
Abstract
We describe the submission entered by SRI International and UC Davis for the I2B2 NLP Challenge Track 2. Our system is based on a machine learning approach and employs a combination of lexical, syntactic, and psycholinguistic features. In addition, we model the sequence and locations of occurrence of emotions found in the notes. We discuss the effect of these features on the emotion annotation task, as well as the nature of the notes themselves. We also explore the use of bootstrapping to help account for what appeared to be annotator fatigue in the data. We conclude a discussion of future avenues for improving the approach for this task, and also discuss how annotations at the word span level may be more appropriate for this task than annotations at the sentence level.
Introduction
We describe the joint submission entered by SRI International and University of California at Davis for track 2 of the 2011 Medical NLP Challenge. 1 Our system implements a machine learning approach, and leverages a set of psycholinguistic resources to capture the emotional content of the text.
System overview
We leverage a machine learning based model for our system, using logistic regression combined with L2 regularization. Given a note, our system treats each of that note's constituent sentences as individual instances to be featurized. During training, we primarily consider each labeled instance individually. During test time, for a given note we process its sentences in sequential order, recording the annotations made for each sentence.
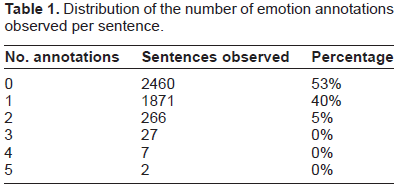
Our system consists of two stages, the first stage determines whether a given sentence contains any emotion annotations, the second determines which emotions should be present. Our choice of a two stage architecture was governed by the highly skewed statistics found in the training notes. As seen in Table 1, which lists the distribution of the number of emotion annotations per sentence in the training notes, the majority of sentences do not have any annotations. Table 2 lists the distribution of emotion annotations found in the training set, in descending order of frequency. If we consider the lack of any annotations for a sentence as its own distinct
Distribution of the number of emotion annotations observed per sentence.
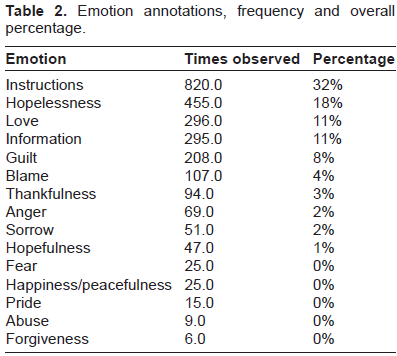
Emotion annotations, frequency and overall percentage.
To prevent our system from skewing in favor of not emitting any emotion annotations, the first stage of our system performs a binary classification, identifying whether a sentence should have any emotions annotated or not. Our assumption here is that grouping all of the sentences that contain one or more emotion annotations together can allow us to generate a model that can adequately separate sentences with one or more emotion annotations from those without.
Once a sentence has been identified as containing emotion annotations, the second stage of our system emits one or more target emotion labels. Due to limited time and resources for this effort, we decided to focus on the case of generating single emotion hypotheses, instead of multi-label methods. The majority of annotated sentences only have one emotion annotated, accounting for 86% of the total, as shown in Table 1. Given an initial scan of the training notes, we made the assumption that models developed for the single emotion case can be extended to multiple emotions.
In this case, we found that treating this as a multiclass classification problem outperformed using individual binary classifiers for each target emotion. This was likely due to the significant skew in the distribution over emotion annotations, with majority class labels such as
In order to account for the remaining 14% of sentences that have multiple annotations, during training we treated these sentences as being individual instances of each emotion that was found. We experimented with using partially weighted instances, but found its performance to be poorer in comparison. In order to emit multiple emotion annotations at test time, we simply output the top scoring emotion and any the emotions whose scores were within 75% of the top emotion's score.
We initially experimented with using different sets of features for each of the two stages, but found that the features we experimented with lead to improvements in performance over the training set to be comparable for both stages. Thus we used the same set of features for both the first and second stages, with any differences noted below in the feature description.
Features
We now describe the types of features used by our system to characterize instances, along with the motivations for their inclusion. Our features were divided into three categories: lexical, psycholinguistic, and emotional sequence. All are applied on a per-sentence basis. The lexical features are derived from the orthographic representation of the sentences, while the psycholinguistic features map words and phrases encountered into psychologically valid dimensions. The emotional sequence features use both the ordering and placement of emotions to govern which emotions to emit at test time.
Lexically Derived Features
For given a sentence, we removed known English stop words, lowercased the sentence, and applied a whitespace tokenizer to segment the words, from which we extracted unigrams and bigrams, which were used directly as features for that instance. This is the “bag-of-words” approach commonly used for text classification, and we also use it as a baseline system for comparison with our other features. For the other non-baseline lexical features described here, we did not remove stop words, as they may be a significant component of a feature.
Previous studies have shown that part-of-speech (POS) can play a significant role in a variety of classification tasks involving populations with psychiatric or neurological issues, and can discriminate between suicidal and non-suicidal language.2,3 To obtain the POS tags for sentences, we used the Stanford Part-of-Speech tagger 4 to tag the tokens in the original sentence with their part-of-speech. For a given sentence, we collected the the frequencies of occurence of single POS tags and bigrams of tags, and incorporated these directly as features for our instances.
In order to capture the kind of actions described by nested expressions such as
During our analysis of the notes, we found that the way sentences began tended to govern which emotion annotations were assigned to that sentence. For example, those which contained the emotions
Psycholinguistic Features
As the majority of the target annotations are expressions of emotions, we sought to incorporate information about the psychological and emotional content of the notes by using Linguistic Inquiry and Word Count
7
(LIWC). LIWC is a psycholinguistic resource that assigns one or more psychological categories such as
In order to perform category assignment for a given sentence, LIWC perform a lexical match against its word to category dictionary. As such, LIWC is essentially performing a look-up, without conducting any part-of-speech identification nor sense disambiguation, and employs a few simple look-aheads to deal with a handful of ambiguous cases. In the authors’ experience, when given a word, LIWC usually presumes that word's primary part-of-speech and word sense for assigning psychological and emotional dimensions. For example, the categories induced by the word
For each sentence, we applied LIWC and used the returned counts directly as features. Because LIWC's analysis also included explicitly non-emotional categories that may be redundant with information already encoded by the POS tagger, such as the presence of pronouns and prepositions, we used only LIWC categories that contained emotional content.
One of the primary motivations for using psycholinguistic resources such as LIWC is to introduce additional knowledge that could help identify the rarer emotions. As shown in Table 2, the top eight emotions account for 90% of all annotations. This leaves the remaining seven emotions at risk of being overpowered, as the optimizer used to train the emotion classifier is likelier to favor the majority classes and neglect emitting the minority classes as hypotheses. We hoped to ameliorate this by introducing potentially strong signals into the featureset that correlate highly with just those minority classes. By doing this, the classifier's performance on those classes should be improved.
During develpoment, we found that LIWC tended to assign multiple labels to words that would ideally like to be identified using a single label. For example, words commonly associated with the
Although LIWC profiles text along 80 dimensions, there are only three of these that we consider clearly relevant to the 8 “emotion” tags of this challenge. Those three categories are
To this end, we developed our own custom word and phrase lists that targeted the emotion annotations of interest. Like LIWC, these are applied over a source sentence, and enter as features the number of matches found in that sentence. These lists were developed using the training notes, as well based off of experience.
Emotional Sequence Features
During our data analysis, we observed that the sequence of emotion annotations tended to follow certain patterns. For example, we found that sentences annotated with
For the first stage classifier, we group the presence of any emotions into a single
In addition, we noticed that certain emotions tended to group in certain positions of the notes. To account for this behavior, we also included the current line number as a feature.
Evaluation and analysis
We now analyze features and performance based on our two stages: how well the system can identify whether emotions should be added or not, and how well it can guess the emotions. Assessment here was conducted using two-fold cross validation over the training notes.
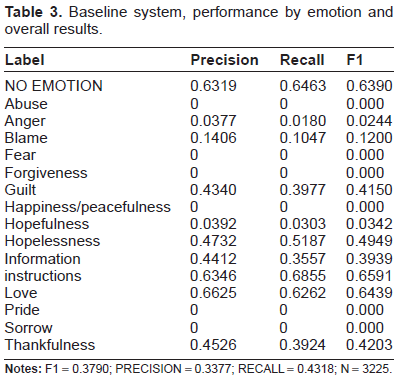
We first note the performance of the baseline system, with a more in-depth view of scores by emotion, along with overall score over the training notes, given in Table 3. We include the lack of any emotion annotations as its own label, “NO EMOTION,” in order to assess the performance of the first stage of our system. As noted before, the baseline system uses only the unigrams and bigrams found in each sentence as features.
Baseline system, performance by emotion and overall results.
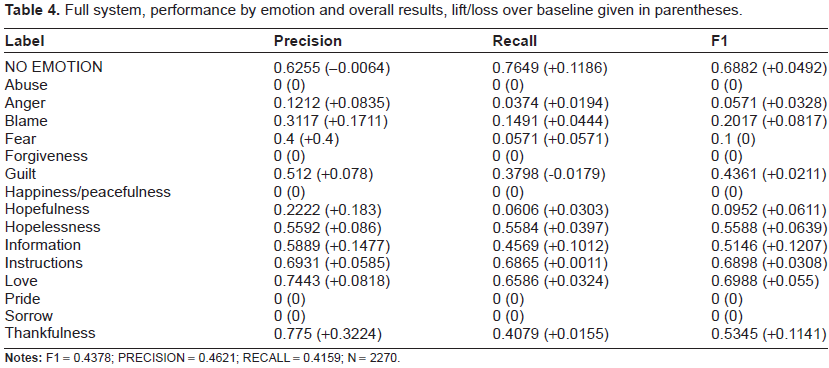
For comparison, we show the performance of the full system in Table 4. We note any lift over baseline performance next to the entries for specific emotions, with gains given as positive values and losses as negative values. Overall, the full system achieves higher scores over the baseline, but is still unable to identify low frequency classes such as
Full system, performance by emotion and overall results, lift/loss over baseline given in parentheses.
We give the results for systems using the baseline with the full set of lexical features in Table 5, the baseline with the psycholinguistic features activated in Table 6. Here, the baseline system we compare against is a “standard” text classification model that employs unigrams and bigrams, as described in the lexical features section. Any lift in performance over the baseline system is given in parentheses as a positive value, and any loss is given as a negative value.
Baseline with full set of lexical features, lift/loss over baseline given in parentheses.
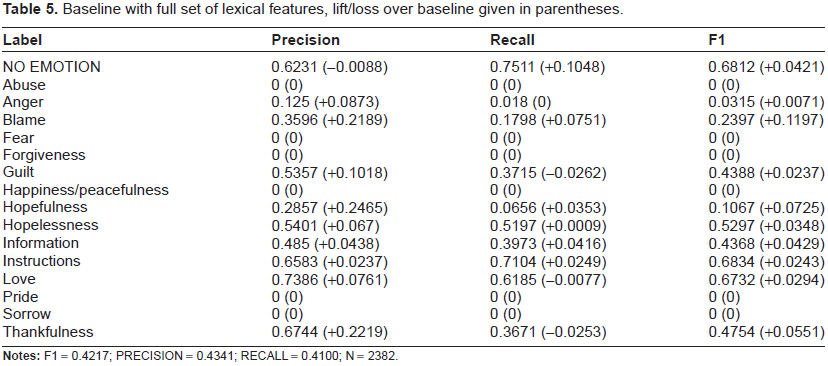
Baseline system with psycholinguistic features, lift/loss over baseline given in parentheses.
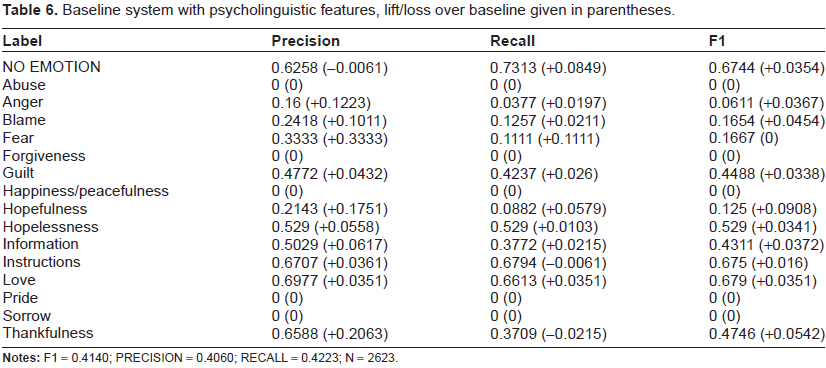
We note that both the use of the full set of lexical features and the psycholinguistic features give gains over the baseline system. However these gains were primarily over the the top eight most frequent emotions. For the seven least frequent emotions, these were still essentially neglected by the system, and the psycholinguistic features only managed to identify a handful of
The performance of the baseline system with the emotion coherence features is given in Table 7. What is interesting to note is even with a simple sequence model of emotional coherence, we see an overall gain in performance.
Baseline system with emotional sequence features, lift/loss over baseline given in parentheses.
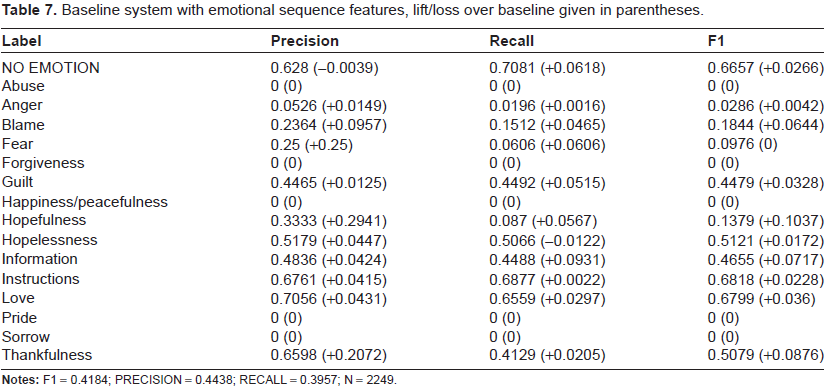
Examination of the confusions derived from testing on the same data as was trained on showed exhibited strong overfitting over all systems.
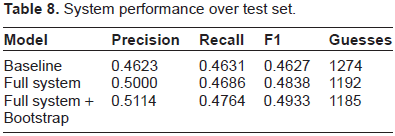
Performance of the baseline and full system is given in Table 8. 1
We identified a bug in our system after submisssion, and performance measures here reflect those of the fixed system.
System performance over test set.
Missing annotations and bootstrapping
One of our observations during an analysis of the notes was that annotator fatigue appeared to play an issue. There were numerous cases where a sentence contained no emotion annotation, yet given the language observed we expected an annotation to be present.
Given that assumption that our training data is partially labeled, we tested our system by treating the labeled data as seeds for bootstrapping. We performed just a single iteration of bootstrapping over the training set, this being equivalent to an early stop employed by “cautious” learning approaches over unsupervised data. 9 We found that this gave a small increase in precision and recall, amounting to nearly an additional point in F1 over the test set (Table 8).
Conclusion and Future Work
We have described how a variety of lexical, psycholinguistic, and emotional sequence features can augment a baseline text-classification system. A clear area for future improvements is in the handling of the multi-label cases, such as employing a classifier that specifically targets multiple labels. And given the signal derived from the emotional sequence model, improvements to both how we model multiple emotions and the emotional transitions are warranted.
Another area of improvement would be to address the seven minority emotion annotations, which constituted only 10% of all the annotations introduced. We could certainly employ methods that can incorporate a small number of positive instances, such as using an instance-based classifier. However, the lack of available training data for these classes would argue for more training data to cover those cases, or some deterministic rules in our system to account for them.
We also found that misspellings and poor grammar tended to be present for in significant number of notes. In addition to introducing extra sparsity into the feature space, this would also present a problem for resources, such as LIWC, that rely on lexical matches. Also, even if a more reliable sentence segmentation algorithm were employed for future emotion annotations, the presence of grammatical errors could still impact what is deemed a sentence.
One point of interest here is the under performance of the psycholinguistic resources. Analysis of the notes showed that in most of the cases we observed, the emotions of interest were commonly associated with phrases instead of single words. This is particularly true of the
Certainly increasing the range of phrasings covered by our phraselists would be one way to account for this. However, given the apparent phrase-based nature of the problem, we would argue that a system that worked on the token to phrase level would be more appropriate for this task than one that works on a sentence level. Indeed, during development it became apparent that viewing the fundamental task as that of information extraction, instead of text classification, may have been a better fit for this task. In general, information extraction approaches treat the hypotheses of interest as applying over word spans, instead of entire sentences. Given this, we would recommend that future annotations of this form be performed at the word span level.
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
The authors would like to thank the Challenge organizers and volunteer annotators for all of their hard work and effort. In addition, we would like to thank Dimitra Vergyri, Bruce Knoth, and the members of the SRI Artificial Intelligence Center for their helpful comments and suggestions.