
Abstract
In this paper, we examine a data‐driven optimization approach to making optimal decisions as evaluated by a trained random forest, where these decisions can be constrained by an arbitrary polyhedral set. We model this optimization problem as a mixed‐integer linear program. We show this model can be solved to optimality efficiently using pareto‐optimal Benders cuts for ensembles containing a modest number of trees. We consider a random forest approximation that consists of sampling a subset of trees and establish that this gives rise to near‐optimal solutions by proving analytical guarantees. In particular, for axis‐aligned trees, we show that the number of trees we need to sample is sublinear in the size of the forest being approximated. Motivated by this result, we propose heuristics inspired by cross‐validation that optimize over smaller forests rather than one large forest and assess their performance on synthetic datasets. We present two case studies on a property investment problem and a jury selection problem. We show this approach performs well against other benchmarks while providing insights into the sensitivity of the algorithm's performance for different parameters of the random forest.
INTRODUCTION
There has been significant recent interest within the operations community in prescriptive analytics—leveraging data to make decisions. In this setting, the data may include previous decisions and the corresponding outcomes that have resulted from these decisions. It is natural for practitioners to want to learn from this data, and use this information to make new decisions that are more likely to result in favorable outcomes.
Oftentimes, the exact relationship between the decisions and outcomes is unknown a priori, but data exist on previous performance. This can be due to incomplete knowledge of how the underlying system works, or due to inherent uncertainty in the problem. In this setting, the data can be leveraged to build a richer understanding of the decision‐making process. This has led to a number of applications where this relationship is learned from data using machine learning techniques where the outcome is
A practical challenge that arises with this approach is choosing the best decision as evaluated by the trained machine learning model. In this setting, the trained machine learning function can be thought of as the objective function that is being optimized over. In particular, if 
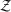
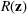
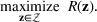
Some examples of optimization problems with an uncertain relationship between actions and outcomes

In certain situations, where the decision set is small, all possible decisions can be enumerated and evaluated by the machine learning model. However, in many practical applications, the decision set is large and complex. This includes settings where the decision variables are continuous and/or multidimensional. Furthermore, decisions are often constrained to lie within a complex feasible set. In this case, enumeration methods are not possible and more sophisticated optimization approaches must be used, which is the focus of this paper. The models we will explore in this paper have polyhedral feasible sets, combined with integer‐variable restrictions on the decision variables. This provides a rich framework for modeling a wide variety of real‐world problem instances but may result in combinatorial challenges when solving this optimization problem.
In many cases, the decision made depends on relevant contextual data, which define the scenario in which the decision takes place. For example, a data‐driven decision about how to price a particular good might depend on features of the customer and the good being sold. Incorporating this contextual data are important for making effective decisions. We can incorporate the contextual data 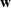
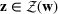
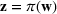
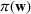
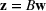
We will focus our attention on the case where the machine learning model is a random forest (Breiman, 2001). A random forest is an example of an ensemble method, which combines predictions from several decision trees. A decision tree uses a tree structure to predict an outcome for a feature vector 
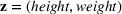
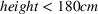
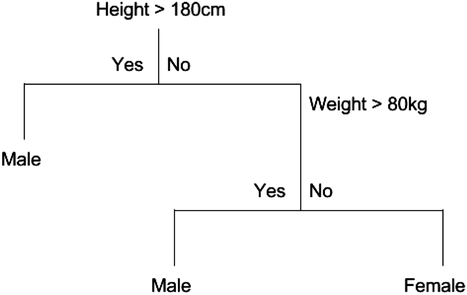
Example tree for classifying gender

Example tree to illustrate formulation with given
In practice, individual decision trees are often associated with high variance predictions and poor out‐of‐sample predictive accuracy. They will often overfit the data if they are not restricted in size (Breiman, 1996). Random forests decrease this variance using bagging. This involves taking the average of many trees, each trained by randomly sampling the training data and features that are used in the splits (Breiman, 2001). Random forests can be applied for either regression or classification problems.
Using a random forest as an objective function has many advantages. Random forests are a very powerful prediction algorithm which can fit unknown nonlinear and complex interactions of features with minimal feature engineering, making them popular and widely used in machine learning (Biau & Scornet, 2016). Furthermore, they are generally recognized as being able to deal effectively with high dimensional data and have few parameters to tune (Biau & Scornet, 2016). Of particular relevance to optimization, random forests have a special combinatorial structure which allows us to leverage the power of mixed‐integer linear programming and powerful existing solvers to solve large‐scale problems.
Contributions
First, we show how to
Second, 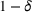
Third, for very large problem instances,
Finally,
Our paper follows the following outline: in Section 3, we introduce the model, the MIP formulation, and show how to decompose this MIP using Benders decomposition and implement pareto‐optimal Benders cuts. In Section 4, we prove some analytical results about the suboptimality of a smaller random forest as an approximation to a large forest and introduce a heuristic based on cross‐validation for optimization. In Section 5, we introduce case studies on property investment and jury selection, respectively, and we explore the properties of the random forest algorithms on these datasets.
RELEVANT LITERATURE
Data‐driven optimization
There has been significant recent interest in incorporating machine learning techniques into data‐driven optimization problems. In particular, often machine learning is used to estimate the objective as a function of decisions and auxiliary covariates, which is called a “predict then optimize” approach. Bertsimas et al. (2016) use ridge regression in a data‐driven approach to design chemotherapy regimens for cancer. Baardman et al. (2019) use multiplicative regression (log‐linear) to estimate demand for promotion vehicles, which is used to maximize revenue. Besbes et al. (2010) optimize over a Nadaraya–Watson kernel regression function, where the kernel is Gaussian. Further examples of operations management problems incorporating covariate data into optimization problems include Ban et al. (2016); Ban & Rudin (2018); Aouad et al. (2019); Cohen et al. (2020); Bertsimas & Kallus (2020); Ban & Keskin (2021); Chen et al. (2021); Elmachtoub & Grigas (2022). There has recently been significant recent interest in modeling trained neural networks in this context using mixed‐integer optimization techniques (Anderson et al., 2020; Fischetti & Jo, 2018; Tjeng et al., 2017). We focus on modeling this relationship using tree ensembles.
There is some recent literature that incorporates random forests into a predict‐then‐optimize framework. Ferreira et al. (2015) study a pricing problem in retail, where prices come from a discrete ladder. They use a random forest to estimate the demand for the product conditioned on the price and make predictions for all price‐product combinations. This avoids having to optimize over the structure of the random forest, which would be necessary if the set of prices was significantly larger or continuous.
Since the initial version of this paper was released online, we became aware of Mišić (2020), who has simultaneously and independently studied optimizing tree‐based ensembles. The MIP formulation in Mišić (2020) is effective but is restricted to unconstrained problems or problems with box constraints on decision variables. In contrast, our model admits general polyhedral constraints. This provides flexibility for modeling a greater range of applications, and in particular, allows the policy class to be specified and modeled. Another significant difference is in heuristics used to solve large‐scale random forests. Mišić (2020) uses an approach that truncates trees at a certain depth, while we use an approach where we optimize over fewer trees and use cross‐validation procedure. We analyze the theory of optimizing over smaller forests and derive bounds on the suboptimality of doing so.
In the data mining community, there have been several papers studying sensitivity analysis for machine learning algorithms, in terms of the impact of an input of a predictive approach on its output. In particular, the inverse classification stream studies the problem of minimizing a probability of an event by finding the optimal set of actions (Aggarwal et al., 2010; Pendharkar, 2002). Some papers have introduced constraints in the optimization framework to enforce the solution's feasibility. These can be constraints that are imposed to eliminate extreme solutions (Barbella et al., 2009), to separate the contextual features from the decision features (Chi et al., 2012; Yang et al., 2012), or to limit the range of possible changes to the decision features (Lash & Zhao, 2016). However, when these constraints are considered altogether, nondifferentiable classifiers are underexplored. In contrast, our MIP formulation offers a more flexible framework with a wider class of constraints to optimize a random forest output (which is nonconvex and nondifferentiable). Furthermore, to solve this problem, these papers use heuristic‐based methods such as variable neighborhood search (VNS), genetic algorithms, and hill‐climbing leading to locally optimal solutions. In our work, we can solve the MIP formulation globally optimally as well as improve the speed of the MIP solver by introducing Benders cuts.
There have been recent efforts to apply modern optimization techniques to estimate globally optimal classification trees, rather than by following a greedy estimation heuristic as has been done in CART. Bertsimas and Dunn (2017) present a mixed‐integer linear programming (MIP) formulation and show it outperforms widely used heuristics for datasets of a reasonable size. They focus on training trees (optimal estimation), whereas our optimization is focused on choosing the best “input feature vector”
Relation to causal inference
In the causal inference literature, the approach of estimating a model from data, and then using this model to estimate the reward of a policy is often broadly referred to as a direct method or direct comparison approach (Qian & Murphy, 2011). Our approach falls within this class of problems but focuses on the difficulty of solving the resulting optimization problem when the model is a tree ensemble model and the decision is complex (multi‐dimensional and/or constrained), so a simple enumeration or search for the optimal policy is not tractable. As such, we are agnostic to the estimation procedure used to train the tree ensemble, and indeed, our approach can be adapted to optimize tree ensembles trained using different techniques, as would be appropriate under different assumptions on the data.
The success of direct comparison methods depends on whether the fitted model is a good representation of the relationship between outcome, decision, and scenario data. A prerequisite for this is to have appropriate data. One key assumption made in direct comparison methods is unconfoundedness. This requires measurement of the right covariates to separate the effect of the treatment itself from the effect of the assignment. More precisely, under the potential outcomes framework, where we observe the action 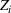
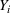
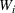
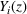
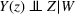
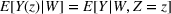
If the unconfoundedness assumption is not satisfied, in particular, if there are hidden confounding variables that affect both the observed decision and the outcome, then different techniques need to be used, such as instrumental variables. These can be incorporated into a random forest approach (Athey et al., 2019). We can also adapt other tree ensemble methods from the causal inference literature, such as causal random forests (Wager & Athey, 2017). These are intended for estimating individual treatment effects with binary treatments, so they cannot be directly plugged into our framework, but the core idea of using honest trees (Athey & Imbens, 2016) is applicable to our setting. Honest trees incorporate a sample splitting procedure so that different data are used to construct the tree (a sequence of variables splits), to the data used to estimate the outcomes in each leaf. This generally improves estimates in each leaf as they are no longer correlated with the tree construction. Causal forests also require the unconfoundedness assumption. There is a variety of different causal inference methods which are suitable for different data settings. Many of these approaches involve estimation using tree ensembles, and as long as they give estimates of the reward given the decision and outcome, our method can be used to solve the corresponding optimization problem.
MODEL
Our goal is to maximize 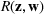

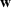
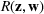
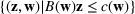
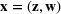
The random forest is the average 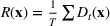
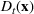

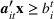
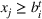

We introduce the following notations for our model: For every tree 
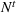
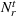
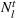
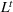
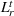
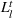
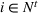
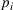
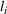
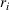
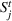
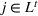

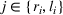
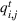
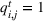

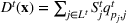

MIP formulation
We need logical constraints which determine which leaf a solution 
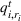
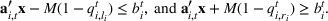

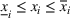
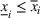
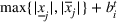
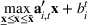

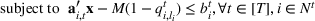
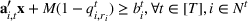
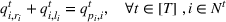
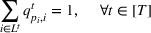
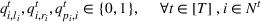
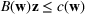
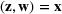

Alternative MIP formulations for trees are possible, such as the union of polyhedra formulation of Biggs and Perakis (2019). However, it is shown in that article that the numerical performance is generally not superior to the big‐M formulation presented in this article in the case of modeling tree ensemble objectives. In addition to that, it does not allow for Benders decomposition (Section 3.2), which greatly improves its performance. Furthermore, the formulation of Mišić (2020) cannot be applied to this setting with general polyhedral constraints without introducing considerable complexity.
Another powerful tree ensemble method which often has a higher predictive accuracy than random forests is gradient‐boosted trees, including 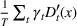
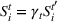
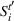
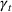
Benders decomposition
The previous formulation can be slow to solve to optimality for large problem instances, as explored in Section 5.3. Fortunately, this problem has a structure that makes it an attractive candidate for Benders decomposition with lazy constraint generation. The problem can be decomposed into the master problem (MP) that chooses a solution 

To generate Benders cuts, we can solve the dual linear problem to retrieve the dual solution. However, This can be time‐consuming for large problem instances, since we need to solve an LP to generate a cut every time. Due to the special structure of the dual problem, we can find an explicit analytical expression of a viable solution to the dual solution. We provide the expression of the analytical solution in Section S1.2.
Using Benders cuts results in a significant speed improvement because we only generate cuts for the objective as required. This improvement is explored numerically in Section 5.3. An issue with our dual subproblem is degeneracy. There are often multiple optimal dual solutions. Pareto‐optimal cuts have been implemented in many applications employing Benders decomposition (Mercier et al., 2005; Santoso et al., 2005), and in the work conducted by Magnanti and Wong (1981) and Tang et al. (2013), it has been shown that their use can speed up the convergence of the algorithm.
1
Magnanti and Wong (1981) propose a method to generate pareto‐optimal cuts when the objective of the subproblem dual is linear with the variable vector 

APPROXIMATING LARGE RANDOM FORESTS
Analytical results
While the MIP formulation can solve many real‐world datasets to optimality in a reasonable amount of time, for large‐scale data, the MIP can be prohibitively slow. Motivated by this, we explore a sampling heuristic that is faster while still obtaining good solutions. Suppose we have a large target forest 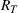
We can consider the random forest to be a partition of the feature space into 
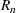
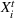
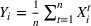
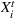
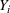
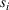
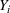
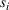
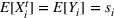
The only assumption we make is that the scores between trees for the same set are independent and identically distributed (i.i.d.), that is, for any pair of trees 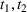
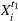
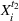
If we optimize over the sample random forest, the set to which the chosen solution belongs is Let 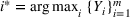

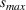
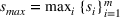
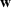
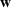
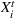
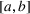
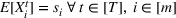
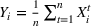
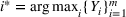
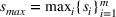
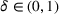
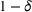
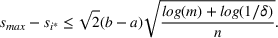
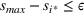
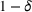
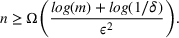
We previously defined Setting the right hand side bound equal to δ and solving for ε, we have: That is, with probability at least
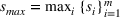
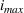
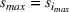
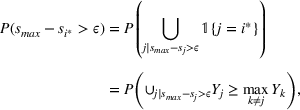
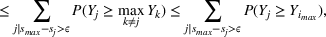
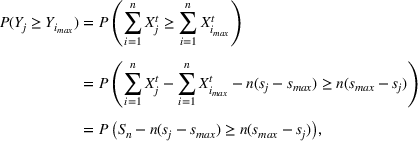
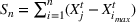
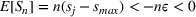
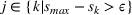
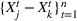
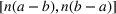
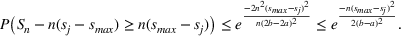
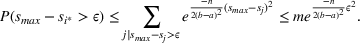
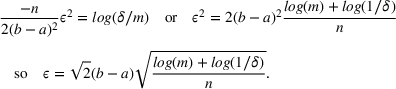
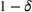
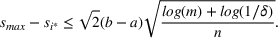

Theorem 1 allows us to bound the suboptimality of the sampled solution by 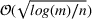
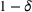
A relevant result to Theorem 1 can be found in Kleywegt et al. (2002) where the authors bound the suboptimality of the SAA approximation of stochastic discrete optimization using Cramér's large deviation (LD) theorem. Similar to our use of Hoeffding's inequality, the LD theory can be used to derive exponential bounds on tail distributions of sums of independent random variables. However, estimating the theoretical bounds in Kleywegt et al. (2002) is not a straightforward task, and thus can complicate the practical use of the SAA approximation method. Instead, the bound in Theorem 1 only uses the number of sets in the random forest
For this analysis, we focus on axis‐aligned splits, which are implemented in the most widely used tree ensemble methods. These are splits of the form For a random forest with 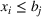
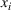
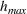
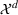
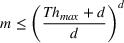
The proof can be found in S2. A similar bound can be derived from the known result that arranging In the setting of Theorem 1, if the target random forest has axis‐aligned splits and feature space dimension 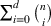
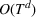
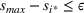
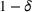
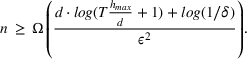
This corollary provides guidance on how to select the number of trees in the sampled random forest to obtain a desired accuracy level. In particular, it suggests choosing 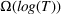
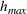
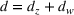
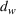
Also, it is worth noting that Lemma 1 provides an upper bound on the actual number of sets 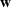
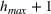
Number of sets in a random forest: a simulation study
We have shown that for trees with axis‐aligned splits,
We provide the following experimental setup to explore this relationship. The number of nonempty sets 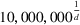
We evaluate the approximate number of sets on datasets which have been used in the context of optimizing tree ensembles. In particular we evaluate on 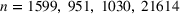
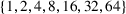
To evaluate the scaling between number of sets and number of trees, we fit different regression models to see which best fit this relationship empirically. In particular, we fit the following models: (i) 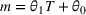
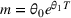
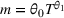
We report the 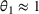

Plots of the relationship between the number of sets, the number of trees, and the dimension can be found in Figure 3. Overall, we observe that for these datasets, the number of sets with unique scores often scales sublinearly with the number of trees in the forest. This can be observed in particular for
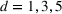
How the number of sets scales with the number of trees. Rows: housing, solubility, wine, and concrete datasets. Columns: Dimension
Furthermore, Table 2 shows that the exponential model never fits as well as the linear or multiplicative models, suggesting that the true relationship between the number of sets and the number of trees is unlikely to be exponential. While these experiments are imperfect and are less reliable for large
Degree of polynomial θ1 for best regression model describing relationship between number of sets and number of trees
Cross‐validation for optimization
Following the previous section, we propose a heuristic where we decompose a large target random forest into several smaller random forests. For each random forest subset, we select the optimal solution using our MIP formulation. We then test each solution against the forests it was not optimized over, to get the average score referred to from now on as the
Cross‐validation for optimization
We can derive analytical bounds on the performance of this algorithm. Due to a random forest being the average of several trees (or equivalently average of smaller random forest), the global optimal solution is Let 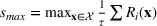
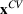

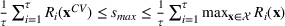
The proof can be found in Section S2. These bounds are very useful in practice; if we solve the heuristic for forests of a certain size, we know how good the obtained solution is relative to the best solution, and how much we could potentially gain by repeating the heuristic with larger forests. This allows the practitioner to make an informed decision about whether to increase the forest size with consideration of the computational burden.
Although it is straightforward to adapt the MIP techniques in this article to boosted trees, the sampling and cross‐validation approaches we provide are not suitable to apply to boosted trees algorithms. There are two issues: First, since in each boosting round the new tree is fitted to the residuals of the existing tree ensemble, the score of each leaf in a tree 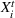
NUMERICAL EXPERIMENTS
We now describe in detail two case studies with real data which both analyze the behavior of the algorithms we have introduced and explore the effectiveness of a random forest compared to optimizing over different objective functions. These case studies are both constrained optimization problems, which cannot be easily solved using unconstrained formulations (such as in Mišić, 2020).
Case study: Property investment
Property investors face difficulty in assessing how much a property will sell for on the market. Residential properties have many different features (such as the number of bedrooms, bathrooms, floors, size of the house, quality of construction, and location), which are prioritized and valued in different ways by different buyers. Furthermore, there is a degree of unpredictability in the sale price depending on which buyers happen to be interested in a property. This makes it hard for property investors to make sound investment decisions when evaluating the different options available. In particular, we look at a situation in which the property investor is interested in buying an empty lot, constructing a new house, and then selling that property to make a profit. We overcome this uncertainty by estimating the sale price for a given property using a random forest model trained from data on previous house sales. We then optimize to find the property which is predicted to achieve the highest price, as predicted by the random forest.
Prediction
We have data from Kaggle on house sale prices for King County, which includes Seattle (Harlfoxem, 2016). It includes 21,613 houses sold between May 2014 and May 2015. We divide the features into those related to the house and those related to the lot as shown in Table 4. Table 5 shows the performance of various algorithms for predicting the sale price of a property. We used a 70% / 30% training / testing split. We see that XGBoost (another ensemble tree approach) performs the best with 90% OOS accuracy while Random Forest performs second best with 88% OOS accuracy. Regression approaches do worse, achieving around 70% OOS accuracy (Table 5).
Variables of housing dataset
Predictive accuracy house sales prices
Variables of jury dataset
Predictive jury verdict averaged over 20 data splits
Formulation
Suppose we have a number of empty sections the investor has to choose between. The investor needs to decide (i) which lot to purchase and (ii) what kind of house to build on that lot. We assume the property investor has a fixed budget with which to buy the lot and construct the house. The property investor wants to maximize the sale price (or predicted value) of the resulting house.
Suppose we have trained a random forest 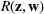
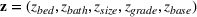
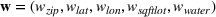
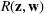

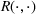
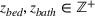
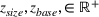
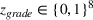
Suppose there is a set 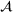
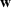
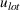
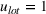
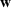
Let 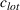
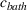
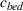
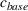
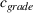
We also require the house chosen to be within the convex hull of the set of properties observed in the data. This ensures the feasible set is bounded, and that the selected house is not too dissimilar from the houses observed in the dataset. Let 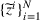
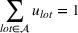
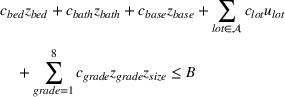
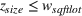
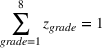
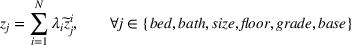
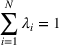
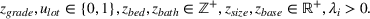
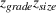
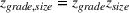
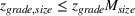
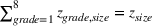
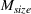
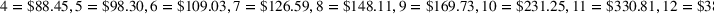
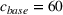
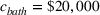
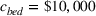
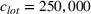
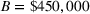
Jury selection case study
Background
Juries are composed of members of the public and decide many court cases. While these jurors are supposed to be impartial and make their decision based solely on the available evidence, several studies have suggested that jurors may have inherent biases based on their race, education, wealth, and political views (Denove & Imwinkelried, 1995). In many legal systems (including in the United States), lawyers are allowed a fixed number of peremptory challenges, whereby they are allowed to reject potential jurors without stating a reason. Lawyers are also able to ask jury members several questions to ascertain personal information about them. This has spawned an industry known as jury consulting (a branch of trial consulting), where experts use a range of qualitative social science and psychology techniques to try and choose favorable juries for a civil or criminal trial. Despite a lack of empirical evidence supporting its efficacy, the trial consulting industry was estimated to be worth 400 million in 1999, with over 400 firms operating in the market (Hartje, 2004).
We study the problem of selecting a jury from a larger juror pool, taking into account information about the demographics and views of the eligible jurors and characteristics of the case. First, we will show that it is possible to predict the verdict of a jury with a higher accuracy than 50%, solely based on this information, then we will show how to combine these predictive models with optimization to pick these jurors intelligently.
Predicting jury verdict
In this section, we explore how the members of a jury influence the verdict. Specifically, we use data on jurors' personal demographics and views, and the characteristics of the case to predict whether the jury will return a guilty or not guilty verdict.
We obtained data from the Inter‐university Consortium for Political and Social Research on noncapital felony jury trials in the state trial courts of Los Angeles (CA), Maricopa (AZ), Bronx (NY), and Washington DC (Hannaford‐Agor et al., 2003). The information was collected for 3497 jurors and 354 cases with 83 features. Some of the features are related to jurors' opinions on the trial and their interpretation of evidence. Since this information is not available before the trial starts, we restricted the dataset to 20 variables that the interviewing lawyer could easily collect before the trial. Table 6 shows a list of these variables.
Table 7 shows the performance of various algorithms for predicting jury outcomes. We used a 70% / 30% training/testing split and averaged our trials over 20 random splits of the data. We see that the random forest model performs the best with 60% OOS accuracy while XGBoost performs second best with 57% OOS accuracy. To estimate the increase in accuracy attributable to having information about the jury and not due to other features of the case, we compared against a baseline random forest that had the jury features omitted. This is a strong baseline to compare against, but we still managed to get a 6% improvement OOS. This is surprising considering we do not use any features in our predictions that are based on the evidence presented in the trial.
Jury selection formulation
In the jury selection problem, the lawyer has to select a subset 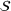
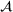
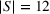
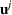
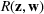

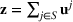
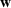
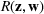
Two main objectives could be considered when choosing a jury: (i) choosing the fairest jury or (ii) choosing a jury that is most likely to return an outcome desired by the lawyer. Both objectives can be modeled under our framework. To align with the lawyer's goals, we would either maximize the probability of returning a guilty verdict by setting the objective to be 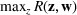
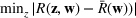
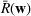
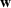
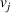
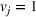
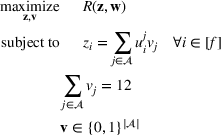
Simulations for optimizing a given forest
In this section, we explore the performance of the various random forest optimization procedures we have proposed in Sections 3.2 and 4. Note that this section is a comparison of how well the algorithms do in optimizing over given a random forest, rather than an analysis of how good random forest optimization is at selecting solutions, which we explore in Section 5.4.1. First, in Section 5.3.2, we test the speed of Benders decomposition compared to the standard MIP formulation, then in Section 5.3.3, we test the accuracy and speed of the cross‐validation performance compared to the MIP. We test the sensitivity of the algorithms discussed with the key parameter of our model; the number of trees in the random forest. Finally, in Section 5.3.4, we provide simulations that compare our approach of optimizing over a subset of trees of full depth to an alternative heuristic suggested in Mišić (2020), which instead truncates the depth of trees in the forest and optimizes over a shallower forest.
Testing environment
The random forests are trained on the datasets in
Benders decomposition comparison
The solution times of the different algorithms are shown in Figure 4. As expected, the MIP formulation displays exponential behavior with respect to the number of trees in the random forest. It is very fast for small to medium‐sized problem instances up to 160 trees on the jury dataset (9100 nodes) and 80 trees on the housing dataset (35840 nodes) but takes prohibitively long for forests larger than this. For random forest instances larger than 500 trees on the jury dataset and 300 trees on the housing dataset, the MIP did not solve within the imposed solve limit of 1000 s. The MIP formulation with Benders cuts is slower than the MIP formulation for a small number of trees, but for forests larger than 200 trees on the jury dataset and 100 trees on the housing dataset, Benders is faster. The initial lag of the Benders formulation might be due to Gurobi's effective presolve techniques which are unable to be applied to the MIP formulation with Benders cuts because the master problem starts with very few constraints. As the problem grows larger, the benefits of Benders cuts outweigh the presolve.
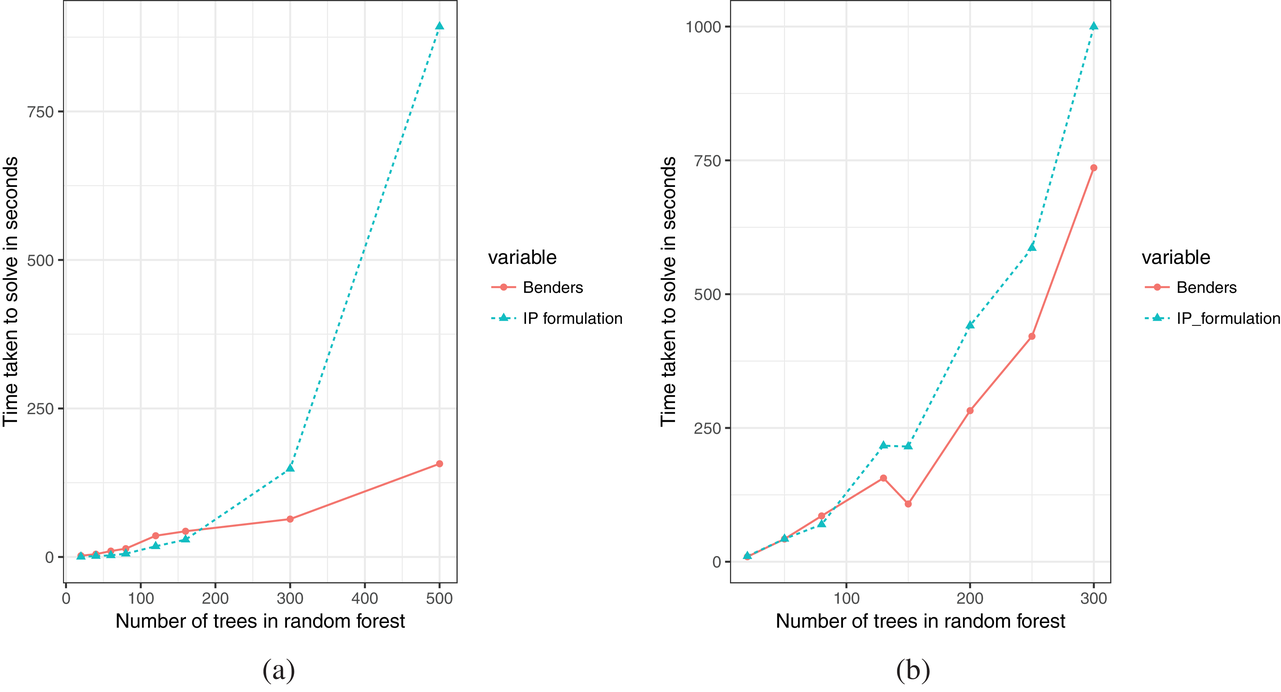
Time taken to solve algorithms for increasing forest size. (a) On the jury dataset. (b) On the housing dataset
Cross‐validation experiments
For each of these experiments, there is a target forest to optimize over, with the number of nodes in that forest given by 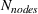
Tables 8 and 9 show the performance of the cross‐validation algorithms relative to the MIP formulation, both in terms of the percentage of time taken to solve and the score of the cross‐validation solution as a percentage of the optimal MIP solution for the jury and housing datasets. We observe that the cross‐validation procedure can achieve a large percentage of optimality in a fraction of the time taken to solve the full MIP. This is surprising since the forests that cross‐validation is optimizing over are just one‐tenth or twentieth of the size of the target forest for the jury and housing datasets, respectively. Cross‐validation is particularly effective for the jury dataset, where the solve times are less than 10% of the MIP, but achieve over 95% of the accuracy if parameters are chosen correctly. This is because there is high variance in the predictions associated with the jury dataset (each forest subset has comparatively low accuracy), so there is significant value in validating the score of the jury chosen using different forests to the one it was chosen with. This suggests more broadly that cross‐validation is more valuable on noisy datasets where it is difficult to train accurate models. We note the % optimality is not guaranteed to be monotone because the subsets chosen for each experiment are independent. We further explore the behavior of cross‐validation with additional numerical experiments in Section S3.
Cross‐validation performance on the jury dataset
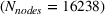
Cross‐validation performance on the housing dataset
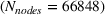
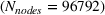
Comparison with depth restricted trees
We use the datasets 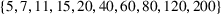
The results are shown in Figure 5. We observe that for the
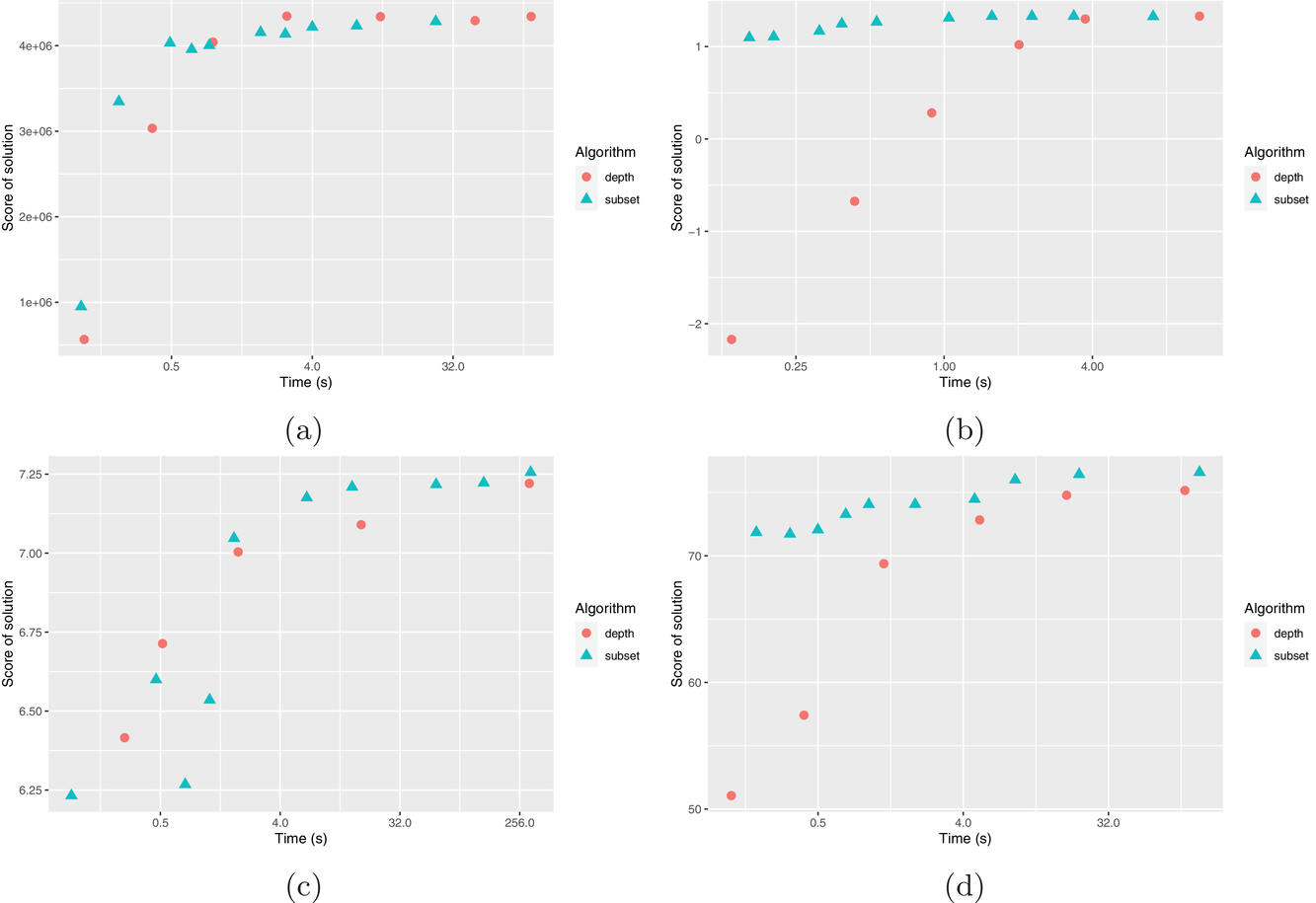
Time versus score for truncated tree depth and forest subset heuristics. (a)
In addition, changing the number of trees provides much more flexibility than truncating the depth of trees in achieving the quality versus time taken trade‐off. When truncating the depth of trees, the total number of nodes in the problem changes by approximately a factor of 2 every time the depth is increased by one layer. Since the MIP is exponential in solve time, this can be the difference between a problem that solves in seconds, compared to hours (if not days). It is not possible to collect any information about the quality of the solution between these points. In comparison, the change in the number of nodes we are optimizing over is linear in the number of trees, making this an easier tool in terms of experimentation.
Comparison with optimizing over other machine learning objective functions
In this section, we compare optimizing over a random forest objective function compared to optimizing over other simple, yet commonly used objective functions derived from linear or logistic regression.
Testing environment
In most real‐world datasets, we do not observe the counterfactual outcomes associated with different actions from those taken in the data. In particular, we cannot observe the actual outcome for the solutions we select with our optimization procedure, so we need a way to estimate the effectiveness of the random forest optimization methodology compared to other choices of machine learning objective functions.
We train multiple machine learning functions from the training data and choose the best solution as evaluated by each function. This is to compare the random forest solution with the solution that would be found if we optimized over a different machine learning function. For the jury selection (classification) problem, we compare the juries selected using a random forest, a linear regression and a logistic regression objective function, respectively, 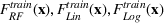
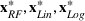
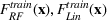
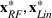
Next, we need to measure the performance of these solutions. We propose evaluating the performance of each solution using a range of different machine learning functions trained on an independent testing dataset. For the jury selection problem, we evaluate the juries chosen using a random forest evaluator 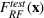
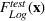
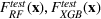
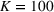
Out‐of‐sample testing procedure
Results for the jury selection case
Figure 6 shows the performance of juries chosen via various approaches. 2 For this simulation, we assume the optimizer is a prosecution lawyer who is trying to get a guilty verdict. Figure 6 shows the number of juries that were classified as guilty by the out‐of‐sample evaluators out of the 100 randomly drawn juror pools. We observe that optimization over the random forest objective outperforms optimization over the other objectives when evaluated using both the random forest and logistic regression evaluators. Of particular interest is that the random forest optimization outperforms the logistic regression even using the logistic regression evaluator. This may be due to the higher out‐of‐sample predictive accuracy of the random forest (60%) compared to either logistic regression (56%) or linear regression (49%). Interestingly, the improvement in the number of convictions using random forest (+10%) is greater than the improvement in predictive accuracy using a random forest (+4%).
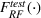
Number of juries (out of 100) which are predicted to return a guilty verdict according to out‐of‐sample model, if optimized for guilty verdict. (a) Random forest evaluator
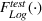
Results for the property investment case
Table 10 shows the sale price of property chosen using random forest minus the sales price of a property chosen by linear regression, as evaluated on an out‐of‐sample XGBoost 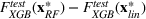
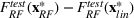
Difference in sale price of the property chosen using random forest (RF) versus linear regression as evaluated on OOS XGBoost
Difference in sale price of property chosen using random forest (RF) versus linear regression as evaluated on OOS random forest
Synthetic data
To overcome the issue of not being able to observe the counterfactuals in real datasets, we also ran experiments on synthetic data. With these datasets, it is possible to evaluate exactly how well each option does since we know what the counterfactuals are. We used the synthetic datasets from Friedman et al. (1991), which is a well‐known benchmark dataset in the machine learning community. The datasets tested are: Friedman 1: Friedman 2:
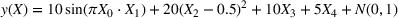
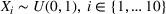
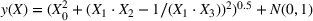
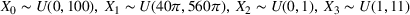
We compare learning and optimizing over a linear function, a CART tree, and a random forest with 10 trees. 2000 data points are used for training the models. In both cases, we solve 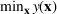

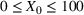
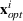
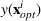
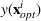
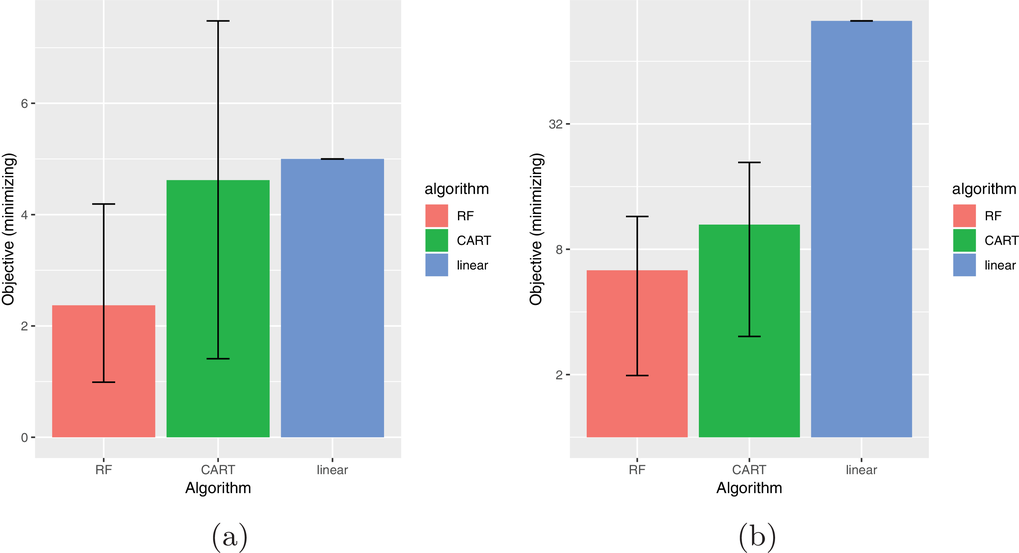
Performance on synthetic data. (a) Friedman 1 dataset. (b) Friedman 2 dataset
CONCLUSIONS
In this paper, we examine a data‐driven optimization approach, where an uncertain objective is estimated according to a machine learning function. In particular, we have shown that it is possible to optimize over a random forest objective function with general polyhedral constraints using mixed‐integer linear programming. Including constraints in our approach allows us to model many problems of practical interest as well as to define a policy class for our decisions, which can be useful for interpretable decision‐making. While the efficacy of this approach depends on the predictive accuracy of random forest relative to other predictive models, and the time available to find a solution, this approach has many advantages. First, random forests are a very powerful prediction algorithm that can fit unknown nonlinear and complex interactions of features with minimal feature engineering. Second, random forests often perform very well in practice, with high prediction accuracy. Third, we can leverage existing MIP solvers which are effective at solving large‐scale complex problems and provide flexibility to model a wide range of problems. We demonstrate the effectiveness of this approach at solving real‐world problems using a case study on jury selection and property investment and show this method outperforms other machine learning objective functions. We also show that it is possible to achieve significant speed improvements using Benders cuts for large‐scale problems.
For large‐scale random forests, we propose an algorithm for approximating a random forest with a limited number of trees and show analytical bounds on the probability of being suboptimal by a given amount. In particular, for trees with axis‐aligned splits, we show that the number of trees we need to sample to be within ε of the optimal solution with a probability 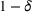
Footnotes
1
2
We fixed the case features for each of the trials we selected a jury for and selected a juror pool by bootstrapping from the juror population. Note that the results below are for a difficult instance of the problem; the case type makes a conviction unlikely, so the appropriate benchmark is the likelihood of conviction for a randomly selected jury, not 50%.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.