
Abstract
Human-Robot Collaboration (HRC) has been widely used in daily life and industry for maximizing the advantages of humans and robots, respectively. However, the internal modeling errors or external perturbations still affect robotic systems such as human collisions and environmental changes. Multimodal anomaly detection plays an increasingly important role in HRC applications, which detects unexpected anomalies from multimodal signals. Due to the complex temporal dependence and stochasticity, it is still difficult to choose a common model applicable to all collaborative tasks, and lack of comparative analysis of existing methods and verification of specific application cases. In this paper, six representative deep learning-based methods are evaluated and the comparing metrics including detection accuracy, multi-modality combinations, and anomaly time bias. For a fair comparison, each detector models multimodal signals from non-anomalous samples and then determines an anomaly using a predefined threshold. We evaluate the detectors with force, torque, velocity, tactile, and kinematic sensing during a human-robot kitting experiment that consists of six individual skills, results indicate that the LSTM-DAGMM based detector outperformed the others, which yielding higher accuracy and efficiency. The metrics are measured with the RUC and ROC by changing the settings of multi-modality combinations and various anomaly biases, which aim to obtain the best performance of multimodal anomaly detection.
Introduction
As the rapid development of collaborative robot, HRC tasks (e.g. household, services, warehouse logistics, etc.) are willing to be accomplished in a shared, unstructured, and nonstandard environment.1–3 It’s intractable to completely model the underlying dynamics, which likely to result in robotic abnormal movements with unexpected anomalies such as human collision, tool collision, and object slip in a HRC kitting experiment,4,5 as shown in Figure 1. Robots that can detect and respond appropriately to common anomalies have the potential to provide more effective and safer collaboration. Once the anomaly precisely detected, the anomaly identification for identifying the type, location, size of anomalies such that they can be used to prevent potential failures and minimize damage as well as recover the common anomalies. 6

Illustration of those most likely unexpected anomalies in a human-robot collaborative kitting experiment (left-to-right).
An anomaly detector should detect when the current multimodal observations differ significantly from those past normal observations, which can be analogous to the problem of finding unexpected patterns in multivariate time series. The anomaly detection of multivariate time series using data-driven method remains a big challenge because of the complex temporal dependence and stochasticity during robot manipulation tasks.7,8 Several common factors that make the detection difficult in HRC contexts, including
The diversity of manipulation task, users, and environments makes the normal observations with noises;
The anomalies in robotics are usually occur from various sources such as body damage, sensing errors, control failures, or environmental changes;
The anomalies exist unexpectedly and occur sporadically. Lacking of realistic anomalous samples for training, the detection method has to be an unsupervised one;
The anomalies are multimodal that integrated multiple sensory signals from different sensors;
The range of anomalous observations are ambiguous, which would be determined by a point or a short sequence. The collection of anomalies is various;
(6) The importance of modality combination for anomaly detection at different execution phase;
(7) The fixed threshold and fast detection may increase the false positive rate (detect the normal as anomaly).
Specifically, for the reasons (1), the robot manipulation tasks are designed to adapt the modifications of human’s behaviors or environmental changes in HRC, which possibly resulting the robotic movements are modeled with the movement primitive techniques, for example, Dynamical Movement Primitives (DMP), 9 Gaussian Mixture Model (GMM) 10 as well as Kernelized Movement Primitives (KMP). 11 Various complex manipulation tasks would be generated with the learned movement primitives by sequencing. For the reasons (4) and (6), although the robots can precisely understand the manipulation object and the interacting environment with the benefits of multimodal observation, how to evaluate the integrated sensors are redundant or insufficient given specific task remains challenging. Besides that, As described in Aryal et al., 12 the anomaly detector should address the problem of the multimodal data that represented using different units/scales. Therefore, the performance comparison of anomaly detectors under various multimodalities combinations is proposed in this paper, which can be used to determine the importance of each modality and more specifically the relationship of other modality values. This research can also directly understand how much each modality affects the manipulation task at different execution phase. Those aforementioned phenomenon emphasize the difficulties of effectively implementing anomaly detection in HRC scenarios.
To address these concerns, a wide variety of data-driven multimodal anomaly detector are popularly proposed in recent years.13–15 Motivated by the continued success of deep learning methods in high-dimensional data modeling, an increasing number of deep-learning methods have been applied in anomaly detection, the most advantage that do not require the effort of significant data preprocessing and feature engineering. In this paper, we mainly compare the performance of reconstruction-based methods that using autoencoder paradigm, 16 where the anomaly thresholds are calculated based on the reconstruction error. The main idea of those considered methods in this compassion is to learn robust latent representations to capture normal dynamics of multimodal observations, which including both the temporal dependence as stochasticity. Therefore, although fruitful progress has been made in recent years, 17 designing a robust anomaly detector on multimodal or high-dimensional sensory data in unsupervised fashion remains an open issues.
Related work
Typically collaborative robots used in HRC are equipped with multiple sensors that allow robots to perceive the internal information and external environment. The use of multiple sensors results in the generation of a sensory multimodal signal that can be exploited to learn a robot’s model of the world. Therefore, robot abnormal behaviors are classified as such when at least one signal dimension exhibits inconsistencies compared to previously experienced nominal executions.
Generally, anomalies can be classified into four categories: point anomalies, collective anomalies, contextual anomalies, and change points. 18 These categories have a significant influence on the type of anomaly detection methods that is employed. Specifically, anomalies in temporal data are contextual anomalies by time providing the context, where an abnormal observation is viewed in a particular context not just reflect the current moment. Another critical consideration is the dimensionality of temporal data. If multidimensional dataset is provided and each feature is represented in a time-series individually, one can use anomaly detection methods for multivariate time series.19,20 However, alternative methods that separate the temporal data for implementing anomaly detection in multidimensional space by univariate time series, respectively.21,22
The recent advancement of deep learning-based anomaly detection methods have gained much popularity with their promising performance.23,24 For instance, implementing the anomaly detection using the Auto-Encoder (AE) by inspecting its reconstruction errors. 25 Additionally, Recurrent Neural Networks (RNNs) architectures and have resulted in outstanding performance for a variety of problems including time series prediction and sequence-to-sequence learning.26,27 Until recently, many applications of deep learning in modeling temporal data involving univariate or multivariate for anomaly detection are presented good performance.28,29 Specifically, RNNs represent a significant improvement in efficiently processing and prioritizing historical information valuable for future prediction. 30 When compared to dense Deep Neural Networks (DNNs) and early RNNs, the LSTMs have been shown to improve the ability to maintain memory of long-term dependencies due to the introduction of a weighted self-loop conditioned on context that allows them to forget past information in addition to accumulating it. 31 LSTMs have been widely used in modeling time series in applications as diverse as the speech recognition, 27 multimodal anomaly identification during industrial big data, 32 robot manipulation tasks, 33 remote monitoring of patients, 34 and acoustic modeling. 35 To the best of our knowledge, there are two dominant approaches to anomaly identification with time-series using RNNs: Prediction-based approaches36,37 and reconstruction-based approaches.38,39
Since the RNNs model is widely applied to time series prediction and reconstruction, we mainly review related works that use RNNs for temporal anomaly detection. RNNs-based Time series prediction has been popularly investigated in recent decades, LSTMs are capable of learning the underlying pattern between past observations and current observations and representing that patterns in the form of learned weights. 31 For instances, the traffic flow prediction with LSTMs is proposed in Shao and Soong 40 and Liu et al. 41 experimental results indicate that the intrinsic feature of LSTMs for capturing long-term dependencies in sequential data such that make it a suitable choice in complex time series prediction. In Sagheer and Kotb, 42 a prediction model is designed by using temporal attention mechanism on top of stacked LSTMs for multivariate time series prediction and used to predict pollution levels. The excellent prediction performance of LSTMs, makes them an ideal candidate for anomaly detection. In addition, recent solutions of collective anomalies identification have been proposed for mitigating false positive and improving the accuracy, which commonly employ sliding windows to transform a time-series into a set of labels for implementing the predication in a supervised fashion. Subsequently, modeling the prediction errors using multivariate Gaussian Model or other statistical tricks (e.g. mean, medium, and maximum). In Hundman et al., 26 takes LSTMs as prediction model and mitigates false positive by introducing the percentage of decrease of the max prediction error for anomaly detection at each time step. In Bontemps et al., 29 LSTMs are used for detecting collective anomalies in network security domain, in which a prediction model with a single recurrent layer is used and a point anomaly is identified when a prediction error greater that a lower bound.
In Malhotra et al., 36 stacked LSTMs approach (LSTM-AD) and stacked RNNs approach (RNN-AD) using recurrent sigmoid units are employed to identify anomalies by modeling the prediction errors of time series. The model takes only one time step as input variable to predict multiple time steps, maintains LSTM units in a hidden layer are fully connected through recurrent connections, and is trained on normal dataset. Thus each observation in normal sequence should have multiple predictions made at different times in the past, an error value can be computed between the prediction and input. Consequently, error vectors are calculated from the multiple predictions, which are modeled using a multivariate Gaussian distribution to give the likelihood of an anomaly. The same implementation procedure is also applied to detect anomalies in Electrocardiography signals. 43 Those results are promising that a valuable reference for anomaly detection of multivariate time series.
Beside that, recent works have been proposed to comparing the reconstruction error induced by deep autoencoders, and demonstrate promising results. 44 The reconstruction-based methods assume that anomalies are incompressible and thus cannot be effectively reconstructed from low-dimensional projections, such as LSTM-based Variational Autoencoder (LSTM-VAE), 33 Deep Autoencoding Guassian Mixture Model (DAGMM), 45 and its variant that the encoder and decoder are designed with LSTM architecture (LSTM-DAGMM), both of them also reported good performance for multivariate anomaly detection.
In this work, we follow the promising success of deep learning-based multivariate anomaly detection and implement the comprehensive comparison of recurrent neural network based autoencoder (AE), stacked Long-short Term Memory (sLSTM), LSTM-based encoder and decoder (LSTM-ED), LSTMs-based Variational Autoencoder (LSTM-VAE), Deep Autoencoder Gaussian Mixture Model (DAGMM), and its variants with LSTM encoder-decoder (LSTM-DAGMM) based on a human-robot collaborative system. The contributions of this paper can be summarized as follows:
A comprehensive comparison of multimodal anomaly detection using the state-of-the-art deep-learning methods is proposed, which can evaluate the performance for learning the data more effectively under different robot execution phase;
An intuitive comparison of various modalities combination for anomaly detection based on the state-of-the-art deep-learning methods in a real-world dataset;
An intuitive comparison of various anomaly bias for anomaly detection based on the state-of-the-art deep-learning methods in a real-world dataset;
This implementation scheme can be easily used to anomaly monitoring of unmanned production line, machinery, and healthcare.
Learning latent representation of normal multimodal observations
Multimodal time series
With the development of multi-modal sensing fusion technology and the diversity of the environment, except the joint encoders, robots often need to add force/torque sensors and tactile sensors to sense the surrounding environment, so that the robot’s observation is often multimodal. In general, a multidimensional time series with dimension

where,

Each row in equation (2) represents the observation at time
Autoencoder
The autoencoder is designed to model the multimodal data by integrating multi-layer perception neural networks with three hidden layers, and both the input and output layers have

To detect anomaly, the trained autoencoder can be used to score each observation with the value of reconstruction error as formulated in equation (3), and then the sort the scores in descending order, the score ranked higher are likely anomalies. Therefore, an anomaly detector based on autoencoder can be developed with a quantitative score based on reconstruction error and determined the threshold with the percentage of sorted scores.
Stacked LSTM
Long Short Term Memory (LSTM) networks can effectively learn underlying temporal and spatial pattern of sequential data with unknown length because of their ability to maintain long term memory. A networks with multiple LSTM would improve the learning ability of temporal dynamics, named stacked LSTM (sLSTM). To address the problem of anomaly detection, the sLSTM is trained on normal observations and used as a predictor over a number of time steps (sliding window). Unlike the autoencoder in Section 3.2, a detector base on sLSTM is integrated with a multivariate Gaussian distribution that used for modeling the prediction error, and then the anomaly can be triggered by assessing the likelihood of testing error.
Specifically, a multimodal time series
To detect anomaly, there are
LSTM-ED
As described in Section 3.2 and 3.3, the autoencoder and LSTM networks can successfully applied to anomaly detection of multimodal observation. However, it remains challenging on those situations that with unpredictable, periodic, anomalies using prediction errors. A LSTMs based encoder-decoder, named LSTM-ED, 47 is proposed for anomaly detection, which attempt to reconstruct the normal dynamics via latent representation learning and uses the reconstruction error to detect anomalies. That is, when given an anomalous instances, it may not be able to reconstruct it well, and hence would lead to higher reconstruction errors compared to the reconstruction errors for the normal instances. According to Section 3.2, a scoring scheme also proposed for the determining anomalies, where the reconstruction error at any time step is used to calculate the likelihood of anomaly at that time. A higher anomaly score indicates a higher likelihood of the point being anomalous.
Specifically, a normal multimodal time series

where the
To detect anomaly, we should score the observation at each time

An anomaly can be determined based on a threshold
VAE
A Variational Autoencoder (VAE) is a variant of an AE (described in Section 3.2) rooted in Bayesian inference.
49
Similar to the AE formulation, a VAE is able to represent the high-dimensional data

Where

Where the first term regularizes the latent variable
Considering the data characteristics during human-robot collaboration, a long short-term memory-based variational autoencoder is present by introducing the temporal dependency of time-series data into a VAE. The feed-forward network in a VAE is replaced with LSTMs, which similar to conventional temporal AEs (Section 3.2) such as aforementioned LSTM-AD (Section 3.3) and LSTM-ED (Section 3.4).
To detect anomaly, we also define an anomaly score

Where,
DAGMM
As described in Section 3.5, the sparse representation of multimodal observation has achieved great success in anomaly detection without human supervision. However, it’s difficult to effectively perform density estimation in the latent space when the dimentionality of input data becomes higher. To address this problem, a Deep Autoencoding Gaussian Mixture Model (DAGMM) for unsupervised anomaly detection is proposed, 44 which combining the dimensionality reduction and density estimation in the latent space for the high-dimensional observations. That is, DAGMM utilizes a deep autoencoder to generate a low-dimensional representation and reconstruction error for each observation, which is further fed into a Gaussian Mixture Model (GMM) for density estimation.
Specifically, a normal multimodal time series
To detect anomaly, this model should mainly focus on the novel proposal on estimation network based on GMM with
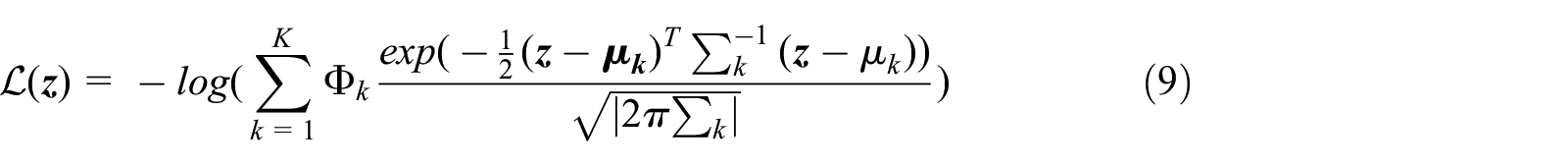
Where |·| denotes the determinant of a matrix. Therefore, to detect anomaly based on the calculated likelihood in equation (9) during the testing phase, where would predict samples of high likelihood as anomalies by a constant threshold. In this implementation, the threshold is chosen with the top 20% samples of the highest likelihood are marked as anomalies.
Additionally, motivated by the continued success of LSTMs on learning temporal characteristics, a extension of DAGMM using an LSTM-autoencoder as the compression network instead of a neural network autoencoder, named as LSTM-DAGMM, and the scheme of anomaly detection is the same as DAGMM.
Experimental verification and discussion
Experimental setup
To compare the anomaly detection performance of considered methods in a multimodal dataset. We designed a HRC task with six respective movements for picking and placing object into a container (300 mm × 250 mm × 200 mm) using Baxter robot, named as kitting experiment. Specifically, a human co-worker places a set of six objects marked with Alvar tags (http://wiki.ros.org/artrackalvar) on the robot’s reachable region (located in front of the robot) in a one-at-a-time fashion. The detail information of objects is illustrated in Table 1.
The detail information of objects during robot kitting experiment, including the material, weitht, and shape.

Irregular shape.
The objects may accumulate in a queue in front of the robot once the first object is placed on the table, the robot’s left arm camera identifies the object and the robot’s right arm picks, transports, and places it in a container located to the right of the robot, as shown in Figure 2. After which, the robot appropriately places each of the six objects in different parts of the container.

An human-robot collaborative kitting experiment with Baxter robot: the robot is designed to transport six marked objects with variable weights and shapes to a container, where the external anomalies may arise from accidental collisions (human-robot, robot-world, robot/object-world), mis-grasps, object slips, etc So as to identify those unexpected anomalies, the robot arm is integrated with multimodal sensors, including internal joint encoders, F/T sensor, and tactile sensor. A kitting experiment consists of six movements that were modeled by DMP, respectively. Objects that need to be packaged are placed by a human collaborator before the robot in a collection bin. The shared workspace affords possibilities for accidental contact and unexpected alteration of the environment.
Multiple sensors should be installed for effectively identifying the unexpected anomalies in such a kitting experiment. Here, the right arm of Baxter robot is equipped with a six degrees of freedom (DoF) Robotiq F/T sensor and two Baxter-standard electric pinching fingers, where each finger is further equipped with a multimodal tactile sensor composed of a 4 × 7 taxel matrix that yields absolute pressure values. In addition, Baxter’s left hand camera is placed flexibly in a region that can capture objects in the collection bin with a resolution of 1280 × 800 at 1 fps (we are optimizing pose accuracy and lower computational complexity in the system). The use of the left hand camera facilitated calibration and object tracking accuracy.
Experimental procedure
The detailed movement implementation is shown in Figure 2. The kitting experiment consists of six individual movements, including (Movement 3): Home → Pre-pick; (Movement 4): Pre-pick → Pick; (Movement 5): Pick → Pre-pick; (Movement 7): Pre-pick → Pre-place; (Movement 8): Pre-place → Place; (Movement 9): Place → Pre-place) that were effectively modeled with DMP and ROS-SMACH (http://www.ros.org/SMACH). One-shot kinesthetic demonstrations were used to train DMP models for each of the Movements of the kitting experiment. Note that a movement’s starting and ending pose can be adapted if necessary thus providing a flexible and generalizable movement encoding procedure. The robot is tasked to pick each one of the objects and place them in the container to its right. The visualization module uses the ALVAR tags to provide a consistent global pose with respect to the base of the robot. The trajectory adaptations will change the lengths of movements and increase the variability in the data collection even from nominal executions, resulting in augmenting the difficulty of assessing the sensory data with temporal uncertainty for robust anomaly detection.
Potential anomalies
External disturbances may be introduced into such a HRC task for a variety of reasons, as illustrated in Table 2.
The potential anomalies during robot kitting experiment.

Multimodal dataset collection and description
To effectively capture the underlying dynamics for each movement, we tasked five participants as collaborator (one expert user who confidently know this implementation and other four novice users) in our designed kitting experiment. Novice users first learned from the expert to induce anomalies during robot executions, which would aggravate the external uncertainty and increase the modeling difficulties. During data collection, each participant performed one nominal and six anomalous executions by placing the set of six household objects in a one-by-one fashion. Consequently, we ignore the failure executions and totally collected a dataset with 18 nominal executions and 180 anomalous executions, where each anomalous execution has at least one anomaly.
Dataset partition and labeling
After collection, we assume a multivariate time series
The information of each movement during robot kitting experiment with the anomaly bias “[−1, 1]”.
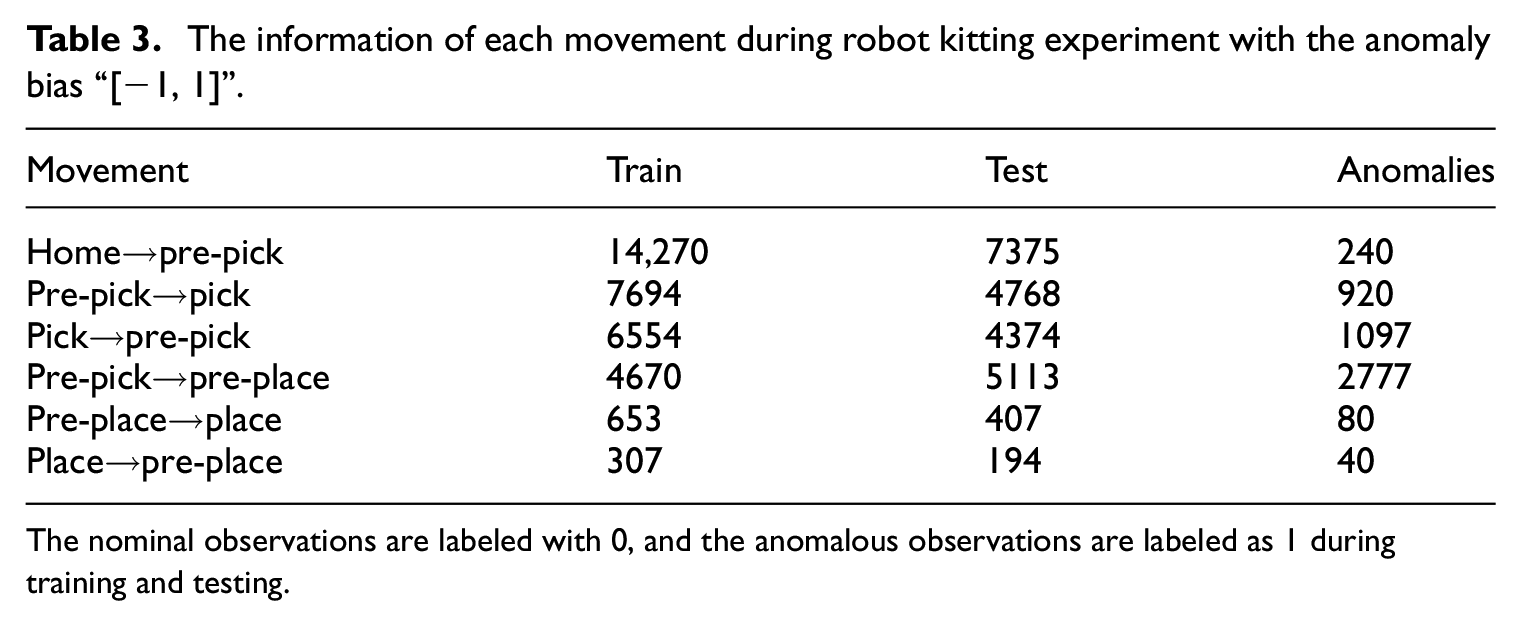
The nominal observations are labeled with 0, and the anomalous observations are labeled as 1 during training and testing.
Sensory Preprocessing
As for our multimodal observation vector
Wrench modality
The raw signals of F/T sensor is denoted by
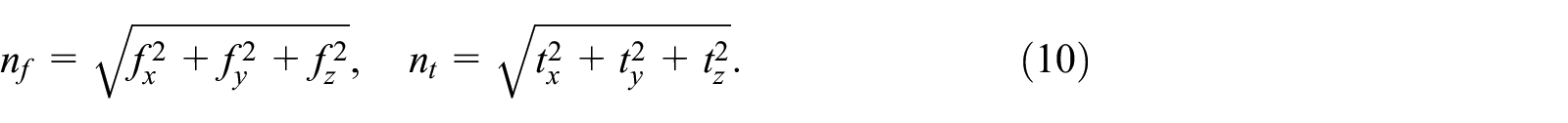
Velocity modality
Similarly, we take the Cartesian linear
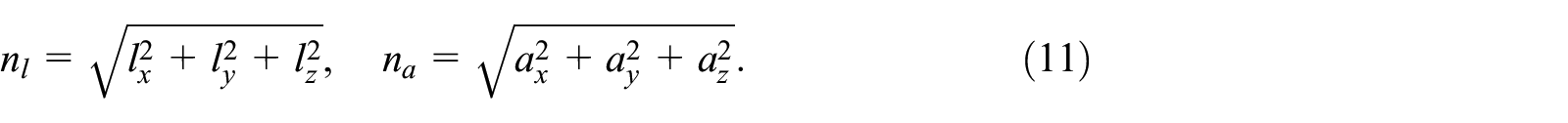
Tactile modality
Due to the computational cost of processing the tactile sensor’s high dimensionality, we empirically tested a number of features for each tactile sensor, they include: the maximum taxel value, the largest five taxel values, the mean of all taxel values, and the standard deviation for all taxel values. It was the standard deviation, which proved to be the most useful feature for anomaly detection. The standard deviation for each tactile sensor

where
In our prior knowledge, those extracted features are acting respective roles involving the wrench modality would sense the collision with the environment, the velocity modality would perceive the accidental human collision various in orientation and magnitude as well as the tactile modality would take responsibility to the object slip and no object situation. Therefore, our feature vector

Illustrates the extracted features of ten nominal executions in the kitting experiment, where different movements are represented in different colors. “Gray” represents the robot is moving to home or pause, we will ignore those situations in this paper; “Red, Green, Blue, Cyan, Magenta, and Yellow” indicate the underlying dynamics in Movement 3, Movement 4, Movement 5, Movement 7, Movement 8, and Movement 9, respectively. We can intuitively assume that almost all the unexpected anomalies can be identified by monitoring the wrench, velocity, and tactile modalities.
Verification and evaluation metrics
To evaluate the feasibility and efficiency of the considered methods for anomaly detection in the HRC scenarios by assessing the tradeoff between false positive (FPR) and true positive (TPR) rates. We first present all of our detection results as receiver operating characteristic curves (ROC) across six movements in the kitting experiment. Each resulting point in ROC is generated by varying a single parameter
Performance comparison
Various modalities combinations
We investigated if multiple modalities improve the detection performance of those deep learning models. Table 4 shows average AUC over modality combinations of various modalities (i.e. force
Anomaly detection performance (the AVERAGE AUC across all the movements) over various modalities combinations with fixed anomaly bias “[−1, 1].”

Where
The bold values represent the best performance.
Various anomaly bias
In this section, we evaluate the performance with various anomaly bias (Changing the anomaly region that labeled by human during data collection) under the optimal modalities combinations
Anomaly detection performance (the AVERAGE AUC across all the movements) over various anomaly bias with considered models, where “[−1, 1]” denotes the observations located in the anomalous range before/after 1 s of the labeled moment by human during data collection, and “[0, 0]”. a
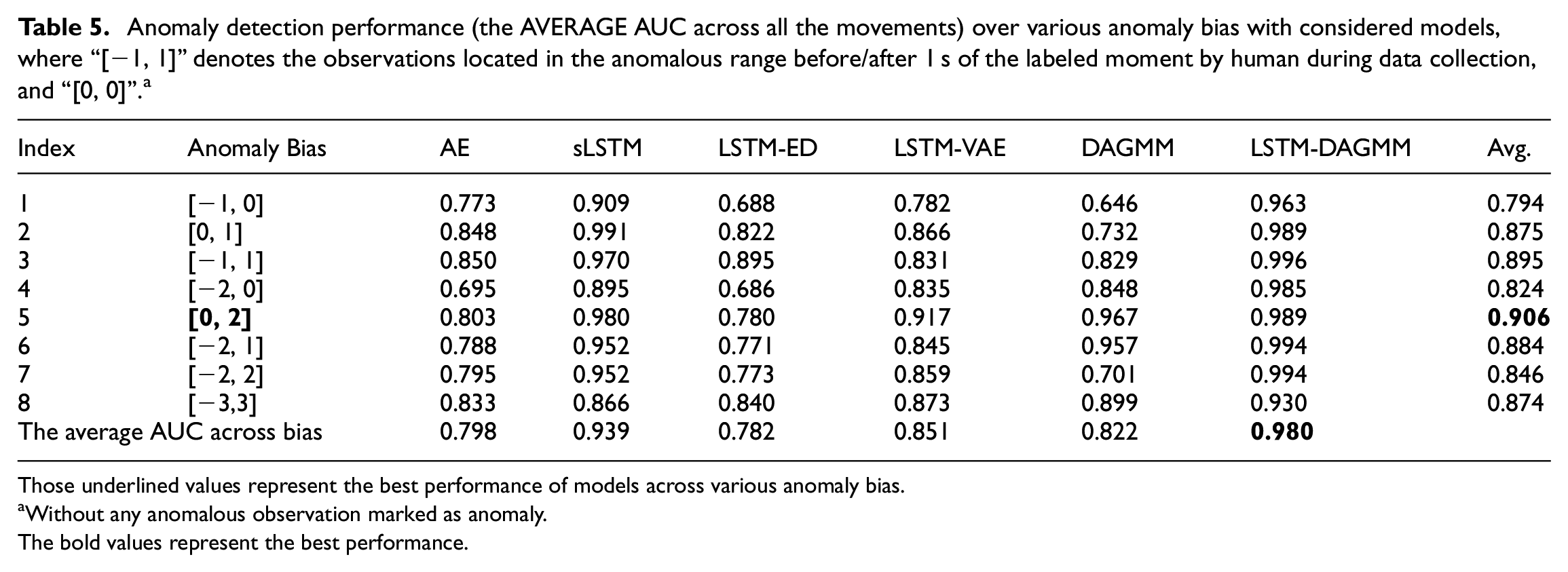
Those underlined values represent the best performance of models across various anomaly bias.
Without any anomalous observation marked as anomaly.
The bold values represent the best performance.
We finally present all of our anomaly detection results with optimal modalities combination with

Illustration of the ROC curves with optimal modalities combination with
Conclusion
In this paper, a comprehensive comparison of six representative unsupervised methods for multimodal anomaly detection,including recurrent neural network based autoencoder (AE), stacked Long-short Term Memory (sLSTM), LSTM-based encoder and decoder (LSTM-ED), LSTMs-based Variational Autoencoder (LSTM-VAE), Deep Autoencoder Gaussian Mixture Model (DAGMM), and its variants with LSTM encoder-decoder (LSTM-DAGMM). Experimental verification is performed in a multimodal dataset of self-designed human-robot collaborative task and results indicate that
Intuitively, the norm magnitude of modality would model the underlying dynamics and depress the noise, which effectively improve the anomaly detection performance; RNN-based deep learning architecture should improve the modeling capability of time-dependent observations.
Multiple modalities would substantially more effective than uni-modalities in anomaly detection. However, it does not indicate that more modalities always enhance detection performance;
LSTM-DAGMM outperforms all the other models for multimodal anomaly detection, which can be easily used to anomaly monitoring of healthcare, autonomous production line, etc;
For the implementation procedure, reconstruction error-based methods outperform the prediction error-based methods during multimodal anomaly detection.
We believe that this comprehensive comparison will offer a detailed knowledge about the state-of-the-art of recent research in the field of deep learning-based multimodal anomaly detection, and help researchers to purse research to address open issues and existing challenges in this direction.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by Guangdong Province Key Areas R&D Program (Grant No. 2019B090919002, 2020B090925001), Guangdong Provincial Key Laboratory of Electronic Information Products Reliability Technology (2017B030314151), Guangzhou Basic and Applied Basic Research Project (Grant No. 202002030237), GDAS’ Project of Thousand doctors(post-doctors) Introduction (2020GDASYL-20200103128), Foshan Key Technology Research Project (Grant No. 1920001001148), Foshan Innovation and Entrepreneurship Team Project (Grant No. 2018IT100173), Guangzhou Science Research Plan Major Project (Grant No. 201804020095), Guangzhou Science and Technology Plan Project (Grant No. 201803010106), Guangdong Province International Cooperation Project of Science and Technology (Grant No. 2019A050510040), National Science Foundation of China (Grant No. 61950410758).