
Abstract
This paper presents our solution for the i2b2 sentiment classification challenge. Our hybrid system consists of machine learning and rule-based classifiers. For the machine learning classifier, we investigate a variety of lexical, syntactic and knowledge-based features, and show how much these features contribute to the performance of the classifier through experiments. For the rule-based classifier, we propose an algorithm to automatically extract effective syntactic and lexical patterns from training examples. The experimental results show that the rule-based classifier outperforms the baseline machine learning classifier using unigram features. By combining the machine learning classifier and the rule-based classifier, the hybrid system gains a better trade-off between precision and recall, and yields the highest micro-averaged F-measure (0.5038), which is better than the mean (0.4875) and median (0.5027) micro-average F-measures among all participating teams.
Introduction
Previous biomedical text mining research has mostly focused on dealing with the factual aspects in the text, such as identifying biomedical entities (e.g., gene and protein names), classifying biomedical articles based on whether the article discusses a given topic (e.g., proteinprotein interactions), and extracting relationships (e.g., gene regulatory relationships), etc. More recently, increasing attention has been paid to the analysis of sentiments of subjective biomedical text. Sentiment analysis of biomedical text (e.g., the text from patients with mental illnesses) is considered an important way to understand patients’ thoughts, so as to facilitate the research and promote the treatment of the illness. The fifth i2b2 (Informatics for Integrating Biology and the Bedside) challenge announced such a task 1 , which asked the participants to find fine-grained sentiments in suicide notes.
To be more specific, a collection of suicide notes was made available by the challenge organizers, and each note was manually annotated at the sentence level. The annotation schema consists of 15 categories, among which 13 categories are sentiment-related, including
This classification task has the following characteristics that separate it from many other similar tasks and make it more challenging: (1) the classes cover both factual (ie, information and instructions) and sentimental aspects. It separates this task from traditional topic classification that focuses on classifying text by objective topics (e.g., music vs. sports) and sentiment classification that engages in classifying text by subjective sentiment (e.g., positive vs. negative), (2) some sentences have more than one label, (3) sentences with similar content might have different labels, which suggests that it is important to capture the context of sentences for classification, and (4) the class distribution is highly imbalanced. For example, in the training data set, there are 820 sentences labeled as
Before giving an overview of our approach, we name a few relevant studies on suicide note analysis and fine-grained sentiment classification. Pestian et al.
2
utilized machine learning algorithms to differentiate genuine notes and elicited suicide notes. Pang et al.
3
classified movie reviews into multiple classes by modelling the relationships between different classes, e.g.,
In this paper, we create a hybrid system that combines both machine learning and rule-based classifiers. For the machine learning classifier, we investigate the effectiveness of different types of features for this specific classification task that covers both factual and sentimental categories. Knowledge-based and simple syntactic features that have been shown effective in many sentiment analysis studies are verified useful for this task. In addition, we find that sophisticated syntactic features (ie, sentence tense, subject, direct object, indirect object, etc.) can further improve the performance. For the rule-based classifier, we propose an algorithm for automatic construction of a pattern set with lexical and syntactic patterns extracted from training data set, and our experiments show that it outperforms the baseline machine learning classifier using unigram features. Observing that the machine learning classifier achieves relatively high precision and low recall, in order to improve the performance, we combine it with the rule-based classifier to get a better trade-off between precision and recall in the hybrid system.
The rest of the paper is organized as follows. We first describe our approach and focus on the features used by the machine learning classifier and automatic construction of pattern set used by the rule-based classifier. Then we discuss the experiments and results for all three classifiers (ie, the machine learning classifier, the rule-based classifier and the hybrid classifier), before coming to the conclusion at last.
Approach
In this section, we first discuss the preprocessing of the input notes, then list different types of features for the machine learning classifier, and at last describe how we automatically extract patterns from the training data set and create the rule-based classifier.
The preprocessing serves two purposes: (1) to normalize the input text so that the language parser can achieve higher accuracy, and (2) to make generalization over raw text so that syntactically different but semantically similar signals can be aggregated. For (1), we correct misspellings (e.g.,
The machine learning classifier
SVM is an off-the-shelf supervised learning approach which has been shown to be highly effective for text classification. Its idea is to map input vectors into higher dimension space by a kernel function and then draw a separating hyperplane to maximize the margin between the plane and the nearest vectors. We use LIBSVM 8 , an open source SVM implementation, which supports multi-class classification by applying a “one-against-one” approach. A variety of features used by the classifier can be divided into the following groups (also see Table 1):
N-gram features: These are simple features based on unigrams, bigrams and trigrams. We apply MIT Java Wordnet Interface a for stemming. Observing that stop words might be useful for capturing the properties of some categories, we do not do any stop word removal. In addition, we require the minimum occurrence for each feature should be ≥ 3.
Knowledge-based features: These are features based on prior knowledge about the subjectivity, sentiments or semantic categories of English words. Specifically, we use MPQA 7 and LIWC b (Linguistic Inquiry and Word Count). MPQA is a subjective lexicon, which provides sentiment polarities (positive/negative/neutral) and strength (strong-subj/weaksubj) of 8,211 words. For each input sentence, we count the numbers of positive, negative, neutral, strongsubj, and weaksubj words according to MPQA as features. LIWC is a text analysis program with an in-built dictionaries. For each piece of input text, it outputs a vector with 69 dimensions covering positive/negative sentiments, casual words, numbers, etc.
Syntactic features: These are features based on syntactic information of the text, including dependency relation, POS (part-of-speech) tag and sentence tense. We first apply Stanford Parser
9
to parse each sentence and get corresponding collapsed dependencies. For each collapsed dependency
Context features: We hypothesize that the sentiments of the surrounding sentences may affect the sentiment of the current sentence. So we use MPQA feature
Besides the above generic features which don't focus on a specific class, we propose a few class-specific features targeting at
Information features: We observe that sentences indicating the location of property are more likely to be labeled as
Instruction features: We also observe that sentences that ask other people to do something or to give something to someone are usually labeled as
Features used by the SVM classifier.

The rule-based classifier
Rule-based approaches are widely employed for sentiment classification. One example is the usage of sentiment bearing words, e.g., the word “excellent” suggests positive sentiment, while “nasty” indicates negative sentiment in the text. The text is classified as positive or negative depending on the sentiment bearing words it contains.
Following a similar idea, we developed a rule-based classifier which leverages lexical and syntactic patterns to classify sentences in suicide notes. Manually constructing such a set of lexical and syntactic patterns in different categories can be laborious and time-consuming, especially in this case where the patterns should be collected for 15 categories. Therefore, we propose an algorithm to automatically extract patterns from the training data set.
Let
The algorithm starts with extracting candidate patterns, which include (1) n-grams up to length four (e.g.,
After collecting all candidate patterns, the
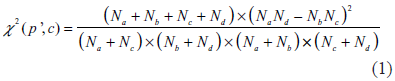
where
In the following step, the algorithm estimates the value of
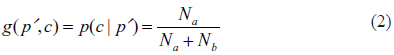
We remove patterns with
Based on the pattern set
Experiments and Discussions
In this section, we present and discuss the experimental results. The challenge provided a total of 900 suicide notes, 600 of which were released as the training set, and the other 300 notes were used for testing. Each note had been annotated at the sentence level. As the challenge required, the classification results were evaluated using micro-averaged F-measure. We first conducted experiments using the SVM classifier and the rule-based classifier separately, and then examined the performance of the hybrid classifier created by combining both SVM and rule-based classifiers. We first trained all classifiers on the training dataset and then applied them to the testing dataset. All the results below are obtained from 300 testing suicide notes.
Evaluation of the machine learning classifier
We applied LIBSVM to do multi-class classification. We chose Radius Basis Function (RBF) as the kernel function, and we applied grid search script in LIB-SVM package to find the optimal values for parameters
Table 2 gives the results of the SVM classifier using different feature combinations. Since there are many different features, we applied a greedy fashion approach to find an optimal feature combinations. We started with combining features in n-gram category and found the optimal n-gram feature combination. Then based on this optimal feature combination, we incorporated features from the next category, and searched for a new feature combination with a better result. We repeated the above procedures until all the feature categories had been explored. For each feature category in Table 2, we highlight the best feature combination if its performance is better than the best performance in previous feature category.
Performance of the SVM classifier with different feature combinations on the testing data.
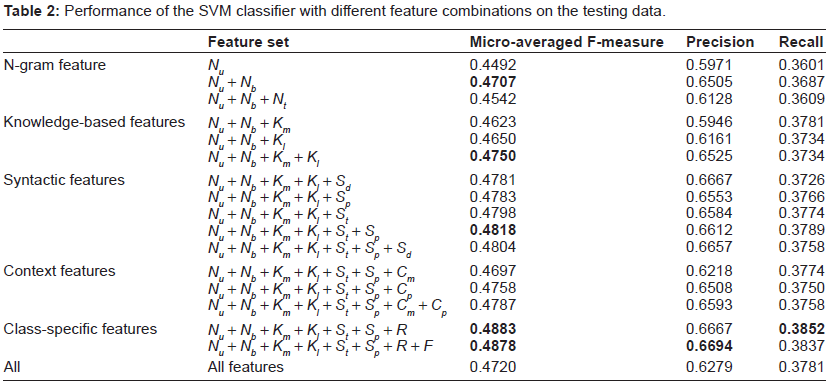
Applying selected features from n-grams, knowledge-based, syntactic and class-specific feature categories, we got the best micro averaged F-measure, the best recall and the second best precision. And the best F-measure, 0.4883, is 3.9% higher than the F-measure of the baseline and is slightly higher than the mean F-measure among all participating teams (0.4875). More specifically, we want to analyze the utility of different features. For n-gram features, the combination of unigrams and bigrams gets an F-measure of 0.4707, while adding trigrams decreases the F-measure to 0.4542. For knowledge-based features, it is interesting to see that MPQA or LIWC features alone decrease the performance, but applying both of them increases the performance by 0.43%. Among individual syntactic features, adding sentence tense features increases F-measure by 0.48%, which verifies that sentence tense features are useful for differentiating different categories. It's surprising that adding context features does not improve the result, which may suggest that it is not sufficient to capture context with only the previous and next sentences. Applying class-specific features for
Evaluation of the rule-based classifier
We studied the effect of varying values of threshold
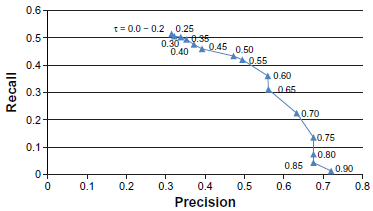
Precision-recall curve of the rule-based classifier with varying threshold
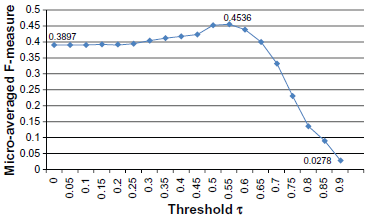
F-measure of the rule-based classifier with varying threshold
According to Figure 1, the precision increases and the recall decreases with the threshold
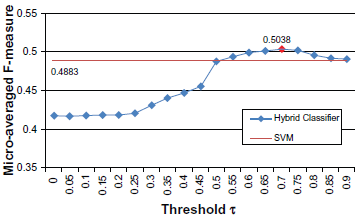
F-measure of the combined classifier on the test data.
Evaluation of the hybrid classifier
A hybrid classifier was created by combining the SVM classifier and the rule-based classifier. Since SVM classifier exhibited the property of relatively high precision and low recall, we considered using the rule-based classifier to improve the recall. Following this idea, we applied a simple combination algorithm.
Each sentence was fed to both SVM classifier and rule-based classifier to get the judgements respectively. If a sentence is assigned the label of any of the 15 categories by the SVM classifier, we keep the label, otherwise, we accept the label given by the rule-based classifier. For example, a sentence
We combined the SVM classifier that got the best result in the previous experiments with different rule-based classifiers tuned by the threshold
Conclusion
In this paper, we presented our approach for the i2b2 Challenge of fine-grained sentiment classification of suicide note. We developed a hybrid system by combining both a machine learning classifier and a rule-based classifier for this task. For the machine learning classifier, we focused on examining the effectiveness of different types of features. Our experiments showed how much the various features contributed to the performance of the classifier. For the rule-based classifier, we proposed a method for creating the pattern set automatically, and the performance of the classifier could be tuned up by a threshold
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
This work was supported by NSF IIS-1111182: SoCS: Collaborative Research: Social Media Enhanced Organizational Sensemaking in Emergency Response.