
Abstract
Random forests consisting of an ensemble of regression trees with equal weights are frequently used for design of predictive models. In this article, we consider an extension of the methodology by representing the regression trees in the form of probabilistic trees and analyzing the nature of heteroscedasticity. The probabilistic tree representation allows for analytical computation of confidence intervals (CIs), and the tree weight optimization is expected to provide stricter CIs with comparable performance in mean error. We approached the ensemble of probabilistic trees’ prediction from the perspectives of a mixture distribution and as a weighted sum of correlated random variables. We applied our methodology to the drug sensitivity prediction problem on synthetic and cancer cell line encyclopedia dataset and illustrated that tree weights can be selected to reduce the average length of the CI without increase in mean error.
Keywords
Introduction
The prediction of an output response Y based on supervised training of a predictor X has been approached using numerous methodologies, such as elastic net, 1 support vector regression, and random forests (RFs),2,3 where majority of the techniques provide point prediction estimates of the output. In this article, we consider the generation of prediction confidence intervals (CIs) for RFs, which is a commonly used prediction model in diverse scenarios.3,4 The generation of input-dependent prediction probability distribution provides an estimate of the heteroscedasticity or the change in error variance for different predictor samples. RF regression 2 consists of an ensemble of regression trees where the prediction output of the forest is based on the average prediction of individual regression trees. We utilize the concept of probabilistic regression trees5,6 to convert the point estimate of individual trees to probability distributions and further consider the optimization of the weights of the ensemble of probabilistic regression trees that can provide stricter CIs.
The ensemble of probabilistic regression trees is considered from two different perspectives.
First, we consider the ensemble as a mixture distribution for each prediction sample X
i
. Consider an ensemble of T trees where the tree j produces the predicted output probability density function P(Y
j
|X
i
). The probability density function P(Y|X
i
) of the ensemble of the T regression trees with weights α1,…,α
T
is then given by
For the second perspective, we consider the output of the ensemble to be the random variable Z where
Note that the use of equal weights (ie,
Background
A probabilistic theory for classification has been developed for some time that can provide bounds on the probability of misclassification. 7 For instance, binary minimax probability machine classification algorithm 8 computes a bound on the probability of misclassification, using only estimates of the covariance matrix and mean for each class, as obtained from the training data. Probability estimation trees (PETs) 9 are introduced in Ref. 10 as classification trees 11 with a class probability distribution at each leaf instead of single-class label. Similar to classification trees, the PETs can be used for classifying examples, and this is simply done by assigning the most probable class according to the PET. They can also be used for ranking examples, and this is done by ordering the examples according to their likelihood of belonging to some particular class as estimated by the PET. Probabilistic RF for classification has been introduced in Ref. 12 with the perspective of providing an estimate of the probability of misclassification for each data point, without detailed probability distribution assumptions or resorting to density modeling. Probabilistic RF for classification is based on two existing algorithms: minimax probability machine classification 8 and RFs. 2
It has been noted in Ref. 13 that classification trees are not equally successful in labeling all instances. This simple observation led to the idea that use of selected trees in classification can potentially increase accuracy. The selection of trees based on their performance on similar instances had limited success. Further refinement of this idea led to the concept of weighted voting. Mishina et al. 14 proposed a boosted RF model where a boosting algorithm is integrated with a conventional RF approach. The boosted RF maintains a high classification performance, even with fewer decision trees, based on constructing complementary classifiers through sequential training by boosting.
For our relevant purpose of regression using ensemble approaches, there have been limited studies on the probabilistic behavior of ensemble of regression trees. Theoretical analysis of RF models has usually focused on the consistency and rate of convergence of the design procedure. 15 Probabilistic decision and regression trees have been considered in Ref. 5 but the ensemble of probabilistic regression trees in the context of altering the variance of prediction error has not been explored. A weighted random forest (wRF) for regression approach has been proposed, 16 where the weight of each tree has been calculated based on the prediction accuracy of out-of-bag samples for that tree. wRF considers the empirical out-of-bag errors for estimating the regression tree weights, whereas this article considers an analytical approach where parametric distributions are estimated to specify a probabilistic representation of each regression tree and the sample-dependent probability distributions are utilized to generate the tree weights.
Methods
RF regression
RF regression refers to ensembles of regression trees, 2 where a set of T unpruned regression trees are generated based on bootstrap sampling from the original training data. For each node, the optimal node splitting feature is selected from a set of m features that are picked randomly from the total M features. For m = M, the selection of the node splitting feature from a random set of features decreases the correlation between different trees, and thus, the average response of multiple regression trees is expected to have lower variance than individual regression trees. Larger m can improve the predictive capability of individual trees and can also increase the correlation between trees and void any gains from averaging multiple predictions. The bootstrap resampling of the data for training each tree also increases the variation between the trees.
Process of splitting a node
Let xtr (i,j) and y(i) (i = 1,…,n; j = 1,…,M) denote the training predictor features and output response samples, respectively. At any node η
P
, we aim to select a feature j
s
from a random set of m features and a threshold z to partition the node into two child nodes η
L
(left node with samples satisfying
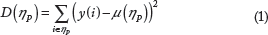
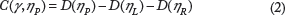
The partition γ* that maximizes C(γ, η P ) for all possible partitions is selected for node η P .
Forest prediction
Using the randomized feature selection process, we fit the tree based on the bootstrap sample {(X1 Y1),…, (X
N
, Y
N
)} generated from the training data. Let Y
i
(x) denote the regression tree prediction for input response x corresponding to tree i. The prediction for the RF consisting of T trees denoted by
Weighted RF
For comparison purposes, we will also consider the wRF methodology proposed in Ref. 16 that uses empirical values to calculate the weight of the trees. The prediction error of a tree denoted by tPE
j
is calculated based on the out-of-bag samples for that tree, and the weight of that tree is estimated as
Probabilistic regression trees
Let us consider the generation of regression trees from a probabilistic perspective, which will allow us to utilize well-known concepts of parameter estimations for statistical models. Estimation of regression trees using probability models has been explored in Refs. 5,6. For a regression tree, our goal is to generate the conditional density of the form
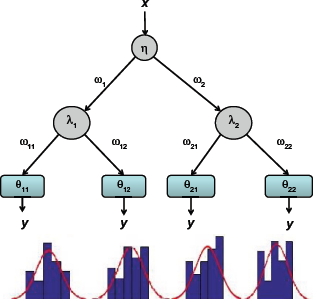
Example of probabilistic decision tree.
The first decision is based on probability P(ω1|x, η) where ω1 is the event signifying partition toward the left of the root node and η denotes a parameter vector η = [η1 T1].
Note that if we consider

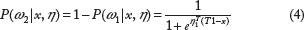
If we consider all the branches of the tree as shown in Figure 1, the corresponding distribution of y conditional on x and tree parameters
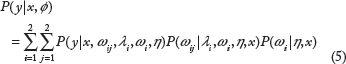
For larger number of branches in the tree, the above technique can be extended to obtain P(y|x, ϕ) for a tree with parameter set ϕ. In this article, we consider that the tree parameters ϕ are generated based on the standard RF node generation criteria given in Eq. 2. The probability distribution at any leaf node is approximated by a Gaussian distribution with mean and variance equal to the mean and variance of the samples at the leaf node. Some examples of empirical distributions fitted to normal approximations are shown in Figure 1.
Consequently, an ensemble of T trees generated by RF regression can be represented by the T tree parameters ϕ1, ϕ2,…,ϕ
T
with each producing the conditional distribution
Probabilistic Rfs
Mixture distribution
As discussed earlier, we consider the prediction ensemble as a mixture distribution for each sample X
i
. Consider an ensemble of T trees where tree j produces the predicted output probability density function P(Y
j
|X
i
). The predicted distribution for each tree is based on the estimated probabilistic regression tree model described in the previous section. The probability density function (pdf) P(Y|X
i
) of the forest of T regression trees with weights α1,…,α
T
with α
j
≥ 0 and
The mean (μ) of the mixture distribution will be equal to the weighted sum of the distribution means (μ
i
) of the trees as shown in Eq. 6.

The variance of the mixture distribution (σ
2
) is given by Eq. 7.
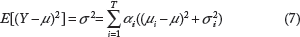
Weighted sum of random variables
The mixture distribution approach selects a tree based on the tree weights and then selects a sample output according to the pdf of the tree. Another potential is to consider the weighted sum of realizations from each tree. As discussed earlier, this will be equivalent to considering the output of the forest to be a random variable Z where
Example for weighted sum of two uncorrelated Gaussian distributions
Consider two independent random variables X1 and X2 that are normally distributed with pdfs

Based on the idea of derived distributions, the pdf of random variable


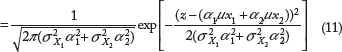
Eq. 11 represents the sum of two independent Gaussian random variables. For T independent Gaussian random variables X1, X
T
with pdfs
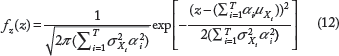
Thus, Z has a normal distribution with
However, if the random variables are correlated, ie, the covariance between different tree outputs are nonzero, the mean and variance of Z are given as follows:


If the vector C = [α1,…,α
T
]′ represent the weight vector and σ represent the T × T covariance matrix, the variance of Z can be represented concisely as

Note that the mean of Z denotes the weighted sum of the means of individual trees in the forest and the prediction is same as regular RF when the tree weights are equal. The mean of Z remains the same irrespective of whether the trees are correlated or not, whereas the variance of Z is directly related to the covariance of the trees using Eq. 15. In the following sections, we will attempt to estimate the covariance among the trees in a forest and analyze the effect of change in C on the variance of Z.
Empirical measure of correlation between probabilistic trees
The covariance between the trees will be estimated using empirical approaches to arrive at the covariance matrix σ. The i,j position element of σ denotes the covariance between the predictions of ith and jth tree represented by random variables Y
i
and Y
j
respectively, ie,
For each input sample X
i
, tree j will produce a pdf P(Y
j
|X
i
), which will be used to select an output prediction realization y
j
. We perform this for all the other trees to arrive at a joint realization of the trees for sample X
i
. This is repeated for N input training samples to produce N joint realizations of the random variables Y1,…,Y
T
, which are used to calculate the sample covariance matrix shown in Eq. 34.

Effect of tree weight on variance
In this section, we will attempt to generate the lower and upper bounds on CVC where C = [α1,…,α
T
]′ represents the tree weight vector. Assuming V is a Hermitian positive definite matrix (note that the covariance matrix V is always positive semidefinite
17
), we can generate the Cholesky decomposition
18
of V = LL
T
, where L is a lower triangular matrix with real and positive diagonal entries. Let the variance of the prediction of a specific forest be given by the function f(C). We have

Let us analyze the minimum and maximum value of f(C).




The minimum for f(C) under the constraint C′e = 1 where e = [1,1, …, 1]′ is given by
Diagonal elements of covariance matrix equal
In the conventional RF model, it is assumed that the trees are uncorrected. Thus, nondiagonal elements of the covariance matrix (which shows the covariance between two different trees) are infinitesimal compared with the diagonal elements (reflecting the variance in the tree). If we ignore the small nondiagonal values and replace them with zeroes, then the covariance matrix (V) is a diagonal matrix. If the variance of the trees are equal
Since the covariance matrix is diagonal with each diagonal entry equal to σ 2 , all the T eigenvalues will also be equal to σ 2 .
From Eq. 22,


When C′ = [1/T,1/T,…,1/T] as in a conventional RF scenario, the variance is given by:

Comparing Eqs. 25 and 26, we observe that C′ = [1/T, 1/T,…,1/T] achieves the minimum variance for uncorrected trees with equal variance.
Diagonal elements of covariance matrix unequal
Consider the case where the covariance matrix is a diagonal matrix and the variance of the trees are not equal as shown in Eq. 27.




When the weights of the trees are equal (ie, C′ = [1/T, 1/T,…,1/T] we have


We can show that the minimum f(Cmin) in such a scenario is
Forest with correlated trees
If we consider scenarios where trees are correlated (ie, covariance matrix is not diagonal), placing higher weights on uncorrected trees will result in lower variance. We illustrate this idea intuitively for a forest consisting of three trees.
Consider the covariance matrix for a three-tree forest as

The minimum variance will be achieved for
Consider

For a regular RF scenario with equal weights
We note that
Regression Forest Weight Optimization
In this section, we discuss two approaches to select the weights for the ensemble of trees based on MLE and incorporation of tree correlations.
MLE for mixture model
Consider N independent and identically distributed samples (x
i
, y
i
) for i = {1,…,N} used for the generation of the T trees. Let α1, α
T
denote the weights of the trees, then the likelihood (conditional) will be given by:

To ensure that
If we denote

The goal is to maximize the product
We solve this optimization problem using Matlab fmincon function that utilizes an interior point approach to find the minimum of a constrained nonlinear function.
Weight distribution based on correlation of trees for weighted sum of random variables model
Among T trees in the forest, consider that some of the trees can have higher correlation between themselves which can be clustered as groups with high correlations among the trees in a group but have limited correlation between trees in different groups. The purpose is to provide higher weight to the uncorrelated trees as compared with the correlated trees. The algorithmic pseudo code is shown as Algorithm 1.
Algorithmic representation of weight selection
STEP 1: Cluster Trees Based on Correlations
STEP 2: Let the k clusters be
STEP 3: Assign equal weight
To achieve the clustering of the trees, we have applied hierarchical clustering with inverse of the covariance between trees as the distance criteria and linkages between clusters decided based on the minimum distance among pairs belonging to the two clusters (single-linkage clustering). The pair of trees that have the smallest distance among all pairs is linked first followed by the next pair and so on. An example of hierarchical ordering with six trees is shown in Figure 2. To generate the final clusters, we have applied a threshold for the inverse covariance and all links below the threshold are considered as separate clusters. The threshold has been taken to be 60% of the average variance of the trees or in other words

Example of hierarchical clustering.
Results
Synthetic dataset
ML estimate for mixture model
To evaluate the performance of our algorithm as compared with competing methodologies, we created a synthetic dataset consisting of 100 × 10 size predictor matrix X and 100 × 1 size response vector

One of our objectives is to check if we are able to reduce the mean square error (MSE) in prediction along with lowering the width of the CI by using MLE of the tree weights. From henceforth, the probabilistic RF with tree weights generated by MLE will be termed as PRF and the probabilistic RF with equal tree weights will be denoted as RF. The weighted random forest approach 16 will be denoted by wRF.
To report our results, we have used 75 samples (75%) for training and the remaining 25 samples (25%) for testing (holdout validation) and compared Pearson correlation coefficients, mean absolute error (MAE), MSE, normalized root mean square error (NRMSE), and width of the CI between predicted and experimental responses for RF, wRF, and PRF models. NRMSE of output response can be calculated as:

MAE, NRMSE, and correlation between actual and predicted responses for 100 samples for different number of trees in the forest.

The previous measures are based on the mean of the predicted pdf and actual observation. We also consider a probabilistic measure to capture where an actual observation lies in comparison with the predicted pdf. Similar to P-value for doubled tailed event, we considered the probability η(y i ) of observing results more extreme than y i when our prediction probability density function is given by the pdf of Ŷ.
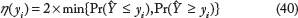
A higher value of η(y
i
) will denote that we cannot reject the hypothesis that the observed responses are from the predicted distributions. A higher value of

We report the percentage difference in the width of the CI at different confidence levels (CLs) for PRF as compared with RF and wRF in Table 3. An M% change in the width of the CI denotes that on an average, PRF generated CI is M% lower than the RF generated CI. We observe that the average width of the CI for PRF is lower than RF and wRF for all CLs and different number of trees.
Change in CI width for different CLs between RF and PRF and wRF and PRF model for 100 samples for different number of trees in the forest.

Table 4 shows the NRMSE and correlation coefficient between actual and predicted responses for RF, wRF, and PRF and percentage change in the width of CI with PRF as compared with RF for a simulation with 250 samples. Similar to the previous results with 100 samples, we observe improvement with PRF as compared with both RF and wRF with respect to NRMSE and correlation coefficient between actual and predicted responses. The results also show that the NRMSE has decreased for all the approaches when the sample size has been increased to 250 samples as compared to 100 samples. The absolute difference in performance for PRF as compared with RF and wRF is better for 100 samples, but the percentage improvement in performance is similar for both the sample scenarios.
NRMSE, correlation between actual and predicted output, and change in CI width for different CLs for 250 samples for different number of trees in the forest.

Weighted sum of random variables
In this section, we consider the effect of tree weights on the MSE and prediction variance for the weighted sum of random variables scenario. We generated a synthetic feature matrix of 500 samples and 1000 features based on a uniform probability distribution [0 1]. The output response has been generated based on Eq. 38 where the output response is dependent on nine of the input features. A random set of 300 of these 500 samples have been used for training, while the remaining 200 samples have been used for testing. We have used the filter feature selection approach RRelieff 19 to reduce the initial set of 1000 features to 100 (10 among these 100 are randomly considered for each node splitting) for training the regression trees.
We have considered five trees for the generation of the RF model, and the covariance matrix for the five trees based on the training samples is given by Eq. 41. We have used smaller number of trees for easy visualization of the covariance matrix along with concise analysis of the inferred weights.

In Eq. 41, the diagonal elements are the variance of each tree with itself, while the nondiagonal elements are covariance between different trees. We note that the covariance between trees 2 and 5 is high compared with the other covariances. By applying hierarchical clustering with inverse covariance as the distance measure and 60% of average variance as threshold, we arrive at four clusters: [2, 5], [1], [3], [4]. We assign equal weights to each cluster (0.25), and where there is more than one tree in a cluster, the weight is equally divided among the trees in the cluster. Thus, we arrive at the following weight vector for PRF model C = [0.25 0.125 0.25 0.25 0.125].
Since we considered holdout validation for variance comparison, we generated the covariance among the trees for the testing samples (denoted by σ) which is shown in Eq. 42.

Consequently, the variance of the forest with equal tree weights is given by


The above results illustrate that for the weighted sum of random variables scenario, the variance of the forest prediction can be reduced by generating the weight of the trees based on tree clusters as compared with using equal weights for all trees.
ML estimate of mixture model applied to CCLE dataset
CCLE dataset has been downloaded from http://www.broadinstitute.org/ccle/home. CCLE dataset has two types of genetic characterization information: (i) gene expression and (ii) single-nucleotide polymorphism (SNP6). Gene expression has been downloaded from CCLE_Expression_Entrez_2012-09-29.gct. In this dataset, there are 18,988 gene features with no missing values for 1037 cell lines. The SNP6 dataset has been extracted from CCLE_copynumber_ayGene_2013-12-03.txt. For 1043 cell lines, there are 23,316 features. For our experiments, we have selected 1012 cell lines that are common to both gene expression and SNP6 dataset.
The drug sensitivity data has been downloaded from the addendum published by Barretina et al. 20 The data provide 24 drug responses for 504 cell lines. Drug sensitivity data of the area under the curve have been collected from Act Area and normalized to [0 1]. The SNP6 and gene expression data integrated model was constructed based on individual RF models combined with a linear regression stacking approach. 3
CI and variance
For the calculation of the CI, we have considered 15 drugs in the CCLE database and considered samples with drug sensitivity higher than 0.1 so as to have noticeable variance among the output responses. The number of samples used for the experiments for the 15 drugs varies from 70 to 395. We have used fivefold cross-validation for all our computations, where the data samples are randomly partitioned into five equal parts and four parts are used for training and the remaining part used for testing and the process repeated five times corresponding to the five different testing partitions.
Based on the model inferred from the training samples, the mean and variance of the output of the leaf node for the testing set has been calculated. Thus, for a testing set of 20 samples and 10 trees, we have a matrix of mean and variance of size 20 × 10. Based on the calculated means and variances, a Gaussian mixture distribution has been derived. Cumulative distribution function has been eventually derived from this distribution to calculate the CIs for different CLs.
To analyze the estimated CIs, we have considered the ratio of the number of experimental testing responses contained in the predicted CI to the total number of testing samples. We will term the ratio as the coverage probability of the CI. Note that we are calculating the coverage probability from cross-validation data as compared with resubstitution data, and thus, there can be significant differences from the CI level for limited samples.
The coverage probability for different CLs for all the 15 drugs is shown in Table 5. We observe that the RF and PRF coverage probabilities are quite similar and PRF coverage probability is closer to the actual CL than the RF coverage probability. As expected, the coverage probability is increasing with the increase in CL for both RF and PRF model.
Coverage probabilities for four CIs (CL) for PRF and RF predictions for different drugs.
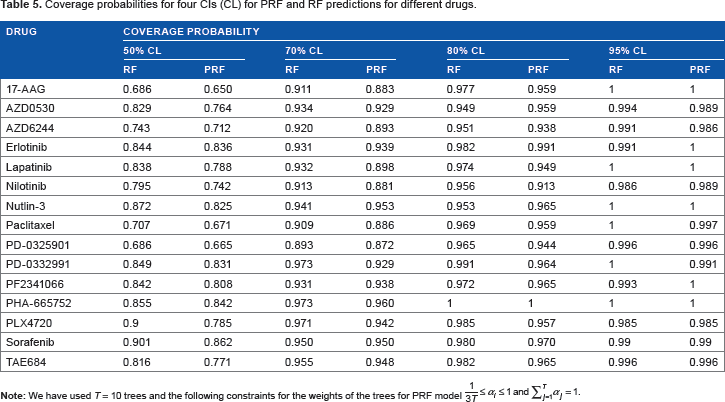
For the results shown in Table 5, we also calculated the P-values of paired t-test between PRF and RF predictions and actual responses. The P-values of paired t-test between (a) PRF prediction and actual responses turned out to be 0.6172 and between (b) RF prediction and actual responses turned out to be 0.6052. A higher value for the PRF scenario represents that the PRF predictions are closer to the actual responses as compared with the RF predictions.
The change in coverage probability with the number of trees (T) for drug 17-AAG is shown in Table 6. We observe that the coverage probabilities are closer to the actual CLs with lower number of trees. However, the increase in the number of trees in the forest produces lower variance and higher prediction accuracy.
Coverage probabilities for four CIs for different number of trees (from 2 to 100) for drug 17-AAG with 395 samples.

From Tables 5 and 6, we observe that both RF and PRF provide similar coverage probabilities for the generated CIs.
We next analyzed the error in prediction using different error metrics (MSE, MAE, and NRMSE) and the length of the CIs for PRF in comparison with RF and wRF 16 .
We first explored whether PRF in comparison with RF and wRF can reduce prediction error (as measured by different metrics) while decreasing the CI in majority of the cases. The ratio of the number of testing samples, where the PRF model-generated CI is lower than the RF model-generated CI, to all samples is defined as PRF CI ratio. For example, a PRF CI ratio of 0.60 will denote that for 60% of the testing samples, PRF model-generated CI is lower than RF model-generated CI.
The MSE, MAE, and NRMSE for different drugs are shown in Table 7, while Table 8 shows the PRF CI ratio in comparison with RF and wRF for different CLs. Tables 7 and 8 show that the average errors for PRF in comparison with RF and wRF is similar based on multiple error metrics, whereas the PRF CI ratio is >0.5 (between 0.54 and 0.6) for all CLs. Thus, the results support the idea that as compared with using equal weights for all trees, weight optimization using MLE can potentially predict drug sensitivity with higher confidence while maintaining similar error. Figure 3 represents two example pdfs generated by PRF and RF, which shows that the PRF predicted distribution has lower variance as compared with RF, while maintaining similar mean.

RF generated PDF is more spread out than PRF generated pdf, which implies that the CI of RF generated pdf is higher than PRF generated pdf.
Performance of all the drugs in terms of MSE, MAE, and NRMSE.

Performance of all the drugs in terms of CI.
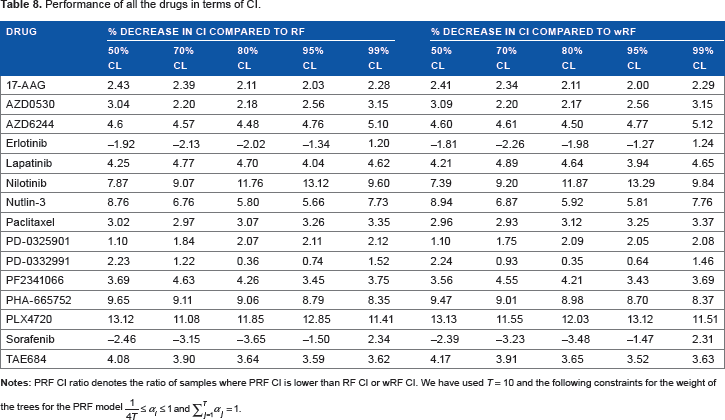
The percentage decreases in mean CI with PRF as compared with RF and wRF are shown in Table 9. We note that the average CI for PRF is lower than RF and wRF in an overwhelming majority of cases.
Percentage decrease in mean CI with PRF as compared with RF and wRF for 15 drugs of CCLE dataset.

We also compared our approach with quantile regression forests (QRFs) 21 that uses nonparametric empirical distributions to model the distributions at the leaf nodes. We observed (results not included) that QRFs can produce smaller CIs than RF and PRF but the coverage probability of PRF is significantly lower. It appears that the empirical distributions based on a few samples can provide smaller variance but has limited coverage that defeats the purpose of designing the CIs.
Prior feature selection
In this experiment, we have used filter feature selection algorithm RRelieff 19 to reduce the initial set of features used for training the RF, PRF, and wRF models. We have considered the CCLE cell lines that are common to all 15 drugs resulting in 396 samples. Features election has been used to reduce the number of features to 50 for each dataset.
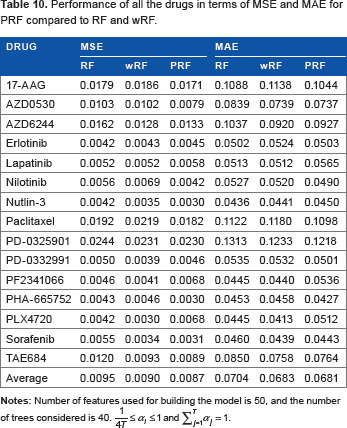
Table 10 shows the average errors in terms of MSE and MAE for the 15 drugs with 50 selected features for RF, wRF, and PRF. We observe that PRF performs better in comparison with RF and wRF in terms of both average MSE and MAE.
Performance of all the drugs in terms of MSE and MAE for PRF compared to RF and wRF.
The prediction performance can also be measured in terms of the bias and variance of the error distributions produced by different predictive models. The bias will be an inverse measure of accuracy, and variance will be an inverse measure of precision. Table 11 shows the bias and variance for RF, wRF, and PRF for different drugs. We note that the average absolute bias (measure of inaccuracy) is lower for PRF (0.0014) as compared with RF (0.0020) and wRF (0.0025). Similarly, the variance (measure of imprecision) for PRF (0.0087) is smaller than variances for RF (0.0096) and wRF (0.0090).
Performance of all the drugs in terms of bias and variance for PRF compared with RF and wRF.

The results given in Tables 10 and 11 show that the PRF provides improvement in terms of average error, accuracy, and precision. We next consider the length of the CI with PRF as compared with RF and wRF Table 12 shows that the percentage decrease in average CI for PRF when compared with RF and wRF is positive for majority of the drugs.
Performance of all the drugs in terms of % decrease in mean CI with PRF as compared with RF and wRF.

Conclusions
In this article, we considered the probabilistic analysis of RFs by representing an RF as an ensemble of probabilistic regression trees. The two perspectives that we presented in the manuscript are based on how we would like to treat a probabilistic ensemble of regression trees. We can consider that we would like to select one tree from the available trees conditional on the weights and predict the output response based on the tree distribution resulting in the mixture distribution scenario. The second scenario is where the output response is considered as the weighted average of all the realizations of the trees similar to the averaging of responses from different trees as considered in conventional RF. Thus, if individual trees have large biases (measure of inaccuracy) that are both positive and negative, considering a weighted sum of random variables can provide a better representation. If we consider the mixture distribution approach for this case, selecting an individual tree for each prediction might be unable to remove the bias. However, the mixture distribution approach is reasonable in selecting tree weights to reduce the CIs, while maintaining coverage and MSE as shown in the results presented in this article.
The probabilistic representation presented in this article allowed us to generate and analyze the CIs of individual predictions. We explored various structures of covariance matrices representing the relationships between the generated probabilistic regression trees and the corresponding tree weights that will optimally reduce the variance of prediction. We studied the effect of tree weights generated using MLE on different error measures and prediction CIs. The application of the maximum likelihood estimates of tree weights on the CCLE drug sensitivity prediction problem illustrated the average reduction in CI, while maintaining or lowering MSE. Future research will consider the generation of a probabilistic framework for multivariate RFs along with generation of sufficiency conditions for reduction in CI by optimizing tree weights.
Software Availability
Matlab implementation can be downloaded from https://github.com/razrahman/PRF_codes.git.
Author Contributions
Conceived and designed the experiments: RR, SH, SG, RP. Analyzed the data: RR, SH, RP. Wrote the first draft of the manuscript: RR, RP. Contributed to the writing of the manuscript: RR, SH, RP. Agreed with manuscript results and conclusions: RR, SH, SG, RP. Jointly developed the structure and arguments for the paper: RR, RP. Made critical revisions and approved the final version: RR, RP. All the authors reviewed and approved the final manuscript.