
Abstract
We focus on gesture recognition based on 3D information in the form of a point cloud of the observed scene. A descriptor of the scene is built on the basis of a Viewpoint Feature Histogram (VFH). To increase the distinctiveness of the descriptor the scene is divided into smaller 3D cells and VFH is calculated for each of them. A verification of the method on publicly available Polish and American sign language datasets containing dynamic gestures as well as hand postures acquired by a time-of-flight (ToF) camera or Kinect is presented. Results of cross-validation test are given. Hand postures are recognized using a nearest neighbour classifier with city-block distance. For dynamic gestures two types of classifiers are applied: (i) the nearest neighbour technique with dynamic time warping and (ii) hidden Markov models. The results confirm the usefulness of our approach.
Keywords
1. Introduction
Hand gestures are a natural form of communication among people, and in contrast to devices such as joysticks or keyboards they remain intuitive, touchless, non-invasive means of human-computer, or human-robot, communication. However, despite decades of research in the domain, the hand operated devices are not commonly used in our daily lives since the currently developed systems offer reasonable reliability only in a controlled laboratory environment. The number and significance of constraints imposed on such systems is still important.
Nowadays, new devices such as time-of-flight (ToF) cameras or sensor Kinect that offer new possibilities have been developed. They provide 3D information about observed scenes but due to their specific nature they require new algorithms and processing schemes. This paper is related to the problem of hand gesture recognition using such cameras. We consider dynamic gestures representing sign language words, as well as hand postures representing letters of a finger alphabet. Dynamic gestures are relatively difficult to recognize because hands are not the objects nearest to the camera and/or they touch each other, touch the head or appear in the background of the face. Most of the hand postures characteristic for finger alphabets are also difficult to classify if only 2D projection of a 3D real scene is available (i.e., when a typical camera is applied). We propose using point cloud processing and VFH as the global descriptor of the scene. To increase distinctiveness of features based on VFH a modification is proposed which consists in dividing the observed area into smaller cells and calculating the VFH for each of them. In the case of dynamic gestures we assume that the person performing the gestures is the only object in the foreground; in the case of hand postures the active hand is assumed to be the object closest to the camera. Postures are recognized by a nearest neighbour classifier. For dynamic gestures two types of classifiers are used: (i) the nearest neighbour technique with dynamic time warping and (ii) hidden Markov models. The presented results confirm the usefulness of our approach.
The remaining part of the paper is organized as follows. Section 2 contains a brief overview of related publications. Section 3 discusses VFH calculation. Our approach to recognition of dynamic gestures is presented in Section 4. Section 5, in turn, considers recognition of hand postures from finger alphabets. Conclusions and future works are included in Section 6.
2. Related Work
In the literature on hand gesture recognition depth cameras are used in order to support hand segmentation, and as additional information incorporated into feature vectors describing extracted objects (e.g., [1–6]). Some authors assume that the hands are the objects nearest the camera [1, 2, 4–6]. In works [1, 4, 5] the depth data are thresholded creating a confined area between the camera and the body of the person performing gestures. Such an approach is limited to a set of gestures performed in front of the body, in the central region of the scene. For other gestures some parts of the forearm are also identified as a hand. A different approach can be found in [2], where the region growing method is used. The procedure starts from the point nearest the camera and expands the region, taking into account similar depth values. In this approach a stopping criterion for region growth has to be defined. Moreover, due to non-uniform spatial density of the captured points, the region expansion may stop too early, resulting in partially segmented hands. The distance between two adjacent points on the hand in 2D image can vary significantly depending on the hand orientation. Furthermore, the assumption that the hands are the objects nearest the camera is not always met. For certain gestures when the hand touches head, ear, nose, mouth, throat or chest, the wrist, forearm or elbow is the object closest to the camera. In [7] the hand is located based on the assumption that it is an end point of the human body. This assumption is not true when the hand touches other parts of the body or is not visible due to occlusion. An interesting approach is proposed in [3] where depth and colour cameras are used. The face is detected, its distance from the camera measured and used to remove the background by thresholding the depth image. The hands are identified by applying skin colour detection to the remaining pixels. Additional processing to remove the arms is required when the user is wearing short sleeves. In the cited work this is achieved by the assumption that the arm is underneath the hand. This is obviously not fulfilled for the gestures performed in the area of the stomach and waist.
Apart from the topic of hand gesture recognition there are also promising approaches for general action recognition (in the sense of type of human activity) [8, 9] using 3D data.
The ToF camera provides accurate and complex information about the spatial shape of the visible surface. In [2, 5] the 3D information is not added to the feature vectors. In [1] only the coarse information in the form of the hand geodesic centre and the minimum depth point is used. The depth images containing a lot of information about the hand posture are used in [3, 4]. The pixel-wise depth distance between the registered templates and the observed gesture is used in classification. This approach requires that the user's distance from the ToF camera is not greater than 1 m because of its low resolution.
An approach to recognize hand postures based on depth data is presented in [10] where finger regions are separated from the palm regions. For this purpose a central palm point is found using the fact that the region around it has the highest point density and performing the Gaussian blur. The feature vector used for recognition includes distances of the fingertips from the palm centre and from a plane fitted on the palm samples, curvature of the contour of hand region, as well as the shape of the palm region. In [11] the person performing gestures is required to wear a black belt on the wrist of the gesturing hand. Then the RANSAC method is used to locate the position of the belt and reject wrist fragments. Gesture recognition is performed based upon time series curves which describe the relative distance between each contour vertex to a centre point designated using the distance transform.
In work [12] the depth and colour information of observed pixels from Kinect are used to recognize 14 hand shapes useful for arithmetic operations and three shapes for a Rock-paper-scissors game. Kinect's depth images in [13] are applied to recognize nine gesture commands adopted in a Sudoku game. The authors propose an algorithm based on the depth information to identify the gesture. Kam et al. in [14] recognize eight hand gestures in real time, achieving an accuracy of over 99%. Li in [15] obtained 90% recognition rate for nine gestures. Hand postures representing American Sign Language (ASL) digits are recognized in work [16] with 99% recognition rate. Dynamic sign gesture recognition with Kinect's depth data can be found in [17, 4].
State-of-the-art approaches to gesture recognition use neural networks [5], hidden Markov models (HMM) [18], boosting [19], dynamic time warping (DTW) [20] or recently Latent Regression Forest [21] and Latent-Class Hough Forests [22].
Recently VFH - a new descriptor for 3D point cloud data-has been introduced [23]. It encodes the geometry and viewpoint of the surface and is robust to large noise and missing depth information. Moreover, it has been shown experimentally that the VFH can detect subtle variations in the geometry of objects even for untextured surfaces [23]. The main motivation of our work is to propose an approach which uses a descriptor based on VFH. To increase the distinctiveness of the descriptor, especially for the gestures with subtle differences in shape, we propose a modification which consists in dividing the scene into a number of smaller cells and calculating the VFH for each cell.
3. Viewpoint Feature Histogram
Point cloud is a data structure representing a multi-dimensional set of points [23, 24]. In a 3D cloud each point is described by its coordinates x, y, z. In a 4D cloud additional information about the brightness is available. Point clouds can be obtained using imaging devices, such as stereo cameras, 3D scanners, ToF cameras or sensors like Kinect.
Points in 3D space are expressed in a clockwise coordinate system centered at the intersection of the optical axis with the plane containing the front wall of the camera. The x-axis is horizontal and is directed to the left, the y-axis runs vertically and faces up, the z-axis coincides with the optical axis of the camera and is turned towards the object.
VFH is the global descriptor of the point cloud. It has been successfully used for object recognition and 6-DOF pose estimation [23]. The descriptor consists of two components: (i) a surface shape component, (ii) viewpoint direction component.
The first component collects values θ, cos(α), cos(φ) and | d | calculated for each pair of the points (pc,pi), where pc is the cloud gravity centre and pi any point belonging to the cloud (comp. Fig. 1). nc is the vector with initial point at pc and coordinates equal to the average of all surface normals. ni is the surface normal estimated at point pi. The vectors and angles shown in the Fig. 1 are defined as follows:

Calculation of the surface shape component of the VFH





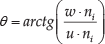
where dot (cross) denotes the scalar (vector) product of vectors. The viewpoint component is computed by collecting a histogram of the angles that the viewpoint direction makes with each normal. The number of points nn belonging to the neighbourhood used to estimate the surface normal at the query point is the method parameter. The details of the calculation are given in [23, 25, 26]. Computational complexity of VFH is quadratic with respect to the number of cloud points. Default descriptor consists of 308 values, 45 for each feature θ, cos(α), cos(φ), |d | and 128 for the viewpoint component.
4. Dynamic Hand Gesture Recognition
In this section our approach to dynamic hand gesture recognition is described. It consists of: (i) acquisition of depth images sequence for a given gesture, (ii) application of point cloud filters, (iii) calculation of VFH-based descriptor and (iv) designing and testing classifiers.
The proposed method was verified on Polish sign language (PSL) gestures. PSL signs are static or dynamic. Most of them are two-handed. For one-handed signs the so-called dominant hand performs the sign, whereas for two-handed signs the non-dominant hand is also used. Dynamic signs are both sequential and simultaneous. Sequentiality indicates that the order of shown hand shapes and places of execution is important. Simultaneity means that during gesture performance the features (e.g., hand position and shape) can be changed in parallel, although not necessarily in synchrony. The hands often touch each other or appear against the background of the face. Therefore, the recognition of dynamic gestures is a challenging task.
In experiments we used our PSL datasets containing gestures performed by an interpreter from The Polish Association of the Deaf. Gestures were acquired using a MESA Swiss Ranger 4000 camera [27] based on the time-of-flight principle [28] or sensor Kinect which uses infrared structured light to obtain depth data. For the ToF camera, 84 PSL words were repeated 20 times at three orientations of the gesticulating person with respect to the camera, respectively of −10°, 0°, 10°. Words are characterized by different speeds of execution (comp. Fig. 2), hands are often not the objects nearest the camera, they touch each other, touch the head or appear in the background of the face. Moreover, the orientation of the person with respect to the camera is variable.

Gesture length variation measured as the ratio stdev/mean
For Kinect, 30 words were repeated ten times. Our ToF and Kinect gesture datasets can be downloaded from http://vision.kia.prz.edu.pl.
4.1 Point Cloud Processing
In this work the Point Cloud Library (PCL) v. 1.6.0 was used [24]. First, the so-called pass through filter was applied. The input point cloud was filtered along the z-axis. Points we h aose z coordinate is greater than the assumed threshold were rejected. The threshold was selected to remove the background objects and extract the foreground object, e.g., person performing the gestures. For each point in the cloud some of ToF cameras provide the amplitude value which characterizes strength of the active illumination signal reflected by the object. These values form the amplitude image, that is acquired together with the cloud. Fig. 3 shows sample pictures obtained from ToF camera: an amplitude image and the projection of the point cloud on the xy plane. Kinect and newest ToF cameras provide colour images. The person's head position in the amplitude image was found using the Haar detector (Fig. 3 (c)) [29]. The z coordinate of the point corresponding to the head centre, considered as person distance from the camera, was increased by Δz and chosen as the pass through filter threshold. Δz is the method parameter. It was assumed that there is only one person visible in the frame and its position does not change during the execution of gestures. Therefore, the Haar detector was used only for the initial frames.

Sample amplitude image (a), input cloud projected on the xy plane (b), head segmentation in the amplitude image (c)
For Kinect the provided RGB image was used to find the person's head position. Colour image pixels were mapped to depth data using calibration parameters proposed at http://nicolas.burrus.name/index.php/Research/KinectCalibration, which in practical tests proved to be accurate. It is worth mentioning that Kinect depth data contain information if a given pixel belongs to the body posture, which helps with extracting such a posture from the background. Kinect also provides a so-called skeleton image with a 3D point indicating the position of the head. Since we wanted our approach to be camera independent we did not use extraction and skeletal data provided by Kinect. Pass through filter was applied here as well.
In the next step the radius outlier removal filter was used in order to reject sparse, noisy points, which may corrupt the results leading to erroneous values of local point cloud characteristics such as surface normals [24]. For each point of the cloud the spherical neighbourhood with radius r is defined. If the number of points in this neighbourhood is less than k the given point is rejected. The values r and k are the filter parameters.
The obtained cloud is then downsampled in order to reduce the number of points and to speed up further calculations. The so-called voxel grid filter is used [24]. This filter creates a 3D voxel grid over the input point cloud data. The physical dimensions of the voxel Vx xVy xVz are the filter parameters. Then, in each voxel (i.e., 3D box), all the points present are approximated with their centroid.
The following filter parameters were experimentally selected: Δz=20cm, r=10mm, k =3, Vx =Vy =Vz =10mm, nn=32.
Sample VFHs calculated for the selected frame from the gesture analysis observed by ToF camera and Kinect are shown in Fig. 4. ToF camera and Kinect work on a different principle, and therefore the acquired clouds and calculated VFHs differ (comp. Fig. 4 (c) and (d)). The cloud obtained using Kinect consists of more points (see Table 1). The significant reduction in the number of points, observed for ToF camera after applying the radius outlier removal filter, results from the large number of isolated points between background and foreground object (comp. Fig. 4 (e) and (f)). After applying the voxel grid filter the numbers of points become similar. Moreover, the ToF camera and Kinect were not set at exactly the same place. This resulted in a difference in the shape of the viewpoint component.
Number of points belonging to the cloud at different stages of processing the clouds shown in Fig. 4


Depth images (a), (b), VFHs (c), (d) and side views (e), (f), generated from the point cloud registered with ToF camera (left column) and Kinect (right column)
4.2 Recognition Techniques
Recognition is based on feature vectors. Here, however, the feature vectors form a time series, which can have different lengths even for the same gesture (comp. Fig. 2). Thus to compare discrete sequences we use dynamic time warping (DTW) [30], which allows a non-linear mapping of one sequence to another by minimizing the distance between them. Another motivation for using DTW is its ability to expand or compress the time scale, which makes it possible to compare sequences that are similar but locally out of phase. For example, some related parts of gestures representing the same expression may be performed with different velocities. Given two time series Q ={q(1),q(2),…,q(Tq)} and R = {r(1),r(2),…,r(Tr)} DTW aligns the two series so that their difference is minimized. To this end, a Tq xTr matrix, where the (i, j) element of the matrix contains the distance d(q(i),r(j)) between two points q(i) and r(j), is considered. Usually the Euclidean distance is used. A warping path, W=w1,w2,…,wK where max(Tq,Tr) ≤ K ≤Tq + Tr-1, is a set of matrix elements that satisfies three constraints: boundary condition, continuity and monotonicity. The boundary condition constraint requires the warping path to start and finish in diagonally opposite corner cells of the matrix. That is w1 = (1,1), w
K
= (T
q
T
r
). The continuity constraint restricts the allowable steps to adjacent cells. The monotonicity constraint forces the points in the warping path to be monotonically arranged in time. The warping path that has the minimum distance
To recognize dynamic gestures we also investigated hidden Markov models (HMMs) [18, 32]. Human hand gestures are performed in a spatio-temporal domain, i.e., a hand changes its shapes and positions in a predefined order. Gesture execution is usually not perfect and may vary depending on e.g., mood or purpose. The same person may perform a given gesture with different speed and accuracy. Human performance involves two distinct stochastic processes: human mental states and resultant actions. The mental state is immeasurable, the action is measurable. Therefore, many researchers use HMMs to recognize hand gestures. An HMM is a statistical model used to characterize the statistical properties of a signal. The model consists of two stochastic processes: one is unobservable Markov chain with a finite number of states, an initial state probability distribution and a state transition probability matrix; the other is a set of probability density functions associated with observations generated by each state. HMM training consists of an estimation of models' parameters with the help of observation sequences. Estimation can be solved using the expectation-maximization method (Baum-Welch technique [32]). This tries to find a stochastic process, HMM, which generated observation sequences. The recognition step returns a class represented by a model which gives the highest probability of generating a recognized sequence. This is done using the Viterbi algorithm.
Finally, two classifiers of dynamic gestures were used: (i) the nearest neighbour classifier, (ii) the HMM classifier. The first classifier indicates the sought class by a pattern closest, in the DTW sense, to the recognized gesture represented, say, by a time series Q. The second one shows the sought class by a model Λ which gives the highest conditional probability P(Q | Λ) on the set of known HMM models. We used HTK software [33] to design the HMM-based models. HTK is designed for building HMM-based speech processing tools, but it can be used to model any time series since the core of HTK is similarly general purpose. We experimentally found that each gesture from our database can be represented by one state HMM with Gaussian output.
Despite the known HMM advantages (e.g., their generalization abilities), which are proved to be superior to the nearest neighbour (NN) technique with DTW distance, we decided to run recognition tests using both approaches since DTW is in many cases of sequences modelling a classifier of the first choice. The main reason is its simplicity. DTW in its base form, i.e., without constraints, is a non-parametric technique, and the nearest neighbour classifier does not require any training nor modelling, which with the HMM approach are inevitable. The NN classifier is sensitive to noise, and if the results obtained with its use are weaker than for better generalizing techniques, it could indicate large intra-class variance characterizing a good dataset.
4.3 Experimental Results
Since VFH consists of 308 values we decided to represent each feature using its mean and standard deviation to avoid problems with higher dimensionality. Then, in order to find the best, in the sense of recognition efficiency, feature combination we run tests for all possible feature combinations. The experimentation led to the conclusion that using features based on a histogram of cos(α) and on a histogram of |d| gives the best result.
Fig. 5 shows depth images and corresponding to VFH descriptors for two sample scenes. The VFH descriptors look very similar, although the hands present quite different gestures. The observed similarity may cause recognition problems, since the classifier would not be able to differentiate between some gestures' executions from different classes. To run classification tests gestures were divided into ten disjoint subsets of equal sizes. We performed ten-fold cross-validation tests in two variants: in the first variant (A) we used nine subsets as the training set and the remaining subset as the test set, in the second variant (B) the training and the test set were swapped. In the (B) variant the number of training examples was too small to train HMM using HTK, and thus they were shown several times. The results are given in Table 2. Recognition rate [%] is considered as the number of correctly recognized words [%] from the test set. Features (i.e., means and standard deviations obtained from VFH) were independently normalized to the range [0,1], maximum and minimum values were determined on the basis of the training set.
Ten-fold cross-validation recognition results. VFHs are calculated for the entire cloud. Recognition rates are given in %.

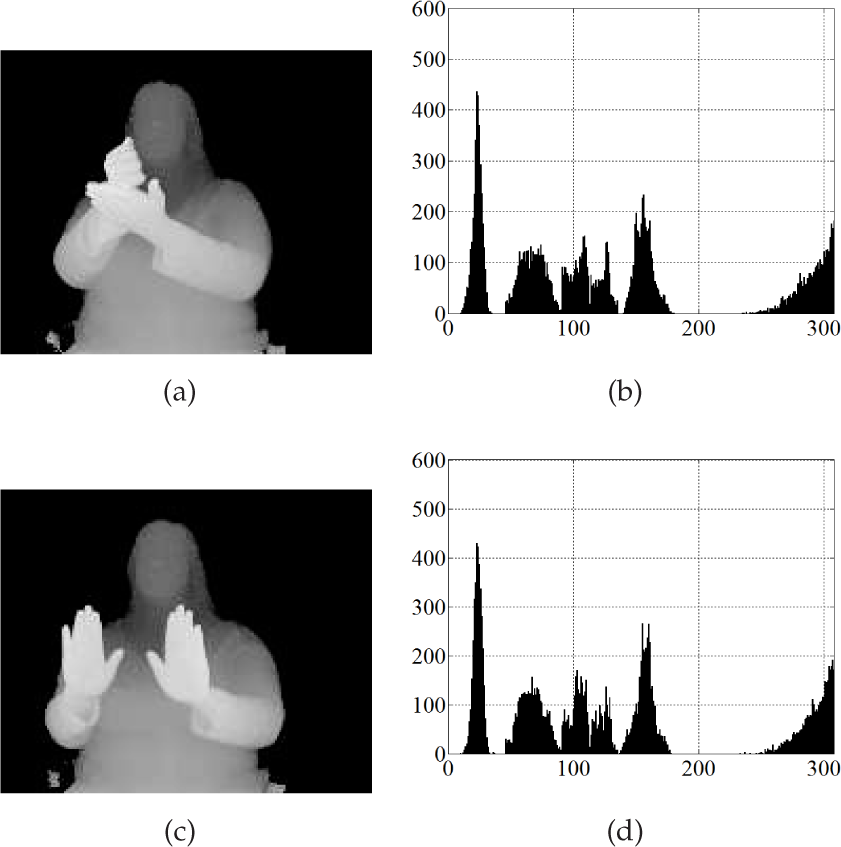
Depth images (a), (c) and corresponding VFH descriptors (b), (d) for two gestures
The mean values of the obtained results indicate the existence of recognition problems, in particular for the NN classifier, which does not have good generalization properties in comparison with HMM-based classifier and is very sensitive to outliers. Some gesture's executions were misclassified due to their resemblance to gestures from other classes and even for correctly recognized signs the distance to the closest, in the DTW sense, execution from other classes was not significant. Therefore to increase the distinctiveness of the classifier we propose to enhance the description of the scene. The modification consists in dividing the user's work space into smaller cells (Fig. 6). Then, the point cloud fragments belonging to the individual cells are treated as independent clouds and described using VFHs. Such modification resembles to some extent a division of the image into several regions using a popular histogram of oriented gradients (HOG) [34] descriptor to improve recognition rate.

Dividing the userd's work space into so m ttaller cells labelled a to i

Depth images of some gestures from our dictionary shown at the beginning, in the middle, and at the end of execution
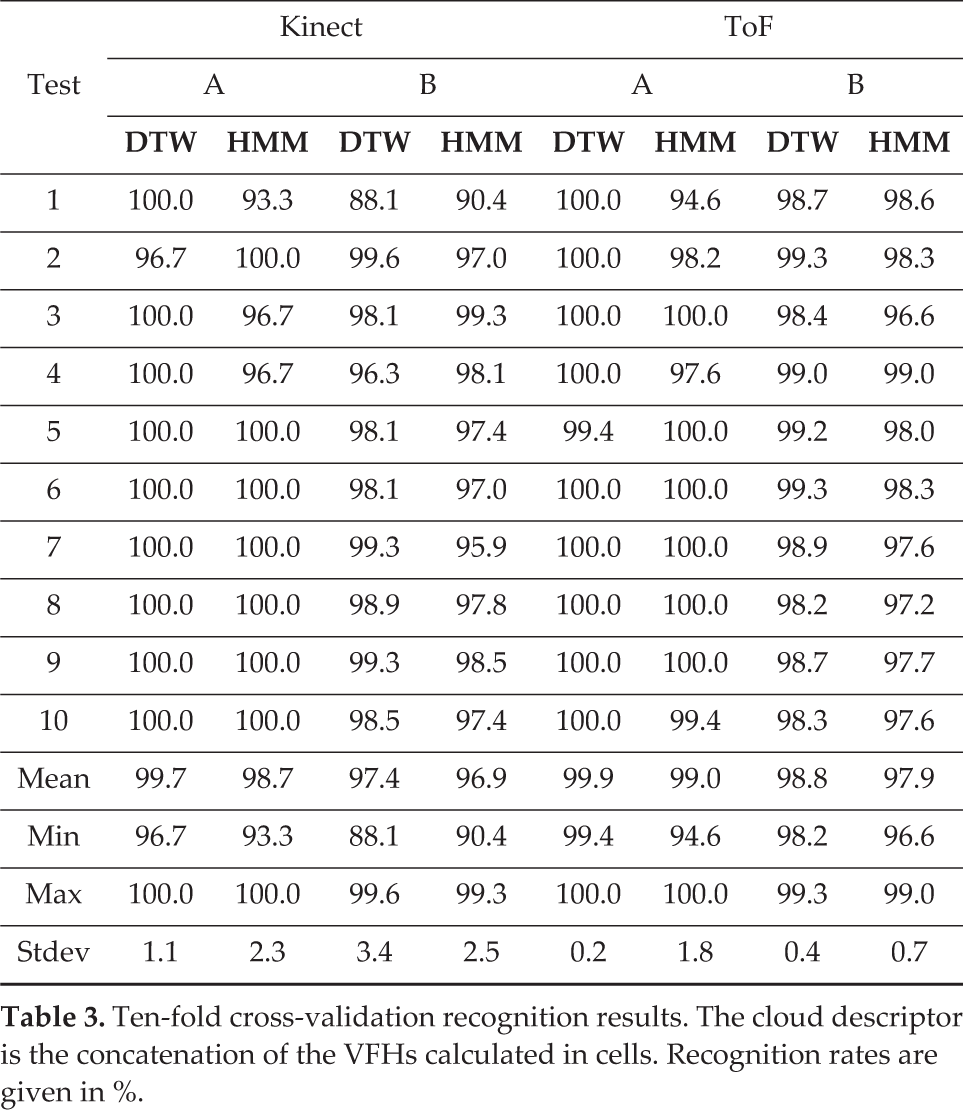
Finally the resulting descriptor is created by the concatenation of VFHs calculated for cells. Concatenation was made from left to right and from top to bottom. The user's work space is defined in 3D as the smallest possible cuboid, which includes all the clouds belonging to the training set. Ten-fold cross-validation tests were run to prove our assumptions. Results are given in Table 3.
Ten-fold cross-validation recognition results. The cloud descriptor is the concatenation of the VFHs calculated in cells. Recognition rates are given in %.
Our approach seems not to be invariant to rotation since some parts of the gesture could be moved between neighbouring cells. Therefore, additional tests were run with gestures performed by a person slightly rotated relative to the camera based on a training set containing only the gestures shown directly in front of the camera. The obtained recognition rates are 86.1% and 75.5% for the rotation of −10° and 10°, respectively. In this case the recognition errors occur for the certain gestures only, and almost all executions of these gestures are misclassified. For rotation of 10° mostly one-handed gestures are incorrectly recognized. Most frequently the gesture to ache was recognized as to feel. For rotation of −10° some two-handed gestures begin to resemble other gestures, e.g., analysis and family. The mentioned gestures are visually very similar (comp. Fig. 4). Further rotation can hide certain details relevant to their recognition. For the gesture to ache the fingers can be folded back from the body, or obscured by the palm, depending on the direction of rotation. At some stage of the gesture analysis, the rotation may slightly turn the inner part of the hand towards the camera, resulting in similarity to the gesture family.
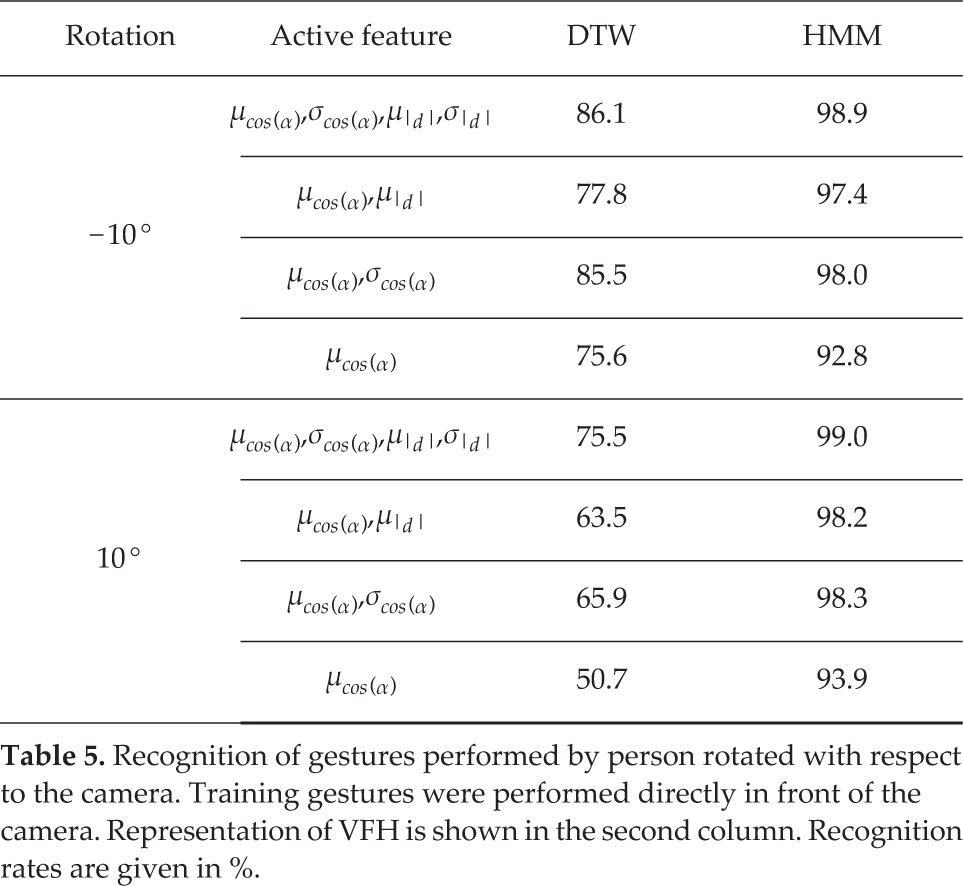
Results presented in Table 3 were obtained for the case when VFH is represented by mean of cos(α) (μcos(α)), standard deviation of cos(α) (σcos(α)), mean of | d | (μ|d |), and standard deviation of | d | (σ|d |). Some combinations of these features also lead to comparable results (see Table 5). However, the selected feature vector (μcos(α), σcos(α), μ|d |, σ|d |) seems to be less sensitive to the orientation of a person relative to the camera (see Table 6).
Summary of ten-fold cross-validation recognition tests. Representation of VFH is shown in the second column. Recognition rates are given in %.

Recognition of gestures performed by person rotated with respect to the camera. Training gestures were performed directly in front of the camera. Representation of VFH is shown in the second column. Recognition rates are given in %.
Results (given in %) of cross-validation tests on PFA dataset (active features:

The HMM-based classifier yielded significantly better results compared to the nearest neighbour technique with DTW in the case where the entire cloud was processed (see Table 2). It also better classified gestures performed by a person rotated relative to the camera. Moreover, it appears that these slight changes of orientation with respect to the camera almost do not affect the recognition efficiency.
The point clouds recorded at 50 frames/s for the ToF camera and 20 frames/s for the Kinect sensor were processed off-line. On an ordinary PC (i7, 3.4 GHz, 12 GB RAM, Windows 7 64 bit) the single cloud processing time was approximately 100 ms for the ToF camera and 170 ms for the Kinect sensor for the nine cells case. The recognition time did not exceed 15 ms for the DTW-based classifier and 1.5 ms for HMMs.
It may seem interesting that quite good classification is obtained using one-state HMMs with normal distributions of observations. Experiments were also carried out with two-state Bakis HMMs and normal observations, as well as with one-state HMMs and mixtures of two Gaussians. In the first case the results turned out to be worse; in the second the results were comparable with those presented in this section. It is worth noting that the observation vectors contain 36 elements, i.e., four VFH-based features are associated with each of the nine spatial cells. Such a description turns out to be distinctive, and differentiates the variability, both in time and space, of observations corresponding to investigated gestures. This allows the application of simple Markov models.
5. Hand Postures Recognition
Hand posture recognition using our approach was evaluated on three datasets: (i) Polish finger alphabet (PFA) database acquired in our laboratory, (ii) American sign language finger-spelling database [35] and (iii) postures of American sign language letters found in [36]. Consecutive steps of our approach are similar to the dynamic gesture recognition considered in Section 4. The main difference is that here the hand is extracted. This is a rough extraction in the sense that we get a cuboid with fixed dimensions, including an appropriate point cloud, and it is based on observation that the hand is the object closest the camera. Relevant details are presented in the subsections below.
5.1 Polish Finger Alphabet Dataset
Polish sign language contains a set of hand postures performed with the right hand located about 20 cm from the face, forming a so-called finger alphabet. Finger alphabet is commonly used for spelling words for which there is no sign in the sign language dictionary, i.e., proper nouns, acronyms, and loanwords. Some letters (symbols) are similar to each other leading to possible recognition problems. Our research involves the classification of hand postures on the basis of hand shape analysis. The shapes occurring in the finger alphabet are complex, since fingers often occlude each other and therefore some symbols observed as two-dimensional projections become ambiguous. For example, postures ‘O’, ‘S‘, ‘T’ differ only in thumb position related to other hand elements. This justifies the use of a three-dimensional approach. Sixteen recognized postures are presented in the Fig. 8, and each was executed 20 times by three subjects (960 executions in total) - datasets can be downloaded from http://vision.kia.prz.edu.pl. The postures' executions have a variable orientation, position relative to the camera, and differ in the arrangement of fingers and thumb as one can see on Fig. 9.

Chosen PSL hand postures (left side) and corresponding depth images (right side)

Depth images of some executions of ‘T’ (top) and ‘U’ (bottom) postures
The first step of the PFA postures recognition based on point clouds was filtration. First, we used a pass through filter in order to reject points located outside the so-called gesticulation area of a cuboidal shape. The user should place his whole hand and a small part of the forearm in the gesticulation area. The boundaries of this area were set to constant values. The presence of the head in the image could help to define this area, but it was not the case in most data used here. The depth images shown in Fig. 8 correspond to cloud parts located within the gesticulation area. The next step of filtration was to reject isolated points whose number of neighbours in a given radius r does not exceed the threshold value k. For this aim we used the radius outlier removal filter described in Section 4.1. Then, we performed downsampling of the point cloud - with the use of the voxel grid filter. If the number of points of the obtained cloud exceeded some given threshold value, the cloud was subjected to classification. We have noticed that the quality of filtration, which obviously affects the correctness of the classification, strongly depends on the parameters of filtration methods. To set the configuration of filtration parameters we applied the genetic algorithm, maximizing the number of correctly classified postures in a ten-fold cross-validation test. Optimal values of the parameters are as follows: r = 0.20674, k = 8, Vx, Vy, Vz = 0.00439, nn = 44. We used the nearest neighbour classifier with the city-block distance.
In order to create a VFH descriptor of postures a cuboidal area around the filtered point cloud must be defined. The boundaries of this area, hereinafter referred to as the work space, were determined by the points placed furthest in each direction (xMin, xMax, yMin, yMax, zMin, zMax). In this way, its size is matched to the size of the filtered cloud embracing it entirely with no spaces from the boundaries. This is relevant because the hands of people performing gestures may have different sizes. Additionally, we have to ensure that too large a point cloud fragment corresponding to the forearm is not included in the work space. We checked that hand height is the greatest while performing the ‘B’ gesture and we denoted this value as bh. Then bh of the person showing postures was measured. An obtained value of 20 cm was set as a maximum height of the work space wshmax. However, we found that while showing relatively high hand postures only a fragment of a hand of height 15 cm (0.75*bh) measured from the tip of the longest finger is relevant to the classifier, which was confirmed by further experiments. Thus, in order to minimize the forearm area included in the work space for the gestures of relatively small height, we assumed that wshmax = 15 cm. If the point cloud placed in the gesticulation area has a height greater than wshmax, then the work space is shortened from the bottom so that its height becomes equal to wshmax. Human hands have a variable size but their shape and proportions are very similar. It is therefore advisable for a PFA recognition system to ask the user at the beginning of the work with the system to present the letter ‘B’ in a fixed position in order to measure his or her bh. To provide high accuracy, the hand should be measured from the tip of the middle finger to the lower end of the wrist bones. Then, the system should set the value of wshmax in proportion to bh: wshmax = 0.75 * bh.
The created work space was then divided into nine equal cuboidal cells, and for each of them the VFH was calculated. Three sample filtered point clouds placed in the gesticulation area with the work space are shown in the Fig. 10. We also considered the cases when: (i) the single VFH was calculated for the entire work space, i.e., without dividing it into cells (ii) the work space was divided into three horizontal cells, (iii) the work space was divided into three vertical cells. Such work spaces can be less orientation-and-articulation-dependent. However, particular histograms calculated for each cell can be less distinctive. In the experiments we used three feature vectors consisting of mean and standard deviation of different combinations of VFH values: |d|+θ, |d|+cos(α), |d| + cos(φ). For example, |d| + θ denotes a feature vector including the following features: μ|d|, σ| d|, μθ, σθ. In the cases with divided work space, the mentioned features were calculated for each cell. For example, in the case of nine cells, the feature vector contained a total of 36 (9*4) features. The combination |d | + cos(φ) turned out to be the best for the recognition of PFA so we present results for these features only (see Table 7). The best recognition rate is 96% which was obtained for the (iii) case. Confusion matrix for PFA postures is presented in Table 8. As one can see, some executions were not correctly recognized. The ‘T’ letter was frequently confused with ‘O’. This is due to the significant similarity of these letters. Some of the other noticed mistakes can also be explained by the similarity, which becomes particularly evident in the less precise execution or setting the hand with respect to the camera. There were a few other mistakes, like confusing ‘U’ with ‘E’. Analysing the nine cells case, we found that such mistakes probably happen due to the significant difference between σcos(φ) for two of the lower cells of the classified ‘U’ and other shown ‘U’ letters. Improving the method of calculating work space boundaries, which would therefore lead to more accurate removal of forearm points, could eliminate such mistakes.
Confusion matrix with numbers of classified PFA postures' executions (cross-validation test with three vertical cells)

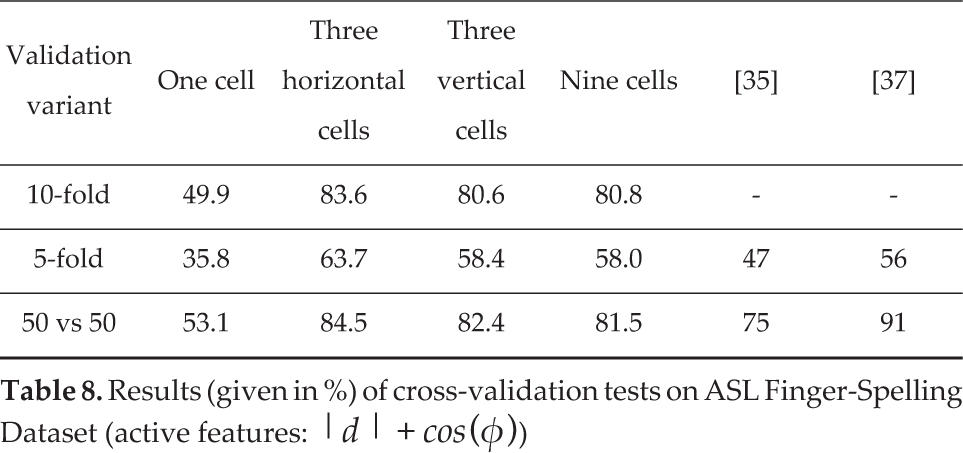
Results (given in %) of cross-validation tests on ASL Finger-Spelling Dataset (active features:
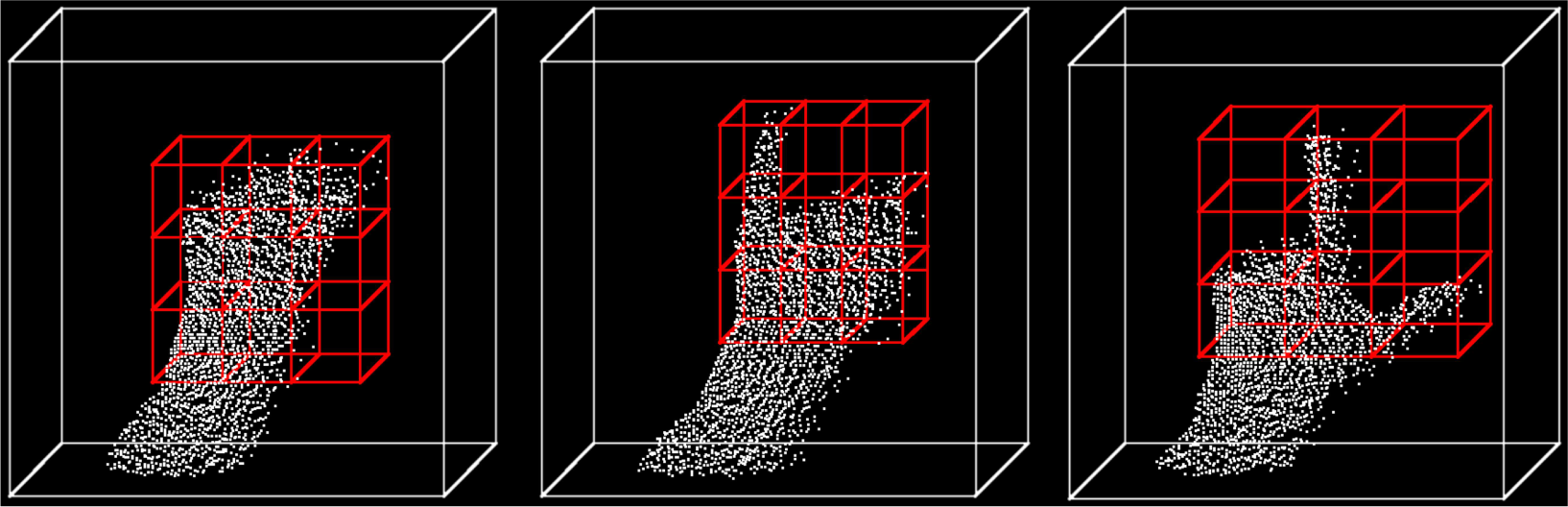
Point clouds placed within the gesticulation area (white edges) with the work space divided into nine cells (red edges). Postures: ‘A’ (left), ‘I’ (middle) and ‘L’ (right).
For the nine cells case the single cloud processing time was between 13 and 33 ms. The recognition time did not exceed 0.3 ms.
5.2 American Sign Language Finger-Spelling Dataset
Our method was evaluated on a dataset provided by [35]. It contains letters of American sign language finger alphabet, which similarly to PFA has strict rules of how one should show a given symbol (letter). This rules impose many restrictions on a hand, among which hand should be kept steady in one point in space maintaining the same orientation with minimal changes. Database contains 65000 hand postures of 25 letters performed by five subjects and acquired by Kinect. We have converted depth maps to point clouds. Authors of the dataset ignore the letters j and z as they involve motion. In this dataset neighbour clouds seem to be captured one after another within a short time. Thus, in our experiments we used only 100 realizations for each person and each gesture, beginning from the file with number 100 and considering only the numbers divisible by four. The offset from beginning was caused by accidentally captured head images which remain in the dataset.
In order to perform hand segmentation, the previously proposed method of calculating gesticulation area boundaries cannot be used because hands are not located at similar distances related to the head's position. However, we have noticed that in gestures' executions the hand is the object nearest to the camera. It provides an opportunity to set the gesticulation area's front face centre gfc as the point nearest to the camera. Good quality of this dataset and the fact that particular clouds correspond only to a small part of scene containing hand allow us not to use outlier removal filters as well as thresholding along x and y axis. Therefore, for the first step of filtration we calculated gfc and applied the pass through filter rejecting points whose depth was greater than gfcz + 10 cm. Then we used the voxel grid filter to downsample the clouds. The work space boundaries were calculated in the same manner as for PFA postures. bh values were estimated for each person based on ‘B’ letter, which is similar to the letter ‘B’ from Polish finger alphabet.
The evaluation of our method on this dataset was performed by 10-fold and 5-fold cross-validation tests with the same classifier as described in previous subsection. In the five-fold tests, letters shown by subjects from the test subset were not present in the training subset. Table 5.2 presents the results only for the best combination of features: | d | +cos (φ). The filtration and VFH 0 calculation parameters for these tests were set as follows: Vx, Vy, Vz = 00.00439, nn = 48.
In [35] hand shape features were based on Gabor filtering of the intensity and depth images. For classification authors used multi-class random forest and performed a validation test where half of the dataset was used as a test set and another half was used for training the classifier (the 3 ‘.50 vs 50’ case). We also compared our results with results reported in [37]. In this paper the authors used a method based on Gabor filtering and SVM classifier. As one can see, the results obtained using our approach in five-fold validation test, which also examines classifier ability to generalize over unseen subjects, outperform other works. Division of the work space into three horizontal cells proved to be useful.
5.3 American Sign Language Postures Dataset
We also evaluated our approach using the dataset provided by [36] which contains American Sign Language finger alphabet postures shown in a manner not preserving strict f 0 ger-spelling rules regarding stable hand position and orientation. Ten hand postures are repeated ten times by 14 subjects (14000 executions in total). We have converted depth maps acquired by Kinect to point clouds. This dataset is very challenging for our method, since orientation, scale and articulation of hands differ significantly, as can be seen in Fig. 11.

Colour images corresponding to depth maps from dataset [36]. Diversity in performances of posture ‘G4’.
The gesticulation area was set in the similar manner to the subsection above. However, while processing this dataset we had to ensure that in every case gfc belongs to the hand. Thus, we performed initial thresholding along the y-axis that removes points corresponding to the desk and small objects placed on it. We then used voxel grid and radius outlier removal filters to reject isolated artefacts that may contain points incorrectly classified by Kinect as being relatively close to the camera. Having gfc coordinates that certainly belong to the hand, we calculated the gesticulation area boundaries gax, gay and gaz as:
We experimentally found and set values of gawidth, gaheight and gadepth as follows: gawidth =gaheight = 36 cm and gadepth = 10 cm.
Obtained gesticulation area boundaries were used as parameters of the pass through filter. The work space boundaries were calculated in the same manner as for PFA postures with bh values estimated for each person based on ‘G9’ posture, which is similar to the letter ‘B’ from PFA.
To evaluate our approach on this dataset, we performed ten-fold cross-validation tests using the same classifier that was used with our data. We also applied 14-fold cross-validation in a way that gestures' executions of subjects from the test subset were not present in the training subset. The filtration and VFH calculation parameters for these tests were experimentally set as follows: r = 0.20674, k = 8, Vx, Vy, Vz = 0.00439, nn = 48. Table 5.3 presents the results only for the best known combination of features: |d|+cos(k).
Results (given in %) of cross-validation tests on ASL Postures Dataset (active features:

As one can see, the best results were obtained for the three horizontal cells case (82.8% for ten-fold cross-validation and 77.4% for 14-fold cross-validation). This can be explained by the fact that, when the fingers are usually facing up, such work space is less dependent on the orientation around the z-axis than the three vertical cells, whereas the postures' executions in the ASL dataset seem to be rotated around the z-axis to the greatest degree (compared to other axes). The one-cell case yielded the worst results, presumably due to the fact that the improvement of rotation-invariance, compared to cases with divided work space, is insufficient to compensate for the loss of VFH distinctiveness. In general, the results for this dataset, considering the large variety of performed gestures, are promising, although [36] reports better performance also presented here in Table 5.3. In [36] the hand is extracted from the acquired depth and colour data and two different types of features: curvature C and correlation R are computed from the 3D points corresponding to the hand. Some details of the approach are also given in [10] mentioned in Section 2. In contrast to our approach, these require a more-detailed analysis of hand shape.
6. Conclusions and Future Work
In this paper we propose using point cloud processing and the Viewpoint Feature Histogram as the global descriptor of the scene. To increase the distinctiveness of the descriptor a modification is proposed which consists in dividing the working space into smaller cells and calculating the VFH for each of them. The method is evaluated on publicly available Polish and American sign language datasets containing dynamic gestures, as well as postures acquired by a ToF camera or Kinect. The dynamic gestures are relatively difficult to recognize because hands often are not the objects nearest the camera and/or they touch each other, touch the head or appear in the background of the face. The shapes occurring in finger alphabets are also complex. Fingers often overlap each other, and therefore some symbols observed as two-dimensional projections become ambiguous. Results of ten-fold cross-validation are given. Hand postures were recognized by a nearest neighbour classifier. For dynamic gestures two types of classifiers were considered: (i) the nearest neighbour technique with dynamic time warping and (ii) hidden Markov models. The results confirm the usefulness of our approach. The method has several advantages. The hand segmentation process, problematic for many of the considered gestures and dependent on lightning, background and clothing is not required for dynamic gesture recognition. The method does not require colour information of the observed scene. The background can be non-uniform and dynamic provided that the person performing gestures is the object closest to the camera. There is also no need to wear special long-sleeved clothes. When using the ToF camera, the method is independent on lightning and may even work in a completely dark room. The use of 3D cameras imposes also some restrictions. For the Kinect, the results can be worse when strong sunlight is directed towards the camera. For the ToF camera, glossy materials and objects away from the camera by more than a certain threshold should not be present in the scene.
The approach requires further research. Dividing the work space into cells, and considering various classifiers as well as the processing time are exemplary interesting problems. Future work in the area of finger alphabet recognition based on point cloud information includes the development of more effective methods for rejecting points belonging to the forearm, which may improve the effectiveness of classification. Recognition of hand postures under a variety of hand orientations seems to be another interesting direction for research. The applied approach is not rotation/orientation invariant. Problems with slight differences with respect to the preferred orientation (of the signing person or the hand) can be solved by extension of the training set. One form of classification could be to apply the PCA and eigenspaces [38, 39] of the cloud of points to get the cloud orientation.
Footnotes
7. Acknowledgements
This article is a revised and expanded version of a paper entitled Recognition of Dynamic Hand Gesture Observed by Depth Cameras presented at Workshop on Real-Time Gesture Recognition for Human Robot Interaction, IAS-13 13th Intl. Conf. on Intelligent Autonomous Systems, pp. 354-359, Padova (Italy) July 15-19, 2014.
The authors thank the anonymous referees for their valuable comments and suggestions which helped to improve the article.