
Abstract
In order to solve the problem that the existing reinforcement learning algorithm is difficult to converge due to the excessive state space of the three-dimensional path planning of the unmanned aerial vehicle, this article proposes a reinforcement learning algorithm based on the heuristic function and the maximum average reward value of the experience replay mechanism. The knowledge of track performance is introduced to construct heuristic function to guide the unmanned aerial vehicles’ action selection and reduce the useless exploration. Experience replay mechanism based on maximum average reward increases the utilization rate of excellent samples and the convergence speed of the algorithm. The simulation results show that the proposed three-dimensional path planning algorithm has good learning efficiency, and the convergence speed and training performance are significantly improved.
Introduction
Unmanned aerial vehicle (UAV) has attracted wide attention from scholars all over the world in past decade. UAV has the advantages of small size, low cost, convenient use, low requirements for the operational environment, flexible, no casualty risk, and so on. It is widely used in aerial photography, plant protection, express transportation, disaster rescue, surveying and mapping, power inspection, reconnaissance, and other fields. Path planning is one of the key technologies for UAVs to accomplish the above tasks. Path planning refers to finding an optimal or feasible trajectory from the starting point to the target point under given space and constraints. UAV path planning is an NP complex problem with multiple constraints, which include fuel consumption and maneuvering constraints, terrain obstacles, threat information, and so on. Many scholars have done a lot of work in path planning.
Reinforcement learning is an important method in the field of machine learning. 5 Unlike supervised learning and unsupervised learning, reinforcement learning relies on the agent to continuously interact with the environment, and each interaction receives an evaluative feedback signal in return for learning the optimal behavior by maximizing its cumulative reward. Theoretically, reinforcement learning does not depend on the exact model. Whatever exploration and utilization strategy is adopted, it will converge to the optimal value after a long enough time. But for a practical problem, when the state space is large and each state can perform more actions, there will be a very large state-action space. In order to accelerate the convergence speed of reinforcement learning algorithm, researchers have proposed several effective methods. Hengst 6 uses hierarchical reinforcement learning to decompose large-scale reinforcement learning problems into several sub-problems, which reduces the state space of the problem. However, reasonable hierarchical processing is a challenging task and is difficult to achieve. Andrew et al. 7 introduced shaping function into reinforcement learning and added heuristic value to the returns of agents, which effectively improved the convergence speed. Asmuth et al. 8 used potential field function as a priori knowledge to enlighten the reinforcement learning process and proved the effectiveness of the algorithm.
Based on the existing reinforcement learning algorithm for path planning, this article proposes a three-dimensional path planning method for UAV based on heuristic return function and maximum average reward experience replay mechanism. First, the state space of UAV is discretized to reduce the scale of path planning problem. Then, a heuristic reward function is constructed based on the maneuverability of UAV, fuel consumption, terrain obstacles, flight altitude, and other factors to improve the convergence speed of the algorithm. The experience replay mechanism is improved, and the importance of samples is evaluated by the maximum average return value at a small computational cost. Finally, the validity of the method is verified by the three-dimensional path planning simulation experiment of UAV, which achieves the effective approximation of the value function, and has good learning efficiency and generalization performance. The convergence speed and training performance are obviously improved.
Problem formulation
The state space of UAV in real environment is continuous, which greatly increases the difficulty of problem-solving. Therefore, three-dimensional discretization of planning space should be carried out first, so the search space of path planning problem is reduced to a discrete set of spatial nodes; each node

The set of all flight paths, including the starting point and the target point, is represented by L

The cost from state space node

where
Q-learning
Algorithm principle
The research of reinforcement learning is based on the theoretical framework of Markov decision process (MDP). The state and reward of the next moment only depend on the current state. The MDP can be represented by a quaternion
S is the set of states, and any state
A is the set of actions, and any action
R is the reward function, which represents the immediate reward that UAV receives when it executes an action
The model of reinforcement learning can be described as UAV–environment interaction in Figure 1. The UAV chooses an action

Reinforcement learning model.
The goal of reinforcement learning is to learn a good strategy to maximize future cumulative rewards in sequential decision-making. The sum of discount cumulative rewards is called expected reward

where
The state-action value function

Q-learning algorithm is a model-free offline strategy reinforcement learning control algorithm,
9
which has good convergence in discrete MDP. The state-action value function

where
Training strategy
Because of the huge state space of UAV’s three-dimensional path planning, it is difficult to record all state-action value functions in tabular form. At present, the common method is to approximate the optimal action-value function with neural network and adjust the weight parameters of neural network by reducing the mean square error of Bellman equation. However, the convergence of this method is poor. Experiential playback and target separation can accelerate the convergence speed of the algorithm. 11
Experience replay mechanism is proposed by Lin.
12
A fixed-length cached sample data set
Each sample
It breaks the correlation of continuous samples in traditional Q-learning algorithm and helps to prevent the algorithm from falling into local optimum.
Minh et al.
13
proposed to use two neural networks for learning, one is target neural network predicting

When the estimated neural network is trained, the loss function of the neural network can be written as follows

The estimated neural network is continuously updated. When it is updated to a certain number of times o, the parameters of the estimated neural network are copied to the target neural network. Target neural network delays the influence of parameter updating, eliminates the correlation between the estimated value and the target value, and reduces the possibility of non-convergence of the algorithm.
Action selection strategy
In order to ensure good convergence, action selection strategies need to consider both exploration and application. The commonly used action selection strategy is


Heuristic Q-learning
In order to improve the convergence speed of Q-learning, this article proposes a heuristic Q-learning method by improving the reward function and action selection strategy.
Reward function
Traditional Q-learning mostly uses sparse reward function. For path planning problem, if UAV reaches the target point, it will give a positive reward value, and if it collides with obstacles or exceeds the state space range, it will generate a negative penalty value. In other cases, the return value is generally 0. Sparse reward function has the advantages of simple calculation and easy design. But for UAV three-dimensional path planning problem, the state space is very large, the reward value of most actions is 0, and the probability of finding meaningful reward value is relatively small which leads to the slow convergence speed of learning algorithm. In order to overcome the shortcomings of sparse return function, a heuristic reward function

where
p
1 represents the fuel consumption cost of the UAV from state
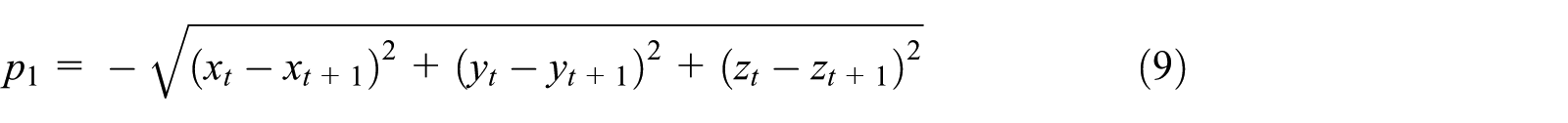
In the artificial potential field method, the target point will attract the UAV. According to this idea, this article constructs


where
p
3 is the cost of UAV deviating from cruise altitude
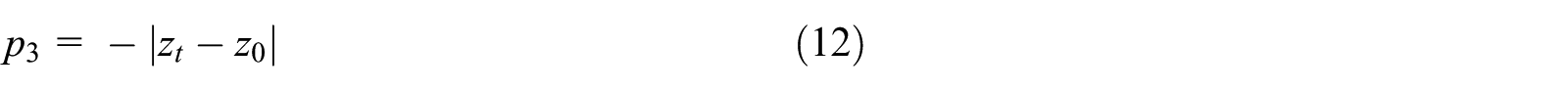
p 4 is the cost of collision between UAV and obstacle or beyond the scope of state space

where
p 5 is the reward value of the UAV when it reaches the target point. A larger reward value can make the algorithm converge quickly

where
Action selection strategy
The key point of Q-learning algorithm convergence is to explore and utilize the balance problem and choose the appropriate action selection strategy which can not only make UAV explore the environment fully to avoid falling into local optimal solution but also make the learning algorithm converge faster. The optimal strategy of Q-learning is usually based on the estimation of state-action value function
Therefore, this article designs an evaluation function

If

In the early stage of learning, UAV is ignorant of environmental information, so action selection strategies should pay more attention to exploration. With the deepening of learning, the reliability of state-action value function is getting higher, and action selection strategies should be paid more attention to and utilized. So

where

MARER Q-learning
The experience replay mechanism has the drawback that the sampling is randomly performed in the buffered sample data set, and the quality of the sample is neglected. The sample that the UAV has reached the target point after thousands of explorations may not have the Q-learning algorithm selected. In order to improve the learning efficiency, Schaul et al. 14 proposed the sampling strategy of prioritized replay and sorted the samples according to their importance. However, the algorithm needs to continuously sort the samples in the data set, which greatly increases the computational complexity.
In order to further improve the efficiency of the algorithm and reduce the complexity of the algorithm, this article proposes a preferred cached experience replay mechanism using the maximum average reward value (MARER Q-learning) based on heuristic Q-learning:
Calculate the average of reward values

Then update the maximum average reward value

If the maximum average reward value is updated, indicating that there is a good sample in this episode, all the samples included in this episode are directly put into the algorithm for learning, and the samples in this episode are copied three times and then put into the cached sample data set, which improves the proportion of excellent samples. Then, algorithm randomly selects m samples from the cached sample data set every n episode into the Q-learning algorithm for learning.

Simulation results
Assume that the mission area of the drone is 200 km × 100 km × 250 m, and a representative topographic map is generated according to typical terrain features. The discrete step in the horizontal direction is 5 km, and the discrete step in the height direction is 5 m. The discrete space of the three-dimensional path planning of the machine is 40 × 20 × 50, and there are 40 × 20 × 50 × 9 state-action values.
The expression for the terrain model used for the simulation is as follows



Three-dimensional topographic map.
Simulation experiment parameters are as follows:
Reward parameters
Discount factor
Neural network training interval
Position coordinates of starting point
The maximum number of steps per learning episode is 200.
By statistically reaching the episode of the target point successfully, as shown in Figures 3 and 4, we can clearly see the difference in convergence speed of the three reinforcement learning methods. Heuristic Q-learning begins to converge after about 1700 episodes. MARER Q-learning converges after about 1300 episodes. However, Q-learning has not reached the target point after 2000 episodes. The fastest convergence among the three algorithms is the MARER Q-learning algorithm, while the convergence of Q-learning is the slowest. Heuristic Q-learning constructs a reward function by introducing path information such as height and distance, so that the UAV can have a deeper understanding of the environment and actively eliminates adverse actions to reduce the motion search space, thereby accelerating the convergence speed of the algorithm. Based on the heuristic Q-learning, MARER Q-learning evaluates the pros and cons of the sample by the maximum average return value and makes the algorithm select the excellent samples in a targeted manner, thus achieving more excellent results.

The number of episode of successful reach to the target point.

Average reward per episode: (a) heuristic Q-learning and (b) MARER Q-learning.
The optimal three-dimensional path given by heuristic Q-learning is shown in Figure 5, and the projection of the optimal trajectory (heuristic Q-learning) on the height profile and the horizontal profile is shown in Figure 6. The optimal path given by MARER Q-learning is shown in Figure 7, and the projection of the optimal path (MARER Q-learning) on the height profile and the horizontal profile is shown in Figure 8. By comparing the vertical plane of Figures 6 and 8, it can be found that the flight height of the latter is lower, and the latter has better obstacle avoidance ability; by comparing the horizontal plane of the two, it can be found that the track of the latter is more straight and has better economic performance. In summary, the MARER Q-learning algorithm is better than the other algorithms in terms of convergence speed and planning results.
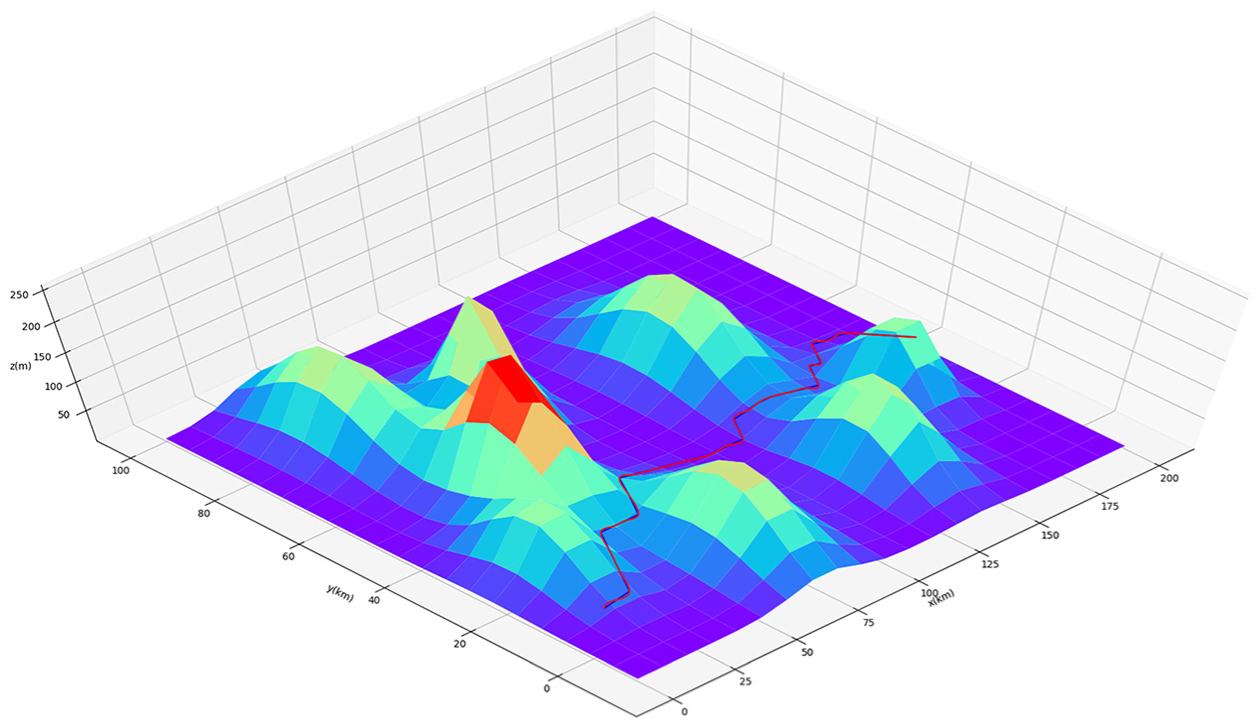
Three-dimensional path map of UAV (heuristic Q-learning).
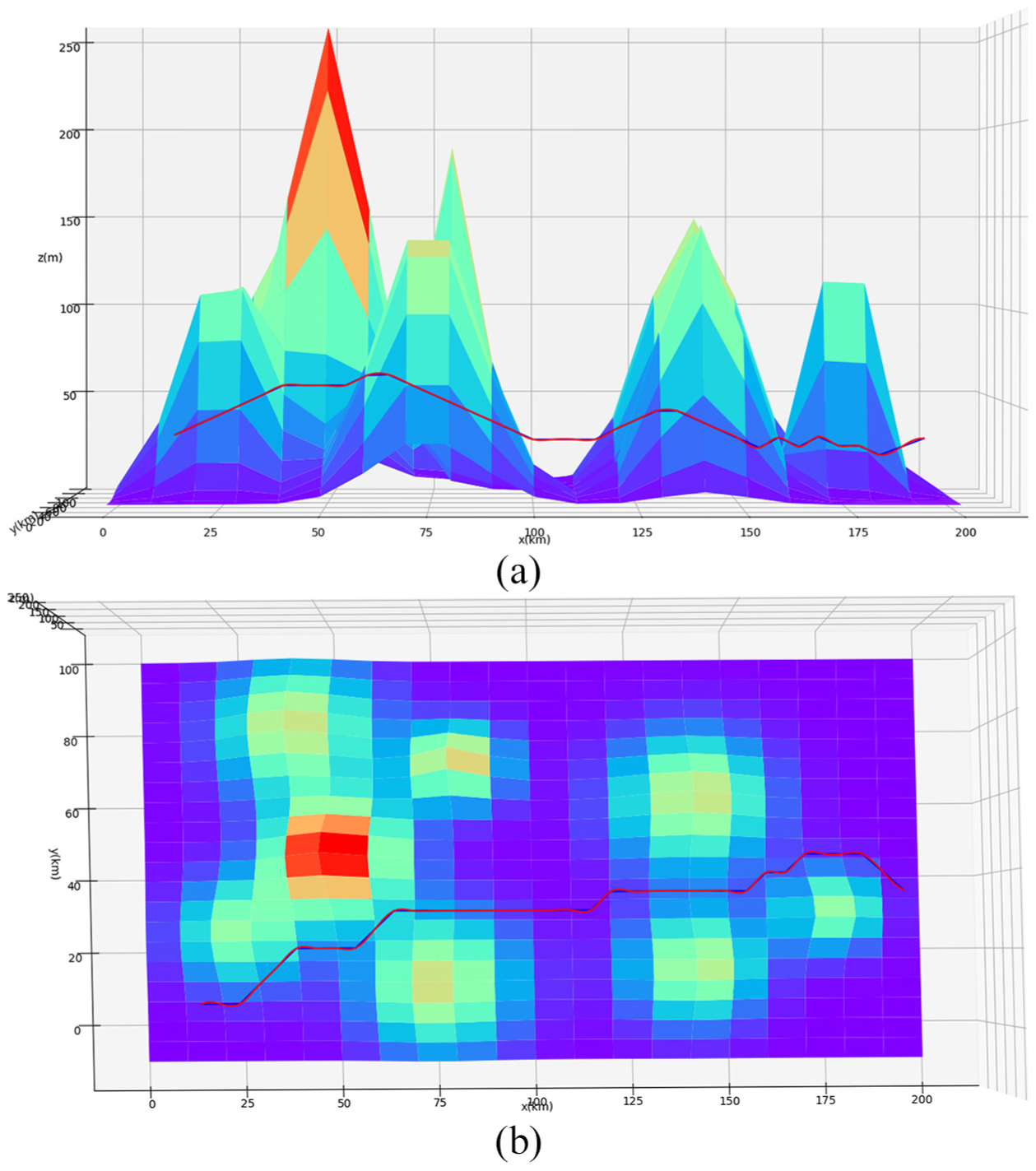
Three-dimensional path profile of UAV (heuristic Q-learning): (a) vertical plane and (b) horizontal plane.

Three-dimensional path map of UAV (MARER Q-learning).

Three-dimensional path profile of UAV (MARER Q-learning): (a) vertical plane and (b) horizontal plane.
It can be seen from the figure that the two reinforcement learning methods can successfully find the lower position of the two mountain joints and pass through them, climb up after encountering obstacles, and the altitude will drop to cruise altitude after overturning obstacles. The path planning of MARER Q-learning is better than that of heuristic Q-learning. The three-dimensional path planning of MARER Q-learning is mostly flat, basically the best path from the starting point to the target point.
Conclusion
Traditional Q-learning methods are less efficient. When the scale of state space increases linearly, the complexity of the problem increases exponentially, so the traditional reinforcement learning method is difficult to solve the problem of UAV three-dimensional path planning. This article proposes a Q-learning algorithm based on the heuristic function and the maximum average reward value of the experience replay mechanism. By synthetically considering the constraints of UAV path planning, a heuristic function is constructed to guide the learning behavior of UAV effectively, which can break away from blind exploration to a certain extent and improve the learning efficiency. The improved empirical playback mechanism greatly improves the convergence speed of the algorithm with a small computational cost. The simulation results show that the three-dimensional trajectory obtained by the proposed method of UAV’s three-dimensional path planning achieves the expectation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work received support from National Natural Science Foundation of China (No 61702023, 61976014) and Fundamental Research Funds for the Central Universities.