
Abstract
Background
Reference change values (RCVs) were introduced more than 30 years ago and provide objective tools for assessment of the significance of differences in two consecutive results from an individual. However, in practice, more results are usually available for monitoring, and using the RCV concept on more than two results will increase the number of false-positive results. Therefore, a simple method is needed to interpret the significance of a difference when all available serial biomarker results are considered.
Methods
A computer simulation model using Excel was developed. Based on 10,000 simulated data from healthy individuals, a series of up to 20 results from an individual was generated using different values for the within-subject biological variation plus the analytical variation. Each new result in this series was compared to the initial measurement result. These successive serial relative differences were computed to give limits for significant unidirectional differences with a constant cumulated maximum probability of both 95% (P < 0.05) and 99% (P < 0.01).
Results
Factors used to multiply the first result from an individual were calculated to create the limits for constant cumulated significant differences. The factors were shown to become a simple function of the number of results and the total coefficient of variation.
Conclusions
To interpret unidirectional differences in two or more serial results of a biomarker, the limits for significances are easily calculated using the presented factors. The first result is multiplied by the appropriate factor for increase or decrease, which gives the limits for a significant difference.
Keywords
Introduction
Differences in serial concentrations of a biomarker in an individual may be not only due to improvement or deterioration of disease, but are also due to inherent sources of variation, within-subject biological variation (CVI) and random analytical variation (CVA). A method to calculate the significance of change in serial measurements was introduced by Harris and Yasaka. 1 The basis for this method in monitoring serial results from an individual is that, for a change to be significant, the numerical difference must exceed the inherent variation, which is termed the reference change values (RCVs). Since all laboratories know the CVA of each of their analyses from internal quality control activities and because data on CVI are available for many quantities, 2 the total coefficient of variation (CVT) can be calculated from the estimates of CVA and CVI (CVT = [CVA2 + CVI2]½). 3 This variation is assumed to be normally (Gaussianly) distributed and the found result for any analysis lies within (±Z · CVT) with the probability defined by the applied Z-score. In this context, it is important to note that if the clinical decision making is based on either a significant decrement or increment, then the RCV is considered as unidirectional. The Z-scores for a unidirectional probability of 95% (P < 0.05) as well as 99% (P < 0.01) have been widely published. In consequence, 1.65 and 2.33 are the generally appropriate Z-scores to use for these RCV significance calculations. Thus, after choosing a Z-score, the RCV significance limits may easily be calculated (RCV = ±[Z · 2½ · CVT]). 3 The RCV calculation assumes that CVT has a random fluctuation around a homeostatic setting-point and is normally (Gaussianly) distributed. However, several biochemical quantities have a CVT in individuals over time that is not normally distributed.4–7 Moreover, others suggest that original data generated across medicine are not always normally distributed. Accordingly, a log-normal distribution may be a better model for presenting biological data. 8
In practice, often more than two serial results are available for an individual. Using traditional RCV, it is only possible to calculate the significance of changes between each of the two consecutive measurements and a RCV method including all available serial results would likely be more useful for interpretation of significant differences over time. Now, one serious problem regarding interpreting several serial results must be kept in mind during repeated RCV testing. When the RCV concept is used on more than two results, the number of false-positive results will increase. 1 Furthermore, if the serial results are compared with the initial measurement, the repeated RCV test is a dependent test. 1 To date, a formula to quantify cumulated false-positive results for dependent testing is unavailable.
The objective of this study was to develop a simple method, based on both normal and log-normal computer-simulated distributions of data from ‘healthy individuals’, to calculate limits for significant unidirectional differences in two or more serial biomarker results with a constant cumulated probability of both 95% (P < 0.05) and 99% (P < 0.01).
Materials and methods
All data for the simulations were generated using Microsoft Excel version 2010.
Two serial results, normal distributions
The traditional RCV limits are given by: ±RCV = ±(Z · 2½ · CVT). 3
The difference of two consecutive results, X1 and X2, are considered significant when the percentage difference exceeds the calculated traditional RCV limit;
3
i.e.
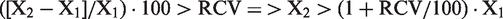
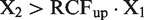
Similarly, a decrease is considered significant when
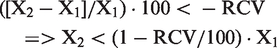
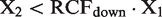
By definitions, RCFup = 1 + RCV/100 and RCFdown = 1–RCV/100. By substitution of RCV into the relations, the following relation is derived
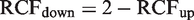
The latter relationship states that, when the RCFup factor is calculated, then the corresponding RCFdown factor is easily derived for normally distributed data.
Normal distributions of data from simulated healthy individuals were generated with a mean (μ) plus a random number (random) from a normal distribution (with mean = 0 and standard deviation = 1) multiplied by the CVT and μ. According to Bliss,
9
this is mathematically expressed as
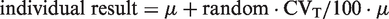
A total of 10,000 simulated healthy normally distributed results were generated for each investigated CVT (10.0, 20.0, 30.0 and 40.0%). The database of results consisted of 100 columns and 100 rows. From each column, two results were selected as representing serial results from an individual. From one column, sets of two results were selected for testing; i.e. 99 sets consisting of two results from each column were tested. In total, from 100 columns, 9900 individual sets of paired serial results were tested. For each test, it was recorded if X2 was increased significantly as compared to X1. Since all the normal distributed data sets were regarded as results from 9900 healthy individuals, the significant increases of X2 could be recorded as false-positive increases. The RCFup factor was then determined when 5% of the 9900 tested sets were recorded as having a significant increase for a unidirectional probability of 95% (or the same as when 5% of the X2 results exceeded the upper significant limit given by the determined RCFup factor), i.e. when
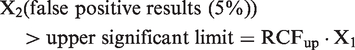
In the same way, the RCFup factor was determined when 1% false-positive results were recorded as having a significant increase for a unidirectional probability of 99%.
Three and more serial results, normal distributions
The difference between three consecutive results, X1, X2 and X3, are considered significant when at least one of the two results (X2 or X3) exceed the upper significant limit (RCFup · X1); i.e.
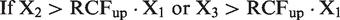
Similarly, as for the procedure for two serial results, sets consisting of three results were selected for testing. From one column, sets of three results were selected for RCV testing when three serial results were examined; i.e. 98 sets consisting of three results from each column were tested as serial results from 98 individuals. In total, 9800 individual sets of three serial results were tested. For each test, it was recorded if X2 or X3 had a significant increase as compared to X1. If X2 or X3 showed a significant increase, the tested set was recorded as having a significant increase. The RCFup factor was then determined when the provided upper significant limit recorded 5% and 1% of the 9800 test sets as having significant increases. Similarly, RCFup factors were calculated for four serial results and then up to 20 serial result sets consisting of 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 and 20 serial results were tested. In total, 99,500 sets of serial results were tested for each CVT and including four different percentages of CVT (10.0, 20.0, 30.0 and 40.0%) consequently 398,000 sets (from 398,000 individuals) of serial results were tested. All RCFup factors were calculated for the significant upper limits of a constant unidirectional probability of 95% (P < 0.05) and 99% (P < 0.01).
Log-normal distributions
Data follow a log-normal distribution if the logarithms follow a normal distribution. The normal distribution is generated as: individual results = μ + random · CVT/100 · μ. Taking the exponential function of this normal distribution will give an ln-normal distribution. This is mathematically expressed as
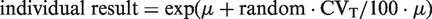
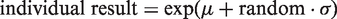
Fokkema et al.
4
have described the relation between σ and CVT
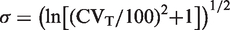
Fokkema et al. 4 have also described the following formulae
RCFup = exp(Z · 2½ · σ) and RCFdown = exp(–Z · 2½ · σ) and the following is derived from these relationships
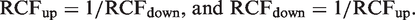
As for normal distributions, when RCFup has been calculated, the corresponding RCFdown is easily derived. Zn-score calculations were based on ln-normal simulated data. The formula RCFup = exp(Zn·2½·σ) was then rearranged to: Zn = ln(RCFup)/(2½ · σ) in order to calculate the Zn-scores.
Results
RCFup factors for calculating the upper limits for a significant increase at a constant cumulated unidirectional probability of 95% and 99%.
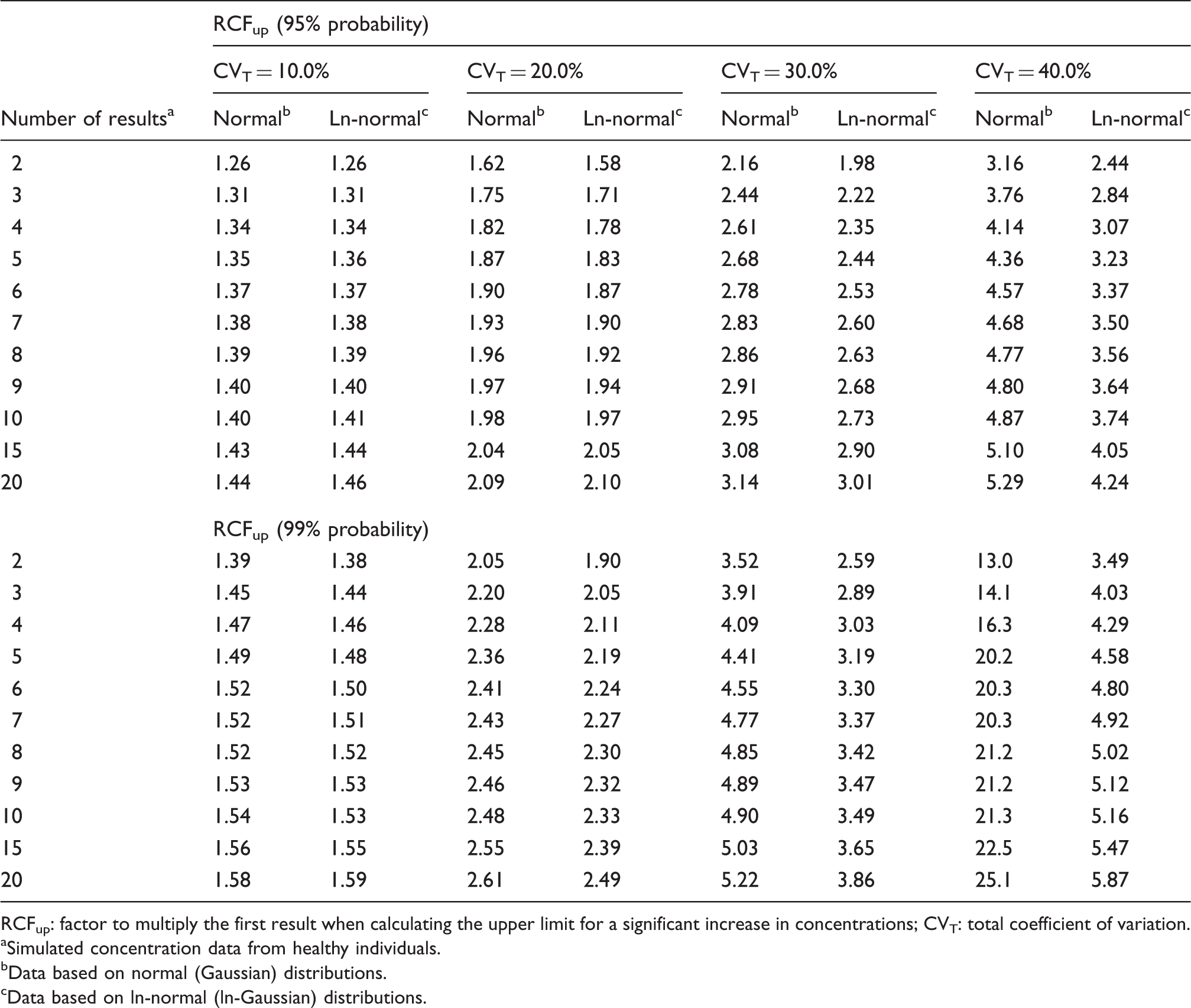
RCFup: factor to multiply the first result when calculating the upper limit for a significant increase in concentrations; CVT: total coefficient of variation.
Simulated concentration data from healthy individuals.
Data based on normal (Gaussian) distributions.
Data based on ln-normal (ln-Gaussian) distributions.
Normal distributions
Normal data distributions are symmetrical around the mean. The generated simulated data sets showed that more results were extremely low (near zero) or even negative when CVT increased. According to the practical use of the traditional RCV calculations, the change between two results is related to the first result (see Methods). If the first result (X1) is low or zero, the second result (X2) will be recorded as a significant increase. Therefore, also very small increments will be recorded as significant. Consequently, the RCFup factors calculated in Table 1 based on simulated data sets are greater than the theoretically RCFup calculations (based on [RCFup = 1 + RCV/100]). For example, for two serial results and use of a unidirectional probability of 95% (Z = 1.65), the RCFup results based on the theoretically RCFup calculations were 1.23; 1.47; 1.70 and 1.93 for CVT (10.0, 20.0, 30.0 and 40.0%), respectively; and the corresponding RCFup results based on the simulations (Table 1) were 1.26; 1.62; 2.16 and 3.16. Obviously, these differences increase as CVT increases. For CVT = 40% and 99% probability, the RCFup factors were extremely high (RCFup > 13, Table 1).
Ln-normal distributions
Zn-scores a dependent on the number of serial results (n).
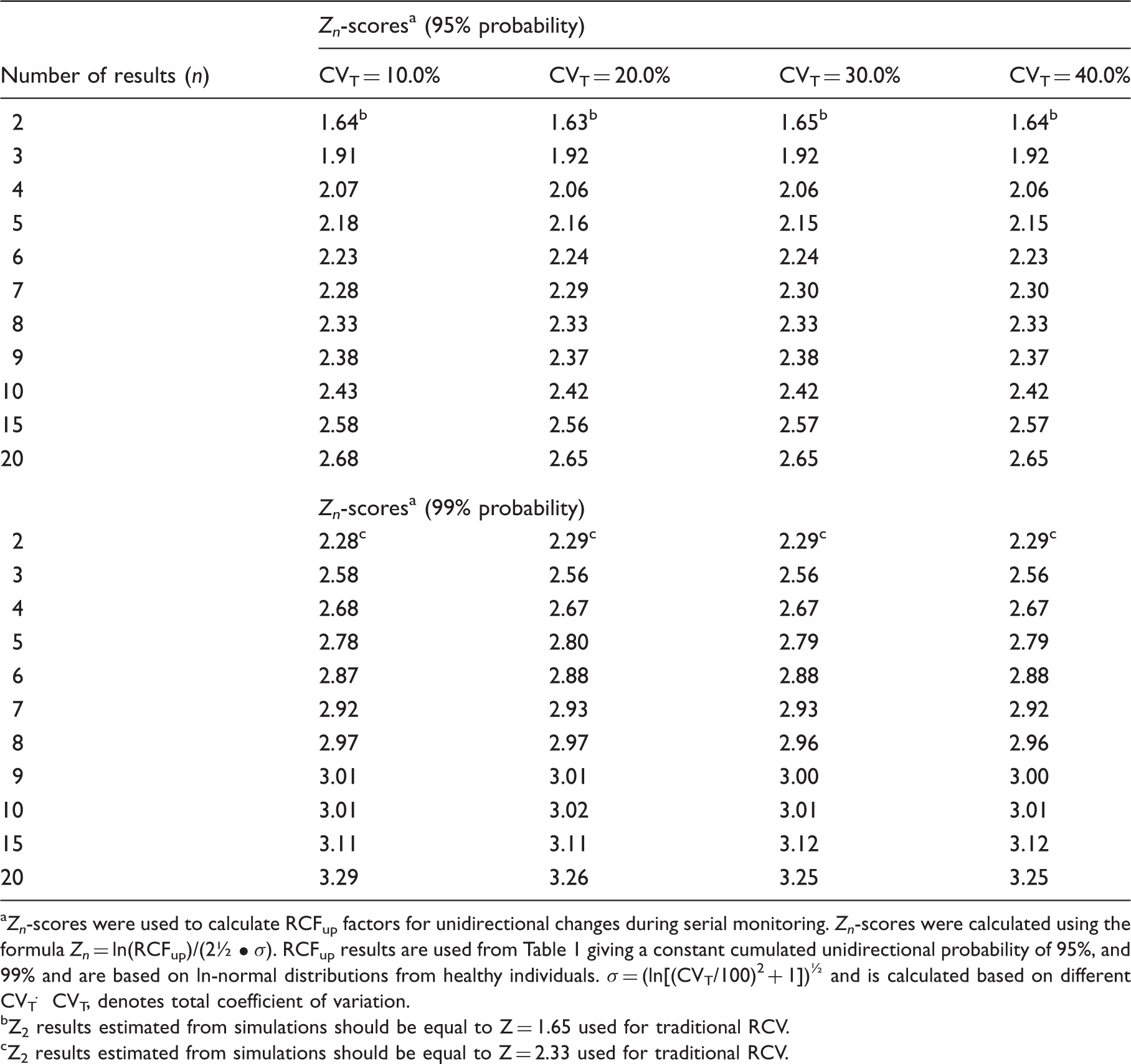
Zn-scores were used to calculate RCFup factors for unidirectional changes during serial monitoring. Zn-scores were calculated using the formula Zn = ln(RCFup)/(2½ • σ). RCFup results are used from Table 1 giving a constant cumulated unidirectional probability of 95%, and 99% and are based on ln-normal distributions from healthy individuals. σ = (ln[(CVT/100)2 + 1])½ and is calculated based on different CVT. CVT, denotes total coefficient of variation.
Z2 results estimated from simulations should be equal to Z = 1.65 used for traditional RCV.
Z2 results estimated from simulations should be equal to Z = 2.33 used for traditional RCV.
Discussion
General considerations
With the introduction of the concept of RCV, in 1983, 1 an excellent tool for interpretation of consecutive unidirectional measurements in patients became available and today practically all articles about the application of data on biological variation include calculations of RCV. Originally, Harris and Yasaka 1 used standard deviations for the calculations but following numerous publications showing rather constant coefficients of CVI, the consequence was that the RCV most often became based on CVT. 2 Within the last decade, discussions about normal and ln-normal distributions of biological parameters have become intense and the tendency is now moving towards the application of ln-distributions.4–8 One problem with the RCV is that it can only be used in assessment of differences between two serial results, which makes it susceptible to the effect of repeated testing, where the probability of false-positive results increases with the number of results available. Therefore, a new concept to overcome the problems with repeated testing, by keeping the probability of false-positive results constant for several consecutive results and only dependent on the number of results available seems worthwhile.
The new model
In the new model, we have solved the problem of repeated testing by expanding the actual test value, denoted Zn, in relationship to the number of results available in the monitoring sequence. Thereby, the cumulated probability of false-positive results, either 5% or 1%, is kept constant for the individual during the whole monitoring period. These Zn scores are independent of CVT and make it easy to calculate the limit for each new result according to the chosen total cumulated level of unidirectional significance for the individual. Furthermore, we have investigated the influence of normally distributed individual data and found that practical use of the traditional RCV method to test a difference through assessment of the difference from the first measurement is susceptible to low concentration values for the first result. This is not a problem for the ln-normally distributed data (Table 1). We have shown that the practical use of traditional RCV calculations will produce too many false-positive results, especially for high values of CVT, compared to theoretical RCV calculations. On the other hand, the calculated RCFup factors are comparable for both normal and ln-normal distributions up to about CVT = 20.0% (Table 1). At higher CVT, the RCFup factor results for normal distributions will exceed the RCFup factors for ln-normal distributions and, in addition, the RCFup factors will also be greater than 2 (Table 1). From the relation RCFdown = 2–RCFup, it is also obvious that RCFdown will be negative for RCFup >2 and make no sense, since the significant limit for decreasing results will be negative for normal distributions. Consequently, we recommend that all calculations of limits for unidirectional significant differences should be based on ln-normal distributions, i.e. RCFup = exp(Zn · 2½ · CVT/100). Compared with traditional RCV calculation (RCV = [Z · 2½ · CVT]), the proposed significance calculations based on ln-normal distributions may seem more complicated. However, the only difference in variables compared with traditional RCV calculations is the Zn-score obtained from Table 2 for more than two serial results. It should be noticed, that the Zn-scores are dependent on the number of serial results (n) and probability level – but are independent of CVT. In contrast to traditional RCV calculations, an additional merit of use of RCF factors is that the significant limits are given as simple numbers with appropriate units. For the sake of clarity and space, we have focused on unidirectional differences. However, the RCV, RCFup, RCFdown and Zn calculations could also be applied to bidirectional differences. A bidirectional change is used when both increases and decreases of results are being considered. This aspect will be addressed in another communication.
Simulation models have also been used in several monitoring studies to validate the utility of different criteria to interpret increments in serial cancer biomarker concentrations.10–12 In addition, this model system may also be suitable for Phase I development of new cancer biomarker assessment and to optimize already existing criteria. 13
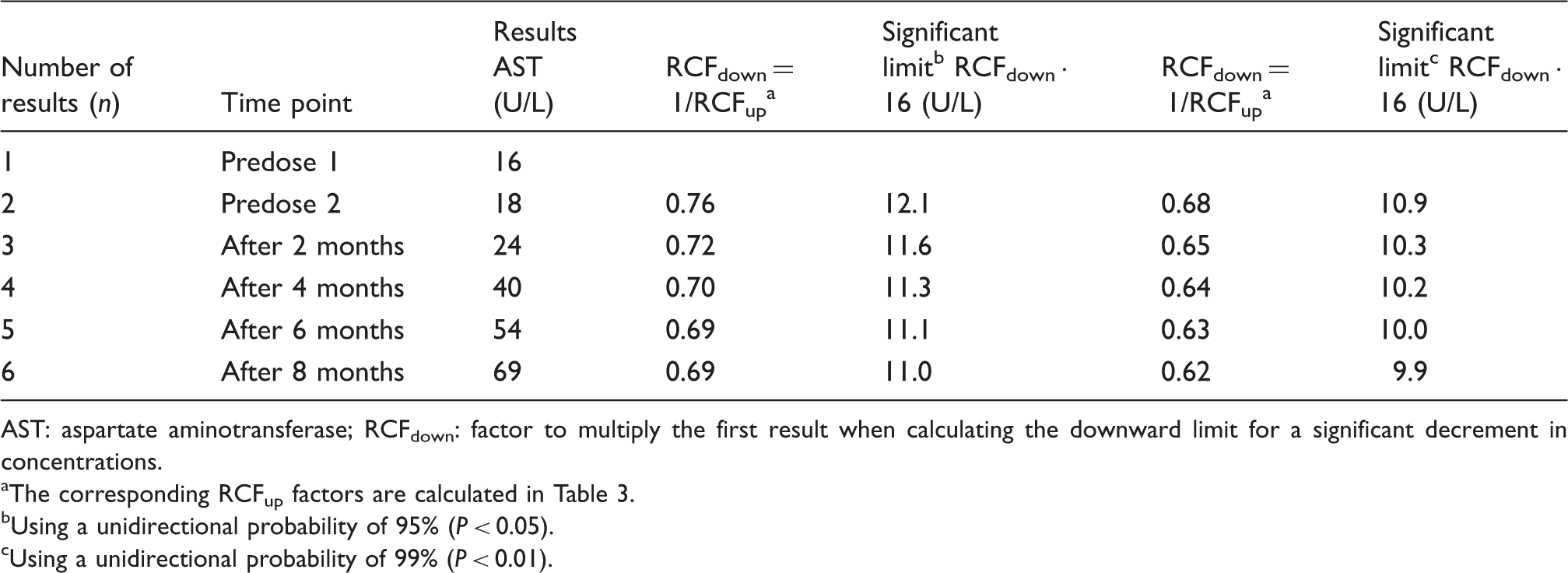
An example of calculation of limits for significant unidirectional differences for up to six serial results
As an example, Fraser
3
has described a case of changes in liver function tests in a 63-year-old man who was prescribed statin therapy to lower his less-than-ideal serum cholesterol concentration. The serum aspartate aminotransferase (AST) concentration rose with time (16, 18, 24, 40, 54, 69 U/L). The results of the serum AST activities from the patient treated with statin are used for the calculations.
3
The method is also presented in Table 3 and (RCFup = exp[Zn · 2½ · CVT/100]) is used for the calculations. The limits for both significant (P < 0.05) and highly significant (P < 0.01) increments are calculated (RCFup factor multiplied by first result) and listed with the serial results in Table 3. These results are also illustrated in Figure 1. From both Table 3 and Figure 1, it is clearly shown that, when the increments in serial concentrations exceed the significant limit (result 3) and the highly significant limit (result 4). Note that, as a consequence of the developed method, the concentration limits increase with the number of results due to the constant cumulated percentage of false positives during repeated testing. For application of the complete method, the downward significant limits are also calculated and listed in Table 4 – although not relevant for the actual example.
Serum aspartate aminotransferase concentrations in a patient treated with statin. The significant upper limits for increments were calculated using unidirectional probabilities of 95% and 99%. Calculation of upper limits for significant increments in serum AST concentrations in a patient treated with statin.
3
AST: aspartate aminotransferase; RCFup: factor to multiply the first result when calculating the upper limit for a significant increment in concentrations. Zn-scores are found from Table 2 using the unidirectional probability of 95%. CVT = (CVA2 + CVI2)½ = 11.95% where analytical variation, CVA = 1.1% and within-subject biological variation, CVI = 11.9%.
3
Using an unidirectional probability of 95%. Zn-scores are found from Table 2 using an unidirectional probability of 99%. Using an unidirectional probability of 99%. The result is a significant increment as compared with the first result (95% probability, P < 0.05). The result is a highly significant increment as compared with the first result (99% probability, P < 0.01). Calculation of downward limits for significant decrements in serum AST concentrations in a patient treated with statin.
3
AST: aspartate aminotransferase; RCFdown: factor to multiply the first result when calculating the downward limit for a significant decrement in concentrations. The corresponding RCFup factors are calculated in Table 3. Using a unidirectional probability of 95% (P < 0.05). Using a unidirectional probability of 99% (P < 0.01).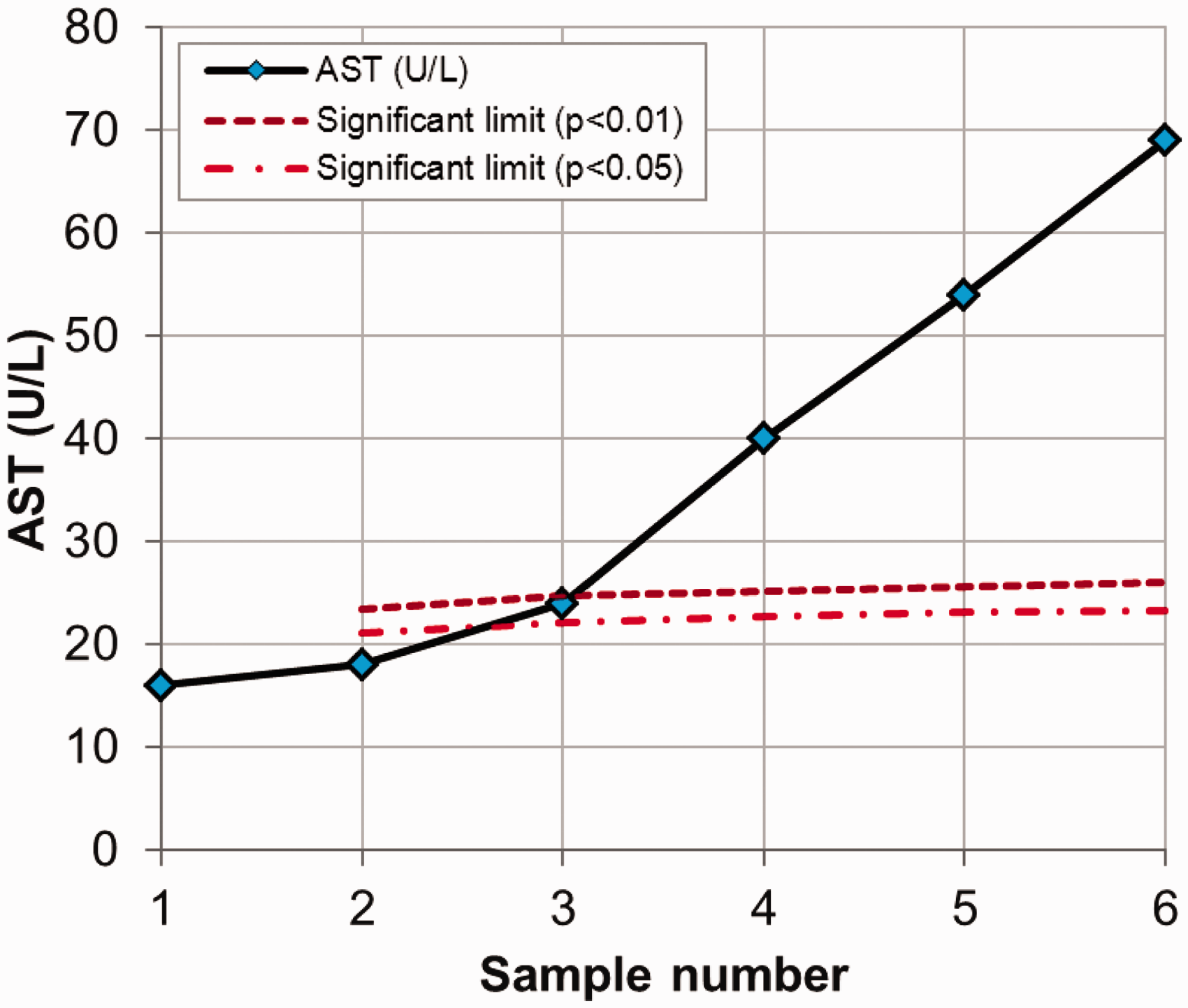

Conclusions
A simple calculation of limits for significant unidirectional differences in two or more results of a biomarker. The upper limit for significant increment of serial results is calculated by a factor RCFup. If X1 is the first result, then upper limit is found with X1 multiplied by RCFup
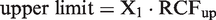
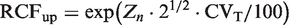
The Zn is found from Table 2 and CVT is calculated using estimates of CVA and CVI (CVT = [CVA2 + CVI2]½). The corresponding downward limit for a significant decrement of serial results is calculated by a factor RCFdown (downward limit = X1 · RCFdown). RCFdown factor is found from the relationship
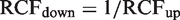
Footnotes
Acknowledgements
The authors would like to thank Merete Frejstrup Pedersen for her assistance in generating the figure.
Declaration of conflicting interests
None.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Ethical approval
Not required.
Guarantor
FL.
Contributorship
FL and PHP designed and generated the computer simulations. FL wrote the first draft of the manuscript. All authors contributed to the discussions, and reviewed and edited the manuscript.