
Abstract
Critical appraisal is a key skill employed across the spectrum of laboratory medicine practice. It underpins the use of information that is relevant, of good quality and is meaningful. Relevance is answering the right question for the right patient at the right time, with quality ensuring provision of the right information. Meaningful is making the right decisions in order to deliver the right outcomes. Critical appraisal is about minimizing the risk of bias or ‘departures from trueness’ in all of the facets of laboratory medicine practice. It can be summarized in four steps: (i) a clear understanding and articulation of the problem being addressed – whether it be an analytical challenge, individual patient care or policymaking; (ii) verifying the methodological approach employed; (iii) assuring the reliability of the results and (iv) ensuring the applicability and implications of the results. Reference is made to a number of checklists that can be used to assist in the process of critical appraisal.
Keywords
Introduction
It is easier to be critical than correct. (Benjamin Disraeli, 1804–1881)
Making the best possible, evidence-based, decisions is an important element of professional laboratory practice, irrespective of whether it is in the laboratory, on the ward or in the management setting.1,2 The process of decision-making involves critical thinking and a thoughtful and systematic approach to the evaluation of information; this approach to practice is important throughout professional life. Critical appraisal of information in the context of laboratory medicine is applicable during the education and training, service delivery, research, clinical, managerial and leadership facets of one’s career. Therefore, the appropriate generation, evaluation and use of information taking into account the issues of relevance, quality and meaning are vitally important.
Critical appraisal is one of five steps, or ‘A5’, used in the practice of evidence-based laboratory medicine: Ask, Acquire, Appraise, Apply and Audit.3–5 Figure 1 shows that a sixth step, i.e. ‘Analyse’, between Appraisal and Apply is frequently included when performing systematic reviews.
6
The A5 or A6 cycles serve as decision-making frameworks that can be used in the commissioning, delivery and management of laboratory medicine services. Critical appraisal specifically examines the relevance, validity and applicability of information; these elements will be explored in this review in relation to the varying ways in which a laboratory medicine investigation may be employed.
A6 cycle strategy for systematic reviewing. The Analyse step may not be relevant for addressing questions in routine practice.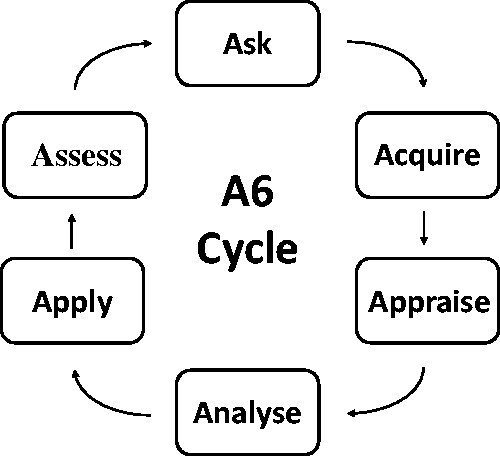
Critical appraisal has been described as ‘the process of carefully and systematically examining research to judge its trustworthiness, value and relevance in a particular context’.7,8 There are four fundamental questions being addressed in critical appraisal.
What is the explicit question (or problem) being addressed in the information provided, e.g. a study? Was the work that forms the basis of the information conducted well methodologically? Are the results at the core of the information reliable? Are the results applicable to the current problem?
The first three questions deal with the issue often referred to as ‘internal validity’ – are the results robust? The final question deals with the issue referred to as ‘external validity’ – can the results be applied to my problem? 9
Critical appraisal is used in (i) reviewing a paper that might answer a question regarding a specific clinical scenario; (ii) performing a systematic review, e.g. at the commencement of a research project or health technology assessment; (iii) development of clinical or other practice recommendations or guidelines and (iv) as part of the development of health care policy.
Methodological quality in research and practice
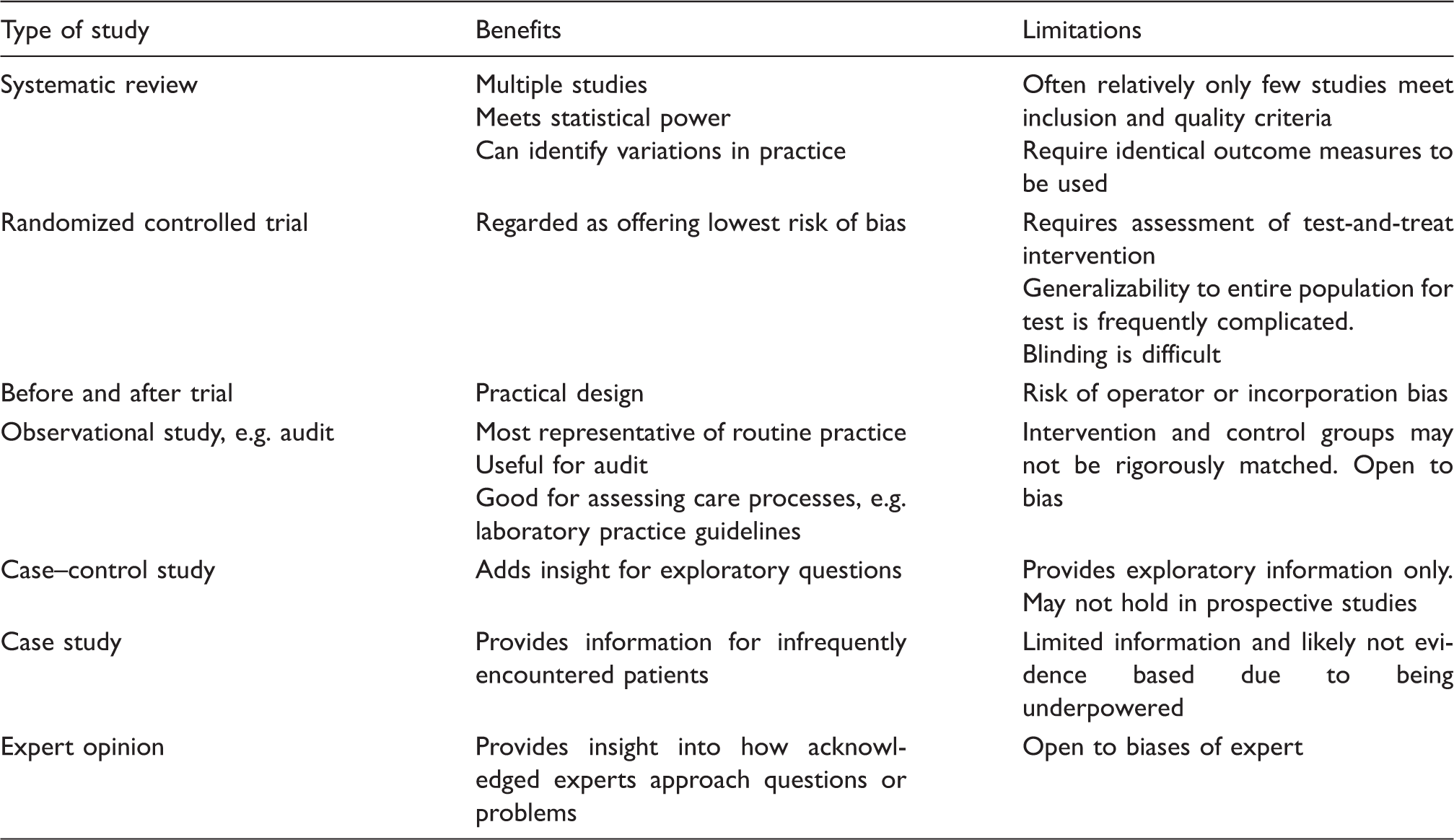
Hierarchy of evidence in laboratory medicine.
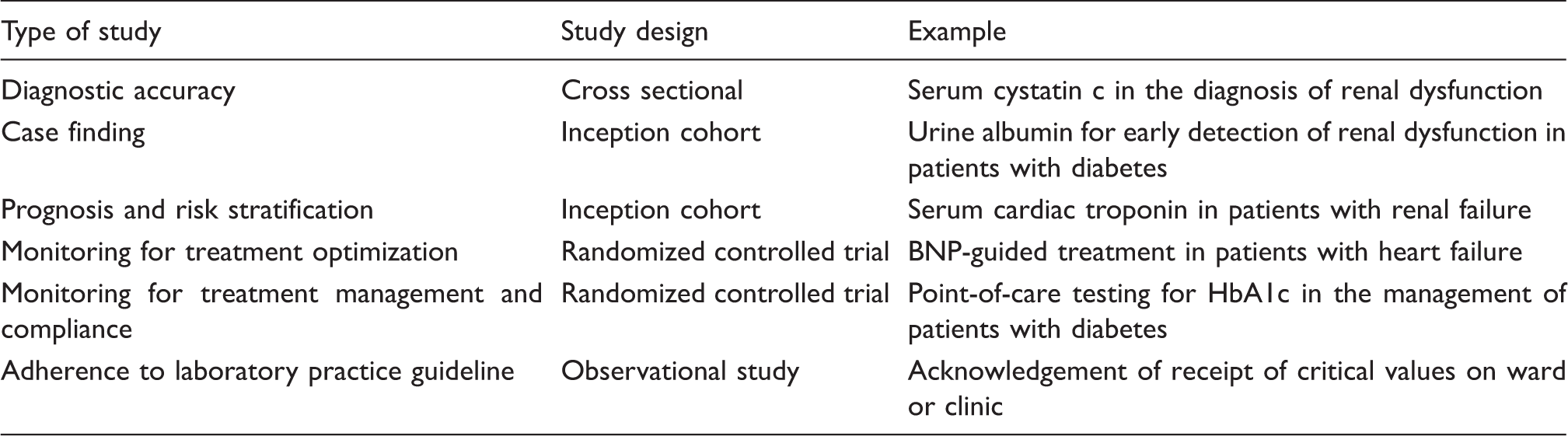
Trial design used in laboratory medicine.
The quality, and consistency of evidence and practice is dependent on what can be considered ‘departures from trueness’; this is generally referred to as bias. It was recognized several decades ago that new diagnostic tests and devices were becoming available with little evidence to support the safety and effectiveness of their use.14,15 Furthermore, despite the availability of methodological standards to guide the generation of robust evidence, compliance with such standards was poor. This led to concerns about the use of tests where safety and effectiveness had not been demonstrated. 16 Some of the most common causes of bias are discussed in the following paragraphs: a useful glossary can be found at the Cochrane Collaboration site. 17
Spectrum bias
This is a generic term that draws attention to the fact that there may be differences in the performance of the test in different patient populations. It is a commonly reported problem in studies of diagnostic accuracy, using a case–control design where the two populations (case and control) show different characteristics. An extreme example would be comparing results in a group of patients with the condition, with a healthy population serving as the control group. The performance of a test can change according to a range of demographic variables, examples being gender, age, height and weight, disease severity, other co-morbidities, as well as different clinical settings (as they are likely to reflect disease status), e.g. home, primary and secondary care settings. Similarly the prevalence of the disease in the population being studied may also have an impact on the diagnostic accuracy. 18 Lijmer et al. studied the comparative effects of a range of biases using the relative diagnostic odds ratio in a total of 18 meta-analyses, finding that spectrum bias had by far the greatest effect. 19 Rutjes et al. performed a similar review of 31 meta-analyses, and using the relative diagnostic odds ratio to compare the effect between biases. They found that the greatest effect of spectrum bias was when the control group was a healthy population (relative diagnostic odds ratio 4.9 (95% confidence interval (CI) 0.6–37.3)). 20 Spectrum bias can also include selection (also referred to as ‘recruitment’) bias which occurs when only a specific population or type of patient is selected from the disease continuum, e.g. a certain age group, and when the test is intended for a wider spectrum of patients. It could also occur if the reference test is undertaken first and is thought to play a part in the patients subsequently chosen to receive the index test.
Clearly spectrum bias is a key item to examine in the critical appraisal exercise in routine clinical practice. It is important to select the evidence from literature where the study population matches that of the patient or population of current interest. Willis illustrated this in primary care practice with the impact of mismatch between study and practice populations. 21
Underpowered study bias
Power calculations are an important part of study design. Such calculations are routinely seen in randomized controlled trials of therapeutic interventions but are far less common in diagnostic accuracy studies. 22 The main consequence of this is that it is not possible to gain any insight into the variability of measures or any reliable analysis of subgroups within the population studied.22,23 For researchers and others interested in estimating the proper number of subjects needed to reliably power diagnostic studies, there is a straightforward and accessible nomogram tool developed by Carley et al. 24
Attrition bias
Invariably there are some participants in any study ‘lost-to-follow up’. It is important to assure that all of these are accounted for, because their loss can lead to a form of selection bias. Similarly there is an equivalent exercise in systematic reviewing where studies are excluded, e.g. if they do not meet the inclusion criteria as far as participants are concerned, or do not meet the methodological criteria. These exclusions also must be explained so that readers can understand how indeterminate results may arise and are dealt with.
Verification bias
This can also be referred to as ‘work-up bias’ or ‘referral bias’. It refers to the situation when the results of the index test influence the choice of the reference test. Reference tests may be invasive, carry risks or are more costly, such that the reference test is only used in the case where the index test is positive. This has also been referred to as ‘partial verification bias’. Alternatively there can be ‘inappropriate reference test bias’ when the reference test does not represent the best available comparator. Lijmer et al. found that use of different reference tests gave the second highest level of bias. 19 An example of the latter could also include the use of an in vitro test where there is no agreed reference method or reference material. Such a situation was reported as a limitation in the systematic review of a point-of-care test for the detection of albuminuria using the urine albumin creatinine ratio. 25 There is also the situation when the information related to the index test is included in the diagnostic criteria. This is referred to as ‘incorporation bias’ 26 and an example is the case where a cardiac marker result (e.g. cardiac troponin) is ‘incorporated’ in making the diagnosis of myocardial infarction in a study to assess the diagnostic accuracy of another version of a cardiac marker (e.g. a high sensitivity troponin).
Observer or operator bias
Here the person using the test result is aware of other information about the patient, or the results of other investigations – including the index or the reference test result. This can also be referred to as ‘review bias’ and can lead to an overestimation of the effect, e.g. test accuracy. Observer bias can be mitigated by incorporating blinding into the study design; it can be applied to (i) selection of patients entered into a trial or arm of a trial, (ii) establishment of the definitive diagnosis (e.g. in a diagnostic accuracy study) or (iii) the reading of the test result using the reference method (e.g. in a method comparison study). Whilst this is straightforward in a diagnostic accuracy study it is more challenging in an outcomes study, especially when assessing the use of point-of-care testing (POCT), as it is difficult to blind the clinician or care-giver to the change of practice.
Disease progression bias
This can occur if there is a long delay between the index and reference tests being performed such that there has been a change in the disease status of the patients being studied.
Performance bias
While this might be considered a very generic potential form of bias it does cover systematic differences in the care, other than the intervention under investigation, provided to participants in the comparison groups. In the case of a test outcome study, especially in the case where the use of POCT is being assessed, a change in performance is important, i.e. responding to the rapid delivery of results. A failure to consider this can compromise the validity of the study.27,28 In the case of outcomes studies it is also important to report the detail of the care pathway, and ensure that this is followed, e.g. that the result is acted on and the appropriate treatment change is made. If this is not clear it reduces the quality of the findings and may lead to the study’s exclusion from a review. 29
Test reproducibility bias
Reproducibility of test results will undoubtedly have an impact on the clinical performance and effectiveness of the test, although it is not a particularly well documented effect. However, it is recognized as an issue in qualitative testing modalities, e.g. histopathology and imaging. Modelling approaches have been employed to identify the link between test variability and clinical decision-making, 30 and differences in technical performance have been demonstrated between operators with different professional backgrounds, e.g. clinical and technical, in relation to the impact on diagnostic accuracy. 25 It is important therefore that the technical performance of the analytical methods is described in detail.
Reporting bias
It was recognized over a decade ago that the quality of reporting of diagnostic studies was poor, thus making effective critical appraisal of evidence difficult. For many studies following how the design, conduct and analysis of data were undertaken, and consequently determining their impact on internal and external validity was complicated. It was concluded that this could have an adverse impact on clinical decision-making and a reporting checklist was proposed.31,32 The Standards of Reporting of Diagnostic Accuracy (STARD) statement is a checklist of 25 items and a flow chart that authors are encouraged to use to ensure that all of the necessary information is provided, and which covers the issues outlined above. 31 Many journals now require a completed STARD checklist at the time of manuscript submission and some improvements have been reported. 33
Publication bias
This is a recognized phenomenon, and there are a number of approaches that have been proposed for the detection of publication bias, especially when the studies are candidates for use in meta-analysis.34,35 Publication bias spans from the reluctance to publish ‘negative data’ through duplicate reporting of results either in their entirety or inclusion of an earlier reported cohort into a larger study. The consequence is that in a meta-analysis the patient cohort may not be representative of that claimed.
Tools for critical appraisal must include criteria for assessing the risk of bias in all aspects of work and laboratory medicine practice. The importance, implications and stages in assessing risk of bias in individual studies and systematic reviews have been articulated in a recent document published by the Agency for Healthcare Research and Quality. 36 This document reiterates that assessing the risk of bias is a part of assessing the strength of a body of evidence, but must be considered separately from items covered in other domains. Thus, it is recommended that reviewers separate criteria for quality assessment or risk of bias from appraisal of poor reporting; industry funding; disclosed conflict of interest; applicability of results (external validity); precision, i.e. the certainty surrounding an outcome’s effect size estimate based on sample size and number of events; and directness, i.e. whether evidence directly links an intervention to an outcome of importance and/or whether comparison studies are conducted head to head.
Critical appraisal tools
There are a number of critical appraisal tools that have been described, as well as being reported in the systematic review literature.
Centre for Evidence Based Medicine, Oxford (CEBM) (http://www.cebm.net/critical-appraisal/).. There are a number of appraisal forms for evaluating diagnostic, prognostic, evaluation of harm, therapeutic questions and systematic review. The site also contains useful definitions and calculators.
Critical Appraisal Skills Program (CASP) (http://www.phru.nhs.uk/learning/critical_appraisal_tools.htm). There are several critical appraisal tools for use in evaluating a variety of study types including diagnostic, economic, qualitative, randomized clinical trials, case control and cohort studies, as well as systematic reviews.
Screening and Diagnostic Test Evaluation Program (STEP) (http://www.health.usyd.edu.au/step/). This site explores the test performance characteristics of different screening and diagnostic tests.
Quality Assessment of Diagnostic Accuracy in Systematic Reviews (QADAS 2) (http://pubmedcentral.gov/articlerender.fcgi?artid=305345). This is a quality assessment tool intended for use in performing systematic reviews to assess the quality of primary studies of diagnostic accuracy. 37
Appraisal of Guidelines for Research and Evaluation (AGREE 2) (http://www.agreecollaboration.org/). The AGREE instrument is intended to provide a framework for assessing the quality of clinical practice guidelines. It was developed through discussion between researchers having extensive experience and knowledge in clinical guidelines. 38
National Institute for Care and Clinical Excellence (NICE) (http://www.nice.org.uk/article/PMG6/chapter/1%20Introduction). Methodology for the development of clinical practice guidelines; uses the Grading of Recommendations Assessment, Development and Evaluation (GRADE) process. 39
Scottish Intercollegiate Guidelines Network (SIGN) (http://www.sign.ac.uk/methodology/index.html). Tools for the development of clinical practice guidelines; uses the GRADE process.
In 2004 the GRADE Working Group reported a critical appraisal of the systems for grading the quality of evidence and strength of recommendations in the development of clinical guidelines, concluding that approaches at the time had important ‘short comings’.39,40 The working group subsequently developed new recommendations, which have begun to be adopted.40–42 Emphasis has been placed on separate consideration of the quality of the evidence and the strength of the recommendations, and some of the former will be discussed further. There are two important features in the GRADE approach as far as diagnostic tests are concerned: (i) a randomized trial is the preferred approach to assessing the diagnostic performance of a test, as earlier approaches to diagnostic accuracy (e.g. a cross-sectional study) require that inferences are made about patient important outcomes, e.g. morbidity and mortality, and (ii) it separates quality of evidence from strength of recommendations and in so doing it gives the opportunity to ‘trade up’ poorer quality evidence, e.g. from observational studies, if the effect was positive and consistent, when it comes to strength of recommendations. 43 One of the key points is to ensure that the performance of the test is assessed in relation to the impact on ‘patient-important’ outcomes. This increases the degree of similarity between the diagnostic and the monitoring test – alone, a test result is not effective, and has no value. 44
Centers for Disease Control (CDC) Laboratory Medicine Best Practices Program (LMBP) (http://wwwn.cdc.gov/futurelabmedicine/our_methods/default.aspx).
LMBP™ systematic reviews are conducted using the six-step ‘A6’ model (Figure 1) to focus on practice effectiveness for preanalytical, analytical and postanalytical laboratory practices. 6 The critical appraisal and other methodology were adapted from validated evidence-based review strategies, including those from the US Preventive Services Task Force 45 and the Task Force on Community Preventive Services. 46 A standard checklist is used for each review; candidate studies that meet the stated inclusion criteria are summarized to generate a body of candidate evidence. Each piece of candidate evidence is rated quantitatively by at least two independent reviewers 6 ; rating discordances are determined by consensus. The body of evidence is ‘Analysed’, and the overall classification awarded is based on effectiveness from the combination of effect size and study quality ratings into four categories: (i) high, (ii) moderate, (iii) suggestive or (iv) insufficient. The evidence review is then forwarded to an independent CDC work group that decides, based on the body of evidence, on a final disposition of (i) recommend, (ii) no recommendation for or against or (iii) recommend against.
Conducting a critical appraisal
The process of critical appraisal is typically undertaken with the aid of a checklist, choosing the one most appropriate to the problem being addressed. The framework of the majority of checklists is based on the review of the clinical research literature. However, it is possible to modify checklists for other applications based on the problem(s), articulated in questions, and the available evidence that must be appraised to draw valid and reliable conclusions. The process is facilitated if the investigators have followed experimental research guidelines on how to avoid bias, robust patient recruitment, statistical power calculations and choice of evaluative statistics. A description of such a comprehensive process can be found in the Cochrane Collaboration’s Handbook for Diagnostic Test Accuracy Reviews. 47 Similarly, answering the critical appraisal questions is aided by adherence to reporting guidelines, such as the STARD guidelines, 31 that can ensure the necessary information is included.
While critical appraisal in the individual patient setting may be conducted on an individual basis, when undertaken as part of a technology assessment or clinical guideline development programme, it will be conducted on a team basis. Thus, typically two members of the team will independently assess the relevance of the studies that have been found in relation to the steps outlined in the following paragraphs. The degree of concordance between the assessors is then reported as well as the decision of an arbitrator when disagreement arises.
Examples of checklist use for addressing key questions for three test utilities are described in the following paragraphs. The questions are primarily based on the CASP and CEBM critical appraisal checklists, as well as those provided in an Evidence-Based Laboratory Medicine (EBLM) workbook that includes examples of completed checklists. 9 Many critical appraisal checklists focus on clinical effectiveness and thus clinical outcomes. However, here the examples describe the process of appraisal from a generic perspective for the purpose of enabling use of the core features applicable to other settings requiring similar critical skills, e.g. performance management, quality improvement, clinical audit, cost effectiveness and process efficiency. Although the approach to critical appraisal remains basically the same, some aspects of the methodology for evaluating the evidence and the outcome measures will vary.
Step One: identifying the problem or the question being asked
A clear question that accurately reflects the problem being addressed is the crucial starting point for any problem-solving task where critical appraisal is applied. 48 The PICO approach (Patient or Population, Index test, Comparator, Outcome) is commonly used to state the problem clearly. It should address the characteristics of the patient or population being considered, the clinical setting and the expected outcomes – the P of PICO. Characteristics specified should include age, gender, ethnicity, family history, co-morbidities and clinical state, e.g. symptoms, severity of state, as well as clinical setting of presentation, e.g. home, primary care, Emergency Department, ward, etc. This definition of patient or patient cohort will feature twice in the critical appraisal process: (i) to establish the nature of the problem being addressed, i.e. the reason that prompted the critical appraisal (an individual patient problem, a systematic review topic, etc.), and (ii) to establish the topic of the information, e.g. research study being appraised to determine its relevance to the current problem.
Assessing prognosis is primarily concerned with mortality or the risk of complications associated with the disease. Broadly speaking it could also be considered for stratification of patients in relation to potential choice of treatment intervention. Thus, it is important to understand the patient population being studied, including age, gender, ethnicity, family history, co-morbidities and disease history.
In the case of an outcome study, the question should consider both the patient (or population) being considered and identify the test and the intervention that constitutes the ‘test-and-treat’ management strategy and the expected outcomes.
Step Two: verifying the methodological approach
The methodological approach will vary according to the application of the test, i.e. diagnosis, prognosis or supporting treatment intervention. In the case of diagnosis, the outcome (the ‘O’ of PICO) is the diagnostic accuracy of the test of interest (i.e. index test, the ‘I’ of PICO) assessed against the comparator, which is the best available means of making a diagnosis (the ‘C’ of PICO) – which, if practical, is likely to be the method in common use.
Prognostic and risk stratification applications of a test ask about outcomes – what is the risk of the patient developing worse morbidity or of dying? The P, I and O variables of PICO remain the same for diagnostic and prognostic studies; the ‘C’ element may be absent in prognostic studies because the magnitude (or dose) of the index test may be the indicator or risk. In order to provide a concise commentary of the critical appraisal question, we have chosen to combine these two test utilities. The outcome measures will be morbidity and mortality, or accepted surrogates.
Outcome studies associated with the use of diagnostic tests are, by definition, challenging because more than one decision is being made during the intervention. While any use of an appropriate test, be it screening, diagnosis or monitoring, involves multiple decisions – at a minimum the decision to request a test and the action made upon receipt of the result. The use of tests for monitoring can include choice of treatment, amount of treatment, change of treatment and monitoring of efficacy. It could also include how the test is delivered, e.g. with the use of POCT for real-time result notification. Informing treatment decisions can be considered as a complex intervention, 49 often called a ‘test-and-treat’ intervention. 50
Is there an appropriate comparator? In a diagnostic accuracy study, the comparator is a reference method – the best method available. Further, there are two elements to the method that can have an impact on the accuracy of the result, the method principle and reagents, e.g. immunoassay and choice of antibodies, and the calibration of the method. Frequently, there are not internationally agreed-upon reference methods or reference materials, with consequent increased variability in inter-method performance. 51 This can be a limitation in diagnostic accuracy studies. A further point that also has to be taken into account is the method that has been used in studies to define the clinical decision point (cut-off value), as it may have a bias when compared to an agreed reference method, or the index method under consideration.
Outcome measures to assess benefit of laboratory medicine service.
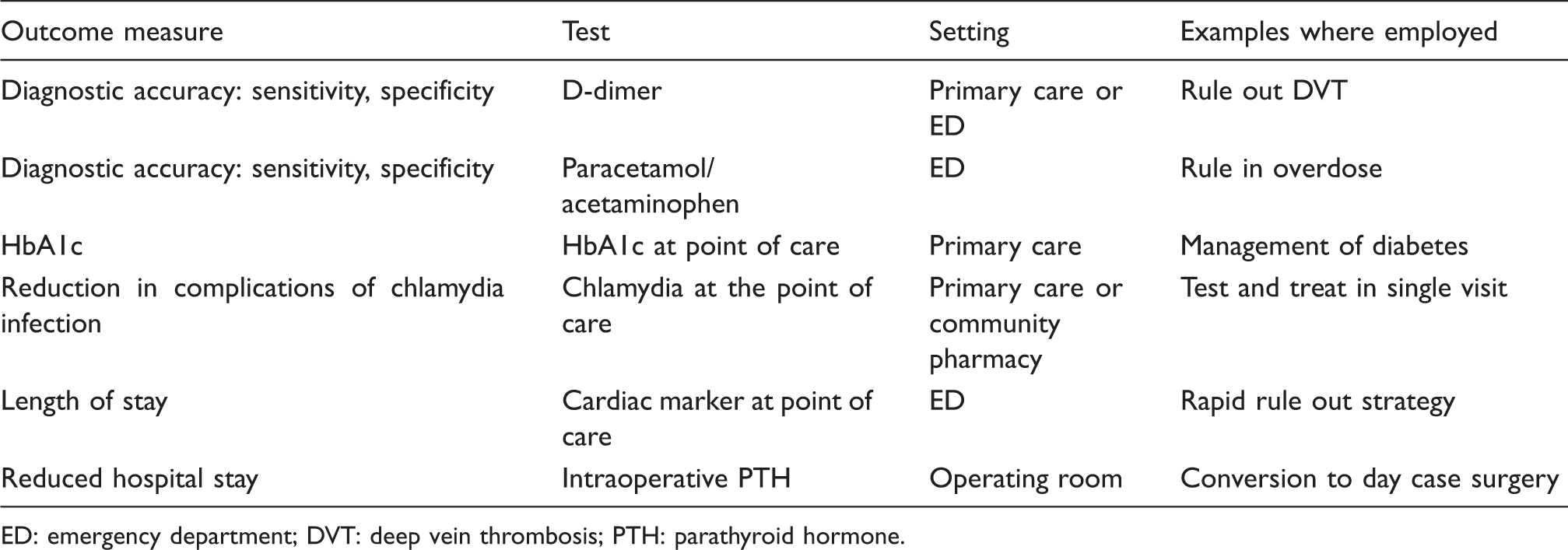
ED: emergency department; DVT: deep vein thrombosis; PTH: parathyroid hormone.
In outcome studies it is always important to clearly describe the initial intervention in which the test is involved, as well as the current intervention, and to define the outcome metrics. There may be more than one way to assess the outcome, e.g. an absolute value or proportion of patients within desirable or target values. Thus, it can be helpful to choose that in most common use to enable inclusion of the information in meta-analysis and systematic reviews. One of the more difficult aspects is how to ensure that the complete intervention is provided, e.g. the ‘treat’ element of ‘test and treat’.
Did all of the patients get the diagnostic test of interest and the comparator measure? This question is primarily designed to check for any evidence of work-up bias, and assess the proportion of patients lost-to-follow up – and the reasons for the loss.
In a prognostic or risk stratification study, it is usual to recruit patients early after the diagnosis of the disease; these patients are referred to as an ‘inception cohort’. The patient characteristics are critically important as patients in secondary care may have more advanced disease than those presenting in primary care, and thus different prognoses.
In the case of an outcome study, the questions can be more specific, such as when the ‘test-and-treat’ intervention is compared with a control group in a way that minimizes bias and yet ensured that the results were used to make clinical decisions leading to a demonstrable outcome. In this situation practice will differ between the experimental and control arms, and it is important that the clinical decisions and actions in all arms are clearly described. Furthermore, it may be helpful to know if the control arm of the study represented current clinical practice.
In all types of studies it is also important to be aware of the number of participants lost to follow up; was it recorded? If there is a significant proportion of participants lost to follow up then there is potentially a risk of bias in the outcomes, especially if the number is not explained.
How is the situation when a subject in a randomized controlled trial is allocated to one test or treatment arm on initial assignment, but then changes their testing or treatment group reconciled? Use of the ‘intention-to-treat’ analysis is commonly utilized for this purpose. Intention to treat means that the subject’s harms, benefits and other outcomes will be included with the group they were assigned to initially and not with the testing or treatment cohort they eventually received. Use of intention-to-treat analysis can help avoid a number of misleading errors such as participant crossover, i.e. non-randomized attrition of subjects to the alternative test or treatment. Inclusion of intention-to-treat analysis is considered more straightforward than other forms of study design because it does not require observation of compliance status for different tests or treatments, or incorporation of compliance into the analysis. Intention-to-treat analysis is widely employed in published clinical trials; however, frequently it is incorrectly described and many problems have been apparent with its application in clinical trials. 52 As stated by Hollis and Campbell ‘Intention to treat is better regarded as a complete trial strategy for design, conduct and analysis rather than as an approach to analysis alone’. 52 Further, a fundamental issue for use of intention-to-treat analysis is that the data-set is complete, i.e. no missing outcome data. There is no consensus on how to conduct an intention-to-treat analysis when outcome data are missing.
Could the results for the test of interest have been influenced by the results of the comparator or test measure? This question concerns the ‘blinding’ of the operator to the results of the other method or comparator measure. For a diagnostic study examples include (i) when specimens selected for measurement using the index method are based on the result of the reference method or (ii) the diagnosis where the reference method result has contributed to the diagnosis. In an outcome study, this question would also cover the approach to allocation to experimental and control arms; is it truly random? Further, if the outcome is based on the magnitude of the test measurement, the test may be repeated inappropriately if investigators are not blinded to subject assignment. As mentioned earlier blinding in outcome studies involving diagnostic tests and devices can be challenging.
Is the disease status of the tested population clearly described? The information should include symptoms, family history (if appropriate), disease state or severity, co-morbidity and differential diagnosis. The disease state or severity might be reflected by the setting in which the study cohort presents, e.g. primary care, or Emergency Department. However that, in and of itself, might vary according to the health system or country of origin of the study. Accurate description of the target population’s disease state is the core of the PICO question addressed in the appraisal.
Was the protocol for performing the test described in sufficient detail? You should expect to see the methods described or referenced with an indication they were followed without any deviation. It is also helpful if performance and logistic metrics for the specific study are included, e.g. imprecision, anticoagulant used for collection, storage time and analytical bias of the methods. In the case of studies involving POCT, it is important to identify the professional background of the operator, e.g. technical or non-technical.
It is also important to understand the origin of the clinical decision values employed in the studies, including the population from which they were derived and the analytical methods employed in deriving those values, e.g. how does the method relate to current methodology and reference methods? Clearly stating what the decision or action of a clinician will be should be stated in the methods section as this is the critical treat element of ‘test and treat’. Also stating how clinical staff were educated on the protocol can be valuable.
In an outcome study the methods employed in both experimental and control arms should be described, such that the study could be repeated, including both performance of the tests used as well as the clinical decision-making and action processes, e.g. treatment changes. There might be specific features of the study protocol that might be critically important in a study, e.g. the time at which the specimen is taken, and when it is analysed. There should be robust and consistent outcome measures employed in the study and, ideally they should be accepted measures such that data from several studies can be combined in meta-analysis.
Critical appraisal Step Three: the results and their reliability
What are the results? The results in a diagnostic accuracy study should be based on the sensitivity and specificity, together with the derived parameters of likelihood ratios and predictive values. If not directly presented then the data presented should enable these parameters to be calculated.
In the prognostic study, the most common approach is reporting the proportion of individuals experiencing the event of interest. A more sophisticated approach is to report survival over time, in the form of a survival curve. 53 Statistical information can be provided in the form of an estimate of the risk reduction or the absolute risk reduction.
In an outcomes study, the results are expressed in terms of the outcome measure of interest; this could be a clinical outcome, e.g. reduction in HbA1c concentration; a process outcome, e.g. a reduction in the length of stay; or an economic outcome, e.g. cost per treatment episode.
How confident are you with the results? In order to be confident of the results, you need to be assured that the results did not occur by chance. Assurance can be given with the presentation of CIs, which should be considered compulsory. It is also helpful to know if the study is properly powered, i.e. a sufficient sample size has been included in the study to ensure that the effect of a given size is likely to be demonstrated.
Critical appraisal Step Four: the applicability and implications of the results
Can the results be applied to your patient(s) or the population of interest? When using information (i.e. results) from previous studies or observations (e.g. experience, audit or data mining of health records) it is important to ensure that the patients or populations are comparable, e.g. gender, age, ethnicity, similar clinical setting and similar stage of disease as far as can be ascertained. Other issues that need to be considered are the feasibility of the intervention and whether the benefits outweigh any risks that may be incurred.
Can the test be applied to your patient(s) or the population of interest? When it has been established that the evidence is relevant and of acceptable quality, the attention then moves to the practical issues of transferability and the challenges of adoption. It is necessary to consider all of the consequences of adopting the test including the perspectives of all stakeholders including patient, clinician, carer, provider organization and purchaser/commissioner. In this consideration it will be necessary to cover (i) clinical implications, e.g. any potential side effects; (ii) process implications, e.g. how to integrate POCT into the ambulatory clinic visit; (iii) required changes in practice and access to the necessary expertise, e.g. in interpretation of results and (iv) the issues of affordability, including the challenges of investment and disinvestment decisions.
Were all outcomes important to the individual or population, and other relevant stakeholders, considered? From the patient’s perspective it is important to consider whether knowledge of the results will lead to a change in patient management, and whether this will lead to improved patient experience and wellbeing. While the initial focus is on clinical effectiveness and the patient, it is important to be aware of the needs and perspective of other stakeholders. In terms of purchaser and provider, the impact will be on resource utilization and processes, and the impact on the respective organizations, in relation to their quality metrics. 54
Are the results of the study consistent with other available evidence? It is always necessary to be aware of the other evidence in the literature, as well as health technology assessments and current guidelines.
What would be the impact of using this test on your patient(s)/population and other relevant stakeholders? The impact on individuals is mirrored in individual and societal impacts, e.g. patient satisfaction, working days gained, etc.
Conclusions
Critical appraisal is a core skill set that will be required in laboratory medicine practice ranging from bench to bedside, in research, service provision, management and policymaking. There is a considerable literature covering critical appraisal as a tool, a large proportion of which is devoted to assessing the quality and relevance of evidence to support clinical decision and policymaking. The emphasis is about mitigating the effects of bias, while relevance addresses the issues regarding the problem for which answers are being sought.55,56 There are a number of checklists and other resources that can be used to address different types of applications or test utilities, e.g. diagnosis, prognosis, etc. as well as with different objectives in mind, e.g. systematic review, clinical guideline. All have a common core of four issues: (i) the question being addressed, (ii) the quality of the methodology used in the study where the answer might be found, (iii) the quality of the results and (iv) the applicability to the problem and the potential consequences of using the evidence.
It is equally important to recognize the context in which these skills are deployed, and the expectations of the stakeholders that define that context. Much has been made in recent years of the problems in health care that result from the fragmented nature of care provision, including the limitations of a silo approach to organization and management. 57 Laboratory medicine is a good example where there has been a heavy emphasis on analytical performance, with less of a focus on the link to clinical, operational and economic outcomes. One consequence is a parallel literature in laboratory medicine indicating a significant level of inappropriate testing – implying uncritical use … . or at least requesting (ordering) … … of tests.58,59 Hofmann has recently suggested ‘our abilities to produce and use technologies [i.e. tests] outrun our abilities to reflect on their application’. 60 Inappropriate testing represents a failure to apply critical appraisal skills to the use of laboratory medicine across the care pathway to address unmet clinical needs and improve health outcomes.
Critical appraisal skills in laboratory medicine therefore highlight the current limitations of practice, and the future direction the service should be taking if the goals of more integrated and systems approach to patient care are to be achieved.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This article presents independent research (CPP) funded by the National Institute for Health Research (NIHR) Diagnostic Evidence Co-operative Oxford.
Ethical approval
Not required.
Guarantor
CPP.
Contributorship
The authors contributed equally to the content of this review.
Acknowledgements
This article was prepared at the invitation of the Clinical Sciences Reviews Committee of the Association for Clinical Biochemistry. The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health. The study sponsors had no role in the design, analyses or reporting of the study. The researchers retained complete independence in the conduct of this study.