
Abstract
The purpose of this investigation is to develop and evaluate a new Bayesian network (BN)-based patient survivorship prediction method. The central hypothesis is that the method predicts patient survivorship well, while having the capability to handle high-dimensional data and be incorporated into a clinical decision support system (CDSS). We have developed EBMC_Survivorship (EBMC_S), which predicts survivorship for each year individually. EBMC_S is based on the EBMC BN algorithm, which has been shown to handle high-dimensional data. BNs have excellent architecture for decision support systems. In this study, we evaluate EBMC_S using the Molecular Taxonomy of Breast Cancer International Consortium (METABRIC) dataset, which concerns breast tumors. A 5-fold cross-validation study indicates that EMBC_S performs better than the Cox proportional hazard model and is comparable to the random survival forest method. We show that EBMC_S provides additional information such as sensitivity analyses, which covariates predict each year, and yearly areas under the ROC curve (AUROCs). We conclude that our investigation supports the central hypothesis.
Keywords
Introduction
There remains uncertainty as to how to best treat many cancer patients. For example, consider breast cancer, which is the most common cancer among women. Various breast cancer subtypes have been defined which, along with the tumor stage, predict response to therapy and survival, albeit imperfectly. HER2-amplified breast cancer is a subtype with poor prognosis, and therapy with an antibody to HER2 (Herceptin) has vastly improved the survival of such patients. Although Herceptin is used in the therapy of all patients with HER2-amplified tumors, only some respond. Also, it is expensive and can cause cardiac toxicity. 1 Thus, it is important to give Herceptin only to patients benefiting from it.
A clinical decision support system (CDSS) is a computer program that is designed to assist healthcare professionals and patients in making decisions such as the Herceptin therapy decision. Researchers have recognized from the early days of computing that one of the important benefits computers can provide is to support physicians in making clinical decisions, by helping them “sift through the vast collection of possible diseases and symptoms”. 2 Thus, one of the earliest efforts in biomedical informatics was to develop computer decision support systems. Starting in the 1960s, numerous systems were developed. However, few are in routine use. Through a literature search, we identified 13 CDSSs that are implemented, but only 3 that are routinely used. Lack of clinical credibility and lack of evidence of accuracy, generality, and effectiveness are reasons identified for the failure of acceptance of prognostic models in medicine. 3 Thus, there remains a vital need to further our research in CDSS.
Traditional clinical data are becoming increasingly available in an electronic form. Unprecedentedly, abundant genomic data are available to researchers as a result of advanced sequencing technologies such as the next generation sequencing. Studies show that thousands of genes are associated with subtype and prognosis of breast cancer, and particular allele combinations may usefully guide the selection of effective treatment. 4 These sources of data provide significant opportunities for developing CDSSs that can achieve substantial progress over what is currently possible. However, the high dimensionality of these data (the number of variables is often in the millions) presents formidable computational and modeling challenges. A CDSS that can amass all this genomic information and combine it with clinical information holds promise to enhance accurate classification and treatment choices. We call such a CDSS a new generation CDSS.
Central to a new generation CDSS is a component that predicts patient survivorship. This survivorship component must be capable of handling high-dimensional data, and we must be able to seamlessly incorporate the information it provides into a system that analyzes all relevant patient data and recommends surgical therapy (in the case of breast cancer, breast conservation or not, axillary dissection or not, reconstruction or not); adjuvant systemic therapy (in the case of breast cancer, endocrine or chemotherapy therapy or both); and radiation therapy (in the case of breast cancer, yes or no). Although we illustrated the problem for breast cancer patients, it also clearly exists for every type of cancer and for other diseases.
The standard techniques for survival analysis such as the Cox proportional hazards model produce a survivorship function based on the values of covariates. However, they do not provide the other capabilities we mentioned. Thus, there remains a need for a survival prediction method that has such capabilities. Furthermore, the standard techniques are based on specialized assumptions, which we discuss next.
The Cox proportional hazards model 5 is the standard technique used in survival analysis to model the relationship between survival time and covariates. However, several difficulties have been noted with the model. First, its proportional hazards assumption is not necessarily justified in all cases. Strategies for dealing with deviations from this assumption include the following: 6 (1) using non-proportional covariates as stratification factors, (2) partitioning time into intervals so that the proportional hazard assumption holds in each interval, (3) using coefficients that depend on time, and (4) using Aalen's additive hazard model. 7 Each of these methods embodies its own specialized assumptions. Another difficulty with the Cox model is that its purpose is more to identify covariates than to predict survival; the latter task is our main goal here. When our task is purely prediction, we may improve prediction performance in a particular application by making fewer parametric assumptions. That is, the regression linearity assumptions in the Cox model should be unjustified if we have interacting discrete variables.
As a result, several other methods have been developed for predicting survivorship. These include the use of regression trees, 8 bagged survival trees, 9 random survival forests, 10 and a nearest neighbors approach. 11 These methods have been applied to predicting survivorship in breast cancer 12 and other cancers.13,14 However, these methods all simply produce survivorship functions based on the values of covariates. They were not designed to handle high-dimensional data, and they do not result in a component that can readily be incorporated into a CDSS that the physician can utilize in the office to help with the decision as to how to best serve the patient.
A probabilistic CDSS does not reach certain conclusions or claim that a decision will result in a definite outcome. Rather, it informs us about the probability of events given evidence, and it can tell us the expected utility of a decision. A Bayesian network (BN)-based CDSS is probabilistic. Such CDSSs are most suitable in helping to solve medical-related problems such as diagnosis, prognosis, and treatment decisions, due to the uncertain nature of these problems. There are alternative approaches to developing CDSSs such as the rule-based approach and the artificial neural network (ANN) approach. In 1992, Heckerman
In this paper, we develop a BN-based patient survival prediction method using a newly developed BN algorithm called EBMC. The EBMC algorithm was designed to handle high-dimensional data, and research has supported that it has this capability. 17 Even if we have sparse information about a particular patient, the method enables us to perform predictions and investigate the results of interventions based on that information. Furthermore, the method can handle high-dimensional data since it is based on EBMC, and it can be seamlessly incorporated into a complete CDSS because EBMC is a BN algorithm. We compare the prediction performance of our method to that of the standard Cox proportional hazards model and the random survival forest method (RSF) 10 using the Molecular Taxonomy of Breast Cancer International Consortium (METABRIC) dataset, 18 which concerns primary breast tumors. We show that our method substantially outperforms the Cox model and performs comparable to the RSF.
The central hypothesis is that our method can predict patient survivorship well, while having the capability to handle high-dimensional data and be readily incorporated into a comprehensive CDSS. Our results support this hypothesis.
Method
As our method uses BNs, we first review BNs.
BNs and Influence Diagrams (IDs).
BNs19–23 are increasingly being used for uncertain reasoning and machine learning in many domains including biomedical informatics.24–29 A BN consists of a directed acyclic graph (DAG)
Figure 1 shows a causal BN modeling the relationships among a small subset of variables related to respiratory diseases. The value

A BN modeling the relationships among a small subset of variables related to respiratory diseases.
Using a BN, we can determine conditional probabilities of interest with a BN inference algorithm.
19
For example, using the BN in Figure 1, if a patient has a smoking history (
The task of learning a BN from data concerns learning both the parameters in a BN and the structure (called a DAG model). Specifically, a DAG model consists of a DAG
In the score-based structure learning approach, we assign a score to a DAG based on how well the DAG fits the data. Cooper and Herskovits
31
developed the Bayesian score, which is the probability of the data given the DAG. This score uses a Dirichlet distribution to represent prior belief for each conditional probability distribution in the network and contains hyperparameters representing these beliefs. It is standard to use this distribution to represent belief about a relative frequency not only because it has an intuitive appeal as discussed in Ref. 29 but also because Zabell
32
proved that if we make certain assumptions about an individual's beliefs, then that individual must use the Dirichlet density function to quantify any prior beliefs about a relative frequency. In the case of discrete distributions, the Bayesian score is as follows:
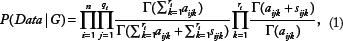
To learn a DAG from the data, we can score all DAGs using the BDeu score and then choose the highest scoring DAG. However, if the number of variables is not small, the number of candidate DAGs is forbiddingly large. Furthermore, the BN model selection problem has been shown to be NP-hard. 34 Thus, heuristic algorithms have been developed to search over the space of DAGs during learning. 19
An ID is a BN augmented with decision nodes and a utility node. An ID not only provides us with probabilities of variables of interest but also recommends decisions based on the patient's preferences. Figure 2 shows an ID modeling the decision of whether to be treated with a thoracotomy for a non-small-cell carcinoma of the lung, taken from Ref. 35. The circular nodes are chance nodes, as in BNs. An edge into a chance node is called a relevance edge. The rectangular nodes are decision nodes. An edge into a decision node is an information edge and represents what is known when the decision is made. The diamond-shaped node is a utility node, and represents the utility of the outcomes to the patient. Edges into this node represent features that directly affect this utility.

An ID modeling the decision of whether to be treated with a thoracotomy for a non-small-cell carcinoma of the lung.
Algorithms for solving IDs determine the decision that maximizes expected utility. 19 The ID in Figure 2 is solved and the expected utility of the first decision (CT scan) is shown in that node.
EBMC
Next, we introduce the BN-based EBMC algorithm used by our survival prediction method.
EBMC Algorithm.
Ideally, if we want to use causes to predict an effect such as survival status, we would want to make all the causes parents of the effect in a BN, and use that network for our predictions. However, unless there are few causes, we do not have the data to learn such a network. For example, if all variables are binary and we have only 10 variables, there are 1024 combinations of values of the causes. An approach often taken to circumvent this dilemma is to make the causes children of the effect. Such a network is called a naive Bayesian network (naive BN), 23 and has sometimes been shown to have good results. 36 However, there is a problem with this approach. That is, it makes the wrong conditional independency assumptions. That is, it assumes the causes are conditionally independent given the effect, whereas in actuality, they are conditionally dependent given the effect (due to what psychologists call discounting). As a result, naive BNs have sometimes yielded very poor results. 37
EBMC
17
builds on the naive BN approach, but ameliorates the difficulty just mentioned. We discuss how EBMC scores candidate models after illustrating its search algorithm using an example. Figure 3 shows an example of the search. The algorithm starts by scoring all DAG models in which a single predictor is the parent of the target node T The model containing the highest scoring predictor is our initial model as shown in Figure 3(a), where we have labeled the predictor

An example illustrating the EBMC search.
Suppose our final model is the one in Figure 3(b). We then make the predictors in the model children of
Next, the search continues in the same manner identifying additional predictors. That is, we first identify the single predictor that when added as a parent of
EBMC scores models using the BDeu score in conjunction with the supervised (prequential) scoring method described in Ref. 39. This scoring method evaluates how well the predictor variables (both parents and children) predict the target variable rather than focusing on learning an overall most probable model.
Note that even if all the predictors are fully observed, EBMC does not make the same prediction as the naive BN model. For example, suppose we have the network in Figure 3(c) and we are computing 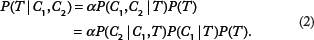
Time Complexity of EBMC.
The time complexity of the EBMC search is
EBMC Handles High-Dimensional Data.
The EBMC algorithm has been shown to be capable of handing high-dimensional datasets. In Ref. 17, it was used to predict late onset Alzheimer's disease (LOAD) using a genome wide association study (GWAS) dataset containing 312,316 single nucleotide polymorphisms (SNPs). 40 In a 5-fold cross-validation analysis, EBMC predicted LOAD risk with an area under the ROC curve (AUROC) equal to 0.728.
Predicting Survivorship Using EBMC.
We model survivorship by discretizing the survival time into whole years. We then use EBMC to learn a separate prediction model for each year. We call the resultant method for predicting survivorship EBMC_Survivorship (EBMC_S). Predicting survivorship by treating each year as a separate prediction problem is a new strategy and, as we shall see in the Results section, has advantages in the patient survival prediction problem.
We evaluated EBMC_S using the METABRIC dataset, 18 which concerns primary breast tumors. There are 981 patients included in this dataset. We first transformed the METABRIC dataset using a combination of domain knowledge and equal distribution discretization strategy. We discuss that transformation next.
Transforming the Dataset.
Table 1 shows the variables and their values used in our analysis. We discuss only the variables whose values we transformed from their original METABRIC values.
The variables used to predict survival.

Furthermore, the dataset has the following two fields:
day: this field denotes the number of days.
Any patient whose
A table developed from the METABRIC dataset.

Evaluation Methodology.
We compared the prediction performance of EBMC_S to that of the standard Cox proportional hazards model
5
and the RSF
10
method using the METABRIC dataset.
18
We chose the RSF method because it was recently shown to significantly outperform both the Cox model and a newly develop
Results
Table 3 shows the concordance indices with 95% confidence intervals for EBMC_S, the Cox proportional hazards model, and the RSF method. Table 4 shows the results of significance testing for EBMC_S versus those for the other two methods. EMBC_S performed significantly better than the Cox model in all the 3 years investigated, with the difference more noteworthy when we looked 5 or 10 years into the future. EBMC_S significantly outperformed the RSF method at 15 years, while the RSF method significantly outperformed EBMC_S at 5 years. Although EBMC_S outperformed the RSF method at 10 years, the result was not significant at the 0.05 level.
Concordance indices with 95% confidence intervals for EBMC_S, the Cox proportional hazards model, and the RSF method.

Significance testing results for EBMC_S versus the Cox proportional hazards model and the RSF method.

The superior performance of EBMC_S relative to the Cox model is likely due to a number of factors including the following: (1) EBMC_S does not make linearity assumptions, but rather naturally models non-linear interactions. For example, survival risk is higher for young and old patients than it is for the middle-aged patients. EBMC_S can capture this with its non-linear modeling. (2) EBMC_S does not make a proportional hazard assumption, but rather looks at each year separately. EBMC_S only performed slightly better than the Cox model when we looked 15 years into the future. However, its performance was still as good as its 10 year prediction performance. On the other hand, the RSF method exhibited its worst performance when we looked 15 years into the future.
Figure 4 shows the ROC curves for EBMC_S for predictions at 1, 5, 10, and 15 years; and Figure 5 shows the AUROCs for all 15 years plotted as a function of the year. We see that, in general, prediction improves as the number of years into the future increases. The result is initially unintuitive because ordinarily we would expect to be able to predict closer events better than more distant events. However, in the case of breast cancer survival, it seems that we can predict whether the person will survive the cancer (15 year prediction) fairly well, but we cannot as readily predict how long those who do not survive the cancer will live.

ROC curves for 1, 5, 10, and 15 year predictions.
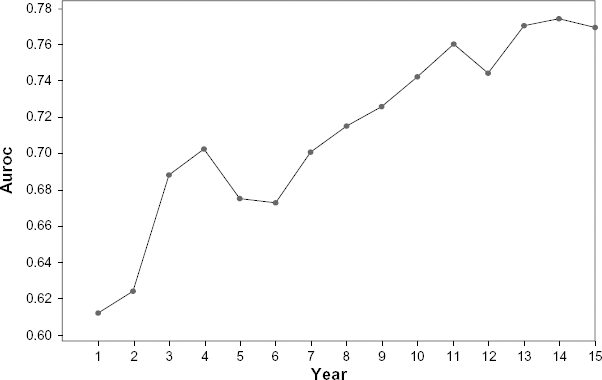
AUROCs plotted as a function of year.
Figure 6 shows the models studied by EBMC_S for 1, 5, 10, and 15 year predictions, when using the entire dataset to study the model. We see that the predictors for the various years are similar but not identical. It is notable that

Models learned by EBMC_S for 1, 5, 10, and 15 year predictions.
Discussion
We have obtained results indicating that the BN-based EMBC_S algorithm predicts patient survivorship better than the Cox proportional hazard model and comparable to the RSF method. EBMC significantly outperformed the Cox model but did not significantly outperform the RSF method. However, the fact that it performed as well as one of the best current prediction methods is important for several reasons.
First, because EBMC can handle high-dimensional data (as discussed at the end of the EBMC section), EBMC_S can be extended to predict patient survivorship based not only on clinical features but also on high-dimensional genomic dataset. Second, because EBMC_S is BN based, it can readily be incorporated into a complete CDSS that recommends decisions for patients based on their preferences. These two capabilities enable us to make EBMC_S a key component of new generation CDSSs.
EBMC_S has other capabilities not found in many survivorship prediction methods. First, we can perform a sensitivity analysis
20
concerning each predictor in the BN learned by EBMC. For example, considering the BN in Figure 6(a), we can determine how sensitive 

If we have current 

Second, we can learn which covariates predict survival for a given year. They are not identical for all years.
Third, we can obtain an AUROC for each individual year. Future research can investigate how these AUROCs can be combined with the sample size to predict the measure of confidence in the prediction for each year.
A purpose of this investigation was to make progress toward the development of new generation CDSSs that can make predictions from whatever data are available for a particular patient, inform the physician as to the probable outcomes of treatment options, and make decisions based on the patient's preferences. Next, we plan to expand the breast survival prediction component to include genomic data using the Cancer Genome Atlas (TCGA) database. TCGA is a comprehensive and coordinated effort to accelerate our understanding of the molecular basis of cancer through the application of genome analysis technologies, including large-scale genome sequencing. TCGA makes available breast cancer data from 899 patient tumor samples and 920 matched normal samples, and includes 95 clinical features, 1,561,140 SNPs, 27,578 methylation features, 17,815 gene expression features, 239,323 RNA sequence features, and 1046 miRNA sequence features. Clinical data include demographic features, such as the age at initial pathological diagnosis; diagnostic features, such as diagnosis subtype, histological subtype, tumor size, tumor stage, tumor focality, cellularity, metastasis status, neoplasm disease lymph node status, and HER2/neu positive status; treatment features, such as surgery; and patient outcomes, such as survival. Our resultant prediction system could be used to make survival predictions based on whatever data are available, whether it is clinical data, genomic data, or both. Furthermore, the system could be used to predict how treatment interventions could affect survival status. Eventually, we plan to extend the BN model to an ID model, which not only makes predictions but recommends decisions based on the preferences of the patient.
Conclusion
We conclude that our study supports that EBMC_S can predict patient survivorship better than the Cox proportional hazard model as well as the RSF method. Furthermore, EBMC_S can be extended to predict patient survivorship based not only on clinical features but also on the high-dimensional genomic dataset, and can be readily incorporated into a new generation CDSS that recommends decisions for patients based on their preferences.
Author Contributions
XJ conceived and designed the experiments. DX analyzed the data. RN wrote the first draft of the manuscript. XJ contributed to the writing of the manuscript. AB and SK agreed with the manuscript results and conclusions. RN and XJ jointly developed the structure and arguments for the paper. AB and SK made critical revisions and approved the final version. All authors reviewed and approved the final manuscript.
Disclosures and Ethics
As a requirement of publication the authors have provided signed confirmation of their compliance with ethical and legal obligations including but not limited to compliance with ICMJE authorship and competing interests guidelines, that the article is neither under consideration for publication nor published elsewhere, of their compliance with legal and ethical guidelines concerning human and animal research participants (if applicable), and that permission has been obtained for reproduction of any copyrighted material. This article was subject to blind, independent, expert peer review. The reviewers reported no competing interests.