
Abstract
An ensemble of supervised maximum entropy classifiers can accurately detect and identify sentiments expressed in suicide notes. Using lexical and syntactic features extracted from a training set of externally annotated suicide notes, we trained separate classifiers for each of fifteen pre-specified emotions. This formed part of the 2011 i2b2 NLP Shared Task, Track 2. The precision and recall of these classifiers related strongly with the number of occurrences of each emotion in the training data. Evaluating on previously unseen test data, our best system achieved an F1 score of 0.534.
Introduction
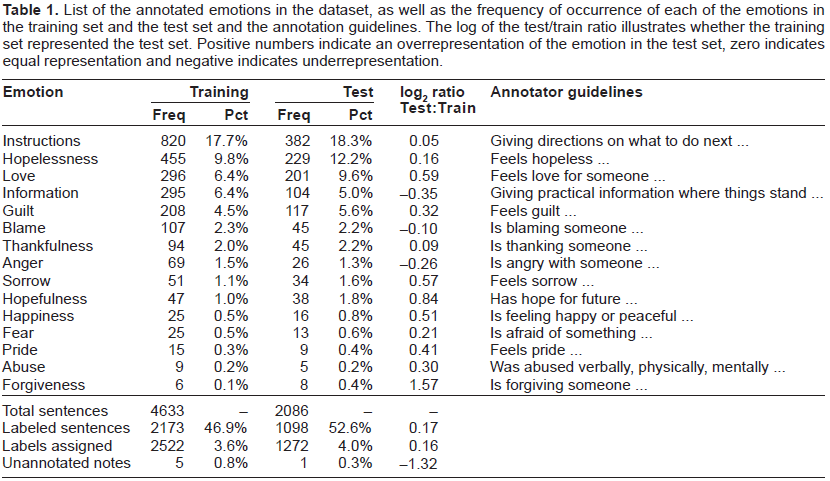
The goal of this study was to identify emotional content expressed in suicide notes. This was undertaken as part of the 2011 i2b2 NLP Shared Task, 1 Track 2. The organizers of the shared task created a fixed inventory of fifteen emotions (Table 1).
List of the annotated emotions in the dataset, as well as the frequency of occurrence of each of the emotions in the training set and the test set and the annotation guidelines. The log of the test/train ratio illustrates whether the training set represented the test set. Positive numbers indicate an overrepresentation of the emotion in the test set, zero indicates equal representation and negative indicates underrepresentation.
An external team first collated the notes and subsequently anonymized them so that no personal or identifiable data remained; names and addresses were substituted with a small selection of alternatives. Subsequently, volunteers who had a strong emotional connection to someone who had committed suicide provided a sentence-level annotation of the suicide notes such that every sentence was either assigned one or more emotions or, more often, was left unlabeled. Sentences were labeled with a particular emotion only when a sufficient number of annotators agreed upon the annotation; hence, an unlabeled sentence does not necessarily indicate a complete agreement that these emotions were absent from the sentence nor does a labeled sentence necessarily indicate incontrovertible evidence that an emotion was present in the sentence.
Participants in the shared task were provided with 600 annotated notes as training data. The task organizers asked participants to optimize their systems according to F1 score: the harmonic mean of precision and recall.
Two of our systems attempted to achieve maximal F1 score, as instructed, by balancing precision and recall. Our third system attempted to achieve higher precision at the expense of lower recall. In the sections below, we describe our activities with the annotated training data before focusing on our performance with the test data.
Methods
Overview
In the task presented here, each sentence of a suicide note was classified as exhibiting zero or more emotions, annotated from a pre-defined set of 15 “emotions”. The emotions are shown in Table 1 and include two non-emotional labels: “information” and “instructions”. In addition, the label we refer to as “happiness” included both “happiness” and “peacefulness”. Many well-studied natural language processing (NLP) classification tasks (part-of-speech tagging, word-sense disambiguation, spelling correction, named entity detection, sentiment analysis and spam filtering, to name a few) also draw their labels from a pre-defined label inventory. However, the classifier in those tasks must assign exactly one label to each information unit whereas here we must provide zero or more labels. While this difference is worth noting, it does not preclude us from investigating off-the-shelf implementations of classifiers used for other NLP tasks. It simply requires recasting into the more familiar problem where the classifier assigns exactly one label to each sentence. We accomplish this by training 15 different classifiers, one for each emotion.
Each classifier performs a binary labeling for that emotion (estimating it as present or absent). We then transform the output of each classifier so that the labeling from classifier
In Table 1, we show the number and percentage of sentences that were annotated with each label (“Labeled sentences”). Since each sentence could have been labeled with up to 15 labels, we may wish to consider the number of total labels assigned (“Labels assigned”). This value exceeds the number of labeled sentences since 14% of labeled sentences had multiple labels. There were 4,633 sentences in the training set, each of which could have received up to 15 different labels. Of the potential 69,495 labels that could have been assigned, 2,522 (3.63%) were assigned.
Maximum entropy classifier and features
For each emotion, we trained a maximum entropy classifier 2 using only the training data supplied as part of the shared task, then we applied the trained classifier to the test data. Maximum entropy classifiers have been widely used in NLP classification tasks, for example in part-of-speech tagging 3 and in named-entity recognition. 4 In this work, we made use of the freely available Stanford Classifier. 5 In addition to using words (unigrams) as features, we experimented with a wide variety of additional classifier options, preprocessing options, and feature types:
Classifier Options
Preprocessing Options
Feature Types
See http://goo.gl/Zrybe.
See the Dependencies Manual accompanying the Stanford Parser for more details.
The Results section presents the performance of these features using five-fold cross-validation on the training data. In explaining the features used in this presentation, we use the key presented in Table 2.
Key to the features used in the classifiers. For example, the notation “W1–1/C0–0/L-/M-/D-/O-” indicates a feature set using only unigrams as features and “W1–2/C0–0/L+/M+/Dd/Oe” indicates a feature set using word unigrams and bigrams, spelling correction, stemming, dependency relations and a split point optimized for each emotion. See the Methods section for a complete description of these features.

Heuristics
Systems used for submission
As part of the evaluation exercise, participants were allowed to submit the results from up to three classifiers, with the understanding that the single best classifier, as determined by F1 score, would be the system used to provide a ranking of all participants. Below is a description of the three systems that we developed and submitted:
Results
In this section, we present two sets of results. We detail the performance of each feature used by our classifiers using 5-fold cross-validation methods on the training data. Then, we present the performance of our three submitted systems on the test data and compare that to system performance on cross-validated training data.
Cross-validated results and feature selection
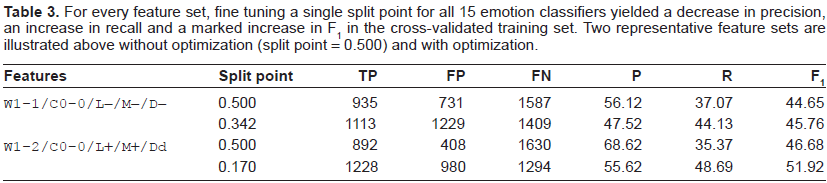
Confidence tuning has a pronounced effect on the results regardless of the feature set used; therefore, we begin by presenting results using our default 0.5 split point and the tuned split point found using cross-validation on two representative feature sets. Table 3 sets out the true and false positives (TP and FP) and false negatives (FN) for these models, together with the precision (P), recall (R) and F1 score. True negatives are not shown in any of the models as they do not impact the F1 score. Comparing the first and third rows, we can see how introducing bigrams, spelling correction, stemming and dependencies greatly reduced the false positives but at the cost of fewer true positives and more false negatives. The impact on F1 was still beneficial. The second and fourth rows show how fine-tuning the split point could further improve the functioning of these classifiers.
For every feature set, fine tuning a single split point for all 15 emotion classifiers yielded a decrease in precision, an increase in recall and a marked increase in F1 in the cross-validated training set. Two representative feature sets are illustrated above without optimization (split point = 0.500) and with optimization.
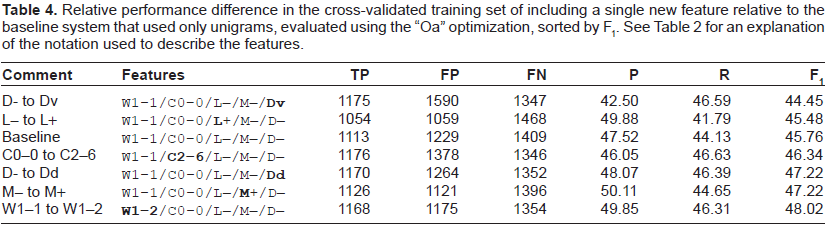
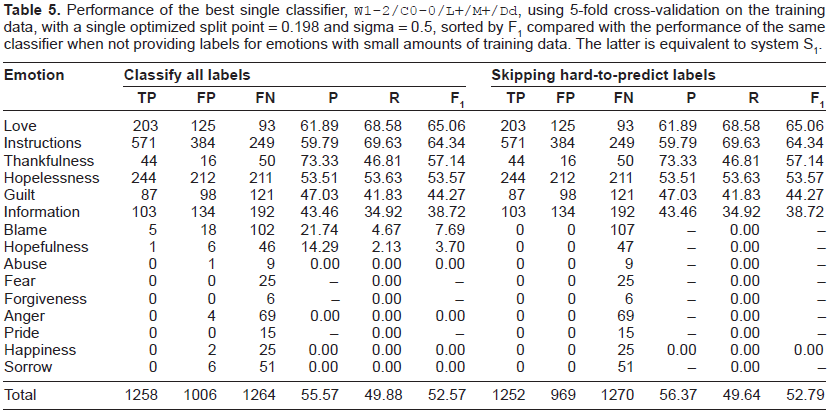
Given the across-the-board improvement due to split point optimization, Table 4 presents the results of using each of the features individually (relative to using only using word unigrams) using only this optimization. Table 5 shows the performance of the single best classifier using cross-validation. In Table 6, we present the mean change in precision, recall and F1 observed when each feature was added to our classifier, averaging across all permutations of the other features. Since the overall F1 score is the mean across all possible other sets of features, one can view the values in Table 6 as an approximation of the additive amount of increase in F1 that can be obtained by adding each feature to the standard classifier. Table 7 presents the performance for each of our three submitted systems on both the training and test data.
Relative performance difference in the cross-validated training set of including a single new feature relative to the baseline system that used only unigrams, evaluated using the “Oa” optimization, sorted by F1. See Table 2 for an explanation of the notation used to describe the features.
Performance of the best single classifier, W1–2/C0–0/L+/M+/Dd, using 5-fold cross-validation on the training data, with a single optimized split point = 0.198 and sigma = 0.5, sorted by F1 compared with the performance of the same classifier when not providing labels for emotions with small amounts of training data. The latter is equivalent to system S1.
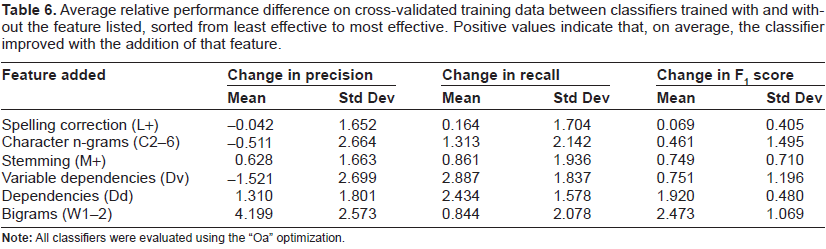
Average relative performance difference on cross-validated training data between classifiers trained with and without the feature listed, sorted from least effective to most effective. Positive values indicate that, on average, the classifier improved with the addition of that feature.
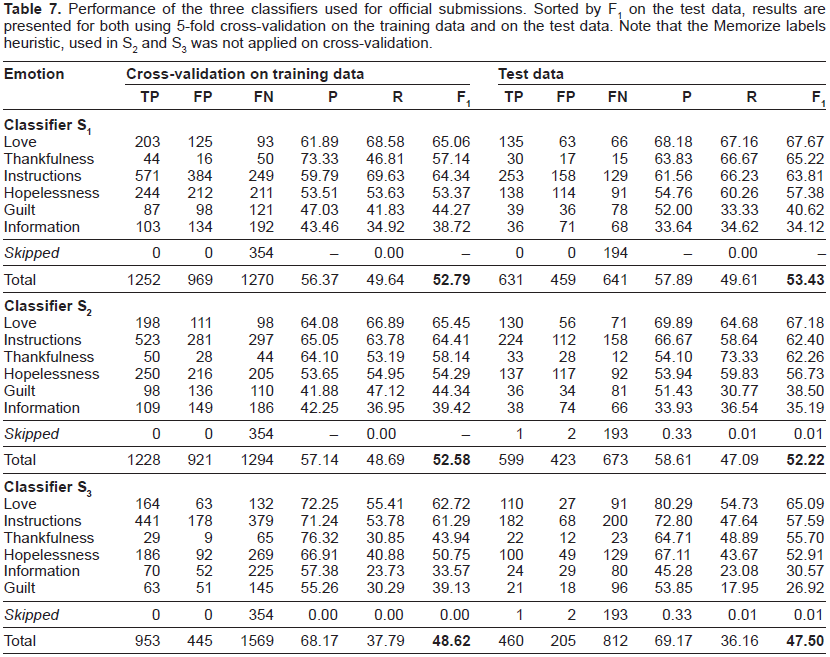
Performance of the three classifiers used for official submissions. Sorted by F1 on the test data, results are presented for both using 5-fold cross-validation on the training data and on the test data. Note that the Memorize labels heuristic, used in S2 and S3 was not applied on cross-validation.
Discussion
All of the systems we submitted achieved results in line with the performance we obtained using cross-validation on the training set. Since, for testing, we could train on the full data set (instead of 80% as in the 5-fold cross-validation setup), we expected a small improvement in our F1 score on the test data; this was realized for our first (S1) and third (S3) systems, but not in our second (S2) system. One possibility is that the individualized optimization of split points on a per-emotion basis used in S2 led to overtraining.
We trained our classifiers to function well specifically in terms of the F1 score as this was the scoring goal of the i2b2 competition. The F1 score is the harmonic mean of precision and recall. In other settings, precision is known as sensitivity; it captures the proportion of annotated emotions that the classifier detects. Recall also uses the correct positive annotations, focusing on the proportion of positive estimates which were correct; this is known in many other settings, notably health research, as positive predictive value. In those same settings, precision (sensitivity) is supplemented, not by recall but by specificity which focuses on the non-annotation of a label. Here, specificity would be the proportion of sentences that should not be annotated with a given emotional label correctly not having that label applied. The use of F1 score as a summary in this setting completely ignores the true negatives (ie, those that were correctly not labeled with a given emotion). We believe that these true negatives were actually important. With this exercise we were effectively running a series of yes/no annotation exercises on the same dataset. The clear majority of sentences were not labelled with each given emotion: annotated sentences for each given emotion were quite rare in both the training and test datasets. The correct answer was to not label with each particular emotion in most instances. It is interesting to note that the specificity was extremely high (and, therefore, very encouraging) for all of the classifiers that we developed.
The annotated datasets were the gold standard in these exercises and reflected the time and effort of many people. Each sentence was annotated by at least three annotators, assigning annotations to sentences only when two or more annotators agreed. However, there were many instances in both the training and test dataset where we found that emotions were inappropriately applied or omitted by the annotators, as detected by our classifiers. For example, the guidelines state that a sentence should be annotated with “forgiveness” if the author is forgiving someone, not if the author is asking for forgiveness. Yet, the sentence “Forgive me for this rash act but I alone did it.” was wrongly annotated with “forgiveness” in the training set by the annotators.
In addition, there were instances where exactly same sentence did not attract the same emotion from the annotators. In the training data, some sentences appeared multiple times across notes. For example, the sentence “I love you.” appeared in 7 training sentences: 5 times annotated with “love” and 2 left unannotated. Our
The suicide notes provided in the data set were transcriptions of hand-written notes. These notes contained many spelling errors and tokenization inconsistencies. It was unclear where these errors originate, but we suspect some are genuine errors from the author and others were transcription errors in preparing the data sets eg, “3333 Burnet Ave” is sometimes “3333 Burent Ave”; other such errors could have been introduced. Our spelling correction algorithm fixed minor errors (eg, “sufering” → “suffering”; “attemp”^ “attempt”; “beond” → “beyond”) but failed to correct more complex errors that involved more than a single substitution, transposition, insertion or deletion. For example, “capsuls” was amended by our system as “capsule” instead of “capsules”. Additionally, many spelling errors involved words (often spelled somewhat phonetically) that could not be corrected at all by this simple method: “hemorige” (“hemorrhage”), “disponded” (“despondent), “rearenge” (“rearrange”). Some mispelled words were “corrected” erroneously. There were also instances where the algorithm corrected words that weren't incorrect. For example, changing the abbreviations “appt” (appointment) → “apt” and “tel” (telephone) → “tell”. Some of these errors may have been addressed more accurately by using an n-gram language model to estimate the best possible correction.
10
For example, the phrase “get
Introducing dependency relations (Dd) into the model provided a large boost to the overall system performance: the second largest increase in precision, the second largest increase in recall, and the second largest increase in overall F1. The variable dependencies feature (Dv) conflated dependencies such as “dobj(blame, John)” and “dobj(blame, Mary)” into “dobj(blame,
As one might expect, each classifier did particularly poorly on the emotions that occurred infrequently in the training data. Indeed, the performance of the classifiers for these emotions was so poor that we had better results simply ignoring these emotions rather than include them in our final labeling. Improving our performance on these emotions should be the focus of the continuing development of this work; we suspect that additional training data would have aided.
Our attempts to use classifier combinations were only partially successful. We have demonstrated that introducing the emotionless classifier to boost the confidence of our labelings provided a large increase in recall; however, this yielded a large decrease in precision, with the F1 score remaining largely unchanged. We also explored using logistic regression to select a panel of orthogonal classifiers with combinations of features that might better balance precision and recall. The efforts to select small panels from 48 combinations of features using regression models were not feasible in the time available to us but may warrant further investigation. An exhaustive evaluation of all pairs and triples of classifier combinations found that no combination of two or three classifiers outperformed the best standalone classifier.
In developing our classifiers, we tried to consider the practical applications of the findings from this exercise. 11 The loss of any life is sad, and the early termination of one's own life particularly so. There is no doubt in our minds that the sentiments expressed in the suicide notes must have been present prior to the actual time of suicide. We consider that there may have been previous efforts to express these emotions to other people. We anticipate that one might consider employing an automatic detection algorithm on social networking platforms. This could review posts and activate access to support networks. However, only systems with very high precision would be of any practical value: high precision is more important than high recall because we would not wish to propose interventions unless we were extremely confident in our predictions.
Towards that goal, our final system, S3, attempted to achieve high precision at the expense of recall, while minimizing the impact on F1 score. Potentially, we could have looked to further improve precision with detrimental effects on recall and F1 score, though it is encouraging that we achieved high precision while maintaining an F1 score similar to the mean of all systems submitted to this shared task. Further research might be required to consider whether the sentiments expressed on suicide notes are truly expressed previously. Further information on the age, gender and physical and psychiatric health of these people may be of value.
Previous work in suicide note authorship detection used structural and grammatical features such as the number of paragraphs in the note, the number of misspellings, and the depth of parse tree. 12 Our intuition was that these features would not have been useful here, though we corrected spelling errors and used dependency relations from a parser. Structural and grammatical features should be investigated further.
Conclusion
We have shown that it is possible to construct classifiers that can perform well on this task and we have shown that dependency relations can be used effectively as features in these classifiers. We presented a classifier that performs at high levels of precision in order to be useful as a mechanism to propose intervention. We are confident that further improvements could be achieved using off-the-shelf components as done here.
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
We acknowledge the efforts of the i2b2 organizers and all of the brave efforts of the volunteers who kindly annotated the extensive and sensitive dataset.