
Abstract
When a phylogenetic reconstruction does not result in one tree but in several, tree metrics permit finding out how far the reconstructed trees are from one another. They also permit to assess the accuracy of a reconstruction if a true tree is known. TreeCmp implements eight metrics that can be calculated in polynomial time for arbitrary (not only bifurcating) trees: four for unrooted (Matching Split metric, which we have recently proposed, Robinson-Foulds, Path Difference, Quartet) and four for rooted trees (Matching Cluster, Robinson-Foulds cluster, Nodal Splitted and Triple). TreeCmp is the first implementation of Matching Split/Cluster metrics and the first efficient and convenient implementation of Nodal Splitted. It allows to compare relatively large trees. We provide an example of the application of TreeCmp to compare the accuracy of ten approaches to phylogenetic reconstruction with trees up to 5000 external nodes, using a measure of accuracy based on normalized similarity between trees.
Introduction
Different methods used to reconstruct phylogenetic trees often do not find the same tree for the same input data. This is because of the differences in their optimality criteria, in the way they search in the tree space (which is huge even for a relatively small number of taxa), and in their sensitivity to uncertainty in the input (usually nucleotide or protein sequences). Some methods (for example, maximum likelihood or maximum parsimony) often do not find one tree but a set of equally optimal trees, especially for a large number of external nodes (terminal nodes, leaves, often representing operational taxonomic units). Other methods, like Bayesian inference of trees, explicitly aim to find a set of trees: a sample from the posterior distribution of trees. Comparing the trees obtained using different methods or trees in a set obtained using one method requires a measure of distance between trees. Such measures (metrics for trees) are also useful when the accuracy of phylogenetic reconstruction methods is evaluated, in particular, when a new method is developed.1,2 Other uses for tree metrics include tree comparison in mining phylogenetic information databases. 3
We have recently described some properties of a novel method for comparing unrooted phylogenetic trees, the Matching Split distance (MS). 4 Here we describe TreeCmp, a first implementation of this new metric and of its rooted version, the Matching Cluster distance (MC). TreeCmp also implements six other popular metrics for trees that can be computed in polynomial time: Robinson-Foulds (RF) 5 and a rooted version of RF based on clusters instead of splits (RC), Path Difference (PD), 6 Nodal Splitted with norm L 2 (NS), 7 Triple (TT) 8 and Quartet (QT) 9 metric. Other metrics, for example, metrics based on edit operations, such as nearest neighbour interchange (NNI), subtree-pruning-regrafting (SPR) and Tree-Bisection-Reconnection (TBR), were not implemented in TreeCmp mainly because their computation is a non-deterministic polynomial-time hard (NP-hard) problem,10–12 so their application is limited to small trees (with less than 100 external nodes). It is generally believed (but it has not been proven) that NP-hard problems do not have polynomial time (ie, computationally effective) solutions. All metrics implemented in TreeCmp take into account only the topology of compared trees. Branch lengths are ignored.
In this paper we present the new tool and an example of its application: we use TreeCmp to compare the accuracy of a set of popular reconstruction methods for unrooted trees with 250, 1250 and 5000 leaves.
Methods for Tree Comparison Implemented in TreeCmp
Since phylogenetic reconstructions sometimes do not allow to solve all multifurcations, TreeCmp implements distance measures for arbitrary (not only bifurcating) phylogenetic trees. Let UL and RL denote sets of all unrooted phylogenetic trees and all rooted phylogenetic trees over the set of leaves (species) L, respectively. All the distances implemented in TreeCmp are metrics over the sets UL or RL. A function d: X × X→R+ ∪ {0} is a metric over X if and only if the following conditions are met: (i) for each x, y ∊ X, d(x, y) = 0 if and only if x = y, (ii) for each x, y∊X, d(x, y) = d(y, x), (iii) the triangle inequality: for each x, y, z∊X, d(x, y) + d(y, z) ≥ d(x, z). We will now describe briefly each metric implemented in TreeCmp and compare the distances obtained using each metric using 5-leaf unrooted (Fig. 1) or 4-leaf rooted trees (Fig. 2) as an example.
Computation of MS, RF, PD and QT distances for 5-leaf unrooted trees. Computation of MC, RC, NS, and TT distances for rooted trees.

Matching Split metric (MS) for unrooted trees
MS 4 is based on comparing splits in two trees. A split A|B of a set L is an unordered pair (ie, A|B = B|A) of its subsets, such that L = A∩B and A∩B = Ø. Let min(A|B) = min{|A|, |B|}. To compare splits in two trees, MS finds a minimum-weight perfect matching in bipartite graphs whose vertices correspond to splits in these two trees and edges connect each split from one tree to a split in another tree. If the number of splits in the trees differs, the smaller set is extended by the missing number of “dummy” elements.
Because splits from the same tree are not linked in these graphs, these graphs are complete bipartite. One can chose a set of edges so that no two edges share a common vertex (such a set is called a matching) and so that every vertex is connected to another vertex (such a matching is called perfect). Many perfect matchings are possible for complete bipartite graphs. The one with the smallest total cost (sum of the weights associated with the edges) is minimal. The weight associated by MS to each edge is a measure of dissimilarity between splits: hS(A|B, C|D) = min{|A⊕C|,|A⊕D|}, where X⊕Y = (X\Y)∪(Y\X) is a symmetric difference of the sets X and Y. For a “dummy” element O, hS(A|B, O) = min{|A|,|B|}. The value hS(A|B, C|D) is equal to the minimal number of leaf relocations needed to transform one split into the other. For example (Fig. 1), hS(abc|de, acd|be) = 2, because 2 such relocations are needed: abc|de → ac|bde → acd|be. The cost hS(A|B, O) can be interpreted as a cost of leaving an element A|B unmatched. MS distance between two unrooted phylogenetic trees T1, T2 ∊ UL is the total cost of the minimal perfect matching between their splits. For unrooted trees in Figure 1, dMS(T1,T2) = 3. The method allows also obtaining a matching (“alignment”) between their splits (red edges in Fig. 1).
Since the bipartite graphs for trees with n leaves can have at most 2(n – 3) vertices and the function hS takes integer values, their perfect minimal matching can be found in time O(n2.5logn) using methods described elsewhere.13,14 Our implementation of MS uses another popular and effective algorithm, 15 which performs very well in practical applications. 16
Matching Cluster metric (MC) for rooted trees
To compare rooted trees, we define a metric similar to MS but which uses clusters instead of splits, the MC metric. A cluster associated with a vertex v in a rooted tree T with leaves L is a subset of leaves that are descendants of v. To measure the dissimilarity between clusters, MC uses function hC(A, B) = |A⊕C|. For a dummy element, O = Ø, hC(A, O) = |A|. For example, hC(cd, abc) = 3. For rooted trees in Figure 2, dMC(T1,T2) = 3.
MC inherits most of the features of MS, including computational complexity. In particular, an “alignment” between clusters of compared trees can be obtained at the same time as the distance is computed.
Robinson-Foulds metric (RF) for unrooted trees
The RF metric 5 is equal to the number of different splits in compared trees (divided by 2). It can be formulated in the same way as the MS metric, but replacing the function hS with a simple function that returns 1 for different splits, 0 for identical splits, and 0.5 for unpaired (the distance to the “dummy” element). For unrooted trees in Figure 1, dRF(T1,T1) = 2.
RF distance can be computed in O(n). 17 The implementation of RF in TreeCmp is slightly slower. We have optimized the comparison of splits (which are stored in a table as bit sets) using a hashing technique.
Robinson-Foulds metric based on clusters (RC) for rooted trees
Just as clusters can be matched instead of splits to formulate MC instead of MS, the function that is used to compare splits in RF can be used to compare clusters and to create the RC metric, so RC distance between trees is equal to the number of different clusters divided by 2. For rooted trees in Figure 2 dRC(T1,T2) = 1.5. All implementations aspects are similar for RC and RF.
Path Difference metric (PD) for unrooted trees
Let eij(T) denote the number of edges in T∊Un in the path joining leaves i and j, and let e(T) be the associated n(n – 1)/2-element vector obtained by a fixed ordering of the pairs {i, j}. Then the PD metric 6 between trees T1, T2 ∊ UL is the square root of the sum of squared differences (eij(T1) – eij(T2)):

For unrooted trees in Figure 1, dPD(T1,T2) = 141/2. The implementation of PD is based on calculation of distances between all pairs of leaves in time O(n 2 ).
Nodal Splitted metric with norm L 2 (NS) for rooted trees
While PD can be used only for unrooted trees, a family of metrics based on a similar principle (NS metrics) can be created for rooted trees. 7 Let lT(i, j), denote the number of edges in T in the path joining leaf i with the most recent common ancestor of leaves i and j. For tree T ∊ RL, (|L| = n) we define n × n square matrix l(T) as:

To make a NS metric similar to PD, one can use norm L 2 to compare such matrices, with proven properties and advantages. 6 This is the norm we have implemented in TreeCmp. We thus define the NS distance between two trees T1, T2 ∊ RL as:
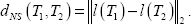
For two rooted trees in Figure 2, dNS(T1,T2) = 71/2. The implementation of NS in TreeCmp has time complexity O(n 2 ).
Quartet metric (QT) for unrooted trees
The QT metric 9 is based on comparing sets of quartets induced by two trees. A set of quartets induced by an unrooted tree is the set of the topologies of all 4-species subsets of its leaves consistent with its topology. QT distance between two trees T1, T2 ∊ UL is the number of different quartets in two respective sets. For two trees T1 and T2 presented in Figure 1, dQT(T1,T2) = 4.
For bifurcating trees, QT can be computed in time O(nlogn). 18 For multifurcating trees, an algorithm with running time O(n2.688) has been recently presented. 19 In TreeCmp we have modified and optimized the code form QuartetDist. 20 The time complexity of this algorithm is O(n + |I‖I'|min{id, id′}), 20 where id and id' are the degrees of internal nodes with the highest degree (disregarding edges to leaves) in two input trees (which may have multifurcations), and |I| and |I′| are the counts of internal (non-leaf) nodes. Therefore, the complexity varies between O(n 2 ) for strictly bifurcating trees and O(n 3 ) in the worst case (eg, two different trees which both have internal nodes of degree n/2 linked to nodes which all connect to two leaves).
Triple metric (TT) for rooted trees
TT is similar to QT, but considers triples instead of quartets. A set of triples induced by a rooted tree is a set of the topologies of all 3-species rooted subtrees consistent with this tree. TT distance 8 between two trees T1, T2 ∊ RL is the number of different triples in the respective sets. For two rooted trees T1 and T2 in Figure 2, dTT(T1,T2) = 3.
The implementation of TT in TreeCmp is based on two algorithms, both with time complexity O(n 2 ). In the case of bifurcating trees, a well-known and relatively old algorithm is used. 8 For non-bifurcating trees, TreeCmp is using a newer and much more complicated algorithm. 21
Topological accuracy measure based on normalized similarity between trees
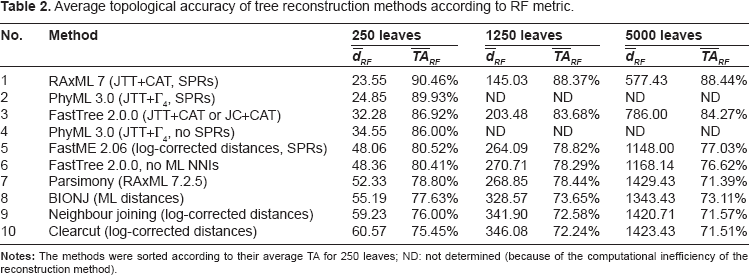
In 1 the topological accuracy (TA) is defined as the proportion of the splits in the true tree that are recovered by a given phylogenetic reconstruction method. This measure of TA is based explicitly on RF. We have created a more general measure of topological accuracy according to a particular metric m (TAm), based on normalized tree similarity for a particular metric (NTSm).
The average distance and computation time for random and similar trees using metrics implemented in TreeCmp.


NTSm is 1 when distance between two trees is 0 (both trees are the same), and is about 0 when the trees are as similar (according to a given metric) as two random trees on average. NTSm (T1,T2) < 0 when T1 and T2 are further apart than two random trees.
When one of the trees is a true tree (T*) and the other is reconstructed (Tr), NTSm is a measure of topological accuracy of the reconstruction: TAm = NTSm (T*,Tr). The model we have used to generate random trees (the Yule model) assumes instantaneous, strictly bifurcating speciation occurring with the same probability for all lineages at any given time. 22 Trees are constructed iteratively: starting from four random taxa, new taxa (chosen randomly) are added to a branch connected to a leaf. 22 As the size of trees goes to infinity, RF distance for two Yule random trees follows asymptotically the Poisson distribution, and the average value quickly tends to the number of non-trivial splits, 6 so TARF is very close to the measure of proportion of true splits used in. 1
Using Metrics Implemented in TreeTmp to Compare Trees
The comparison of phylogenetic trees is a difficult problem, and even very intuitive measures may lead to non-intuitive results. Consider three trees with five leaves presented in Figure 3. Which of the two trees T1 or T3 is the most similar to T2? According to the RF metric, both trees are equally similar to T2. However, all other metrics indicate that T1 and T2 are more similar than T2 and T3 The second answer is more intuitive, because removing leaf e makes trees T1 and T2 identical, while there is no similar operation for trees T2 and T3.
Distances between trees with 5 leaves and normalized tree similarities between “caterpillar trees” using different metrics.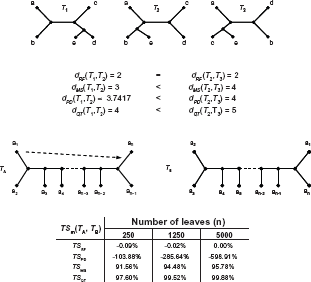
MS can be regarded as a refinement of RF, so these two metrics are the easiest to compare. MS takes into account not only the identity of splits, but also more subtle similarities, so for any set of trees it gives a wider range of distance values, allowing for improved diversification. In comparison to RF, MS concentrates more on differences corresponding to edges deep inside the tree (when both parts of a split A|B have large cardinality) than on differences corresponding to edges closer to the leaves. Finally, MS allows for structural comparison of trees by returning an optimal matching between their splits.
The fundamental advantage of MS over RF is that for large phylogenies, relocations of a bounded number of leaves cause small changes of MS distances (O(n), asymptotically small in comparison to Θ(n 2 ) for maximal possible MS distance for n-leaf trees). In contrast, RF distance can increase from 0 to the maximal value for a given number of leaves after only one relocation of a single leaf (a1) in a “caterpillar” tree (Fig. 3). The normalized relative similarity between two such “caterpillar” trees varies hugely depending on which metric is used. For RF and PD, a large discrepancy is observed (average NTSRF around 0% and NTSPD less than 0%). MS and QT suggest high similarity (NTSMS and NTSQT over 90%, and increasing as the trees grow larger). The results given by MS and QT are more intuitive.
To investigate what effect different properties of metrics for unrooted trees can have for phylogenetic trees reconstructed using biological sequences, we have used 3 previously described data sets 1 of simulated protein alignments (see 1 for details; these data sets are available at http://microbesonline.org/fasttree/#Sims). We have obtained the average topological accuracy (for 308 different sequence alignments with 250 sequences, 92 with 1250 sequences, and 7 with 5000 sequences) of 10 approaches to phylogenetic reconstruction: RAxML 7 23 with SPR, PhyML 324,25 with SPR or without, BIONJ 26 with ML distances obtained using PROTDIST (part of PHYLIP 27 ), FastTree 2 1 with Maximum Likelihood NNI to improve the tree or only minimum-evolution SPR (no ML NNIs), FastME 2, 28 Parsimony (using RAxML 7.2.5), neighbour joining, 29 and its faster variant Clearcut. 30 JTT model 31 (using 4 rate categories in the Γ distribution or the CAT approximation which estimates the rate for each site, see 1 for details) or log-corrected distances were used to measure evolutionary distances between sequences.
Average topological accuracy of tree reconstruction methods according to RF metric.
Average topological accuracy of tree reconstruction methods according to PD metric.

Average topological accuracy of tree reconstruction methods according to MS metric.

Average topological accuracy of tree reconstruction methods according to QT metric.
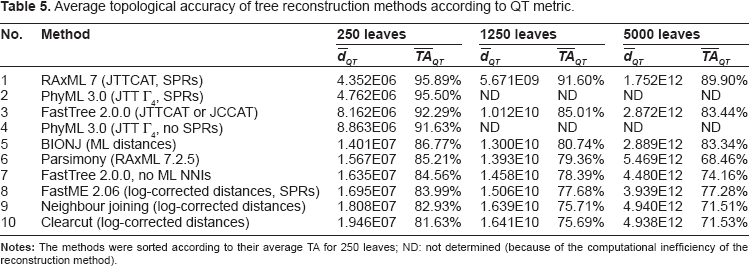
Another observation concerns the fact that according to PD, the reconstructed trees are further away from the true tree relative to the average distance between random trees, than according to the other 3 metrics. In other words, the values of average topological accuracy according to PD are, in general, much lower than for the other metrics, their range is 37.92%–77.94% compared with 71.39%–90.46% for RF, 77.10%–92.41% for MS, and for 68.46%–95.89% (Tables 2–5). This measure also indicates that as the number of leaves increases, the topological accuracy of FastTree and Parsimony reconstructions is more affected than the accuracy of other methods.
The calculation of distances between random trees generated using the Yule process allows to compare the running time for distance calculation using TreeCmp (Fig. 4). Not surprisingly, the calculation of distances was the fastest for RF, and the slowest for QT. PD could be computed faster than MS. The calculation of average TAm requires the comparison of true trees and trees reconstructed by a particular method for a particular alignment, so we could compare the running times for calculations of distances between random trees with the times for similar trees (Table 1). Computation time of MS in case of trees that share some splits can be optimized considerably because the shared splits can be omitted from further computation.
4
This results in reducing the size of the bipartite graph used for computing the minimum-weight prefect matching. In consequence, MS can be computed one order of magnitude faster for simulated trees with 5000 leaves than for random trees.
Computation time of distances between trees using TreeCmp for different metrics.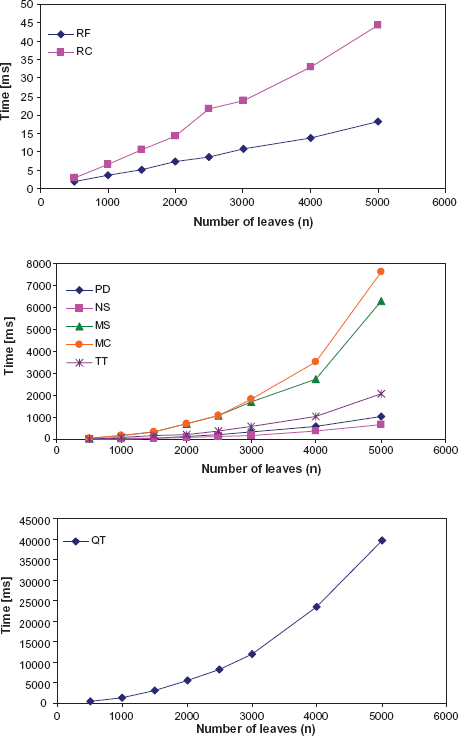
Finally, it is easy to obtain normalized distances using normalized similarity for a given metric: δm = 1 – NTSm. A normalized distance larger than one indicates that two trees are more dissimilar than two random trees with the same number of leaves according to a given metric. Such normalization provides more intuitive measures of tree similarity than the original metrics, measures that are stable as the number of leaves increases.
Availability, System Requirements, User Interface, and Comparison with other Software
We have created TreeCmp as a stand-alone application in Java with a command line interface and a system of hints built on base of Jakarta Commons CLI. The application is freely available at http://kaims.pl/~dambo/treecmp/.
TreeCmp takes as input a file with N > 2 trees and allows for: sequential pairwise comparison (command line option: -s; the output is N – 1 distances between pairs of trees neighbouring in the list), sequential window comparison (-w <window size S>; the output is distances between all trees in neighbouring non-overlapping windows), all-to-all pairwise comparison (-m; the output is N(N – 1)/2 pairwise distances between trees), and one-to-all comparison (-r <file with one reference tree>; each tree in the input file is compared to the reference tree).
In addition, TreeCmp allows for comparison of trees with different leaf sets (–P). Since all the implemented metrics take as input two trees on the same set of leaves, trees on different leaf set are pruned to subtrees having the same set of leaves. Then the subtrees are compared using selected metrics.
We have also allowed for reporting of distances (-N) scaled by the average distance between two random trees with the same number of leaves (see below for the discussion of these scaled metrics). After enabling this option two additional columns per each chosen metric appears in the output file (for two different tree generation methods; the Yule model and the uniform model; see 22 for review). The software uses pre-computed values of averages stored in 16 files (for 8 metrics and 2 random tree generation methods). The files contain also standard deviations and quantiles, so they can be used to test the null hypothesis that the distance between two given trees in not larger than the average distance between random trees with the same number of leaves.6,32
Another feature implemented in TreeCmp is the generation of an “alignment” between trees (-A). A side effect of MS/MC metric computation is a perfect matching that illustrates best correspondence between edges (or nodes) in both trees. Because a perfect matching with minimal weight is not necessarily unique, this matching of similar splits (for MS) or clusters (for MC) is also not unique. However, identification of corresponding phylogenetic groups may be useful for the analysis of large phylogenies, so this method could be an alternative to or extension of software tools for this purpose (eg, TreeJuxtaposer 33 ).
TreeCmp has a very general input file parser based on PAL. 34 The application simply searches for trees in the Newick format (a sequence of characters that begins with the left parenthesis and ends with the right parenthesis and a semicolon), so files created by commonly used phylogenetic packages (MrBayes, BEAST, PAUP, PHYLIP) are supported without any pre-processing.
Output files are tab separated text files (TSV). Such files can be easily read by various data analysis software packages (for example R, Microsoft Excel, OpenOffice.org). The content of an output can file consists of two sections. The first section contains distances using selected metrics. The second optional section (enabled using –I switch) contains some general statistics for all rows in the first section (row average and standard deviation, minimal and maximal values).
As far as we are aware, there is no other software which would allow computing the MC/MS distance or would conveniently implement the NS metric (the only other implementation 7 is in pre-release and requires knowledge of Python). However, there are several free tools for computing subsets of popular tree metrics. One such tool is COMPONENT 2.0 35 which allows to compute RF, TT, and QT distances (and to perform many other operations on phylogenetic trees). Unfortunately, using COMPONENT 2.0 we were unable to compare trees with more than 100 leaves. Another tool, TOPD/FMTS, 36 allows computing RF, PD, QT, and TT, but is considerably slower than TreeCmp. For example, comparison of two unrooted trees takes 2 min for 5000 leaves using RF metric (and <1 s with TreeCmp), >1 h for 1250 leaves using PD (< 1 s with TreeCmp) and >20 h for 100 leaves using QT (< 1 s with TreeCmp). Comparison of rooted trees for 100 leaves using TT metric takes >30 min (< 1 s with TreeCmp). All the tests have been performed on Intel Core i7 920 2.66 GHz with 12 GB RAM server under Ubuntu 10.10.
Conclusions
We provide a tool, TreeCmp, that allows to efficiently compare relatively large (even up to 5000 leaves) arbitrary (possibly multifurcating) trees using four measures for unrooted and four measures for rooted trees. Other available software tools are much more limited: they often implement a small number of measures and are computationally inefficient (in particular, they do not allow comparing large trees). TreeCmp is the first implementation of the Matching Split metric and its rooted variant, the Matching Cluster metric. The computation of these two metrics permits to obtain the alignment of splits (or clusters) in two trees using TreeCmp. The tool also provides a modified, optimized implementation of the Quartet metric adopted form, 20 an efficient version of the Triple metric, a version of the Robinson-Foulds metric, implemented using bit sets and hashing technique, together with its rooted variant based on clusters. Finally, TreeCmp provides an efficient implementation of the Path Difference and Nodal Splitted metrics. The software calculates normalized distances between trees for all the metrics that have been implemented (for trees with 4-1000 leaves). We believe that such normalized distances are more intuitive measures of dissimilarity between trees. Since the tool is written in Java, TreeCmp is ready to run on a variety of operating systems without installation or compilation. We show that four metrics for unrooted trees implemented in TreeCmp may give different results when assessing the accuracy of phylogenetic reconstruction. When such a situation takes place, it is the results obtained with Robinson-Foulds metric that usually do not agree with the other three metrics (Matching Split, Path Difference and Quartet).
List of Abbreviations
the Matching Cluster metric for rooted trees;
the Matching Split metric for unrooted trees;
a metric based on nearest neighbour interchange operations;
a class of non-deterministic polynomial-time hard problems;
the Nodal Splitted metric with norm L 2 for rooted trees;
normalized similarity between trees for a particular metric m;
the Path Difference metric for unrooted trees;
the Quartet Metric for unrooted trees;
the Robinson-Foulds metric based on clusters for rooted trees;
the Robinson-Foulds metric for unrooted trees;
a metric based on subtree prune and regraft operations;
Topological Accuracy of a tree reconstruction according to metric m;
a metric based on tree bisection and reconnection operations;
the Triple Metric for rooted trees.
Author Contributions
Implemented distance metrics in TreeCmp, carried out the numerical analysis: DB. Participated in designing the algorithms: KG. Conceived and designed the study, analysed the results, and prepared the manuscript: BW. All authors reviewed and approved of the final manuscript.
Funding
This work was supported by the Polish Ministry of Science and Education (grant number N303 291234 to BW), and the Polish National Science Centre (decision number DEC-2011/02/A/ST6/00201 to KG and DB).
Competing Interests
Author(s) disclose no potential conflicts of interest.
Footnotes
Supplementary Data
The file contains a compressed directory including the Java application (TreeCmp.jar in directory bin) with a configuration file (config.xml in the directory config), pre-computed data (in the directory data), source files (in the directory src), and the user manual (TreeCmp_manual.pdf) which provides examples on how the program can be used (with files in the directory examples as inputs).
Acknowledgements
We would like to thank Morgan Price for the dataset of alignments and trees.
As a requirement of publication author(s) have provided to the publisher signed confirmation of compliance with legal and ethical obligations including but not limited to the following: authorship and contributorship, conflicts of interest, privacy and confidentiality and (where applicable) protection of human and animal research subjects. The authors have read and confirmed their agreement with the ICMJE authorship and conflict of interest criteria. The authors have also confirmed that this article is unique and not under consideration or published in any other publication, and that they have permission from rights holders to reproduce any copyrighted material. Any disclosures are made in this section. The external blind peer reviewers report no conflicts of interest.