
Abstract
Objective
To evaluate whether machine learning algorithms can predict healthcare professionals’ occupations (physiotherapist, nurse, and dietitian) from PACPS (Physical Activity Counseling Practices Scale) item responses.
Methods
We conducted a cross-sectional study in Konya (January–April 2025) with 242 participants. Five algorithms (Random Forest, K-Nearest Neighbors, Support Vector Machine, Decision Tree, and Naive Bayes) were trained and evaluated as follows: we first performed a stratified 70:30 split of the original dataset (train n = 126, test n = 116). Data augmentation was then applied only to the training set to address class imbalance, increasing it to n = 269, while the test set remained untouched (n = 116), preserving an effective ≈70:30 ratio. Performance was assessed on the independent test set (n = 116) using accuracy, precision, recall, and F1-score. Random Forest feature importance was examined to aid interpretability.
Results
On the test set (n = 116), accuracies were 0.76 (Support Vector Machine), 0.82 (K-Nearest Neighbors), 0.71 (Naive Bayes), 0.75 (Random Forest), and 0.67 (Decision Tree). Random Forest identified PACPS12 as the most informative item for discrimination among occupations.
Conclusion
PACPS responses contain distinctive patterns that enable moderate occupation prediction, with SVM and KNN yielding the best generalization in this small-sample setting. These results support the feasibility of combining a clinically grounded scale with machine learning methods, while underscoring the need for larger and externally validated datasets before clinical implementation.
Keywords
Introduction
Physical activity counseling for patients in primary healthcare is an important component of health promotion. 1 Randomized controlled trials have shown that adults of all genders can increase their physical activity and fitness after receiving counseling in primary healthcare. 2 Physical activity counseling has been found to be effective in increasing physical activity levels with regular follow up, community support, and referrals for physical activity. In addition, the integration of physical activity counseling and referral programs into primary healthcare teams was found to be cost-effective. 3
While most clinical guidelines assign physicians the responsibility for physical activity counseling, the recent Making Every Contact Count strategy extends the responsibility for promoting positive behavioral changes to all healthcare professionals. Therefore, it is important to note that physical activity counseling should be at the center of medical consultation. While there is some literature on general practitioners “use of brief interventions to increase patients” physical activity in primary healthcare, there is a lack of evidence on the physical activity counseling practice of hospital-based health professionals.3,4 The Physical Activity Counseling Practices Scale (PACPS), was developed to facilitate the examination. 5 PACPS, which we developed in our previous study, determines the extent to which health professionals perform physical activity counseling. The scale is a Likert-type scale, where a high score indicates a good level of physical activity counseling.
Artificial intelligence is an interdisciplinary field of research that has recently gained significant importance in society, the economy and the public sector. Advances in artificial intelligence have attracted the attention of researchers and experts, offering a variety of valuable applications in the public sector. Artificial intelligence systems are designed to simulate or mimic human behavio to max efficiency and productivity, min errors, and ensure accurate and appropriate decision making. Consequently, artificial intelligence systems are oriented toward logical thinking and action by imitating the natural human decision-making process.6,7
Obtaining information about health professionals’ professions may be difficult due to individual privacy concerns. The artificial intelligence-supported model is designed to predict the professions of health professionals who fill out the scale. The goal is to predict the profession of healthcare professionals by teaching PACPS to support artificial intelligence applications. Occupational prediction and a high degree of reliability are important for the adaptation of the study to other occupational groups. The research we planned is pioneering. There are no similar studies in literature.
Materials and methods
Design
This research is a descriptive study. Ethical permission was obtained from Necmettin Erbakan University Health Sciences Scientific Research Ethics Committee (Decision No:2025/915 08.01.2025). 8
Participants
This research was evaluated using self-report scales and distributed to healthcare professionals (physiotherapists, dietitians, and nurses) working at Necmettin Erbakan University in Konya. Detailed information about the research was also shared via Google Forms in professional WhatsApp groups of physiotherapists, nurses, and dietitians. In this way, it was aimed to reach a larger sample. Participants were included in the study voluntarily in accordance with the Declaration of Helsinki between January and April 2025. 9 Inclusion criteria: being between the ages of 18 to 64, and being a health professional (physiotherapist, dietitian, and nurse) for at least 2 years. 10 Participants agreed to participate voluntarily after being informed about the study verbally and in writing. Participants were excluded from the study based on the following criteria: working less than 2 years; having cognitive, mental, or psychological problems; or having a chronic disease that will affect their life. 11
The sample size is the minimum number of participants required to conduct research by clinical significance. Although the power analysis program G*Power 3.1.9.7 is widely used in general research for the calculation of sample size, it is specifically applied to our research due to its capability to support artificial intelligence applications. Similar studies have stated that there should be 10 to 20 times the number of items in simple linear regression applications and at least 100 to 200 participants in logistic regression.12,13 In Decision Trees machine learning research: it is recommended that there should be 200 to 500 participants. DT has considered the risk of overfitting. For K-Nearest Neighbors’ classification, over 100 datasets have been proposed. 14
In this research, the calculation was made using the sampling theory formula: n (sample size) and Z (Z-score). For a 95% confidence interval, the Z-score corresponds to approximately 1.96 in the table
Outcome measures
PACPS: It consists of 13 questions. It is a five-point Likert-type scale with the following scoring: 1: Never, 2: Rarely, 3: Occasionally, 4: Most of the time, and 5: Always. The scale has a minimum score of 13 and a maximum score of 65. The standard error of the measure (SEM) and minimal detectable change (MDC) values calculated for the PACPS developed in Turkish were 0.81 and 2.25 points, respectively. 5 The Physical Activity Counseling Practices Scale (PACPS) was developed and validated by Çankaya et al. 5 As the scale developers, we have full rights to use it in the present study, and no additional copyright permission was required.
Prediction modeling
All experimental setup and analysis were performed using a PC with the following specifications. MacBook, M2, 8GB RAM, and 256GB storage capacity. The dataset was preprocessed using a Jupyter Notebook in Dataspell with Python version 3.13.2. In this study, five different machine learning algorithms were used to classify the dependent variable.
Random Forest (RF): Due to its capacity to learn complex and nonlinear relationships, 16 K-Nearest Neighbors (KNN) has a simple structure and heuristic approach. 17 Support Vector Machines (SVM): For its effective results with high dimensional and nonlinear datasets; Decision Tree (DT): Due to its easy interpretability and visualization advantages; Naive Bayes (NB): Because of its fast and efficient classification performance. TRIPOD-Cluster is a checklist used.
Sample size and augmentation: The original dataset comprised n = 242 respondents (used for descriptive tables). For prediction modeling we targeted n = 385 (based on the a priori calculation). To avoid information leakage, we first performed a stratified 70:30 split of the original dataset (train n = 126, test n = 116). Data augmentation was then applied only to the training set, increasing it to n = 269, while the test set remained unchanged (n = 116). This corresponds approximately to a 70:30 effective ratio. Synthetic samples were generated to preserve the marginal distributions of the 13 Likert-type PACPS items and the class balance; no participant-level identifiers were used. All hyperparameter tuning and cross-validation were conducted after this split and within the training data only. Results are reported exclusively on the untouched test set.
Machine learning algorithms
Model tuning and selection: We used an inner 3-fold stratified cross-validation with randomized/grid search for each algorithm. 18 The primary selection metric was macro-F1 (to balance class-wise performance), with overall accuracy recorded as a secondary metric. Pipelines included scaling where appropriate. All preprocessing steps (e.g. scaling/encoding) were fit only on inner-fold training splits and applied to validation splits to avoid data leakage. After tuning, the best configuration was re-fit on the entire training set (n = 269) and evaluated once on the held-out test set (n = 116). Stratified splits and fixed random seeds ensured reproducibility.
In this study, five prediction models—RF, KNN, NB, SVM, and DT—were developed and compared using the PACPS items as predictors under a stratified 70:30 train–test split. The optimized models were then used to predict occupation based on PACPS responses.
Final performance was reported with accuracy, precision, recall, and F1-scores, and confusion matrices (Table 1) were generated to illustrate class-level prediction patterns. The individual machine learning algorithms are described below.
Test-set confusion matrices for each model (n = 116).
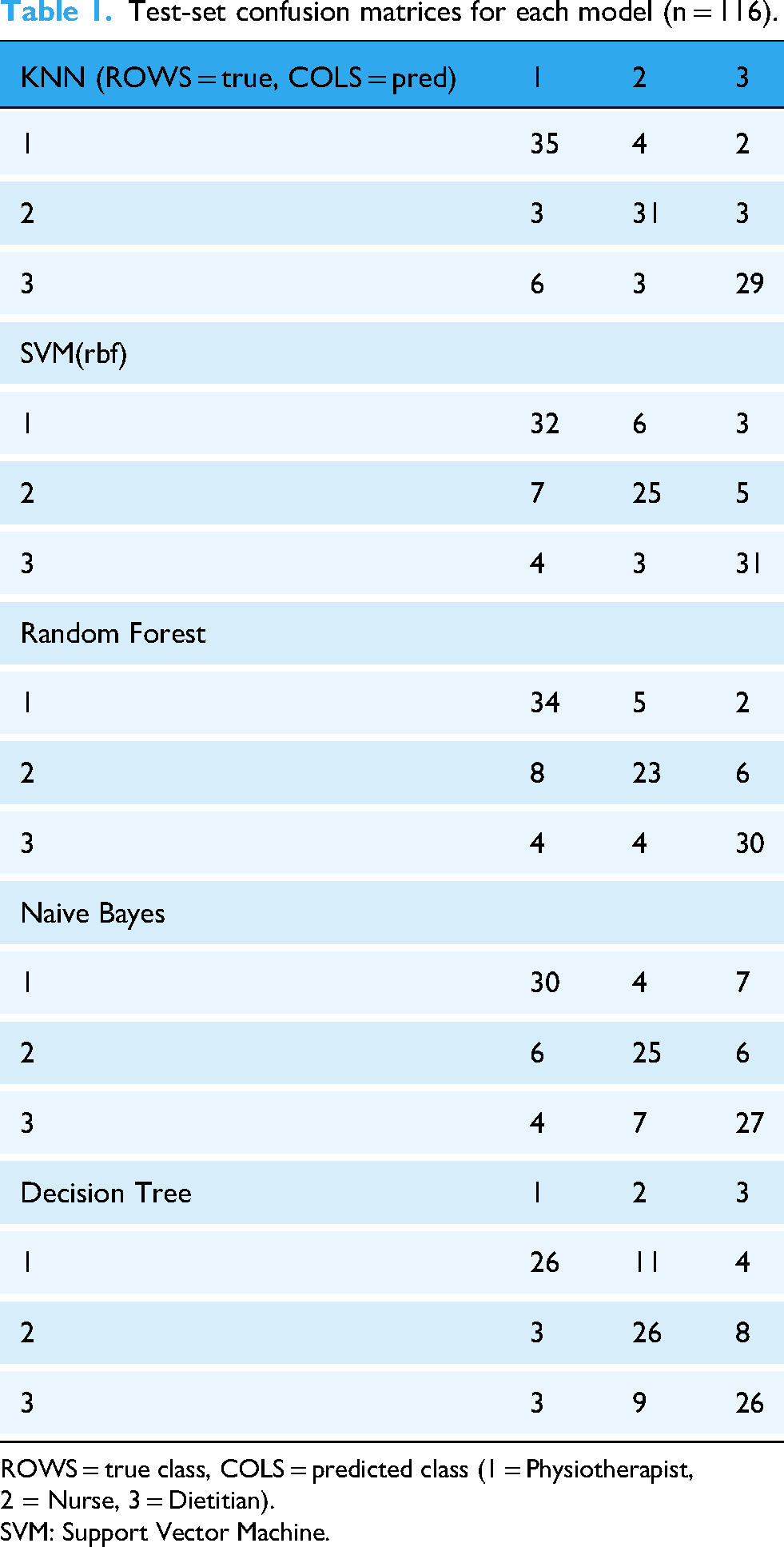
ROWS = true class, COLS = predicted class (1 = Physiotherapist, 2 = Nurse, 3 = Dietitian).
SVM: Support Vector Machine.
Random forest
In this study, RF was optimized over the number of estimators (100–500), maximum tree depth, and split criteria (gini vs. entropy). The best configuration (n_estimators ≈ 300, max_depth = None, criterion = gini) achieved a test accuracy of 0.75. RF feature importance analysis indicated that PACPS12 (interprofessional counseling and collaboration) was the most influential item, consistent with the observed professional differences across physiotherapists, nurses, and dietitians. Although RF provided relatively high accuracy, deeper trees showed signs of overfitting compared to simpler models.
K-Nearest Neighbors
KNN was tuned for the number of neighbors (k = 3–15) and distance metric (Euclidean vs. Manhattan). The best setting was k = 7 with Manhattan distance (p = 1), reflecting the ordinal structure of the Likert-type PACPS items. This yielded the highest generalization among all models, with a test accuracy of 0.82 and balanced class performance, confirming the suitability of KNN for small-scale health datasets.
Naive Bayes
The multinomial variant of NB was applied due to the categorical/ordinal nature of the PACPS responses. No major hyperparameters required tuning beyond Laplace smoothing (alpha = 1). Despite its strong independence assumption, NB performed competitively, with a test accuracy of 0.71, and provided fast, robust classification with minimal risk of overfitting.
Support Vector Machine
SVM was optimized for kernel type, C, and gamma parameters. The best configuration was an RBF kernel with C = 10 and gamma = 0.1, which achieved a test accuracy of 0.76. This performance demonstrates the ability of SVMs to capture nonlinear decision boundaries in health survey data, while maintaining robustness under limited sample size conditions. 19
Decision Tree
DT were tuned using GridSearchCV with candidate criteria (gini and entropy), class_weight settings (none and balanced), and depth constraints. The best configuration was criterion = gini, max_depth = 5, min_samples_split = 2, min_samples_leaf = 3, class_weight = balanced.
On the independent test set (n = 116), the DT achieved an accuracy of 0.67. Precision, recall, and F1-scores were 0.66, 0.68, and 0.67 for physiotherapists; 0.65, 0.66, and 0.65 for nurses; and 0.70, 0.68, and 0.69 for dietitians. These results show that DT produced intuitive and interpretable decision rules useful for clinical understanding. However, the model was susceptible to overfitting; while depth and leaf-size regularization partly mitigated this issue, performance remained lower than ensemble methods such as RF.
Overfitting control: For tree-based models, we applied depth and leaf-size constraints (e.g. DT: max_depth = 5, min_samples_leaf = 3; RF: tuning max_depth, min_samples_*, and class_weight = balanced) and used stratified splits. Data augmentation was restricted to the training folds only, and all preprocessing (scaling/encoding) was fit within the inner training folds and applied to validation folds to prevent leakage. Hyperparameters were selected via inner three-fold CV using macro-F1 as the primary metric; the best configuration was then re-fit on the full training set (n = 269) and evaluated once on the untouched test set (n = 116). We monitored train–test deltas in accuracy and macro-F1 to detect residual overfitting.
İstatistiksel Analiz
The SPSS IBM 29.00 software package was used for data analysis. The statistical significance level was determined as p = 0.05. The data obtained from the interview form created to determine the characteristics to be measured was analyzed using frequency and percentage distributions as part of descriptive statistics. The findings were presented in graphs and tables. 20 In this section, various data preprocessing steps were performed using Python 3.13.2 for statistical analysis of the dataset. First, the basic statistical properties of the dataset were analyzed using the Pandas, PyReadStat, Numpy, Matplotlib, and Sklearn libraries, which collectively help define the data. 15 The operations performed on the dataset ensured that statistical analyses were conducted appropriately, and data optimization was achieved. 21
Defining and Cleaning the Data Set; the dataset was obtained from an Excel file created through the system, from data collected with the help of Google Forms, using the PyReadStat library. The data was read from the Excel file obtained. Before performing basic statistical analysis on the dataset, a horizontal examination scheme was presented using the describe T function. General statistical properties of the dataset were extracted. 22 Next, discrete data were found and removed, improving the quality of the dataset. It was divided into training and test sets for the model. The parameters of the models created with machine learning algorithms were optimized. The best parameters were determined with the help of GridSearch CV. 23 In this step, the features of the dataset were scaled. 24 The performance of the model was evaluated by dividing it into training/test sets. 25 The performance was reported. The reports were graphed and presented.
Results
Dataset
The dataset used for this study was obtained using the PACPS. The dataset consists of health professionals categorized as physiotherapists, nurses, and dietitians. The dataset does not contain sensitive personal information such as participants’ names or other identifying information. Sociodemographic information for all variables is shown (Table 2). The average PACPS scores by occupational groups, as well as overall means, are shown in Table 3. The PACPS 12 question had the lowest mean scale score in the dietitian occupational group, while the PACPS 1–11 and 13 questions had lower means in the nursing occupational group (Table 3).
Physical and sociodemographic characteristics of the participants (n = 242).

BMI: body mass index; M: mean, SD: standard deviation.
Physical Activity Counseling Practices Scale (PACPS) mean scores by occupation (n = 242).
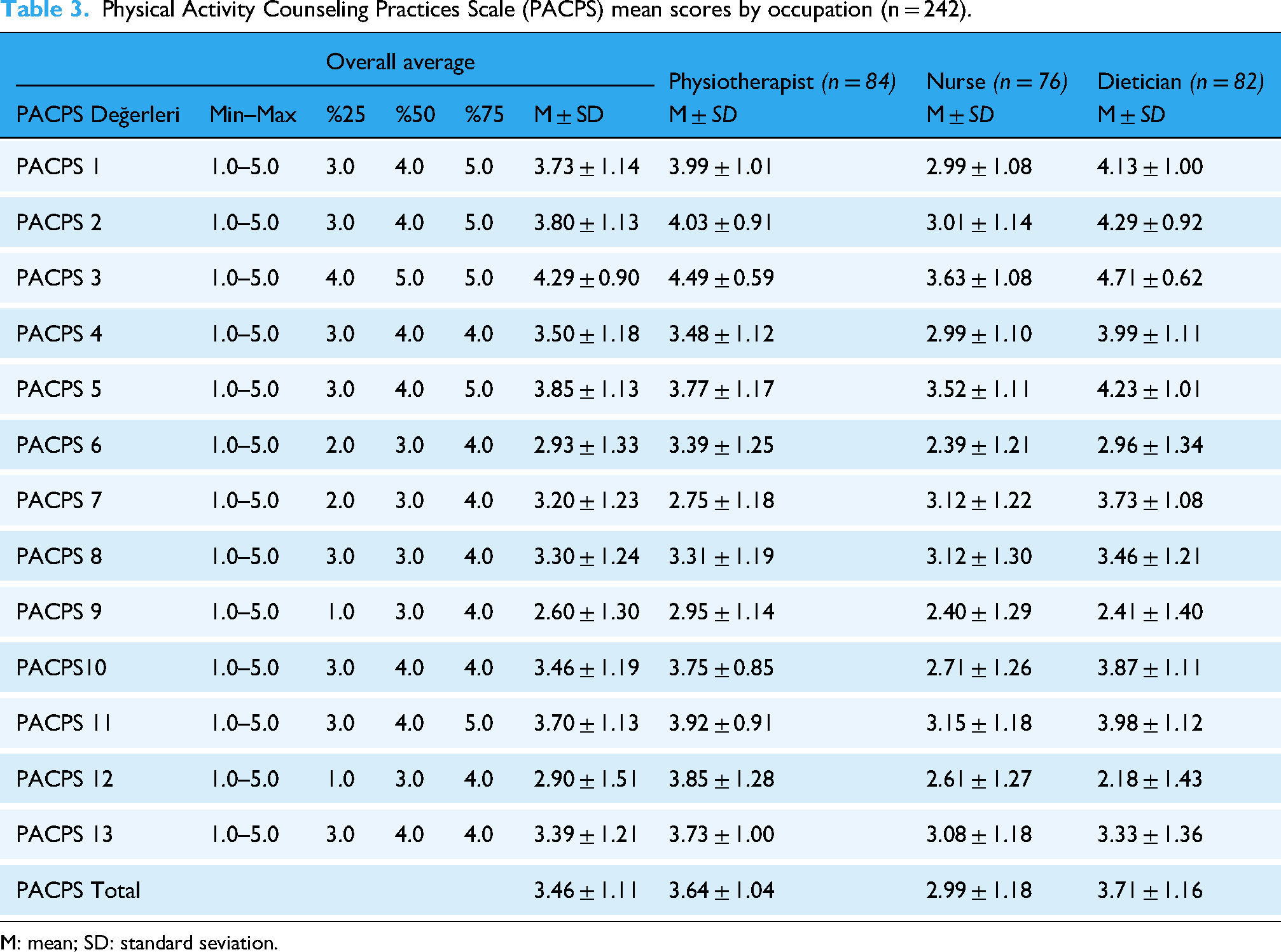
M: mean; SD: standard seviation.
Random Forest
The parameter optimization for the RF model was performed using GridSearchCV. Candidate values of n_estimators (200, 300, and 400) were tested, and the best configuration was obtained with n_estimators = 300, max_depth = None, min_samples_split = 5, min_samples_leaf = 5, and class_weight = balanced.
Feature importance analysis indicated that PACPS12 was the most influential item (importance = 0.131) (Table 4). On the independent test set (n = 116), the overall accuracy of the RF model was 75%. The classification report showed precision, recall, and F1-scores of 0.74, 0.77, and 0.75 for physiotherapists; 0.70, 0.71, and 0.71 for nurses; and 0.80, 0.77, and 0.78 for dietitians, respectively (Table 5). These results suggest that while RF effectively identified relevant features, its generalization performance was slightly lower than that of KNN and SVM (Figure 1(a)).

Training and test accuracy scores of Random Forest (a) and K-Nearest Neighbors (b) algorithms based on the PACPS dataset. PACPS: Physical Activity Counseling Practices Scale.
Feature importance of the Random Forest algorithm.

| Feature | Importance |
|---|---|
| İPACPS12 | 0.1679 |
| İPACPS14 | 0.1160 |
| İPACPS7 | 0.1005 |
| İPACPS3 | 0.0863 |
| İPACPS10 | 0.0759 |
| İPACPS2 | 0.0663 |
| İPACPS6 | 0.0558 |
| İPACPS1 | 0.0517 |
| İPACPS13 | 0.0457 |
| İPACPS9 | 0.0454 |
| İPACPS12 | 0.1679 |
| İPACPS14 | 0.1160 |
| İPACPS7 | 0.1005 |

