
Abstract
Many industries, both within and outside healthcare, have benefited from the adoption of open-source software and open standards. Notable examples of this include the use of open-source languages, such as Python and Perl to perform both chemo- and bioinformatics work. In parallel industries, most of the world's largest Web sites operate on open-source software both in the operating system (Linux) and the Web server software (Apache).
However, the field of laboratory automation has neither adopted nor created a great deal of standards and has also not taken advantage of the wide range of open-source software available. This article introduces open-source software and discusses the benefits to a wider world and the possible advantages to the field of drug discovery and laboratory automation.
Introduction
Software is one of the most common components used in the development of laboratory automation systems. Products are available from a variety of sources, including instrumentation, LIMS, and within the last few years, Electronic Laboratory Notebooks (ELN) vendors. The range offered leaves gaps in software that are usually filled by customers paying vendors, consultants, or internal groups for modifications/tailoring to meet unique needs, or extensions to standard packages; often at a considerable expense. In addition, there are other gaps that may exist because there is not a sufficient market for a product to justify development costs, or because a vendor has dropped support for a product.
One alternative to the cost of software modifications is the use of open-source communities to define projects and guide their development, distribution, and support. The use of a community would provide a wider range of perceptions and could lead to better software. There are open-source programs for laboratory use that include LIMS (Bika [http://www.bikalabs.com/] and a product under development by LabLynx [http://www.lablynx.com/Content/default.asp]). Earlier projects include the FORTH language (www.forth.org) and hardware developed at National Institute of Standards and Technology through the Consortium on Automated Analytical Laboratory Systems project (ftp://ftp.omg.org/pub/docs/lifesci/99-03-13.ppt).
Companies doing software development work may believe that their needs are unique, however, laboratories doing similar work do not differ much in their software needs (instrument connections, dissolution analysis, stability software, and so on). Those customers may prefer to use an open-source project that has wider use, documentation, testing, and support than doing the development in-house.
The purpose of this article is to
review the history of open-source development,
compare key factors in open-source and commercial software,
review the benefits, development requirements in a regulated environment, and
propose a test project.
Our interest is to start a discussion of the subject and gain input from others who would be interested in this work.
History of Open-Source Programming
The modern PC arguably has its roots in the late 1960s; when home computers were assembled in computing clubs and bedrooms by hobbyists and academics. During this period, software was free and open to all, not because of any specific agreements but more because the key players at that time all knew each other. The times changed in 1976 when Bill Gates released an infamous “Open Letter to Hobbyists.” 1 In brief, this letter expressed frustration by Bill Gates that his software was being copied and distributed for free among his peers. He claimed that if people continued to do this, then programmers could not make money and pay their bills.
Moving on 40 years, people who were around at that time went on to form the largest companies in the world, including Sun, Apple, Microsoft, Hewlett-Packard, and more. The writing and licensing of software is a major business and we do indeed have high-quality software, which benefits our lives and society. However, not all software works on the traditional model of computer programmers working and then selling the fruits of their labor to a willing market.
During this time, a group of people took an initiative to re-ignite the original concept of sharing software. This was the GNU Project, 2 launched by Richard Stallman in 1983. The products detailed and distributed under the umbrella of these projects are mainly targeted at computer scientists and expert users. Although they affect our computing lives, these operate in the background away from the public eye.
This started to change in 1991 when Linus Torvalds created the first generation of a new operating system called Linux. This was the seed which led to the popular distribution of Linux which is an operating system in wide use today. Although Linux is not the most common operating system on the desktop, it is very popular in computers which run the Web and serve files to users.
Arguably, the most popular open-source end-user focused applications today are organized by the Mozilla Foundation and encompass products such as Thunderbird for reading email and Firefox for Web browsing. This foundation was inspired by an essay by Eric S. Raymond entitled “The Cathedral and the Bazaar.” 3 In this essay, Raymond describes the idea of including as wide a group of people as possible and to release the software as frequently and as often as possible. Following this philosophy followed, Mozilla produces software that comfortably competes with both Microsoft and Apple.
Linux, GNU, and Mozilla show markedly different approaches to open-source management. Some open-source projects are galvanized around a central figure that organizes and co-ordinates all of them. Others, such as GNU, are galvanized behind a strong inspirational leader; sometimes these people are called Benevolent Dictators For Life (BDFL, another example is Guido Van Rossum 4 ). Yet another example is the Mozilla Foundation which is run as a company and works in a much greater corporate style. The basic message here is that organization and project management techniques are as wide and varied as the proprietary, close-source sector.
Today, open-source software is big business; some products are sponsored by major corporations such as an open-source office suite called OpenOffice, 5 which is backed by Sun Microsystems. Other open-source products are produced by a company which releases an open-source version and then backs this up with a premium version which is paid for. One famous example of this model is MySQL, 6 which was recently purchased by Sun Microsystems for 1 billion USD, showing that the open-source software is indeed big business.
Other models have included giving away the software and then offering support to users who require it. An often quoted criticism of open-source software is that the customers have no support which they can rely on. Apart from open newsgroups on the Internet, this model is used by nearly every open-source company. Again, a company which released software to enable large scale software to be written entitled J Boss has recently been acquired by RedHat Inc. for 350 million USD.
Parallel industries have benefited from the adoption of open-source software, including bioinformatics, silicon chip manufacture, banking, governmental administration, and so forth. The adoption of open-source software has increased productivity, aided standards, and increased security in every case it has been introduced. Indeed, computer programmers in these industries must know these technologies or they will find it difficult to find a job! The end-users in these industries either use open-source software or will be using software that has been constructed using open-source tools.
The industry of laboratory automation has not as yet benefited greatly from open-source software; however, this is starting to change as the tools we adopt are moved to open source, thereby changing the attitude of developers and project managers.
The open-source approach to software development would be of benefit to the laboratory automation community by providing robust software for techniques where it is lacking and user-defined/controlled alternatives to current commercial products. The plug-in architecture would broaden the options for data analysis. A basic framework for instrument data acquisition, analysis, and reporting would—through modules developed by independent researchers—be expanded to include choices that might not otherwise be available. This could spur research into laboratory informatics that might not be practical because of limitations on its ability to be broadly applied.
Open-Source vs. Commercial Software
Open-source software has in some cases produced high-quality products, several of which have been noted in earlier discussion. WordPress 7 is a high-quality package used for Web-logs (blogs) with a community of developers, contributors, users, vendors of add-on software, and publishers of “how-to…” books. In many ways it is a good model for managing open-source software. How does that model hold up in a laboratory environment? The following table gives one perspective on key criteria for evaluating projects from the two environments.
Assuming you are technically competent or have ready access to technically competent people for installation and start-up, the major concerns are support and regulatory issues. Support is not a significant problem. The software is available at no charge or a very small charge if you order it on disk and decide to purchase additional documentation from third-party sources. Given that, it would be reasonable to do a trial evaluation of the software, determine its suitability through use, and the need for and quality of support. If it does not meet your needs, remove it and look for traditional vendor supplied packages; your risk is small. As a contrast, with a product purchased from a vendor, you may have to rely on vendor support statements and those of end-user reference sites before you commit to a purchase.
Beyond the trial evaluation phase, you have to consider the product life-cycle: whether the software is being actively maintained (bug fixes) and whether there is a formal mechanism for requesting new capabilities.
The Open-Source Initiative 9 states that there are “No Intentional Secrets: The standard MUST NOT withhold any detail necessary for interoperable implementation. As flaws are inevitable, the standard MUST define a process for fixing flaws identified during implementation and interoperability testing and to incorporate said changes into a revised version or superseding version of the standard to be released under terms that do not violate the OSR (Open Standards Requirements).”
This statement should be tested against any packages one considers because one is committed to one's laboratory data (package) and would want to ensure that if something happens to the availability of software and if any data structures are open, they can be recovered as intellectual property.
One place where vendors have clear advantage is the vendor audit. They can be visited, questioned, facilities can be toured, and so forth. Open-source projects may lack that sense of a physical place to arrange a meeting, although project conferences, Web-logs, and forums may meet your requirements. WordPress (www.wordpress.org) is one example of how the need for vendor audits can be addressed. The purpose of a vendor audit is to determine the quality of the process used for development, the support available, review code, and to gain a measure of the organization on which one is going to rely on to produce a product one is considering for use. Through its Web site, one can gain access to code, documentation, troubleshooting information, support groups, requests for information/features and feedback, and group meetings, to name a few points. It is a virtual organization and may be typical of the distributed development environments that will become common in the future. The key question is this: can you get sufficient information from the site and interactions with users (effectively reference accounts) to gauge the quality of the product and development/support team?
The code for open-source projects should be readily available, allowing a detailed examination of the code. This is a clear difference from vendor products; vendors own the software and protect it, access to the code may be difficult to arrange. If the company drops a product or goes out of business, you may have difficulty gaining access to source code unless it was part of the purchase agreement.
Support is fundamental to successful commercial software products. As noted earlier, a low cost or free support structure for open-source projects may take time to develop. Developers may use support as a basis for generating revenue for continued development and to keep themselves afloat. Linux packages are available from several sources, some free, some charge for the software distribution and that charge includes a support agreement. Customers may initially purchase the paid version of an application and once they become confident in its use, and support becomes available, use free versions for additional systems.
One revenue model that should be useful, and have some benefits when dealing with regulatory issues, is to have two (or more) layers of software. A core layer would consist of the primary functional module containing the main element of the software. A second (or more) layer(s) would contain customizable sections of the software. These might include a user interface, plug-in module for devices, links to databases, and so on. The higher layers would be revenue producing and vary from customer to customer, whereas the core would be open source with some minimal higher layer functionality.

The broader user community would provide support for the core, individual companies would provide the layers for service and support. This model is used by CrownPeak (www.crownpeak.com) for the SaaS system, WordPress (www.wordpress.org), and others.
In addition to the validation document set noted earlier, developers of the core software could generate revenue through software development kits (SDKs), courses for developers, hosting in-person, or on-line conferences to note a few.
Benefits of Open-Source Methodologies for Development
When producing a product for consumption by others, the developers are driven by many more incentives than revenue, or “making money.” Other incentives include the desire to create, challenge themselves with intellectual problems, and learn new technical skills. Indeed in large organizations, the developers, inventors, and engineers are kept away from the “money” side of things and these matters are dealt with by others.
The main reason for this is that it allows the developers to focus on the needs of the customer and allows someone else to cost the product. This allows the creative people to do what they do best, which is innovate. Although having an obvious creative advantage, the engineers need to maintain a link to the revenue-generating aspect of the business. For example, Microsoft is producing and giving away Internet Explorer, and Apple is doing the same with Safari. Although these are good products, neither company is doing this for purely altruistic reasons—they are doing this to provide advertising channels and sell associated products.
However, open-source projects do not have the need to develop revenue—instead the only reason an open-source project exists is to provide functionality to the company's product. This means that the engineers can solely concentrate on the elements of their project that “make it better.” This freedom which is felt by the engineers empowers the individual and leads to better software.
Another common problem in developing software is the prevalence of the dreaded bug. Basically a bug is an unintended function of the software; nearly always this is the cause of a problem. In a complex piece of software, no matter how skilled the team developing the software is that bugs will appear irrespective of how well the software is reviewed and tested. The reason behind this is that it is uneconomical to hire enough reviewers and testers to support the development work—the numbers simply do not add up. However in an open-source world, this does not apply. Here, the developer releases the code to the world which means that there is a large pool of reviewers available to the developer. In addition to this, the users are the effective reviewers—if the users find a problem, then they can actually look at the source code of the application, fix the error, and submit it back to the developers. This practice should lead to software which contains fewer errors and is therefore more reliable.
Along similar lines to this, the developer gains from a certain degree of auditing. When software needs to be secure and provide correct audit trails of the process which the software is managed, the developer must ensure that this section is correct. However, any errors that appear in the tracing or security can be easily picked up by the active community surrounding the project and flagged immediately as a priority to correct. As an extra benefit to the users of the software, this allows them to ensure that the security and traceability are actually being performed correctly—something that could never happen without being able to inspect the source code of the product.
Finally, open-source methodologies also give the participants of the project to learn new skills. Unlike a closed source project, anyone can take part—there is no need to get a new job to learn new skills. This means that the project and the participants can take advantage of a diverse range of skills and backgrounds, leading to a better final product and a more valuable experience for each participant in the project.
Development Requirements of Open-Source Laboratory Projects in a Regulated Environment
At first glance, this subtitle may appear to be an internal contradiction. The major concern is the validation requirements. The U.S. Food and Drug Administration (FDA), 10 for example, recognizes two general classes of software:
that which is considered a medical device 11 (which covers software produced within a company, including out-sourced contracts), and
By nature, open-source projects would not be considered as medical devices but rather as off-the-shelf software because they are not customer application-specific developments. An open-source project would be expected to have a broad range of potential customers as its target market to justify development.
This shifts the validation burden from the developers to the end-users, who would have to develop a statement of need and then demonstrate that the software fills that need, just as they would for any commercial product.
This does not take the vendor off the hook. The FDA has special documentation requirements 14 for off-the-shelf software. Section 2.5.1 reads: “Provide assurance to FDA that the product development methodologies used by the OTS Software developer are appropriate and sufficient for the intended use of the OTS Software within the specific medical device. FDA recommends this include an audit of the OTS Software developer's design and development methodologies used in the construction of the OTS Software. This audit should thoroughly assess the development and qualification documentation generated for the OTS Software.”
and continues:
“Note: If such an audit is not possible and after hazard mitigation, the OTS Software still represents a Major Level of Concern, the use of such OTS Software may not be appropriate for the intended medical device application.”
This additional documentation may be considered as a separately priced “add-on” product by the developer. The same may hold true for any procedures, scripts, or software used as part of the installation, operation, and performance qualification steps.
Another area of potential concern is the development process used for open-source programs. An article titled “Benefits of Using Open Source Software” 15 makes comments that run counter to FDA concerns. The article states that open-source projects:
lack formal development specifications, 16 and
provides the ease with which problems can be detected and changes can be made to correct them. This improves the reliability of the software by having a community available to address problems more effectively than a small development group could.
These are offered as part of the culture of open-source systems. The first point is a serious issue that can be addressed by the development of formal specification—and the adoption of a formal development cycle. The FDA's “General Principles of Software Validation” cited earlier makes several points:
“Because of its complexity, the development process for software should be even more tightly controlled than for hardware, to prevent problems that cannot be easily detected later in the development process” (page 8)
“Typically, testing alone cannot fully verify that software is complete and correct. In addition to testing, other verification techniques and a structured and documented development process should be combined to ensure a comprehensive validation approach” (page 8)
You can't test quality in software.
One of the frequently cited benefits of the open-source culture is that you have a larger group of people working with the software, exposing and fixing problems and as a result providing a “better quality” product. Quality has to be designed in. Testing will reveal the resulting quality of the design and implementation effort. The availability of a large testing group identifying and fixing problems will be of value if the basic product design is sound. As noted earlier, the WordPress program is an example of having this done successfully.
The real benefit of the open-source movement in laboratory software will be the availability of a community of people willing to contribute to all phases of the project: functional specification, design, implementation, testing, and so on. The “many eyes” approach should yield better project definitions and quality improvements in all project phases, at the expense of speed—projects will be slower to implement because of the overhead of coordinating and managing the diverse inputs. Fortunately, Web-based resources for collaboration could mitigate that potential problem. This approach would protect users of the product from one of the hazards of commercial software: loss of access and support for a product if a company drops it or goes out of business. The membership of the project group may change, but if the product is valuable, the group could go on indefinitely.
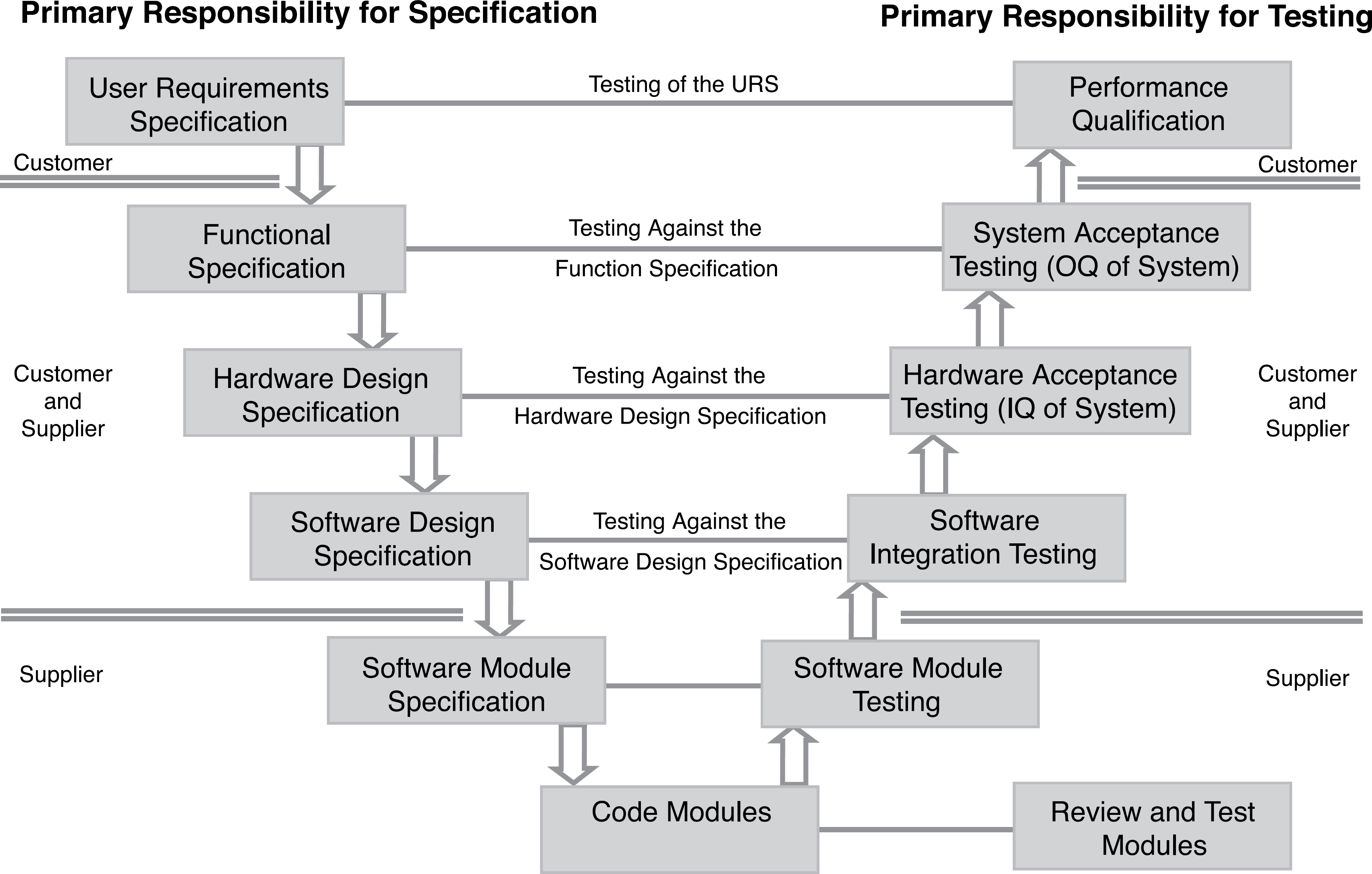
There are ways of satisfying regulatory requirements within the open-source world. The term “open source” refers to two points: a licensing model and the availability of design materials needed to work with the hardware/software, including the code for any programming. It does not refer to an engineering methodology. One accepted approach is to use the “V” model 17 (shown later) for specifications, development, testing, and qualification. The model outlines a process. The left arm shows the steps in project definition, the base is the actual development, and the right arm illustrates the steps in testing and qualification. The diagram uses the word “customer,” which for the purposes of this discussion would be the open-source community. The “supplier” is the engineering team.
To do open-source development in a regulated environment (FDA, ISO, and others), there are at least two choices. Having a small group of developers, local to each other, do the actual engineering, and the other, using a community for evaluation purposes.
Let us assume someone has an idea for a project. As noted earlier, there is a revenue model for a layered software implementation—the base of the system is a functional product designed for user/third-party extensibility. A proposed specification can be drafted and circulated within the interested community for comment (left arm of the “V”). At some point it is frozen and the next development stage proceeds in a similar fashion. The open-source development work is done on the core software with specifications and examples for customizable layers. The traditional code-walk throughs and testing are done within the community (customer). Once the software is certified for release, bug fixes are done using a structured bug-notification, fix, and periodic controlled release. Throughout this process, sound engineering methodologies would be used to demonstrate control over design and development, as well as change management. This would yield a system that has sufficient documentation to function as off-the-shelf software.
With user-customizable functions limited to upper layers, we have a workable compromise. All the benefits of open-source software are available (licenses, access to code, a community for support, and so forth) with segregation of user modifiable functions. This makes it possible to treat the core as traditional off-the-shelf software with the ability to make and validate user-specific features. This approach is very similar to that used in product development where user or third-party extensibility is designed (Adobe's Photoshop & Dreamweaver, and National Instrument's LabVIEW are examples of this structure). The key elements to a successful project are clear documentation (including revision history) and a well-developed communications process. Project engineers will recognize this as business-as-usual, with an expanded customer base.
The benefits of the “many eyes” aspect of community involvement are a more robust system because of more diverse input and broader—and hopefully better—testing. It should be noted that the end result of testing by the community is bug reporting, not bug fixing by the community. Error correction would be a task of the core engineering team to maintain control of design and code.
A more ambitious engineering methodology would use the community for the development of part of the system. Groups would be assigned functional modules for development and be responsible for documentation, bug fixes, and maintenance—final code builds would be maintained by the primary project management group. The crux of the issue is the ability to do the work in a collaborative engineering environment. This need is going to grow as companies and development teams work to develop products in a distributed geographical environment. A simple Web search will show an active community of corporate and academic efforts to make collaborative development a reality. There are two examples that point to the potential for success in this arena.
The Open Prosthetics Project 18 describes a geographically distributed open-source collaborative engineering and design program for the development of better prosthetic hands and arms for amputees. This community-based approach is an example of cooperative development. The article and Web site aren't clear on the regulatory aspects of the work, but stress the effectiveness of the collaboration. The use of sound engineering processes noted earlier should yield a product that meets regulatory issues.
“Successful Collaborative Software Projects for Medical Devices in an FDA Regulated Environment: Myth or Reality?” 19 describes two case studies from Roche Molecular Diagnostics that addresses the topic squarely. This collaboration uses the V-model noted earlier as the basis of its methodology. The success of one and the issues of another lead the authors to the statement: “Overall, we believe that success in a global collaborative software development project is not a myth and can be achieved when the team is committed to all aspects of the software development process, including regulatory compliance. We also emphasize the need for commitment of all people involved in these projects.”
The key component in successful projects is clear communication, commitment of the developers, and the adoption of solid engineering practices, whether the team is on the same floor or different continents.
The authors acknowledge that an open-source development project could be a stimulating undertaking, whether the controlled-development-extensible model or the distributed-engineering approach is used. Distributed development in a regulated industry is likely to become common as companies look to reduce development costs and take advantage of expertise not available locally. The key criteria for success are the adoption of sound engineering methodologies, effective communication, and dedication toward a successful outcome. Learning how to meet the challenges in doing work at the level of quality needed to meet the requirements of FDA, ISO, and others requirements are worth the effort.
The Next Steps
How do we proceed from here? Open-source projects (both hardware and software) are potentially valuable resources that can benefit scientists in their work. Turning that potential into reality is going to take effort including the following steps:
The development and publication of a formal methodology for the development of open-source projects that recognizes two points: that the end result will be used in a regulated environment (Food and Drug Administration (FDA), Enviromental Protection Agency (EPA), International Organization for Standardization (ISO), Good Laboratory Practice (GLP), Good Automated Laboratory Practice (GALP) and others) and the developers are required to help their users meet those requirements, and most of the users may not be programmers and systems designers, but competent users of products.
The organization of a community of users and developers who are committed to the creation of quality open-source hardware and software tools. One of the benefits of the open-source movement is the participation of people working to ensure that projects produce useful high-quality results. This process will take time, and commitment is needed to prevent the initial enthusiasm from waning as development takes place. Employers should support this effort because they will directly and materially benefit.
A trial project should be defined to start the process. The intent would be to produce a useful tool and to develop the needed methodology and community. One mechanism for starting this process is to use the Google group “Open Laboratory Automation,” 20 moderated by one of the authors, as a communications and organizational forum.
One aspect of this work needs further comment. The open-source movement has stated positions on public standards for data interchange and storage formats. Any development of laboratory software is going to involve the collection and storage of data. Part of the development effort should include the public discussion of data storage formats so that common data types (data from the same technique) are all stored according to the same specification. It is not enough to have an open format, we need to have an open and commonly used—standardized—format. This will slow down the process of development and add complexity to the initial process for a given technique. The results will be well worth the effort.
Open Laboratory Automation
The Open Laboratory Automation (OLA) project is a new initiative, founded by one of the authors of this article. The project has the aim to produce a software product capable of a controlled range of interconnected laboratory equipment. The group consists of a number of equipment manufacturers, laboratory scientists, and associated laboratory automation professionals.
The project is at an early stage and has undertaken a commitment to build an early prototype. This prototype will release an application that will control a plate-loading device to load up a small benchtop piece of equipment to dispense/read/seal a plate. The finished application and the associated code will be available for free. After this work, the OLA consortium will work toward a system to control many devices using a rich graphical user interface (GUI) and a scheduler to correctly time processes running on such a system.
You can find more information about Open Laboratory Automation at the following locations:
Open Laboratory Automation Google Group: http://groups.google.com/group/open-lab-automation
Sourceforge Project Site: http://sourceforge.net/projects/openlabauto
{kind=link}
“OASIS/ISO OpenDocument Format—using open standards to promote competition and close the digital divide,” OpenDocument Fellowship, October 2006.
Requirements of the U.S. Food and Drug Administration are noted extensively in this section because of the impact the FDA has on pharmaceutical, biotech, and other industries, and because its requirements are often used by other regulatory bodies and countries.
The reference to “medical devices” does not limit the scope of the discussion or the applicability of this material. The Federal Food, Drug, and Cosmetic Act provides a very broad definition of what constitutes a medical device, including software, so that adopting the regulatory guidelines for medical devices for a broader range of applications is a conservative approach.
“General Principles of Software Validation; Final Guidance for Industry and FDA Staff,” January 11, 2002, U.S. Department of Health and Human Services, FDA, Section 6.
“Guidance for industry, FDA reviewers and compliance on off-the-shelf software use in medical devices,” September 9, 1999, U.S. Department of Health and Human Services, FDA.
Ibid, section 2.5, page 11.
Ibid, section on “Reliability.”
DeSpautz, Kovacs, Werling. GAMP standards for validation of automated systems. Pharmaceutical Processing, March 2008, p 24. Note: some minor wording changes have been made for clarity.
Sam Boykin. With open-source arms. Scientific American, 2008, 299(4), 90–95.
Sudershana, S., Villca-Roque, A., Baldanza, J. Successful collaborative software projects for medical devices in an FDA regulated environment: myth or reality? In Proceedings of the International Conference on Global Software Engineering, 2007, pp 217–224.