
Abstract
The appearance model has been shown to be essential for robust visual tracking since it is the basic criterion to locating targets in video sequences. Though existing tracking-by-detection algorithms have shown to be greatly promising, they still suffer from the drift problem, which is caused by updating appearance models. In this paper, we propose a new appearance model composed of ranking middle-level patches to capture more object distinctiveness than traditional tracking-by-detection models. Targets and backgrounds are represented by both low-level bottom-up features and high-level top-down patches, which can compensate each other. Bottom-up features are defined at the pixel level, and each feature gets its discrimination score through selective feature attention mechanism. In top-down feature extraction, rectangular patches are ranked according to their bottom-up discrimination scores, by which all of them are clustered into irregular patches, named ranking middle-level patches. In addition, at the stage of classifier training, the online random forests algorithm is specially refined to reduce drifting problems. Experiments on challenging public datasets and our test videos demonstrate that our approach can effectively prevent the tracker drifting problem and obtain competitive performance in visual tracking.
Introduction
Visual tracking plays a key role in a variety of practical fields, such as autonomous robot systems, human-robot interaction, driver assistance, security surveillance and so on. Despite tracking having drawn much attention in research, serious problems still exist in realistic applications. Scale, pose and illumination changes confuse the tracker, while background clutters and occlusion from other objects distract the tracker. Most state-of-the-art models of object tracking mainly focus on two aspects [1], object representation (i.e., object model) and mode seeking. Object representation describes the basic criteria of mode seeking, hence helps to locate candidate targets in videos. Recently, tracking-by-detection models, which formulate tracking as a binary classification between targets and background, have shown great promise in state-of-the-art frameworks [2,3,4]. Such methods involve the continuous detection in individual frames and the association of detections across frames. In contrast to background modelling-based trackers, they are generally robust to changing background and moving cameras. However, the existing challenge of such models when applied to real-world scenarios is the unavoidable drifting problem. That is, when learning a new model to adapt to appearance change and to maintain model plasticity, the model stability would be reduced. Hence, the distinctiveness of an appearance model is very important for improving tracking efficiency against the drifting problem.
Grabner proposed an online boosting algorithm to generate strong classifiers as a tracker, in which bottom-up features (e.g., colour, orientation, intensity, etc.) were not considered in the appearance model [2]. Another work, called Ensemble Tracking [3], proposed to embed diverse feature vectors in an Adaboost framework to formulate an object/background appearance model. Its drawback was that several heterogeneous cues were merged in the same subspace. Penne et al. improved a modular version of Ensemble Tracking combined with a Markov Chain Monte Carlo particle filter [5]. This indicated the necessity to find the optimal combination of feature configuration that improves the tracking process. Grabner et al. [6,7] used semi-supervised online boosting to alleviate the drifting problem. Babenko et al. introduced multiple instance learning to describe and locate targets in videos where a bounding box including the object was considered as a positive bag and others as negative ones [8]. Supancic et al. [9] used self-paced learning to select reliable frames from which to extract additional training data. In this way, they obtained a good appearance model. They also proved that an appearance model is more effective than a strong motion model. Tang et al. proposed a discriminative ranking list tracker which constructed a pair of different scale models, and alleviated the distraction from backgrounds[10]. Their ranking lists were gained according to K-NN with Euclidean distance metrics. For comparison, our ranking middle-level patches are based on a totally different mechanism where our ranking metric is composed of discrimination scores.
In summary, aforesaid models mainly used top-down cognitive attention (e.g., faces, humans, etc.) to represent a target. They ignored the bottom-up features (e.g., colour, orientation, intensity, etc.) which are highly discriminative for individual objects. Therefore, their models are not discriminative enough and models drift easily. In contrast, some works provided tracking models based on salient bottom-up features [11–14]. Although they obtained compelling results, they lagged behind primates' performance in real scenes. For example, primates can recognize a person and track it when the person isn't salient but is meaningful from backgrounds, while the above methods cannot realize that using only bottom-up features. The reason for the gap largely lies in the role of top-down features [15]. Hence, it will be beneficial to combine top-down and bottom-up features for constructing models and reach primates' performance on object tracking.
In this paper, we propose a novel framework by integrating high-level top-down and low-level bottom-up features to boost the distinctiveness of the appearance model. For high-level top-down features, large-scale patch-wise features are extracted because they contain more appearance information than pixel-wise features. However, their sparser distribution and lower sensitivity than pixel-wise features, result in their disadvantage of lower location accuracy [16]. Therefore, low-level pixel-wise features are extracted to compensate for these drawbacks. More importantly, selective feature attention is utilized to determine feature scores in bottom-up spaces according to the discrimination ability that best separates the target from backgrounds. These scores are used to linearly weight corresponding top-down patches. As a result, rectangular top-down patches are clustered into irregular ranking middle-level patches. Our discriminative appearance model is described by these ranking middle-level patches, and treats tracking as a three-class classification problem, as shown in Figure 1.

Framework of our tracking-by-detection algorithm
In tracking-by-detection methods, another key part is how to train and maintain the classifier. Random forests (RFs) [17] and their melioration [6] have attracted considerable attention in computer vision for their excellent characteristics, such as they are more robust to noise than Adaboost [18], paralleled easily, not prone to overfitting and so on [19]. Hence, online random forests (ORFs) are adopted as our basic classifier for their inherent multi-class property. Additionally, online gradient boosted regression trees (GBRT) is novelly utilized to reduce the current residuals in gradient direction, in order to refine the training errors of RFs classifier.
The remainder of this paper is organized as follows, Section 2 describes the proposed appearance model with top-down and bottom-up features. The online refined random forests classifier is presented in section 3. Section 4 details extensive experiments on challenging public datasets and test videos recorded by us on a mobile robot. Finally, we come to conclusions and discuss possible extensions in section 5.
Our goal is to obtain a discriminative target appearance model. The whole framework of our method is shown in Figure 1. Firstly, target tracking is determined by hand in frame t, and bottom-up features and top-down patches are based on this. Selective feature attention calculates the scores of bottom-up feature spaces according to discrimination ability of the features. Then, three kinds of ranking middle-level patches are derived to be used to train our refined random forests classifier as samples. To adapt to appearance changes, an online learning algorithm is adopted to update the refined random forests classifier. The trained classification model recognizes the target from backgrounds on frame t + 1, updating the samples of the target and its backgrounds at the same time. Finally, we come to run mean-shift [20] to identify the peek of the classification result (confidence map), i.e., location of the target. The tracking procedure repeats frame-by-frame. The collaboration of three-class ranking middle-level patches and online refined random forests is the key technique of our proposed method.
Visual Feature Spaces
Traditionally, intensity, orientation and colour can be used for saliency estimation [21]. In this paper, our bottom-up features also include other features which have shown correlation with bottom-up visual attention and have underlying biological plausibility.
For human-robot interaction and visual surveillance, faces (human or animal) can easily draw primates' attention. Hence, two excellent goal-driven, top-down cognitive features are adopted into our feature spaces.
Dalai, who proposed HOG, believes that an object can be represented by the statistics of the local edge directions [24]. In our method, edges are divided into eight directions. Each patch is represented by a 40-dimension vector composed of five 8-bin histograms. Haar-like features are boosted by classifiers, as proposed in [2].
Selective Feature Attention Mechanism
The efficiency of tracking depends on the discriminative ratio between the target and its backgrounds [13]. Tracking a person in red cloth under the sun is very easy due to its salient colour. However, it is very difficult to keep tracking the person when he/she walks into a shadow. At this time, red is no longer salient and we should shift our attention from the red colour to the distinctive shape in the feature spaces. Therefore, the attention mechanism of feature selection [11,25] plays an important role in the learning procedure to find the most discriminative feature space.
In this paper, the contribution of each selected feature is calculated by the variance ratio of the log likelihood function [11] which has been proved effective in [13]. p(i) denotes the discrete probability distributions of one stimulus feature in target and q(i) denotes the discrete probability distributions of the feature in backgrounds. They are separately estimated by normalizing their feature histograms H T (i) and H B (i) over pixel numbers nT and nB in them,
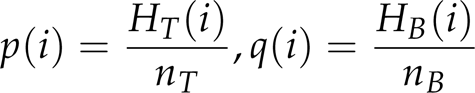
where HT(i) and HB(i) are obtained from target and background windows. Index i ranges from 1 to 2 b indicating patches, and b is the number of histogram buckets.
The log likelihood of the feature i is then given as,

where σ is a small value like 0.001 that prevents dividing by zero or taking the log of zero.
The variance ratio VR(L; p, q) of L(i) is calculated to quantify the feature's contribution and to distinguish the target from backgrounds. Given a discrete probability density function d(i), the variance of L(i) with respect to d is calculated as follows,

The variance ratio of the log likelihood function L(i) can now be defined as,
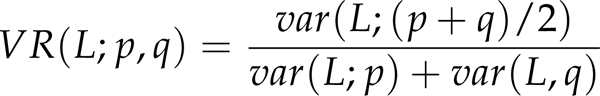
A feature receives a high score if it renders the target more salient than distracters in backgrounds, and vice versa. Updating this score is shifting attention in bottom-up feature spaces, while the appearances of target and backgrounds are constantly changing. In our method, the variance ratio of the log likelihood function for each feature is calculated and normalized to determine the score s i ,

After discrimination scores of bottom-up features are obtained, they are used to linearly weight corresponding top-down patches. On one hand, if one patch is weighted with different scores, it will be segmented into different irregular patches. On the other hand, if different adjacent patches are weighted with approximate scores, they will be clustered into one irregular patch. Hence, the rectangular top-down patches are clustered into irregular ranking patches, which are in the form of a middle level between high-level patches and low-level features. These patches are called discriminative ranking middle-level patches in this paper. Considering the fact that one patch may contain both target and backgrounds since their appearances are similar with nearby scores, this paper models object tracking as a three-class classification issue. Three classes correspond to three kinds of patches, patches only containing the target, patches only containing backgrounds and patches containing both target and backgrounds. Target and backgrounds patches will be adaptively tuned in each round of training. An overview of the training classifier with irregular ranking middle-level patches is depicted in Figure 2.
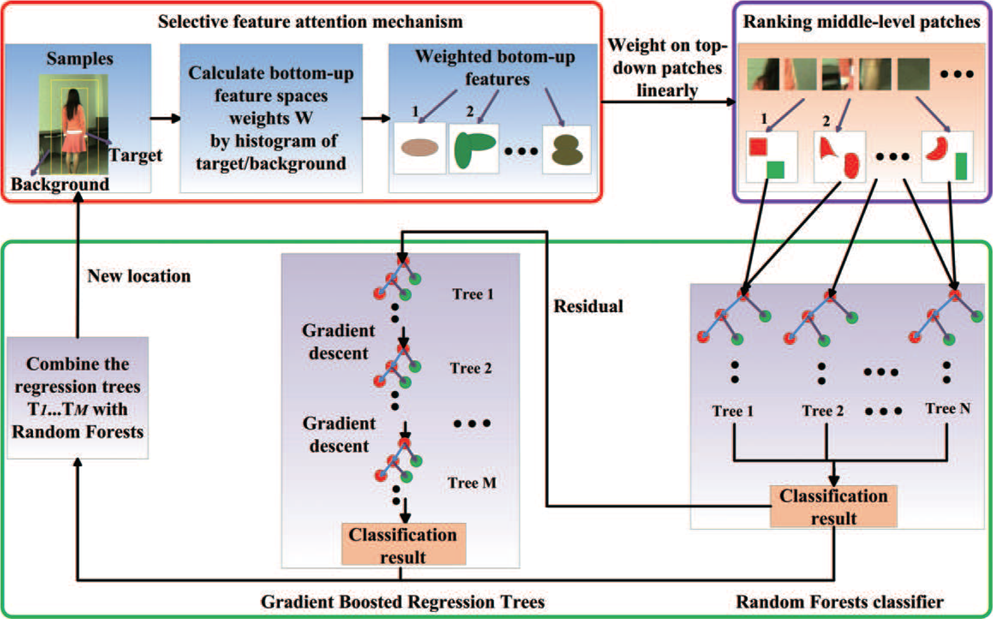
Overview of training classifier with ranking middle-level patches
In a tracking-by-detection algorithm, another key part is how to train and maintain the classifier besides object representation [26]. RFs [17] have piqued researchers' interest as they demonstrate better or at least comparable performance to other state-of-the-art methods in classification, keypoint recognition and clustering applications [18,19,27,28]. More importantly, (1) inherent multi-class classifiers RFs are adapted to our three-class classification problem. (2) RFs can tell the importance of features in training, thus our proposed ranking patches with high weights can be judged by tree nodes preferentially. Hence, online random forests classifiers are used as basic classifiers. Taking the importance of precision into consideration, the classification results of RFs are refined by GBRT. The derived residual of the loss function by training RFs is used to initialize GBRT. Then GBRT corrects the residual in gradient directions. In this way, learning of wrong information can be effectively reduced, so that drifting problem can be alleviated. To cope with continuous model changes in tracking, we adopt online growing trees to constitute RFs and GBRT. In the following subsections, RFs and GBRT will be briefly introduced.

Online Refined Random Forests
RFs are an ensemble of decision trees [17]. For each sample, its classification result is the weighted sum of all trees. Trees in RFs gain random samples with bagging for training, and select random features to evaluate finding the best spitting point at each node. RFs are an inherently parallel algorithm in that every single tree is independent from earlier trees. Another advantage of RFs is that they can provide extra information about the training dataset. Out-Of-Bag (OOB) samples of a tree which are not included during the training can be used to estimate the generalization error, called Out-Of-Bag-Error (OOBE) [17].
Gradient Boosted Regression Trees
Similar to RFs, GBRT is a machine learning technique which is based on tree averaging. GBRT sequentially adds a new tree in each iteration. The new tree focuses on samples that are responsible for the current remaining residual. In each iteration, GBRT uses boosting to reduce the current residual and improve the last results in the gradient direction [29], as illustrated in the gradient boosted regression trees of Figure 2.
Let T(xi) denote the current classification result of sample (xi, yi), where xi denotes the values of the ith feature vector, and yi is the label of the sample. Furthermore, assume that ℒ = (T(x1), …, T(xn)) denotes a continuous, convex and differentiable loss function which reaches its minimum when T(xi) = yi. In this paper, the loss function is equal to square loss function, just as follows,

GBRT performs a gradient descent in the sample space, that is, during each iteration the classification T(xi) is updated with a gradient step, as follows,

where γ is the learning rate. In the case where ℒ is the squared loss, the gradient becomes the residual, i.e.,
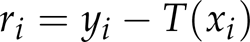
Since RFs and GBRT are based on decision trees, we adopt online tree growing strategy in [19] to train the online RFs and online GBRT classifiers. For each tree, the split principle of each node is that tests at node satisfy g(x) > θ, where g(x) is a test function, and θ is a threshold meaning quality measurement (e.g., information gain or Gini index). In online mode, the test function is randomly generated and the threshold θ is selected randomly, which are also adopted in an extremely randomized forest. Then the best tests and θ are determined by a quality measurement. Moreover, a node splits according to the statistics of samples falling in it. In online mode, statistics are gathered over time. Therefore, a node decides when to split depending on, (1) if there has been enough samples in a node to give a robust statistics and (2) if the splits are good enough for the classification purpose. In order to get a more robust estimation of statistics, two hyper-parameters are introduced which must be met, (1) α, the minimum number of samples a node has to see before splitting, (2) β, the minimum gain a node has to achieve when splits. The grown tree based on these tree-growing strategies is denoted as DecisionTree((x, y), α, β,).
The proposed online refined random forests algorithm is shown in Algorithm 1, Ft(xi) and Tt(xi) denote the tth tree's classification results of sample (xi, yi) in RFs and GBRT respectively. Trees in RFs and GBRT are derived by online DecisionTree((x, y), α, β,) novelly instead of the off-line classification and regression trees. Moreover, the online classifier learns new information for model updating, and forgets old information by discarding the entire tree whose OOBE is larger than the threshold in RFs.
Traditionally, GBRT is initialized with the all-zero function T0(xi), then the residual is ri = yi, leading to the true convergence of ℒ not holding in practice. This is because 1) in each iteration, the gradient is only approximated, 2) for true convergence, the learning-rate γ should be small, requiring an unrealistically large number of iterations M >> 0 [30]. In the online refined random forests algorithm, the initial residual ri is set with the residual of the RFs classification result, i.e., ri = yi − F(xi), the 15th line in Algorithm 1. In this way, errors derived from training samples by RFs can be refined. At the same time, the gradient descent procedure is conducted as the 19th line in Algorithm 1, thus GBRT can converge to its global minimum. The final boosted classifier is added with the initial results of RFs. The whole procedure can be seen in Figure 2.
Experiment and Analysis
To demonstrate performance of the proposed tracking method, extensive experiments are conducted. In order to show the effect of different pieces of our method, self-comparison experiments are conducted. In experiments without ranking middle-level patches, only Haar-like features are used.
Set 1, only RFs without GBRT and without ranking middle-level patches. Set 2, RFs with GBRT and without ranking middle-level patches. Set 3, only RFs with ranking middle-level patches, without GBRT. Set 4, our tracker, RFs with GBRT and ranking middle-level patches.
We also compare our method with five state-of-the-art methods, online AdaBoost (OAB) [2], tracking-learning-detection (TLD) [4], Parallet Robust Online Simple Tracking (Prost) tracker [18], online random forests (ORF) [19] and Hough-based tracking (HT) [27].
For our tracker, 100 trees are used in RFs as in [18] and 10 trees in GBRT as the common rule. For DecisionTree((x, y), α, β,), the maximum tree-depth is set to five, each node with 10 random features, α = 100, β = 0.1, γ = 0.1. All experiments are implemented with fixed parameters. For compared trackers, we use tuned parameters from their source codes for the best results. Because the source code of the Prost tracker [18] is not available, the results of the Prost tracker are gathered from what is reported in [18]. Since all algorithms depend on some randomness, we run them 10 times and average the results for each sequence. For all trackers, Haar-like features are extracted. But the difference is that features of our tracker are selected by weights, while others are selected by boosting. The performance of trackers is measured by Recall - number of true positives divided by the length of the sequence (true positive is considered if the overlap with ground truth is larger than 50%) [4]. All experiments are carried out on an Intel Dual-Core 3.00 GHz CPU with 2GB memory. Our software relies on Microsoft Visual Studio 2008. Taking into consideration of real-time capability of the algorithm, we also compute the frame per second (FPS). In order to guarantee robustness, our method is about five FPS, which is also real-time.
Experiment Sequences
For quantitative analysis, we use the publicly available tracking sequences and videos recorded with a mobile robot in real scenes. David, Sylvster, Girl, Face Occ1, Face Occ2 and Tiger 2 are basic test sequences. Box and Lemming are from [18], while Moun bike and Cli-dive 1 are from [27]. Sequence 11 and 12 are recorded by us in an indoor environment and an outdoor environment respectively. The challenges of all sequences are shown in Table 1.
Challenges of experiment sequences
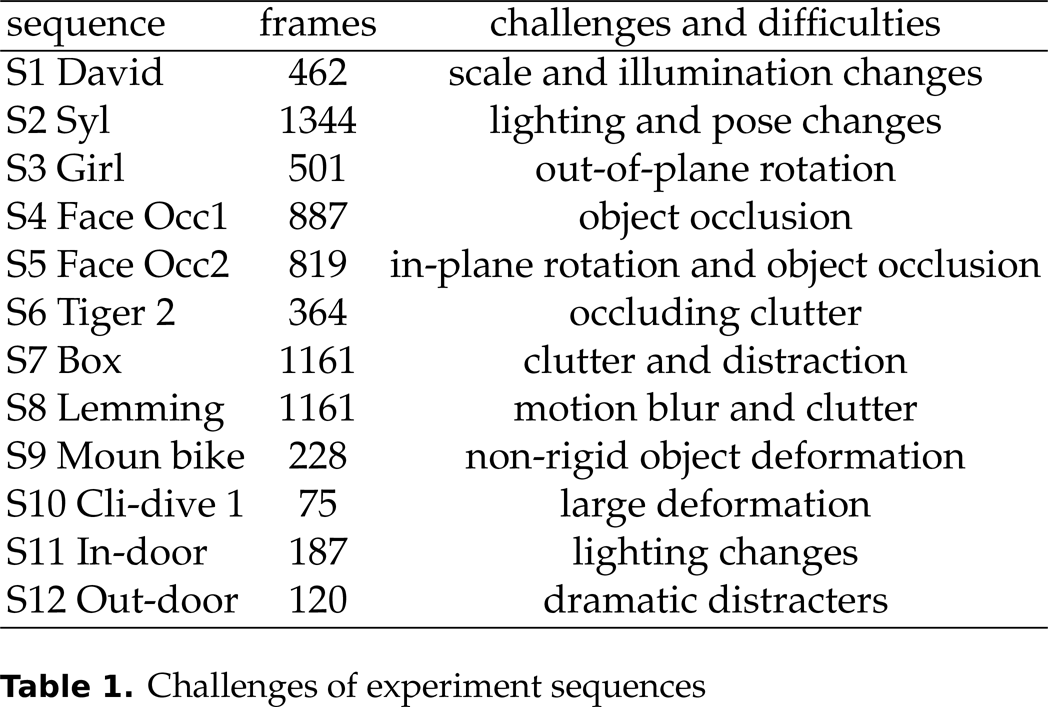
Challenges of experiment sequences
Table 2 shows the results of the self-comparison experiments. From the table, it can be found that our tracker gains the best average performance in all sequences. Figure 3 depicts the illustrative pixel error plots for David sequences. Pixel error represents the mean centre location error in pixels [18]. It can be seen that our tracker is the most stable and the drifts smallest since its mean errors are the smallest and it barely fluctuates. Near frame 250, Set 1 fluctuates strongly, and at the last part of sequences, Set 2 fluctuates frequently. Set 3 and Set 4 keep relatively stable for all sequences, and the mean errors of Set 4 are averagely smaller than for Set 3, which confirms that the drifting problem is alleviated at different levels with different pieces of our method.

Pixel error plots for sequence David
Recall(%) of Self-comparison

The comparative results between Set 1 and Set 3 demonstrate the validity of ranking middle-level patches. Set 3 achieves the second best performance in self-comparison experiments, which shows the effectiveness of ranking middle-level patches. Through weighting top-down features by discrimination scores, three-class irregular patches are obtained to describe the target and its backgrounds, which avoids the distraction of clutter or similar backgrounds. Therefore, Set 3 gains much better results than Set 1, especially for Tiger 2, Face Occ 2 and Lemming sequences. The comparative results between Set 1 and Set 2 prove the validity of GBRT. Set 1 is actually the ORF tracker, so its results are the same as the ORF tracker. Set 2 is better than Set 1 in all sequences since Set 2 uses GBRT to refine the errors of the RFs classifier.
From Figure 3, it can be found that pixel errors of Set 2 are smaller than for Set 1 for most frames, which illustrates that Set 2 is more stable than Set 1. Set 4 shows the results of our tracker, which stems from integrating top-down and bottom-up features and the online refined random forests classifier. Its superiority will be introduced in the following experiment analysis.
Table 3 shows that our method delivers competitive results with other state-of-the-art trackers. From the table, it can be found that our method outperforms all other trackers in eight sequences. The recall of our tracker has been improved by 11% compared with the second best tracker HT [27]. Illustrative tracking results are shown in Figure 5, which depicts that our method can locate the tracking target with higher recall. Taking the Lemming sequences as examples, our method can track the target until the end, while all the others drift away and lose the target. For our tracker, the drifting problem is alleviated with the collaboration of the discriminative appearance model and online refined random frosts classifier, which avoids incorrectly updating the appearance models. An analysis of the comparative experiments will be shown on the basic of challenges in tracking.

For indoor sequences, despite the light changing, ranking middle-level patches can render the target more salient from its backgrounds, so our tracker can deal with small fluctuations in illumination. Our method outperforms ORF because that our method revised RFs' classification result. When the target is almost out of sight, OAB and ORF lose the target, while our tracker can maintain long-term tracking. Figure 4 shows the feature weight variation of HSV colour tuned by selective feature attention for indoor sequences. When the target moves into the region with the highest intensity, the importance of hue and value for separating target and backgrounds declines, while the weight of saturation accordingly increases. When the target moves out of this region, their weights will be restored. Hence, in this sequence, the influences of hue and value in separating target and backgrounds are the same, and they are contrary to the influence of saturation.

Normalized weights variation (hue, saturation, value for HSV)

Illustration of tracking results. (Yellow-Ours, Red-OAB, Green-ORF, Purple-HT, Blue-PROST)
In this paper, a new appearance model composed of ranking middle-level patches is proposed for robust object tracking. This novel approach integrates top-down and bottom-up features through linearly weighting low-level feature scores and ranking high-level patches. As a result, high-level top-down patches are clustered into irregular ranking middle-level patches, which makes the tracking procedure a three-class appearance model. The collaboration of a three-class appearance model and a multi-class refined random forests classifier enables us to achieve more accurate target representation and to avoid incorrect appearance model updates. Extensive experiments demonstrate the superior performance of our tracker over several state-of-the-art tracking methods. They also verify that the proposed method can alleviate the drift problem well. Moreover, our method has been applied to a smart surveillance system for schoolyard, which realizes robust tracking in real scenes.
Footnotes
6.
This work is supported by the National Natural Science Foundation of China (NSFC, nos. 61340046, 60875050, 60675025), the National High Technology Research and Development Programme of China (863 Programme, no. 2006AA04Z247), the Scientific and Technical Innovation Commission of Shenzhen Municipality (nos. JCYJ20120614152234873, CXC201104210010A, JCYJ20130331144631730, JCYJ20130331144716089), and the Specialized Research Fund for the Doctoral Programme of Higher Education (SRFDP, no. 20130001110011).