
Abstract
This paper reports on a shared task involving the assignment of emotions to suicide notes. Two features distinguished this task from previous shared tasks in the biomedical domain. One is that it resulted in the corpus of fully anonymized clinical text and annotated suicide notes. This resource is permanently available and will (we hope) facilitate future research. The other key feature of the task is that it required categorization with respect to a large set of labels. The number of participants was larger than in any previous biomedical challenge task. We describe the data production process and the evaluation measures, and give a preliminary analysis of the results. Many systems performed at levels approaching the inter-coder agreement, suggesting that human-like performance on this task is within the reach of currently available technologies.
Keywords
Introduction
In this paper we describe the 2011 challenge to classify the emotions found in notes left behind by those who have died by suicide. A total of 106 scientists who comprised 24 teams responded to the call for participation. The results were presented at the Fifth i2b2/VA/Cincinnati Shared-Task and Workshop: Challenges in Natural Language Processing for Clinical Data in Washington, DC, on October 21–22, 2011, as an American Medical Informatics Association Workshop. The following sections provide the background, methods and results for this initiative.
Background Content of Notes
All age groups leave suicide notes behind between 10% and 43% of the time. What is in a suicide note? Menniger suggested that “the wish to die, the wish to kill and the wish to be killed must be present for suicide to occur,” 1 but there is a paucity of research exploring the presence of these motives in suicide notes. Brevard, Lester and Yang analyzed notes to determine if Menniger's concepts were present. Without controlling for gender, they reported more evidence for the wish to be killed in suicide notes of completers (those who successfully complete suicide) than the notes of non-completers. 2 Leenaars, et al revisited Menninger's triad and compared 22 suicide to 22 parasuicide notes that were carefully matched. They concluded that the notes from completers were more likely to have content reflecting anger or revenge, less likely to have escape as a motive, and, although it was not statistically significant, there was a tendency to show self-blame or self-punishment. In another study of 224 suicide notes from 154 subjects, note-leavers were characterized as young females, of non-widowed marital status, with no history of previous suicide attempts, no previous psychiatric illness, and with religious beliefs. Suicide notes written by young people were longer, rich in emotions, and often begging for forgiveness. Another study noted that statements found significantly and more frequently in genuine notes included: the experience of adult trauma, expressions of ambivalence; feelings of love, hate and helplessness, constricted perceptions, loss and self-punishment. One important and consistent finding is the need to control for differences in age and gender Leenaars et al. 3
Using suicide notes for clinical purposes
At least 15% of first attempters try again, most often successfully dying by suicide. “Determining the likelihood of a repeated attempt is an important role of a medical facility's psychiatric intake unit and notoriously difficult because of a patient's denial, intent for secondary gain, ambivalence, memory gaps, and impulsivity.” 4 One indicator of the severity and intent is simply the presence of a suicide note. Analysis has shown that patients presenting at an emergency department with non-fatal self-harm and a suicide note suggests that these patients were likely to be at increased risk for completing suicide at a later date. 5 Evidence of a suicide note may illuminate true intentions, but the lack of one does not squelch questions like: without a note is the patient substantially less severe, how many patients died by suicide without leaving a note behind, or is there a difference between the notes of completers and attempters? Valente's matched notes from 25 completers and attempters found differences in thematic content like fear, hopelessness and distress. On the other hand, Leenaars found no significant difference between thematic groups.3,6
These studies, however, were unable to take advantage of advanced Natural Language Processing (NLP) and machine learning methods. Recently, Handleman incorporated basic NLP methods like word-counts and a rough approximation of a semantic relationship between a specific word and a concept. For example, the concept of
Corpus Preparation
The corpus used for this shared task contain the notes that were written by 1319 people before they died by suicide. They were collected between the years of 1950 and 2011 by Dr. Edwin Shneidman and Cincinnati Children's Hospital Medical Center. The database construction began in 2009 and is approved by the CCHMC IRB (#2009-0664). Each note was scanned into the Suicide Note Module (SNM) of our clinical decision support framework called CHRISTINE. The notes were scanned to the SNM and then transcribed to a text-based version by a professional transcriptionist. Each note was then reviewed for errors by three separate reviewers. Their instructions were to correct transcription errors but leave errors like spelling, grammar and so forth alone.
Anonymization
To assure privacy, the notes were anonymized. To retain their value for machine learning purposes, personal identification information was replaced with like values that obscure the identity of the individual. 9 All female names were replaced with “Jane,” all male names were replaced with “John,” and all surnames were replaced with “Johnson.” Dates were randomly shifted within the same year. For example, Nov 18, 2010, may have been changed to May 12, 2010. All addresses were changed to 3333 Burnet Ave., Cincinnati, OH, 45229, the address of Cincinnati Children's Hospital Medical Center main campus.
Annotators
It is the role of an annotator to review a note and select which words, phrases or sentences represent a particular emotion. Recruiting the most appropriate annotators led us to consider “vested volunteers,” or volunteers who had an emotional connection to the topic. This emotion connection is what makes this approach different than crowd-sourcing
10
where there is no known emotional connection. In our case, these vested volunteers are routinely called
Emotional assignment
Each note in the shared task's training and test set was annotated at least three times. Annotators were asked to identify the following emotions: abuse, anger, blame, fear, guilt, hopelessness, sorrow, forgiveness, happiness, peacefulness, hopefulness, love, pride, thankfulness, instructions, and information. A special web-based tool was used to collect, monitor and arbitrate the annotation. The tool collects annotation at the token and sentence level. It also allows for different concepts to be assigned to the same token. This makes it impossible to use simple
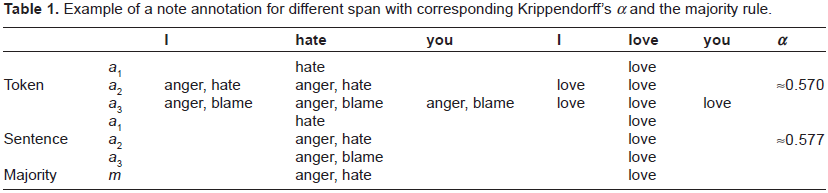
Table 1 shows an example of a single note annotation done by three different coders. At a glance, one can see that the agreement measure has to accommodate multiple coders (
Example of a note annotation for different span with corresponding Krippendorff's
Annotator characteristics.

Evaluation
Micro- and macro-averaging
Although we rank systems for purposes of determining the top three performers on the basis of micro-averaged
Systems comparison
A simple table showing micro-averaged
The data
It is our goal to be fully open-access with data from all shared tasks. The nature of these data, however, requires special consideration. We required each team to complete a Data Use Agreement (DUA). In this DUA, teams were required to keep the data confidential and only use it for this task. Other research using the data is encouraged, but an approved Institutional Review Board protocol is required to access the data first.
Results
The results are described below. First a description of the annotators and their overall performance is provided. Then a description of the teams and their locations as described. More about the teams’ performance is described in the workshop's proceedings. After this, each team's performance is listed.’
Annotators
The characteristics of the annotators are described in Table 2.
Participants
A total of 35 teams enrolled in the shared task. The geographic locations of these teams are shown in Figure 1. A total of 24 teams ultimately submitted results. There were a total of 106 participants on these teams. Team size ranged from 1 to 10. The averages size was 3.66 (SD = 1.86).
Geographic location of participants.
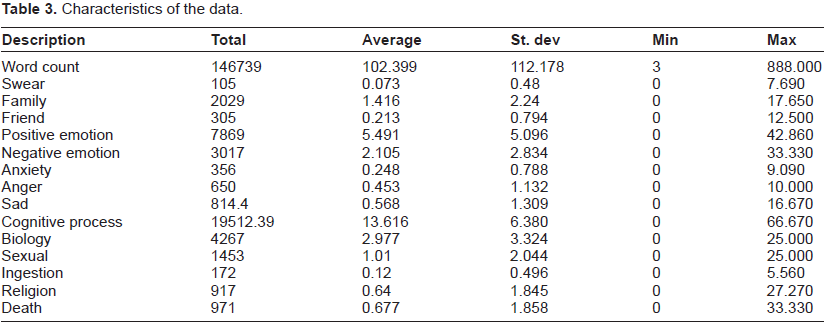
Characteristics of the data
Selected characteristics of the data are found in Table 3. This table provides and overview of the data using Linguistic Inquiry and Word Count, 2007. This software contains within it a default set of word categories and a default dictionary that defines which words should be counted in the target text files. 20
Characteristics of the data.
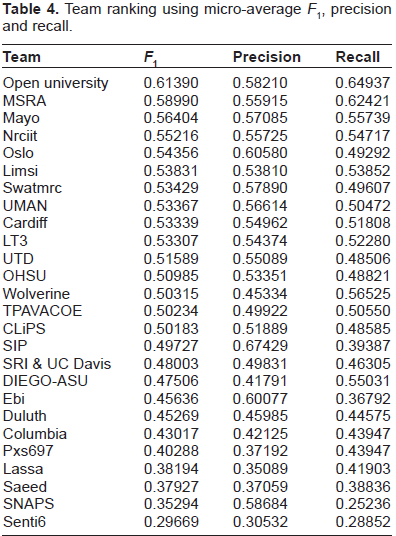
Ranking
The ranking by each team is listed in Table 4. It provides each team's
Team ranking using micro-average
It is interesting to look at relationship between different systems. Figure 2 provides a visual representation of the clustered results including the gold standard reference. It shows that the two most similar systems are
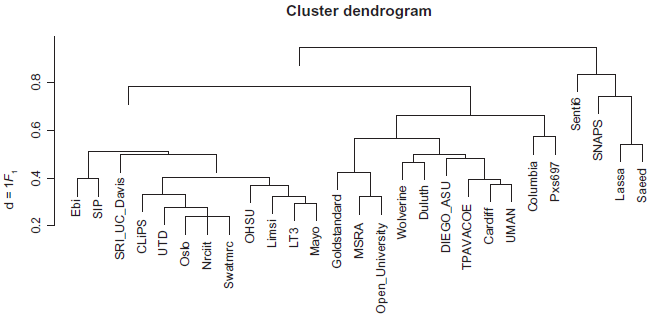
Comparison of different systems’ outputs using distance
Examples of sentence/label combinations that were misclassified by all systems.

On the other hand, if we would look at errors made by at least one system there were 5539 total combinations of sentence/label that were assigned by at least one system but were not present in the test gold standard and there were 1234 total combinations of sentence/label that were not assigned by at least one system but were present in the test gold standard. This leaves 38 sentence/label combinations that every system got right.
Even though there were frequent errors committed by individual classifiers, there were very few of the same errors committed by all systems. This suggests that appropriate ensemble of sentence classifiers might perform much better than a single instance classifier or even better than an ensemble of human experts. These findings make it more difficult to prove that there is a connection between the IAA that is calculated for human behavior and the
Discussion
Observations on running the task and the evaluation
Evaluations like the Challenge 2011 usually provide a laboratory of learning for the managers as well as the participants. In our case a few observations resonate. First, without the vested-volunteers it is unlikely we would have been able to conduct this challenge. Their courage was admirable, even when it led to churning such deep emotional waters. Next, we relearned that emotional data remain a challenge. In our previous Shared Task, an inter-annotator agreement of 0.61 was achieved using radiology data. 9 Here we were able to attain a 0.546, which given the variation in data and annotators is appropriate. We conjecture that part of this difference is due to psychological phenomenology. That is, each annotator has a psychological perspective that he/she brings to emotionally-charged data and this phenomenology causes a natural variation. 21 Whether our use of vest-volunteers biased the interoperation, we are not sure. Preliminary analysis, suggests that these volunteers identify a smaller set of labels than mental health professionals. Finally, we wonder the what, if any bias traditional macro and micro F score introduce to this analysis. This question is apropos when dealing with multilabel-multiclass problems. Measures like micro and macro precision, recall, f1, hamming loss, ranked loss, 11-point average, break-even point, and alpha-evaluation are exploring this issue but consensus has yet to emerge.22–26 The relation between inter-annotator agreement and automated system performance is not clear. The belief is that low IAA results in weak language models 27 but this connection was never formally established.
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
This research and all the related manuscripts were partially supported by National Institutes of Health, National Library of Medicine, under grant R13LM01074301, Shared Task 2010 Analysis of Suicide Notes for Subjective Information. Suicide Loss
We would like to acknowledge the efforts of Karyl Chastain Beal's online support groups Families and Friends of Suicides and Parents of Suicides and the Suicide Awareness Voices of Education, a non-profit organization directed by Danial Reidenberg, PsyD.
Finally, we acknowledge the extraordinary work of Edwin S. Shneidman, PhD and Antoon A. Leenaars, PhD who have had an everlasting impact on the field of suicide research.