of hidden nodes in the RBF kernel mapping layer, number of BP hidden layers, and number of BP hidden nodes. Table 7 shows the performance of the model when these parameters change under the Concrete Circle dataset. As shown, when the three parameters are combined arbitrarily, the proposed method can maintain a relatively stable and high classification performance. This further verifies that the proposed can effectively combine the local nonlinear mapping ability of the hidden nodes of the RBF network with the global nonlinear classification ability of the BP network. By selecting the Heart Disease dataset and adjusting the parameters of the BP hidden layer and the number of hidden nodes in the RBF kernel mapping layer, the performance of the proposed method is compared with other methods, as presented in Figure 7. As shown, compared with other methods, the proposed method can maintain a relatively higher classification performance, and the overall stability of the network is better. This indicates that although the proposed method increases the number of training parameters, it reduces the dependence on the selection of BP hidden layer parameters and the number of hidden nodes in the RBF kernel mapping layer. Therefore, the advantages of RBF network stability and BP network generalization performance can be effectively combined. The proposed method can effectively overcome the shortcomings of single BP neural networks and RBF neural networks in complex nonlinear problems.
Performance comparison of different parameters of proposed method on Concrete Circle dataset.


Classification performance comparison of proposed method with other methods based on different kernel parameters: (a) BP hidden nodes and (b) RBF kernel mapping.
Conclusion
In this study, an integrated neural network model with pre-RBF kernels is proposed. The proposed network effectively connects and integrates RBF and BP networks, and the established learning algorithm can optimize the network parameters. Experiments on an artificial dataset and several benchmark datasets show that the proposed model can effectively combine the local nonlinear mapping ability of the hidden nodes of the RBF network with the global nonlinear classification ability of the BP network, as well as improve the network performance of a single BP network and an RBF network. Overall, the testing accuracy of the proposed method is higher than that of SGBP obviously. For the Concrete Circle dataset, the testing accuracy of the proposed method is approximately 1.3%–2.3% higher than those of FCRBF and SGBP under different training parameters. For the Climate dataset, the testing accuracy of the proposed method is approximately 6.7%–31% higher than those of SGBP, CO-BP, FCRBF, and FOGDM-RBF under different training parameters. For the Heart Disease data set, the testing accuracy of the proposed method is approximately 1.6%–5% higher than those of CO-BP, FCRBF, and FOGDM-RBF under different training parameters. For the Blood Transfusion data set, the testing accuracy of the proposed method is approximately 0.6%–10% higher than those of CO-BP, FCRBF, and FOGDM-RBF under different training parameters. The advantages of the proposed method can be effectively verified. However, the training samples are presented via batch learning, which fails to consider the online learning method of using sequence samples. Hence, we will investigate the learning method involving sequence samples in our future study.
Supplemental Material
sj-m-1-sci-10.1177_00368504211026111 – Supplemental material for Integrated neural network model with pre-RBF kernels
Supplemental material, sj-m-1-sci-10.1177_00368504211026111 for Integrated neural network model with pre-RBF kernels by Hui Wen, Tao Yan, Zhiqiang Liu and Deli Chen in Science Progress
Supplemental Material
sj-m-2-sci-10.1177_00368504211026111 – Supplemental material for Integrated neural network model with pre-RBF kernels
Supplemental material, sj-m-2-sci-10.1177_00368504211026111 for Integrated neural network model with pre-RBF kernels by Hui Wen, Tao Yan, Zhiqiang Liu and Deli Chen in Science Progress
Footnotes
Acknowledgements
We thank the Putian Science and Technology Bureau (2018RP4004). We thank Dr. Hang Xu for his guidance and help in the revised draft.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Natural Science Foundation of Fujian Province (Nos. 2019J01815, 2019J01816, 2020J05213, and 2020H0047), New Century Excellent Talents in Fujian Province University (2018, Yantao), and the Department of Education of Fujian Province (JT180486, FJJKCG20-101).
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.